你好呀,我是苍何!
办公室里鸦雀无声,我木然的看着窗外射进来的阳光,它照在光滑的地板上,又反射到天花板上,再从天花板上反射下来时,就变成一片弥散的白光。
我在白光里偷偷放了一个恶毒的臭屁,如果是以前,同事们会偷偷捂住鼻子,然后目光看向旁边的人,没有人看向我,我也捂住鼻子,附和的来了句"谁又放毒了?"。
其实我却在心里偷偷笑,反正谁也猜不到是我。
如今办公室除了我再无一人,我还要在自己的臭屁下写文章,可能因此我的文章多少有些被「污染」。
但我依旧希望我的文章不是屁,最起码不能是臭屁。
那接下来,苍何给大家分享一个大厂面试常见问题:
如何保证缓存和数据库的一致性?,也即是既要又要怎么做?
缓存的重要性
缓存大家都并不陌生,说白了就是一种存储机制,用于暂时保存数据,以加速数据的读取和访问。
数据库好好的为什么要用缓存?关键点在于缓存快啊!
比如微信中的很大消息都是缓存在你本地手机的,(看到有自媒体博主发视频说能找回你 10 年前的微信聊天记录,大哥,前提是你 10 年不换手机?或者每次换手机你都能把所有聊天记录导出来?)
微信手机中的缓存是一种常见的本地缓存,对于开发来说本地缓存常用有以下这些:
- JDK 自带的 HashMap 和 ConcurrentHashMap
- Ehcache、Guava Cache、Spring Cache、Caffeine 等常见的本地缓存框架
除了本地缓存,还有常见的分布式缓存如常用的 Redis。本地缓存和分布式缓存很好区别,本地缓存和应用在同一个地方,而分布式缓存是可以独立部署在不同的服务器上的,比如 Redis 可以单机或者集群部署在不同的服务器上。
不管是本地缓存还是分布式缓存,都只有一个目的,那就是用空间换时间,用更多的存储空间来存储一些可能重复使用或计算的数据,从而减少数据的重新获取或计算的时间。
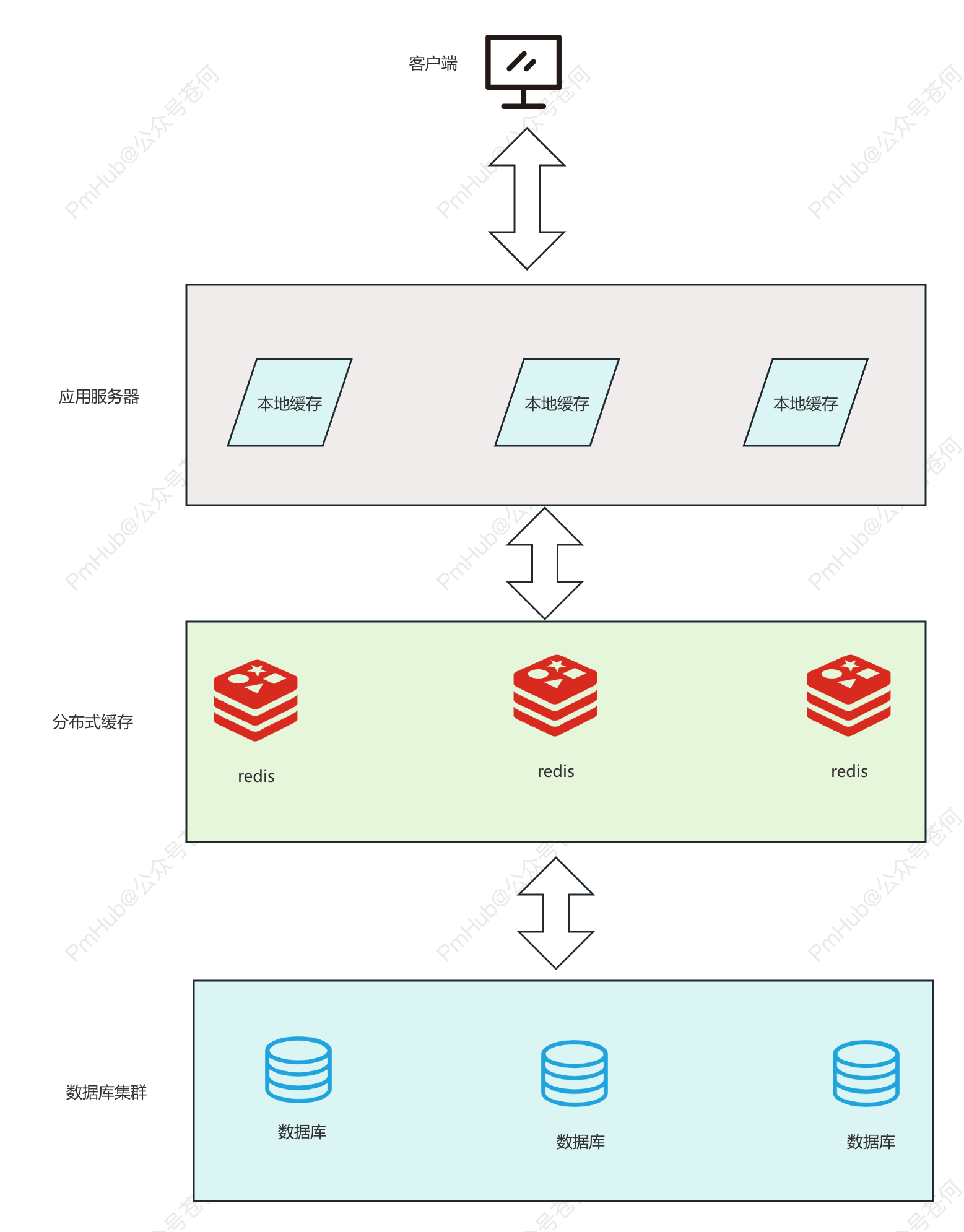
缓存一致性问题
你有没有想过一个问题,既然一份数据同时在缓存中和数据库中都有,那这两者到底哪个是最新数据呢?如何保证其数据一致性呢?
那么导致不一致的原因主要有:
- 缓存过期:缓存中的数据有一个生命周期,当数据过期后,如果没有及时更新,就会出现不一致的情况。
- 写操作延迟:在执行写操作时,数据库更新和缓存更新的时间不同步,可能会导致缓存中的数据不一致。
- 并发操作:多个并发操作同时进行,可能会导致数据更新时出现竞态条件,从而导致缓存和数据库数据不一致。
- 缓存失效策略不当:使用不当的缓存失效策略,可能导致缓存中的数据无法及时更新,导致不一致。
- 网络延迟或故障:由于网络延迟或故障,缓存服务器和数据库之间的通信出现问题,导致数据不一致。
常见的解决不一致问题有如下解决方案:
- Cache Aside 模式:在读写操作中使用 Cache Aside 模式,确保在写操作后及时失效缓存中的数据。
