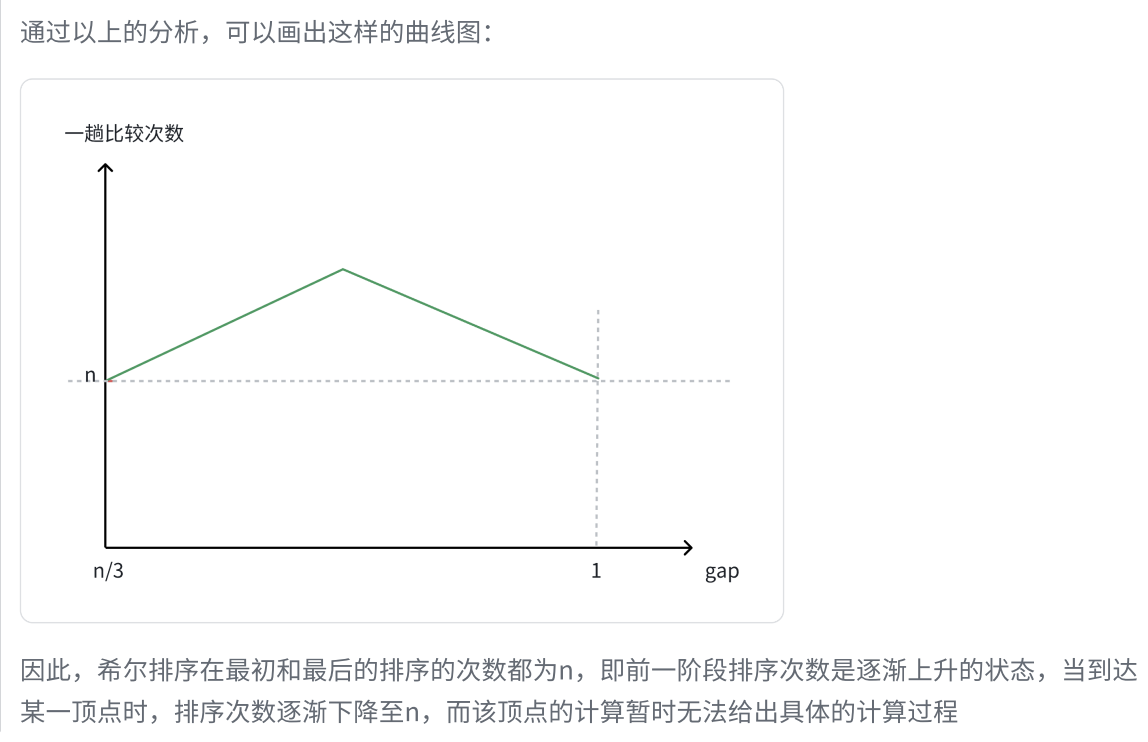
目录
- 前言
- 第一步:手写BP神经网络
- 1 概念简介
- 1.1 神经网络内的概念
- 1.2 神经网络外的概念
- 2 类BPNetwork
- 2.1 初始化
- 2.2 激活函数
- 2.2.1 Sigmod
- 2.2.2 Linear
- 2.2.3 Sigmod_derivative
- 2.3 损失函数
- 2.4 前向传播
- 2.5 后向传播
- 2.6 训练模型
- 2.7 预测
- 2.8 绘制损失值变化曲线
- ** 安装必要的库 **
- ** 必要资源下载 **
- 3 “曲线”问题
- 3.1 拟解决的问题
- 3.2 加载数据
- 3.3 绘制原始图像
- 3.4 加载数据->构建模型->训练模型->预测结果->绘制图像(重要)
- 3.5 主程序(重要)
- 4 “异或”问题
- 4.1 拟解决的问题
- 4.2 加载数据
- 4.3 绘制原始图像
- 4.4 加载数据->构建模型->训练模型->预测结果->绘制图像(重要)
- 4.5 主程序
- 5 小结:实操的五个步骤
- 第二步:基于TensorFlow框架开发
- 1 手写字识别(卷积神经网络)
- 1.1 加载数据
- ***非必要:查看Minst数据集
- 1.2 构建模型
- 1.3 训练模型
- 1.4 预测结果
- 1.5 绘制图像(分析模型性能)
- 非必要:文章最后提供了未使用卷积和池化层的版本,可自行比较二者的性能差异
- 2 情感分类(循环神经网络)
- 2.1 数据预处理
- 2.2 加载数据
- 2.3 构建模型
- 2.4 训练模型
- 2.5 预测结果
- 2.6 绘制图像(分析模型性能)
- 第三步:基于预训练模型快速构建应用
- ** 使用SAM预训练模型实现图像分割 **
- 1 加载模型(参数)
- 2 调用模型(结构+参数)
- 3 图像分割
- 4 实验结果
- 四、总结
- 五、完整代码
- BP.py
- Minst.py
- Minst_plus.py
- LookMinst.py
- LSTM_pretreat.py
- LSTM
- ann_segment.py
前言
善始者繁多,克终者盖寡。
本文用于工作室学习经验分享,适用对象为机器学习初学者,文中所阐述内容仅为个人观点,提供以下案例:
- 手写BP神经网络拟合曲线
- 手写BP神经网络模拟“异或”操作
- 基于TensorFlow的手写字识别
- 基于TensorFlow的情感分类
- 基于SAM预训练模型的目标分割
本人期望通过 手写BP神经网络入门 --> 使用TensorFlow开发 --> 利用TensorFlow Hub快速构建应用 的逻辑帮助各位 理解神经网络的工作原理和流程、使用现有框架构建自己的神经网络、利用他人提供的预训练模型实现自己的需求。
文中代码部分由AI编写,在学习开始时推荐大家使用AI辅助编程。嵌入式的辅助工具有亚马逊的CodeWhisppser、微软的Copliot、阿里的通义灵码;对话式的辅助工具有微软的GPT(推荐使用4o)、Kimi、科大讯飞的AI。
第一步:手写BP神经网络
人类期望 使用计算机模拟生物体中的“神经细胞” 以解决现实中的问题。
1 概念简介
1.1 神经网络内的概念

神经元:神经网络中的最小单位,类似于生物体中的细胞;
激活函数:处理输入信息的数学函数,模拟了生物体中细胞的应激反应,信号传入神经元后该执行何种操作就是由激活函数决定
神经网络;多个神经元组成的网络,在实际操作中通常会人为地设置神经网络的结构;
权重:用于描述输入信息对某个神经元的影响程度;
偏置:用于描述系统中不确定因素的影响;
模型:模型是对神经网络结构和参数的一种称呼,“模型=结构+参数”,结构指神经网络有多少层、每层包含多少神经元,参数主要值权重和偏置;
损失函数:用于描述和计算模型输出和真实值间的差异(上图未呈现);
前向传播:信号(输入的数据)从输入层到输出层的过程,该过程会经过多次数值计算;
反向传播:信号(前向传播计算的结果)从输出层到输入层的过程,该过程同样会经过多次的数值计算。
1.2 神经网络外的概念

一个形象的例子是:在学校老师会把前10套卷子拿来给同学们学习,帮助学生掌握知识,接着拿出几套卷子测试学生的掌握程度。
数据集:一组数据的集合,人类期望计算机从这些数据中学习到某些规律以解决某些特定问题;
训练:让计算机从数据中学习规律的过程,其本质是激活函数、损失函数等数学函数的运算;
测试:测试计算机的过程,同样是一系列的数值运算;
训练集:给计算机学习的数据的集合;
测试集:测试计算机规律掌握程度的数据的集合;
验证集:某些情况下对训练集的进一步划分,可以理解为训练集的一部分;
标量:一个具体的数值;
向量:一组数据的集合,对应程序设计中的一维数组;
矩阵;一组数据的集合,对应程序设计中的二维数组;
张量;一组数据的集合,对应程序设计中的多维数组。
训练和测试的目的是为模型找到最佳的结构和参数。
通常情况下训练集和测试集会按照“7:3”或“8:2”的比例进行划分。
神经网络中所有的操作都可以理解为数值的运算。
2 类BPNetwork
新建一个python文件,名称任取(为避免混淆不要取名为BPNetwork),本节提供类BPNetwork中所有的必要组件及其代码,请根据注解提示自行组装并尝试运行程序。
文章最后提供了完整的代码。
import numpy
from matplotlib import pyplot
from scipy.special import expit
'''
从中国科技大学源下载必要的库
pip install numpy -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install matplotlib -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install scipy -i https://pypi.mirrors.ustc.edu.cn/simple/
'''
'''
构建一个三层的BP神经网络
'''
class BPNetwork:
'''
初始化
input, hidden, output分别表示输入层、隐含层、输出层的神经元个数
'''
'''
Sigmoid激活函数,使用scipy.special.expit以避免溢出问题
'''
'''
线性激活函数,用于回归问题输出层
'''
'''
Sigmoid导数,用于反向传播
'''
'''
损失函数,使用均方差作为损失函数(当然使用方差和同样可以),此处的二分之一是为就算方便
'''
'''
前向传播
'''
'''
后向传播
'''
'''
训练模型
'''
'''
预测
'''
'''
显示损失值变化曲线
'''
2.1 初始化
def __init__(self, input, hidden, output):
# Xavier 初始化
self.weight1 = numpy.random.uniform(low=-numpy.sqrt(6/(input+hidden)), high=numpy.sqrt(6/(input+hidden)), size=(input, hidden))
self.weight2 = numpy.random.uniform(low=-numpy.sqrt(6/(hidden+output)), high=numpy.sqrt(6/(hidden+output)), size=(hidden, output))
# 偏置
self.bias1 = numpy.random.uniform(low=-numpy.sqrt(6/(input+hidden)), high=numpy.sqrt(6/(input+hidden)), size=(1, hidden))
self.bias2 = numpy.random.uniform(low=-numpy.sqrt(6/(hidden+output)), high=numpy.sqrt(6/(hidden+output)), size=(1, output))
# 损失值
self.loss = []
2.2 激活函数
2.2.1 Sigmod
def sigmod(self, x):
return expit(x)
2.2.2 Linear
def linear(self, x):
return x
2.2.3 Sigmod_derivative
def sigmod_derivative(self, x):
return x * (1 - x)
2.3 损失函数
def loss_mse(self, x, y):
return 1/2 * numpy.mean((x - y) ** 2)
2.4 前向传播
def forward(self, data):
# 隐含层
self.hidden_input = numpy.dot(data, self.weight1) + self.bias1
self.hidden_output = self.sigmod(self.hidden_input)
# 输出层
self.output_input = numpy.dot(self.hidden_output, self.weight2) + self.bias2
self.output_output = self.linear(self.output_input)
return self.output_output
2.5 后向传播
def backward(self, data, label, learning_rate):
# 计算误差(损失)
output_error = self.output_output - label
# 输出层误差项(包含了误差、激活函数导数两部分信息)
'''
去掉了对输出层使用Sigmoid导数,不仅能够避免溢出问题,还提高了模型的性能
'''
# output_delta = output_error * self.sigmod_derivative(self.output_output)
output_delta = output_error
# 将误差传入隐藏层
hidden_delta = numpy.dot(output_delta, self.weight2.T) * self.sigmod_derivative(self.hidden_output)
# 更新权重
self.weight1 -= numpy.dot(data.T, hidden_delta) * learning_rate
self.weight2 -= numpy.dot(self.hidden_output.T, output_delta) * learning_rate
# 更新偏置
self.bias1 -= numpy.sum(hidden_delta, axis=0) * learning_rate
self.bias2 -= numpy.sum(output_delta, axis=0) * learning_rate
2.6 训练模型
def train(self, data, label, learning_rate, epoch):
for i in range(epoch):
output = self.forward(data)
self.backward(data, label, learning_rate)
# 记录损失值变化
loss = self.loss_mse(label, output)
self.loss.append(loss)
# 打印每1000次的损失值
if i % 1000 == 0:
print(f"Epoch {i}, Loss: {loss}")
2.7 预测
def predict(self, data):
return self.forward(data)
2.8 绘制损失值变化曲线
def show_loss(self):
pyplot.title("LOSS")
pyplot.xlabel("epoch")
pyplot.ylabel("loss")
pyplot.plot(self.loss)
pyplot.show()
** 安装必要的库 **
'''
