目录
下载地址
Java 21(LTS)
概述
变动说明
1、JEP 441: Switch 的模式匹配(正式特性)
功能进化
Switch 模式匹配
类型标签
null标签
守卫标签
使用enum常量作值
语法总结
2、JEP 440:Record模式(正式特性)
功能进化
Record历史
一个示例类
紧凑型构造函数
使用限制
与record相关的API
3、JEP 431:有序集合
4、JEP 444:虚拟线程(正式特性)
功能进化
创建和使用虚拟线程
1. 使用静态方法
3. 与ExecutorService结合使用
3. 使用虚拟线程工厂
5、细微改动(JDK21)
(1)String中增加2个indexOf方法
(2)Emoji表情字符支持(JDK-8303018)
(3)String和java.util.regex.Pattern中增加splitWithDelimiters()方法(JDK-8305486)
(4)java.net.http.HttpClient自动关闭 (JDK-8267140)
(5)支持GB18030-2022编码 (JDK-8301119)
(6)StringBuilder 和StringBuffer中新增repeat()方法 (JDK-8302323)
(7)正则表达式中支持Emoji表情判断 (JDK-8305107)
(8)使用-XshowSettings:locale 查看Tzdata版本 (JDK-8305950)
(9)java.util.Formatter可能在double 和 float返回不同结果(JDK-8300869)
6、移除的APIs、工具、容器
Java 20
变动说明
1、移除的APIs、工具、容器
Java 19
变动说明
1、移除的APIs、工具、容器
Java 18
变动说明
1、JEP 400:默认UTF-8编码
2、JEP 408:简易Web服务器
jwebserver的参数
示例1
准备页面
启动
3、JEP 421:弃用 Finalization 功能
4、JEP 413:支持在 Java API 文档中加入代码片段
5、移除的APIs、工具、容器
Java 17(LTS)
概述
商用免费
版本说明
变动说明
1、JEP 409:密封的类和接口(正式特性)
功能进化
限制手段
密封类
什么是密封类
示例代码
2、JEP 356:增强型伪随机数生成器。
Java 17 之前的随机数生成
Random
ThreadLocalRandom
SecureRandom
Java 17 的随机数生成
RandomGeneratorFactory
3、JEP 403:强封装JDK 内部API
4、移除的APIs、工具、容器
Java 16
变动说明
1、JEP 395:Record类(正式特性)
功能进化
一个示例类
紧凑型构造函数
使用限制
与record相关的API
2、JEP 394:模式匹配的 instanceof(正式特性)
功能进化
作用域
与运算符结合
3、细微改动
(1)增加Stream.toList()方法(JDK-8180352 )
Stream.toList()和stream.collect(Collectors.toList())的区别
(2)java.time包的格式化支持一天中的数据段(JDK-8180352 )
(3)HttpClient的默认实现返回可取消的Future对象(JDK-8245462)
(4)修正Path.of或Paths.get的第一个参数为null时不会抛出空指针异常的问题(JDK-8254876)
4、移除的APIs、工具、容器
Java 15
变动说明
1、JEP 378:文本块(正式特性)
功能进化
2、JEP 371:隐藏类
隐藏类示例
3、移除的APIs、工具、容器
Java 14
变动说明
1、JEP 361:Switch 表达式(正式特性)
功能进化
2、JEP 358:改进 NullPointerExceptions 提示信息
3、移除的APIs、工具、容器
Java 13
变动说明
1、JEP 353:重构 Socket API
2、移除的APIs、工具、容器
Java 12
变动说明
1、新增String API
indent()
transform()
describeConstable()和resolveConstantDesc()
2、新增Files API
3、新增 NumberFormat API
4、新增 Collectors API
5、移除的APIs、工具、容器
Java 11(LTS)
概述
商用收费
版本说明
补充说明
变动说明
1、JEP 323:局部变量类型推导的升级
局部变量类型推导原则
2、新增String API
isBlank()
lines()
strip()
repeat()
3、新增Files API
writeString()
readString()
isSameFile()
4、JEP 330:运行单文件源码程序
传参
一个文件中多个类
Shebang文件
5、JEP 321:标准 HTTP Client 升级
6、移除的APIs、工具、容器
Java 10
变动说明
1、JEP 286:局部变量的类型推导
简单类型
复杂类型
var的问题
1. var 让类型变得模糊
2. var 无法与 lambda 结合使用
2、删除的工具
3、弃用的API
Java 9
变动说明
1、JEP 222:交互式编程环境Jshell
使用
启动Jshell
执行计算
定义变量
定义方法
定义类
帮助命令:/help
查看定义的变量:/vars
查看定义的函数:/methods
查看定义的类:/types
列出输入源条目:/list
编辑源条目:/edit
删除源条目:/drop
保存文件:/save
打开文件:/open
重置jshell:/reset
查看引入的包:/imports
退出jshell:/exit
2、JEP 269:集合工厂方法
一般写法
Java8的写法
Java9的写法
List.of与asList的区别
3、JEP 213:细微调整
接口支持私有方法
try-with-resources 优化
不支持下划线(_)作为标识符
允许匿名类使用 <>(省略泛型的标记)
4、Stream API 增强
ofNullable
iterate
takeWhile
dropWhile
5、Optional 的增强
ifPresentOrElse
or
stream
6、JEP 110:HTTP2客户端
7、JEP 266:CompletableFuture增强
支持超时机制
支持延迟执行
8、JEP 102:Process API
9、JEP 259:Stack-Walking API
10、JEP 277:增强的@Deprecated注解
11、JEP 261:模块化系统
Oracle JDK和OpenJDK之间的差异
下载地址
最新版本的JDK,你可以从这个链接下载Oracle JDK版本,更多版本下载。
也可以从这个链接下载生产就绪的OpenJDK版本。文件为压缩包,解压并设置环境变量就可以使用。
我们倒着来,先从21讲起。
Java 21(LTS)
概述
JDK 21于 2023 年 9 月 19 日正式发布。该版本是继JDK 17之后最新的长期支持(LTS)版本,将获得至少 8 年的支持。
JEP(Java Enhancement Proposal)Java增强提案
CSR(Compatibility & Specification Review) 兼容性和规范审查
孵化特性:JEP 11 预览特性:JEP 12
变动说明
官网:
Java Platform, Standard Edition Java Language Updates, Release 21
