路径优化系列文章:
- 1、路径优化历史文章
- 2、路径优化丨带时间窗和载重约束的CVRPTW问题-改进遗传算法:算例RC108
- 3、路径优化丨带时间窗和载重约束的CVRPTW问题-改进和声搜索算法:算例RC108
- 4、路径优化丨复现论文-网约拼车出行的乘客车辆匹配及路径优化
- 5、多车场路径优化丨遗传算法求解MDCVRP问题
- 6、论文复现详解丨多车场路径优化问题:粒子群+模拟退火算法求解
- 7、路径优化丨复现论文外卖路径优化GA求解VRPTW
- 8、多车场路径优化丨蚁群算法求解MDCVRP问题
- 9、路径优化丨复现论文多车场带货物权重车辆路径问题:改进邻域搜索算法
- 10、多车场多车型路径问题求解复现丨改进猫群算法求解
- 11、带时间窗车辆路径问题论文复现:改进粒子群算法求解
- 12、物流中心选址问题论文复现丨改进蜘蛛猴算法求解
- 13、论文复现丨带时间窗和服务顺序的多车辆路径问题:联合优化遗传算法
问题描述
某区域内有1个配送中心(配送中心集合记为J = {0}),分别用m种车型为n个顾客(顾客集合记为 I = {1, 2*, . . . , n})提供m种不同类型的服务(服务需求类型集合记为K* = {1, 2*,* · · · , m}),每种类型的车辆只能提供单一类型的服务,假设:
(1)各种类型的车辆均从配送中心出发,完成任务后仍回到原配送中心;
(2)每个顾客的一种需求只需要被同类型车辆服务一次;
(3)每条路径上的顾客总需求量不能超过车辆的最大服务能力;
(4)每辆车的总行驶时间不能超过规定的最长行驶时间;
(5)每个顾客的第1种需求对应的时间窗为软时间窗,服务车辆早到或晚到会产生等待或惩罚费用;
(6)具有多种服务需求的顾客,其各类需求的服务顺序为1*,* 2*,* · · · , m,即同一顾客的第k类服务完成时间必须早于第k + 1类服务的开始时间,且时间间隔不能超过最大允许时间间隔SLk(服务水平。
