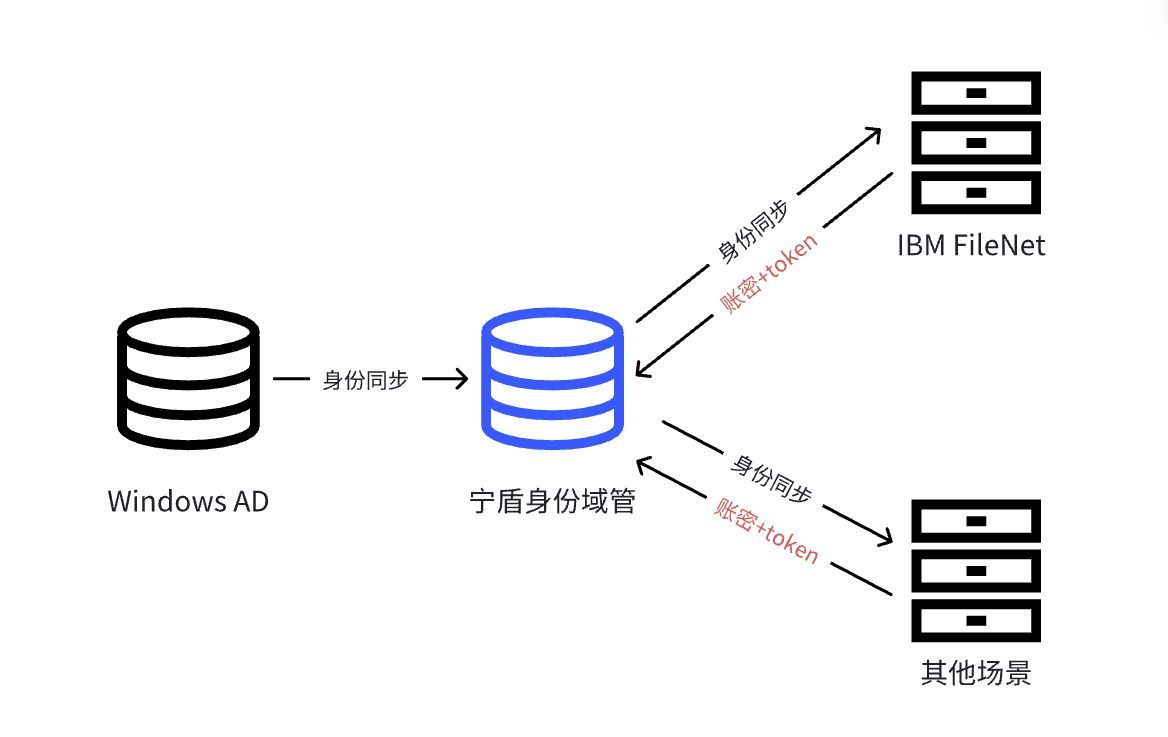
除了时间序列的token是patch了再value embedding,其余的都是普通的扩维embedding,都是nn.parameter可训练的
在UniTS模型中,不同类型的token(如mask token、CLS token、prompt token和时间序列token)的embedding方式如下:
- Mask Token的Embedding方式:
- Mask token的embedding是通过一个线性层(
nn.Linear)实现的,其权重参数在模型初始化时被随机初始化。 - 具体代码在
Model类的初始化函数中,通过nn.ParameterDict来存储不同数据集的mask token:
这个应该就是mask token embedding的方式,就是这样self.mask_tokens = nn.ParameterDict({})
- Mask token的embedding是通过一个线性层(
self.mask_tokens[dataset_name] = torch.zeros(
1, configs_list[i][1]['enc_in'], 1, args.d_model)
- 在
prepare_prompt函数中,mask token被重复并应用到输入序列中:this_mask_prompt = task_prompt.repeat(x.shape[0], 1, task_prompt_num, 1)
-
CLS Token的Embedding方式:
- CLS token的embedding方式与mask token类似,也是通过一个线性层实现的。
- 具体代码在
Model类的初始化函数中,通过nn.ParameterDict来存储不同任务的CLS token:self.cls_tokens = nn.ParameterDict({}) - 在
classification函数中,CLS token被重复并应用到输入序列中:this_function_prompt = task_prompt.repeat(x.shape[0], 1, 1, 1)
-
Prompt Token的Embedding方式:
- Prompt token的embedding方式与CLS token类似,也是通过一个线性层实现的。
- 具体代码在
Model类的初始化函数中,通过nn.ParameterDict来存储不同数据集的prompt token:self.prompt_tokens = nn.ParameterDict({}) - 在
prepare_prompt函数中,prompt token被重复并应用到输入序列中:this_prompt = prefix_prompt.repeat(x.shape[0], 1, 1, 1)
-
时间序列Token的Embedding方式:
- 时间序列token的embedding方式是通过
PatchEmbedding类实现的,该类将时间序列数据分割成固定长度的patch,并应用线性层进行embedding。 - 具体代码在
Model类的tokenize函数中:x = self.patch_embeddings(x) PatchEmbedding类中的value_embedding线性层用于将patch转换为embedding向量:self.value_embedding = nn.Linear(patch_len, d_model, bias=False)
- 时间序列token的embedding方式是通过
总结来说,UniTS模型中不同类型的token的embedding方式都是通过线性层实现的,具体实现细节在Model类的初始化函数和prepare_prompt函数中有所体现。
