在当下的职场环境中,996 工作制一直是一个备受争议的话题。
“996”是一种工作制度的代称,指的是工作日早上 9 点上班,晚上 9 点下班,中午和傍晚休息 1 小时(或不到),总计工作 10
小时以上,并且一周工作 6 天的工作制度。
有人对其深恶痛绝,认为它严重影响了生活质量;而也有人在某些情况下,能够接受这种工作模式。那么,到底在什么情况下,人们会愿意接受 996 呢?
最近在一个平台上,热榜第一就是这个话题,引来了好多人的讨论。在这话题里,有人说项目到了关键时候,得加班加点赶进度,就愿意接受 996,好保证项目能交付。就像后端开发的时候,碰到紧急上线或者重大系统优化,为了系统稳当、性能好,可能就得花更多时间和精力。
还有人觉得要是公司给的回报和发展机会够多,996 也能接受。比如说在一些技术领域,参加有挑战性的项目,能得到宝贵经验,技能也能提升,对职业发展有好处。
那你呢?你啥时候能接受 996 ?是为了职业目标,还是因为别的?
好了,这个话题就讨论到这里,今天接着更新粉丝投稿的最新面经,应粉丝要求,我把问题和答案一个一个整理好了:
内容整理如下(删除了跟项目相关的内容):

遇到过kafka消息积压或者消息丢失的问题吗, 说一下怎么处理?
消息积压
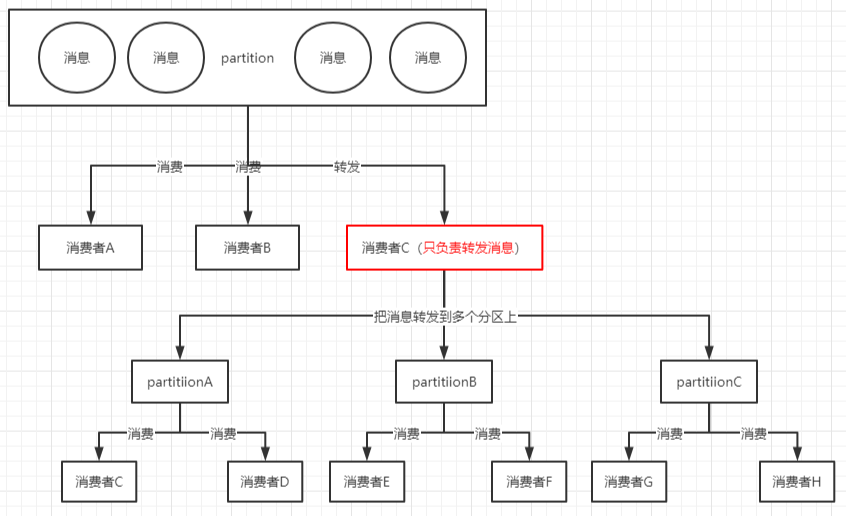
- 线上有时因为发送方发送消息速度过快,或者消费方处理消息过慢,可能会导致broker积压大量未消费消息。
- 解决方案:此种情况如果积压了上百万未消费消息需要紧急处理,可以修改消费端程序,让其将收到的消息快速转发到其他topic(可以设置很多分区),然后再启动多个消费者同时消费新主题的不同分区。如图所示:
- 由于消息数据格式变动或消费者程序有bug,导致消费者一直消费不成功,也可能导致broker积压大量未消费消息。
- 解决方案:此种情况可以将这些消费不成功的消息转发到其它队列里去(类似死信队列),后面再慢慢分析死信队列里的消息处理问题。这个死信队列,kafka并没有提供,需要整合第三方插件!
