这篇论文来自CVPR2019,paper地址:Character Region Awareness for Text Detection。
代码:CRAFT-pytorch。
这篇论文主要解决之前的文本检测是基于word-level的检测框,不能识别任意形状的文本的问题。与之前的方法不同,此方法的主要特点是针对文本的检测是字符级的,同时还会学习字符间的affinity(字符间的亲和性,表示字符之间的关系,这种亲和性帮助算法将相邻的字符组合成单词或文本行)。CRAFT 是一种基于字符区域感知的文本检测方法,它不仅关注单个字符的检测,还关注字符之间的关系。这样做的好处在于:使用小感受野也能预测大文本和长文本,只需要关注字符级别的内容而不需要关注整个文本实例。
基于character-level(字符区域)检测有两个难点:
- 如何确定哪些字符是连接在一起组成文字的,而哪些字符是分离的;
- 数据标注问题,因为当前的数据集都是文字级别(word-level)的标注。
paper主要围绕解决这两个问题展开。
1. 确定哪些字符是连接的
字符检测:本文使用的网络使用了目前关键点检测中常用的网络结构,即采用预测热图的方式来进行检测关键点,那么在这里我们就可以把每个字符当做一个关键点,所以每个字符其实对应着一个热点,只要预测每个文字所对应的热点那么就可检测出每个字符。
字符连接的识别:字符的检测方法有了,要怎么知道哪些字符是组成一个文字的呢?作者也使用热图的方式来表示文字的连接,如果两个字符是相连接的,那么这两个字符之间就有一个热点,利用热点图来确定两个字符是不是一组的。
热点就代表着一个响应,如果图片中的某个地方有热点响应,那么表示这个地方存在我们需要的信息,热点的值的大小就代表着置信度,如果置信度越高,那么越确定。
2. 数据集构造
CRAFT之前,现有的文本数据库,其标注方式基本是基于文本行的(word-level),所以文中提出了利用合成数据加从真实数据中得到chatacter-level的估计GT的弱监督方法。
我们看一下网络的构造。

特征提取的主干网络采用的VGG-16以及batch normalization,解码器部分采用了U-net的方法,采用自顶向下的特征聚合方式,最终输出两个通道:region score map和affinity score map,分别为单字符中心区域的概率和相邻字符区域中心的概率,得到原图大小1/2的预测图。
我们再来看一下数据集的构造。首先是合成数据集的处理。
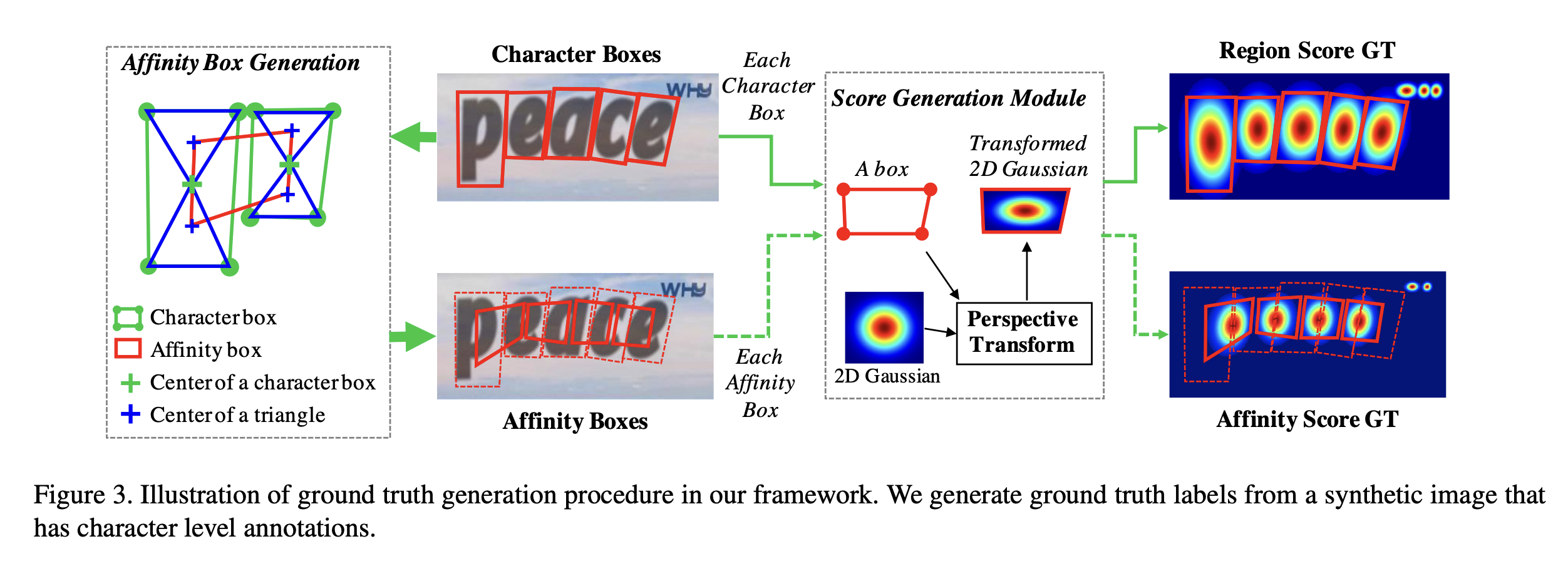
合成的数据集是通过字符的bounding box和affinity的box来表示的。但是CRAFT是使用热度图来表示信息的。使用热度图来表示信息有如下的好处:对于GT区域不是能够严格框住的场景,使用高斯热度图会更加灵活一些。
从bounding box到高斯热度图的处理过程中,由于我们拍摄的物体,图像的边界框会由于相机的透视投影关系而发生扭曲,因此首先要对其进行矫正。矫正的方法就是如图先使用一个二维各向同性高斯图,然后计算高斯映射区域与各字符框之间的透视变换,最后,利用上一步计算的透视变换,将高斯图变形到字符框所在的区域。这样,即使字符框因为透视效果而扭曲,生成的高斯热度图也能准确地映射到字符的实际区域上。这个变形的高斯图就作为 region score 的真实标注。
上面说的是数据处理中的一部分,合成数据到character-level高斯热度图gt的过程。数据处理的另一部分是使用真实数据集。