JDK 21 Release Notes, Important Changes, and Information
JDK 21
https://blogs.oracle.com/java/post/the-arrival-of-java-21
更多参考:
JDK 21 Documentation - Home 更多版本:Java Platform, Standard Edition Documentation - Releases
Java Platform, Standard Edition Oracle JDK Migration Guide, Release 21
1、JEP 441: Switch 的模式匹配(正式特性)
JEP 441 (specification/language)
在Java21中,Switch 的模式匹配终于成为一个正式特性。
功能进化
switch的功能进化
| java版本 | 特性类型 | JEP | 特性 |
|---|---|---|---|
| Java 5 | 首次引入,仅支持整型数据类型(如 byte, short, char, 和 int)及枚举类型 | ||
| Java 7 | 支持 String 类型 | ||
| Java 12 | 预览特性 | JEP 325 | 支持Switch表达式(箭头函数) |
| Java 13 | 预览特性 | JEP 354 | 加入 yield 语句来替代 break 语句,用于从 switch 表达式返回值 |
| Java 14 | 正式特性 | JEP 361 | 前2个版本的新特性转为正式特性 |
| Java 17 | 预览特性 | JEP 406 | 引入Switch的模式匹配作为预览特性 |
| Java 18 | 第二次预览 | JEP 420 | 调整优化 |
| Java 19 | 第三次预览 | JEP 427 | 调整优化 |
| Java 20 | 第四次预览 | JEP 433 | 调整优化 |
| Java 21 | 正式特性 | JEP 441 | 成为正式特性 |
Switch 表达式是在 Java 12 中首次作为预览特性引入,而在 Java 13 中对 Switch 表达式做了增强改进:在块中引入了 yield 语句来返回值,而不是使用 break。在Java 14中成为一个标准特性。
Switch 表达式主要功能包括:
-
简化的语法:
switch表达式使用更简洁的箭头语法 (->)编写,可以直接返回一个值,且不再需要break语句。 -
多值匹配:每个
case分支可以同时匹配多个值,使用逗号分隔。 -
yield关键字:当使用switch表达式处理复杂逻辑时,可以根据情况使用yield在代码中返回一个值。
示例代码:
// 旧写法:冗长,切容易出错。漏掉break会穿透到下一条件。
public static String getTypeOfDay0(String name) {
String desp;
switch (name) {
case "稻":
desp = "dào,俗称水稻、大米";
break;
case "黍":
desp = "shǔ,俗称黄米";
break;
case "稷":
desp = "jì,又称粟,俗称小米";
break; // 可以注释掉看看
case "麦":
desp = "mài,俗称小麦";
break;
case "菽":
case "豆":
desp = "shū,俗称大豆";
break;
default:
throw new IllegalStateException("不是五谷之一: " + name);
}
return desp;
}
// java12写法
public static String getTypeOfDay1(String name) {
return switch (name) {
case "稻" -> "dào,俗称水稻、大米";
case "黍" -> "shǔ,俗称黄米";
case "稷" -> "jì,又称粟,俗称小米";
case "麦" -> "mài,俗称小麦";
case "菽", "豆" -> "shū,俗称大豆";
default -> {
throw new IllegalStateException("不是五谷之一: " + name);
}
};
}
// java12写法:条件中需要特殊处理的情况,需要在外部单独定义一个变量接收处理值
public static String getTypeOfDay2_1(String name) {
// 如果不需要特殊处理,可以直接返回
String desp;
switch (name) {
case "稻" -> desp = "dào,俗称水稻、大米";
case "黍" -> desp = "shǔ,俗称黄米";
case "稷" -> desp = "jì,又称粟,俗称小米";
case "麦" -> desp = "mài,俗称小麦";
case "菽", "豆" -> desp = "shū,俗称大豆";
default -> {
// 处理复杂逻辑
if (name == null || name.isEmpty()) {
desp = "名称为空";
} else {
throw new IllegalStateException("不是五谷之一: " + name);
}
}
}
return desp;
}
// java13写法,即java14写法
public static String getTypeOfDay2(String name) {
return switch (name) {
case "稻" -> "dào,俗称水稻、大米";
case "黍" -> "shǔ,俗称黄米";
case "稷" -> "jì,又称粟,俗称小米";
case "麦" -> "mài,俗称小麦";
case "菽", "豆" -> "shū,俗称大豆";
default -> {
// 处理复杂逻辑
if (name == null || name.isEmpty()) {
yield "名称为空";
} else {
throw new IllegalStateException("不是五谷之一: " + name);
}
}
};
}
@Test(priority = 0) // 不指定顺序时默认按字母顺序执行
public void test() {
String name = "稷";
System.out.printf("%s:%s%n", name, getTypeOfDay0(name));
System.out.printf("%s:%s%n", name, getTypeOfDay1(name));
System.out.printf("%s:%s%n", name, getTypeOfDay2(name));
}
在 Java 16 中, JEP 394 将 instanceof的模式匹配发布为正式属性。虽然可以不需要强制转换了,但是仍然需要大量的 if...else。而 Switch 表达式虽然简化了if...else,但是它无法像instanceof一样不需要强制转换。为了解决这个痛点,Java 17引入模式匹配的Switch表达式特性 ,目前该特性为预览特性。
该特性扩展了 switch 表达式和语句,允许它们使用模式匹配,这就意味着我们可以在 switch 的 case 标签中使用模式,如类型模式,使得代码更加灵活和表达性更强。而且也无需进行显式的类型转换了。例如,可以使用 case Integer i 这样的语法来匹配并自动转换类型。