消息丢失
kafka在生产端发送消息 和 消费端消费消息 时都可能会丢失一些消息
①:生产者消息丢失
- 生产者在发送消息时,会有一个ack机制,当ack=0 或者 ack=1时,都可能会丢消息。如下所示:
- acks=0
表示producer不需要等待任何broker确认收到消息的回复,就可以继续发送下一条消息。性能最高,但是最容易丢消息。大数据统计报表场景,对性能要求很高,对数据丢失不敏感的情况可以用这种。
- acks=1
至少要等待leader已经成功将数据写入本地log,但是不需要等待所有follower是否成功写入。就可以继续发送下一条消息。这种情况下,如果follower没有成功备份数据,而此时leader又挂掉,则消息会丢失。
- acks=-1或all
这意味着leader需要等待所有备份(min.insync.replicas配置的备份个数)都成功写入日志,这种策略会保证只要有一个备份存活就不会丢失数据。这是最强的数据保证。一般除非是金融级别,或跟钱打交道的场景才会使用这种配置。当然如果min.insync.replicas配置的是1则也可能丢消息,跟acks=1情况类似。
②:消费端消息丢失
- 消费端丢消息最主要体现在消费端offset的自动提交,如果开启了自动提交,万一消费到数据还没处理完,此时你consumer直接宕机了,未处理完的数据 丢失了,下次也消费不到了,因为offset已经提交完毕,下次会从offset出开始消费新消息。
解决办法就是采用消费端的手动提交。
切片, map, channel的底层结构?
切片:
type slice struct {
array unsafe.Pointer // 指向底层数组
len int // 长度
cap int // 容量
}
map:
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
channel:
type hchan struct {
qcount uint // total data in the queue
dataqsiz uint // size of the circular queue
buf unsafe.Pointer // points to an array of dataqsiz elements
elemsize uint16
closed uint32
elemtype *_type // element type
sendx uint // send index
recvx uint // receive index
recvq waitq // list of recv waiters
sendq waitq // list of send waiters
// lock protects all fields in hchan, as well as several
// fields in sudogs blocked on this channel.
//
// Do not change another G's status while holding this lock
// (in particular, do not ready a G), as this can deadlock
// with stack shrinking.
lock mutex
}
切片它能作为 map 结构的 key 吗?
答案显然是不能的,因为 slice 是不能使用 “==” 进行比较的,所以是不能做为 map 的 key 的。
而且官方文档中也说明了 https://go.dev/blog/maps
As mentioned earlier, map keys may be of any type that is comparable. The language spec defines this precisely, but in short, comparable types are boolean, numeric, string, pointer, channel, and interface types, and structs or arrays that contain only those types. Notably absent from the list are slices, maps, and functions; these types cannot be compared using ==, and may not be used as map keys.
一段代码片段里面有多个 defer的时候,它的执行顺序是什么样?
在 Go 语言中,如果一个函数中有多个defer语句,它们会按照“后进先出”(Last In First Out,LIFO)的顺序执行。也就是说,最后注册的defer函数会第一个执行,而第一个注册的defer函数会最后执行。
defer,它在什么样的情况下能去修改返回值?在什么样的情况下
defer在return之后执行,但在函数退出之前,defer可以修改返回值。下面是一个例子:
func test() int {
i := 0
defer func() {
fmt.Println("defer1")
}()
defer func() {
i += 1
fmt.Println("defer2")
}()
return i
}
func main() {
fmt.Println("return", test())
}
// defer2
// defer1
// return 0
上面这个例子中,test返回值并没有修改,这是由于Go的返回机制决定的,执行Return语句后,Go会创建一个临时变量保存返回值。如果是有名返回(也就是指明返回值func test() (i int))
func test() (i int) {
i = 0
defer func() {
i += 1
fmt.Println("defer2")
}()
return i
}
func main() {
fmt.Println("return", test())
}
// defer2
// return 1
这个例子中,返回值被修改了。对于有名返回值的函数,执行 return 语句时,并不会再创建临时变量保存,因此,defer 语句修改了 i,即对返回值产生了影响。
map 它是线程安全的吗?