pip install numpy -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install matplotlib -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install scipy -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install scikit-learn -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install tensorflow -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install pandas -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install opencv-python -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install segment_anything -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install jieba -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install torch -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install torchvision -i https://pypi.mirrors.ustc.edu.cn/simple/
'''
** 必要资源下载 **
哈工大停词表下载:hit_stopwords.txt
SAM预训练模型(模型的参数)下载:sam_vit_b_01ec64.pth
3 “曲线”问题
类BPNetwork编写完毕后就可以开始尝试解决一些实际问题了,例如通过训练模型来拟合如下曲线以预测其未来走势。
本节代码均与class BPNetwork同级。

3.1 拟解决的问题
def fx(x):
return 10 * numpy.sin(5 * x) + 7 * numpy.cos(4 * x)
3.2 加载数据
'''
加载fx的数据,包括训练集(输入、标签)和测试集(输入和标签)
'''
def load_data_fx():
X_train = numpy.arange(0, 10, 0.1).reshape(-1, 1)
y_train = fx(X_train)
return X_train, y_train, X_train, y_train
3.3 绘制原始图像
'''
绘制fx的原始图像
'''
def draw_fx():
X = numpy.arange(0, 10, 0.1)
Y = fx(X)
pyplot.plot(X, Y)
pyplot.show()
3.4 加载数据->构建模型->训练模型->预测结果->绘制图像(重要)
'''
依次执行如下操作:
1.加载数据
2.构建模型(获得形状)
3.训练模型(获得参数)
4.预测(得到结果)
5.绘制预测曲线
6.显示损失值变化曲线
'''
def run_fx():
# 加载数据
X_train, y_train, X_test, y_test = load_data_fx()
# 构建模型(形状)
network = BPNetwork(1, 12, 1) # 增加隐含层神经元数量
# 训练模型(权重和偏置)
learning_rate = 0.01
network.train(X_train, y_train, learning_rate, 20000)
# 预测
prediction = network.predict(X_test)
print(prediction)
# 绘制预测曲线
pyplot.plot(X_train, y_train, color="red", label="True Function")
pyplot.plot(X_test, prediction, color="blue", label="Predicted Function")
pyplot.title('Nonlinear Equation Results')
pyplot.legend()
pyplot.show()
# 显示损失值变化曲线
network.show_loss()
3.5 主程序(重要)
'''
程序入口
'''
if __name__ == '__main__':
run_fx()


实验结果表明前文构建的BP神经网络在一定范围内能够很好的拟合曲线,但是训练次数在1000多的时候损失值(实际值与预测值间的均方差)几乎不在变化,现在尝试修改下列代码中的参数,观察曲线有何变化。
12表示隐含层神经元的个数;
0.01表示神经网络的学习率;
20000表示训练次数。
注意:初始参数也会影响模型的预测效果,但本文中难以以可视化的方式呈现处理。
# 构建模型(形状)
network = BPNetwork(1, 12, 1) # 增加隐含层神经元数量
# 训练模型(权重和偏置)
learning_rate = 0.01
network.train(X_train, y_train, learning_rate, 20000)
将学习率调整为0,005,实验结果如图所示,此时模型的拟合效果更优,但是通过观察损失值变化曲线发现,当训练次数到达2500后其减少程度非常缓慢,文中构建的模型并不是最好的,但是请尝试调整参数让模型的表现尽可能好。


4 “异或”问题
在第3节中,输入的数据只有一个,即一个x对应一个y,使用平面坐标系能够很轻松的绘制其变化情况,可视化效果佳,此时输入神经元个数为1,现在将将输入神经元个数增加至2,即一次输入包含两个数值,最典型的例子就是“异或”操作。

4.1 拟解决的问题
“异或”问题总共有四种情况:
0 0 -> 0
0 1 -> 1
1 0 -> 1
1 1 -> 0
4.2 加载数据
'''
加载“异或”问题的数据,总共四种情况
0 0 -> 0
0 1 -> 1
1 0 -> 1
1 1 -> 0
'''
def load_data_yihuo():
# 创建训练数据集
X_train = numpy.array([[0, 0],
[0, 1],
[1, 0],
[1, 1]])
y_train = numpy.array([[0],
[1],
[1],
[0]])
# 创建测试数据集
X_test = numpy.array([[0, 0],
[0, 1],
[1, 0],
[1, 1]])
y_test = numpy.array([[0],
[1],
[1],
[0]])
return X_train, y_train, X_test, y_test
4.3 绘制原始图像
'''
绘制异或操作的原始图像
'''
def draw_yihuo():
#加载数据
X_train, y_train, X_test, y_test = load_data_yihuo()
y_train_flat = y_train.flatten()
pyplot.scatter(X_train[:, 0], X_train[:, 1], s=100, color='blue', edgecolors='k')
for i, (xi, yi) in enumerate(zip(X_train[:, 0], X_train[:, 1])):
pyplot.text(xi, yi, f'{y_train_flat[i]:.1f}', fontsize=12, ha='right')
pyplot.xlabel('A')
pyplot.ylabel('B')
pyplot.title('True XOR Operation')
pyplot.show()
4.4 加载数据->构建模型->训练模型->预测结果->绘制图像(重要)
'''
依次执行如下操作:
1.加载数据
2.构建模型(获得形状)
3.训练模型(获得参数)
4.预测(得到结果)
5.绘制预测曲线
6.显示损失值变化曲线
'''
def run_yihuo():
#加载数据
X_train, y_train, X_test, y_test = load_data_yihuo()
#构建模型(形状)
network = BPNetwork(2, 4, 1)
#训练模型(权重和偏置)
learning_ration = 0.005
network.train(X_train, y_train, learning_ration, 20000)
#预测
prediction = network.predict(X_test)
print(prediction)
# 创建一个图形和两个子图
fig, (ax1, ax2) = pyplot.subplots(1, 2, figsize=(12, 6))
# 绘制第一个子图:带有数值标签的散点图
y_train_flat = y_train.flatten()
ax1.scatter(X_train[:, 0], X_train[:, 1], s=100, color='blue', edgecolors='k')
for i, (xi, yi) in enumerate(zip(X_train[:, 0], X_train[:, 1])):
ax1.text(xi, yi, f'{y_train_flat[i]:.5f}', fontsize=12, ha='right')
ax1.set_xlabel('A')
ax1.set_ylabel('B')
ax1.set_title('True XOR Operation')
# 绘制第二个子图
prediction_flat = prediction.flatten()
ax2.scatter(X_test[:, 0], X_test[:, 1], s=100, color='red', edgecolors='k')
for i, (xi, yi) in enumerate(zip(X_test[:, 0], X_test[:, 1])):
ax2.text(xi, yi, f'{prediction_flat[i]:.5f}', fontsize=12, ha='right')
ax2.set_xlabel('X1')
ax2.set_ylabel('X2')
ax2.set_title('Predicted XOR Operation')
# 显示图形
pyplot.tight_layout()
pyplot.show()
#显示损失值变化曲线
network.show_loss()
4.5 主程序
经过训练的模型能够将预测误差控制在0,01级别内,效果还是很棒的。
'''
程序入口
'''
if __name__ == '__main__':
run_yihuo()


5 小结:实操的五个步骤
模型包含两个部分:模型的结构、模型的参数,可以说“模型=结构+参数”,上述进行的所有操作都是为了寻找最佳的模型结构,获得最佳的模型参数,具体操作步骤有:
- 加载数据
- 构建模型(获得模型结构)
- 训练模型(获得模型参数)
- 预测结果
- 绘制图像(分析模型性能)
第二步:基于TensorFlow框架开发
在“第一步”中作者同大家一起手动构建了一个三层的BP神经网络,解决了“曲线”和“异或”问题,现在期望编写一个神经网络识别下图的数字,此时简单的三层BP神经网络已经显得力不从心了,我们需要重新设计神经网络的结构,该过程极其费事费力,互联网龙头大哥Geogle提供了一个工具箱——TensorFlow,它包含了丰富多样的“层”,例如Dense、Dropout、LSTM等。
我们能够使用这些已有的模型(模型的结构)满足自己的个性化需求。

1 手写字识别(卷积神经网络)
使用TensorFlow框架构建一个多层的神经网络识别手写字,使用官方提供的示例数据集。
本人期望通过多种实例让初学者们清楚神经网络的工作流程与具体操作步骤,所以本节中并不会详细解释代码如何编写的,大家只需要按照顺序将模块组装起来保证程序能够正常运行即可。
1.1 加载数据
从官方提供的仓库中下载示例数据,这是一个包含70000张图片的压缩包,其中训练集60000张,测试集10000张。
