本文首发于 ❄️慕雪的寒舍
学习C++14的那些新特性

为了方便指定使用C++14来编译代码,本文的测试都是在linux下进行的,g++版本如下
$ g++ --version
g++ (GCC) 8.5.0 20210514 (Red Hat 8.5.0-4)
如果你和我一样,也是使用VSC来链接linux进行代码编写,那一定要记得修改C++插件里面的CPP版本,否则默认以C++11来进行语法高亮的话,会把C++11不支持的语法标红,影响我们学习

本文参考 https://zhuanlan.zhihu.com/p/588826142 进行学习;
官方文档 https://zh.cppreference.com/w/cpp/14
1.lambda新特性
C++14给lambda表达式添加了两个新功能
- 参数推断(auto)
- 参数初始化后捕获(可以在
[]对某个新参数进行赋值)
先来复习一下C++11中学习的lambda捕获的基本方式
[val]:表示值传递方式捕捉变量val
[=]:表示值传递方式捕获所有父作用域中的变量(包括this)
[&val]:表示引用传递捕捉变量val
[&]:表示引用传递捕捉所有父作用域中的变量(包括this)
[this]:表示值传递方式捕捉当前的this指针
在C++14中,新增的是下面的这种情况
int a = 30;
// [] 中赋值了一个参数
// () 中可以使用auto关键字来推断参数类型
auto func = [x = 3](auto y) {return x + y; };
cout << func(a) << endl;
运行测试,可以看到成功输出了结果
$ make
g++ test.cpp -o test -std=c++14
$ ./test
33
修改一下类型,也能正常调用
double a = 30.2;
auto func = [x = 3](auto y)
{ return x + y; };
cout << func(a) << endl;
$ ./test
33.2
如果想将赋值参数和原本的捕获方式一起使用,则需要将赋值参数放在[]的最后面
void test_lambda2()
{
int a = 10, b = 20;
int c = 1, d = 3, e = 5;
// 赋值的参数要放在[]的最后面,捕获方式放在前面
auto func6 = [=, f = 30, g = 40]
{
return (a + b + c + d + e + f + g);
};
cout << func6() << endl;
}
$ ./test
109
初始化捕获的好处是可以支持移动捕获了;不然在C++11中,lambda就只能使用赋值捕获和引用捕获
std::unique_ptr<Item> item(new Item());
// std::move改为右值进行赋值后捕获
auto func = [m = std::move(item)] { /* do something */ };
这个新特性的提出,也让lambda成功有了和bind比拼的能力。在C++11中,bind的优势就是在于移动捕获的支持;如今lambda也有了这份能力了,我们可以更灵活地根据场景选用lambda或者bind,而不是只能使用bind了。
2.变量模板
2.1 示例
看清楚这个名字啊!是变量模板,可不是什么函数模板哈!
template<class T>
T pi = T(3.1415926535897932385L); // variable template
// 数字最后的L代表这是一个长浮点型
void test_value_template()
{
cout << pi<double> << endl;
cout << pi<float> << endl;
cout << pi<int> << endl;
}
如上就是一个最最最简单的变量模板,我们在传入对应的类型后,他就会转成我们需要的类型
$ make
g++ test.cpp -o test -std=c++14
$ ./test
3.14159
3.14159
3
2.2 类中使用
当你需要在类中使用模板变量的时候,这个变量必须定义为static;
因为它是模板,我们还可以接用模板本身就有的特性,将这个模板针对某一个类型进行特化
struct Limits
{
template<typename T>
static const T min; // 声明静态成员模板
};
template<typename T>
const T Limits::min = { }; // 定义静态成员模板,全部使用默认值
// 下面三个是模板变量的特化
template<>
const float Limits::min<float> = 4.5;
template<>
const double Limits::min<double> = 5.5;
template<>
const std::string Limits::min<std::string> = "hello";
int main()
{
std::cout << Limits::min<int> << std::endl;
std::cout << Limits::min<float> << std::endl;
std::cout << Limits::min<double> << std::endl;
std::cout << Limits::min<std::string> << std::endl;
return 0;
}
$ ./test
0
4.5
5.5
hello
2.3 和类型转换的区别
这里我又直接定义了一个变量,使用static_cast直接转换变量,看看结果会不会有什么区别
// 数字最后的L代表这是一个长浮点型
template<class T>
T pi = T(3.1415926535897932385L); // 变量模板
long double lpi = 3.1415926535897932385L; // 直接定义长浮点型
void test_value_template()
{
cout << pi<double> << endl;
cout << pi<float> << endl;
cout << pi<int> << endl;
cout << " ----- \n";
cout << static_cast<double>(lpi) << endl;
cout << static_cast<float>(lpi) << endl;
cout << static_cast<int>(lpi) << endl;
}
看上去二者的结果完全相同,那么既然可以直接使用变量类型转换,为什么还要新增一个模板变量呢?