上图是整个工程的训练流程。其中包括了真实数据集到character-level的高斯热力度的过程。
真实数据集通常都是word-level的标注,就是bounding box都是标注在一整个单词上面的,没有针对一个单词里面每个字符进行标注。因此作者使用弱监督训练的方法,从word-level的真实数据集生成chatacter-level的标注。
模型首先使用前面介绍的合成数据集进行训练,这时候得到一个model,已经具备初步的character-level的识别能力。然后使用这个interim model去预测从word-level的真实数据集到character-level的字符区域。
但是这时候模型只在合成数据集上训练过,因此其预测真实数据集的能力还不够好,其预测的character-level的字符区域有可能不准确,因此作者加上了一个置信度map去评测网络预测真实数据集的结果的可信度。置信度的计算是用网络预测出来的字符个数除以gt的字符个数。(在大多数数据集中,提供了单词的转录,单词的转录信息中包含了字符的个数)。

上图表达的是从word-level生成character-level字符框的全过程。首先把字符区域从图像中抠出来,然后使用合成数据集训练的模型去预测字符区域的score,然后使用分水岭算法去分割字符区域,然后把字符区域再转换回原图上。
在CRAFT(Character Region Awareness for Text Detection)算法中,使用高斯热度图(Gaussian heatmap)和分水岭算法(Watershed algorithm)来生成字符级别的字符框(character-level bounding boxes),而不是直接从高斯热度图生成字符框,主要有以下几个原因:
-
高斯热度图的连续性:高斯热度图提供了一个连续的概率分布,表示字符中心的概率密度。这种连续性使得热度图在表示精确的字符边界时不够明确,因此需要进一步的处理来确定字符的实际边界。
-
字符区域的分割:分水岭算法是一种有效的图像分割技术,可以将连续的区域分割成独立的部分。在CRAFT中,分水岭算法用于将高斯热度图中的连续文本区域分割成单独的字符区域,从而生成更精确的字符框。
-
处理复杂形状:文本在自然场景中可能出现各种形状和方向,直接从高斯热度图生成字符框可能难以适应这些复杂形状。分水岭算法能够更好地处理这些不规则形状,生成更准确的字符框。
-
弱监督学习:CRAFT中使用弱监督学习方法来生成字符级别的标注。分水岭算法生成的字符框可以作为弱标注信息,用于训练和优化模型,尤其是在真实数据集中缺乏精确的字符级标注时。
-
提高鲁棒性:分水岭算法能够处理文本区域中的噪声和不连续性,提高生成字符框的鲁棒性。这对于提高文本检测算法在复杂场景中的性能至关重要。
-
利用现有标注:在一些数据集中,可能只有单词级别的标注而没有字符级别的标注。通过使用分水岭算法,可以从这些单词级别的标注中生成字符级别的标注,从而扩展数据集的可用性。
-
生成高质量的训练数据:生成高质量的训练数据对于训练深度学习模型至关重要。分水岭算法可以帮助生成更准确和一致的字符框,从而提高模型的训练效果。
总之,CRAFT算法中结合使用高斯热度图和分水岭算法,是为了更好地处理文本检测中的复杂性和不确定性,生成更精确和鲁棒的字符框,从而提高文本检测的性能。这种方法在处理不规则文本和缺乏精确标注的数据集时尤其有效。
通过训练过程的图示,在使用弱监督时,由于需要使用估计的GT,如果估计的GT字符的区域不准确,会导致模型的输出有模糊。所以在训练中,需要对估计的GT进行质量评估。
作者使用下面的置信度分数来作为loss对不同质量的估计GT采取不同的权重。