在 Go 语言中,内置的 map 不是线程安全的。
如果在多个线程中同时对一个普通的 map 进行读写操作,可能会导致不可预测的结果,比如数据不一致、程序崩溃等。
例如,如果一个线程正在读取 map 中的数据,而另一个线程正在删除或添加元素,就可能会出现问题。
如果需要在多线程环境中安全地使用 map ,可以使用一些同步机制,比如使用 sync.RWMutex 来实现加锁保护,或者使用第三方的线程安全的 map 实现。
Redis 实现一个实时更新的排行榜
在 Redis 中,可以使用 Sorted Set(有序集合)来实现实时更新的排行榜。
Sorted Set 中的每个元素都关联一个分数(score),元素会按照分数进行排序。
以下是一个基本的实现思路:
- 插入数据
- 当有新的数据需要加入排行榜时,将数据作为元素,相关的数值(比如得分)作为分数,插入到
Sorted Set中。
- 当有新的数据需要加入排行榜时,将数据作为元素,相关的数值(比如得分)作为分数,插入到
- 更新数据
- 如果需要更新某个元素的分数(比如用户的得分发生了变化),可以使用
ZINCRBY命令来增加或减少元素的分数,从而实现实时更新。
- 如果需要更新某个元素的分数(比如用户的得分发生了变化),可以使用
- 获取排行榜
- 使用
ZRANGE命令可以获取排行榜的前若干名。 - 例如,
ZRANGE sorted_set 0 9可以获取排行前 10 名的数据。
- 使用
- 倒序排行榜
- 如果需要获取倒序的排行榜,使用
ZREVRANGE命令。
- 如果需要获取倒序的排行榜,使用
跳表的节点高度是由什么决定的?
在 Redis 中,跳跃表节点的高度是根据幂次定律随机生成的,其值介于 1 和 32 之间。
每次创建一个新跳跃表节点时,Redis 会使用随机算法生成一个介于 1 和 32 之间的值作为level数组的大小,这个大小就是该节点的“高度”,即层数。
这种随机确定节点高度的方式有一定的概率性。通过使用幂次定律,使得较高的层数出现的概率相对较低,从而在保证查找效率的同时,避免了过多的额外内存开销。这样可以在平均情况下实现对数时间复杂度的查找、插入和删除操作,同时又不会因固定的多层结构而导致过高的空间浪费。
这种设计的优点在于,它不需要严格维护相邻两层链表之间的节点个数关系,新插入的节点能根据自身随机生成的层数决定在哪些层的链表上出现。既能提高查找效率,又能较好地应对动态的插入和删除操作,避免了复杂的调整操作,使时间复杂度不会退化到 O(n)。
分库分表
分库分表是一种数据库架构优化技术,主要是为了解决数据库在数据量过大、并发访问过高时出现的性能瓶颈和管理难题。
分库指的是将一个大型数据库按照业务或其他规则拆分成多个独立的数据库,每个库可以部署在不同的服务器上,以减轻单个数据库的负载和提高数据处理能力。
分表则是将一张大数据表按照特定规则拆分成多个小表,比如按照时间、地域、业务类型等进行划分。分表可以是水平分表,即将表中的数据按照行进行分割,分布到多个表中;也可以是垂直分表,即将表中的列按照业务相关性分割到不同的表中。
实现分库分表的方法主要有以下几种:
- 基于哈希的分库分表:通过对数据的某个字段进行哈希计算,根据哈希值将数据分配到不同的库表中。
- 基于范围的分库分表:按照数据字段的取值范围,如按照时间区间、数值大小范围等进行分库分表。
- 基于枚举值的分库分表:根据数据字段的枚举值,如地区、业务类型等进行分库分表。
分库分表的好处包括:
- 提高系统的性能和响应速度,减少数据查询和操作的时间。
- 增强系统的可扩展性,便于应对不断增长的数据量和业务需求。
- 方便数据的管理和维护,降低单个库或表的复杂度。
欢迎关注 ❤
我们搞了一个免费的面试真题共享群,互通有无,一起刷题进步。
没准能让你能刷到自己意向公司的最新面试题呢。
感兴趣的朋友们可以私信我。