简单来说:客户点有多个服务需求,两个服务时间点差距必须在一定范围内,其余同一般车辆路径问题一样。文献的客户点有配送需求,安装需求(部分点)。
数学模型
文献的模型:

第一部分是车辆固定成本,第二部是行驶成本,第三部分是时间窗成本。
数据:
包含参考文献参考数据和rc101到rc108成本:
文献参考数据
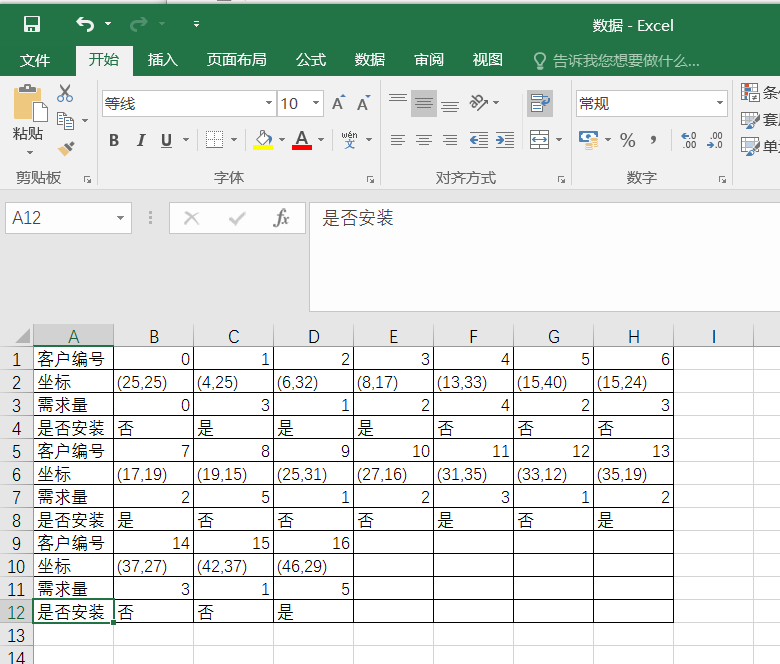
rc数据:
其中论文参考数据没有时间窗(可以自行设计),解码时不计算,rc数据无安装点,按照文献任意生成40个。
代码运行环境
windows系统,python3.6.0,第三方库及版本号如下:
numpy==1.18.5
matplotlib==3.2.1
第三方库需要在安装完python之后,额外安装,以前文章有讲述过安装第三方库的解决办法,点击下方文章名字跳转:
-
1、代码运行环境说明
-
2、第三方库安装方法
编码解码
1、编码
随机打乱配送点和安装点即可得到配送路径编码和安装路径编码。
2、配送路径解码
依次遍历配送路径,载重约束下车辆尽可能服务更多点:
step1:初始只有一辆车,载重为0,遍历路径第一个点,更新载重,更新车辆路径;
step2:不断遍历路径的点,更新载重和车辆路径,遍历到某点不满足载重时转入step3;,否则遍历完所有点结束;
step3:新加入车辆,载重更新为该点的需求量,新车辆路径加入该点。
核心代码如下:
while road: # 当路径还有点未分配给车
DE_idx.append(road[0]) # 每次车辆路径加入路径第一个点
if sum(np.array(self.DE)[DE_idx])<=self.load:
road.pop(0) # 如果满足载重约束,删除路径第一个点
else:
road_car.append(DE_idx[:-1]) # 如果不满足,截取上一个车辆路径
DE_idx = [] # 新车辆路径从空开始
road_car.append(DE_idx) # 循环完成添加最后一辆车辆路径
得到各车辆的路径后,计算成本比较容易,路径数就是车辆数,任意2点距离除速度得到时间,累积时间就可以判断是否违反时间窗:
def caculate(self,road_car,signal):
t_arrive = []
t_a = [0 for w in self.AZ] # 初始安装点的配送时间为0
z = len(road_car)
for rc in road_car: # 每辆车的路径
t = 0
beg_ = 0 # 从中心0开始
for r in rc + [0]: # 最后回到中心0
dis = np.sqrt((self.XY[r][0] - self.XY[beg_][0])**2 + (self.XY[r][1] - self.XY[beg_][1])**2)
t += dis/self.v # 计算到达时间
if r in self.AZ: # 如果点属于安装路径
idx = self.AZ.index(r) # 找到对应点在安装路径编码的位置
t_a[idx] = t # 更新安装点到达时间
t_arrive.append(t) # 更新每个点到达时间(包括回到中心点)
beg_ = r
w = self.gk*z + self.ck*sum(t_arrive) # 计算不包含时间窗的成本
if self.WD and signal: # 如果时间窗存在且需要计算(安装路径时不需要)
c = 0
u = 0
for rc in road_car: # 路径成本
for r in rc + [0]:
win_left = self.WD[r][0] # 左时间窗
