众所周知,现在训练AI最需要的是什么?
数据,数据,还是数据。——毕竟只有让AI学好了,AI才能好好地回答你的问题,否则就会答非所问。
但是喂给AI的数据,现在和GPU一样,成了紧缺资源。前不久有人试图用AI自己造的数据来喂AI,结果发现这样的话AI越学越笨,最后连他亲妈来了都不忍直视的那种。
不过,最近来了个天大的好消息——MINT-1T来了!
MINT-1T是一个包含一万亿token的多模态预训练数据集,它是史上最大的同类数据集,并且比以前的开源数据集更加多样化。
把开源多模态数据集的规模扩展了10倍,达到万亿token!
数据集来源于HTML、PDF和ArXiv论文等不同源,都是精挑细选的好货,妈妈再也不用担心我的AI吃不饱了!

论文标题:
MINT-1T: Scaling Open-Source Multimodal Data by 10x: A Multimodal Dataset with One Trillion Tokens
论文链接:
https://arxiv.org/abs/2406.11271
GitHub链接:
https://github.com/mlfoundations/MINT-1T

MINT-1T有多大?扩了10倍
大规模开源预训练数据集对开发透明的开源模型至关重要。大型多模态模型(MLM)是未来的研究趋势,这需要海量的多模态数据。
然而,现有的开源多模态数据集在规模和多样性上远逊于纯文本数据集,限制了模型的学习广度。这一局限无疑阻碍了开源LMM的发展,导致开源与闭源模型之间出现了能力差距。
MINT-1T 包含总共 1 万亿个token和 34亿张图像,来自 HTML、PDF 和 ArXiv 等不同来源。在 MINT-1T 之前,该领域最大的开源数据集是 OBELICS,其中包括 1150 亿个文本标记和 3.53 亿张图像,全部来自 HTML。
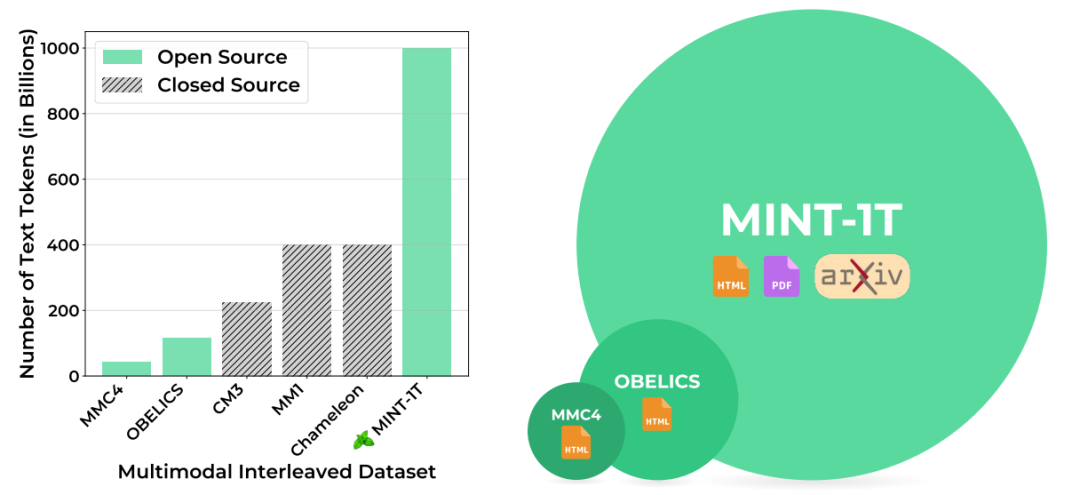
▲MINT-1T和其它数据集大小的比较
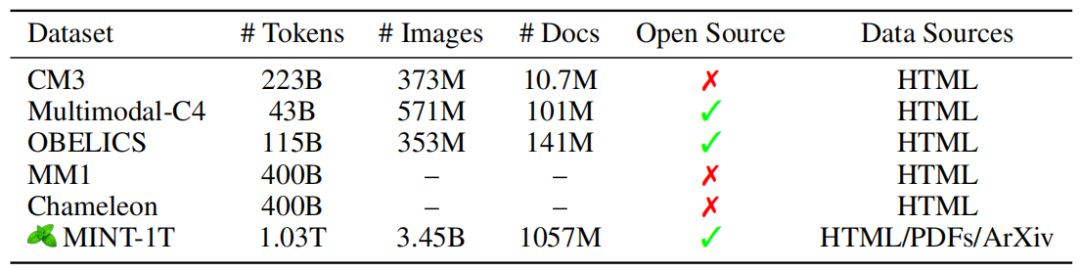
▲MINT-1T和其它数据集多方面的比较
MINT-1T是如何诞生的?