下载后其默认保存位置为’C:\Users\user.keras\datasets\mnist.npz’,此位置因人而异,依次点击“此电脑->C->用户->你的用户名”可找到。
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Conv2D, MaxPooling2D, Flatten
'''
pip install tensorflow -i https://pypi.mirrors.ustc.edu.cn/simple/
'''
# 加载MNIST数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理
x_train = x_train.reshape(-1, 28, 28, 1).astype('float32') / 255
x_test = x_test.reshape(-1, 28, 28, 1).astype('float32') / 255
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
以压缩包格式打开mnist.npz,发现其中包含训练集、训练集标签、测试集、测试集标签四项,文件后缀为npy,是库numpy的文件格式,由此可知,Minst中的图片是以数组的形式存放的。

***非必要:查看Minst数据集
新建一个Python文件,执行下列代码可读取mnist.npz中的npy文件并将其以图片的形式显示出来。
import numpy as np
import matplotlib.pyplot as plt
# 加载MNIST数据集
file_path = r'C:\Users\user\.keras\datasets\mnist.npz'
data = np.load(file_path)
# 列出文件中的数组
print(data.files)
# 提取数据
x_train = data['x_train']
y_train = data['y_train']
x_test = data['x_test']
y_test = data['y_test']
# 查看数据形状
print("训练数据形状:", x_train.shape)
print("训练标签形状:", y_train.shape)
print("测试数据形状:", x_test.shape)
print("测试标签形状:", y_test.shape)
# 显示一些图像
fig, axes = plt.subplots(1, 5, figsize=(15, 3))
img_indexs = np.random.randint(0, x_train.shape[0], 5)
for i,index in zip(np.arange(0, 6),img_indexs):
axes[i].imshow(x_train[index], cmap='gray')
axes[i].set_title(f"Label: {y_train[index]}")
axes[i].axis('off')
plt.show()
1.2 构建模型
'''
构建模型(顺序模型,即将不同的层依次组合起来)
Dense:全连接层
Conv2D:卷积层
MaxPooling2D:池化层
Dropout:Drop层,防止过拟合
Flatten:将多维数组展平
输出层:激活函数为softmax,输出神经元个数为10(因为MNIST数据集有10个类别,0至9,输出的值分别表示10个类别的“概率”)
'''
model = Sequential([
Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1)),
MaxPooling2D(pool_size=(2, 2)),
Dropout(0.2),
Conv2D(64, kernel_size=(3, 3), activation='relu'),
MaxPooling2D(pool_size=(2, 2)),
Dropout(0.2),
Flatten(),
Dense(128, activation='relu'),
Dropout(0.2),
Dense(10, activation='softmax')
])
'''
编译模型(模型构建好后是无法直接使用的,需要设置必要的参数)
设置优化器、损失函数、评估指标
'''
model.compile(optimizer=Adam(),
loss='categorical_crossentropy',
metrics=['accuracy'])
1.3 训练模型
# 训练模型
history = model.fit(x_train, y_train, epochs=10, batch_size=128, validation_split=0.2)
1.4 预测结果
# 从训练集抽取10条数据,输出其预测标签和真实标签
predictions = model.predict(x_test[:10])
print('Predictions:', np.argmax(predictions, axis=1))
print('Actual:', np.argmax(y_test[:10], axis=1))
1.5 绘制图像(分析模型性能)
模型每训练一轮都会在验证集上计算一次损失值,所以此例中会有验证集的损失曲线而手写的BP神经网络中没有。
# 从训练集抽取10条数据,输出其预测标签和真实标签
predictions = model.predict(x_test[:10])
print('Predictions:', np.argmax(predictions, axis=1))
print('Actual:', np.argmax(y_test[:10], axis=1))
# 绘制模型损失值的变化曲线
plt.plot(history.history['loss'], label='train_loss')
plt.plot(history.history['val_loss'], label='val_loss')
plt.title('Model Loss Progress')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend()
plt.show()
# 评估模型
score = model.evaluate(x_test, y_test, batch_size=128)
print('Test loss:', score[0])
print('Test accuracy:', score[1])

经过10轮训练,从测试集抽取的前10项真实标签和预测结果如图所示,模型的预测准确率在99%上下。

非必要:文章最后提供了未使用卷积和池化层的版本,可自行比较二者的性能差异
2 情感分类(循环神经网络)
使用TensorFlow框架构建一个多层的神经网络进行情感分类,使用自己收集到的数据集。
在手写字识别中使用了TensorFlow框架以及官网提供的完整数据集,至少在数据收集上真实情况往往复杂的多,例如数据量、数据质量难以保证,数据格式也不尽相同。本节将解决如下场景的问题:已经人工收集到了某门课程的45条评论,人工将其标注为“赞同”、“质疑”、“陈述”三种情感类别,现希望使用神经网络判断某句评论表达的情感。
2.1 数据预处理
将收集到的数据使用excel表格记录下来,部分数据如下图所示,预处理阶段将多余的字符去除并将评论和标签分别存放到txt文档中(理论上任何格式的文件都可以,作者本人习惯使用txt格式)。

代码中“hit_stopwords.txt”是哈工大提供的停此表。
import jieba
import pandas
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
'''
pip install jieba -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install pandas -i https://pypi.mirrors.ustc.edu.cn/simple/
'''
# 加载停用词表
def load_stopwords(filepath):
stopwords = set()
with open(filepath, 'r', encoding='utf-8') as file:
for line in file:
stopwords.add(line.strip())
return stopwords
# 分词并去除停用词
def preprocess_text(text, stopwords):
# 使用jieba分词
words = jieba.cut(text)
filtered_words = [word for word in words if word not in stopwords and word.strip()]
return " ".join(filtered_words)
# 读取数据文件
def read_data(filepath:str):
if filepath.endswith('.xlsx'):
data = pandas.read_excel(filepath)
return data
# 保存预处理后的数据
def save_processed_data(filepath, processed_data):
with open(filepath, 'w', encoding='utf-8') as file:
for line in processed_data:
if line != "" and line != " ":
file.write(line)
file.write("\n")
# 保存序列化后的数据
def save_sequences(filepath, sequences):
with open(filepath, 'w', encoding='utf-8') as file:
for sequence in sequences:
file.write(" ".join(map(str, sequence)))
file.write("\n")
# 停用词表文件路径
stopwords_file = 'hit_stopwords.txt'
# 加载停用词表
stopwords = load_stopwords(stopwords_file)
# 示例数据文件路径
data_file = '编码.xlsx'
# 读取数据
orign_data = read_data(data_file)
data = orign_data.iloc[:, 0].to_list()
label = orign_data.iloc[:, 1].to_list()
# 预处理数据
processed_data = [preprocess_text(line, stopwords) for line in data]
# 找到processed_data中所有为”“或者” “的索引,保存在列表indexs中
indexs = [i for i, line in enumerate(processed_data) if line == "" or line == " "]
# 删除processed_data和label中索引为indexs的元素
processed_data = [line for i, line in enumerate(processed_data) if i not in indexs]
label = [line for i, line in enumerate(label) if i not in indexs]
# 保存预处理后的数据
processed_data_file = 'data.txt'
processed_label_file = 'label.txt'
save_processed_data(processed_data_file, processed_data)
save_processed_data(processed_label_file, label)
print(f"预处理后的数据已保存")
# 构建词汇表和序列化处理
tokenizer = Tokenizer(num_words=5000)
