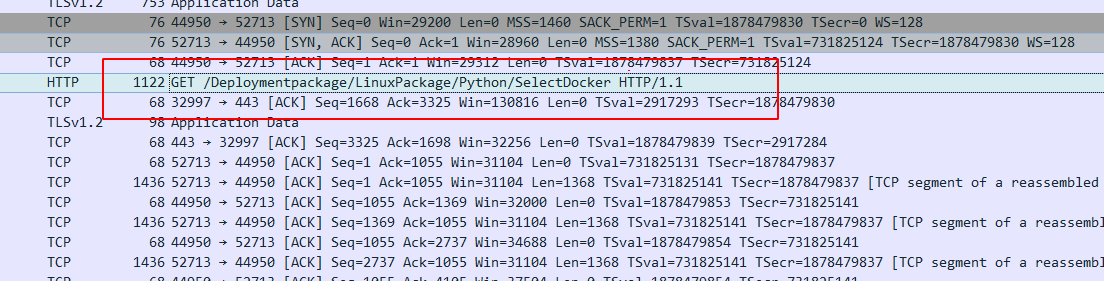
【arxiv 2024】Latte: Latent Diffusion Transformer for Video Generation
- 一、前言
- Abstract
- 1 Introduction
- 2 Related Work
- 3 Methodology
- 3.1 Preliminary of Latent Diffusion Models
- 3.2 The model variants of Latte
- 3.3 The empirical analysis of Latte
- 3.3.1 Latent video clip patch embedding
- 3.3.2 Timestep-class information injection
- 3.3.3 Temporal positional embedding
- 3.3.4 Enhancing video generation with learning strategies
- 4 Experiments
- 4.1 Experimental setup
- 4.2 Ablation study
- 4.3 Comparison to state-of-the-art
- 4.4 Extension to text-to-video generation
- 5 Conclusion
一、前言
Authors: Xin Ma, Yaohui Wang, Gengyun Jia, Xinyuan Chen, Ziwei Liu, Yuan-Fang Li, Cunjian Chen, Yu Qiao
【Paper】 > 【Github_Code】 > 【Project】
这项工作提出了 Latte,一种简单且通用的视频扩散方法,它采用视频 Transformer 作为生成视频的骨干。为了提高生成的视频质量,确定了所提出模型的最佳实践,包括剪辑补丁嵌入、模型变体、时间步长类信息注入、时间位置嵌入和学习策略。综合实验表明,Latte 在四个标准视频生成基准测试中取得了最先进的结果。此外,与当前的 T2V 方法相比,还获得了可比的文本到视频结果。Latte 可以为未来有关将基于 Transformer 的骨干网集成到视频生成扩散模型以及其他模式的研究提供有价值的见解。
Abstract
介绍:我们提出了一种新颖的潜在扩散变压器,即 Latte,用于视频生成。 Latte 首先从输入视频中提取时空标记,然后采用一系列 Transformer 块对潜在空间中的视频分布进行建模。为了对从视频中提取的大量标记进行建模,从分解输入视频的空间和时间维度的角度引入了四种有效的变体。为了提高生成视频的质量,我们通过严格的实验分析确定了 Latte 的最佳实践,包括视频片段补丁嵌入、模型变体、时间步级信息注入、时间位置嵌入和学习策略。
实验:我们的综合评估表明,Latte 在四个标准视频生成数据集(即 FaceForensics、SkyTimelapse、UCF101 和 Taichi-HD)上实现了最先进的性能。此外,我们将 Latte 扩展到文本到视频生成 (T2V) 任务,其中 Latte 取得了与最新 T2V 模型相当的结果。我们坚信 Latte 为未来将 Transformer 纳入视频生成扩散模型的研究提供了宝贵的见解
Keywords: Video generation, diffusion models, transformers
1 Introduction

扩散模型 \citep{ho2020denoising、song2020score、song2020denoising} 是强大的深度生成模型,适用于内容创建中的各种任务,包括图像到图像生成 \citep{meng2021sdedit, zhao2022egsde, saharia2022palette, parmar2023zero}、文本到图像生成 \citep {Zhou_2023_CVPR, rombach2022high, zhou2022towards, ruiz2023dreambooth, zhang2023adding},以及3D对象生成\citep{wang2023score, Chen_2023_ICCV, zhou20213d, shue20233d}等。与这些在图像中的成功应用相比,生成高质量视频仍然面临着重大挑战,这可以主要归因于视频的复杂性和高维性,这些视频在高分辨率帧中包含复杂的时空信息。
同时,研究人员揭示了骨干网革命对于扩散模型成功的重要性\citep{nichol2021improved, peebles2023scalable, bao2023all}。依赖于卷积神经网络(CNN)的 U-Net \citep{ronneberger2015u} 在图像和视频生成作品 \citep{ho2022video, dhariwal2021diffusion} 中占据了突出的地位。相反,一方面,DiT \citep{peebles2023scalable} 和 U-ViT \citep{bao2023all} 将 ViT \citep{dosovitskiy2020image} 的架构调整为用于图像生成的扩散模型,并取得了良好的性能。此外,DiT 已经证明 U-Net 的归纳偏差对于潜在扩散模型的性能并不重要。另一方面,基于注意力的架构 \citep{vaswani2017attention} 提供了一种直观的选项,用于捕获视频中的远程上下文关系。因此,一个非常自然的问题出现了:\textit{基于 Transformer 的潜在扩散模型能否增强真实视频的生成?}
在本文中,我们提出了一种用于视频生成的新型潜在扩散变压器,即Latte,它采用视频变压器作为骨干。 Latte 采用预先训练的变分自动编码器将输入视频编码为潜在空间中的特征,其中从编码特征中提取令牌。然后应用一系列 Transformer 块对这些令牌进行编码。考虑到时空信息之间的固有差异以及从输入视频中提取的大量标记,如图2所示,我们从输入视频的分解时空维度的角度设计了四种高效的基于Transformer的模型变体。