MINT-1T的构建涉及多个步骤。
1.数据源收集
-
HTML文档:通过解析CommonCrawl的WARC文件中的DOM树来获取,获取文档的时间范围是2017年5月到2024年4月,比之前的OBELICS项目覆盖的时间更长。接着排除掉无图、图像过多以及其他不适合的文档。
-
PDF文档:从 2023 年 2 月到 2024 年 4 月的 CommonCrawl WAT 文件中获取。最初,所有 PDF 链接都是从这里提取的;然后研究团队尝试使用 PyMuPDF 下载和读取 PDF,剔除掉过大文件和没有文本的页面,并为其余页面标注阅读顺序,便于AI阅读。
-
ArXiv文档:团队使用 TexSoup 从 LaTeX 源代码入手来取得,对于多文件论文则识别主 Tex 文件,并且通过删改LaTeX 代码实现对论文中导入、参考文献、表格等“无关紧要”的数据的清理。
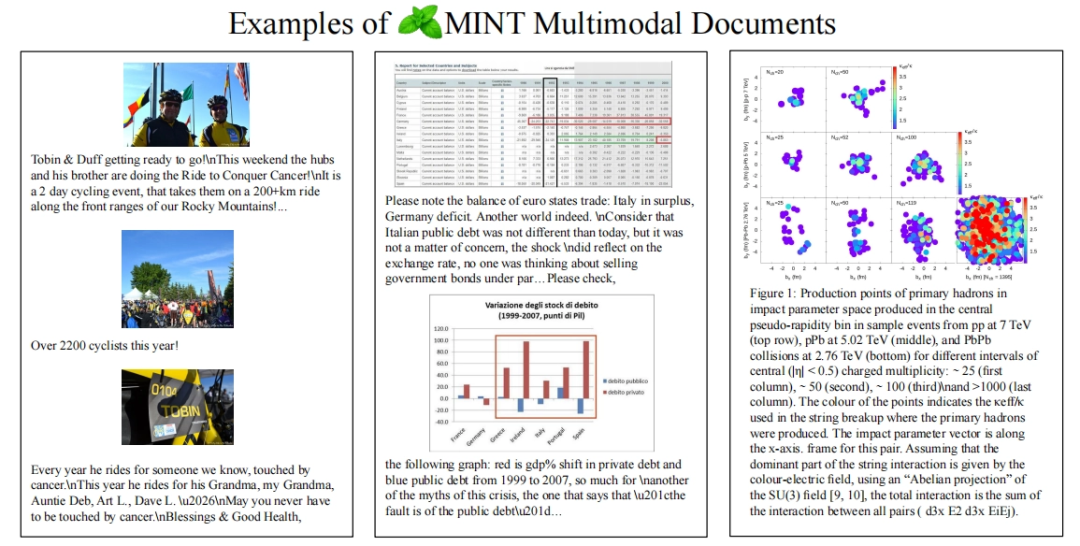
▲MINT-1T的数据来源示例
2.数据过滤
-
文本数据过滤:团队最初使用Fasttext的语言识别模型(置信度阈值为 0.65)过滤掉非英语文档,还利用URL字符串检索删除不良信息。此外,还应用RefinedWeb中的文本过滤方法,专门删除具有过多重复n-gram的文档和低质量的文档。
-