tokenizer.fit_on_texts(processed_data)
sequences = tokenizer.texts_to_sequences(processed_data)
# 填充序列
max_sequence_length = 5 # 根据实际数据调整,左填充
padded_sequences = pad_sequences(sequences, maxlen=max_sequence_length)
# print(padded_sequences)
# 保存序列化后的数据
sequences_file = 'sequence.txt'
save_sequences(sequences_file, padded_sequences)
print(f"序列化后的数据已保存到 {sequences_file}")
2.2 加载数据
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense, Dropout, BatchNormalization, Conv1D, MaxPooling1D, Flatten
from tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as plt
# 加载数据
def load_data(data_path, label_path):
with open(data_path, 'r', encoding='utf-8') as file:
data = file.readlines()
with open(label_path, 'r', encoding='utf-8') as file:
labels = file.readlines()
data = [line.strip() for line in data]
labels = [line.strip() for line in labels]
return data, labels
# 数据文件路径
data_path = 'data.txt'
label_path = 'label.txt'
# 加载数据
data, labels = load_data(data_path, label_path)
# 标签编码
label_encoder = LabelEncoder()
encoded_labels = label_encoder.fit_transform(labels)
# 划分训练集和测试集,随机选择30%数据作为测试集,并使用stratify参数进行分层抽样
X_train, X_test, y_train, y_test = train_test_split(data, encoded_labels, test_size=0.3, stratify=encoded_labels, random_state=42)
# 构建词汇表和序列化处理
tokenizer = Tokenizer(num_words=5000)
tokenizer.fit_on_texts(X_train)
X_train_sequences = tokenizer.texts_to_sequences(X_train)
X_test_sequences = tokenizer.texts_to_sequences(X_test)
# 填充序列
max_sequence_length = 5
X_train_padded = pad_sequences(X_train_sequences, maxlen=max_sequence_length)
X_test_padded = pad_sequences(X_test_sequences, maxlen=max_sequence_length)
# 将标签转换为类别编码
num_classes = len(set(encoded_labels))
y_train_encoded = to_categorical(y_train, num_classes=num_classes)
y_test_encoded = to_categorical(y_test, num_classes=num_classes)
2.3 构建模型
# 构建LSTM模型
def create_lstm_model(input_length, num_classes):
model = Sequential()
model.add(Embedding(input_dim=5000, output_dim=128, input_length=input_length))
model.add(LSTM(128, dropout=0.2, recurrent_dropout=0.2))
model.add(Dropout(0.2))
model.add(Dense(num_classes, activation='softmax'))
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
return model
# 创建模型
model = create_lstm_model(max_sequence_length, num_classes)
2.4 训练模型
history = model.fit(X_train_padded, y_train_encoded, batch_size=32, epochs=10, validation_data=(X_test_padded, y_test_encoded))
2.5 预测结果
# 标签解码并打印前10个预测
y_pred = model.predict(X_test_padded)
y_pred_classes = np.argmax(y_pred, axis=1)
decoded_y_pred = label_encoder.inverse_transform(y_pred_classes)
# 打印实际标签和预测标签
print("Actual vs Predicted:")
actual_vs_predicted = list(zip(label_encoder.inverse_transform(y_test), decoded_y_pred))[:10]
for actual, predicted in actual_vs_predicted:
print(f"Actual: {actual}, Predicted: {predicted}")
2.6 绘制图像(分析模型性能)
# 绘制准确率和损失值的变化曲线
def plot_history(history):
plt.figure(figsize=(10, 4))
# 准确率变化曲线
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='Train')
plt.plot(history.history['val_accuracy'], label='Test')
plt.title('Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
# 损失值变化曲线
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='Train')
plt.plot(history.history['val_loss'], label='Test')
plt.title('Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.tight_layout()
plt.show()
plot_history(history)
# 评估模型性能
loss, accuracy= model.evaluate(X_test_padded, y_test_encoded)
print(f'Test Loss: {loss}')
print(f'Test Accuracy: {accuracy}')
观察准确率及损失值变化曲线发现,随着训练的进行模型在测试集上的准确率在60%上下,此时模型可能已经出现了过拟合状况,通过增加数据量以及模型结构能够提升模型性能。


第三步:基于预训练模型快速构建应用
可以将模型理解为 “模型=结构+参数”
“第一步”中手动创建了模型结构,通过训练获得了模型参数;
“第二步”中使用TensorFlow提供的模型结构,通过训练获得了模型参数;
“第三步”将使用预训练模型实现图像分割任务,预训练模型提供了模型结构以及训练好的模型参数。
** 使用SAM预训练模型实现图像分割 **
从代码量上看,使用不到10行代码即可完成图像分割任务,唯一的不足是:模型的体积非常大。本节中使用的“sam_vit_b_01ec64.pth”大小约为350M,属于体积最小的一个了。
1 加载模型(参数)
import os
import cv2
import numpy as np
from datetime import datetime
import matplotlib.pyplot as plt
from segment_anything import sam_model_registry, SamPredictor
'''
pip install opencv-python -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install segment_anything -i https://pypi.mirrors.ustc.edu.cn/simple/
'''
# 模型(参数)路径
sam_checkpoint = "D:\\playground\\label_anything\\sam_vit_b_01ec64.pth"
# 模型类型
model_type = "vit_b"
# 两种取值:"cpu" or "cuda"
device = "cpu"
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
2 调用模型(结构+参数)
类SamPredictor类似于文中开头提到的类BPNetwork,它是模型的结构。
# 添加必要的模型参数
sam.to(device=device)
# 调用预测模型
predictor = SamPredictor(sam)
3 图像分割
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
def show_points(coords, labels, ax, marker_size=375):
pos_points = coords[labels == 1]
neg_points = coords[labels == 0]
ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white',
linewidth=1.25)
ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white',
linewidth=1.25)
def show_box(box, ax):
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0, 0, 0, 0), lw=2))
img_dir = "D:\\resources\\cat_dataset\\images_test\\"
out_dir = "D:\\resources\\cat_dataset\\images_test_pre\\"
os.makedirs(out_dir, exist_ok=True)
# 遍历图像目录中的每张图片
for img_file in os.listdir(img_dir):
if img_file.endswith(('.png', '.jpg', '.jpeg')):
img_path = os.path.join(img_dir, img_file)
# 读取的图像以NumPy数组的形式存储在变量image中
image = cv2.imread(img_path)
print(f"{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}正在转换图片格式{img_file}......")
