项目描述:本项目是基于Raft算法的分布式KV数据库,保证了分布式系统的数据一致性和分区容错性,在少于半数节点发生故障时仍可对外提供服务。使用个人实现的分布式通信框架mpRPC和跳表数据库skipList提供RPC服务和KV存储服务。
github地址:https://github.com/1412771048/Raft
项目背景与简单介绍
项目背景相关
背景
在当今大规模分布式系统的背景下,需要可靠、高可用性的分布式数据存储系统。
传统的集中式数据库在面对大规模数据和高并发访问时可能面临单点故障和性能瓶颈的问题。
为了解决这些问题,本项目致力于构建一种基于Raft一致性算法的分布式键值存储数据库,以确保数据的一致性、可用性和分区容错性。
目的
学习了Raft算法之后手动实现,并基于此搭建了一个k-v存储的分布式数据库。
解决的问题
- 一致性: 通过Raft算法确保数据的强一致性,使得系统在正常和异常情况下都能够提供一致的数据视图。
- 可用性: 通过分布式节点的复制和自动故障转移,实现高可用性,即使在部分节点故障的情况下,系统依然能够提供服务。
- 分区容错: 处理网络分区的情况,确保系统在分区恢复后能够自动合并数据一致性。
技术栈
- Raft一致性算法: 作为核心算法,确保数据的一致性和容错性。
- 存储引擎: 使用适当的存储引擎作为底层存储引擎,提供高效的键值对操作。目前选择的是跳表,但是可以替换为任意k-v数据库。
项目范围
项目的初始版本将实现基本的Raft协议和键值存储功能。
后续版本可能包括性能优化、安全性增强、监控和管理工具的开发等。
前置知识储备
在学习该项目之前,必须知道的内容有:
- 语言基础,比如:
mutex,什么是序列化和反序列化 - RPC相关,至少要知道什么是RPC
最好知道的内容有:
- c11的部分新特性:
auto、RAII等 - 分布式的基础概念:容错、复制等
你的收获
- Raft共识算法的快速理解
- 基于共识算法怎么搭建一个分布式的k-v数据库
需要注意的是,分布式式的共识算法实现本身是一个比较严谨的过程,因为其本身的存在是为了多个服务器之间通过共识算法达成一致性的状态,从而避免单个节点不可用而导致整个集群不可用,因此在学习过程中必须要考虑不同情况下节点宕机、断网情况下的影响。
许多情况需要仔细思考并实验以验证算法正确性,其中的思考别人无法代替,本项目的内容只能作为分布式共识算法Raft的一个入门的实现,方便大家快速理解Raft算法,从而写到简历上,如果想全部理解分布式算法的精髓只能多思考多看多总结。
基于此,本项目中的一些实现或者结论可能有一些不严谨甚至错误的地方,欢迎指正。