图像数据过滤:在整理PDF和HTML文件后,MINT-1T尝试下载HTML数据集中的所有图像 URL,删除不可检索的链接、没有有效图像链接的文档、小于 150 像素的图像(避免徽标等无关内容)、大于 20,000 像素的图像、宽高比过于失衡的图像。值得注意的是,HTML文档中的图像要求在2:1之内(删掉广告),而PDF放宽到3:1之内,此举做法是避免一些论文中的图片被误删。
-
安全数据过滤:MINT-1T将NSFW图像检测器应用于数据集中的所有图像。如果文档包含单个 NSFW 图像,则整个文档将被删除。此外,为降低个人数据泄露的风险,文本数据中的电子邮件地址和 IP 地址将使用化名代替。
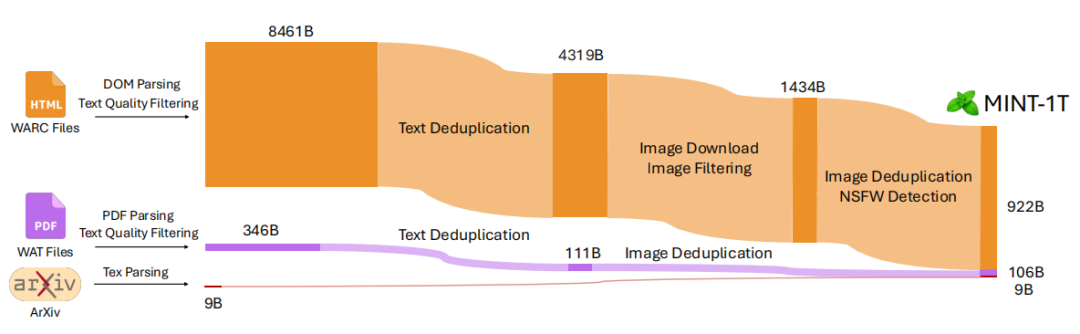
▲MINT-1T的过滤过程
3.数据去重
团队采用了多种方法进行数据去重。首先执行了段落和文档级别的去重,以消除重复的内容。接着移除了常见的模板文本,减少了无用的重复信息。此外团队还进行了图像去重,确保每个图像是独一无二的。
4.数据处理
利用大约2350个CPU内核和大量的计算资源来处理数据,整个过程大约消耗了42百万CPU小时。
在经过了如上过程之后,热乎乎的数据集就被端上来供大家品鉴了!
MINT-1T数据的多样性
MINT-1T数据集的多样性主要体现在其来源广泛。不仅包括HTML数据源,还首次纳入了PDF和ArXiv文档。
PDF文件通常包含学术文章、技术报告、书籍等内容,这些内容的加入显著增加了数据集的学术性和专业性;MINT-1T通过解析ArXiv论文,获取了大量的科学图像和文本数据。这些数据的加入,使得数据集在科学领域的应用更加广泛和深入。与仅基于HTML的OBELICS数据集相比,MINT-1T提供了10倍的数据规模增长,进一步增强了模型的泛化能力。