但是,不知道小伙伴们注意没有,Switch 表达式只有一种类型,比如:我有一个诗人类(Poet),它有3个实现类:唐朝诗人(TangPoet)、宋朝诗人(SongPoet)、汉朝诗人(HanPoet),我要根据诗人的类型进行不同处理 :
Poet poet = ... // 诗人
switch (poet.getClass().getName()) {
case "my.poet.TangPoet":
TangPoet tp = (TangPoet) obj;
// 处理唐朝诗人
break;
case "my.poet.SongPoet":
SongPoet sp = (SongPoet) obj;
// 处理宋朝诗人
break;
case "my.poet.HanPoet":
HanPoet hp = (HanPoet) obj;
// 处理汉朝诗人
break;
// 其他类型
}
这个强转显然比较麻烦。所以,参考Java 17中,参考instanceof的模式匹配,为switch表达式引入了模式匹配功能作为预览特性。
Switch 模式匹配
在 Java 17 中,switch 表达式允许使用模式匹配来处理对象类型,这样就可以直接在 switch 语句中检查和转换类型,而不需要额外的 if...else 结构和显式类型转换。
case后面可以跟的标签主要有:
-
类型标签
-
null标签
-
守卫标签
-
enum或常量值
类型标签
允许在 switch 语句的 case 分支中直接匹配对象的类型。例如,case String s 允许你在该分支中直接作为字符串类型的 s 来使用,避免了显式的类型检查和强制类型转换。
举个例子:
@Test
public void switchTest() {
// 不是用switch根据类型判断
Object[] objects = { "Hello", "Java", "17", 666, 0.618 };
for (Object obj : objects) {
if (obj instanceof Integer v) {
System.out.printf("为整型 :%s %n", v);
} else if (obj instanceof Float v) {
System.out.printf("为Float:%s %n", v);
} else if (obj instanceof Double v) {
System.out.printf("为Double:%s %n", v);
} else if (obj instanceof String v) {
System.out.printf("为字符串:%s %n", v);
} else {
System.out.printf("其他类型:%s %n", obj);
}
}
}
我们用 Switch 表达式来改造下:
@Test
public void switchTest() {
Object[] objects = { "Hello", 123, "World", "Java", 3.14, "skjava" };
for (Object obj: objects) {
switch (obj) {
case Integer v -> System.out.println("为整数型:" + v);
case Float v -> System.out.println("为浮点型:" + v);
case Double v -> System.out.println("为双精度浮点数:" + v);
case String v -> System.out.println("为字符串:" + v);
default -> System.out.println("其他类型:" + obj);
}
}
}
相比上面的 if...else 简洁了很多。同时在 Java 17之前,Switch选择器表达式只支持特定类型,即基本整型数据类型byte、short、char和int;对应的装箱形式Byte、Short、Character和Integer;String类;枚举类型。现在有了类型模式,Switch 表达式可以是任何类型啦。
null标签
当switch允许任何引用类型的选择器表达式,那么我们需要留意null的情况,在Java17之前,向switch语句传递一个null值,会抛出一个NullPointerException,现在可以通过类型模式,将 null 检查作为一个单独的case标签来处理,如下:
@Test
public void switchTest() {
Object[] objects = { "Hello", "Java", "17", 142857, 0.618 };
for (Object obj: objects) {
switch (obj) {
case Integer v -> System.out.println("为整数型:" + v);
case Float v -> System.out.println("为浮点型:" + v);
case Double v -> System.out.println("为双精度浮点数:" + v);
case String v -> System.out.println("为字符串:" + v);
case null -> System.out.println("为空值");
default -> System.out.println("其他类型:" + obj);
}
}
}
case null 可以直接匹配值为 null 的情况。
守卫标签
与匹配常量值的case标签不同,模式case标签可以对应多个变量值。这通常会导致switch规则右侧出现条件语句。
根据字符串长度判断诗句是五言绝句还是七言绝句,代码如下:
@Test
public void switchCaseCaseTest() {
String[] poems = { "千山鸟飞绝", "春城无处不飞花", "红豆生南国", "二月春风似剪刀","念奴娇" };
for (String poem : poems) {
switch (poem) {
case null -> System.out.println("为空值");
case String s -> {
if (s.length() == 5)
System.out.printf("五言绝句:%s%n", s);
else if (s.length() == 7)
System.out.printf("七言绝句:%s%n", s);
else
System.out.printf("不知道是啥:%s%n", s);
}
}
}
}
这里的问题是,使用单一模式(即类型)来区分case就只能判断一种情况。我们只能在模式匹配中再通过if……else判断来区分不同的情况,来对一个模式的细化。这时,我们可以是使用switch中的when子句指定模式case标签的条件,例如,case String s when if (s.length() == 5)。表示当类型为String并且字符串长度为5的时候,我们将这种case标签称为守卫case标签,将布尔表达式称为保护。
@Test
public void switchCaseCaseTest() {
String[] poems = { "千山鸟飞绝", "春城无处不飞花", "红豆生南国", "二月春风似剪刀","念奴娇" };
for (String poem : poems) {
switch (poem) {
case null -> System.out.println("为空值");
case String s when s.length() == 5 -> System.out.printf("五言绝句:%s%n", s);