mit6.824课程,如果你已经学习过该课程,那么已经不需要本项目了,本项目的难度和内容小于该课程。
下面推荐一些相关的学习资料,甚至本项目部分内容都是源于下面内容:
- 卡哥的跳表
- mit6.824课程的汉化book
- raft算法的可视化
- 分布式系统之CAP理论
- 分布式简单入门知识集合
- Raft的介绍
- 大佬的知乎
- mit6.824的讲义
- raft论文
最佳食用指南
关注Raft算法本身:首先整个项目最重点也是最难点的地方就是Raft算法本身的理解与实现,其他的部分都是辅助,因此在学习的过程中也最好关注Raft算法本身的实现与Raft类对外暴露的一些接口。
多思考错误情况下的算法正确性:Raft算法本身并不难理解,代码也并不多,但是简单的代码如何保证在复杂情况下的容错呢?需要在完成代码后多思考在代码不同运行阶段如果发生宕机等错误时的正确性。
项目大纲
项目的大概框图如下:
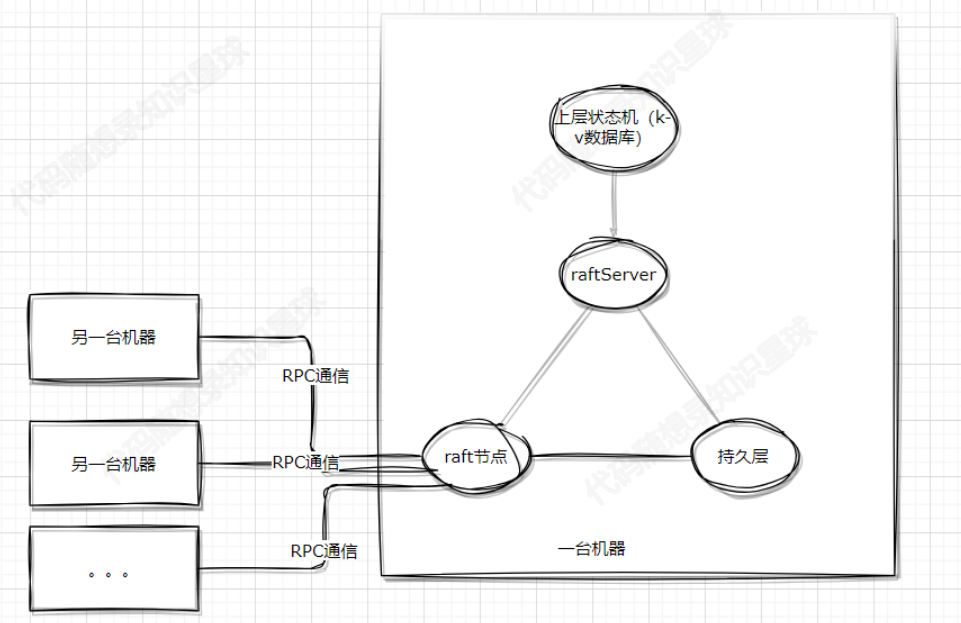
项目大概可以分为以下几个部分:
- raft节点:raft算法实现的核心层,负责与其他机器的raft节点沟通,达到 分布式共识 的目的。
- raftServer:负责raft节点与k-v数据库中间的协调服务;负责持久化k-v数据库的数据(可选)。
- 上层状态机(k-v数据库):负责数据存储。
- 持久层:负责相关数据的落盘,对于raft节点,根据共识算法要求,必须对一些关键数据进行落盘处理,以保证节点宕机后重启程序可以恢复关键数据;对于raftServer,可能会有一些k-v数据库的东西需要落盘持久化。
- RPC通信:在 领导者选举、日志复制、数据查询、心跳等多个Raft重要过程中提供多节点快速简单的通信能力。
目前规划中没有实现节点变更功能或对数据库的切片等更进阶的功能,后面考虑学习加入。
在多个机器启动后,各个机器之间通过网络通信,构建成一个集群,对这样的集群,其对外表现的就像一台单机的k-v数据库一样,且少数节点出现故障不会影响整个集群的工作。
因此有了Raft算法的集群k-v数据库相对于单机的k-v数据库:
优势:集群有了容错的能力,可以理解成Raft算法可以保证各个机器上的k-v数据库(也称状态机)以相同的顺序执行外部命令。
劣势:容错能力需要算法提供,因此程序会变得复杂;需要额外对数据进行备份;需要额外的网络通信开销。
也是因此,其实上层的k-v数据库可以替换成其他的组件,毕竟只是一个状态机而已。
目前设计的后续主要内容:
1.Raft算法的一些概念性内容,比如:Raft算法是什么?Raft算法怎么完成公式?完成Raft算法需要哪几个主要函数?需要哪几个主要的变量维护?