win_right = self.WD[r][1] # 右时间窗
if t_arrive[c] < win_left: # 时间窗成本计算,下同
u += 2*(win_left-t_arrive[c])
if t_arrive[c] > win_right:
u += 2*(t_arrive[c] - win_right)
c += 0
w += u # 成本更新
return w,t_a
当有时间窗数据且需要计算才会计算时间窗成本(安装点路径不需要计算) ,t_a是为了下面的安装路径解码。
3、安装路径解码
依次遍历安装路径,安装路径的点必须和配送时间点在一定范围内(2种情况:早于安装时间;晚于配送时间时间时在允许范围内到达),否则该点加入新车:
step1:初始只有一辆车,载重为0,遍历安装路径第一个点,更新时间(安装车到达时间和配送车到达时间的最大值),更新车辆路径;
step2:不断遍历路径的点,更新时间和车辆路径,遍历到某点时间不满足间隔约束时转入step3;,否则遍历完所有点结束;
step3:新加入车辆,时间更新为中心到该点的时间,新车辆路径加入该点。
核心代码:
for i in range(len(road_car)): # 遍历目前的安装车
if i==0: # 初始从配送中心出发
beg_ = 0
else:
beg_ = road_car[i][-1] # 否则从某辆车的最后一个点出发
dis = np.sqrt((self.XY[r][0] - self.XY[beg_][0])**2 + (self.XY[r][1] - self.XY[beg_][1])**2)
t = dis/self.v + ta[i] # 计算到达时间
if t - t_arrive <= self.slk: # 如果到达时间在可接受范围
road_car[i].append(r) # 车辆加入该点
