大家好,我是程序媛雪儿,今天咱们聊mysql的回表查询,在mysql慢查询那篇文章中我们知道,当extra那一列显示,Using index condition,表示直接使用了索引,但是需要回表查询数据,这种情况建立的索引是需要优化的,那么什么是回表查询呢?
一、聚簇索引和非聚簇索引
| 聚簇索引 | 必须有,只有一个 | 叶子节点保存了行数据 |
| 非聚簇索引/二级索引 | 可以存在多个 | 叶子节点存的是对应的主键 |
聚簇索引选取规则
1、如果存在主键,主键索引就是聚簇索引
2、如果没有主键,就选用第一个唯一(UNIQUE)索引作为聚簇索引
3、如果没有主键也没有唯一索引,那么InnoDB会自动生成一个隐藏的rowid作为聚簇索引

上图是根据id生成的聚簇索引,叶子节点存储了所有的数据
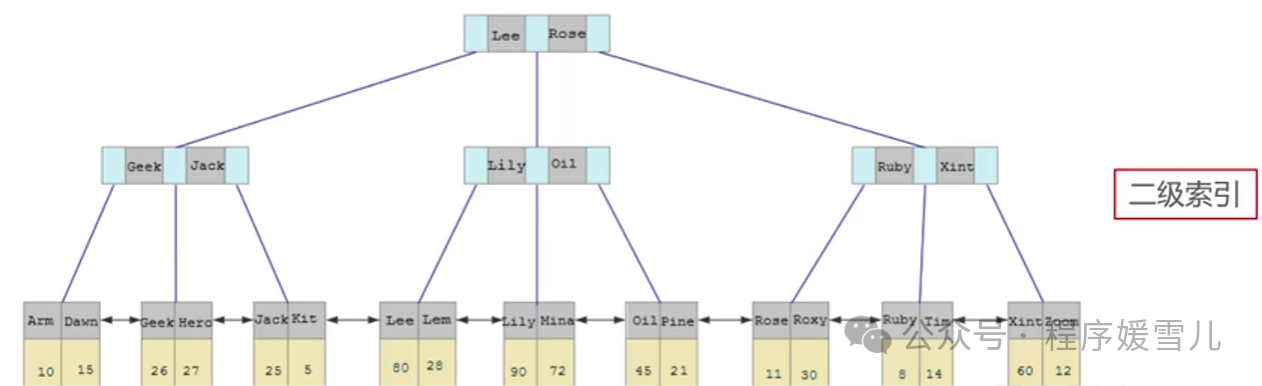
上图是根据name生成的二级索引,叶子节点只存储了id
二、回表查询
如果建立了如上图所示的根据主键(id)生成的聚簇索引,以及根据名称(name)生成的非聚簇索引,在执行 slect * from user where name = 'Arm',这个sql语句时,会先在二级索引中找到Arm的id,再回到聚簇索引中根据拿到的id找到对应的整行数据,至此,sql执行结束。
回表原因:以name作为索引的二级索引里只有id和name可以查到,其他数据无法查到。
那么什么是回表查询呢?
简单说就是无法仅通过索引就会获取到满足需要的列数据,还需要回到原始表中查找额外的数据。
欢迎大家关注我的微信公众号,程序媛雪儿,雪儿会定期在上面发布编程的知识碎片,也有雪儿博客地址,上面有详细系统的笔记,雪儿是全栈,但是公众号目前主要还是发后端的技术,以后可能也会涉及到一些前端的知识,我们下期见,拜拜~