- 分布式锁:在并发写操作时使用分布式锁,确保同时只有一个操作能够更新缓存和数据库,避免竞态条件。
- 双写一致性:在写操作时同时更新数据库和缓存,确保数据的一致性。
- 延迟双删:在写操作时,先删除缓存中的数据,更新数据库后,再次删除缓存中的数据,确保缓存中数据的一致性。
- 版本控制:在缓存和数据库中使用版本号或时间戳,确保数据更新时的一致性检查。
- 监控和告警:对缓存和数据库中的数据进行监控,发现不一致时及时告警并处理。
而 PmHub 中主要围绕 Cache Aside 模式、分布式锁、监控和告警来解决一致性问题,之前章节有介绍分布式锁以及监控告警相关的能力,本节主要针对的 Cache Aside 模式。
常见缓存更新策略
先直接看苍何给做的汇总表吧:
| 模式名称 | 描述 | 优点 | 缺点 | 使用场景 |
| Cache Aside Pattern (旁路缓存模式) | 读取数据时先检查缓存,缓存未命中则从数据库读取并更新缓存。写入数据时先更新数据库,然后使缓存失效。 | - 读取性能高 - 实现简单 | - 首次请求数据一定不在缓存问题 - 写操作较频繁的话会导致缓存中数据被频繁删除,会影响缓存命中率 | - 数据读取频率高,写入频率较低的场景 |
| Read/Write Through Pattern (读写穿透模式) | 所有的读写操作都通过缓存进行,缓存负责同步数据库。 | - 数据一致性好 - 实现了读写操作的统一 | - 实现复杂 - 依赖缓存的高可用性 | - 数据读取和写入频率均较高的场景 |
| Write Behind Pattern (异步缓存写入) | 写操作首先更新缓存,然后异步地将数据写入数据库。 | - 写操作性能高 - 减少数据库压力 | - 存在数据丢失的风险 - 数据一致性较差 | - 写操作频繁,且对实时一致性要求不高的场景 |
Cache Aside 模式概述
数据不一致的主要原因还是先写缓存还是先更新数据库的问题,不正确的方案我们就不阐述了,省的增加同学们的负担。那么 PmHub 采用的就是 Cache Aside 模式来保证缓存和数据库的一致性。
Cache Aside 模式其实就是读取数据时先检查缓存,缓存未命中则从数据库读取并更新缓存。写入数据时先更新数据库,然后使缓存失效。用一张图或许你更好理解一些:
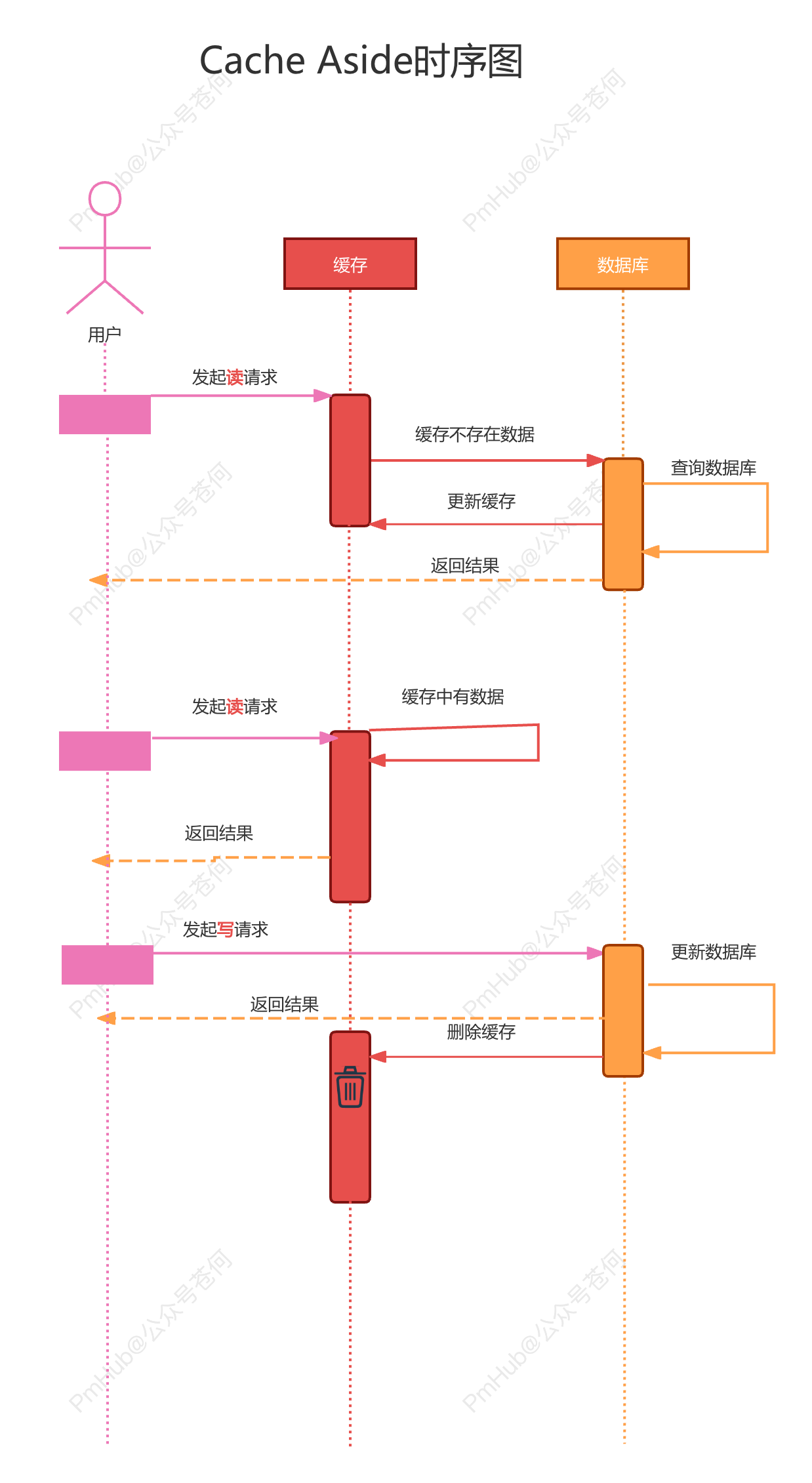
Cache Aside 模式优点和局限
优点
- 读取性能高:
- 缓存命中时可以直接从缓存中读取数据,速度非常快,显著减少了数据库的访问压力。
- 实现简单:
- 该模式逻辑清晰,容易理解和实现,只需在读取和写入操作时分别处理缓存和数据库即可。使用的也比较多的一种方案了。
- 灵活性强:
- 程序员可以根据需要灵活地控制缓存的更新和失效策略,适应不同的应用场景和需求。
- 缓存利用率高:
- 只有在缓存未命中时才从数据库读取数据并更新缓存,避免了不必要的数据冗余。
局限
- 写操作较慢:
- 每次写操作都需要更新数据库并使缓存失效,这样的操作过程较长,导致写操作性能较低。
- 数据一致性挑战:
- 缓存和数据库之间可能会出现数据不一致的情况,特别是在高并发环境下,更容易出现缓存失效不及时或者更新顺序问题。
- 缓存预热问题:
- 初始时缓存为空,第一次读取时会有较大的延迟,直到缓存被逐渐填充起来。所以热点数据建议直接放入缓存
- 复杂的失效策略:
- 程序员需要设计合理的缓存失效策略,以确保缓存的数据及时更新,这增加了实现和维护的复杂性。具体怎么设置失效策略又体现了经验了。
- 过期数据风险:
- 如果没有合适的失效机制,缓存中可能会存在过期数据,从而返回错误或过时的信息给用户。
Cache Aside 模式在读取性能和实现简单性上有显著的优点,但在写操作性能和数据一致性上面临挑战。在使用这种模式时,需要根据具体应用场景设计合理的缓存更新和失效策略,以最大化其优点并最小化其局限。
对于 PmHub 业务来说,Cache Aside 模式就是最大化利用其优点以及最小化利用其局限性的实践。
PmHub 最佳实践
数据读取
原理很简单,就是先查询缓存,如果有就直接返回,没有就去数据库查询,然后再写入缓存。
这个在 PmHub 中很多地方的代码都有使用,随便举个例子吧:
/**
* 根据键名查询参数配置信息
*
* @param configKey 参数key
* @return 参数键值
*/
@Override
public String selectConfigByKey(String configKey) {
String configValue = Convert.toStr(redisService.getCacheObject(getCacheKey(configKey)));
if (StringUtils.isNotEmpty(configValue)) {
return configValue;
}
SysConfig config = new SysConfig();
config.setConfigKey(configKey);
SysConfig retConfig = configMapper.selectConfig(config);
if (StringUtils.isNotNull(retConfig)) {
redisService.setCacheObject(getCacheKey(configKey), retConfig.getConfigValue());
return retConfig.getConfigValue();
}
return StringUtils.EMPTY;
}
数据更新
更新数据的时候,先去更新数据库信息,然后再删除缓存,这个在 PmHub 中很多地方都有使用,比如在批量删除参数信息的场景下,先删除数据库信息,然后再删除缓存信息,代码如下:
/**
* 批量删除参数信息
*
* @param configIds 需要删除的参数ID
*/
@Override
public void deleteConfigByIds(Long[] configIds) {
for (Long configId : configIds) {
SysConfig config = selectConfigById(configId);
if (StringUtils.equals(UserConstants.YES, config.getConfigType())) {
throw new ServiceException(String.format("内置参数【%1$s】不能删除 ", config.getConfigKey()));
}
configMapper.deleteConfigById(configId);
redisService.deleteObject(getCacheKey(config.getConfigKey()));
}
}
当然了,大家可以直接下载 PmHub 的源码,单体版本和微服务版本都可以看看里面具体的使用场景,如果有问题,也欢迎评论区留言,一起讨论。
面试
基于 PmHub 中缓存数据一致性解决方案,面试官可能会问到如下点,同学们只需要好好准备即可。
你们项目中是如何保证缓存和数据一致性的?
这个问题,建议大家学习完本章后,按照自己的理解作答,更加具有真实性
redis 有哪里数据类型
这个是比较基础的问题了,细节网上搜搜,背一背八股。
为什么你删除缓存,而不更新缓存呢?
主要原因有 2 点:
1、更新缓存浪费服务器资源:频繁的缓存更新可能导致缓存服务器的负载增加,通过删除缓存而不是频繁更新,可以减少缓存服务器的压力,提高系统整体性能。
2、避免脏读:在高并发环境下,如果在写操作时直接更新缓存,可能会导致并发读操作获取到未完全更新的数据,从而产生脏读现象。删除缓存可以避免这种情况,因为在缓存被删除后,所有读操作都会直接从数据库读取最新数据。
3、减少并发冲突:如果在写操作时直接更新缓存,可能会引发大量的并发冲突,特别是在频繁写操作的情况下。通过删除缓存,可以减少并发冲突的可能性,简化并发控制。
4、避免双写问题:在写操作时同时更新数据库和缓存,可能会导致双写不一致的问题。如果在更新数据库后失败了,缓存和数据库数据可能不同步。删除缓存可以避免这种双写问题,只需保证数据库写入成功。
先更新 DB,再删除缓存就是完美解决方案了吗?
其实面试官问这个问题,主要是想考哈你严禁性,通常来说,没有完美的解决方案,但你得能 BB 个所以然出来。
那这个问题其实就转换为让你说说 Cache Aside 的局限性,所以完全可以参考本章节关于局限性的解释来作答。
好啦,今天分享了关于数据和缓存一致性方案的一些见解,感谢阅读。