ta[i] = max(t, t_arrive) # 更新该点的完工时间(安装到达时间和配送时间最大值)
signal = 1
break
if signal == 0: # 如果所有车都没加入点
beg_ = 0
dis = np.sqrt((self.XY[r][0] - self.XY[beg_][0])**2 + (self.XY[r][1] - self.XY[beg_][1])**2)
road_car.append([]) # 添加新车
t = dis/self.v
ta.append(max(t, t_arrive)) # 更新该点的完工时间
road_car[-1].append(r) # 新车路径加入点
成本计算同上。
算法改进
1、算法步骤
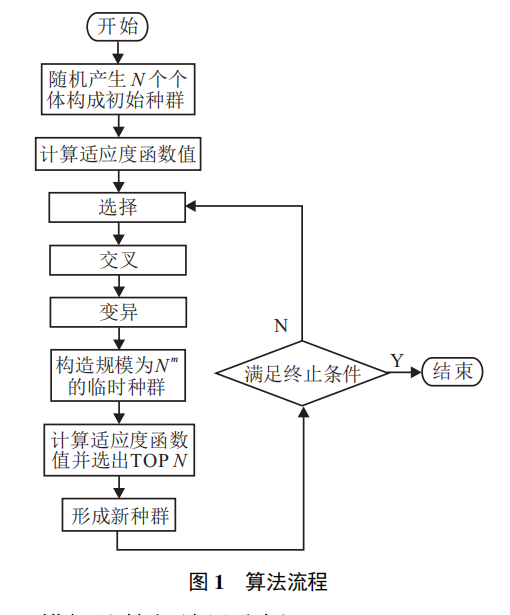
轮盘赌选择,概念可以自行查阅,用np.random.choice实现:
def select(self,pop,pop1,fit): # 轮盘赌选择
fit=np.array(fit)
idx=np.random.choice(np.arange(self.pop_size),size=self.pop_size,replace=True,
p=fit/fit.sum())
return pop[idx],pop1[idx]
idx是轮盘赌选择得到的索引,因为文献存在配送路径和安装路径,返回2个种群。
次序交叉:

任意生成2点,固定2点之间的基因和位置,处理其余冲突基因再重新拼接。
如B处理冲突的1,4,3剩余[2,7,5,6,8],[1,4,3]左拼接[2,7],右拼接[5,6,8]得到子代A,子代B同理。
代码:
def crosss(self, a, b): # 次序交叉
loc = random.sample(range(len(a)), 2) # 生成2个位置
