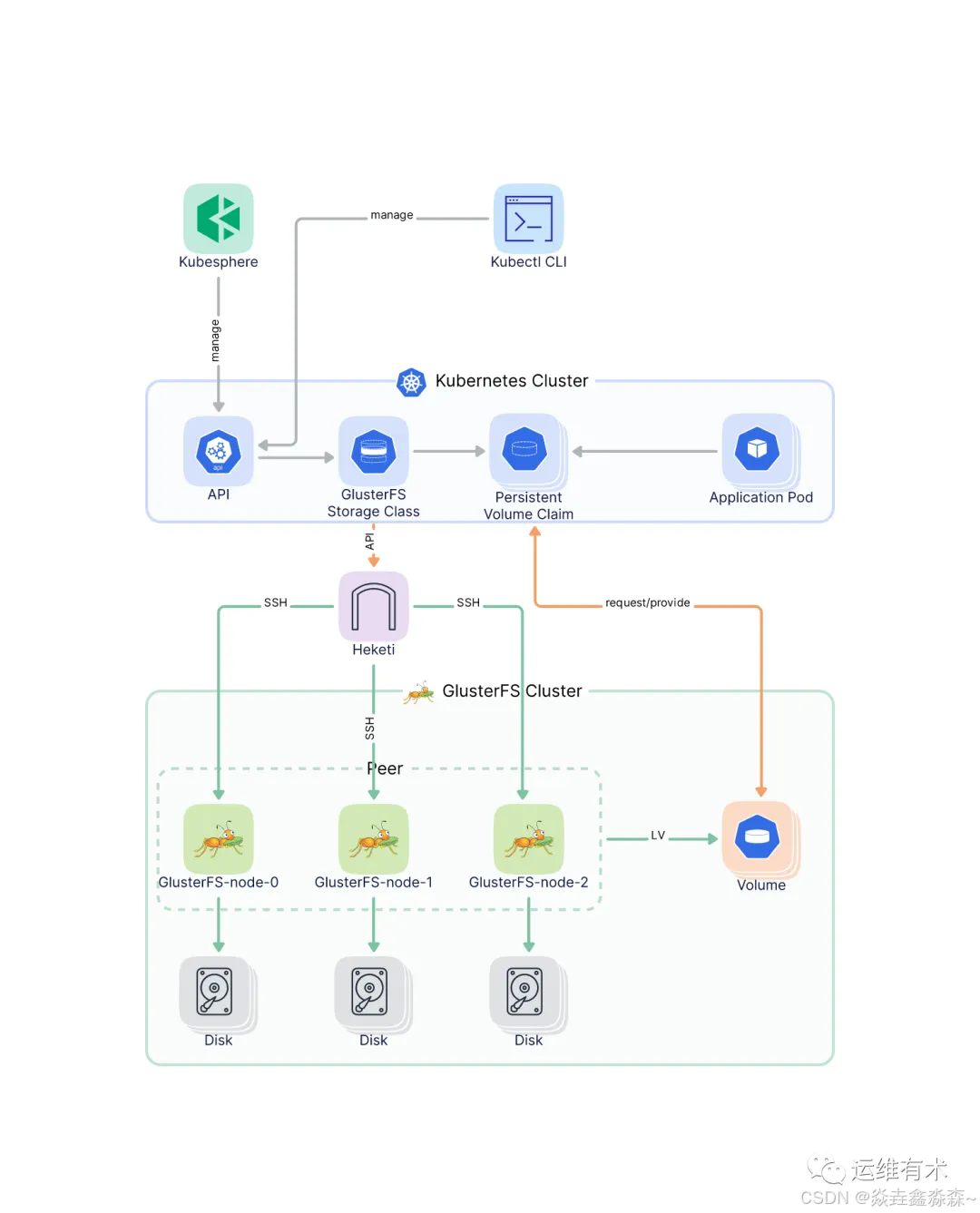
在使用Python进行网络爬虫项目时,数据清洗和预处理是非常重要的步骤。这些步骤有助于确保从网页上抓取的数据准确、一致,并且适合后续的分析或机器学习任务。下面我将详细介绍如何使用Python来进行数据清洗和预处理。

1. 数据获取
首先,你需要使用爬虫技术来获取数据。Python中有许多库可以帮助你完成这项工作,比如requests用于发送HTTP请求,BeautifulSoup或lxml用于解析HTML文档,以及Scrapy框架用于更复杂的爬虫项目。
示例代码:
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 假设我们要提取所有的文章标题
titles = [title.get_text() for title in soup.find_all('h1')]
2. 数据清洗
一旦数据被提取出来,就需要进行清洗。常见的数据清洗任务包括去除HTML标签、处理缺失值、去除重复项等。
示例代码:
# 去除多余的空格
cleaned_titles = [title.strip() for title in titles]
# 去除重复项
unique_titles = list(set(cleaned_titles))
3. 数据预处理
数据预处理通常涉及转换数据格式、标准化数据、填充缺失值等操作。
示例代码:
# 转换为小写
lowercase_titles = [title.lower() for title in unique_titles]
# 填充缺失值(如果有的话)
# 假设我们有一个包含其他字段的字典列表
data = [{'title': title, 'content': ''} for title in lowercase_titles]
for item in data:
if not item['content']:
item['content'] = 'No content available.'