# 将图像从BGR颜色空间转换为RGB颜色空间,还原图片色彩(图像处理库所认同的格式)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# print("[%s]正在初始化模型参数......" % datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
# 调用`SamPredictor.set_image`来处理图像以产生一个图像嵌入。`SamPredictor`会记住这个嵌入,并将其用于随后的掩码预测
predictor.set_image(image)
# --------------------------------------单点输入--------------------------------------
# print("【单点分割阶段】")
print("[%s]正在分割图片......" % datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
# 单点位置 prompt 输入格式为(x, y)和并表示出点所带有的标签1(前景点)或0(背景点)。
input_point = np.array([[image.shape[1]/2, image.shape[0]/2]])
# input_point = np.array([[1500, 2000]])
# 点所对应的标签(前景)
input_label = np.array([1])
# 显示原始图像
# plt.figure(figsize=(10, 10))
# plt.imshow(image)
# show_points(input_point, input_label, plt.gca())
# plt.axis('on')
# plt.show()
masks, scores, logit = predictor.predict(
point_coords=input_point,
point_labels=input_label,
# 为False时,它将返回一个掩码,否则返回三个
multimask_output=True,
)
# print(masks.shape) # (3, 2160, 3840)波段,高,宽
'''
显示所有置信度的图像
'''
# for i, (mask, score) in enumerate(zip(masks, scores)):
# # 三个置信度不同的图
# plt.figure(figsize=(10, 10))
# plt.imshow(image)
# show_mask(mask, plt.gca())
# show_points(input_point, input_label, plt.gca())
# plt.title(f"Mask {i + 1}, Score: {score:.3f}", fontsize=18)
# plt.axis('off')
# plt.show()
'''
仅显示置信度最高的图像
'''
# 找到置信度最高的图像索引
max_score_index = np.argmax(scores)
plt.figure(figsize=(10, 10))
plt.imshow(image)
show_mask(masks[max_score_index], plt.gca())
# show_points(input_point, input_label, plt.gca())
plt.title(f"Score: {scores[max_score_index]:.3f}", fontsize=18)
plt.axis('off')
# 保存图像文件
plt.savefig(os.path.join(out_dir,img_file))
# plt.show()
4 实验结果
下列展示的均为从网络上下载的图像,实验结果表明:使用预训练的SAM模型能够较好的完成图像分割任务。






四、总结
- 模型=结构+参数
- 训练和测试的目的是寻找最佳的结构和参数
- 神经网络中所有操作都可以看作数值的运算
- 实操的五个步骤
- 使用预训练模型能够快速构建一个应用
五、完整代码
BP.py
import numpy
from matplotlib import pyplot
from scipy.special import expit
'''
从中国科技大学源下载必要的库
pip install numpy -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install matplotlib -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install scipy -i https://pypi.mirrors.ustc.edu.cn/simple/
'''
'''
构建一个三层的BP神经网络
'''
class BPNetwork:
'''
初始化
input, hidden, output分别表示输入层、隐含层、输出层的神经元个数
'''
def __init__(self, input, hidden, output):
# Xavier 初始化
self.weight1 = numpy.random.uniform(low=-numpy.sqrt(6/(input+hidden)), high=numpy.sqrt(6/(input+hidden)), size=(input, hidden))
self.weight2 = numpy.random.uniform(low=-numpy.sqrt(6/(hidden+output)), high=numpy.sqrt(6/(hidden+output)), size=(hidden, output))
# 偏置
self.bias1 = numpy.random.uniform(low=-numpy.sqrt(6/(input+hidden)), high=numpy.sqrt(6/(input+hidden)), size=(1, hidden))
self.bias2 = numpy.random.uniform(low=-numpy.sqrt(6/(hidden+output)), high=numpy.sqrt(6/(hidden+output)), size=(1, output))
# 损失值
self.loss = []
'''
Sigmoid激活函数,使用scipy.special.expit以避免溢出问题
'''
def sigmod(self, x):
return expit(x)
'''
线性激活函数,用于回归问题输出层
'''
def linear(self, x):
return x
'''
Sigmoid导数,用于反向传播
'''
def sigmod_derivative(self, x):
return x * (1 - x)
'''
损失函数,使用均方差作为损失函数(当然使用方差和同样可以),此处的二分之一是为就算方便
'''
def loss_mse(self, x, y):
return 1/2 * numpy.mean((x - y) ** 2)
'''
前向传播
'''
def forward(self, data):
# 隐含层
self.hidden_input = numpy.dot(data, self.weight1) + self.bias1
self.hidden_output = self.sigmod(self.hidden_input)
# 输出层
self.output_input = numpy.dot(self.hidden_output, self.weight2) + self.bias2
self.output_output = self.linear(self.output_input)
return self.output_output
'''
后巷传播
'''
def backward(self, data, label, learning_rate):
# 计算误差(损失)
output_error = self.output_output - label
# 输出层误差项(包含了误差、激活函数导数两部分信息)
'''
去掉了对输出层使用Sigmoid导数,不仅能够避免溢出问题,还提高了模型的性能
'''
# output_delta = output_error * self.sigmod_derivative(self.output_output)
output_delta = output_error
# 将误差传入隐藏层
hidden_delta = numpy.dot(output_delta, self.weight2.T) * self.sigmod_derivative(self.hidden_output)
# 更新权重
self.weight1 -= numpy.dot(data.T, hidden_delta) * learning_rate
self.weight2 -= numpy.dot(self.hidden_output.T, output_delta) * learning_rate
# 更新偏置
self.bias1 -= numpy.sum(hidden_delta, axis=0) * learning_rate
self.bias2 -= numpy.sum(output_delta, axis=0) * learning_rate
'''
训练模型
'''
def train(self, data, label, learning_rate, epoch):
for i in range(epoch):
output = self.forward(data)
self.backward(data, label, learning_rate)
# 记录损失值变化
loss = self.loss_mse(label, output)
self.loss.append(loss)
# 打印每1000次的损失值
if i % 1000 == 0:
print(f"Epoch {i}, Loss: {loss}")
'''
预测
'''
def predict(self, data):
return self.forward(data)
'''
显示损失值变化曲线
'''
def show_loss(self):
pyplot.title("LOSS")
pyplot.xlabel("epoch")
pyplot.ylabel("loss")
pyplot.plot(self.loss)
pyplot.show()
'''
拟拟合的非线性方程
'''
def fx(x):
return 10 * numpy.sin(5 * x) + 7 * numpy.cos(4 * x)
'''
加载fx的数据,包括训练集(输入、标签)和测试集(输入和标签)
'''
def load_data_fx():
X_train = numpy.arange(0, 10, 0.1).reshape(-1, 1)
y_train = fx(X_train)
return X_train, y_train, X_train, y_train
'''
绘制fx的原始图像
'''
def draw_fx():
X = numpy.arange(0, 10, 0.1)
Y = fx(X)
pyplot.plot(X, Y)
pyplot.show()
'''
依次执行如下操作:
1.加载数据
2.构建模型(获得形状)
3.训练模型(获得参数)
4.预测(得到结果)
5.绘制预测曲线
6.显示损失值变化曲线
'''
def run_fx():
# 加载数据
X_train, y_train, X_test, y_test = load_data_fx()
# 构建模型(形状)
network = BPNetwork(1, 12, 1) # 增加隐含层神经元数量
# 训练模型(权重和偏置)
# learning_rate = 0.01
learning_rate = 0.005
network.train(X_train, y_train, learning_rate, 20000)
# 预测
prediction = network.predict(X_test)
print(prediction)
# 绘制预测曲线
pyplot.plot(X_train, y_train, color="red", label="True Function")
pyplot.plot(X_test, prediction, color="blue", label="Predicted Function")
pyplot.title('Nonlinear Equation Results')
pyplot.legend()
pyplot.show()
# 显示损失值变化曲线
network.show_loss()
'''
加载“异或”问题的数据,总共四种情况
0 0 -> 0
0 1 -> 1
1 0 -> 1
1 1 -> 0
'''
def load_data_yihuo():
# 创建训练数据集
X_train = numpy.array([[0, 0],
[0, 1],
[1, 0],
[1, 1]])
y_train = numpy.array([[0],
[1],
[1],
[0]])
# 创建测试数据集
X_test = numpy.array([[0, 0],
[0, 1],
[1, 0],
[1, 1]])
y_test = numpy.array([[0],
[1],
[1],
[0]])
return X_train, y_train, X_test, y_test
'''
绘制异或操作的原始图像
'''
def draw_yihuo():
#加载数据
X_train, y_train, X_test, y_test = load_data_yihuo()
y_train_flat = y_train.flatten()
