这是我的第335篇原创文章。
一、引言
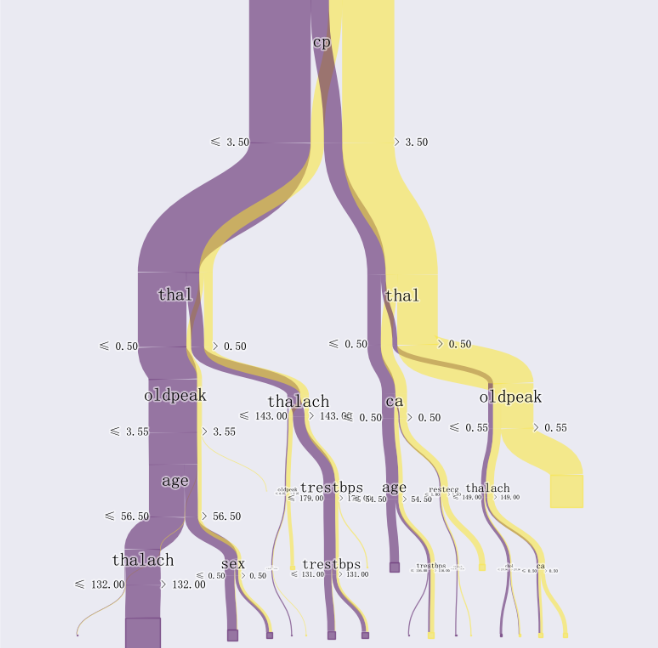
决策树是一个有监督分类模型,本质是选择一个最大信息增益的特征值进行输的分割,直到达到结束条件或叶子节点纯度达到阈值。根据分割指标和分割方法,可分为:ID3、C4.5、CART算法。每一种颜色代表一个class,link的宽度表示从一个节点流向另一个节点的items数量。
需要安装第三方库:
pip install pybaobabdt
pip install pygraphviz二、实现过程
2.1 准备数据
data = pd.read_csv(r'Dataset.csv')
df = pd.DataFrame(data)
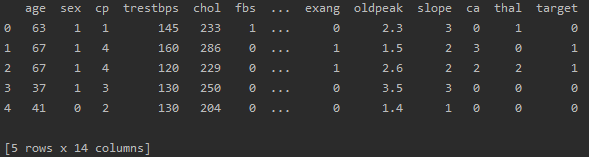
print(df.head())df:
2.2 提取特征变量和目标变量
target = 'target'
features = df.columns.drop(target)
print(data["target"].value_counts()) # 顺便查看一下样本是否平衡2.3 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(df[features], df[target], test_size=0.2, random_state=0)2.4 模型构建和训练
model = DecisionTreeClassifier(max_depth=5)
model.fit(X_train, y_train)2.5 决策树模型可视化
ax = pybaobabdt.drawTree(model, size=10, dpi=300, features=features) #可视化主函数pybaobabdt.drawTree
plt.show()结果:
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。











![[STM32][Bootloader][教程]STM32 HAL库 Bootloader开发和测试教程](https://img-blog.csdnimg.cn/img_convert/6b3c811b36f2cb2e674f5eb09b54f306.png)