导读
大模型是近几年非常火的一个AI名词,很多公司也在训练自己的大模型,但是训练一个大模型需要多少钱呢?本文从多个角度为大家拆解。

Title: Visualizing the size of Large Language Models
Paper: https://medium.com/@georgeanil/visualizing-size-of-large-language-models-ec576caa5557
导读
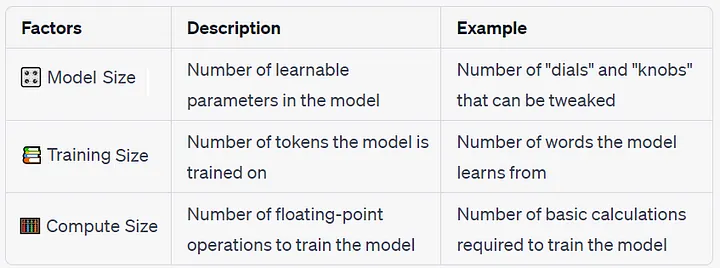
决定语言模型大小的三个重要因素是:
- 模型大小(Model Size)
- 训练规模(Training Size)
- 计算规模(Compute Size)
模型大小可视化
模型大小取决于模型中可学习参数的数量
- 这些参数包括与模型神经网络中各个神经元相关联的权重(和偏置)。
- 在训练之前,这些参数被设置为随机值。随着训练过程的进行,它们会被更新以优化模型在特定任务上的性能。
- 用“旋钮”和“开关”的类比来说,这可以比作调整设备中的各种旋钮来正确调整它。
一旦训练完成,最终的参数值可以被想象成填充到一个“巨型Excel表格“中的单元格。
 模型参数 = 巨型Excel表格中的值.
模型参数 = 巨型Excel表格中的值.
以足球场为单位来表示模型大小
- 如果我们假设每个Excel单元格的大小为(1厘米 x 1厘米)
- 一个足球场大小的Excel表格(100米 x 60米)将包含大约6000万个参数。这大致相当于2017年发布的原始Transformer模型的参数数量
 1个足球场 = 6000万参数
1个足球场 = 6000万参数
- GPT-1,2018年发布,包含大约1.17亿参数。相当于2个足球场大小的Excel表格(2FFs)。
- 最近由谷歌发布的PALM 1和2(参数量为3.4亿到5.4亿)模型,可以想象为一个巨型Excel表格,大小相当于6000到7000个足球场!
按模型大小和发布年份排序
2017年 - 原始Transformer - 6500万参数(或1个足球场)
2018年 - GPT 1 - 1.17亿参数(或2个足球场)
2019年 - GPT 2 - 1.5亿参数(或20个足球场)
2020年 - GPT 3 - 1750亿参数(或2500个足球场)
2021年 - Gopher - 280亿参数(或4000个足球场)
2022年 - PALM - 540亿参数(或7700个足球场)
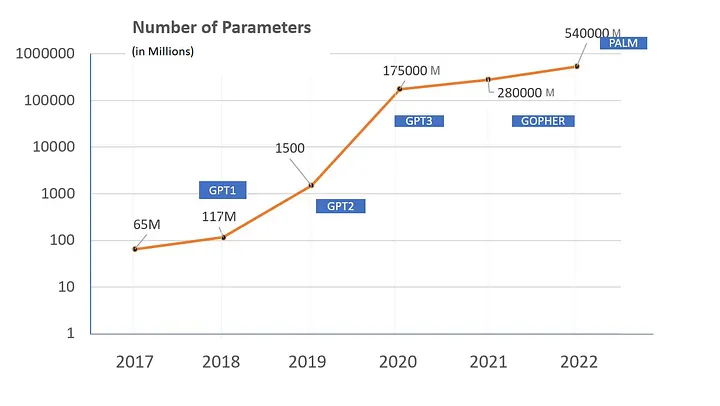 模型参数与发布年份(对数刻度)
模型参数与发布年份(对数刻度)
训练规模可视化
训练规模取决于训练数据集中的Tokens数量。
- Token可以是一个单词、子词或字符——这取决于训练文本是如何被分割成 Token 的(Tokenization)。
- 训练数据集被分成Batches,每个Batch内的tokens一起处理,然后更新模型的参数。
- 整个训练数据集通过模型的一次完整遍历称为一个Epoch。
- 最近的大多数语言模型,Epoch = 1。因此,这样的模型在训练数据集中只会“看到”一次Token 。
以图书馆书架为单位进行可视化
- 如果我们假设一本典型的书,包含大约10万个Token,一个典型的图书馆书架可以容纳大约100本书。那么每个图书馆书架将包含大约1000万Token。
- 原始的Transformer模型用于英德翻译,使用了WMT数据集,包含450万句对(大约1亿Token或10个图书馆书架)。
- GPT-1是在Book Corpus数据集上的7000本书上进行训练的(大约6亿Token或60个图书馆书架)。
- 最近由谷歌发布的PALM模型是在780亿Token上进行训练的,相当于78,000个图书馆书架!