其中,w是训练集中的一个word-level的sample,R(w)是bounding box的区域,l(w)是单词的长度,lc(w)是估计GT的字符长度。如果真实的字符长度与估计的相同,那么Sconf(w)就是1。
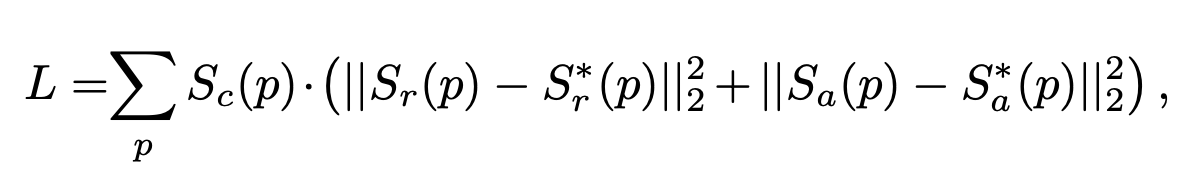
完整的loss计算公式为上面的公式。其中Sc§的计算公式如下,只有在使用word-level的真实数据集训练时,才会让Sc§参与权重计算。当使用合成数据集时,由于可以获得准确的GT,所以Sc§一直为1。

Sr§和Sa§分别代表估计GT的region score和affinity map。Sr§和Sa§是模型预测的region score和affinity score。

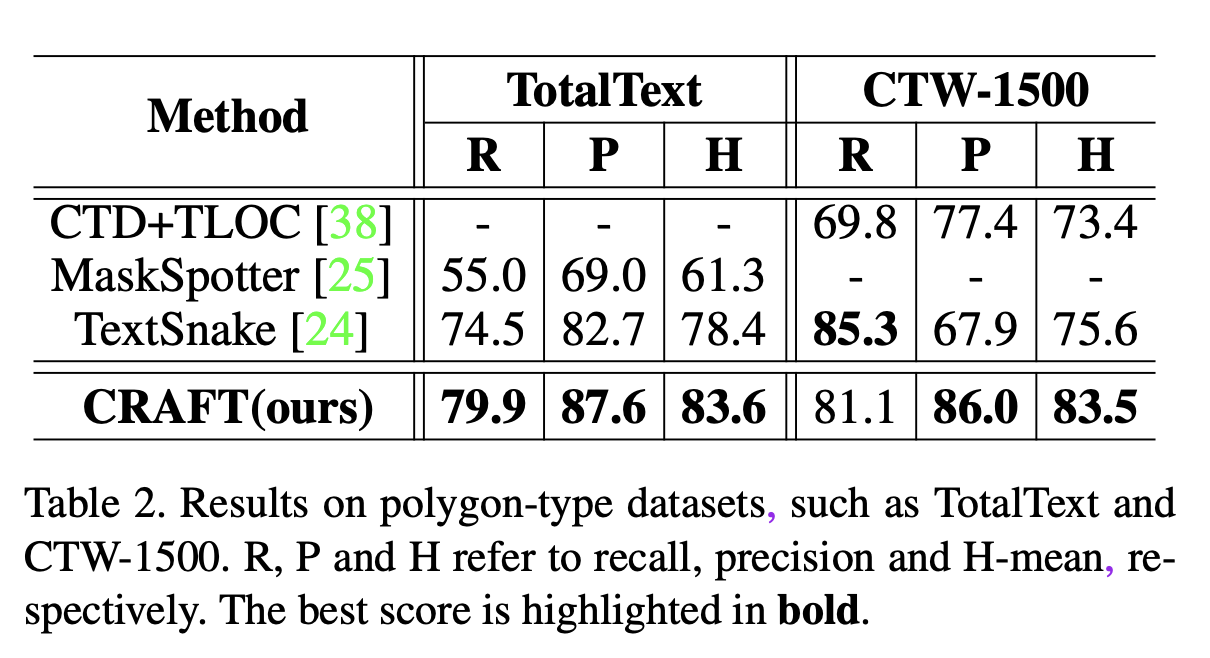
从客观指标上看,CRAFT算法在文本是规则四边形的数据集和不规则的弯曲形状的数据集上测试,都得到了SOTA的结果。

从主观效果上,也是很完美的结果。