case String s when s.length() == 7 -> System.out.printf("七言绝句:%s%n", s);
case String s -> System.out.printf("不知道是啥:%s%n", s); //剩余情况,仍然走这个
}
}
}
使用守卫标签,我们可以编写更灵活和表达性强的代码。
如果类型确定的情况下,模式匹配可以和常量混合使用,如下:
// 测试enum
@Test
public void switchCaseCaseTest() {
String[] poems = { "千山鸟飞绝", "春城无处不飞花", "红豆生南国", "二月春风似剪刀", "念奴娇", "元曲" };
for (String poem : poems) {
switch (poem) {
case null -> System.out.println("为空值");
// 这里可以使用常量值处理
case "宋词", "元曲" -> System.out.printf("勿忘我:%s%n", poem);
case String s -> {
if (s.length() == 5)
System.out.printf("五言绝句:%s%n", s);
else if (s.length() == 7)
System.out.printf("七言绝句:%s%n", s);
else
System.out.printf("不知道是啥:%s%n", s);
}
}
switch (poem) {
case null -> System.out.println("为空值");
case "宋词", "元曲" -> System.out.printf("勿忘我:%s%n", poem);
case String s when s.length() == 5 -> System.out.printf("五言绝句:%s%n", s);
case String s when s.length() == 7 -> System.out.printf("七言绝句:%s%n", s);
case String s -> System.out.printf("不知道是啥:%s%n", s);
}
}
}
需要注意的是类型确定的时候,可以不使用
default语句。但是如果
switch中对象类型是Object类型,则default语句是必须有的。
使用enum常量作值
这里使用中文做变量名只是演示用,正式开发时,我不建议你使用中文做变量名。
// 测试enum
@Test
public void switchEnumTest() {
WuGu name = WuGu.稷;
System.out.printf("%s:%s%n", name, getWuguByName(name));
}
public String getWuguByName(WuGu name) {
return switch (name) {
case 稻 -> "dào,俗称水稻、大米";
case 黍 -> "shǔ,俗称黄米";
case 稷 -> "jì,又称粟,俗称小米";
case 麦 -> "mài,俗称小麦";
case 菽, 豆 -> "shū,俗称大豆";
default -> {
throw new IllegalStateException("不是五谷之一: " + name);
}
};
}
// 定义枚举类
public enum WuGu {
稻, 黍, 稷, 麦, 菽, 豆;
}
语法总结
switch:
case CaseConstant { , CaseConstant }[常量值,可以有多个]
case null [, default] [null或默认处理]
case Pattern [ Guard ] [模式匹配,可加守护标签]
default [默认处理]
2、JEP 440:Record模式(正式特性)
JEP 440
功能进化
| Java版本 | 特性类型 | JEP | 特性 |
|---|---|---|---|
| Java 14 | 预览特性 | JEP 359 | 引入Record类作为预览特性 |
| Java 15 | 预览特性 | JEP 384 | 修正及优化,语法上同上一版没有区别 |
| Java 16 | 正式特性 | JEP 395 | 成为正式特性 |
| Java 19 | 预览特性 | JEP 405 | 引入Record模式匹配作为预览特性 |
| Java 20 | 第二次预览 | JEP 432 | 调整优化 |
| Java 21 | 正式特性 | JEP 440 | 成为正式特性 |
Java 14引入预览特性 Record类提供一种简洁的语法来声明数据载体的不可变对象,主要是为了解决长期以来在Java中定义纯数据载体类时,代码过于繁琐的问题。在 Java 16 中转为正式特性。
模式匹配最初是用在instanceof上,在 Java 14 作为预览特性引入的,为了解决 instanceof 在做类型匹配时需要进行强制类型转换而导致的代码冗余。
Java 20 引入 Record 模式作为预览特性,它允许在instanceof操作中使用记录模式,直接解构和匹配记录中的字段。
比如有一个记录Record Point(int x, int y),可以使用 Record 模式直接检查和提取 x 和 y 值:
// 创建Record类,As of Java 16
record Point(int x, int y) {}
public class RecordTest {
@Test(priority = 0) // 不指定顺序时默认按字母顺序执行
public void test() {
Point point = new Point(2, 3);
System.out.printf("Point类:%s%n", point);
printSum(point);
}
private void printSum(Object obj) {
if (obj instanceof Point p) {
int x = p.x();
int y = p.y();
System.out.println("方法1:" + (x + y));
}
if (obj instanceof Point(int x, int y)) {
System.out.println("方法2:" + (x + y));
}
}
}
可以对比一下方法1和方法2,可以看出,方法2处理类型转换外,更进一步,直接将Record的变量赋值完成了,极大地简化了代码结构。
该特性使Java 模式匹配能力得到进一步扩展。
模式匹配的真正威力在于它可以优雅地缩放以匹配更复杂的对象图。例如,考虑以下声明:
定义好下面4个类:
//As of Java 16
record Point(int x, int y) {
}
enum Color {
RED, GREEN, BLUE
}
record ColoredPoint(Point point, Color color) {}
record Rectangle(ColoredPoint upperLeft, ColoredPoint lowerRight) {}
测试:
@Test(priority = 0) // 不指定顺序时默认按字母顺序执行
public void test1() {
ColoredPoint leftPoint = new ColoredPoint(new Point(0, 100), Color.BLUE);
ColoredPoint rightPoint = new ColoredPoint(new Point(100, 100), Color.GREEN);