在代码中,mask token 主要在 pretraining 方法中被使用。具体来说,mask token 在以下步骤中被用到:
-
随机掩码生成:
choose_masking方法根据right_prob决定使用哪种掩码方法(随机掩码或右掩码)。random_masking和right_masking方法生成掩码,其中掩码表示哪些位置应该被掩码(即用mask token替换)。
-
掩码应用:
- 在
pretraining方法中,掩码被应用到输入数据x上。 mask_repeat是一个与x形状相同的掩码矩阵,其中掩码位置为1,非掩码位置为0。x被乘以mask_repeat,使得掩码位置被mask_token替换。
- 在
-
掩码填充:
init_full_input是包含prompt tokens和x的张量。init_mask_prompt是通过prompt2forecat线性层生成的掩码提示。x被乘以mask_repeat,使得掩码位置被init_mask_prompt替换。
-
位置嵌入:
x被加上位置嵌入,以考虑序列的顺序信息。
-
前向传播:
x被传递到backbone(即 Transformer 的基本块)进行前向传播。
-
预测输出:
mask_dec_out和cls_dec_out是通过forecast_head和cls_head生成的预测输出。mask_dec_out是掩码部分的预测输出。cls_dec_out是分类部分的预测输出。
以下是相关代码片段:
def pretraining(self, x, x_mark, task_id, enable_mask=False):
dataset_name = self.configs_list[task_id][1]['dataset']
task_data_name = self.configs_list[task_id][0]
prefix_prompt = self.prompt_tokens[dataset_name]
mask_token = self.mask_tokens[dataset_name]
cls_token = self.cls_tokens[task_data_name]
seq_len = x.shape[1]
x, means, stdev, n_vars, padding = self.tokenize(x)
seq_token_len = x.shape[-2]
# append prompt tokens
x = torch.reshape(
x, (-1, n_vars, x.shape[-2], x.shape[-1]))
# prepare prompts
this_prompt = prefix_prompt.repeat(x.shape[0], 1, 1, 1)
if enable_mask:
mask = self.choose_masking(x, self.right_prob,
self.min_mask_ratio, self.max_mask_ratio)
mask_repeat = mask.unsqueeze(dim=1).unsqueeze(dim=-1)
mask_repeat = mask_repeat.repeat(1, x.shape[1], 1, x.shape[-1])
x = x * (1-mask_repeat) + mask_token * mask_repeat # todo
init_full_input = torch.cat((this_prompt, x), dim=-2)
init_mask_prompt = self.prompt2forecat(
init_full_input.transpose(-1, -2), x.shape[2]).transpose(-1, -2)
