论文paper地址:An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
本文的主要目的是识别图片中的序列文字的识别。CRNN的主要贡献在于提出了一个网络架构,这种架构具有以下特点:
-
集成特征提取(Feature extraction):网络能够自动从输入图像中提取特征,这些特征捕捉了图像中与文本识别相关的信息。这通常由卷积神经网络(CNN)部分完成,它通过一系列卷积层和池化层来提取图像特征。
-
序列建模(Sequence modeling):CRNN进一步使用循环神经网络(RNN),尤其是长短期记忆网络(LSTM)或双向LSTM(Bi-LSTM),来处理提取的特征。这些网络擅长处理序列数据,能够捕捉时间序列中的动态特征,适用于文本识别中的字符序列。
-
转录(Transcription):在序列建模之后,CRNN使用转录层(例如CTC层)将特征序列转换为最终的文本序列。转录层负责将网络的输出转换为可读的文本形式。
-
统一框架(Unified framework):这些组件—特征提取、序列建模和转录—被整合到一个统一的框架中,这意味着它们可以一起训练和优化,而不是分开独立工作。这种端到端的训练方式提高了效率,并且有助于在整个网络中传播知识,从而提高识别性能。
总的来说,CRNN将图像处理、序列分析和文本生成的不同阶段融合在一起,形成了一个协调一致的系统,用于解决场景文本识别问题。这种架构的优势在于其能够处理任意长度的文本序列,无需词典,且具有较好的泛化能力。
与以往的场景文本识别系统相比,CRNN具有四个特点:
(1)与大多数现有算法的多个组成部分单独训练和调优不同,它是端到端可训练的。
(2)能够处理任意长度的序列,不涉及字符分割或水平尺度归一化。
(3)它不局限于任何预定义的词典,在无词典和基于词典的场景文本 识别任务中都取得了显著的成绩。
(4)CRNN的模型更小,更有利于部署。
在包括IIIT-5K、Street View Ttext和ICDAR数据集在内的标准基准上进行的实验表明,该算法优于现有技术。此外,该算法在基于图像的乐谱识别任务中表现良好,验证了算法的通用性。
下面我们来主要介绍一下CRNN的网络结构。
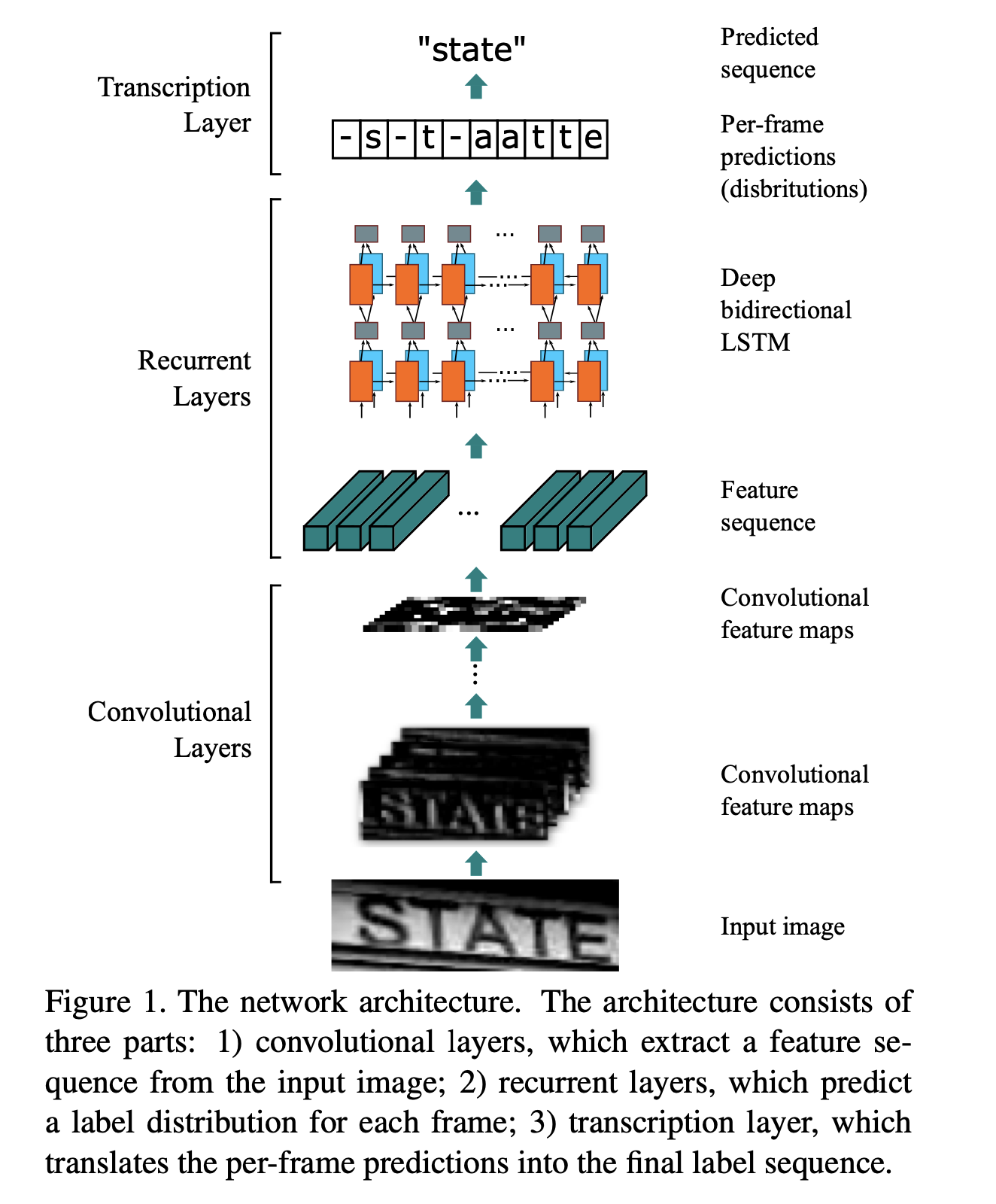
上图是CRNN的网络结构。