卷积模型有许多最佳实践,包括用于问题分类的文本表示 \citep{pota2020best},以及用于图像分类的网络架构设计 \citep{he2016deep} 等。然而,用于视频生成的基于 Transformer 的潜在扩散模型可能会表现出不同的性能特性,需要确定该架构的最佳设计选择。因此,我们进行了全面的消融分析,包括 \textit{视频剪辑补丁嵌入}、\textit{模型变体}、\textit{时间步长类信息注入}、\textit{时间位置嵌入}和 \textit{学习策略} 。我们的分析使 Latte 能够生成具有时间连贯内容的逼真视频(见图 1),并在四个标准视频生成基准上实现最先进的性能,包括 FaceForensics \citep{rossler2018faceforensics}、SkyTimelapse \citep {xiong2018learning}、UCF101 \citep{soomro2012dataset} 和 Taichi-HD \citep{siarohin2019first}。值得注意的是,Latte 的性能远远优于最先进的技术,实现了最佳的 Fr{'e}chet 视频距离 (FVD) \citep{unterthiner2018towards}、Fr{'e}chet 起始距离 (FID) \citep{parmar2021buggy } 和初始分数 (IS)。此外,我们将 Latte 扩展到文本到视频生成任务,与当前的 T2V 模型相比,它也取得了可比的结果。
综上所述,我们的主要贡献如下:
- 我们提出了Latte,一种新颖的潜在扩散变压器,它采用视频变压器作为骨干。此外,还引入了四种模型变体来有效捕获视频中的时空分布。
- 为了提高生成视频的质量,我们全面探索视频片段补丁嵌入、模型变体、时间步长类信息注入、时间位置嵌入和学习策略,以确定基于 Transformer 的视频生成扩散模型的最佳实践。
- 四个标准视频生成基准的实验结果表明,Latte 可以根据最先进的方法生成具有时间连贯内容的逼真视频。此外,Latte 在应用于文本到视频生成任务时显示出类似的结果。
2 Related Work
Video generation视频生成旨在生成逼真的视频,同时展现高质量的视觉外观和一致的运动。该领域先前的研究可分为三个主要类别。首先,一些研究试图扩展基于 GAN 的强大图像生成器的能力来创建视频(Vondrick 等人,2016;Saito 等人,2017;Wang 等人,2020b,a;Kahembwe 和 Ramamoorthy,2020)。然而,这些方法经常遇到与模式崩溃相关的挑战,限制了它们的有效性。其次,一些方法提出使用自回归模型来学习数据分布(Ge et al, 2022; Rakhimov et al, 2021; Weissenborn et al, 2020; Yan et al, 2021)。虽然这些方法通常提供良好的视频质量并表现出更稳定的收敛,但它们存在需要大量计算资源的缺点。最后,视频生成的最新进展集中在基于扩散模型的构建系统(Ho et al, 2020; Harvey et al, 2022; Ho et al, 2022; Singer et al, 2022; Mei and Patel, 2023; Blattmann等人,2023b;Wang 等人,2023b;Chen 等人,2023c;Wang 等人,2023c),取得了可喜的成果。然而,基于 Transformer 的扩散模型尚未得到很好的探索。最近的并行工作 VDT (Lu et al, 2023) 也探索了类似的想法。与 VDT 的不同之处在于,我们对不同的 Transformer 主干和第 2 节中讨论的相关最佳实践进行了系统分析。 3.2 和第 3.2 节3.3 关于视频生成。 VDT 与我们的变体 3 类似。我们在图 6d 中显示了这些模型变体之间的性能差异,其中表明变体 1 优于变体 3。
Transformers Transformers 已成为主流模型架构,并在图像修复 \citep{ma2022contrastive, ma2021free, ma2023uncertainty}、图像超分辨率 \cite{luo2022style, huang2017wavelet}、图像裁剪 \citep{jia2022rethinking}、伪造等领域取得了显着的成功检测\citep{jia2021inconsistency},人脸识别\citep{luo2021fa,luo2021partial},自然语言处理\citep{devlin2018bert}。 Transformers 最初出现在语言领域 \citep{vaswani2017attention, kaplan2020scaling},在那里他们很快就因其出色的能力而建立了声誉。随着时间的推移,这些模型已经熟练地适应了预测图像的任务,在图像空间和离散码本 \citep{chen2020generative, parmar2018image} 内自回归地执行此功能。在最新的发展中,变形金刚已集成到扩散模型中,将其范围扩展到非空间数据和图像的生成。这包括文本编码和解码 \citep{rombach2022high, saharia2022photorealistic}、生成 CLIP 嵌入 \citep{ramesh2022hierarchical} 以及逼真图像生成 \citep{bao2023all, peebles2023scalable} 等任务。
3 Methodology
我们首先在第二节中简要介绍潜在扩散模型。 3.1.接下来,我们将在第二节介绍 Latte 的模型变体。 3.2.最后,第 2 节讨论了 Latte 的实证分析。 3.3.