按训练规模和发布年份排序
2017年 - 原始Transformer - 1亿Token(或10个图书馆书架)
2018年 - GPT 1 - 6亿Token(或60个书架)
2019年 - GPT 2 - 280亿Token(或2800个书架)
2020年 - GPT 3 - 3万亿Token(或3万个书架)
2021年 - Gopher - 3万亿Token(或3万个书架)
2022年 - PALM - 780万亿Token(或7.8万个书架)
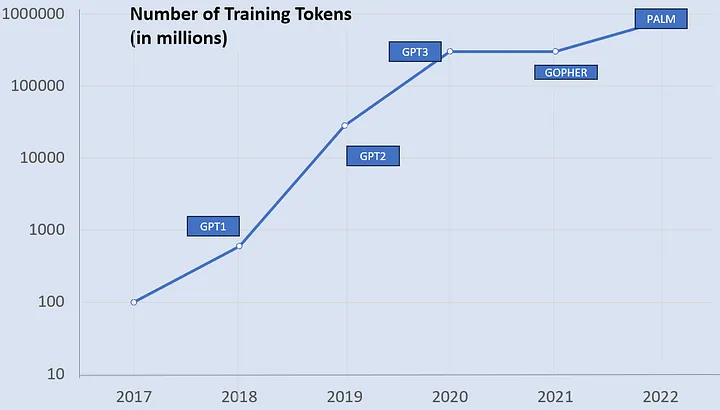 训练规模与发布年份(对数刻度)
训练规模与发布年份(对数刻度)
计算规模可视化
计算规模取决于在模型训练的不同阶段所需的浮点运算(FLOPs)或计算的数量。
在FP32精度下,不同设备典型的FLOPs容量 (1GFLOP = 10亿FLOPs = 1E+9 FLOPs)
💻 现代中型笔记本电脑 ~ 100 GFLOPs
📱 苹果iPhone 14 Pro ~ 2000 GFLOPs
🎮 索尼PlayStation 5 ~ 10000 GFLOPs
🖥️ Nvidia H100 NVL GPU ~ 134,000 GFLOPs
训练过程中的阶段包括:
- 前向传播(Forward Pass)—— 模型接收一系列训练Token作为输入,并进行预测(例如,序列中的下一个词)
- 损失计算(Loss Computation)—— 通过损失函数计算预测值与实际值之间的差异。
- 反向传播和参数更新(Backpropagation and Parameter Update)—— 损失函数的梯度通过反向传播计算(Back propagation),并用于更新模型参数以最小化损失。
- 多轮迭代(Multiple Epochs)—— 前向传播、损失计算、反向传播和参数更新的过程在整个训练数据集中的所有batches上重复进行,跨越多个“运行”或Epochs。
- 在大多数现代大型语言模型(LLMs)中,Epoch等于1,这意味着模型只处理整个训练数据集一次。
整个训练过程所需的近似计算量由以下经验法则给出:
Ct ~ 6.N.D
Ct = 训练所需的计算量
N = 模型参数的数量
D = 训练Token的数量
使用6ND公式进行训练计算:
- 原始的Transformer模型(用于英语到德语任务)在1个Epoch中会消耗3.9 E+16 FLOPs,假设有10个Epoch,总共会消耗3.9 E+17 FLOPs。(相当于在中等配置的笔记本电脑上训练45天,即100GFLOPs)
- GPT-1在1个Epoch中会消耗4.2 E+17 FLOPs,假设有100个Epoch,总共会消耗4.2 E+19 FLOPs。(相当于在中等配置的笔记本电脑上训练13年)
- GPT-2在1个Epoch中会消耗2.5 E+20 FLOPs,假设有20个Epoch,总共会消耗5 E+21 FLOPs。(相当于在中等配置的笔记本电脑上训练1600年)
- 更近期的PALM模型假设Epoch = 1,会消耗2.53 E+24 FLOPs。(相当于在中等配置的笔记本电脑上训练800,000年!)
推理计算:在推理(Inference)时所需的近似计算量由以下经验法则给出:
Ci ~ 2.N.l
Ci = 推理计算量
N = 模型参数的数量
l = 输入/输出长度
 典型笔记本电脑 = 100 GFLOPs = 1.0 E+11 FLOPs
典型笔记本电脑 = 100 GFLOPs = 1.0 E+11 FLOPs
那最火的 GPT-4 呢?
模型大小
- GPT-4采用了一个专家混合 (Mixture of Experts, MoE) 模型,包含16个专家(每个专家有1110亿参数),总共约有 1.8万亿参数 。
- 为了将GPT-4的参数放入一个巨大的Excel表格中,它需要有30,000个足球场那么大,或者180平方公里(比孟买市还要大!)
训练规模
- GPT-4在大约13万亿个tokens(跨越多个时期)上进行了训练。
- 这相当于阅读了130万个图书馆书架上的所有书籍,或者650公里长的图书馆书架!
计算规模
- 估计GPT-4的训练FLOPs约为2.15 E+25 FLOPs。
- 在中等配置的笔记本电脑(100GFLOPs)上训练GPT-4需要7百万年!
估计训练成本约为 6400万美元
- A100 GPU 的峰值 FLOPs = 312 TFLOPS(对于 TF32,稀疏性已启用)
- Azure 对 A100 GPU(ND96asrA100 v4)的按需费用 = 3.40 美元/小时。
- 估计最低训练成本(对于 2.15 E+25 FLOPs)= 6400万美元。
- 这接近 Sam Altman 对 GPT-4 训练成本的估计 = 1亿美元。
估计推理成本约为 0.3 美分,用于 1000 个token
- 假设:提示和响应 = 1024 token长度
- 估计推理 FLOPs = 3 * GPT3 推理 FLOPs = 3 * 350 TFLOPs = 1000 TFLOPs(对于 1024 输入和输出token)
- Azure 对 A100 GPU(ND96asrA100 v4)的按需费用 = 3.40 美元/小时。
- 估计推理成本(对于 1024 输入和输出token)= 0.003 美元,或者每 330 对输入/输出token,将花费 1 美元。
 GPT-4 模型估计
GPT-4 模型估计
AI视觉编推一体机已上市,支持自上传算法模型,并通过逻辑组件的方式,根据业务场景需求,快速优化算法功能。
适用于现场项目需求快速POC,算法功能调优验证。目前已支持多款边缘设备,GPU服务器版本。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。