PIXART-α:扩散Transformer的快速训练,用于逼真的文本到图像合成
Paper Title:PIXART-α: FAST TRAINING OF DIFFUSION TRANSFORMER FOR PHOTOREALISTIC TEXT-TO-IMAGE SYNTHESIS
Paper是华为诺亚方舟实验室发表在ICLR 2024的工作
Paper地址
Code地址
项目地址
ABSTRACT
最先进的文本生成图像 (T2I) 模型需要显著的训练成本(例如,数百万 GPU 小时),这严重阻碍了 AIGC 社区的基础创新,并增加了 C O 2 \mathrm{CO}_2 CO2 排放。本文介绍了 PiXART- α \alpha α,这是一种基于 Transformer 的 T2I 扩散模型,其图像生成质量可与最先进的图像生成器(例如,Imagen、SDXL,甚至 Midjourney)竞争,达到了接近商业应用的标准。此外,它支持高达 1024 × 1024 1024 \times 1024 1024×1024 分辨率的高分辨率图像合成,训练成本较低,如图 1 和图 2 所示。为了实现这一目标,提出了三个核心设计:(1)训练策略分解:我们设计了三个不同的训练步骤,分别优化像素依赖性、文本图像对齐和图像审美质量;(2)高效的 T2I Transformer:我们在扩散 Transformer (DiT) 中引入了交叉注意力模块以注入文本条件,并简化了计算密集的类别条件分支;(3)高信息量的数据:我们强调文本图像对中概念密度的重要性,并利用大型视觉语言模型自动标注密集伪标签,以辅助文本图像对齐学习。因此,PiXART- α \alpha α 的训练速度显著超过现有的大规模 T2I 模型,例如,PiXART- α \alpha α 仅占 Stable Diffusion v1.5 训练时间的 12 % 12\% 12%( ∼ 753 \sim 753 ∼753 vs. ∼ 6 , 250 \sim 6,250 ∼6,250 A100 GPU 天),节省了近 $300,000 ($ 28,400 vs . $320,000),减少了 90 % 90 \% 90% 的 C O 2 \mathrm{CO}_2 CO2 排放。此外,与较大的 SOTA 模型 RAPHAEL 相比,我们的训练成本仅为其 1 % 1\% 1%。广泛的实验表明,PiXART- α \alpha α 在图像质量、艺术性和语义控制方面表现出色。我们希望 PiXART- α \alpha α 能为 AIGC 社区和初创公司提供新的见解,加速从零开始构建自己的高质量、低成本的生成模型。
1 INTRODUCTION
最近,文本到图像 (T2I) 生成模型的进步,例如 DALL·E 2 (OpenAI, 2023)、Imagen (Saharia 等人, 2022) 和 Stable Diffusion (Rombach 等人, 2022) 开启了真实感图像合成的新时代,深远影响了众多下游应用,例如图像编辑 (Kim 等人, 2022)、视频生成 (Wu 等人, 2022)、3D 资产创建 (Poole 等人, 2022) 等。
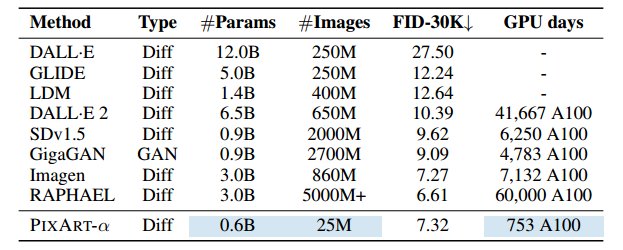
然而,训练这些先进模型需要大量的计算资源。例如,训练 SDv1.5 (Podell et al, 2023) 需要 6K A100 GPU 天,大约花费 320,000 美元,而最近的大型模型 RAPHAEL (Xue et al, 2023b) 甚至需要 60K A100 GPU 天——大约需要 3,080,000 美元,如表 2 所示。此外,训练会产生大量二氧化碳排放,对环境造成压力;例如,RAPHAEL (Xue et al, 2023b) 的训练会产生 35 吨二氧化碳排放,相当于一个人 7 年的排放量,如图 2 所示。如此巨大的成本为研究界和企业家获取这些模型设置了重大障碍,对 AIGC 社区的关键进步造成了重大阻碍。面对这些挑战,一个关键问题出现了:我们能否开发出一种资源消耗可承受的高质量图像生成器?