Rectangle rectangle = new Rectangle(leftPoint, rightPoint);
System.out.printf("Rectangle类:%s%n", rectangle);
printUpperLeftColoredPoint(rectangle);
}
private void printUpperLeftColoredPoint(Rectangle r) {
if (r instanceof Rectangle(ColoredPoint ul, ColoredPoint lr)) {
System.out.println(ul.color());
}
}
执行结果:
Rectangle类:Rectangle[upperLeft=ColoredPoint[p=Point[x=0, y=100], c=BLUE], lowerRight=ColoredPoint[p=Point[x=100, y=100], c=GREEN]] BLUE
ColoredPoint值ul本身就是一个Record类,我们可以进一步分解它。因此,Record模式匹配支持嵌套,这允许Record类里面的组件进一步匹配和分解。我们可以在Record模式匹配中成员Record类,并进行模式匹配,代码如下:
private void printUpperLeftColoredPoint(Rectangle r) {
if (r instanceof Rectangle(ColoredPoint ul, ColoredPoint lr)) {
System.out.println(ul.color());
}
// 对ColoredPoint的值进一步分解。同理lr也可以进一步分解
if (r instanceof Rectangle(ColoredPoint(Point p, Color c), ColoredPoint lr)) {
System.out.println(c);
}
}
可以进一步使用var解构属性
private void printUpperLeftColoredPoint(Rectangle r) {
if (r instanceof Rectangle(ColoredPoint ul, ColoredPoint lr)) {
System.out.println(ul.color());
}
// ColoredPoint值ul本身就是一个记录值,我们可能需要进一步分解它。同理lr也可以进一步分解
if (r instanceof Rectangle(ColoredPoint(Point p, Color c), ColoredPoint lr)) {
System.out.println(c);
}
if (r instanceof Rectangle(ColoredPoint(Point(var ulx, var uly), var ulc), var lr)) {
System.out.printf("左上角:X轴坐标: %s,Y轴坐标: %s,颜色: %s,%n", ulx, uly, ulc);
}
}
Record历史
在JDK14中,引入了一个新类java.lang.Record。这是一种新的类型声明。Records 允许我们以一种简洁的方式定义一个类,我们只需要指定其数据内容。对于每个Record类,Java 都会自动地为其成员变量生成 equals(), hashCode(), toString() 方法,以及所有字段的访问器方法(getter),为什么没有 setter方法呢?因为Record的实例是不可变的,它所有的字段都是 final 的,这就意味着一旦构造了一个Record实例,其状态就不能更改了。
与枚举一样,记录也是类的受限形式。它非常适合作为“数据载体”,即包含不想更改的数据的类,以及只包含最基本的方法(如构造函数和访问器)的类。
与前面介绍的其他预览特性一样,这个预览特性也顺应了减少Java冗余代码的趋势,能帮助开发者编写更精炼的代码。
一个示例类
定义一个长方形类
final class Rectangle implements Shape {
final double length;
final double width;
public Rectangle(double length, double width) {
this.length = length;
this.width = width;
}
double length() { return length; }
double width() { return width; }
}
它具有以下特点:
-
所有字段都是
final的 -
只包含构造器:
Rectangle(double length, double width)和2个访问器方法:length()和width()
您可以用record表示此类:
record Rectangle(float length, float width) { }
一个record由一个类名称(在本例中为Rectangle)和一个record属性列表(在本示例中为float length和float width)组成。
record会自动生成以下内容:
-
为每个属性生成一个
private final的字段 -
为每个属性生成一个与组件名相同的访问方法;在本例中,这些方法是
Rectangle::length()和Rectangle::width() -
一个公开的构造函数,参数包括所有属性。构造函数的参数与字段对应。
-
equals()和hashCode()方法的实现,如果两个record类型相同并且属性值相等,那么它们是相等的 -
toString()方法的实现,包括所有字段名和他们的值。
紧凑型构造函数
如果你想在record自定义一个构造函数。那么注意,它与普通的类构造函数不同,record的构造函数没有参数列表:这被称为紧凑型构造函数。
例如,下面的record``HelloWorld有一个字段message。它的自定义构造函数调用Objects.requireNonNull(message),如果message字段是用null值初始化的,则抛出NullPointerException。(自定义记录构造函数仍然会初始化所有字段)
record HelloWorld(String message) {
public HelloWorld {
java.util.Objects.requireNonNull(message);
}
}
测试代码:
@Test
public void test() {
HelloWorld h1 = new HelloWorld(null); // new HelloWorld("天地玄黄宇宙洪荒"); //用这个测试,可以发现字段还是会初始化的
System.out.println(h1);
}
这个测试代码执行报java.lang.NullPointerException异常。
使用限制
以下是record类使用的限制:
-
Record类不能继承任何类 -
Record类不能声明实例字段(与record组件相对应的private final字段除外);任何其他声明的字段都必须是静态的 -
Record类不能是抽象的;它是final的 -
Record类的成员变量是final的
除了这些限制之外,record类的行为类似于常规类:
-
可以在类中声明
record;嵌套record是static的 -
record可以实现接口 -
使用
new关键字实例化record -
您可以在
record的主体中声明静态方法、静态字段、静态初始值设定项、构造函数、实例方法和嵌套类型 -