3.1 Preliminary of Latent Diffusion Models
Latent diffusion models (LDMs) (Rombach et al, 2022). LDM 是有效的扩散模型\citep{ho2020denoising, Song2020score},通过在潜在空间而不是像素空间中进行扩散过程。 LDM 首先使用来自预训练变分自动编码器的编码器 E \mathcal{E} E 将输入数据样本 x ∈ p data ( x ) x \in p_{\text{data}}(x) x∈pdata(x) 压缩为较低维的潜在代码 z = E ( x ) z = \mathcal{E}(x) z=E(x)。随后,它通过两个关键过程学习数据分布:扩散和去噪。
扩散过程逐渐将高斯噪声引入到潜在代码 z z z中,生成扰动样本 z t = α ‾ t z + 1 − α ‾ t ϵ z_{t} = {\sqrt{\overline{\alpha}_{t}}}z + \sqrt{1-{\overline{\alpha}_{t}}}\epsilon zt=αtz+1−αtϵ,其中 ϵ ∼ N ( 0 , 1 ) \epsilon\sim \mathcal{N}(0,1) ϵ∼N(0,1),遵循跨越 T T T阶段的马尔可夫链。在这种情况下, α ‾ t \overline{\alpha}_{t} αt 用作噪声调度器, t t t 表示扩散时间步长。
训练去噪过程以了解逆扩散过程,以预测噪声较小的
z
t
−
1
z_{t-1}
zt−1:
p
θ
(
z
t
−
1
∣
z
t
)
=
N
(
μ
θ
(
z
t
)
,
Σ
θ
(
z
t
)
)
p_\theta(z_{t-1}|z_t)=\mathcal{N}(\mu_\theta (z_t),{\Sigma_\theta}(z_t))
pθ(zt−1∣zt)=N(μθ(zt),Σθ(zt)),对数似然的变分下界减少为
L
θ
=
−
log
p
(
z
0
∣
z
1
)
+
∑
t
D
K
L
(
(
q
(
z
t
−
1
∣
z
t
,
z
0
)
∣
∣
p
θ
(
z
t
−
1
∣
z
t
)
)
\mathcal{L_\theta}=-\log{p(z_0|z_1)}+\sum_tD_{ KL}((q(z_{t-1}|z_t,z_0)||p_\theta(z_{t-1}|z_t))
Lθ=−logp(z0∣z1)+∑tDKL((q(zt−1∣zt,z0)∣∣pθ(zt−1∣zt))。这里,
μ
θ
\mu_\theta
μθ是使用去噪模型实现的
ϵ
θ
\epsilon_{\theta}
ϵθ 并使用 \emph{simple} 目标进行训练,
L
s
i
m
p
l
e
=
E
z
∼
p
(
z
)
,
ϵ
∼
N
(
0
,
1
)
,
t
[
∥
ϵ
−
ϵ
θ
(
z
t
,
t
)
∥
2
2
]
.
