文章链接:https://arxiv.org/pdf/2407.18247
github链接:https://github.com/LuJingyi-John/RegionDrag
亮点直击
引入了一种基于区域的图像编辑方法,以克服基于点拖拽方法的局限性,利用更丰富的输入上下文来更好地对齐编辑结果与用户的意图。
通过采用无梯度的复制粘贴操作,基于区域的图像编辑比现有方法快得多(见上图1),在一次迭代中完成拖拽。
扩展了两个基于点拖拽的数据集,添加了基于区域拖拽的指令,以验证RegionDrag的有效性并为基于区域的编辑方法提供基准。
基于点拖拽的图像编辑方法,如DragDiffusion,已引起了广泛关注。然而,由于点编辑指令的稀疏性,基于点拖拽的方法存在计算开销大和用户意图误解的问题。本文提出了一种基于区域的复制粘贴拖拽方法,RegionDrag,以克服这些局限性。RegionDrag 允许用户以操作区和目标区的形式表达其编辑指令,从而实现更精确的控制并减少模糊性。此外,基于区域的操作可以在一次迭代中完成编辑,速度比基于点拖拽的方法快得多。还引入了注意力交换技术,以增强编辑过程的稳定性。为了验证本文的方法,扩展了现有的基于点拖拽的数据集,添加了基于区域拖拽的指令。实验结果表明,RegionDrag在速度、准确性和与用户意图的对齐方面均优于现有的基于点拖拽的方法。值得注意的是,RegionDrag在分辨率为512×512的图像上完成编辑的时间少于2秒,这比DragDiffusion快了100倍以上,同时性能更优。
RegionDrag
RegionDrag 允许用户输入操作区和目标区对,然后通过以下两个主要步骤进行编辑:
-
复制操作区覆盖的潜在表示,并在反转过程中存储自注意力特征;
-
将复制的潜在表示粘贴到目标位置,并在去噪过程中插入存储的自注意力特征。
本节讨论基于点拖拽方法的局限性,并介绍基于区域的输入如何解决这些局限性。最后,展示了处理基于区域输入的编辑流程。
从基于点的拖拽到基于区域的拖拽
尽管基于点拖拽的方法提供了一种直观的用户输入方式,但从稀疏点中获得的有限信息在编辑过程中对模型构成了挑战。具体来说,点指令会导致两个主要问题:输入模糊性和推理速度慢。
首先,点指令本质上是模糊的。一种拖拽操作可能对应多种可能的编辑效果。例如,用户试图在图像中延长鸟的喙,如下图2所示。用户选择鸟喙上的一个点并向左上角拖拽。然而,基于点拖拽的方法可能会误解用户的目标,认为是要放大喙或者将整只鸟移动到左侧,而不是延长喙,从而导致用户意图与模型输出之间的不对齐。

