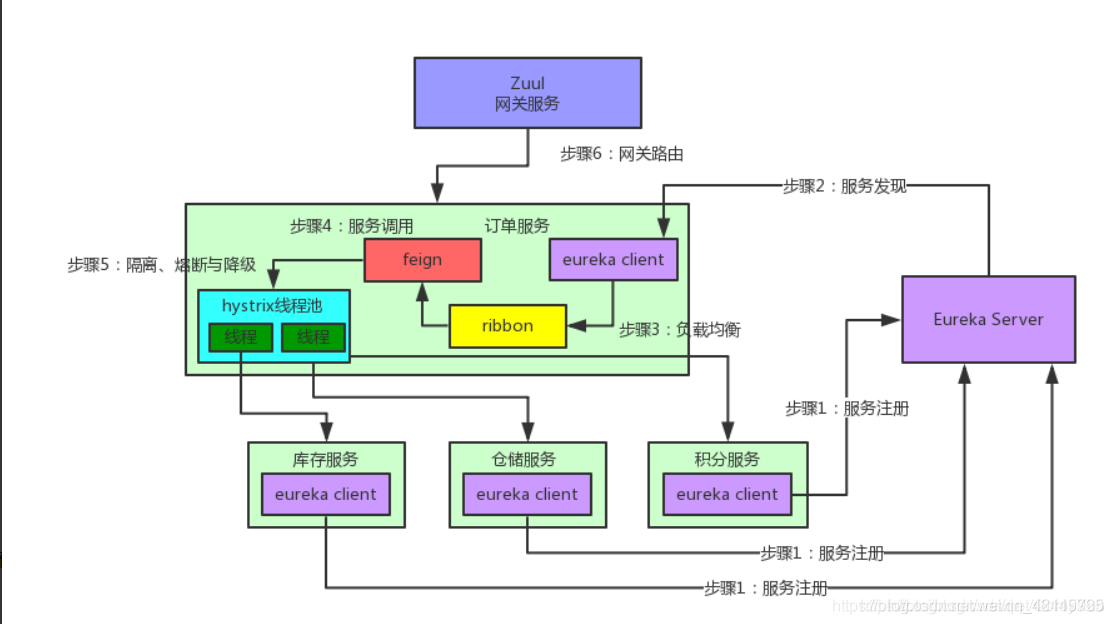
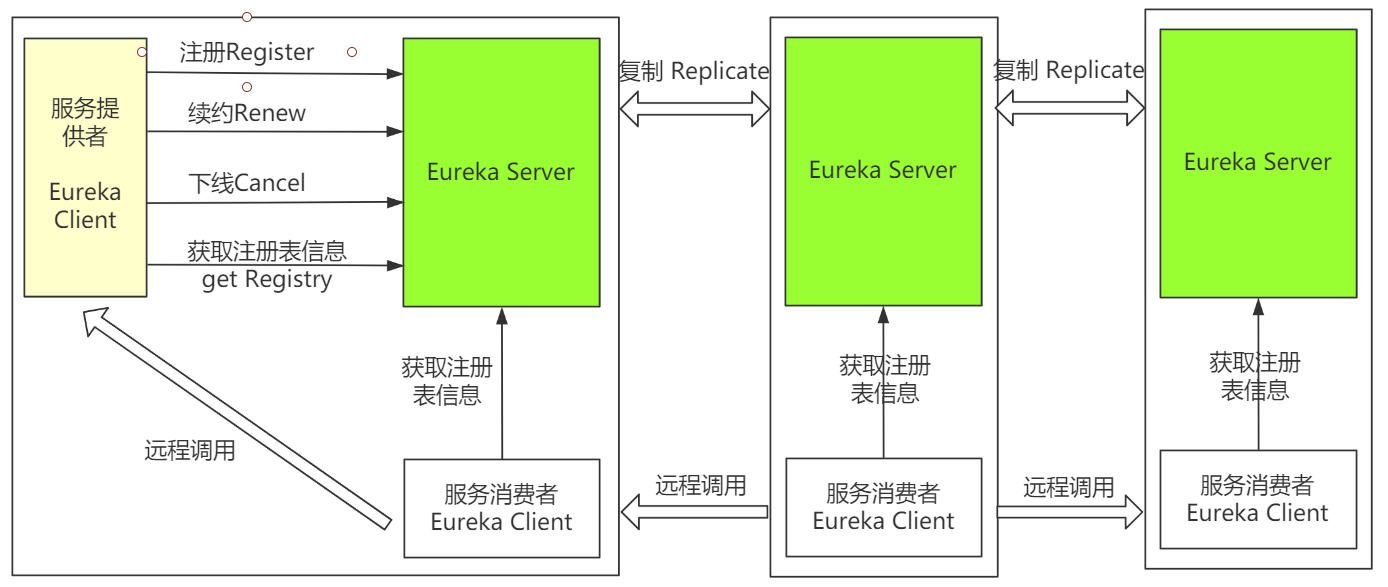
1.eureka注册中心原理简述
1.服务注册:
Eureka Client 会通过发送rest请求的方式向eureka服务端注册自身元数据:ip地址,端口,运行状况等信息,服务端会把注册信息存储在一个双层map中。
- Eureka 的数据存储分了两层:数据存储层和缓存层。
Eureka Client 在拉取服务信息时,先从缓存层获取,如果获取不到,先把数据存储层的数据加载到缓存中,再从缓存中获取。值得注意的是,数据存储层的数据结构是服务信息,而缓存中保存的是经过处理加工过的、可以直接传输到 Eureka Client 的数据结构。
2.服务续约:
eureka客户端每30秒发送一次心跳来续约,告知此客户端正常,如果eureka服务端90秒没收到心跳,则将其从注册表删除。
3.获取注册表信息:
客户端通过rest请求从服务端获取注册表信息,缓存在本地,服务调用的时候,会从注册表查找其它服务,用于服务发现,从而发起远程调用。每30秒更新一次
4.服务调用
客户端获取到服务清单后,就可以从中查找其它服务地址进行远程调用,会通过ribbon自动进行负载均衡。
5.eureka高可用:服务同步
配置eureka集群,服务之间会相互注册,客户端的注册信息和续约信息被复制到集群中的所有节点,只要有一个节点活着都可以发挥注册中心的作用。
6.服务剔除
eureka Client 启动的时候创建一个定时任务,Eureka Server会每60秒遍历一次注册表中的信息,把超过90秒还没有续约的服务剔除。
7.自我保护机制
当网络一段时间内发生了异常,所有服务都没能够续约,eureka server会把所有服务剔除,显然不太合理,所以就有了自我保护机制。
服务端如果15分钟内收到的心跳请求率,如果低于85%,可能网络故障,注册表则不再删除,但是提供正89常的服务注册和查询,当恢复正常时,则取消保护机制
8.eureka客户端注册实例为什么这么慢:
(1)默认设置了延时40秒
(2)eureka服务端维护每30秒更新响应缓存
(3)客户端每30秒更新缓存
(4)ribbon从本地获取服务列表时,本身也维护一个缓存,30秒刷新一次
2.Feign远程调用原理
- 首先通过@EnableFeignClients注解开启FeignClient 的功能。只有这个注解存在,才会在程序启动时开启对@FeignClient注解的包扫描。
- 根据Feign的规则实现接口,并在接口上面加上@FeignClient注解。