\begin{equation} \mathcal{L}_{simple} = \mathbb{E}_{\mathbf{z}\sim p(z),\ \epsilon \sim \mathcal{N} (0,1),\ t}\left [ \left \| \epsilon - \epsilon_{\theta}(\mathbf{z}_t, t)\right \|^{2}_{2}\right]. \end{equation}
Lsimple=Ez∼p(z), ϵ∼N(0,1), t[∥ϵ−ϵθ(zt,t)∥22].根据 \citep{nichol2021improved},要训练具有学习的反向过程协方差
Σ
θ
\Sigma_\theta
Σθ 的扩散模型,有必要优化完整的
D
K
L
D_{KL}
DKL 项,从而使用完整的
L
\mathcal{L}
L进行训练,表示为
L
v
l
b
\mathcal{L}_{vlb}
Lvlb。此外,
Σ
θ
\Sigma_\theta
Σθ 是使用
ϵ
θ
\epsilon_{\theta}
ϵθ 实现的。
我们将 LDM 扩展到视频生成:1)编码器 E \mathcal{E} E 用于将每个视频帧压缩到潜在空间中; 2)扩散过程在视频的潜在空间中运行,以对潜在的空间和时间信息进行建模。在这项工作中, ϵ θ \epsilon_\theta ϵθ 使用 Transformer 实现。我们通过使用 L s i m p l e \mathcal{L}_{simple} Lsimple 和 L v l b \mathcal{L}_{vlb} Lvlb 来训练所有模型。
3.2 The model variants of Latte

如图2所示,提出了四种 Latte 模型变体来有效捕获视频中的时空信息。
Variant
1.
\textbf{Variant 1.}
Variant 1.
如图2 (a) 所示,该变体的 Transformer 主干包括两种不同类型的 Transformer 块:空间 Transformer 块和时间 Transformer 块。前者专注于仅捕获共享相同时间索引的标记之间的空间信息,而后者以“交错融合”的方式捕获跨时间维度的时间信息。
假设我们在潜在空间 V L ∈ R F × H × W × C \boldsymbol{V_L} \in \mathbb{R}^{F \times H \times W \times C} VL∈RF×H×W×C 中有一个视频剪辑。我们首先将 V L \boldsymbol{V_L} VL 转换为标记序列,表示为 z ^ ∈ R n f × n h × n w × d \hat{\boldsymbol{z}} \in \mathbb{R}^{n_f \times n_h \times n_w \times d} z^∈Rnf×nh×nw×d。这里 F F F、 H H H、 W W W和 C C C分别表示潜在空间中视频帧的数量、视频帧的高度、宽度和通道。潜在空间中视频剪辑内的标记总数为 n f × n h × n w n_f \times n_h \times n_w nf×nh×nw, d d d 分别表示每个标记的维度。时空位置嵌入 p \boldsymbol{p} p 被合并到 z ^ \hat{\boldsymbol{z}} z^ 中。最后,我们得到 z = z ^ + p \boldsymbol{z} = \hat{\boldsymbol{z}} + \boldsymbol{p} z=z^+p 作为 Transformer 主干的输入。
我们将 z \boldsymbol{z} z 重塑为 z s ∈ R n f × t × d \boldsymbol{z_s} \in \mathbb{R}^{n_f \times t \times d} zs∈Rnf×t×d 作为空间 Transformer 块的输入以捕获空间信息。这里, t = n h × n w t=n_h \times n_w t=nh×nw 表示每个时间索引的标记计数。随后,包含空间信息的 z s \boldsymbol{z_s} zs被重塑为 z t ∈ R t × n f × d \boldsymbol{z_t} \in \mathbb{R}^{t \times n_f \times d} zt∈Rt×nf×d作为时间Transformer块的输入,用于捕获时间信息。
Variant
2.
\textbf{Variant 2.}
Variant 2.
与变体 1 中的时间“交错融合”设计相反,该变体利用“后期融合”方法来组合时空信息 \citep{neimark2021video, simonyan2014two}。如图 2 (b) 所示,该变体由与变体 1 相同数量的 Transformer 块组成。与变体 1 类似,空间 Transformer 块和时间 Transformer 块的输入形状分别为
z
s
∈
R
n
f
×
t
×
d
\boldsymbol{z_s} \in \mathbb{R}^{n_f \times t \times d}
zs∈Rnf×t×d 和
z
t
∈
R
t
×
n
f
×
d
\boldsymbol{z_t} \in \mathbb{R}^{t \times n_f \times d}
zt∈Rt×nf×d。
Variant
3.
\textbf{Variant 3.}
Variant 3.