2.Raft算法的主要函数实现思路及代码,主要函数包括:AppendEntries 、 sendRequestVote 、 sendAppendEntries 、 RequestVote 等
3.其他部分组件,包括:RPC通信组件、k-v数据库、中间沟通数据库和raft节点的raftServer
项目难点
难点就是项目主要的几个功能模块的实现。
- Raft算法的理解与实现
- RPC通信框架的理解与实现
- k-v数据库
简历写法
在简历中应该突出完成功能的主要模块和对其优化的思考,由于时间原因,我在完成这个项目之后没有太多的时间去优化,因此我采用的写法是将主要模块写出来的作用。
在文章书写的过程中,后续我可能会加入一些项目的优化。
综上,下面给出简历写法,需要注意的是该写法并不是最优解,仅供参考,后续需要大家自行修改使用。
基于Raf共识算法的分布式KV存储数据库
项目描述
本项目是基于Raft共识算法的分布式K-V数据库,具备线性一致性和分区容错性,在少于半数节点发生故障仍可正常对外提供服务。使用个人实现的RPC通信框架MprRpc和跳表数据库SKipListPro完成RPC功能和K-V存储功能。
主要工作:
- 基于protobuf和自定义协议实现RPC通信框架MprRpc通信框架完成各节点之间的远程调用和数据传递功能:
- 基于跳表数据结构实现跳表数据库SkipListPro完成K-V存储功能;
- 实现Raft协议的心跳与选举机制,通过定时线程池触发心跳与选举任务,并维护集群的日志提交状态,
- 实现日志读写与提交,由领导节点处理客户端的读写请求,并将日志复制至跟随者节点,在超过半数节点复制成功后提交日志,应用命令至状态机并返回响应给客户端:
- 实现客户端协议,包括在客户端协议中加入由ip和请求序号组成的“请求id”以保证线性一致性,以及客户端重试等功能。
个人收获:
- 深入了解了分布式系统的相关知识
- 熟悉了Raft共识算法的原理和实现,并加强了对分布式系统中一致性、容错性等重要概念的理解。
- 学习了RPC和K-V数据相关原理和实现。
本项目常见问题
随着文章的进行,后续可能会补充这部分
Raft
包括但不限于下面内容:
1、 Raft算法的基本原理:
- 解释Raft算法的基本工作原理,包括领导者选举、日志复制和安全性保障。
2、 领导者选举:
- 如何进行Raft中的领导者选举?
- 在什么情况下会触发领导者选举?
3、 日志复制:
- Raft是如何通过日志复制来保证数据一致性的?
- 详细描述Raft中的日志复制过程。
4、 安全性保障:
- Raft是如何确保安全性的?讨论一致性、可用性和分区容错性之间的权衡。
5、 选举超时:
- 什么是选举超时?它的作用是什么?
- 选举超时的时间是如何设置的?
6、 日志条目的提交:
- Raft中的日志条目是如何提交的?
- 什么条件下才能够提交一个日志条目?
7、 拓扑变更:
- Raft如何处理集群拓扑的变更?
- 在节点动态加入或退出时,会发生什么?
8、 实际应用:
- Raft算法在实际场景中的应用有哪些?
- 是否了解一些使用Raft的实际系统案例?
9、 Raft与Paxos的比较:
- 与Paxos算法相比,Raft有哪些优势和不同之处?
10、 常见问题与挑战:
- Raft算法在分布式系统中有哪些常见的问题和挑战?
- 如何处理网络分区的情况?
11、 容错性:
- Raft算法如何处理节点故障?
- 在集群中的多个节点同时故障时,系统会有什么表现?
RPC
- 你的RPC如何设计的?
- 负载均衡有没有做?用的什么算法如何考虑的?
- 服务治理和发现有没有做?怎么做的?
- 你这个RPC框架的序列化和反序列化中protobuf细节有没有了解
测试
- 在集群数量变多的时候,Raft性能可能会下降,这方面有没有思考过?
- 有没有对性能进行过测试?用的什么工具?怎么测试的?
下一篇
接下来下一篇带大家来进入 raft的世界。