loc.sort() # 升序
id1, id2 = loc[0],loc[1] # 取对应位置点
change_a = a[id1:id2] # 截取交换位置
change_b = b[id1:id2] # 截取交换位置
for ca in change_a: # 父代b移除a交换的对应基因
b.remove(ca)
a1 = b[:id1] + change_a + b[id1:] # b剩余基因和交换基因得到子代a1
for cb in change_b: # 父代a移除b交换的对应基因
a.remove(cb)
b1 = a[:id1] + change_b + a[id1:] # a剩余基因和交换基因得到子代b1
return a1, b1
变异是交换一个编码任意2个位置的基因:
def mul(self,a):
loc = random.sample(range(len(a)), 2) # 生成2个位置
a[loc[0]], a[loc[1]] = a[loc[1]], a[loc[0]] # 对应基因交换
return a
保留top N个体,比较容易,每次迭代合并父代和子代,保留最优秀的前N个个体:
核心代码:
T_r, T_rz =np.vstack((T_road,T_road1)),np.vstack((T_road_az,T_road_az1)) # 合并父代子代路径
ans = answer + answer1 # 合并父代子代目标
index_sort=np.array(ans).argsort() # 目标最小到大的索引
T_road, T_road_az = T_r[index_sort][0:self.pop_size], T_rz[index_sort][0:self.pop_size] # top N个体