变体 1 和变体 2 主要关注 Transformer 块的因式分解。变体 3 侧重于分解 Transformer 块中的多头注意力。如图 2 ( c) 所示,该变体最初仅在空间维度上计算自注意力,然后是时间维度。因此,每个 Transformer 块都会捕获空间和时间信息。与变体 1 和变体 2 类似,空间多头自注意力和时间多头自注意力的输入分别为
z
s
∈
R
n
f
×
t
×
d
\boldsymbol{z_s} \in \mathbb{R}^{n_f \times t \times d}
zs∈Rnf×t×d 和
z
t
∈
R
t
×
n
f
×
d
\boldsymbol{z_t} \in \mathbb{R}^{t \times n_f \times d}
zt∈Rt×nf×d 。
Variant 4. \textbf{Variant 4.} Variant 4. 在此变体中,我们将多头注意力(MHA)分解为两个组件,每个组件利用一半的注意力头,如图 2(d)所示。我们使用不同的组件在空间和时间维度上分别处理令牌。这些不同分量的输入形状分别为 z s ∈ R n f × t × d \boldsymbol{z_s} \in \mathbb{R}^{n_f \times t \times d} zs∈Rnf×t×d 和 z t ∈ R t × n f × d \boldsymbol{z_t} \in \mathbb{R}^{t \times n_f \times d} zt∈Rt×nf×d。一旦计算出两个不同的注意力操作,我们将 z t ∈ R t × n f × d \boldsymbol{z_t} \in \mathbb{R}^{t \times n_f \times d} zt∈Rt×nf×d 重塑为 z t ′ ∈ R n f × t × d \boldsymbol{z_t^{'}} \in \mathbb{ R}^{n_f \times t \times d} zt′∈Rnf×t×d。然后将 z t ′ \boldsymbol{z_t^{'}} zt′ 添加到 z s \boldsymbol{z_s} zs,用作 Transformer 块中下一个模块的输入。
在 Transformer 主干之后,一个关键过程涉及解码视频令牌序列以导出预测噪声和预测协方差。两个输出的形状与输入 V L ∈ R F × H × W × C \boldsymbol{V_L} \in \mathbb{R}^{F \times H \times W \times C} VL∈RF×H×W×C 的形状相同。继之前的工作\citep{peebles2023scalable, bao2023all}之后,我们通过采用标准线性解码器以及整形操作来实现这一点。
3.3 The empirical analysis of Latte
我们对 Latte 中的关键组件进行了全面的实证分析,旨在发现将 Transformer 集成为视频生成的潜在扩散模型中的骨干的最佳实践。
3.3.1 Latent video clip patch embedding

为了嵌入视频剪辑,我们探索了以下两种方法来分析在令牌中集成时间信息的必要性,即1)统一帧补丁嵌入和2)压缩帧补丁嵌入。
Uniform frame patch embedding. 如图3(a)所示,我们将 ViT \citep{dosovitskiy2020image}中概述的补丁嵌入技术单独应用于每个视频帧。具体来说,当从每个视频帧中提取非重叠图像补丁时, n f n_f nf、 n h n_h nh 和 n w n_w nw 相当于 F F F、 H h \frac{H}{h} hH 和 W w \frac{W}{w} wW。这里, h h h 和 w w w 分别表示图像片段的高度和重量。
Compression frame patch embedding. \textbf{Compression frame patch embedding.} Compression frame patch embedding.第二种方法是通过将 ViT 补丁嵌入扩展到时间维度来对潜在视频片段中的时间信息进行建模,如图 3 (b) 所示。我们沿着时间维度以 s s s 的步幅提取管,然后将它们映射到标记。在这里,与非重叠均匀帧补丁嵌入相比, n f n_f nf 相当于 F s \frac{F}{s} sF。与前者相比,该方法在补丁嵌入阶段本质上融合了时空信息。请注意,在使用压缩帧补丁嵌入方法的情况下,额外的步骤需要集成 3D 转置卷积,以在标准线性解码器和整形操作之后对输出潜在视频进行时间上采样。
3.3.2 Timestep-class information injection
从简单直接的集成到复杂细致的集成角度,我们探索了两种将时间步长或类信息
c
c
c 集成到模型中的方法。第一种方法是将其视为标记,我们将这种方法称为
all
tokens
\textit{all tokens}
all tokens。第二种方法类似于自适应层归一化(AdaLN)\citep{perez2018film, peebles2023scalable}。我们使用线性回归根据输入
c
c
c计算
γ
c
\gamma_c
γc和
β
c
\beta_c
βc,得到方程
A
d
a
L
N
(
h
,
c
)
=
γ
c
LayerNorm
(
h
)
+
β
c
AdaLN(h, c) = \gamma_c \text{LayerNorm}(h) + \beta_c
AdaLN(h,c)=γcLayerNorm(h)+βc,其中
h
h
h 表示 Transformer 块内的隐藏嵌入。此外,我们还对
α
c
\alpha_c
αc 进行回归,该回归直接应用于 Transformer 块内的任何残差连接 (RC) 之前,从而得到
R
C
s
(
h
,
c
)
=
α
c
h
+
A
d
a
L
N
(
h
,
c
)
RCs(h, c) = \alpha_ch + AdaLN(h, c)
RCs(h,c)=αch+AdaLN(h,c)。我们将其称为可扩展自适应层归一化(
S-AdaLN
\textit{S-AdaLN}
S-AdaLN)。
S-AdaLN
\textit{S-AdaLN}
S-AdaLN 的架构如图 4(a) 所示。

3.3.3 Temporal positional embedding