其次,基于点拖拽的编辑涉及的复杂性需要相当大的计算开销。基于点拖拽的编辑具有挑战性,因为模型必须从单个或少数点的运动中推断出整个图像的变化。为了在保持对象身份的同时执行这种复杂的拖拽操作,基于点拖拽的方法严重依赖于两个计算密集的步骤:为每个图像训练一个独特的LoRA和将拖拽过程分解为一系列子步骤。特别是,LoRA帮助模型保持原始图像的身份,逐步拖拽则增加了实现预期编辑效果的机会。否则,编辑结果可能会受到显著的身份扭曲或无效编辑的影响,如上图2所示。问题的根源在于稀疏点对编辑施加的约束不足,因此模型必须依赖LoRA来防止扭曲,并通过迭代编辑在拖拽路径上提供一定程度的额外监督。因此,大多数基于点拖拽的方法需要几分钟才能编辑一张图像,使其在现实世界应用中不切实际。
解决这些问题的最简单方法是鼓励用户提供足够数量的点。然而,这种方法会导致用户在指定和拖拽点时花费过多时间。因此,作者设计了一种不仅对用户友好且能为模型提供更多信息上下文的编辑形式,从而避免指令模糊、推理速度慢和用户过度劳累。提出使用基于区域的操作来代替依赖拖拽点的方法,其中用户指定一个操作区(H)以指示他们希望拖拽的区域,并指定一个目标区(T)以展示他们希望实现的位置。然后,通过区域到点映射算法建立这两个区域之间的密集映射,并通过一次反转和去噪循环直接将操作区覆盖的潜在表示复制到目标区域来完成编辑。
尽管这种操作简单,但它从两个方面解决了模糊性和开销问题:
-
基于区域的操作比拖拽点更具表现力和准确性,从而显著减少了模糊性。如图2所示,通过简单地画一个更长的喙来表示延长鸟的喙,从而减少了基于点拖拽输入的模糊性。
-
每个区域在密集映射后对应大量的点,因此它比稀疏点对编辑结果提供了更强的约束。结果是,不需要沿拖拽路径插值中间点或渴望额外的监督,编辑可以在一个步骤中完成。此外,操作区和目标区可以大小不一且形状任意,允许用户方便地定义它们。
编辑流程
首先介绍基于区域的用户输入,然后介绍区域到点映射算法,最后介绍主要的工作流程。
用户输入:操作区和目标区可以通过两种方式定义:
-
输入顶点以形成多边形(例如三角形或四边形)
-
使用画笔工具刷出一个灵活的区域。
输入形式的选择主要取决于用户的偏好。顶点适用于编辑定义明确的形状,如移动建筑物上的窗口;画笔工具则更适合处理不规则的形状,如弯曲的道路或人类的头发。
区域到点映射:为了在复制和粘贴潜在表示时保留原始空间信息,需要在操作区和目标区之间建立密集的映射。如果区域限制为三角形或四边形,可以使用仿射或透视映射计算转换矩阵。然而,为任意形状的刷出区域找到类似的转换是具有挑战性的。为了解决这个问题,提出了一种算法来数值地找到两个区域之间的映射。
设 和 分别为操作区和目标区中的像素集合。首先线性缩放目标区域的宽度以匹配操作区的宽度。对于目标区中的每个像素 ,x 通过首先减去x坐标的下边界 并使用目标区域的x坐标范围 进行归一化。然后它被缩放到操作区的x坐标范围 ,得到 。
该步骤确保两个区域具有相同数量的像素列。接下来,将每个目标区域的垂直像素列映射到其对应的操作区域列。目标区域中每个点的y值通过减去其垂直列的下边界 并通过其列的y坐标范围 进行归一化,然后缩放到对应的操作区域列的y坐标范围 。符号 表示一个函数 (例如 或 ),该函数接受一个变量和一个条件,并返回满足条件的点中该变量的函数值。整个过程总结如下面算法1所示。