可以对
record和record的属性进行注释
与record相关的API
java.lang.Class类有2个方法与record相关:
-
RecordComponent[] 返回类型getRecordComponents(): 返回
record的所有字段列表。 -
boolean isRecord(): 与
isEnum()类似,如果是record则返回true。
3、JEP 431:有序集合
JEP 431
引入新的接口来表示有序集合。每个这样的集合具有定义明确的第一元素、第二元素等等,直到最后一个元素。它还提供了统一的API,用于访问它的第一个和最后一个元素,以及以相反的顺序处理它的元素。
“生活只能向后理解,但必须向前生活。”——克尔凯郭尔
原文:"Life can only be understood backwards; but it must be lived forwards."— Kierkegaard
它新增了三个新接口:
-
SequencedCollection
-
SequencedMap :继承自
SequencedCollection和Set -
SequencedSet
这些接口附带了一些新方法,以提供改进的集合访问和操作功能。
下面让我们看一下使用JDK 21之前的集合取第一个和最后一个元素的方法:
| 访问位置 | List | Deque | SortedSet |
|---|---|---|---|
| 取第一个元素 | list.get(0) | deque.getFirst() | set.first() |
| 取最后一个元素 | list.get(list.size()-1) | deque.getLast() | set.last() |
三个集合提供了三类不同的使用方法,非常混乱。但在JDK 21之后,访问第一个和最后一个元素就方法多了:
对于List, Deque, Set这些有序的集合,访问方法变得统一起来:
-
第一个元素:
collection.getFirst() -
最后一个元素:
collection.getLast()
SequencedCollection 接口定义了如下方法:
-
addFirst():将元素添加为此集合的第一个元素。 -
addLast():将元素添加为此集合的最后一个元素。 -
getFirst():获取此集合的第一个元素。 -
getLast():获取此集合的最后一个元素。 -
removeFirst():移除并返回此集合的第一个元素。 -
removeLast():移除并返回此集合的最后一个元素。 -
reversed():倒序此集合。
SequencedMap 接口定义了如下方法:
-
firstEntry():返回此 Map 中的第一个 Entry,如果为空,返回 null。 -
lastEntry():返回此 Map 中的最后一个 Entry,如果为空,返回 null。 -
pollFirstEntry():移除并返回此 Map 中的第一个 Entry。 -
pollLastEntry():移除并返回此 Map 中的最后一个 Entry。 -
putFirst():将 key-value 插入此 Map 中开始位置,如果该 key 已存在则会替换。 -
putLast():将 key-value 插入此 Map 中结尾位置,如果该 key 已存在则会替换。 -
reversed():倒序此Map。 -
sequencedEntrySet():返回此 Map 的 Entry。 -
sequencedKeySet():返回此 Map 的keySet的SequencedSet集合。 -
sequencedValues():返回此 Map 的 value集合的SequencedCollection集合。
测试代码:
@Test
public void sequencedCollectionTest() {
List<String> baseList = List.of("梅", "兰", "竹", "菊", "松");
List<String> list = new ArrayList<>(baseList);
Deque<String> deque = new ArrayDeque<>(baseList); // 队列
LinkedHashSet<String> linkedHashSet = new LinkedHashSet<>(baseList);
TreeSet<String> sortedSet = new TreeSet<>(baseList);
System.out.println("list:" + list); //list:[梅, 兰, 竹, 菊, 松]
System.out.println("deque:" + deque); //deque:[梅, 兰, 竹, 菊, 松]
System.out.println("linkedHashSet:" + linkedHashSet); //linkedHashSet:[梅, 兰, 竹, 菊, 松]
System.out.println("sortedSet:" + sortedSet); //sortedSet:[兰, 松, 梅, 竹, 菊]
System.out.println("===== 取第一个元素 =====");
System.out.println("list.getFirst():" + list.getFirst()); //list.getFirst():梅
System.out.println("deque.getFirst():" + deque.getFirst()); //deque.getFirst():梅
System.out.println("linkedHashSet.getFirst():" + linkedHashSet.getFirst()); //linkedHashSet.getFirst():梅
System.out.println("sortedSet.getFirst():" + sortedSet.getFirst()); //sortedSet.getFirst():兰
System.out.println("===== 取最后一个元素 =====");
System.out.println("list.getLast():" + list.getLast()); //list.getLast():松
System.out.println("deque.getLast():" + deque.getLast()); //deque.getLast():松
System.out.println("linkedHashSet.getLast():" + linkedHashSet.getLast()); //linkedHashSet.getLast():松
System.out.println("sortedSet.getLast():" + sortedSet.getLast()); //sortedSet.getLast():菊
Consumer<SequencedCollection<String>> reversedPrint = sequencedCollection -> {
sequencedCollection.reversed().forEach(x -> System.out.printf("%-2s", x));
System.out.println();
};
System.out.println("===== 倒序 =====");
reversedPrint.accept(list); //松 菊 竹 兰 梅