$ ./test
3.14159
3.14159
3
-----
3.14159
3.14159
3
以下内容来自GPT,我觉得它说的很对
定义一个变量并使用数据转换(类型转换)是一种常见的编程方式,但与变量模板有一些区别:
- 通用性: 变量模板允许你通过模板参数来生成多个不同类型的变量,从而在不同的上下文中使用。这使得代码更具通用性和可扩展性,因为你可以为多个类型生成相应的变量。相比之下,直接定义变量并使用数据转换通常只适用于特定的一种数据类型。
- 模板化: 变量模板是一种模板化的方式来生成变量,它遵循 C++ 的模板机制,这意味着你可以使用模板特化、部分特化等技术来定制化生成的变量,以满足不同的需求。而使用数据转换时,你必须显式地执行类型转换,这可能会在代码中引入不必要的重复。
- 编译时计算: 变量模板通常用于在编译时生成值,因此可以在编译阶段进行类型检查和计算。这有助于提高代码的性能和安全性。而数据转换可能在运行时进行,可能会引入一些运行时开销和类型错误的风险。
- 抽象性: 变量模板可以在更高的抽象层次上操作数据,使代码更具表达力和可读性。它允许你以更自然的方式描述某个值与特定类型之间的关系,而不必显式进行类型转换。
总之,变量模板提供了一种更灵活、通用和模板化的方式来生成变量,适用于需要在不同类型上工作的情况。当你需要为多个类型生成特定的变量或值时,变量模板是一种更优雅和强大的选择。
3.constexpr限制放宽
在C++11中被引入的constexpr,可以让编译器在编译程序的期间,就将一部分工作完成,不必等到运行期间再做;在C++11中,constexpr的限制很严格,这导致它并不好用:
- constexpr修饰变量,要求变量必须可以在编译器推导出来
- constexpr修饰函数(返回值),函数内除了可以包含using和typedef指令以及
static_asssert断言外,只能包含一条return语句 - constexpr同时可以修饰构造函数,但也会要求使用这个构造函数的时候,可以在编译器就把相关的内容全推导出来
以下是一个比较基础的C++11中的用例,给该函数设置了constexpr关键字后,该函数就可以在编译期间被计算出结果,再用static_assert在编译期间断言结果是否正确;
constexpr int factorial(int n) {
return (n <= 1) ? 1 : n * factorial(n - 1);
}
int test_constexpr1() {
constexpr int result = factorial(5); // 编译时计算阶乘
static_assert(result == 120, "Factorial of 5 should be 120"); // 编译时断言
cout << result << endl;
return 0;
}
如果在C++11中的constexpr函数内包含其他语句,编译的时候会报错,翻译过来是该函数内部不是一个return返回语句
$ g++ test.cpp -o test -std=c++11
test.cpp: In function ‘constexpr int FuncNew(int)’:
test.cpp:96:1: error: body of ‘constexpr’ function ‘constexpr int FuncNew(int)’ not a return-statement
}
^
c++14中,对constexpr的限制放宽了,允许使用循环、if、switch等等语句,但是主旨还是一样的,需要在编译期间就可以计算出全部内容;限制放宽之后,这个关键字便可以更灵活的使用了。
// 计算前n项和,C++11
constexpr int Func(int n)
{
return n > 0 ? Func(n - 1) + n : 0;
}
// 计算前N项和,C++14
constexpr int FuncNew(int n)
{
if (n <= 0)
{
return 0;
}
int sum = 0;
for (int i = 0; i < n; ++i)
{
sum += i;
}
return sum;
}
4.二进制变量
可以使用0b或者0B开头直接定义二进制变量。
int main()
{
int bit1 = 0b1001;
int bit2 = 0B1011;
std::cout << bit1 << " " << bit2 << std::endl;
}
运行结果如下
$ g++ test.cpp -o test -std=c++14
$ ./test
9 11
我在测试中发现,当我用C++11编译此代码的时候,似乎也没有引发编译错误,难道说0b是在C++11里面就支持了吗?