CRNN(Convolutional Recurrent Neural Network)的网络架构由三个主要部分组成,每部分负责不同的任务,共同完成图像中文本的识别工作。下面是对这三个部分的详细解释:
-
卷积层(Convolutional Layers):
- 作用:卷积层是网络的第一层,负责从输入的图像中提取特征序列。这些特征序列包含了图像中与文本识别相关的信息,如边缘、角点、纹理等。
- 操作:通常包括一系列卷积操作和池化操作,这些操作能够自动学习到图像的有效特征表示。
-
循环层(Recurrent Layers):
- 作用:循环层建立在卷积层提取的特征序列之上,用于预测每个特征向量(帧)的标签分布。这一层能够处理序列数据,并能够捕捉时间序列中的动态特征,例如文本字符的序列关系。
- 操作:通常使用双向长短期记忆网络(Bi-directional Long Short-Term Memory, Bi-LSTM)作为循环层,它能够同时处理前向和后向的信息,从而更好地理解文本序列的上下文。
-
转录层(Transcription Layer):
- 作用:转录层是网络的最后一层,负责将循环层预测的每帧标签分布转换成最终的标签序列,即识别出的文本字符串。
- 操作:这一层通常使用CTC(Connectionist Temporal Classification)算法,它能够处理不定长的序列输入和输出,并且可以忽略序列中的空白符(blank characters),从而将模型的预测转换为正确的文本序列。
整体来看,CRNN的网络架构是一个端到端的系统,它将图像特征提取、序列建模和文本转录整合在一起,形成了一个统一的框架。这种设计使得CRNN能够有效地处理图像中的文本识别任务,无论是在有词典还是无词典的情况下,都能够实现出色的识别性能。此外,CRNN的设计允许它自然地处理任意长度的文本序列,无需进行字符分割或水平尺度归一化,这使得它在处理场景文本识别问题时具有很大的灵活性和鲁棒性。
我们首先来看卷积层的特征提取模块
特征提取模块使用的是标准的CNN网络,使用了卷积层和max-pooling层,去掉了全连接层。在进入CNN网络之前,输入会被scale到同样的高度,经过CNN网络后,CNN网络的输出的特征图会被切分成序列化的特征图,切分后的序列化的特征图,会作为循环网络的输入。