4. 文本预处理
对于文本数据,你可能还需要执行一些特定的预处理步骤,例如分词、去除停用词、词干化等。
示例代码:
import nltk
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
nltk.download('stopwords')
nltk.download('punkt')
stemmer = PorterStemmer()
stop_words = set(stopwords.words('english'))
def preprocess_text(text):
tokens = nltk.word_tokenize(text)
filtered_tokens = [stemmer.stem(word) for word in tokens if word.isalpha() and word not in stop_words]
return ' '.join(filtered_tokens)
preprocessed_titles = [preprocess_text(title) for title in lowercase_titles]
5. 存储与分析
最后一步是存储这些数据以供进一步分析。你可以将数据保存到CSV文件、数据库或者直接用于建模。
示例代码:
import pandas as pd
df = pd.DataFrame(preprocessed_titles, columns=['Title'])
df.to_csv('titles.csv', index=False)
以上步骤提供了从数据获取到预处理的基本流程。根据具体的需求,你可能需要调整这些步骤。如果你有更具体的问题或者需要进一步的帮助,请告诉我!
让我们继续扩展上面提到的代码示例,这次我们将添加更多的细节,包括异常处理、日志记录以及更完整的文本预处理步骤。以下是完整的代码实现:
首先,我们需要安装必要的库,如nltk。可以通过以下命令安装:
pip install nltk
pip install beautifulsoup4
pip install requests
pip install pandas
接下来是具体的代码实现:
import requests
from bs4 import BeautifulSoup
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import PorterStemmer
import pandas as pd
import logging
# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# 下载NLTK资源
nltk.download('stopwords')
nltk.download('punkt')
# 设置URL
url = "https://example.com"
# 发送HTTP请求并解析HTML
def fetch_html(url):
try:
response = requests.get(url)
response.raise_for_status() # 检查响应状态
return response.text
except requests.RequestException as e:
logging.error(f"Error fetching URL: {e}")
return None
# 解析HTML并提取数据
def parse_html(html):
soup = BeautifulSoup(html, 'html.parser')
# 假设我们想要提取所有的文章标题
titles = [title.get_text() for title in soup.find_all('h1')]
return titles
# 清洗数据
def clean_data(titles):
cleaned_titles = [title.strip() for title in titles] # 移除首尾空白
unique_titles = list(set(cleaned_titles)) # 去重
return unique_titles
# 文本预处理
def preprocess_text(titles):
stemmer = PorterStemmer()
stop_words = set(stopwords.words('english'))
preprocessed_titles = []
for title in titles:
tokens = word_tokenize(title)
filtered_tokens = [stemmer.stem(word) for word in tokens if word.isalpha() and word.lower() not in stop_words]
preprocessed_titles.append(' '.join(filtered_tokens))
return preprocessed_titles
# 将数据保存到CSV文件
def save_to_csv(data, filename):
df = pd.DataFrame(data, columns=['Title'])
df.to_csv(filename, index=False)
# 主程序
def main():
html = fetch_html(url)
if html is not None:
titles = parse_html(html)
if titles:
logging.info("Titles extracted successfully.")
unique_titles = clean_data(titles)
preprocessed_titles = preprocess_text(unique_titles)
save_to_csv(preprocessed_titles, 'titles.csv')
logging.info("Data saved to CSV.")