answer = np.array(ans)[index_sort][0:self.pop_size].tolist() # 对应目标
运行结果
主函数
设计主函数如下:
import data
import numpy as np
from decode import de
import random
from ga_combine import ga_c
data_ = 'RC101' # 可选择101到108,运行rc数据时记得屏蔽data_ = 0
data_ = 0 # 运行论文数据
if data_:
XY, DE, WD = data.read_rc(data_)
AZ = random.sample(range(1, len(DE)), 40) # 生成40个安装点
else:
XY, DE, AZ = data.read()
gk = 20 # 单个车辆固定费用
ck = 1 # 单位距离运行成本
v = 1 # 车辆速度
if data_: # rc系列数据时
load = 1000 # 载重
slk = 300 # 允许安装时间和配送时间间隔
else:
load = 15 # 载重
slk = 40 # 允许安装时间和配送时间间隔
WD = [] # 论文数据没时间窗,可自行设计
generation, popsize, cr, mu = 20, 40, 1, 1 # 迭代次数,种群规模,交叉概率,变异概率
d = de(gk, ck, v, load, XY, DE, AZ,slk,WD) # 解码方法
gc = ga_c(generation, popsize, cr, mu, d) # 遗传方法
road, road_z, result = gc.total(len(DE)-1, len(AZ)) # 算法结果
road,road_car = d.creat(road)
w1,t_a = d.caculate(road_car,1)
