官网地址在这里——源码部署 (yuque.com),英文地址——Source Code Deployment | DB-GPT (dbgpt.site)
官网给了三种部署方式:源码部署、Docker部署、Docker-Compose部署,这里我选择的部署方式是源码部署,Docker部署的教程我感觉比较简陋,还是使用源码部署更为稳妥些。不过经过自己的尝试发现,DB-GPT官网给的部署教程属实不太友好,关于配置文件env里各条配置规则的介绍实在太少了,自己连接教程之外的其他llm的时候经常报错。
部署前提
在部署DB-BPT之前,最好确认已经在本地或者服务器上部署好了大语言模型以及对应的embedding模型!!
DB-GPT官网的教程里虽然给了一些embedding模型的安装方法,但是很可能与你部署的大语言模型对应不上导致启动失败!这里我使用的模型是’Qwen2-72b’,使用的系统是Ubuntu,模型是在xinference上部署的,在之后的配置信息中只要配置好url就可以访问了。
(1)下载源代码
git clone https://github.com/eosphoros-ai/DB-GPT.git
使用conda创建新的虚拟环境
conda create -n dbgpt_env python=3.10
conda activate dbgpt_env
这里注意,如果你使用的是非root用户,很可能没有对当前文件夹的读写权限,请先开启一下权限:
# 比如 sudo chmod -R u+rw /usr/local
sudo chmod -R u+rw '你的文件夹路径'
激活环境之后需要进入到 ‘DB-GPT’ 这个子文件夹(之后的命令基本都是在’DB-GPT’目录下执行),然后再执行下面的命令:
pip install -e ".[default]"
这句命令下载的python包会比较多,会消耗较长的时间,需要耐心等待。==如果刚才没有给当前系统用户开放读写权限,这一步安装的时候可能会失败。==包安装好之后,运行下面的命令复制一份配置文件,之后我们修改配置就是在这个 .env 文件里修改
cp .env.template .env
(2)开始部署模型
首先确保安装了 git-lfs 服务,下面是不同系统对应的安装命令,直接运行命令就好:
● CentOS installation: yum install git-lfs
● Ubuntu installation: apt-get install git-lfs
● MacOS installation: brew install git-lfs
由于我使用的是Qwen大模型,而且模型已经在xinference上部署好了,这里只需要安装额外的依赖项:
pip install -e ".[openai]"
pip install dashscope
然后需要注意的是,官网给出的 Qwen模型 的配置信息是这样的:
# .env
# Aliyun tongyiqianwen
LLM_MODEL=tongyi_proxyllm
TONGYI_PROXY_API_KEY={your-tongyi-sk}
PROXY_SERVER_URL={your_service_url}
但是经过我的尝试,配置信息如果这么写是无法成功调用大模型的,调用llm时会爆出api-key非法的错误。
幸亏有前辈之前在Github反映过这样的问题:[Bug] [Module Name] qwen模型使用本地部署,DB-GPT项目独立部署在另外一台机器上面,在使用数据库对话时出现错误。 · Issue #930 · eosphoros-ai/DB-GPT (github.com)
经过尝试,正确的配置信息应该是这样的(在 .env 文件里修改):