时间位置嵌入使模型能够理解时间信号。我们探索了以下两种方法将时间位置嵌入注入到模型中:1)绝对位置编码方法结合了不同频率的正弦和余弦函数(Vaswani 等人,2017),使模型能够识别每个函数的精确位置。视频序列中的帧; 2)相对位置编码方法采用旋转位置嵌入(RoPE)(Su等人,2021)使模型能够掌握连续帧之间的时间关系。
3.3.4 Enhancing video generation with learning strategies
我们的目标是确保生成的视频展现出最佳的视觉质量,同时保持时间一致性。我们探讨了结合两种额外的学习策略(即使用预训练模型进行学习和使用图像视频联合训练进行学习)是否可以提高生成视频的质量。
Learning with pre-trained models. \textbf{Learning with pre-trained models.} Learning with pre-trained models. 预先训练的图像生成模型已经了解了世界的样子。因此,有许多视频生成工作将其模型建立在预先训练的图像生成模型上,以了解世界如何移动\citep{wang2023lavie,blattmann2023stable}。然而,这些工作主要建立在潜在扩散模型中的 U-Net 之上。基于 Transformer 的潜在扩散模型的必要性值得探讨。
我们从 ImageNet \citep{peebles2023scalable, deng2009imagenet} 上预先训练的 DiT 模型初始化 Latte。直接从预训练的DiT模型初始化会遇到参数缺失或不兼容的问题。为了解决这些问题,我们实施以下策略。在预训练的 DiT 中,位置嵌入 p ∈ R n h × n w × d \boldsymbol{p} \in \mathbb{R}^{n_h \times n_w \times d} p∈Rnh×nw×d 应用于每个标记。然而,在我们的视频生成模型中,我们的令牌计数是预训练 DiT 模型的 n f n_f nf 倍。因此,我们将位置嵌入从 p ∈ R n h × n w × d \boldsymbol{p} \in \mathbb{R}^{n_h \times n_w \times d} p∈Rnh×nw×d 临时复制 n f n_f nf 次到 p ∈ R n f × n h × n w × d \boldsymbol{p} \in \mathbb{R} ^{n_f \times n_h \times n_w \times d} p∈Rnf×nh×nw×d。此外,预训练的 DiT 包括标签嵌入层,类别数量为 1000。然而,与 ImageNet 相比,所使用的视频数据集要么缺乏标签信息,要么包含的类别数量明显较少。由于我们的目标是无条件和类条件视频生成,DiT 中的原始标签嵌入层不适合我们的任务,因此我们选择直接丢弃 DiT 中的标签嵌入并应用零初始化。
Learning with image-video joint training. \textbf{Learning with image-video joint training.} Learning with image-video joint training. 基于 CNN 的视频扩散模型的先前工作提出了一种联合图像视频训练策略,该策略极大地提高了生成视频的质量\citep{ho2022video}。我们探讨这种训练策略是否也可以提高基于 Transformer 的视频扩散模型的性能。为了实现视频和图像生成的同步训练,我们将从同一数据集中随机选择的视频帧附加到所选视频的末尾,并且每个帧都是独立采样的。为了确保我们的模型能够生成连续的视频,在时间模块中使用与视频内容相关的标记来对时间信息进行建模,而帧标记被排除在外。
4 Experiments
本节首先概述实验设置,包括数据集、评估指标、基线、Latte 配置和实现细节。随后,我们提出了 Latte 最佳实践选择和模型大小的消融实验。最后,我们将实验结果与最先进的结果进行比较,并呈现文本到视频的生成结果。
4.1 Experimental setup
Datasets. 我们主要在四个公共数据集上进行综合实验:FaceForensics (R´ossler et al, 2018)、SkyTimelapse (Xiong et al, 2018)、UCF101 (Soomro et al, 2012) 和 Taichi-HD (Siarohin et al, 2018)。 2019)。按照(Skorokhodov 等人,2022)中的实验设置,除了 UCF101 之外,我们对所有数据集(如果可用)使用训练分割。对于 UCF101,我们同时使用训练和测试分割。我们使用特定的采样间隔从这些数据集中提取 16 帧视频剪辑,每帧大小调整为 256×256 分辨率以进行训练。
Evaluation metrics. 在定量比较的评估中,我们采用三个评估指标:Fr{'e}chet Video Distance (FVD) \citep{unterthiner2018towards}、Fr{'e}chet Inception Distance (FID) \citep{parmar2021buggy}和初始分数(IS)\citep{saito2017temporal}。我们的主要关注点是 FVD,因为其基于图像的对应 FID 更符合人类的主观判断。遵循 StyleGAN-V 引入的评估指南,我们通过分析 2,048 个视频剪辑(每个视频剪辑包含 16 帧)来计算 FVD 分数。我们仅使用 IS 来评估 UCF101 的生成质量,因为它利用 UCF101 微调的 C3D 模型 \citep{saito2017temporal}。
Baselines. \textbf{Baselines.} Baselines. 我们与最近的方法进行比较以定量评估结果,包括 MoCoGAN \citep{tulyakov2018mocogan}、VideoGPT \citep{yan2021videogpt}、MoCoGAN-HD \citep{tian2021good}、DIGAN \citep{yu2022generating}、StyleGAN-V \citep{skorokhodov2022stylegan} 、PVDM \citep{yu2023video}、MoStGAN-V \citep{shen2023mostgan} 和 LVDM \citep{he2023latent}。此外,我们在 UCF101 数据集上对我们提出的方法和之前的方法进行了额外的 IS 比较。
Latte
configurations.