- 程序启动后,会进行包扫描,扫描所有的@ FeignClient 的注解的类,并将这些信息注入IoC容器中。
- 当接口的方法被调用时,通过JDK的代理来生成具体的RequestTemplate模板对象。
- 根据RequestTemplate再生成Http请求的Request对象。
- Request 对象交给Client去处理,其中Client的网络请求框架可以是HtpURLConnection、HttpClient和OkHttp。
- 最后Client被封装到LoadBalanceClient类,这个类结合类Ribbon做到了负载均衡。

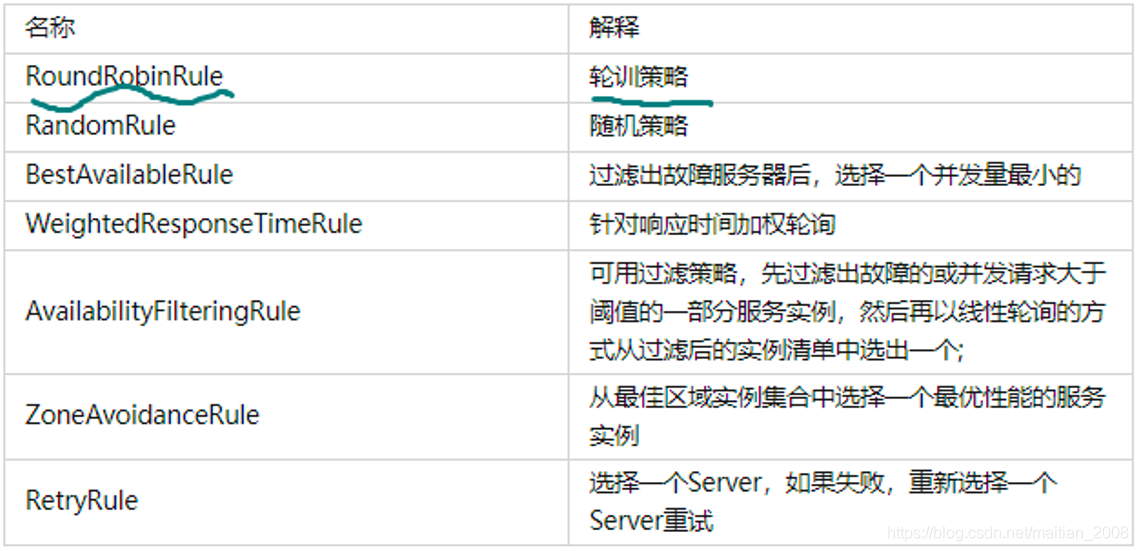
3.Ribbon负载均衡
1.基于Ribbon方式的负载均衡,Netflix默认提供了七种负载均衡策略,
2.@LoadBalanced
1.当使用RestTemplate进行远程服务调用时,假如需要负载均衡,还可以在RestTemplate对象构建时,使用@LoadBalanced对构建RestTemplate的方法进行修饰,例如在ConsumerApplication中构建名字为loadBalancedRestTemplate的RestTemplate对象:
@Bean
@LoadBalanced
public RestTemplate loadBalancedRestTemplate(){
return new RestTemplate();
}2.RestTemplate在发送请求的时候会被LoadBalancerInterceptor拦截,它的作用就是用于RestTemplate的负载均衡,LoadBalancerInterceptor将负载均衡的核心逻辑交给了loadBalancer,核心代码如下所示(了解):
public ClientHttpResponse intercept(final HttpRequest request,
final byte[] body, final ClientHttpRequestExecution execution) throws IOException {
final URI originalUri = request.getURI();
String serviceName = originalUri.getHost();
return this.loadBalancer.execute(serviceName,
requestFactory.createRequest(request, body, execution));