图 1:PIXART-α 制作的样本展现出卓越的品质,其特点是在遵循所提供的文本描述方面具有非凡的保真度和精确度。
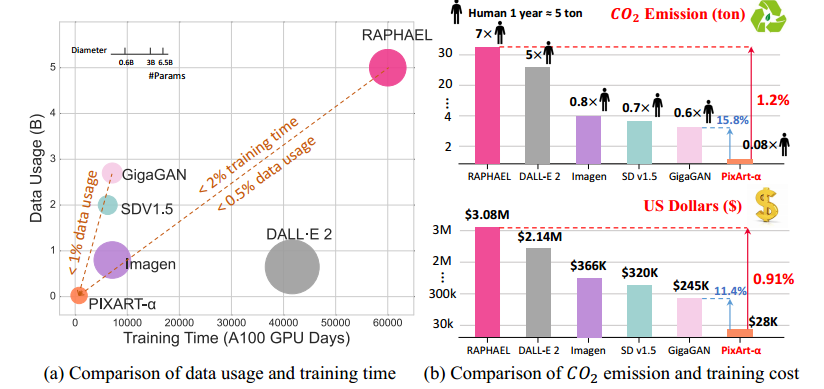
图 2:T2I 生成器之间的二氧化碳排放量和培训成本比较。PIXART-α 的训练成本极低,仅为 28,400 美元。与 RAPHAEL 相比,我们的二氧化碳排放量和训练成本分别仅为 1.2% 和 0.91%。
表 2:我们全面比较了 PIXART-α 与最近的 T2I 模型,考虑了几个基本因素:模型大小、训练图像总量、COCO FID-30K 分数(零样本)和计算成本(GPU 天数)。我们的高效方法显著减少了资源消耗,包括训练数据使用量和训练时间。基线数据来自 GigaGAN(Kang 等人,2023 年)。表中的“+”表示未知的内部数据集大小。
在本文中,我们介绍了 PIXART-α,它显著降低了训练的计算需求,同时保持了与当前最先进的图像生成器相当的图像生成质量,如图 1 所示。为了实现这一点,我们提出了三种核心设计:
训练策略分解。我们将复杂的文本到图像生成任务分解为三个精简的子任务:(1)学习自然图像的像素分布,(2)学习文本图像对齐,以及(3)增强图像的美学质量。对于第一个子任务,我们建议使用低成本的类条件模型初始化 T2I 模型,从而显着降低学习成本。对于第二和第三个子任务,我们制定了一个由预训练和微调组成的训练范式:对信息密度丰富的文本图像对数据进行预训练,然后对具有卓越美学质量的数据进行微调,从而提高训练效率。
高效的 T2I Transformer。基于扩散变换器 (DiT) (Peebles & Xie, 2023),我们结合交叉注意模块来注入文本条件并简化计算密集型类条件分支以提高效率。此外,我们引入了一种重参数化技术,允许调整后的文本到图像模型直接加载原始类条件模型的参数。因此,我们可以利用从 ImageNet (Deng et al, 2009) 学到的关于自然图像分布的先验知识为 T2I Transformer 提供合理的初始化并加速其训练。
信息量高的数据。我们的调查揭示了现有文本-图像对数据集的显著缺陷,例如 LAION(Schuhmann 等人,2021 年),其中文本标题通常缺乏信息内容(即通常仅描述图像中的部分对象)和严重的长尾效应(即大量名词出现的频率极低)。这些缺陷严重阻碍了 T2I 模型的训练效率,并导致数百万次迭代才能学习稳定的文本-图像对齐。为了解决这些问题,我们提出了一种自动标记流程,利用最先进的视觉语言模型(LLaVA(Liu 等人,2023 年))在 SAM(Kirillov 等人,2023 年)上生成标题。参考2.4节,SAM数据集由于其丰富多样的目标集合而具有优势,使其成为创建高信息密度文本-图像对的理想资源,更适合文本-图像对齐学习。
我们的有效设计使得模型训练效率显著,仅需 753 A100 GPU 天和28,400 的成本。如图 2 所示,与 SDv1.5 相比,我们的方法消耗的训练数据量不到 1.25%,与 RAPHAEL 相比,训练时间不到 2%。与 RAPHAEL 相比,我们的训练成本仅为其 1%,节省了大约 3,000,000(PIXART- α \alpha α 的28,400 vs . RAPHAEL 的3,080,000)。关于生成质量,我们的用户研究实验表明,PIXART- α \alpha α 提供了比现有 SOTA T2I 模型(例如 DALL ⋅ \cdot ⋅E 2(OpenAI, 2023),Stable Diffusion(Rombach et al., 2022)等)更好的图像质量和语义对齐,并且在 T2I-CompBench (Huang et al., 2023) 上的表现也证明了我们在语义控制方面的优势。我们希望我们在高效训练 T2I 模型方面的尝试能为 AIGC 社区提供有价值的见解,并帮助更多的独立研究人员或初创公司以较低的成本创建自己的高质量 T2I 模型。
2 METHOD
2.1 MOTIVATION
T2I 训练缓慢的原因有两个方面:训练流程和数据。