LANGUAGE=zh
# LLM_MODEL必须是固定的'proxyllm',不能修改!!
LLM_MODEL=proxyllm
PROXY_API_KEY= 你的api-key
PROXY_SERVER_URL=http://10.xx.xxx.xx:xxxx/v1/chat/completions
PROXYLLM_BACKEND= llm的名字
# EMBEDDING_MODEL也必须是固定的'proxy_http_openapi',不能修改!!
EMBEDDING_MODEL=proxy_http_openapi
proxy_http_openapi_proxy_server_url=http://10.xx.xxx.xx:xxxx/v1/embeddings
proxy_http_openapi_proxy_api_key=你的api-key
proxy_http_openapi_proxy_backend=embedding模型的名字
这里配置EMBEDDING_MODEL的配置信息时最好把原来的配置注释掉,因为DB-GPT官网说配置文件里不支持覆写。
这里我安装的DB-GPT 的版本是 0.5.10,目前为止需要安装的组件已经全部安装好了,可以使用如下命令运行(二者选其一):
python dbgpt/app/dbgpt_server.py
# 或
dbgpt start webserver
(3)启动时报错
1. ImportError: libcupti.so.12: cannot open shared object file: No such file or directory
这个错误的意思是,DB-GPT运行时找不到 “ libcupti.so.12” 这个库,这个问题发生的原因大概率事Anaconda自己的问题,每次创建的新conda环境并不会完全同步cuda相关的依赖。当然也有可能是你没有安装好cuda toolkit。
# 检查一下cuda版本
nvcc --version

如果是像图中一样,是成功安装了的,那么使用如下命令:
sudo find / -name "libcupti.so.12"
这个命令会运行较长的时间,作用是全局找 “libcupti.so.12” 文件,最后查找的结果可能有多个,选择一个文件复制到dbgpt_env环境下即可。
比如,命令的查找结果为:
/usr/local/cuda-12.1/extras/CUPTI/lib64/libcupti.so.12
/home/myuser/anaconda3/envs/DiffFashion/lib/python3.9/site-packages/nvidia/cuda_cupti/lib/libcupti.so.12
/home/myuser/anaconda3/envs/toolbench/lib/python3.10/site-packages/nvidia/cuda_cupti/lib/libcupti.so.12