road_car_az = d.caculate_az(road_z,t_a)
w2,t_a = d.caculate(road_car_az ,[])
print('\n配送编码:',road)
print('车辆配送路径:',road_car)
print('\n安装编码',road_z)
print('车辆安装编码:',road_car_az)
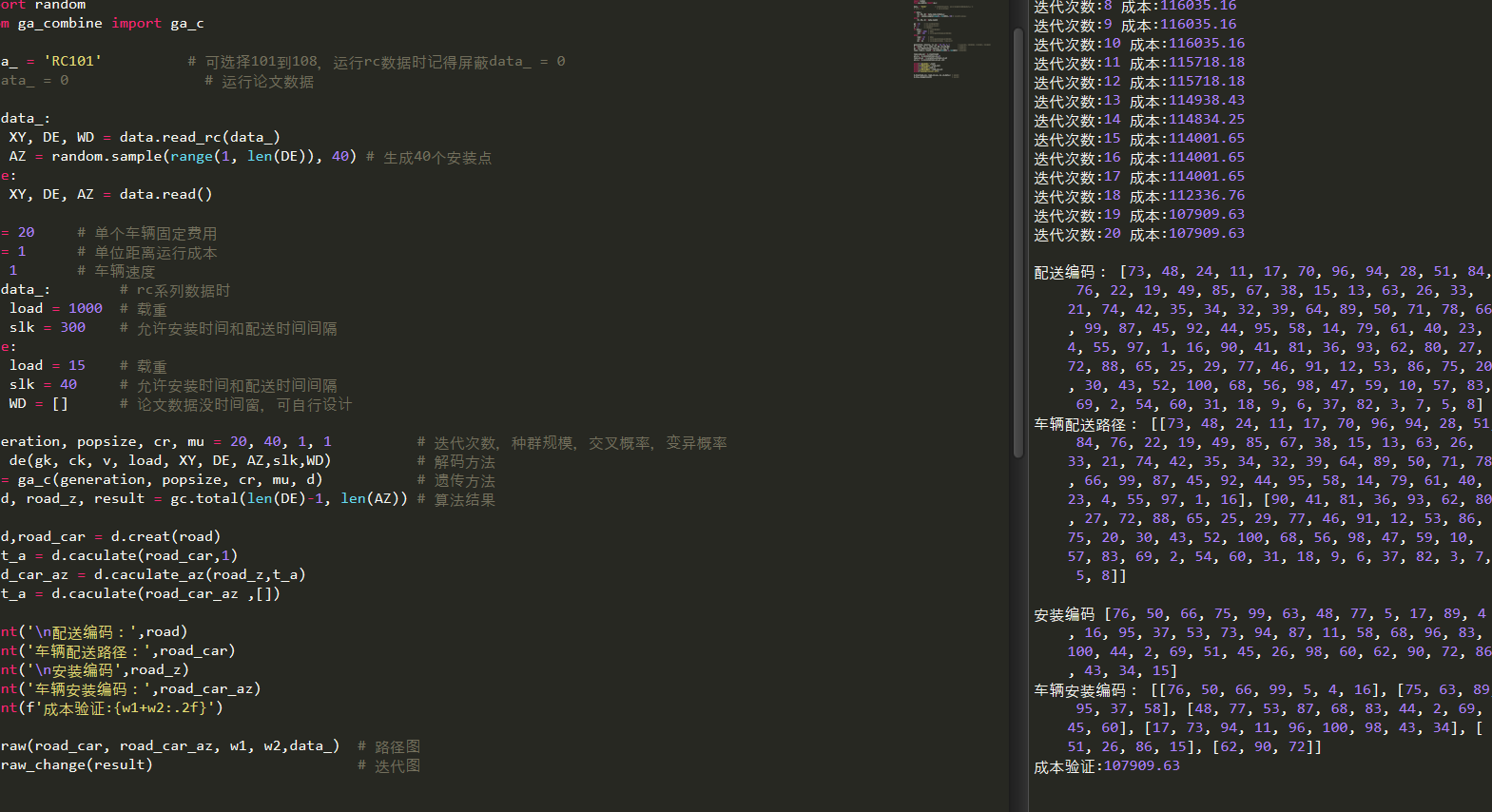
print(f'成本验证:{w1+w2:.2f}')
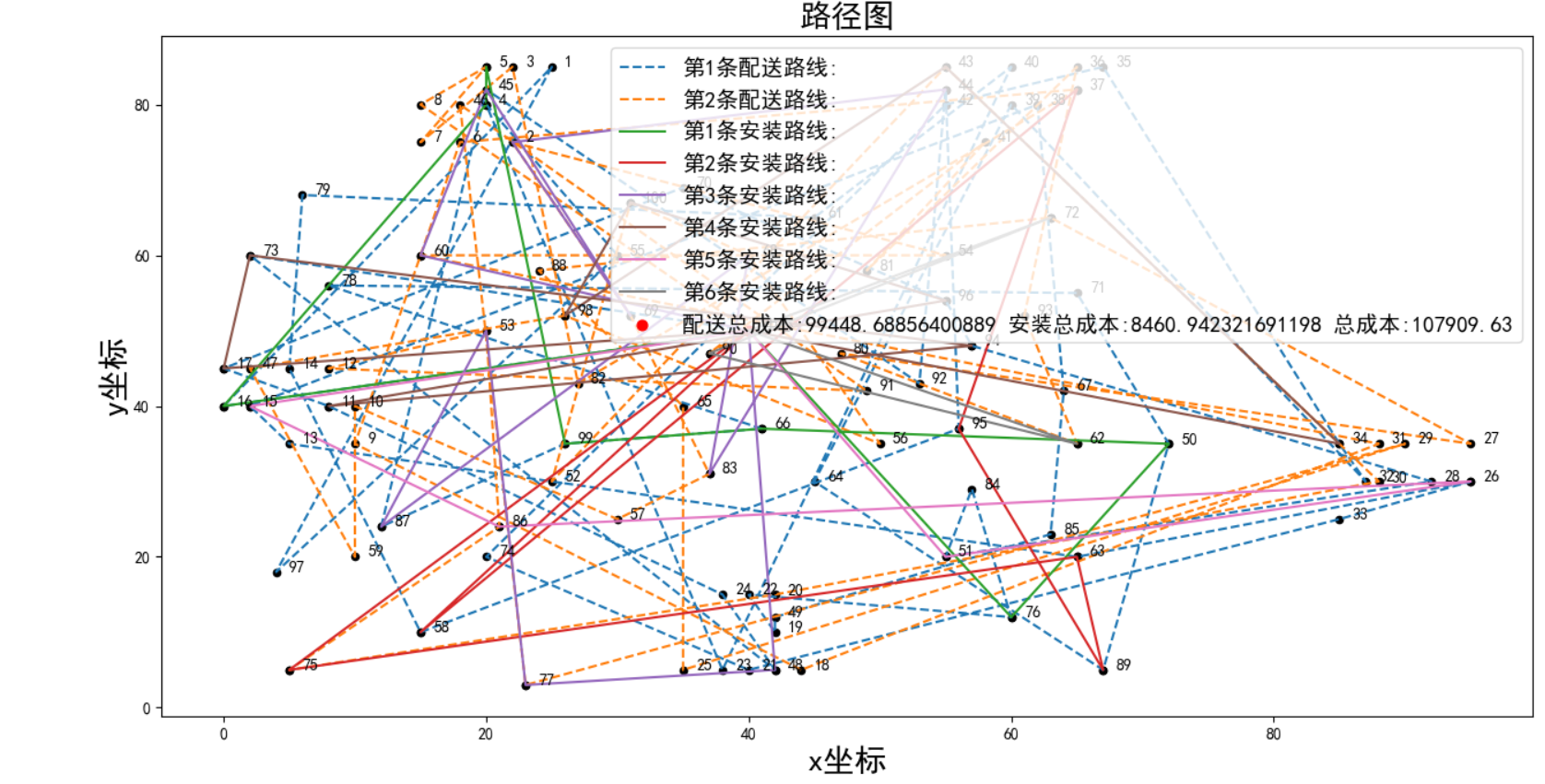
d.draw(road_car, road_car_az, w1, w2,data_) # 路径图
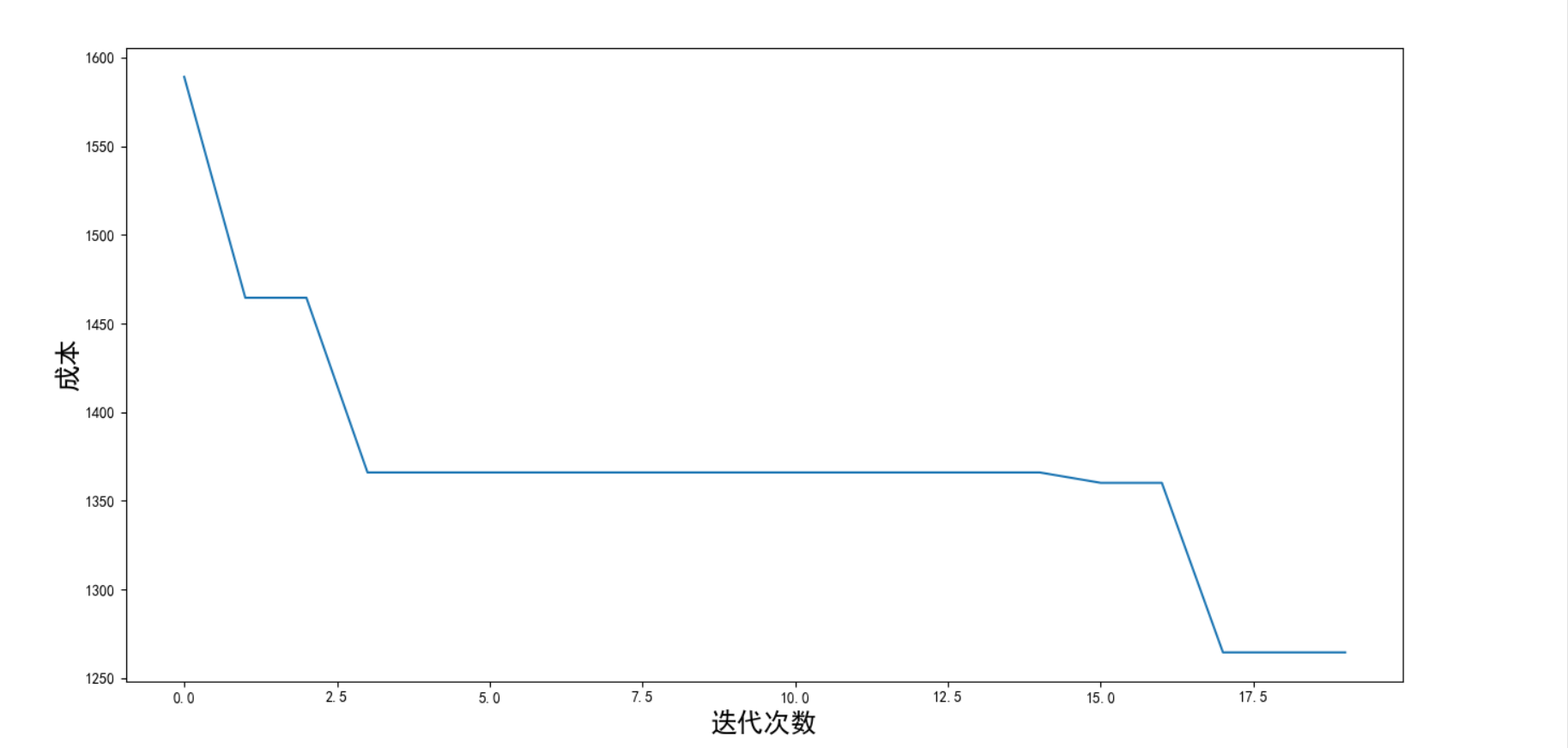
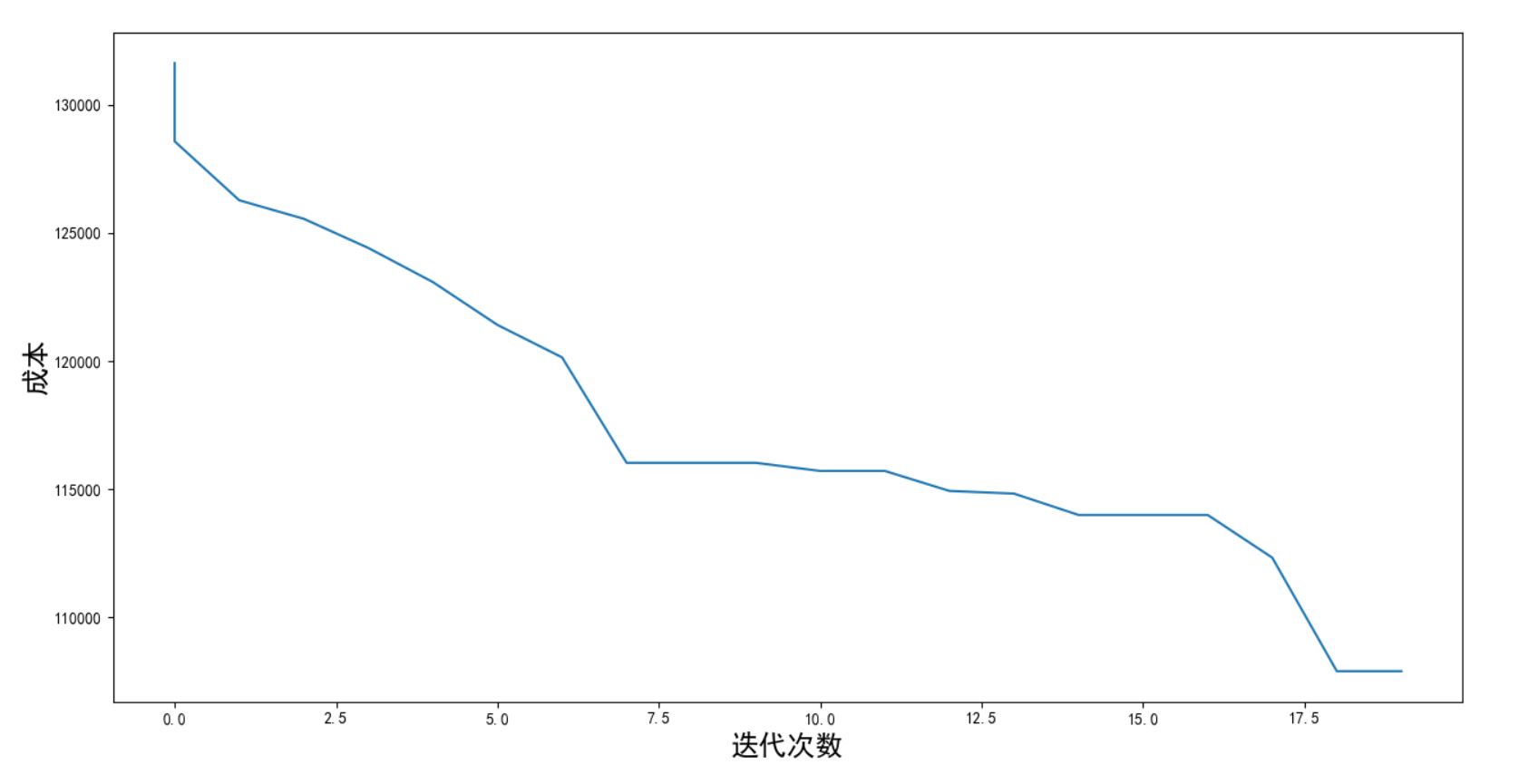
d.draw_change(result) # 迭代图
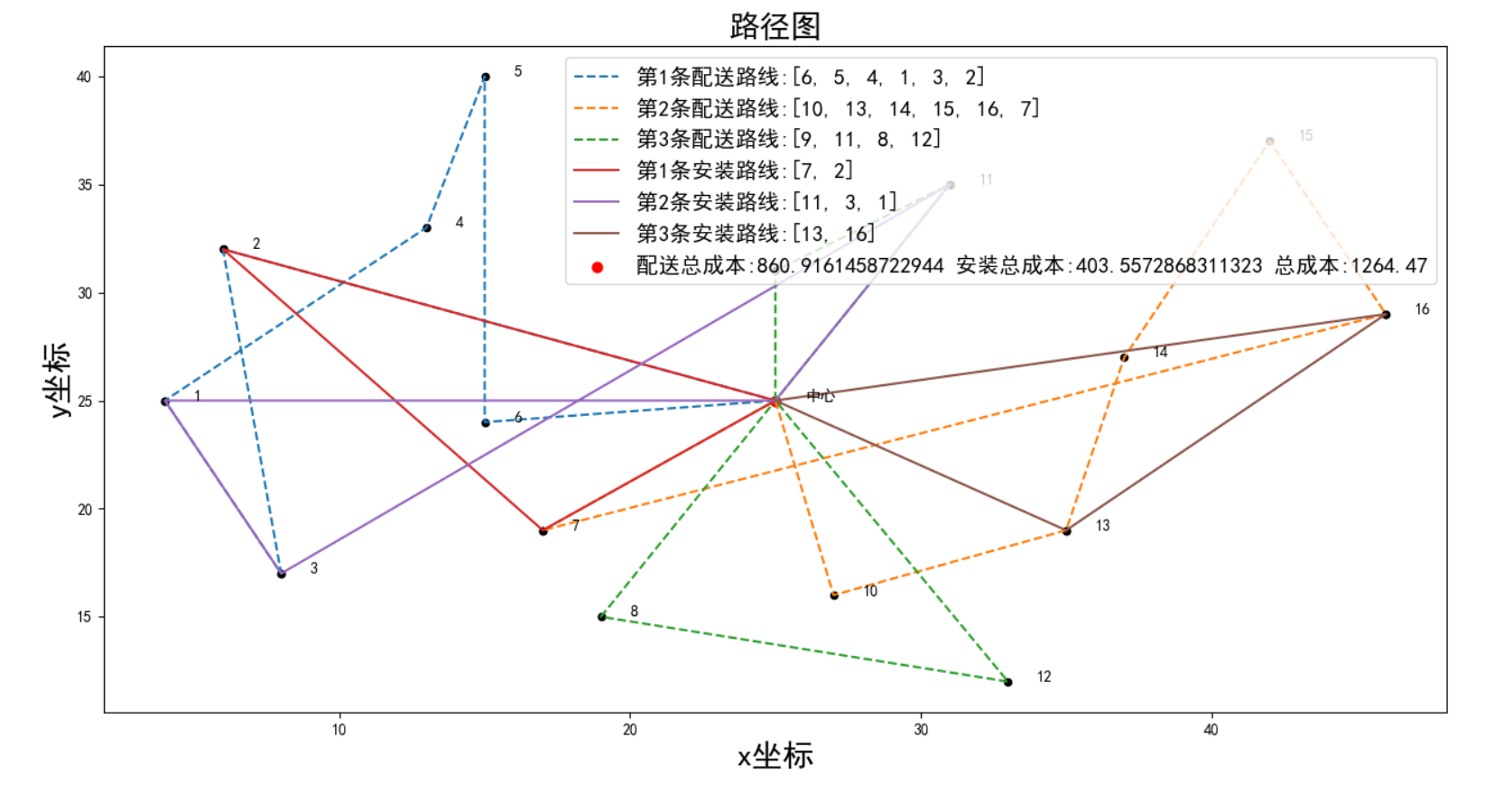
运行结果
论文数据20次结果:

路径图
迭代图
rc101数据20次结果
路径图
迭代图
小结
-
本推文基本对参考论文进行复现,进行了论文数据和rc101到rc108的测试,希望有借鉴意义。excel数据和算法代码参数皆可修改(修改时注意不要改变excel数据的布局)。
-
参考文献:带时间窗和服务顺序约束的多需求车辆路径问题 (李珍萍 张煜炜)
代码
为了方便和便于修改和测试,把代码在4个py文件里,pa.py是rc101-108的一个简单爬虫程序。

演示视频:
论文复现丨带时间窗和服务顺序的多车辆路径问题:联合优化遗传算法
完整算法+数据:
可加微信:diligent-1618,请备注:学校-专业-昵称。