reversedPrint.accept(deque); //松 菊 竹 兰 梅
reversedPrint.accept(linkedHashSet); //松 菊 竹 兰 梅
reversedPrint.accept(sortedSet); //菊 竹 梅 松 兰
}
@Test
public void sequencedMapTest() {
LinkedHashMap<String, String> linkedHashMap = new LinkedHashMap<>();
linkedHashMap.put("诗仙", "李白");
linkedHashMap.put("诗圣", "杜甫");
linkedHashMap.put("诗鬼", "李贺");
linkedHashMap.put("诗魔", "白居易");
linkedHashMap.put("诗佛", "王维");
linkedHashMap.put("诗杰", "王勃");
linkedHashMap.put("诗骨", "陈子昂");
linkedHashMap.put("诗狂", "王维");
linkedHashMap.put("诗佛", "贺知章");
linkedHashMap.put("诗家天子", "王昌龄");
Consumer<SequencedMap<String, String>> consumer = sequencedMap -> {
sequencedMap.forEach((k, v) -> System.out.printf("%s:%-4s", k, v));
System.out.println();
};
// 诗仙:李白 诗圣:杜甫 诗鬼:李贺 诗魔:白居易 诗佛:贺知章 诗杰:王勃 诗骨:陈子昂 诗狂:王维 诗家天子:王昌龄
consumer.accept(linkedHashMap);
System.out.println("===== 添加到开始 =====");
linkedHashMap.putFirst("诗神", "陆游");
// 诗神:陆游 诗仙:李白 诗圣:杜甫 诗鬼:李贺 诗魔:白居易 诗佛:贺知章 诗杰:王勃 诗骨:陈子昂 诗狂:王维 诗家天子:王昌龄
consumer.accept(linkedHashMap);
System.out.println("===== 添加到最后 =====");
linkedHashMap.putLast("诗奴", "贾岛");
// 诗神:陆游 诗仙:李白 诗圣:杜甫 诗鬼:李贺 诗魔:白居易 诗佛:贺知章 诗杰:王勃 诗骨:陈子昂 诗狂:王维 诗家天子:王昌龄 诗奴:贾岛
consumer.accept(linkedHashMap);
//keys:[诗神, 诗仙, 诗圣, 诗鬼, 诗魔, 诗佛, 诗杰, 诗骨, 诗狂, 诗家天子, 诗奴]
System.out.printf("keys:%s%n", linkedHashMap.sequencedKeySet());
//values:[陆游, 李白, 杜甫, 李贺, 白居易, 贺知章, 王勃, 陈子昂, 王维, 王昌龄, 贾岛]
System.out.printf("values:%s%n", linkedHashMap.sequencedValues());
}
4、JEP 444:虚拟线程(正式特性)
JEP 444 (core-libs/java.lang)
功能进化
| java版本 | 特性类型 | JEP | 特性 |
|---|---|---|---|
| Java 19 | 预览特性 | JEP 425 | 引入了虚拟线程作为预览特性 |
| Java 20 | 第二次预览 | JEP 436 | 优化调整 |
| Java 21 | 正式特性 | JEP 444 | 作为正式特性发布 |
Java 19中初次将虚拟线程引入Java平台。虚拟线程是轻量级线程,可以显著减少编写、维护和观察高吞吐量并发应用程序的工作量。Java 21中,虚拟线程作为正式特性发布。
虚拟线程是JDK而不是系统提供的线程的轻量级实现。它们是用户模式线程((user-mode threads))的一种形式,在其他多线程语言中也很成功(例如Go中的goroutines和Erlang中的processes)。虚拟线程可以比传统线程创建更多数量,并且开销要少得多。这使得在自己的线程中运行单独任务或请求变得更加实用,即使在高吞吐量的程序中也是如此。
它的资源分配和调度由VM实现,而不是操作系统。虚拟线程的主要特点包括:
-
轻量级:与传统线程相比,它更轻量,创建和销毁的成本较低。
-
资源消耗更少:由于不是直接映射到操作系统线程,虚拟线程显著降低了内存和其他资源的消耗。这使得在有限资源下可以创建更多的线程。
-
上下文切换开销更低:由于虚拟线程在用户空间,而不是通过操作系统,所以它的上下文切换开销更低。
-
简化并发编程:由于不受操作系统线程数量的限制,我们可以为每个独立的任务创建一个虚拟线程,简化并发编程模型。
-
提升性能:在 I/O 密集型应用中,虚拟线程能够显著地提升性能。而且由于它们的创建和销毁成本低,能够更加高效地利用系统资源。
但是需要注意:
-
不替代传统线程:虚拟线程不能完全替代传统的操作系统线程,只是一个补充。对于需要密集计算和精细控制线程行为的场景,传统线程仍然是主流。
-
不适用低延迟场景:虚拟线程主要针对高并发和高吞吐量,而不是低延迟。对于需要极低延迟的应用,传统线程可能是更好的选择。
开发人员可以选择使用虚拟线程还是系统线程。下面是一个创建大量虚拟线程的示例程序。该程序首先获得一个ExecutorService,它将为每个提交的任务创建一个新的虚拟线程。然后,它提交10000个任务,并等待所有任务完成:
@Test
public void test() {
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
IntStream.range(0, 1_0000).forEach(i -> {
executor.submit(() -> {
Thread.sleep(Duration.ofSeconds(1));
return i;
});
});
} // executor.close() is called implicitly, and waits
}
这个例子中的任务是简单的代码——睡眠一秒钟——现代硬件可以轻松地支持10000个虚拟线程同时运行这样的代码。在幕后,JDK在少数操作系统线程上运行代码,可能只有一个线程那么少。
如果这个程序使用为每个任务创建一个新平台线程的ExecutorService,比如Executors.newCachedThreadPool(),情况会大不相同。ExecutorService将尝试创建10000个平台线程,从而创建10000个操作系统线程,程序可能会崩溃,具体取决于机器和操作系统。
如果程序使用从池中获取平台线程的ExecutorService,比如Executors.newFixedThreadPool(200),情况也不会好到哪里去。ExecutorService将创建200个平台线程,供所有10000个任务共享,因此许多任务将按顺序运行,而不是并发运行,程序将需要很长时间才能完成。对于该程序,具有200个平台线程的池只能实现每秒200个任务的吞吐量,而虚拟线程(在足够的预热之后)可以实现每秒约10000个任务的流量。此外,如果示例程序中的1_0000更改为100_0000,则该程序将提交1000000个任务,创建1000000个并发运行的虚拟线程,并(在充分预热后)实现每秒约1000000个任务的吞吐量。