$ g++ test.cpp -o test -std=c++11
$ ./test
9 11
GPT给出了0B这种二进制变量是在C++14中引入的确认,并提到了为什么会出现上述情况;虽然C++11看上去编译和运行都没有问题,但我们还是得遵循版本,选用正确的版本进行编译,才能根本上避免错误
C++标准通常是向后兼容的,这意味着较新版本的编译器通常会继续支持较旧版本的标准。例如,如果你在使用支持C++11标准的编译器(如g++)时,使用了C++14或更高版本的特性,通常不会引发编译错误,因为这些编译器会尽量向后兼容,以保持现有代码的可编译性。
在你提到的情况下,即使你使用g++编译器以C++11标准编译,它仍然可以理解和接受C++14引入的二进制字面量特性。这是编译器开发者的一种设计选择,以便使代码的迁移更加平滑。但是,为了遵循最佳实践和保持代码的可读性,当你在使用特定C++标准的功能时,最好将编译器选项设置为该标准的版本,以确保代码的可移植性。
5.数字分隔符
在日常生活中使用数字的时候,为了更好的可读性,我们会以3个数组或者4个数组为分割,打一个点
1,0000,0000 一亿
100,000,000
C++14中,也支持了这样的打点,以方便我们更好的看出大数字的位数
void test_num_div()
{
long long big_num1 = 100000000;
long long big_num2 = 100'000'000;
long long big_num3 = 1'0000'0000;
cout << big_num1 << endl;
cout << big_num2 << endl;
cout << big_num3 << endl;
}
需要注意,这样的操作不会对数字本身有任何影响
$ ./test
100000000
100000000
100000000
在C++11中这种语法是不支持的
$ g++ test.cpp -o test -std=c++11
test.cpp:116:29: warning: multi-character character constant [-Wmultichar]
long long big_num2 = 100'000'000;
^~~~~
test.cpp:117:27: warning: multi-character character constant [-Wmultichar]
long long big_num3 = 1'0000'0000;
^~~~~~
test.cpp: In function ‘void test_num_div()’:
test.cpp:116:29: error: expected ‘,’ or ‘;’ before '\x303030'
long long big_num2 = 100'000'000;
^~~~~
test.cpp:117:27: error: expected ‘,’ or ‘;’ before '\x30303030'
long long big_num3 = 1'0000'0000;
^~~~~~
6.返回值auto推导
c++14新增了函数返回值的推导,当返回值声明为auto时,编译器会根据你的return语句推导出你的返回值类型。
template<typename T>
auto Func(T x, T y)
{
return x + y;
}
int main()
{
std::cout << Func(3, 4) << std::endl; // 返回值推导为int
std::cout << Func(3.1, 4.2) << std::endl; // 返回值推导为double
return 0;
}
$ make
g++ test.cpp -o test -std=c++14
$ ./test
7
7.3
这个推导是有限制条件的
1、如果有多个推导语句,那么多个推导的结果必须一致
// 编译报错,第一个return推导为int,第二个return推导为double,两次推导结果不一致
auto Func(int flag)
{
if (flag < 0)
{
return 1;
}
else
{
return 3.14;
}
}
2、如果没有return或者return为void类型,那么auto会被推导为void。
auto f() {} // returns void
auto g() { return f(); } // returns void
auto* x() {} // error: cannot deduce auto* from void
3、一旦在函数中看到return语句,从该语句推导出的返回类型就可以在函数的其余部分中使用,包括在其他return语句中。
auto Sum(int i)
{
if (i <= 1)
{