# keep the unmasked tokens and fill the masked ones with init_mask_prompt.
x = x * (1-mask_repeat) + init_mask_prompt * mask_repeat
x = x + self.position_embedding(x)
mask_seq = self.get_mask_seq(mask, seq_len+padding)
mask_seq = mask_seq[:, :seq_len]
this_function_prompt = cls_token.repeat(x.shape[0], 1, 1, 1)
x = torch.cat((this_prompt, x, this_function_prompt), dim=2)
x = self.backbone(x, prefix_prompt.shape[2], seq_token_len)
if enable_mask:
mask_dec_out = self.forecast_head(
x[:, :, :-1], seq_len+padding, seq_token_len)
mask_dec_out = mask_dec_out[:, :seq_len]
# De-Normalization from Non-stationary Transformer
mask_dec_out = mask_dec_out * \
(stdev[:, 0, :].unsqueeze(1).repeat(
1, mask_dec_out.shape[1], 1))
mask_dec_out = mask_dec_out + \
(means[:, 0, :].unsqueeze(1).repeat(
1, mask_dec_out.shape[1], 1))
cls_dec_out = self.cls_head(x, return_feature=True)
# detach grad of the forecasting on tokens
fused_dec_out = torch.cat(
(cls_dec_out, x[:, :, self.prompt_num:-1].detach()), dim=2)
cls_dec_out = self.pretrain_head(
fused_dec_out, seq_len+padding, seq_token_len)
cls_dec_out = cls_dec_out[:, :seq_len]
cls_dec_out = cls_dec_out * \
(stdev[:, 0, :].unsqueeze(1).repeat(
1, cls_dec_out.shape[1], 1))
cls_dec_out = cls_dec_out + \
(means[:, 0, :].unsqueeze(1).repeat(
1, cls_dec_out.shape[1], 1))
return cls_dec_out, mask_dec_out, mask_seq
else:
return cls_dec_out
总结来说,mask token 在预训练过程中用于生成掩码序列,并在模型训练时帮助模型学习如何预测被掩码的位置。
CLS token被重复并应用到输入序列中,这怎么理解,为什么要这么做
在BERT模型中,CLS(Classification)token是一个特殊的token,它在输入序列的开头添加。CLS token的主要目的是作为整个输入序列的表示,用于分类任务。在训练过程中,CLS token的输出会被用来预测任务相关的标签。
重复CLS token并应用到输入序列中
在训练过程中,BERT模型会接收一个包含多个输入序列的批次。每个输入序列都会添加一个CLS token,并且这个CLS token会被重复应用到整个输入序列中。这样做的原因是:
-
统一表示:通过将CLS token重复应用到整个输入序列中,我们可以确保每个输入序列都有一个统一的表示,这个表示可以用于分类任务。
-
简化模型结构:在模型的前向传播过程中,我们只需要处理一个输入序列,而不需要为每个输入序列单独处理CLS token。
-
提高模型性能:通过使用CLS token,我们可以更好地捕捉整个输入序列的信息,从而提高模型的性能。
##代码示例
以下是一个简单的代码示例,展示了如何在BERT模型中添加CLS token:
import torch
import torch.nn as nn
import torch.nn.functional as F
# 假设我们有一个简单的BERT模型
class SimpleBERT(nn.Module):
def __init__(self, vocab_size, hidden_size, num_layers, num_heads, dropout):
super(SimpleBERT, self).__init__()
self.embedding = nn.Embedding(vocab_size, hidden_size)
self.encoder = nn.TransformerEncoder(
nn.TransformerEncoderLayer(hidden_size, num_heads, hidden_size, dropout),
num_layers
)
self.fc = nn.Linear(hidden_size, vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# 添加CLS token
cls_token = torch.tensor([0]).unsqueeze(0).to(x.device)
x = torch.cat([cls_token, x], dim=0)
x = self.embedding(x)
x = self.dropout(x)
x = self.encoder(x)
cls_token_output = x[0] # 获取CLS token的输出
x = self.fc(x)
return x, cls_token_output