}总结:@LoadBalanced注解是属于Spring,而不是Ribbon的,Spring在初始化容器的时候,如果检测到Bean被@LoadBalanced注解,Spring会为其设置LoadBalancerInterceptor的拦截器。
4.hystrix容错组件
hystrix是一个容错组件,实现了超时机制和断路器模式,提供了熔断和降级。
4.1 降级
降级其实就相当于,当我们向一个服务发起请求,当请求超时了,就会把这次请求记录到服务中,然后就会尝试向其他服务发请求,如果还没成功,就对这次请求进行处理(怎么处理取决于业务需求如)就相当于try catch一样的逻辑,当然hystrix底层使用aop来实现的。
4.2 隔离和限流
Hystrix采取了bulkhead舱壁隔离技术,将外部依赖进行资源隔离,避免任何外部依赖的故障导致本服务崩溃。
舱壁隔离
是说将船体内部空间区隔划分成若干个隔舱,一旦某几个隔舱发生破损进水,水流不会在其间相互流动,如此一来船舶在受损时,依然能具有足够的浮力和稳定性,进而减低立即沉船的危险。

每当向服务发起一个请求时,就是会发起一个http请求,每一个http请求就要开启一个线程,然后等待服务返回信息,这容易导致线程的堆积,所以就可以用http的URI作为一个标识,然后相同的URI可以开启一个线程池,然后线程池中限定线程数,这样就可以设置拒绝策略,当线程池满了,就可以快速的抛出异常或者拒绝请求,用线程池做到线程隔离来达到限流。
4.3 熔断
熔断就是有一个阈值,向服务发起请求后,如果不成功,就会记录次数,然后当连续失败次数达到阈值时,下次请求的时候就会直接把这个服务停止。请求有三种状态,可以请求(开),不可请求(关),还有一个中间状态,相当于半开状态,半开状态是什么意思呢,就是可以尝试着去请求,就可以在关闭状态后一段时间,发一个请求尝试一下是否可以请求成功,如果是吧,继续保持关闭状态,如果请求成功,则变成开放状态。
首先Hystrix发生在请求这一端,所以我们先在consumer端引入Hystrix的依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
<version>2.1.1.RELEASE</version>
</dependency>然后我们来整合一下Hystrix和feign
首先呢,feign有两种方式来指定熔断策略,第一种是直接指定一个类,第二种是用fallbackFactory。区别是一种是可以直接熔断,一种是可以根据不同的类型,进行不同的处理。
首先我们看看第一种,我们可以在@FeignClient注解中加上参数fallback=XXX.class,如下,我们这里的是面向接口编程,可以看我上一篇博客是讲如何用feign的。fallback里面的类也要新建一下。
//这里name是eureka里的服务名