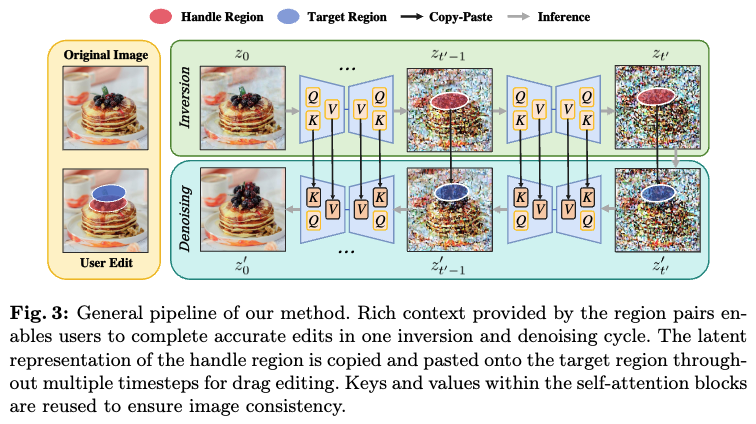
主要流程:如下图3所示,RegionDrag利用了图像编辑流程。首先,将图像的潜在表示 反转为 ,其中 是选定的最大时间步长 之前的一个时间步长。在反转过程中,缓存每个中间步骤 以备将来使用。然后复制 并将副本记为 。根据在公式(5)中定义的混合函数 α,将高斯噪声 与 的操作区域进行混合。
![]()
其中,H 是一个二值mask ,操作区赋值为1, 是一个介于0到1之间的混合系数,用于控制混合效果的强度。噪声 从均值为0、协方差矩阵为单位矩阵的高斯分布中抽取,记为。如果 设置得较低,则添加的噪声较少,从而在操作区保留更多原始图像的特征和细节。与高斯噪声混合后, 通过 DDPM 采样器进行去噪,拖拽以复制粘贴的方式进行。在去噪时间步 ,提取 操作区内的潜在表示,并根据几何变换或算法1计算的密集映射将其映射到 的目标区域。同时,使用互相自注意力控制来帮助保持图像的身份。简而言之,当通过 UNet 的自注意力模块时,用于去噪 的键和值 被替换为来自 的 。这使得编辑后的图像保持原始图像的布局和身份,从而稳定编辑过程。
在 逐渐去噪到 (见上面图3)后,它被解码为编辑后的图像 。尽管 RegionDrag 是通过单个操作-目标区域对引入的,但它支持多个输入对 ,允许用户在单个编辑会话中指定多个修改。每个区域对单独构建密集映射,但在潜在表示复制粘贴操作中共同使用。整个流程总结如算法2所示。

实验结果
评估指标
LPIPS:按照【24】的方法,使用 Learned Perceptual Image Patch Similarity (LPIPS) v0.1来测量编辑后图像与原始图像之间的身份相似性。LPIPS 计算图像对之间的 AlexNet特征距离。高 LPIPS 分数表明由于编辑而发生了意外的身份变化或伪影。较低的 LPIPS 分数表明在编辑过程中对象的身份得到了很好的保留;然而,这并不一定意味着编辑效果更好,因为两个完全相同的图像会产生 LPIPS 分数为0。
平均距离 (MD) :DragDiffusion引入了 MD 指标来评估某方法将操作点内容移动到目标点的效果。为了确定方法将操作点移动到的位置,DragDiffusion 使用 DIFT找到与操作点 最相似的点,并将它们记为 。然后,它使用 DIFT 匹配点与真实目标位置 之间的归一化欧几里得距离作为指标。然而,只需在操作点及其对应的真实目标点周围的区域搜索 ,而不是在整个图像中搜索,以避免 DIFT 错误地将图像中的无关点识别为 并过度惩罚某些方法。正式地,给定一个拖拽点对 ,定义其搜索mask 为:
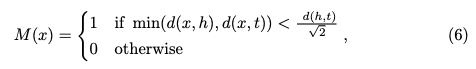
其中 计算两个点 和之间的归一化欧几里得距离,公式为:
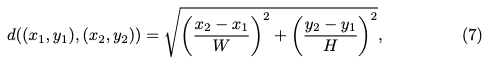
其中 和 分别是图像的宽度和高度。在下图5中提供了搜索mask 的示例。MD 然后被定义为所有 个点的目标点与 DIFT 匹配点之间的归一化距离 的平均值:


实现细节
本文的方法使用 Python 实现,依赖于 HuggingFace和 PyTorch库。采用 Stable Diffusion v1-5 作为扩散模型,图像尺寸为 512 × 512,保持与之前基于扩散的拖拽方法一致。使用 DDPM 采样器进行反转和去噪采样过程,配置为总共使用 20 个步骤。潜在表示反转到时间步 t′ = 500(总共 1000 个步骤中的 SD1-5)。因此,进行 10 次反转步骤和 10 次去噪步骤。互相自注意力控制在所有时间步中都启用,并且潜在的复制粘贴操作在 t'' = 200 处终止。噪声权重 设置为 1。所有实验结果均在 NVIDIA Tesla V100 GPU 上获得。
基准对比
将 RegionDrag 与基于点拖拽的扩散方法进行比较,包括 DragDiffusion、SDE-Drag和 DiffEditor。由于 GAN 基于的方法在编辑 DragBench-S 和 DragBench-D 数据集中的多样图像时存在局限性,且需要领域特定的 StyleGAN 检查点,因此排除了 GAN 基于的方法。基于扩散的方法在编辑任务中优于 GAN 基于的方法,更适合评估。执行时间在两个数据集上取平均,并且所有方法均在同一设备上使用公开发布的代码进行测试。
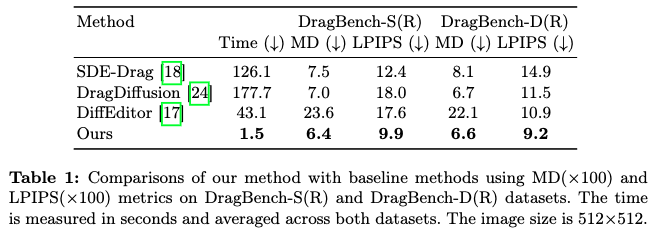
定量评估
为了定量评估方法的编辑性能,使用 LPIPS 和平均距离作为指标,并将两者均乘以 100 以便于说明。如下表1所示,RegionDrag 在 DragBench-S(R) 和 DragBench-D(R) 数据集上显著优于那些计算开销大的基于点的方法。这些结果突显了 RegionDrag 在保持图像一致性同时,在不同数据集上实现竞争性编辑结果的卓越性能。除了效果外,RegionDrag 在效率方面也表现出色。RegionDrag 实现了快速推理速度,编辑一个 512 × 512 的图像大约需要 1.5 秒,比第二快的方法快 20 倍,比 DragDiffusion快 100 倍。鉴于复制粘贴操作引入的计算开销可忽略不计,RegionDrag 的推理时间与使用 SD1-5 生成一张 20 步的图像相当。
定性结果
下图6 比较了基于点拖拽和基于区域的编辑输入及其对应的结果,展示了 RegionDrag 的有效性。基于区域的方法利用了注释区域提供的全面上下文来实现期望的修改,同时保持图像的整体一致性,优于基于点拖拽的编辑方法。

消融研究
作者认为点输入的稀疏性导致了较差的编辑结果。为了定量证明这一点,在 DragBench-DR 数据集上进行了测试,通过随机选择每个样本中等效转换点的子集,并使用这些子集进行推理。逐渐减少所选点的百分比,以观察对 MD 指标的影响。如下图7所示,随着所用点的百分比减少,MD 的结果明显呈上升趋势。这表明,与基于区域的输入相比,稀疏点输入对输出的约束较弱,导致编辑结果不令人满意。这证实了在 RegionDrag 中采用基于区域的输入的好处。

在去噪过程中,在时间间隔内进行图像潜在表示的复制和粘贴。为了验证这一设计,将其与仅在初始去噪时间步进行复制粘贴的方法进行了比较。下图8显示,仅在初始步骤进行编辑可能会导致不可预测的结果,因为后续的去噪阶段可能会丢失这些编辑。多步复制粘贴通过在较小的时间步提供额外的指导,同时保持图像的保真度,从而解决了这一问题。

结论
本文引入了一个高效且有效的基于区域的编辑框架——RegionDrag,用于高保真图像编辑。与现有的基于点拖拽的编辑方法不同,RegionDrag 从区域的角度重新审视了编辑问题。RegionDrag 通过复制和粘贴图像的潜在表示和自注意力特征,实现了单步编辑,这不仅提供了卓越的效率,还达到了优越的编辑性能。此外,基于现有数据集引入了两个新的基准测试,DragBench-SR 和 DragBench-DR,用于评估基于区域的编辑。实验结果一致证明了本文方法在效率和编辑性能上的卓越表现。
参考文献
[1] RegionDrag: Fast Region-Based Image Editing with Diffusion Models
更多精彩内容,请关注公众号:AI生成未来

欢迎加群交流AIGC技术