else:
logging.warning("No titles found.")
else:
logging.error("Failed to fetch HTML.")
if __name__ == "__main__":
main()
这段代码包含了以下几个部分:
- 日志配置:使用
logging模块记录程序运行过程中的信息。 - 异常处理:通过
try-except块来捕获和处理可能出现的错误。 - 数据获取:使用
requests库发送HTTP请求并获取HTML内容。 - 数据解析:使用
BeautifulSoup解析HTML并提取数据。 - 数据清洗:去除空白字符和重复项。
- 文本预处理:分词、去除停用词和词干化。
- 数据保存:使用
pandas将处理后的数据保存到CSV文件中。
这个脚本可以作为一个完整的示例,用来抓取网站上的数据并进行基本的清洗和预处理。你可以根据实际需求调整URL、要提取的元素类型以及其他参数。
我们可以进一步优化代码的功能,比如增加更多的异常处理、日志记录以及更详细的文本预处理步骤。此外,我们还可以加入一个简单的用户界面来控制爬虫的行为,比如指定要抓取的页面数量。
下面是基于之前的代码进一步扩展的例子:
import requests
from bs4 import BeautifulSoup
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import PorterStemmer
import pandas as pd
import logging
from urllib.parse import urljoin
# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# 下载NLTK资源
nltk.download('stopwords')
nltk.download('punkt')
# 设置URL
base_url = "https://example.com"
# 发送HTTP请求并解析HTML
def fetch_html(url):
try:
response = requests.get(url)
response.raise_for_status() # 检查响应状态
return response.text
except requests.RequestException as e:
logging.error(f"Error fetching URL: {url} - {e}")
return None
# 解析HTML并提取数据
def parse_html(html, base_url):
soup = BeautifulSoup(html, 'html.parser')
# 假设我们想要提取所有的文章标题
titles = [title.get_text() for title in soup.find_all('h1')]
# 获取所有链接
links = [urljoin(base_url, link.get('href')) for link in soup.find_all('a') if link.get('href')]
return titles, links
# 清洗数据
def clean_data(titles):
cleaned_titles = [title.strip() for title in titles] # 移除首尾空白
unique_titles = list(set(cleaned_titles)) # 去重
return unique_titles
# 文本预处理
def preprocess_text(titles):
stemmer = PorterStemmer()
stop_words = set(stopwords.words('english'))
preprocessed_titles = []
for title in titles:
tokens = word_tokenize(title)
filtered_tokens = [stemmer.stem(word) for word in tokens if word.isalpha() and word.lower() not in stop_words]
preprocessed_titles.append(' '.join(filtered_tokens))
return preprocessed_titles
# 将数据保存到CSV文件
def save_to_csv(data, filename):
df = pd.DataFrame(data, columns=['Title'])
df.to_csv(filename, index=False)
# 主程序
def main(max_pages=1):
visited_links = set()
titles = []
def crawl_page(url):
if url in visited_links:
return
visited_links.add(url)
html = fetch_html(url)
if html is not None:
page_titles, page_links = parse_html(html, base_url)
titles.extend(page_titles)
for link in page_links:
if len(visited_links) < max_pages:
crawl_page(link)
crawl_page(base_url)
if titles:
logging.info("Titles extracted successfully.")
unique_titles = clean_data(titles)
preprocessed_titles = preprocess_text(unique_titles)
save_to_csv(preprocessed_titles, 'titles.csv')
logging.info("Data saved to CSV.")
else:
logging.warning("No titles found.")
if __name__ == "__main__":
# 用户可以指定要爬取的最大页面数
max_pages = 5
main(max_pages)
在这个版本中,我们做了以下改进:
- 递归爬取:现在脚本可以递归地爬取多个页面。
max_pages参数控制最大爬取页面数。 - 链接处理:使用
urljoin函数来正确构建绝对URL。 - 用户输入:允许用户指定要爬取的最大页面数。
这样,脚本不仅可以抓取初始页面的数据,还可以探索其他相关页面,收集更多数据。请注意,在实际应用中,递归爬取可能会遇到网站的robots.txt规则限制或其他访问限制,因此在部署时请确保遵守网站的爬虫政策。
如果您有其他具体需求或想进一步扩展功能,请随时告知!