@FeignClient(name = "user-provider",fallback = UserProviderBack.class)
public interface UserAPI extends ProviderApi {
}新建UserProviderBack类然后实现我们的UserAPI,把所有的方法都实现一遍,这种熔断策略是针对于每个请求资源的接口。每个接口都是同的。注意这个类要加上@Component注解,就是把这个类给到spring容器去管理。
@Component
public class UserProviderBack implements UserAPI {
@Override
public String alive() {
return "降级了!!!!!!!!!!!!!";
}
@Override
public HashMap getMapById(Integer id) {
return null;
}
}最后一步就是要配置properties文件,因为默认Feign在请求发生错误时,是不会用Hystrix做服务降级处理。
feign.hystrix.enabled=true还可以用不用fallback,改用fallbackFactory
@FeignClient(name = "user-provider",fallbackFactory = UserProviderBackFactory.class)
public interface UserAPI extends ProviderApi {
}然后新建UserProviderBackFactory这个类,去实现FallbackFactory接口,这个接口我们可以把我们的接口类型传进去,然后重写create方法,如图,这里的throwable就是具体的异常信息,就可以根据不同的错误类型,进行catch,然后处理。
@Component
public class UserProviderBackFactory implements FallbackFactory<UserAPI> {
@Override
public UserAPI create(Throwable throwable) {
return new UserAPI() {
@Override
public String alive() {
return "又又又降级了";
}
@Override
public HashMap getMapById(Integer id) {
return null;
}
};
}
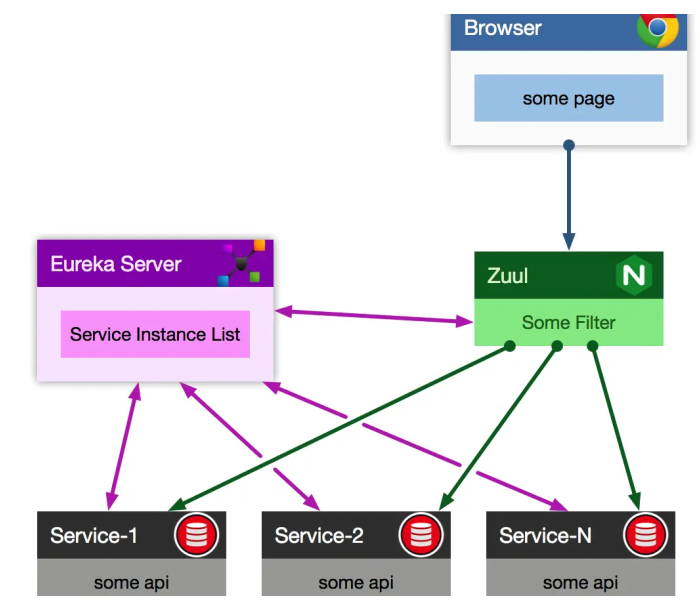
}5.zuul网关