T2I 生成任务可以分解为三个方面:捕获像素依赖性:生成逼真的图像需要理解图像内复杂的像素级依赖性并捕获其分布;文本和图像之间的对齐:需要精确的对齐学习才能理解如何生成与文本描述准确匹配的图像;高美学质量:除了忠实的文本描述之外,美观是生成图像的另一个重要属性。当前的方法将这三个问题纠缠在一起,并使用大量数据直接从头开始训练,导致训练效率低下。为了解决这个问题,我们将这些方面分为三个阶段,如第 2.2 节所述。
图 3 中所示的另一个问题是当前数据集的标题质量。当前的文本-图像对经常存在文本-图像错位、描述不足、词汇使用不频繁以及包含低质量数据的问题。这些问题给训练带来了困难,导致需要进行数百万次不必要的迭代才能实现文本和图像之间的稳定对齐。为了应对这一挑战,我们引入了一种创新的自动标记流程来生成精确的图像标题,如第 2.4 节所述。

图 3:LAION 原始字幕与 LLaVA 精炼字幕。LLaVA 提供高信息密度字幕,帮助模型在每次迭代中掌握更多概念并提高文本-图像对齐效率。
2.2 TRAINING STRATEGY DECOMPOSITION
通过将训练分为具有不同数据类型的三个阶段,可以逐步优化模型的生成能力。
第 1 阶段:像素依赖性学习。当前的类引导方法 (Peebles & Xie, 2023) 在生成单个图像中语义连贯且合理的像素方面表现出色。如附录 A.5 所述,为自然图像训练类条件图像生成模型 (Peebles & Xie, 2023) 相对容易且成本低廉。此外,我们发现合适的初始化可以显著提高训练效率。因此,我们从 ImageNet 预训练模型中提升了我们的模型,并且我们模型的架构设计为与预训练权重兼容。
第 2 阶段:文本-图像对齐学习。从预训练的类引导图像生成过渡到文本到图像生成的主要挑战是如何实现显著增加的文本概念和图像之间的精确对齐。
这种对齐过程不仅耗时,而且本身就具有挑战性。为了有效地促进这一过程,我们构建了一个由具有高概念密度的精确文本-图像对组成的数据集。数据创建管道将在第 2.4 节中描述。通过使用准确且信息丰富的数据,我们的训练过程可以在每次迭代中有效地处理大量名词,同时与以前的数据集相比,遇到的歧义要少得多。这种战略方法使我们的网络能够有效地将文本描述与图像对齐。
第 3 阶段:高分辨率和美观图像生成。在第三阶段,我们使用高质量美观数据对模型进行微调,以生成高分辨率图像。值得注意的是,我们观察到此阶段的适应过程收敛速度明显更快,这主要归功于前几个阶段建立的强大先验知识。
将训练过程分解为不同阶段大大减轻了训练难度,实现了高效的训练。
2.3 EFFICIENT T2I TRANSFORMER
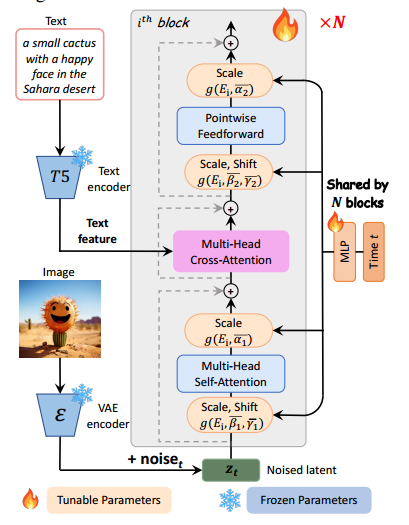
图 4:PIXART-α 的模型架构。每个块中都集成了一个交叉注意模块,用于注入文本条件。为了优化效率,所有块都共享相同的 adaLN-single 参数用于时间条件。
PIXART-α 采用扩散变换器 (DiT) (Peebles & Xie, 2023) 作为基础架构,并创新性地定制 Transformer 模块以应对 T2I 任务的独特挑战,如图 4 所示。提出了以下几种专用设计:
-
交叉注意层。我们将多头交叉注意层整合到 DiT 块中。它位于自注意层和前馈层之间,以便模型可以灵活地与从语言模型中提取的文本嵌入进行交互。为了方便预训练权重,我们将交叉注意层中的输出投影层初始化为零,有效地充当恒等并保留后续层的输入。
-
AdaLN-single。我们发现 DiT 的自适应归一化层 (Perez et al, 2018) (adaLN) 模块中的线性投影占据了相当大比例(27%)的参数。由于我们的 T2I 模型未使用类别条件,这么多参数并无实质性作用。因此,我们提出了 adaLN-single,它在第一个块中只使用时间嵌入作为输入进行独立控制(如图 4 右侧所示)。具体来说,在第 i i i 个块中,令 S ( i ) = [ β 1 ( i ) , β 2 ( i ) , γ 1 ( i ) , γ 2 ( i ) , α 1 ( i ) , α 2 ( i ) ] S^{(i)}=\left[\beta_1^{(i)}, \beta_2^{(i)}, \gamma_1^{(i)}, \gamma_2^{(i)}, \alpha_1^{(i)}, \alpha_2^{(i)}\right] S(i)=[β1(i),β2(i),γ1(i),γ2(i),α1(i),α2(i)] 为 adaLN 中所有缩放和平移参数的元组。