\textbf{Latte configurations.}
Latte configurations. 一系列
N
N
N Transformer 块用于构建我们的 Latte 模型,每个 Transformer 块的隐藏维度为
D
D
D,具有
N
N
N 多头注意力。在 ViT 之后,我们确定了具有不同参数数量的 Latte 的四种配置,如表 4 所示。

Implementation
details.
\textbf{Implementation details.}
Implementation details. 我们使用具有恒定学习率
1
×
1
0
−
4
1 \times 10 ^{-4}
1×10−4 的 AdamW 优化器来训练所有模型。水平翻转是唯一采用的数据增强。遵循生成建模作品 \citep{peebles2023scalable, bao2023all} 中的常见做法,在整个训练过程中维持 Latte 权重的指数移动平均值 (EMA),采用 0.9999 的衰减率。所有报告的结果均直接从 EMA 模型获得。我们借用了稳定扩散 1.4 中预训练的变分自动编码器。
4.2 Ablation study
在本节中,我们在 FaceForensics 数据集上进行实验,以检查第 3.3 节中描述的不同设计的效果、第 3.2 节中描述的模型变体、视频采样间隔和模型大小对模型性能的影响。

Video clip patch embedding. \textbf{Video clip patch embedding.} Video clip patch embedding.我们研究了两种视频剪辑补丁嵌入方法的影响,详见第 Sec3.3.1 部分。在图6e中,压缩帧补丁嵌入方法的性能明显落后于均匀帧补丁嵌入方法。这一发现与视频理解方法 ViViT 获得的结果相矛盾。我们推测使用压缩帧补丁嵌入方法会导致时空信号丢失,这使得 Transformer 主干很难学习视频的分布。
Timestep-class information injection. \textbf{Timestep-class information injection.} Timestep-class information injection.如图6f所示,\textit{S-AdaLN}的性能明显优于\textit{all tokens}。我们认为这种差异可能源于这样一个事实: \textit{all tokens} 仅向模型的输入层引入时间步长或标签信息,这可能面临在整个模型中有效传播的挑战。相比之下,\textit{S-AdaLN} 以更自适应的方式为每个 Transformer 块将时间步长或标签信息编码到模型中。这种信息传输方法似乎更有效,可能有助于实现卓越的性能和更快的模型收敛。
Temporal positional embedding. \textbf{Temporal positional embedding.} Temporal positional embedding. 图6b说明了两种不同时间位置嵌入方法对模型性能的影响。采用绝对位置嵌入方法往往会比其他方法产生稍微更好的结果。
Enhancing video generation with learning strategies. \textbf{Enhancing video generation with learning strategies.} Enhancing video generation with learning strategies. 如图所示6c,我们观察到,训练的初始阶段极大地受益于 ImageNet 上的模型预训练,从而能够在视频数据集上快速实现高质量的性能。然而,随着迭代次数的增加,用预训练模型初始化的模型的性能趋于稳定在一定水平附近,这比用随机初始化的模型差得多。
这种现象可以用两个因素来解释:1)ImageNet 上的预训练模型提供了良好的表示,这可能有助于模型在早期阶段快速收敛; 2)ImageNet和FaceForensics之间的数据分布存在显着差异,这使得模型很难将在ImageNet上学到的知识适应FaceForensics。
如表2和表1所示。我们发现图像-视频联合训练(“Latte+IMG”)导致 FID 和 FVD 显着改进。沿着时间轴将额外的随机采样帧与视频连接起来使模型能够适应每批次内有更多示例,这可以增加训练模型的多样性。


Video sampling interval. \textbf{Video sampling interval.} Video sampling interval. 我们探索各种采样率,从每个训练视频构建 16 帧剪辑。如图6a所示,在训练过程中,早期使用不同采样率的模型之间存在显着的性能差距。然而,随着训练迭代次数的增加,性能逐渐变得一致,这表明不同的采样率对模型性能影响很小。我们选择视频采样间隔为 3,以确保生成的视频具有合理的连续性,以进行与最先进技术的比较实验。
Model
variants.