return i; // 返回值被推导为int
}
else
{
return Sum(i - 1) + i; // sum的返回值已经被推导出来了,所以这里是没有问题的
}
}
但是如果还没被推导出来,那就不能使用。
auto Sum(int i)
{
if (i > 1)
{
return Sum(i - 1) + i;
}
else
{
return i;
}
}
// 编译报错,因为Sum的返回值还没有被推导出来,所以还不能使用
error: use of ‘auto Sum(int)’ before deduction of ‘auto’
4、不能推导初始化列表。
auto func () { return {1, 2, 3}; }
// 编译报错
error: returning initializer list
5、虚函数不能使用返回值推导
struct Item
{
virtual auto Func();
};
// 编译报错
error: virtual function cannot have deduced return type
7.[[deprecated]]标记
这个标记的作用是告知其他人,某个函数被弃用了,不允许继续调用该函数;该字段的好处在于,如果一个方法已经在后续不需要使用了,你可以先给他加上这个关键字,然后再进行其他的代码检查,确认无误后,再将这个函数整体清除;
别人也不需要去检查函数的实现,因为在编译过程中编译器就会告诉你这个函数被弃用;但是编译依旧是成功的!
[[deprecated]]
int test_return_auto()
{
std::cout << Func(3, 4) << std::endl; // 返回值推导为int
std::cout << Func(3.1, 4.2) << std::endl; // 返回值推导为double
return 0;
}
int main()
{
test_return_auto();
return 0;
}
在编译的时候,编译器会警告你,这个函数已经被弃用了;但这里只是警告,编译依旧成功了,所以最终还是需要程序猿去瞅一眼各个警告到底是什么意思。
$ make
g++ test.cpp -o test -std=c++14
test.cpp: In function ‘int main()’:
test.cpp:145:22: warning: ‘int test_return_auto()’ is deprecated [-Wdeprecated-declarations]
test_return_auto();
^
test.cpp:132:5: note: declared here
int test_return_auto()
^~~~~~~~~~~~~~~~
test.cpp:145:22: warning: ‘int test_return_auto()’ is deprecated [-Wdeprecated-declarations]
test_return_auto();
^
test.cpp:132:5: note: declared here
int test_return_auto()
^~~~~~~~~~~~~~~~
std库的新特性
以下是STD库的新增内容!
8.std::make_unique
这个东西在cplusplus网站上找不到释义,所以就去cpp的官网上找了
https://zh.cppreference.com/w/cpp/memory/unique_ptr/make_unique
该函数定义在<memory>头文件中
template< class T, class... Args >
unique_ptr<T> make_unique( Args&&... args );
//(1) (C++14 起) (仅对非数组类型)
template< class T >
unique_ptr<T> make_unique( std::size_t size );
//(2) (C++14 起) (仅对未知边界数组)
template< class T, class... Args >
/* unspecified */ make_unique( Args&&... args ) = delete;
//(3) (C++14 起) (仅对已知边界数组)
作用是构造 T 类型对象并将其包装进 std::unique_ptr;
| 参数 | 说明 |
|---|---|
| args | 将要构造的 T 实例所用的参数列表。 |
| size | 要构造的数组大小 |
- 构造非数组类型
T对象。传递参数args给T的构造函数。此重载只有在T不是数组类型时才会参与重载决议。函数等价于:
unique_ptr<T>(new T(std::forward<Args>(args)...))