pyplot.scatter(X_train[:, 0], X_train[:, 1], s=100, color='blue', edgecolors='k')
for i, (xi, yi) in enumerate(zip(X_train[:, 0], X_train[:, 1])):
pyplot.text(xi, yi, f'{y_train_flat[i]:.1f}', fontsize=12, ha='right')
pyplot.xlabel('A')
pyplot.ylabel('B')
pyplot.title('True XOR Operation')
pyplot.show()
'''
依次执行如下操作:
1.加载数据
2.构建模型(获得形状)
3.训练模型(获得参数)
4.预测(得到结果)
5.绘制预测曲线
6.显示损失值变化曲线
'''
def run_yihuo():
#加载数据
X_train, y_train, X_test, y_test = load_data_yihuo()
#构建模型(形状)
network = BPNetwork(2, 4, 1)
#训练模型(权重和偏置)
learning_ration = 0.005
network.train(X_train, y_train, learning_ration, 20000)
#预测
prediction = network.predict(X_test)
print(prediction)
# 创建一个图形和两个子图
fig, (ax1, ax2) = pyplot.subplots(1, 2, figsize=(12, 6))
# 绘制第一个子图:带有数值标签的散点图
y_train_flat = y_train.flatten()
ax1.scatter(X_train[:, 0], X_train[:, 1], s=100, color='blue', edgecolors='k')
for i, (xi, yi) in enumerate(zip(X_train[:, 0], X_train[:, 1])):
ax1.text(xi, yi, f'{y_train_flat[i]:.5f}', fontsize=12, ha='right')
ax1.set_xlabel('A')
ax1.set_ylabel('B')
ax1.set_title('True XOR Operation')
# 绘制第二个子图
prediction_flat = prediction.flatten()
ax2.scatter(X_test[:, 0], X_test[:, 1], s=100, color='red', edgecolors='k')
for i, (xi, yi) in enumerate(zip(X_test[:, 0], X_test[:, 1])):
ax2.text(xi, yi, f'{prediction_flat[i]:.5f}', fontsize=12, ha='right')
ax2.set_xlabel('X1')
ax2.set_ylabel('X2')
ax2.set_title('Predicted XOR Operation')
# 显示图形
pyplot.tight_layout()
pyplot.show()
#显示损失值变化曲线
network.show_loss()
'''
程序入口
'''
if __name__ == '__main__':
# run_fx()
run_yihuo()
# draw_fx()
# draw_yihuo()
Minst.py
import numpy
from matplotlib import pyplot
from scipy.special import expit
'''
从中国科技大学源下载必要的库
pip install numpy -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install matplotlib -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install scipy -i https://pypi.mirrors.ustc.edu.cn/simple/
'''
'''
构建一个三层的BP神经网络
'''
class BPNetwork:
'''
初始化
input, hidden, output分别表示输入层、隐含层、输出层的神经元个数
'''
def __init__(self, input, hidden, output):
# Xavier 初始化
self.weight1 = numpy.random.uniform(low=-numpy.sqrt(6/(input+hidden)), high=numpy.sqrt(6/(input+hidden)), size=(input, hidden))
self.weight2 = numpy.random.uniform(low=-numpy.sqrt(6/(hidden+output)), high=numpy.sqrt(6/(hidden+output)), size=(hidden, output))
# 偏置
self.bias1 = numpy.random.uniform(low=-numpy.sqrt(6/(input+hidden)), high=numpy.sqrt(6/(input+hidden)), size=(1, hidden))
self.bias2 = numpy.random.uniform(low=-numpy.sqrt(6/(hidden+output)), high=numpy.sqrt(6/(hidden+output)), size=(1, output))
# 损失值
self.loss = []
'''
Sigmoid激活函数,使用scipy.special.expit以避免溢出问题
'''
def sigmod(self, x):
return expit(x)
'''
线性激活函数,用于回归问题输出层
'''
def linear(self, x):
return x
'''
Sigmoid导数,用于反向传播
'''
def sigmod_derivative(self, x):
return x * (1 - x)
'''
损失函数,使用均方差作为损失函数(当然使用方差和同样可以),此处的二分之一是为就算方便
'''
def loss_mse(self, x, y):
return 1/2 * numpy.mean((x - y) ** 2)
'''
前向传播
'''
def forward(self, data):
# 隐含层
self.hidden_input = numpy.dot(data, self.weight1) + self.bias1
self.hidden_output = self.sigmod(self.hidden_input)
# 输出层
self.output_input = numpy.dot(self.hidden_output, self.weight2) + self.bias2
self.output_output = self.linear(self.output_input)
return self.output_output
'''
后巷传播
'''
def backward(self, data, label, learning_rate):
# 计算误差(损失)
output_error = self.output_output - label
# 输出层误差项(包含了误差、激活函数导数两部分信息)
'''
去掉了对输出层使用Sigmoid导数,不仅能够避免溢出问题,还提高了模型的性能
'''
# output_delta = output_error * self.sigmod_derivative(self.output_output)
output_delta = output_error
# 将误差传入隐藏层
hidden_delta = numpy.dot(output_delta, self.weight2.T) * self.sigmod_derivative(self.hidden_output)
# 更新权重
self.weight1 -= numpy.dot(data.T, hidden_delta) * learning_rate
self.weight2 -= numpy.dot(self.hidden_output.T, output_delta) * learning_rate
# 更新偏置
self.bias1 -= numpy.sum(hidden_delta, axis=0) * learning_rate
self.bias2 -= numpy.sum(output_delta, axis=0) * learning_rate
'''
训练模型
'''
def train(self, data, label, learning_rate, epoch):
for i in range(epoch):
output = self.forward(data)
self.backward(data, label, learning_rate)
# 记录损失值变化
loss = self.loss_mse(label, output)
self.loss.append(loss)
# 打印每1000次的损失值
if i % 1000 == 0:
print(f"Epoch {i}, Loss: {loss}")
'''
预测
'''
def predict(self, data):
return self.forward(data)
'''
显示损失值变化曲线
'''
def show_loss(self):
pyplot.title("LOSS")
pyplot.xlabel("epoch")
pyplot.ylabel("loss")
pyplot.plot(self.loss)
pyplot.show()
'''
拟拟合的非线性方程
'''
def fx(x):
return 10 * numpy.sin(5 * x) + 7 * numpy.cos(4 * x)
'''
加载fx的数据,包括训练集(输入、标签)和测试集(输入和标签)
'''
def load_data_fx():
X_train = numpy.arange(0, 10, 0.1).reshape(-1, 1)
y_train = fx(X_train)
return X_train, y_train, X_train, y_train
'''
绘制fx的原始图像
'''
def draw_fx():
X = numpy.arange(0, 10, 0.1)
Y = fx(X)
pyplot.plot(X, Y)
pyplot.show()
'''
依次执行如下操作:
1.加载数据
2.构建模型(获得形状)
3.训练模型(获得参数)
4.预测(得到结果)
5.绘制预测曲线
6.显示损失值变化曲线
'''
def run_fx():
# 加载数据
X_train, y_train, X_test, y_test = load_data_fx()
# 构建模型(形状)
network = BPNetwork(1, 12, 1) # 增加隐含层神经元数量
# 训练模型(权重和偏置)
# learning_rate = 0.01
learning_rate = 0.005
network.train(X_train, y_train, learning_rate, 20000)
# 预测
prediction = network.predict(X_test)
print(prediction)
# 绘制预测曲线
pyplot.plot(X_train, y_train, color="red", label="True Function")
pyplot.plot(X_test, prediction, color="blue", label="Predicted Function")
pyplot.title('Nonlinear Equation Results')
pyplot.legend()
pyplot.show()
# 显示损失值变化曲线
network.show_loss()
'''
加载“异或”问题的数据,总共四种情况
0 0 -> 0
0 1 -> 1
1 0 -> 1
1 1 -> 0
'''
def load_data_yihuo():
# 创建训练数据集
X_train = numpy.array([[0, 0],
[0, 1],
[1, 0],
[1, 1]])
y_train = numpy.array([[0],
[1],
[1],
[0]])
# 创建测试数据集
X_test = numpy.array([[0, 0],
[0, 1],
[1, 0],
[1, 1]])
y_test = numpy.array([[0],
[1],
[1],
[0]])
return X_train, y_train, X_test, y_test
'''
绘制异或操作的原始图像
'''
def draw_yihuo():
#加载数据
X_train, y_train, X_test, y_test = load_data_yihuo()
y_train_flat = y_train.flatten()
pyplot.scatter(X_train[:, 0], X_train[:, 1], s=100, color='blue', edgecolors='k')
for i, (xi, yi) in enumerate(zip(X_train[:, 0], X_train[:, 1])):
pyplot.text(xi, yi, f'{y_train_flat[i]:.1f}', fontsize=12, ha='right')
pyplot.xlabel('A')
pyplot.ylabel('B')
pyplot.title('True XOR Operation')
pyplot.show()
'''
依次执行如下操作:
1.加载数据