\textbf{Model variants.}
Model variants. 我们评估了 Latte 的模型变体,如第 3.2 节所述。我们努力使所有不同模型的参数计数相等,以确保公平的比较。我们从头开始训练所有模型。如图6d所示,随着迭代次数的增加,变体 1 表现最好。值得注意的是,与其他三个模型变体相比,变体 4 的浮点运算 (FLOP) 大约为四分之一,如表 3 所示。 因此,变体 4 在四个变体中表现最差也就不足为奇了。

在变体 2 中,一半的 Transformer 块最初用于空间建模,然后剩下的一半用于时间建模。这种划分可能会导致后续时间建模过程中空间建模能力的丧失,最终影响性能。因此,我们认为与仅使用多头注意力(变体 3)相比,使用完整的 Transformer 块(包括多头注意力、层范数和多线性投影)在建模时间信息方面可能更有效。
Model
size.
\textbf{Model size.}
Model size. 我们根据 Tab.4 训练了四个不同大小的 Latte 模型。 FaceForensics 数据集上的 (XL、L、B 和 S)。图 8 清楚地说明了随着训练迭代次数的增加,相应的 FVD 的进展。可以清楚地观察到,增加模型大小通常与显着的性能改进相关,这在图像生成工作中也被指出~\citep{peebles2023scalable}。

4.3 Comparison to state-of-the-art
基于第4.2节的消融研究。 我们可以获得基于 Transformer 的潜在视频扩散模型的最佳实践(即模型变体 1、统一帧补丁嵌入、S-AdaLN 和绝对位置嵌入方法、图像视频联合训练)。我们在这些最佳实践下使用我们提出的 Latte 与当前最先进的技术进行比较。
Qualitative results. 图 5 展示了 Latte 在 UCF101、Taichi-HD、FaceForensics 和 SkyTimelapse 上的视频合成结果。我们的方法在所有场景中始终如一地提供逼真的高分辨率视频生成结果(256x256 像素)。这包括捕捉人脸的运动和处理运动员的重大转变。值得注意的是,我们的方法擅长在具有挑战性的 UCF101 数据集中合成高质量视频,而其他比较方法常常无法完成这项任务。更多结果可以在项目网站上看到。

Quantitative results. 在表2中。 我们分别提供了Latte和其他比较方法的定量结果。我们的方法在所有数据集上都显着优于以前的工作,这表明我们的方法在视频生成方面的优越性。
在表1中,我们报告FaceForensics 上的 FID 和 UCF101 上的 IS 来评估视频帧质量。我们的方法表现出出色的性能,FID 值为 3.87,IS 值为 73.31,显着超越其他方法的能力。
4.4 Extension to text-to-video generation
为了探索我们提出的方法的潜在能力,我们将 Latte 扩展到文本到视频的生成。我们采用图2(a)所示的方法来构建我们的Latte T2V模型。第 4.2小节 提到利用预先训练的模型可以促进模型训练。因此,我们利用预训练的 PixArt-α(512 × 512 分辨率)(Chen 等人,2023a)的权重来初始化 Latte T2V 模型中空间 Transformer 模块的参数。由于常用视频数据集 WebVid-10M (Bain et al, 2021) 的分辨率低于 512 × 512,我们在 (Wang et al, 2023b) 中提出的高分辨率视频数据集 Vimeo25M 上训练我们的模型。我们在这两个数据集的子集上训练 T2V 模型,其中包含大约 330,000 个文本视频对。我们在图 7 中的视觉质量方面与最近的 T2V 模型 VideoFusion(Luo 等人,2023)和 VideooLDM(Blattmann 等人,2023b)进行了比较。它表明我们的 Latte 可以生成可比较的 T2V 结果。更多结果可以在我们的项目网站上找到。此外,我们选择 2,048 个采样视频来计算 FVD 和 FID 分数。所得的 FVD 和 FID 值分别为 328.20 和 50.72。

5 Conclusion
这项工作提出了 Latte,一种简单且通用的视频扩散方法,它采用视频 Transformer 作为生成视频的骨干。为了提高生成的视频质量,我们确定了所提出模型的最佳实践,包括剪辑补丁嵌入、模型变体、时间步长类信息注入、时间位置嵌入和学习策略。综合实验表明,Latte 在四个标准视频生成基准测试中取得了最先进的结果。此外,与当前的 T2V 方法相比,还获得了可比的文本到视频结果。我们坚信,Latte 可以为未来有关将基于 Transformer 的骨干网集成到视频生成扩散模型以及其他模式的研究提供有价值的见解。