- 构造拥有动态大小的数组。值初始化数组元素。此重载只有在
T是未知边界数组时才会参与重载决议。函数等价于:
unique_ptr<T>(new std::remove_extent_t<T>[size]())
使用示例
class test_class{
public:
test_class(int a=-1):_a(a){}
int _a;
};
int main()
{
std::unique_ptr<test_class> pt = std::make_unique<test_class>(3);
cout << pt->_a << endl;
return 0;
}
$ make
g++ test.cpp -o test -std=c++14
$ ./test
3
9.std::shared_timed_mutex与std::shared_lock
c++11引入了多线程线程的一些库,但是是没有读写锁的,因此在c++14引入了读写锁的相关实现(头文件shared_mutex),其实c++14读写锁也还不够完善,直到c++17读写锁这块才算是完备起来。
std::shared_timed_mutex是带超时的读写锁对象,接口还算比较简洁易懂,和之前接触过的其他锁基本一致;内部成员中lock()是写锁,lock_shared()是读锁;
https://zh.cppreference.com/w/cpp/thread/shared_timed_mutex
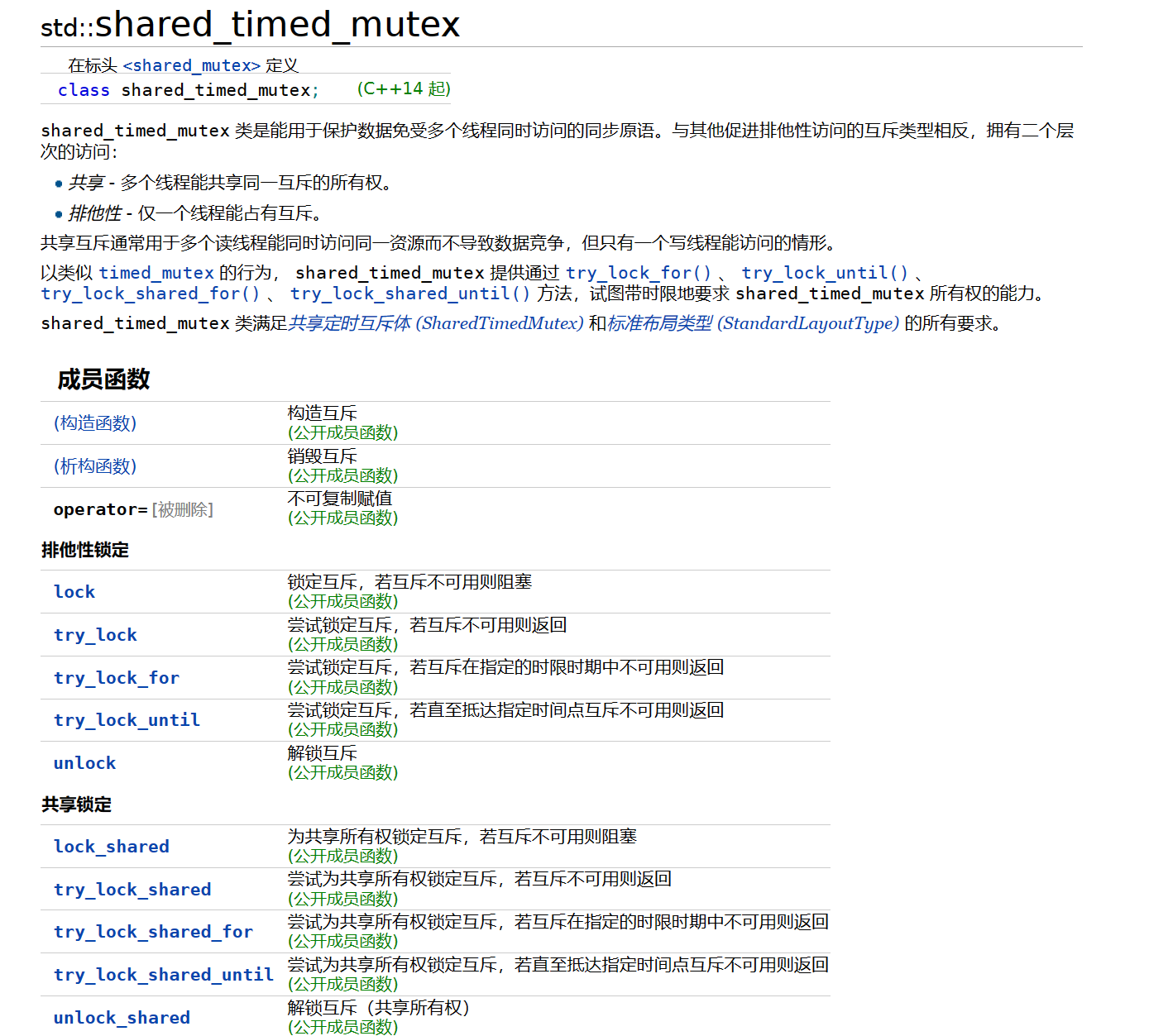
std::shared_lock是加锁的RAII实现,即构造时加锁,析构时解锁;我们使用shared_lock/unique_lock来从shared_timed_mutex中获取锁的时候,就会自动获取读锁和写锁;
std::shared_timed_mutex mutex;
void readOperation() {
// 读锁是多人可以获取的,所以要用shared_lock (读锁)
std::shared_lock<std::shared_timed_mutex> lock(mutex);
std::cout << "Read operation: " << sharedResource << std::endl;