2.构建模型(获得形状)
3.训练模型(获得参数)
4.预测(得到结果)
5.绘制预测曲线
6.显示损失值变化曲线
'''
def run_yihuo():
#加载数据
X_train, y_train, X_test, y_test = load_data_yihuo()
#构建模型(形状)
network = BPNetwork(2, 4, 1)
#训练模型(权重和偏置)
learning_ration = 0.005
network.train(X_train, y_train, learning_ration, 20000)
#预测
prediction = network.predict(X_test)
print(prediction)
# 创建一个图形和两个子图
fig, (ax1, ax2) = pyplot.subplots(1, 2, figsize=(12, 6))
# 绘制第一个子图:带有数值标签的散点图
y_train_flat = y_train.flatten()
ax1.scatter(X_train[:, 0], X_train[:, 1], s=100, color='blue', edgecolors='k')
for i, (xi, yi) in enumerate(zip(X_train[:, 0], X_train[:, 1])):
ax1.text(xi, yi, f'{y_train_flat[i]:.5f}', fontsize=12, ha='right')
ax1.set_xlabel('A')
ax1.set_ylabel('B')
ax1.set_title('True XOR Operation')
# 绘制第二个子图
prediction_flat = prediction.flatten()
ax2.scatter(X_test[:, 0], X_test[:, 1], s=100, color='red', edgecolors='k')
for i, (xi, yi) in enumerate(zip(X_test[:, 0], X_test[:, 1])):
ax2.text(xi, yi, f'{prediction_flat[i]:.5f}', fontsize=12, ha='right')
ax2.set_xlabel('X1')
ax2.set_ylabel('X2')
ax2.set_title('Predicted XOR Operation')
# 显示图形
pyplot.tight_layout()
pyplot.show()
#显示损失值变化曲线
network.show_loss()
'''
程序入口
'''
if __name__ == '__main__':
# run_fx()
run_yihuo()
# draw_fx()
# draw_yihuo()
Minst_plus.py
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Conv2D, MaxPooling2D, Flatten
'''
pip install tensorflow -i https://pypi.mirrors.ustc.edu.cn/simple/
'''
# 加载MNIST数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理
x_train = x_train.reshape(-1, 28, 28, 1).astype('float32') / 255
x_test = x_test.reshape(-1, 28, 28, 1).astype('float32') / 255
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
'''
构建模型(顺序模型,即将不同的层依次组合起来)
Dense:全连接层
Conv2D:卷积层
MaxPooling2D:池化层
Dropout:Drop层,防止过拟合
Flatten:将多维数组展平
输出层:激活函数为softmax,输出神经元个数为10(因为MNIST数据集有10个类别,0至9,输出的值分别表示10个类别的“概率”)
'''
model = Sequential([
Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1)),
MaxPooling2D(pool_size=(2, 2)),
Dropout(0.2),
Conv2D(64, kernel_size=(3, 3), activation='relu'),
MaxPooling2D(pool_size=(2, 2)),
Dropout(0.2),
Flatten(),
Dense(128, activation='relu'),
Dropout(0.2),
Dense(10, activation='softmax')
])
'''
编译模型(模型构建好后是无法直接使用的,需要设置必要的参数)
设置优化器、损失函数、评估指标
'''
model.compile(optimizer=Adam(),
loss='categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
history = model.fit(x_train, y_train, epochs=10, batch_size=128, validation_split=0.2)
# 从测试集抽取10条数据,输出其预测标签和真实标签
predictions = model.predict(x_test[:10])
print('Predictions:', np.argmax(predictions, axis=1))
print('Actual:', np.argmax(y_test[:10], axis=1))
# 绘制模型损失值的变化曲线
plt.plot(history.history['loss'], label='train_loss')
plt.plot(history.history['val_loss'], label='val_loss')
plt.title('Model Loss Progress')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend()
plt.show()
# 评估模型
score = model.evaluate(x_test, y_test, batch_size=128)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
LookMinst.py
import numpy as np
import matplotlib.pyplot as plt
# 加载MNIST数据集
file_path = r'C:\Users\Administrator\.keras\datasets\mnist.npz'
data = np.load(file_path)
# 列出文件中的数组
print(data.files)
# 提取数据
x_train = data['x_train']
y_train = data['y_train']
x_test = data['x_test']
y_test = data['y_test']
# 查看数据形状
print("训练数据形状:", x_train.shape)
print("训练标签形状:", y_train.shape)
print("测试数据形状:", x_test.shape)
print("测试标签形状:", y_test.shape)
print(y_test)
# 显示一些图像
fig, axes = plt.subplots(1, 5, figsize=(15, 3))
img_indexs = np.random.randint(0, x_train.shape[0], 5)
for i,index in zip(np.arange(0, 6),img_indexs):
axes[i].imshow(x_train[index], cmap='gray')
axes[i].set_title(f"Label: {y_train[index]}")
axes[i].axis('off')
plt.show()
LSTM_pretreat.py
import jieba
import pandas
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
'''
pip install jieba -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install pandas -i https://pypi.mirrors.ustc.edu.cn/simple/
'''
# 加载停用词表
def load_stopwords(filepath):
stopwords = set()
with open(filepath, 'r', encoding='utf-8') as file:
for line in file:
stopwords.add(line.strip())
return stopwords
# 分词并去除停用词
def preprocess_text(text, stopwords):
# 使用jieba分词
words = jieba.cut(text)
filtered_words = [word for word in words if word not in stopwords and word.strip()]
return " ".join(filtered_words)
# 读取数据文件
def read_data(filepath:str):
if filepath.endswith('.xlsx'):
data = pandas.read_excel(filepath)
return data
# 保存预处理后的数据
def save_processed_data(filepath, processed_data):
with open(filepath, 'w', encoding='utf-8') as file:
for line in processed_data:
if line != "" and line != " ":
file.write(line)
file.write("\n")
# 保存序列化后的数据
def save_sequences(filepath, sequences):
with open(filepath, 'w', encoding='utf-8') as file:
for sequence in sequences:
file.write(" ".join(map(str, sequence)))
file.write("\n")
# 停用词表文件路径
stopwords_file = 'hit_stopwords.txt'
# 加载停用词表
stopwords = load_stopwords(stopwords_file)
# 示例数据文件路径
data_file = '编码.xlsx'
# 读取数据
orign_data = read_data(data_file)
data = orign_data.iloc[:, 0].to_list()
label = orign_data.iloc[:, 1].to_list()
# 预处理数据
processed_data = [preprocess_text(line, stopwords) for line in data]
# 找到processed_data中所有为”“或者” “的索引,保存在列表indexs中
indexs = [i for i, line in enumerate(processed_data) if line == "" or line == " "]
# 删除processed_data和label中索引为indexs的元素
processed_data = [line for i, line in enumerate(processed_data) if i not in indexs]
label = [line for i, line in enumerate(label) if i not in indexs]
# 保存预处理后的数据
processed_data_file = 'data.txt'
processed_label_file = 'label.txt'
save_processed_data(processed_data_file, processed_data)
save_processed_data(processed_label_file, label)
print(f"预处理后的数据已保存")
# 构建词汇表和序列化处理
tokenizer = Tokenizer(num_words=5000)
tokenizer.fit_on_texts(processed_data)
sequences = tokenizer.texts_to_sequences(processed_data)
# 填充序列
max_sequence_length = 5 # 根据实际数据调整,左填充,根据句子中的最长单词数
padded_sequences = pad_sequences(sequences, maxlen=max_sequence_length)
# print(padded_sequences)
# 保存序列化后的数据
sequences_file = 'sequence.txt'
save_sequences(sequences_file, padded_sequences)
print(f"序列化后的数据已保存到 {sequences_file}")
LSTM
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense, Dropout, BatchNormalization, Conv1D, MaxPooling1D, Flatten
from tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as plt
'''
pip install scikit-learn -i https://pypi.mirrors.ustc.edu.cn/simple/
'''
# 加载数据
def load_data(data_path, label_path):
with open(data_path, 'r', encoding='utf-8') as file:
data = file.readlines()
with open(label_path, 'r', encoding='utf-8') as file:
labels = file.readlines()
data = [line.strip() for line in data]
labels = [line.strip() for line in labels]
return data, labels
# 数据文件路径
data_path = 'data.txt'
label_path = 'label.txt'
# 加载数据
data, labels = load_data(data_path, label_path)
# 标签编码
label_encoder = LabelEncoder()
encoded_labels = label_encoder.fit_transform(labels)
# 划分训练集和测试集,随机选择30%数据作为测试集,并使用stratify参数进行分层抽样
X_train, X_test, y_train, y_test = train_test_split(data, encoded_labels, test_size=0.3, stratify=encoded_labels, random_state=42)
# 构建词汇表和序列化处理
tokenizer = Tokenizer(num_words=5000)
tokenizer.fit_on_texts(X_train)
X_train_sequences = tokenizer.texts_to_sequences(X_train)
X_test_sequences = tokenizer.texts_to_sequences(X_test)
# 填充序列
max_sequence_length = 5
X_train_padded = pad_sequences(X_train_sequences, maxlen=max_sequence_length)
X_test_padded = pad_sequences(X_test_sequences, maxlen=max_sequence_length)
# 将标签转换为类别编码
num_classes = len(set(encoded_labels))
y_train_encoded = to_categorical(y_train, num_classes=num_classes)
y_test_encoded = to_categorical(y_test, num_classes=num_classes)
# 构建LSTM模型
def create_lstm_model(input_length, num_classes):
model = Sequential()
model.add(Embedding(input_dim=5000, output_dim=128, input_length=input_length))
model.add(LSTM(128, dropout=0.2, recurrent_dropout=0.2))
model.add(Dropout(0.2))
model.add(Dense(num_classes, activation='softmax'))
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
return model
# 创建模型
model = create_lstm_model(max_sequence_length, num_classes)
# 训练模型
history = model.fit(X_train_padded, y_train_encoded, batch_size=32, epochs=10, validation_data=(X_test_padded, y_test_encoded))
# 标签解码并打印前10个预测
y_pred = model.predict(X_test_padded)
y_pred_classes = np.argmax(y_pred, axis=1)
decoded_y_pred = label_encoder.inverse_transform(y_pred_classes)
# 打印实际标签和预测标签
print("Actual vs Predicted:")
actual_vs_predicted = list(zip(label_encoder.inverse_transform(y_test), decoded_y_pred))[:10]
for actual, predicted in actual_vs_predicted:
print(f"Actual: {actual}, Predicted: {predicted}")
# 绘制准确率和损失值的变化曲线
def plot_history(history):
plt.figure(figsize=(10, 4))
# 准确率变化曲线
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='Train')
plt.plot(history.history['val_accuracy'], label='Test')
plt.title('Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
# 损失值变化曲线
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='Train')
plt.plot(history.history['val_loss'], label='Test')
plt.title('Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.tight_layout()
plt.show()
plot_history(history)
# 评估模型性能
loss, accuracy= model.evaluate(X_test_padded, y_test_encoded)
print(f'Test Loss: {loss}')
print(f'Test Accuracy: {accuracy}')
ann_segment.py
import os
import cv2
import numpy as np
from datetime import datetime
import matplotlib.pyplot as plt
from segment_anything import sam_model_registry, SamPredictor
'''
pip install opencv-python -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install segment_anything -i https://pypi.mirrors.ustc.edu.cn/simple/
'''
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
def show_points(coords, labels, ax, marker_size=375):
pos_points = coords[labels == 1]
neg_points = coords[labels == 0]
ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white',
linewidth=1.25)
ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white',
linewidth=1.25)
def show_box(box, ax):
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0, 0, 0, 0), lw=2))
# 模型(参数)路径
sam_checkpoint = "D:\\playground\\label_anything\\sam_vit_b_01ec64.pth"
# 模型类型
model_type = "vit_b"
# 两种取值:"cpu" or "cuda"
device = "cpu"
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
# 添加必要的模型参数
sam.to(device=device)
# 调用预测模型
predictor = SamPredictor(sam)
img_dir = "D:\\resources\\cat_dataset\\images_test\\"
out_dir = "D:\\resources\\cat_dataset\\images_test_pre\\"
os.makedirs(out_dir, exist_ok=True)
# 遍历图像目录中的每张图片
for img_file in os.listdir(img_dir):
if img_file.endswith(('.png', '.jpg', '.jpeg')):
img_path = os.path.join(img_dir, img_file)
# 读取的图像以NumPy数组的形式存储在变量image中
image = cv2.imread(img_path)
print(f"{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}正在转换图片格式{img_file}......")
# 将图像从BGR颜色空间转换为RGB颜色空间,还原图片色彩(图像处理库所认同的格式)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# print("[%s]正在初始化模型参数......" % datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
# 调用`SamPredictor.set_image`来处理图像以产生一个图像嵌入。`SamPredictor`会记住这个嵌入,并将其用于随后的掩码预测
predictor.set_image(image)
# --------------------------------------单点输入--------------------------------------
# print("【单点分割阶段】")
print("[%s]正在分割图片......" % datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
# 单点位置 prompt 输入格式为(x, y)和并表示出点所带有的标签1(前景点)或0(背景点)。
input_point = np.array([[image.shape[1]/2, image.shape[0]/2]])
# input_point = np.array([[1500, 2000]])
# 点所对应的标签(前景)
input_label = np.array([1])
# 显示原始图像
# plt.figure(figsize=(10, 10))
# plt.imshow(image)
# show_points(input_point, input_label, plt.gca())
# plt.axis('on')
# plt.show()
masks, scores, logit = predictor.predict(
point_coords=input_point,
point_labels=input_label,
# 为False时,它将返回一个掩码,否则返回三个
multimask_output=True,
)
# print(masks.shape) # (3, 2160, 3840)波段,高,宽
'''
显示所有置信度的图像
'''
# for i, (mask, score) in enumerate(zip(masks, scores)):
# # 三个置信度不同的图
# plt.figure(figsize=(10, 10))
# plt.imshow(image)
# show_mask(mask, plt.gca())
# show_points(input_point, input_label, plt.gca())
# plt.title(f"Mask {i + 1}, Score: {score:.3f}", fontsize=18)
# plt.axis('off')
# plt.show()
'''
仅显示置信度最高的图像
'''
# 找到置信度最高的图像索引
max_score_index = np.argmax(scores)
plt.figure(figsize=(10, 10))
plt.imshow(image)
show_mask(masks[max_score_index], plt.gca())
# show_points(input_point, input_label, plt.gca())
plt.title(f"Score: {scores[max_score_index]:.3f}", fontsize=18)
plt.axis('off')
# 保存图像文件
plt.savefig(os.path.join(out_dir,img_file))
# plt.show()