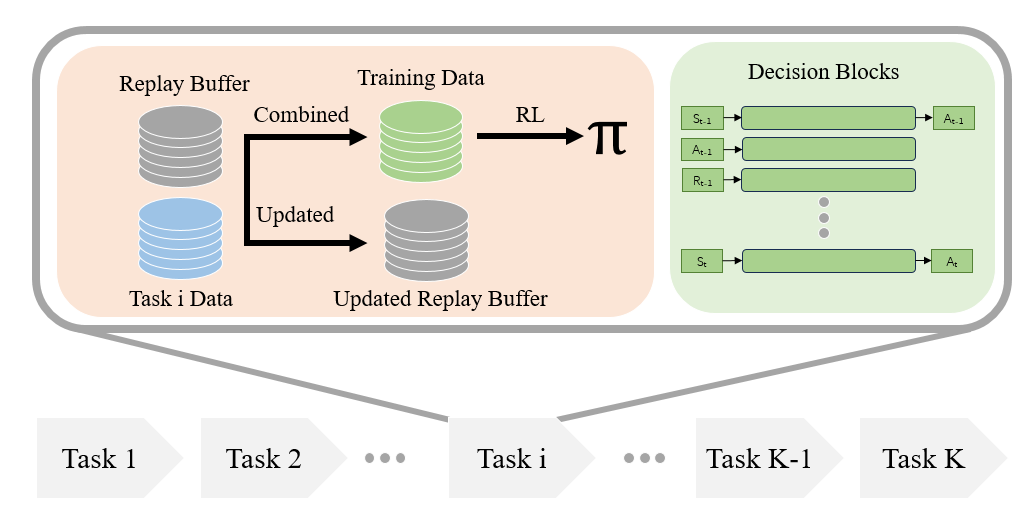
目录
主从复制
主从复制的流程
部署主从复制
步骤
哨兵模式
数据流向
步骤
故障恢复
cluster集群
数据流向
步骤
redis集群的三种模式:
主从复制 奇数台 1主2从
哨兵模式 奇数台 1主2从
cluster 集群 6 台
主从复制
原理:主可以写,写入主的数据通过RDB方式把数据同步到从服务器,从不能更新到主。
它也是哨兵模式的基础。
缺点:它没有办法实现故障自动化恢复。只有主能够写,主从复制完成之后,从服务器变成只读模式。数据的复制是单向的,由主复制到从
主从复制的流程

部署主从复制
192.168.233.61 主
192.168.233.62 从
192.168.233.63 从
步骤
1.安装ntpdate(主从都要安装)
yum -y install ntpdate -y
然后查看时间是否一致

2.主配置文件
vim /etc/redis/6379.conf


3.从配置文件
vim /etc/redis/6379.conf

连接主的ip地址
4.主从重启服务 /etc/init.d/redis_6379 restart
哨兵模式
实现故障自动化恢复
故障切换时,主故障,变成从服务器,主变成从之后,也会进入只读模式
缺点:从节点一旦故障,读会受到影响
原理:互相监控,主备切换
数据流向

步骤
1.主从三台服务器同步操作
cd /opt/redis-5.0.7/
vim sentinel.conf





这里要改为主的IP地址
sentinel monitor mymaster 192.168.233.61 6379 2
初始化监听,都是监听主服务器的状态
2 对应的就是从服务器的数量以及投票的参与者 参与者要和从服务器的数量一致
2台服务器投票通过,主才能进行故障转移
理解不需要修改

判断服务器宕机的时间周期 30秒 每30秒检测一次

判断故障节点的超时的最大时间 180秒
2.启动(要先启动主再启动从)
先启动主再启动两个从(必须要在redis-5.0.7目录下启动)
启动命令:redis-sentinel sentinel.conf &
查询命令:redis-cli -p 26379 info sentinel
这样即为成功
故障恢复
查看日志的文件 tail -f /var/log/sentinel.log
/etc/init.d/redis_6379 stop
结果63就变成主了

注意:如果原来的主重新启动,也不会再变成主,现在的主依然还是63,需要重新投票再选举主
cluster集群
集群是redis3.0之后的分布式存储方案。它由多个节点组成,redis数据保存在这些节点。
把每两台服务器作为主从模式,形成一个大的主从的集群。
集群中的节点分为主和从。主节点主责读写以及维护集群的信息,从节点进行主节点数据的复制。
它解决了写操作的负载均衡。它是一个较为完善的高可用方案。它保证了高可用,但对数据的完整性要求不高。集群的功能只是满足了高可用和写的负载均衡,不能保证数据的完整性。
redis集群的数据分片:在集群概念中,引用的是hash槽的概念,创建了集群就有16384个hash槽
分为3个节点:
主1 0-5460
主2 5461-10922
主2 10923-16383
节点当中,如果主和从全部失败,整个集群都将不可用
数据流向

步骤
1.安装ntpdate(主从都要安装)
yum -y install ntpdate -y
然后查看时间是否一致
2.6台机器同步操作
vim /etc/redis/6379.conf



3.输入命令
redis-cli -h 192.168.233.61 --cluster create 192.168.233.61:6379 192.168.233.10:6379 192.168.233.62:6379 192.168.233.20:6379 192.168.233.63:6379 192.168.233.30:6379 --cluster-replicas 1
redis-cli -h 192.168.233.61 集群的主连接节点 配置节点
--cluster-replicas 1 表示每个主只有一个节点
然后输入yes 最后显示16384即为配置成功

CLUSTER SLOTS 查看集群节点

CLUSTER NODES 查看主从
注释:moved不是报错,只是系统提示客户端到指定位置的hash槽进行读写。系统提示什么,你就去哪个节点操作即可,这个节点是该节点的主。