在卷积层特征提取之后,有一个切分的操作。由于卷积、max-pooling等操作是在图像局部信息上进行处理,它们是平移不变的。所以,在模型结构那张图上,经过卷积计算后的特征层Convolutional feature maps,是可以切分成一条条的特征的,每一条特征对应输入图的一部分,并且是位置对应的,如上图所示。这样切分的好处主要是将输入图转换成序列化的表示,从而可以应对变长的文本识别问题。
再来看循环层

循环层使用的是Deep bi-LSTM网络(上图所示),将多个bi-LSTM堆叠在一起,就是deep bi-LSTM。其作用是预测每一个输入xt,对应的标签的分布yt。xt是CNN提取后的特征序列中的一个。在特征预测层,使用循环网络有三个好处:
(1)RNN具有很强的捕获序列中上下文信息的能力。在基于图像的序列识别中,使用上下文线索比单独处理每个符号更稳定、更有帮助。以场景文本识别为例,宽字符可能需要连续几帧才能完全描述。
(2)一些容易混淆的字符,如果能够处理上下文序列的信息,就很容易识别出来。比如识别"il",如果模型能够处理上下文字符的高度信息,就比单独去识别i和l,识别率更高一些。
(3)RNN可以和CNN联合使用,反向传递误差来更新模型。
最后是转录层
转录层的作用是将RNN预测的每块的结果转换成一个label序列。转录层有两种不同的转录模式:无词典模式(Lexicon-free mode)和基于词典模式(Lexicon-based mode)。
-
转录的定义:
- 转录是将循环神经网络(RNN)对每一帧(frame)所做的预测转换成最终的标签序列(label sequence)的过程。在数学上,转录是根据每一帧的预测找到具有最高概率的标签序列。
-
无词典模式(Lexicon-free mode):
- 在这种模式下,转录过程中不使用任何词典。词典通常是一个预定义的标签序列集合,例如拼写检查字典。无词典模式意味着预测不受任何预定义词汇的限制,网络可以自由地生成任何可能的标签序列。
-
基于词典模式(Lexicon-based mode):
- 在这种模式下,转录过程中使用词典来约束预测。词典可以是一个包含有效单词或字符序列的集合,例如一个拼写检查字典。基于词典的转录意味着在生成最终标签序列时,网络会选择那些在词典中出现并且具有最高概率的标签序列。
-
两种模式的比较:
- 无词典模式提供了更大的灵活性,因为它允许网络识别任何可能的文本序列,而不受预定义词汇的限制。这在处理未知单词或拼写时特别有用。
- 基于词典模式则利用了词典中的先验知识,可以提高识别的准确性,特别是在处理已知词汇或需要拼写校正的应用中。
-
转录的数学基础:
- 转录层通常使用条件概率来定义标签序列的概率。这意味着给定每一帧的预测,转录层会计算所有可能的标签序列的概率,并选择概率最高的序列作为最终输出。
CRNN的转录层是将RNN的逐帧预测转换为最终文本序列的关键步骤,它可以通过无词典模式或基于词典模式来实现。这两种模式提供了不同的权衡,允许CRNN适应不同的应用场景和需求。
在转录层,作者使用Connectionist Temporal Classification (CTC) layer作为条件概率,使用CTC的好处是可以将其作为损失函数统一转录层、RNN和CNN层的反向参数传递,end-to-end的训练整个模型。
(CTC的原理掠过,搞不懂)。
最后来看一下训练过程,数据集的构建形式是X={Ii, Li},Ii是训练的image,Li是GT的标签序列。目标函数是最小化GT的条件概率的负对数似然。
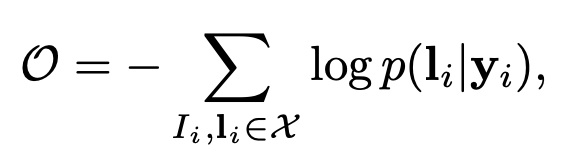
其中,yi是由RNN和CNN生成的序列,输入图像经过网络直接到最后计算这个目标函数的值。因此,整个网络是可以做到端到端训练的。

上图是网络的细节。

从上图的结果中可以看到,在多个数据集上,不管是基于lexicon的场景,还是lexicon free的场景,在多个数据集上都做到了最高的识别率。

对于乐谱,也是可以识别的。

