# 创建模型实例
model = SimpleBERT(vocab_size=10000, hidden_size=512, num_layers=6, num_heads=8, dropout=0.1)
# 假设我们有一个输入序列
input_seq = torch.tensor([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) # 示例输入序列
# 前向传播
outputs, cls_token_output = model(input_seq)
# 计算损失
loss = F.cross_entropy(outputs.view(-1, outputs.size(-1)), input_seq.view(-1))
在这个例子中,我们首先定义了一个简单的BERT模型,然后创建了一个输入序列。在模型的前向传播过程中,我们添加了一个CLS token,并将其重复应用到整个输入序列中。最后,我们获取了CLS token的输出,并计算了交叉熵损失,用于训练模型。
mask token是在时间序列TokenEmbedding后添加时间序列上的还是没有embedding添加的
在代码中,mask token 是在时间序列 TokenEmbedding 后添加的。具体来说,mask token 是在 prepare_prompt 函数中添加的。这个函数根据不同的任务类型(如 forecast, classification, imputation, anomaly_detection)对输入的时间序列进行处理,并在适当的位置添加 mask token。
以下是 prepare_prompt 函数的关键部分,展示了 mask token 是如何添加的:
def prepare_prompt(self, x, n_vars, prefix_prompt, task_prompt, task_prompt_num, task_name=None, mask=None):
x = torch.reshape(
x, (-1, n_vars, x.shape[-2], x.shape[-1]))
# append prompt tokens
this_prompt = prefix_prompt.repeat(x.shape[0], 1, 1, 1)
if task_name == 'forecast':
this_mask_prompt = task_prompt.repeat(
x.shape[0], 1, task_prompt_num, 1)
init_full_input = torch.cat(
(this_prompt, x, this_mask_prompt), dim=-2)
init_mask_prompt = self.prompt2forecat(init_full_input.transpose(
-1, -2), init_full_input.shape[2]-prefix_prompt.shape[2]).transpose(-1, -2)
this_function_prompt = init_mask_prompt[:, :, -task_prompt_num:]
x = torch.cat((this_prompt, x, this_function_prompt), dim=2)
x[:, :, self.prompt_num:] = x[:, :, self.prompt_num:] + \
self.position_embedding(x[:, :, self.prompt_num:])
elif task_name == 'classification':
this_function_prompt = task_prompt.repeat(x.shape[0], 1, 1, 1)
x = x + self.position_embedding(x)
x = torch.cat((this_prompt, x, this_function_prompt), dim=2)
elif task_name == 'imputation':
# fill the masked parts with mask tokens
# for imputation, masked is 0, unmasked is 1, so here to reverse mask
mask = 1-mask
mask = mask.permute(0, 2, 1)
mask = self.mark2token(mask)
mask_repeat = mask.unsqueeze(dim=-1)
mask_token = task_prompt
mask_repeat = mask_repeat.repeat(1, 1, 1, x.shape[-1])
x = x * (1-mask_repeat) + mask_token * mask_repeat
init_full_input = torch.cat((this_prompt, x), dim=-2)
init_mask_prompt = self.prompt2forecat(
init_full_input.transpose(-1, -2), x.shape[2]).transpose(-1, -2)
# keep the unmasked tokens and fill the masked ones with init_mask_prompt.
x = x * (1-mask_repeat) + init_mask_prompt * mask_repeat
x = x + self.position_embedding(x)
x = torch.cat((this_prompt, x), dim=2)
elif task_name == 'anomaly_detection':
x = x + self.position_embedding(x)
x = torch.cat((this_prompt, x), dim=2)
return x
在 prepare_prompt 函数中,根据不同的任务类型,mask token 被添加到时间序列 TokenEmbedding 的不同位置。例如,在 forecast 任务中,mask token 被添加到时间序列的末尾;在 imputation 任务中,mask token 被添加到被掩码的位置。