}
void writeOperation() {
// 写锁互斥获取,用unique_lock (写锁)
std::unique_lock<std::shared_timed_mutex> lock(mutex);
sharedResource++;
std::cout << "Write operation: " << sharedResource << std::endl;
}
10.std::exchange
c++14新增了一个接口std::exchange(头文件utility),其实这个也并不算是新增的,因为这个接口其实在c++11的时候就有了,只不过在c++11中作为一个内部函数,不暴露给用户使用,在c++14中才把它暴露出来给用户使用。使用方法也很简单。
int main()
{
std::string s1 = "hello";
std::string s2 = "world";
std::exchange(s1, s2);
std::cout << s1 << " " << s2 << std::endl;
return 0;
}
// 输出结果
world world
我们可以看到,exchange会把第二个值赋值给第一个值,但是不会改变第二个值。我们来看下它的实现吧。
/// Assign @p __new_val to @p __obj and return its previous value.
template <typename _Tp, typename _Up = _Tp>
_GLIBCXX20_CONSTEXPR
inline _Tp
exchange(_Tp& __obj, _Up&& __new_val)
noexcept(__and_<is_nothrow_move_constructible<_Tp>,
is_nothrow_assignable<_Tp&, _Up>>::value)
{ return std::__exchange(__obj, std::forward<_Up>(__new_val)); }
// C++11 version of std::exchange for internal use.