/home/myuser/anaconda3/envs/CAST/lib/python3.9/site-packages/nvidia/cuda_cupti/lib/libcupti.so.12
/home/myuser/anaconda3/envs/vllm/lib/python3.9/site-packages/nvidia/cuda_cupti/lib/libcupti.so.12
/home/myuser/anaconda3/envs/yolov8/lib/libcupti.so.12
/home/myuser/anaconda3/envs/ladi-vton/lib/python3.10/site-packages/nvidia/cuda_cupti/lib/libcupti.so.12
/home/myuser/anaconda3/envs/chatchat2/lib/python3.8/site-packages/nvidia/cuda_cupti/lib/libcupti.so.12
/home/myuser/anaconda3/envs/qwen2/lib/python3.11/site-packages/nvidia/cuda_cupti/lib/libcupti.so.12
/home/myuser/anaconda3/lib/python3.11/site-packages/nvidia/cuda_cupti/lib/libcupti.so.12
/home/myuser/anaconda3/pkgs/cuda-cupti-12.1.105-0/lib/libcupti.so.12
/home/myuser/.local/lib/python3.10/site-packages/nvidia/cuda_cupti/lib/libcupti.so.12
因为上文中创建的虚拟环境名为dbgpt_env,所以dbgpt_env的路径其实就是 /home/myuser/anaconda3/envs/dbgpt_env/lib/python3.10/site-packages/nvidia/cuda_cupti/
由于我们创建dbgpt_env时使用的环境是python3.10,这里也挑选相同版本的conda环境,比如 /home/myuser/anaconda3/envs/ladi-vton/lib/python3.10/site-packages/nvidia/cuda_cupti/lib/libcupti.so.12
那么其实只用复制文件或者创建一个软链接就行:
# 复制方式
cp /home/zstu/anaconda3/envs/ladi-vton/lib/python3.10/site-packages/nvidia/cuda_cupti/lib/libcupti.so.12 /home/zstu/anaconda3/envs/dbgpt_env/lib/python3.10/site-packages/nvidia/cuda_cupti/lib/libcupti.so.12
# 软链接方式需要先创建路径
mkdir -p /home/zstu/anaconda3/envs/dbgpt_env/lib/python3.10/site-packages/nvidia/cuda_cupti/lib/
ln -s /home/zstu/anaconda3/envs/ladi-vton/lib/python3.10/site-packages/nvidia/cuda_cupti/lib/libcupti.so.12 /home/zstu/anaconda3/envs/dbgpt_env/lib/python3.10/site-packages/nvidia/cuda_cupti/lib/libcupti.so.12
2. No module named ‘botocore’
这个问题比较简单,就是缺乏了botocore这个包
pip install botocore
3.RuntimeError: Failed to import transformers.trainer because of the following error (look up to see its traceback): /home/myuser/.local/lib/python3.10/site-packages/flash_attn_2_cuda.cpython-310-x86_64-linux-gnu.so: undefined symbol: _ZN3c104cuda14ExchangeDeviceEa
这个问题我也没明白是怎么出现的,问了GPT之后是使用如下方法解决的:
pip uninstall flash-attn
pip install flash-attn
(4)开始使用
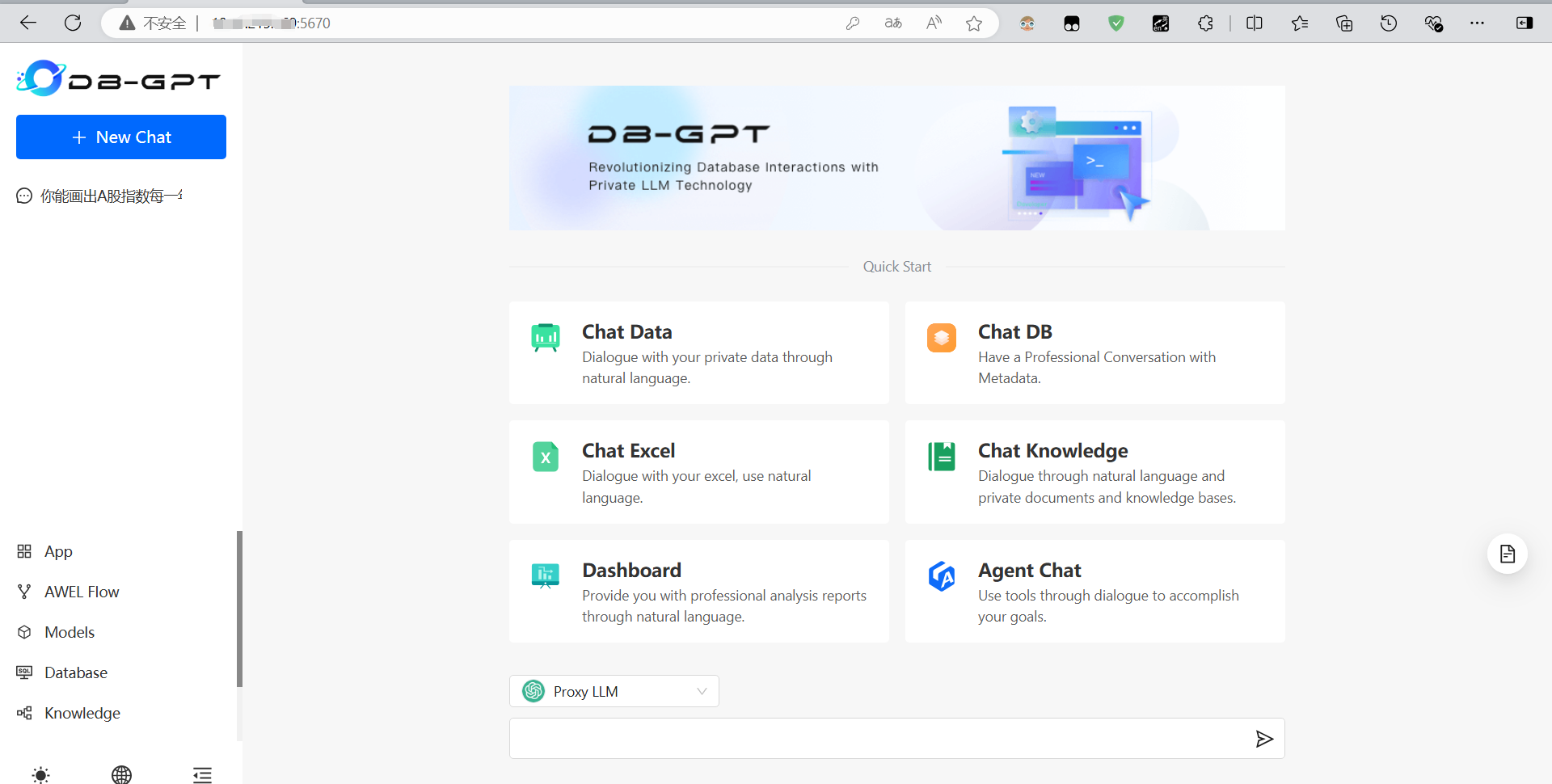
如果访问端口号 5670 可以看到如下页面就代表你安装成功了:
现在我们可以提问了,如果你提问的时候爆出如下错误:
InvalidApiKey:Invalid API-key provided. (error_code: -1)
这个首先检查你的api-key是不是写错了。如果确认是没有写错,那么应该就是配置文件 .env 里没有配置好,比如使用Qwen模型时 LLM_MODEL写成了tongyi_proxyllm。(这个LLM_MODEL配置确实是很迷,我最开始以为它是指的模型的名字,结果最后发现只能写固定名词)
chat_data的使用