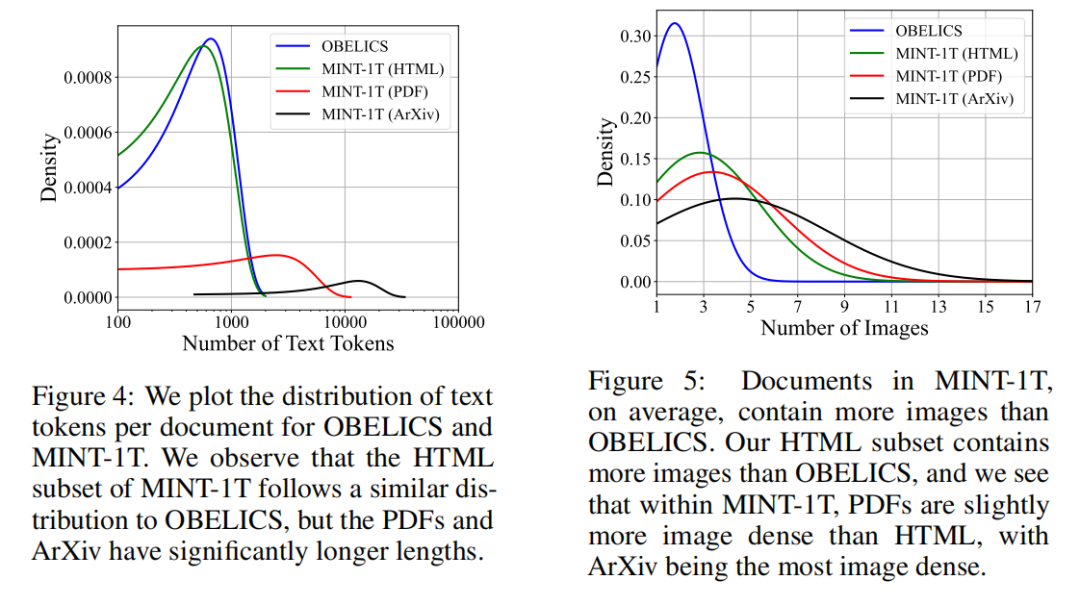
▲MINT-1T和OBELICS的多样性比较
此外,MINT-1T包含了一万亿个文本标记,这些文本数据来自不同的来源和领域,涵盖了各种语言风格、主题和内容。数据集还包含了三十四亿张图像,这些图像与文本数据紧密交织,形成了多模态的数据结构。图像数据的加入,使得数据集在视觉理解和生成任务中更具优势。
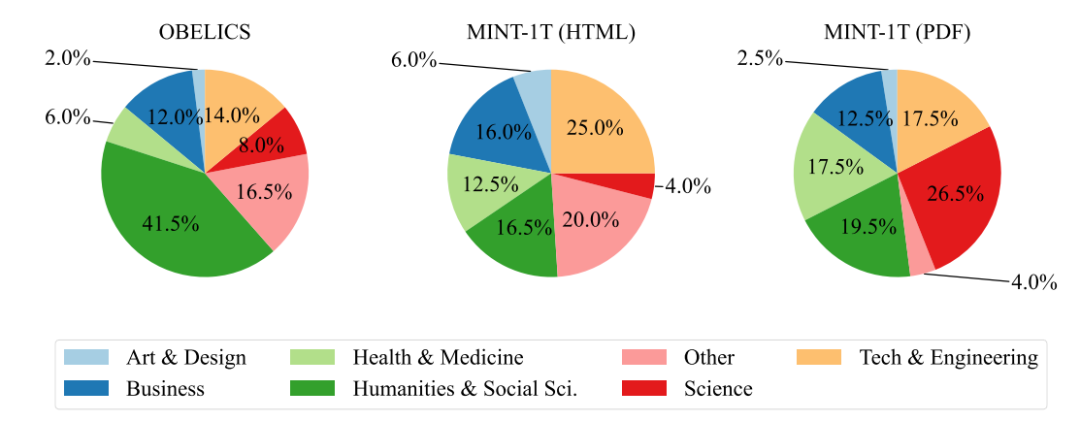
▲MINT-1T的内容分布
MINT-1T有多强?来跑跑看
都说“是骡子是马拉出来遛遛”,光说不练假把式,终于到了大家喜闻乐见的正面对狙,啊不,评估环节。
团队通过测试在该数据集上训练的多模态模型(LMMs)的性能来评估MINT-1T的水准,并将其与在先前领先的数据集(如OBELICS)上训练的模型进行比较。
-
上下文学习:在各种字幕基准和视觉问答数据集上,对模型进行上下文学习性能评估。
-
多图像推理:在MMMU(包含单图像和多图像问题)和Mantis-Eval(所有多图像问题)上评估模型,以探索上下文学习评估之外的多图像推理能力。
团队先将MINT-1T的HTML部分与OBELICS进行了比较(因为OBELICS也是从HTML文档中精选出来的)。在MINT-1T(HTML)文档上训练的模型在VQA任务上的表现优于OBELICS,但在字幕基准上表现更差。平均而言,OBELICS的性能略好于MINT-1T(HTML)。