template <typename _Tp, typename _Up = _Tp>
_GLIBCXX20_CONSTEXPR
inline _Tp
__exchange(_Tp& __obj, _Up&& __new_val)
{
_Tp __old_val = std::move(__obj);
__obj = std::forward<_Up>(__new_val);
return __old_val;
}
通过注释我们可以明白含义,它的作用是把第二个值赋值给第一个值,同时返回第一个值的旧值。
除此之外,我们这里说明一个关键的点。exchange的第二个参数是万能引用,所以说他是既可以接收左值,也可以接收右值的,所以我们可以这样来使用。
int main()
{
std::string s1 = "hello";
// 第二个值是纯右值
std::exchange(s1, "world");
std::cout << s1 << std::endl;
std::string s2 = "hello world";
// 第二个值通过move语义转成右值
std::exchange(s1, std::move(s2));
std::cout << s1 << " | " << s2 << std::endl;
return 0;
}
// 输出结果,注意这里s2为空字符串,因为s2的东西已经被移动拷贝给s1了
world
hello world |
11.std::integer_sequence
类模板 std::integer_sequence 表示一个编译时的整数序列。在用作函数模板的实参时,能推导参数包 Ints 并将它用于包展开。
https://zh.cppreference.com/w/cpp/utility/integer_sequence
这个实在是太难懂了,搞不明白是干嘛的,放弃了😥
12.std::quoted
https://zh.cppreference.com/w/cpp/io/manip/quoted
该函数模板位于 <iomanip> 头文件中,用于在输入输出流中处理被引号包围的字符串。它通常用于处理 CSV(逗号分隔值)文件或其他格式,其中字段被引号括起来以处理包含特殊字符(如逗号、换行符等)的情况。
对于cout而言,quoted会将字符串包围在双引号中输出
int test_quorted() {
std::string data = "Hello, \"world\"\n";
// 输出流中使用 std::quoted,会将字符串在"内包围输出
std::cout << std::quoted(data) << std::endl;
return 0;
}
$ ./test
"Hello, \"world\"
"
以下是官方给的一个示例
#include <iostream>
#include <iomanip>
#include <sstream>
int main()
{
std::stringstream ss;
std::string in = "String with spaces, and embedded \"quotes\" too";
std::string out;
auto show = [&](const auto& what) {
&what == &in
? std::cout << "read in [" << in << "]\n"
<< "stored as [" << ss.str() << "]\n"
: std::cout << "written out [" << out << "]\n\n";
};
ss << std::quoted(in);
show(in);
ss >> std::quoted(out);
show(out);
ss.str(""); // clear the stream buffer
in = "String with spaces, and embedded $quotes$ too";
const char delim {'$'};
const char escape {'%'};
ss << std::quoted(in, delim, escape);
show(in);
ss >> std::quoted(out, delim, escape);
show(out);
}
输出
read in [String with spaces, and embedded "quotes" too]
stored as ["String with spaces, and embedded \"quotes\" too"]
written out [String with spaces, and embedded "quotes" too]
read in [String with spaces, and embedded $quotes$ too]
stored as [$String with spaces, and embedded %$quotes%$ too$]
written out [String with spaces, and embedded $quotes$ too]
在给定的代码中,delim 和 escape 是用于指定自定义的分隔符和转义字符的参数。这些参数是用于 std::quoted 函数的重载形式,允许你指定不同于默认引号的字符来包围字符串,并指定一个不同于默认转义字符的字符来转义引号字符。以下是关于这两个参数的详细解释:
delim: 分隔符 在第一个用法中,std::quoted函数使用了三个参数的重载形式:std::quoted(in, delim, escape)。delim参数用于指定包围字符串的分隔符。通常情况下,std::quoted使用双引号作为默认分隔符,但在某些情况下,你可能想要使用其他字符来包围字符串,以避免与字符串本身的字符冲突。在你的代码示例中,分隔符delim被设置为$,这意味着字符串会被包围在$字符内。escape: 转义字符escape参数允许你指定一个字符,用于转义分隔符字符本身。在默认情况下,std::quoted使用双引号"作为转义字符,以确保在字符串中嵌入的引号不会被解释为结束引号。但如果你选择了自定义的分隔符,你可能还需要指定一个不同于默认转义字符的字符来进行转义。在你的代码示例中,转义字符escape被设置为%,这意味着在字符串中,如果你想要表示分隔符$本身,你需要使用%$。
这部分也不是很容易搞明白它是干嘛的,如果面试官问道了就说我不会吧😭