clickhouse sql 语法参考
- 1. select
- 1.1 将结果中的某些列与 re2 正则表达式匹配,可以使用 COLUMNS 表
- 1.2 ARRAY JOIN - 数组数据平铺
- 1.3 LEFT ARRAY JOIN
- 2. create
- 2.1 分布式创建数据库
- 2.2 分布式创建复制表
- 2.4 CREATE TABLE [IF NOT EXISTS] [db.]table_name ENGINE = engine AS SELECT ...
- 2.3 分布式创建分布表
- 3. delete
- 3.1 DELETE 操作
- 4. update
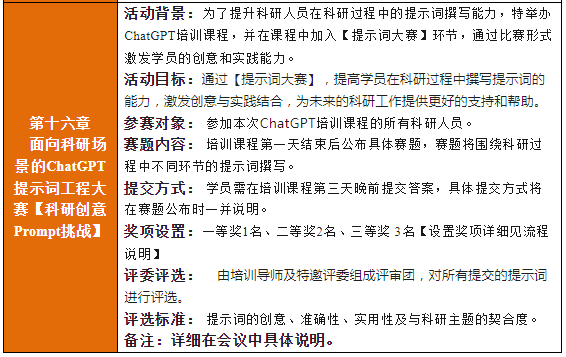
- 常用sql 汇总
- 1. 查询数据库表大小
- 构建日期-分钟维度表sql
1. select
1.1 将结果中的某些列与 re2 正则表达式匹配,可以使用 COLUMNS 表
-
COLUMNS(‘regexp’)
例如表: CREATE TABLE default.col_names (aa Int8, ab Int8, bc Int8) ENGINE = TinyLog 以下查询所有列名包含 a 。 SELECT COLUMNS('a') FROM col_names ┌─aa─┬─ab─┐ │ 1 │ 1 │ └────┴────┘ -
可以使用多个 COLUMNS 表达式并将函数应用于它们。
例如: SELECT COLUMNS('a'), COLUMNS('c'), toTypeName(COLUMNS('c')) FROM col_names ┌─aa─┬─ab─┬─bc─┬─toTypeName(bc)─┐ │ 1 │ 1 │ 1 │ Int8 │ └────┴────┴────┴────────────────┘
1.2 ARRAY JOIN - 数组数据平铺
样例数据:
┌─s───────────┬─arr─────┐
│ Hello │ [1,2] │
│ World │ [3,4,5] │
│ Goodbye │ [] │
└─────────────┴─────────┘
sql :
SELECT s, arr
FROM arrays_test
ARRAY JOIN arr;
结果:
┌─s─────┬─arr─┐
│ Hello │ 1 │
│ Hello │ 2 │
│ World │ 3 │
│ World │ 4 │
│ World │ 5 │
└───────┴─────┘
1.3 LEFT ARRAY JOIN
2. create
# 分布式 ddl - on cluster mycluster [mycluster 是 集群名称]
2.1 分布式创建数据库
create database sztest on cluster mycluster;
2.2 分布式创建复制表
CREATE TABLE log_test ON CLUSTER mycluster
(
`ts` DateTime,
`uid` String,
`biz` String
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/log_test', '{replica}')
PARTITION BY toYYYYMMDD(ts)
ORDER BY ts
SETTINGS index_granularity = 8192;
2.4 CREATE TABLE [IF NOT EXISTS] [db.]table_name ENGINE = engine AS SELECT …
create table file_progress_record_bak ENGINE = MergeTree(par_date,create_time,8192) as select * from daa.file_progress_record;
2.3 分布式创建分布表
create table log_test_all on CLUSTER mycluster as sztest.log_test ENGINE = Distributed(mycluster, sztest, log_test, rand());
备注:Distributed(mycluster, sztest, log_test, rand()),集群名,数据库名,表名,分片键[可选]
3. delete
3.1 DELETE 操作
ALTER TABLE city DELETE WHERE city=‘guangzhou’;
4. update
ALTER TABLE city UPDATE area=‘South’ WHERE city=‘wuhan’;
常用sql 汇总
1. 查询数据库表大小
WITH sum(bytes) as s
SELECT
formatReadableSize(s),
table
FROM system.parts
GROUP BY table
HAVING table LIKE 'http%'
ORDER BY s DESC;
或者
SELECT
formatReadableSize(s),
sum(bytes) as s,
table
FROM system.parts
GROUP BY table
HAVING table LIKE 'http%'
ORDER BY s DESC;
构建日期-分钟维度表sql

CREATE TABLE datawarehouse..dim_time_minutes
(
dt_time DateTime64(3) COMMENT '时间',
dt_date Date COMMENT '日期'
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(dt_date)
ORDER BY dt_time
SETTINGS index_granularity = 8192
truncate table datawarehouse..dim_time_minutes;
insert into datawarehouse..dim_time_minutes
select date_trunc('minute',toDateTime(num)) as dt_time,toDate(num) as dt_date from (
select arrayJoin(
range(
toUInt32(toDateTime ('2028-01-01 00:00:00')),
toUInt32(addMinutes(toDateTime('2028-12-31 23:59:00'), 1))
)
) as num
from numbers(1)
) t
group by date_trunc('minute',toDateTime(num)) as dt_time,toDate(num)
;