这里我展示一下chat data和chat excel的用法,如果要使用chat data是必须要有数据库的,db-gpt会根据你的问题调用text2ToSQL,生成SQL语句之后自动查询,将查询结果返回到前端。首先需要配置数据库,这里我使用的是Clickhouse:
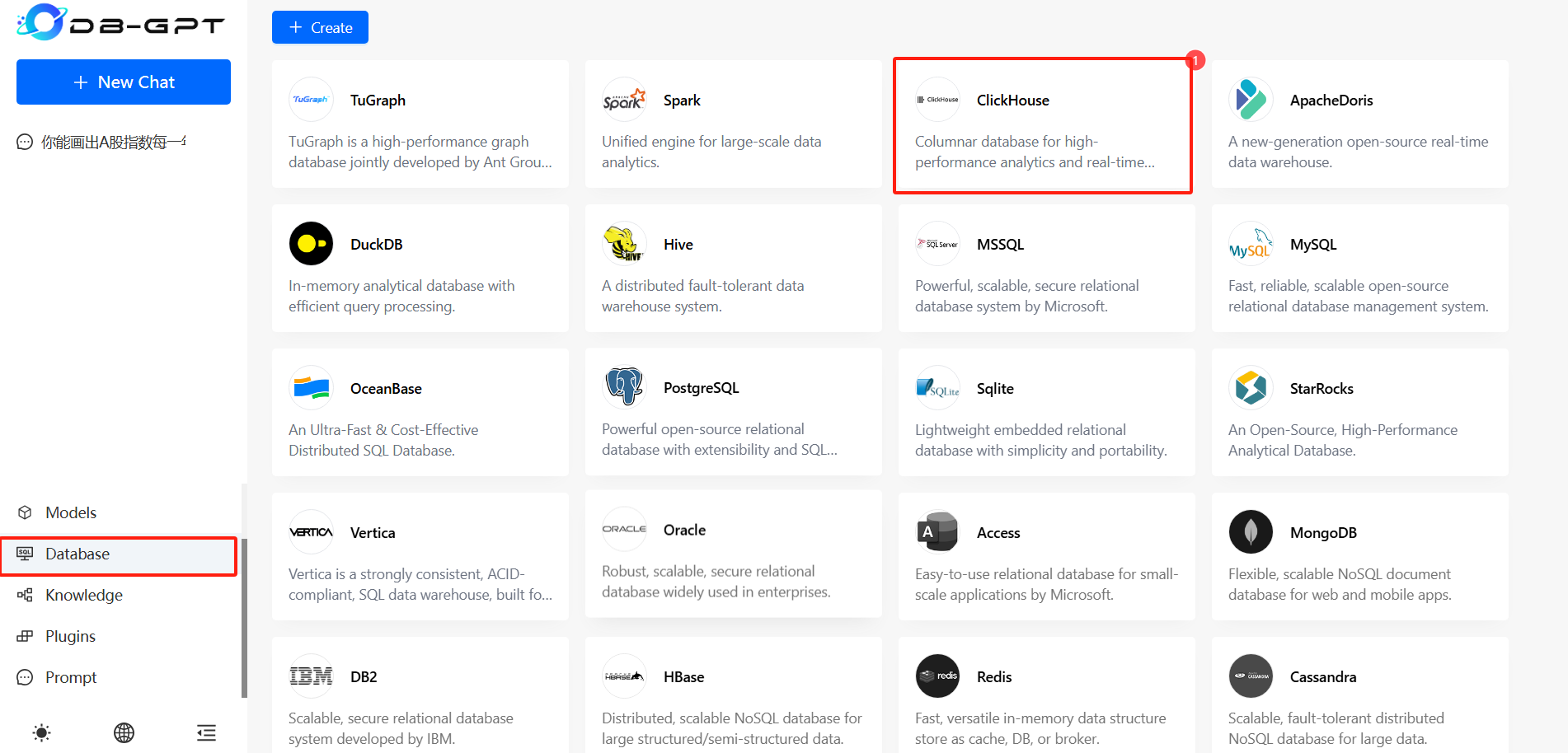
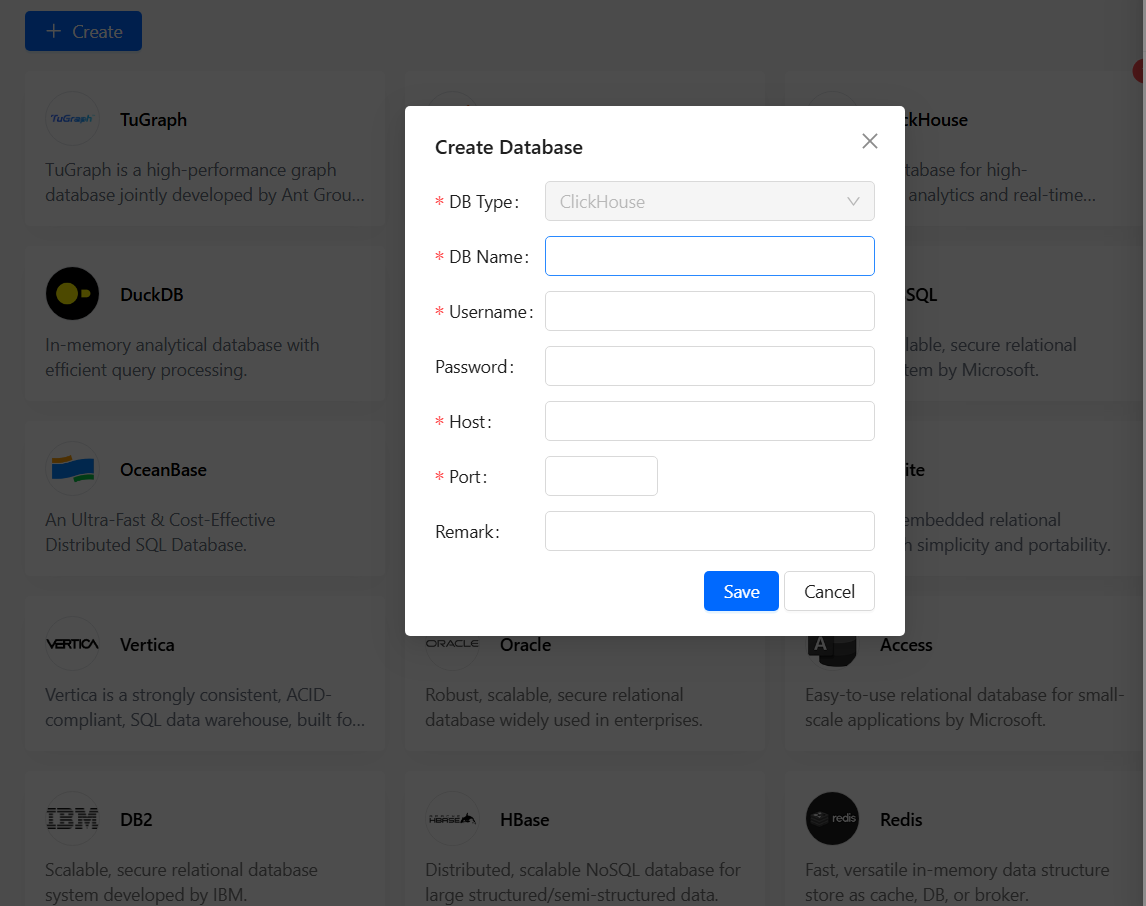
填写好相应的host和port之后保存应该会出现一个 找不到 clickhouse-connect的错误,这里要安装上:
pip install clickhouse-connect
然后回到首页,选择chat_data功能,选择刚才连接的数据库,就可以开始提问了:
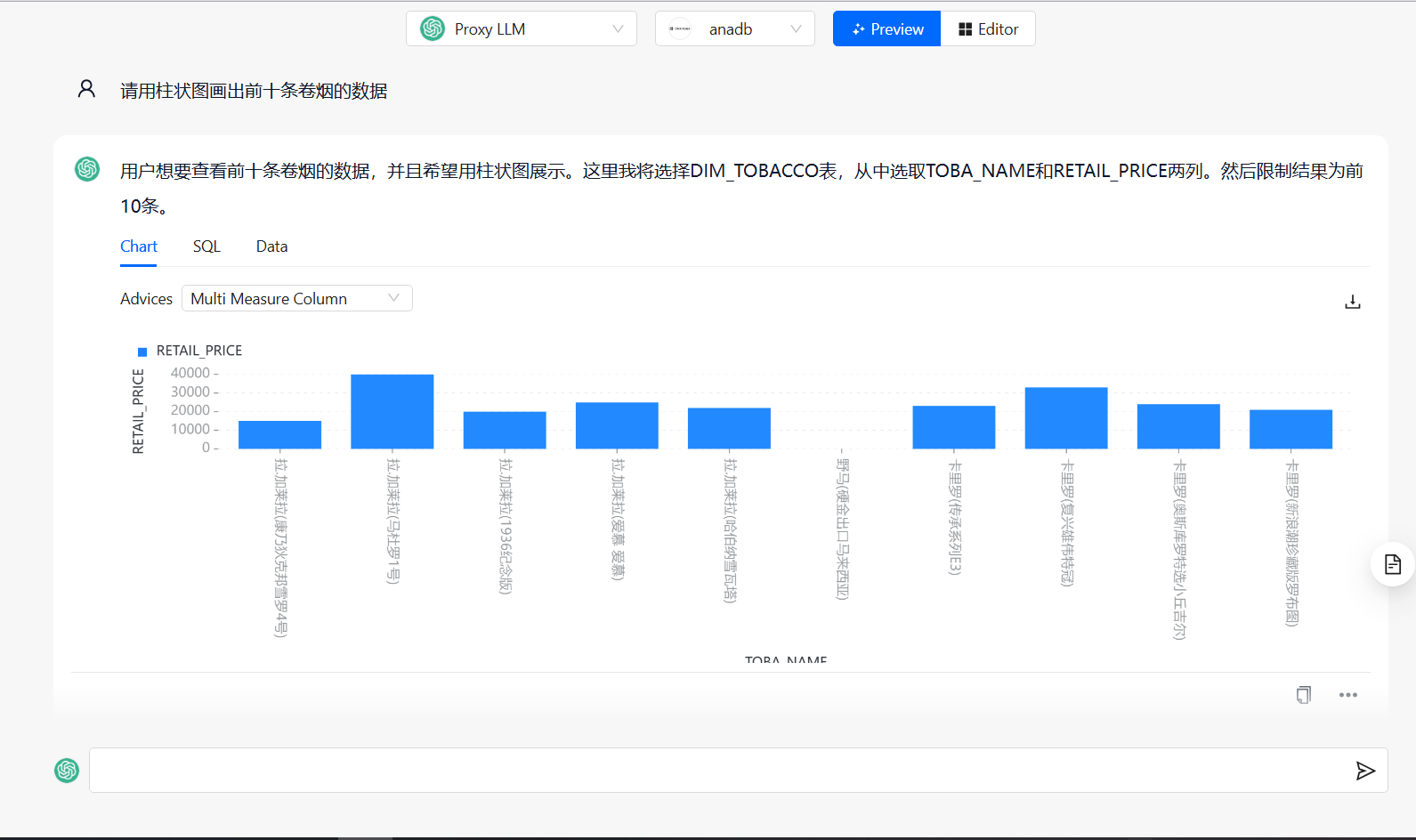
chat_excel
这个功能比较简单,上传一份excel文件,让 db-gpt 解析数据:
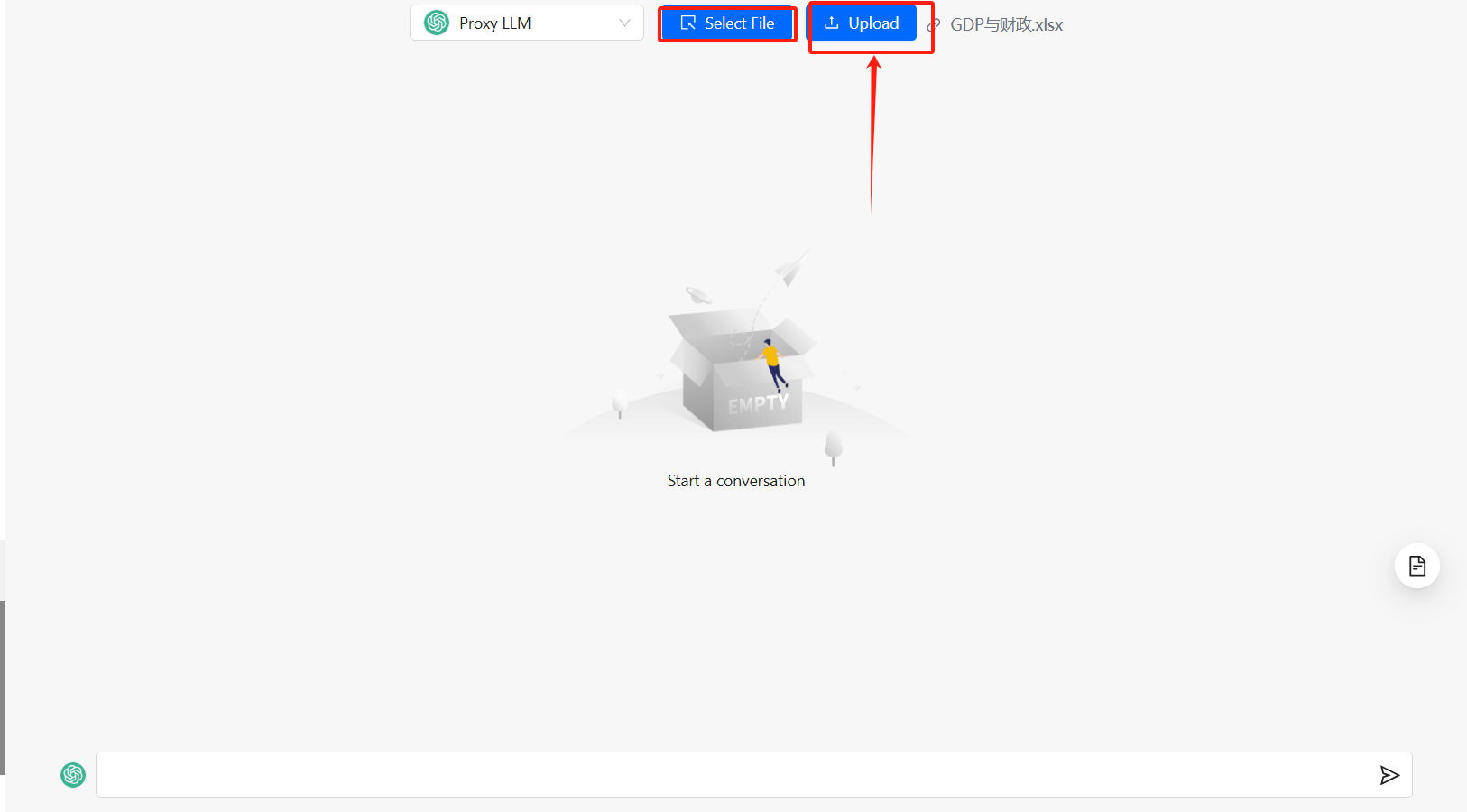
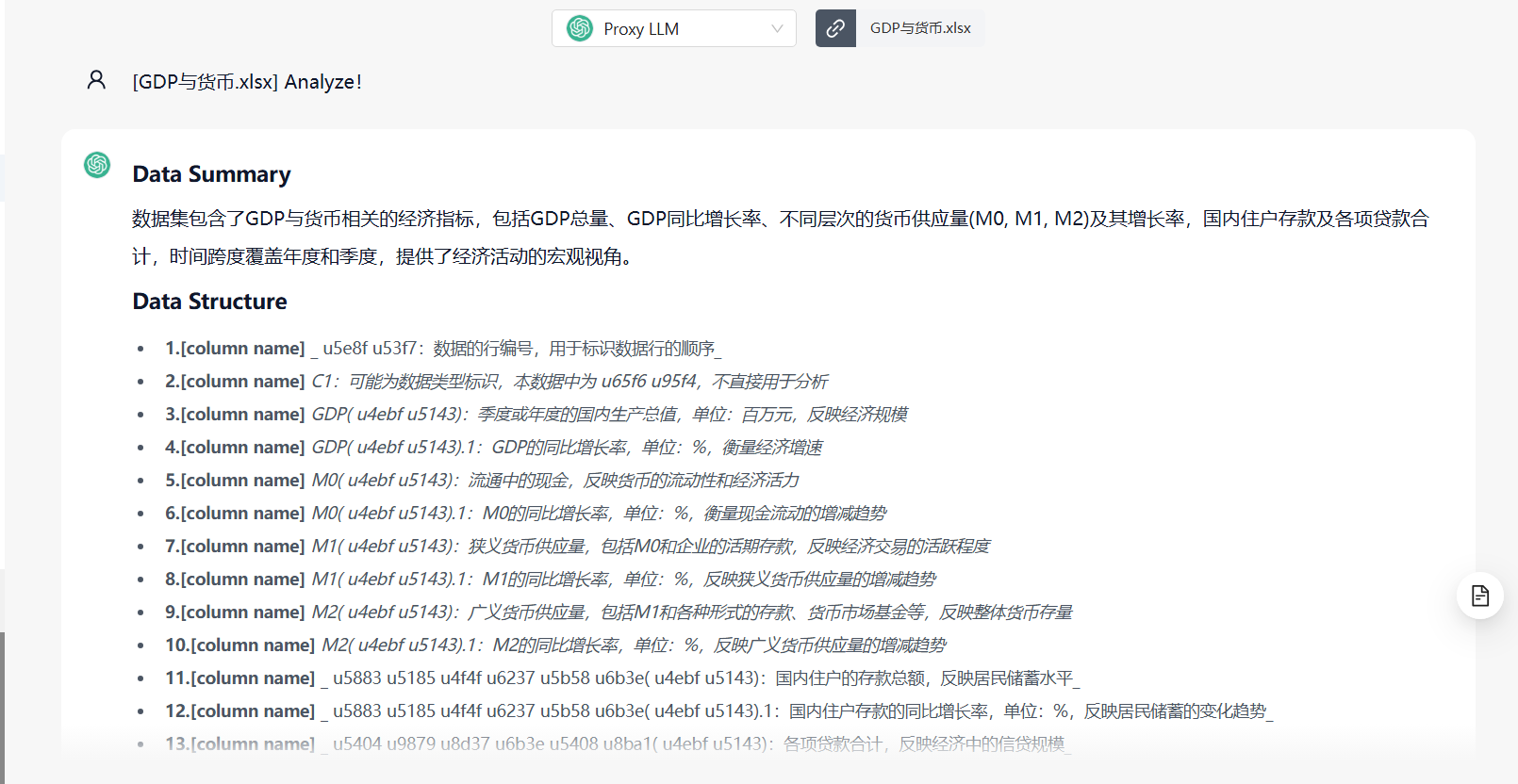
这里选择好文件之后,一定要记得点一下这个 上传按钮,否则文件是没有上传到db-gpt后台解析的,你提问的时候就会发生报错。









![[Bugku] web-CTF-GET](https://i-blog.csdnimg.cn/direct/90661c0c5511403a810886eb4c2488fb.png)