随后,团队使用MINT-1T的完整数据进行训练,50%的数据来自HTML,45%来自PDF,5%来自ArXiv。在完整的MINT-1T数据混合上训练的模型在大多数上下文学习基准上优于 OBELICS 和 MINT-1T(HTML)。在更复杂的多模态推理基准测试中,MINT-1T模型在MMMU上优于 OBELICS,但在Mantis-Eval上表现较差。
在字幕和视觉测试中,OBELICS在四镜头字幕基准上表现优于所有MINT-1T变体,但是在八镜头字幕上表现上,MINT-1T更胜一筹。
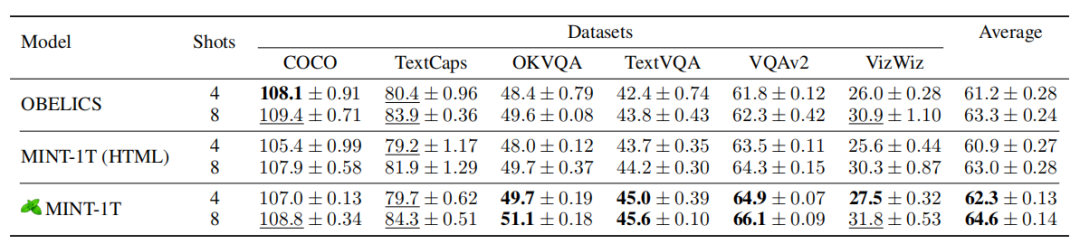
▲上下文学习测试结果
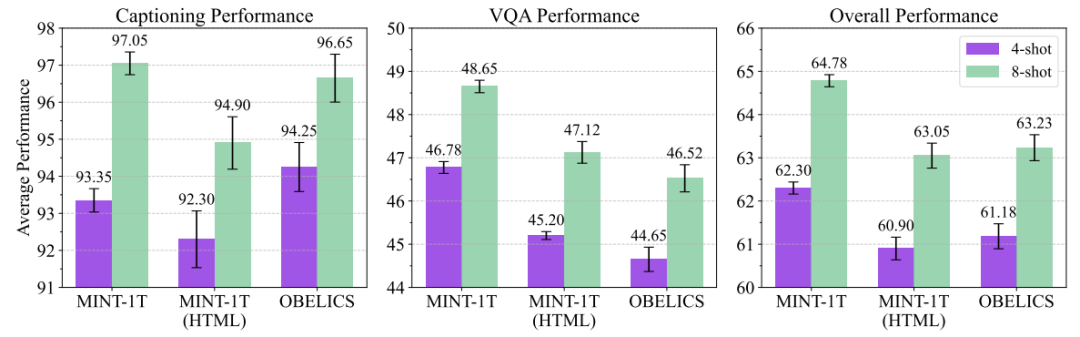
▲字幕和视觉问题回答(VQA)任务的表现
测试表明,使用MINT-1T训练的模型在文本和多模态基准测试中表现优异,同时提供了10倍的数据规模提升,验证了MINT-1T在大规模多模态预训练中的有效性,大家放心大胆用就完了!
题外话:薄荷
英语单词MINT有一个意思是薄荷。如果你玩过《植物大战僵尸2》,你就会知道里面有一类特殊的植物——薄荷。植物根据其特性分为十四个家族,每个家族对应一种薄荷,当薄荷上场的时候会短暂增强场上所有该家族植物的能力。

▲《植物大战僵尸2》的薄荷们。来源:微信公众“一号砚”
笔者希望这个数据集也和“神奇薄荷”一样,为AI的发展注入新的强劲动力!




