在 DiT 中, S ( i ) S^{(i)} S(i) 是通过块特定的 MLP 获得的 S ( i ) = f ( i ) ( c + t ) S^{(i)}=f^{(i)}(c+t) S(i)=f(i)(c+t),其中 c c c 和 t t t 分别表示类别条件和时间嵌入。然而,在 adaLN-single 中,在第一个块中只根据时间嵌入计算一个全局的缩放和平移集合 S ˉ = f ( t ) \bar{S}=f(t) Sˉ=f(t),并在所有块中共享。然后, S ( i ) S^{(i)} S(i) 被表示为 S ( i ) = g ( S ˉ , E ( i ) ) S^{(i)}=g\left(\bar{S}, E^{(i)}\right) S(i)=g(Sˉ,E(i)),其中 g g g 是一个求和函数, E ( i ) E^{(i)} E(i) 是与 S ˉ \bar{S} Sˉ 形状相同的层特定可训练嵌入,用于自适应调整不同块中的缩放和平移参数。
-
重参数化。为了利用上述预训练权重,所有的 E ( i ) E^{(i)} E(i) 都被初始化为在选定的 t t t (经验上,我们使用 t = 500 t=500 t=500)情况下没有 c c c 的 DiT 中产生相同 S ( i ) S^{(i)} S(i) 的值。这个设计有效地用全局 MLP 和层特定可训练嵌入替代了层特定的 MLP,同时保留了与预训练权重的兼容性。
实验表明,结合全局 MLP 和层级嵌入以处理时间步信息,以及用于处理文本信息的交叉注意力层,可以在有效减少模型尺寸的同时,保持模型的生成能力。
2.4 DATASET CONSTRUCTION
图像文本对自动标记。如图 3 所示,LAION 数据集的标题表现出各种问题,例如文本图像错位、描述不足和词汇不常见。
为了生成具有高信息密度的标题,我们利用了最先进的视觉语言模型 LLaVA(Liu et al,2023)。使用提示“以非常详细的方式描述这幅图像及其风格”,我们显著提高了标题的质量,如图 3 所示。
然而,值得注意的是,LAION 数据集主要由购物网站上的简单产品预览组成,这对于训练追求对象组合多样性的文本到图像生成并不理想。因此,我们选择使用 SAM 数据集(Kirillov 等人,2023 年),该数据集最初用于分割任务,但具有富含多样化对象的图像。通过将 LLaVA 应用于 SAM,我们成功获得了具有高概念密度的高质量文本-图像对。
在第三阶段,我们通过结合 JourneyDB(Pan 等人,2023 年)和 10M 内部数据集构建我们的训练数据集,以提高生成的图像的美学质量,使其超越真实照片。
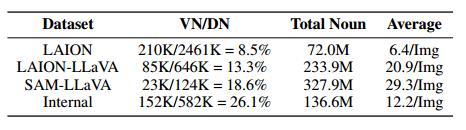
因此,我们在表 1 中展示了词汇分析(NLTK,2023),并将有效的不同名词定义为在数据集中出现 10 次以上的名词。我们将 LLaVA 应用于 LAION 以生成 LAIONLLaVA。LAION 数据集有 2.46 M 个不同名词,但只有 8.5% 是有效的。使用 LLaVA 标记的字幕,这个有效名词比例从 8.5% 显著增加到 13.3%。尽管 LAION 的原始字幕包含惊人的 210K 个不同名词,但其名词总数只有 72M。然而,LAION-LLaVA 包含 234M 个名词数字和 85K 个不同名词,每张图片的平均名词数量从 6.4 个增加到 21 个,这表明原始 LAION 字幕的不完整性。此外,SAM-LLaVA 的表现优于 LAION-LLaVA,总名词数为 328M,每张图片有 30 个名词,表明 SAM 包含更丰富的目标和每张图片更高的信息密度。最后,内部数据还确保了足够的有效名词和平均信息密度以进行微调。LLaVA 标记的标题显著提高了每张图片的有效率和平均名词数,从而提高了概念密度。
表 1:不同数据集的名词概念统计。
VN:有效不同名词(出现 10 次以上);DN:不同名词总数;Average:每张图片的平均名词数。