该组件是负责网络路由的,假设你后台部署了几百个服务,现在有个前端兄弟,人家请求是直接从浏览器那儿发过来的。打个比方:人家要请求一下库存服务,你难道还让人家记着这服务的名字叫做inventory-service,并且部署在5台机器上,就算人家肯记住这一个,那你后台可有几百个服务的名称和地址呢?难不成人家请求一个,就得记住一个?哈哈哈
上面这种情况,压根儿是不现实的。所以一般微服务架构中都必然会设计一个网关在里面,像android、ios、pc前端、微信小程序、H5等等,不用去关心后端有几百个服务,就知道有一个网关,所有请求都往网关走,网关会根据请求中的一些特征,将请求转发给后端的各个服务。
5.1 Zuul 网关主要由以下几个组件构成:
- Filter:过滤器,可以在请求被路由前或者之后添加一些处理逻辑。
- Route:路由,将请求路由到不同的后端服务上。
- Ribbon:负载均衡器,Zuul 默认使用 Ribbon 进行负载均衡。
- Hystrix:容错处理器,可以实现限流和熔断机制。
Zuul 的过滤器链是整个网关的核心部分,它由多个过滤器构成,每个过滤器都负责不同的处理逻辑,比如请求的鉴权、转发等操作。过滤器链在处理请求的过程中,会依次执行这些过滤器,从而实现对请求的全生命周期管理,具体流程如下图所示。
5.2 Zuul 网关可以应用于各种场景中,主要包括以下几个方面:
- 负载均衡:Zuul 可以将请求分发到不同的后端服务上,实现负载均衡的功能。
- 路由转发:Zuul 可以根据请求的 URL,将请求转发到不同的后端服务上,实现路由转发的功能。
- 鉴权和安全:Zuul 可以对请求进行鉴权和认证,保障系统的安全性。
- 限流和熔断:Zuul 可以在高并发的情况下,通过限流和熔断机制,保障后端服务的可用性。
6.Apollo配置中心
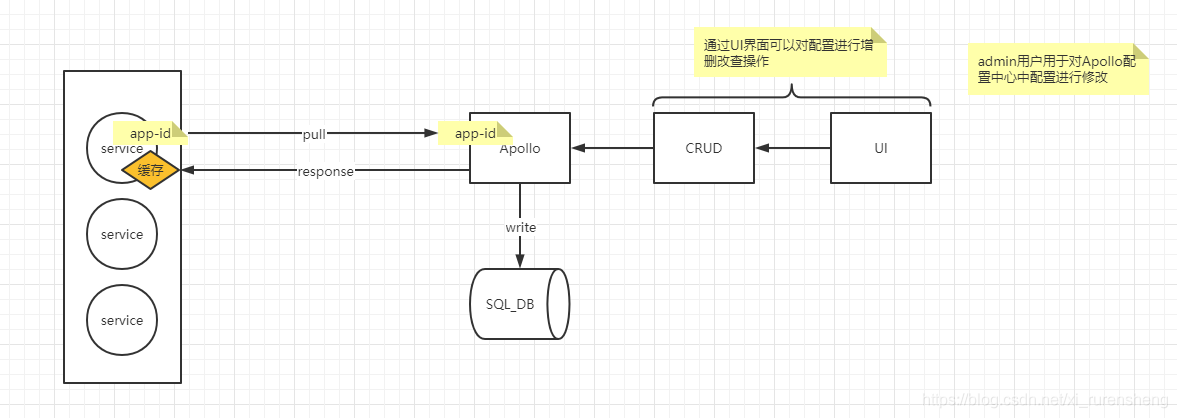
服务通过app-id与Apollo获取配置,获取到配置后会被缓存到本地。
Apollo可以实现WEB页面对配置进行CRUD操作(SpringCloud Config不具备)。
Apollo的配置存储在MySQL中(SpringCloud Config存储于git)
Apollo轻量级,SpringCloud Config则需要依赖于MQ、BUS消息总线
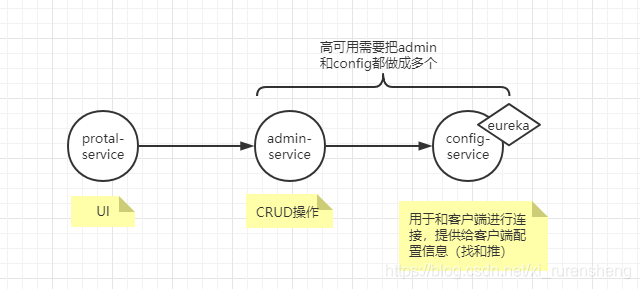
Apollo分为三个服务:portal、admin、config
portal:UI页面
admin:用户、角色管理,CRUD操作
config:用户和服务进行连接,为服务pull和push配置。config服务内置了Eureka
7、流程总结