如果这个程序中的任务执行一秒钟的计算(例如,对一个巨大的数组进行排序),而不仅仅是睡眠,那么将线程数量增加到处理器内核数量之外将没有帮助,无论它们是虚拟线程还是平台线程。虚拟线程不是更快的线程——它们运行代码的速度并不比平台线程快。它们的存在是为了提高规模(更高的吞吐量),而不是速度(更低的延迟)。它们可能比平台线程多得多,因此利特尔法则(Little's law),它们能够实现更高吞吐量所需的更高并发性。
创建和使用虚拟线程
1. 使用静态方法
public static Thread startVirtualThread(Runnable task)
使用Thread.startVirtualThread方法立即启动虚拟线程,要求传入Runnable对象作为参数,具体如下代码:
@Test
public void test() {
// 1、使用静态构建器方法
Thread.startVirtualThread(() -> {
System.out.println("人之初,性本善");
});
}
2、使用Thread Builder
也可以使用Thread.ofVirtual()来创建,使用start()方法启动
public static Builder.OfVirtual ofVirtual()
这个方法可以设置一些属性,比如:线程名称、未捕获异常处理器等。具体如下代码:
@Test
public void test() {
Thread.ofVirtual().name("kevin-virtual-thread")
.uncaughtExceptionHandler((t, e) -> System.out.println("线程[" + t.getName() + "发生了异常。message:" + e.getMessage()))
.start(() -> {
System.out.println("黎明即起,洒扫庭除");
});
}
也可以定义后先不启动,需要时再手动启动
var vt = Thread.ofVirtual().name("kevin-virtual-thread")
.uncaughtExceptionHandler((t, e) -> System.out.println("线程[" + t.getName() + "发生了异常。message:" + e.getMessage()))
.unstarted(() -> {
System.out.println("黎明即起,洒扫庭除");
});
vt.start();
3. 与ExecutorService结合使用
传统线程使用时,一般使用线程池ExecutorServices而不是直接使用Thread类。虚拟线程也支持线程池,也有对应的ExecutorService来适配。
我们可以使用Executors.newVirtualThreadPerTaskExecutor() 创建一个线程池,该线程池会给每个任务分配一个虚拟线程。这意味着每个提交给线程池的任务都会在自己的虚拟线程上异步执行。
示例:
@Test
public void test1() {
ExecutorService executorService = Executors.newVirtualThreadPerTaskExecutor();
for (int i = 0; i < 100; i++) {
executorService.submit(() -> {
System.out.println("黎明即起,洒扫庭除");
});
}
// 关闭线程池。它会等待正在执行的任务完成,但不会接受新的任务。如果需要立即停止所有任务,可以使用 shutdownNow()。
executorService.shutdown();
}
上述代码在try代码块中创建了一个ExecutorServices,用来为每个提交的任务创建虚拟线程。
开发人员习惯常会将应用程序代码从传统的基于线程池的ExecutorService迁移到虚拟线程上。但是,不要忘记,与任何资源池一样,线程池旨在共享昂贵的资源,但虚拟线程并不昂贵,因此它并不需要池化。 直接使用 Thread.startVirtualThread 或 Thread.ofVirtual().start() 来创建和启动虚拟线程可能还更加简单些。
3. 使用虚拟线程工厂
也可以创建一个虚拟线程的工厂ThreadFactory,使用newThread(Runnable r)方法来创建线程:
示例:
@Test
public void test2() {
ThreadFactory vtFactory = Thread.ofVirtual().name("kevin-vt-test", 0).factory();
Thread factoryThread = vtFactory.newThread(() -> {
System.out.println("黎明即起,洒扫庭除");
});
factoryThread.start();
}
这段代码创建了一个虚拟线程工厂,创建的虚拟线程名称以kevin-vt-test为前缀、以数字结尾(从0开始累加)的名称。
5、细微改动(JDK21)
(1)String中增加2个indexOf方法
core-libs/java.lang
public int indexOf(String str, int beginIndex, int endIndex) public int indexOf(int ch, int beginIndex, int endIndex)
增加了在指定索引位置范围内 character ch, and of String str的方法。
indexOf(int ch, int beginIndex, int endIndex) 方法参考 JDK-8302590, indexOf(String str, int beginIndex, int endIndex) 方法参考 JDK-8303648.
(2)Emoji表情字符支持(JDK-8303018)
JDK-8303018(core-libs/java.lang)
在java.lang.Character类中增加了以下六种新方法,用于获取在emoji表情符号技术标准(UTS#51)中定义的emoji符号:
public static boolean isEmoji(int codePoint) public static boolean isEmojiPresentation(int codePoint) public static boolean isEmojiModifier(int codePoint) public static boolean isEmojiModifierBase(int codePoint) public static boolean isEmojiComponent(int codePoint) public static boolean isEmojiComponent(int codePoint)
码位(码点),对应编码术语中英文中的code point,指的是一个编码标准中为某个字符设定的数值,具有唯一性与一一对应性。码位只规定了一个字符对应的数值,并没有规定这个数值如何存储,视编码方案不同有不同的存储方式。
可以使用下面方法判断内容中是否包含emoji表情
@Test
void testEmoji() {
String str = "赵钱孙李周吴郑王。大家好😃我是一只程序🙈,🧙?";
System.out.println(str);
if (str.codePoints().anyMatch(Character::isEmoji)) {
System.out.println("内容中包含表情");
}
}
(3)String和java.util.regex.Pattern中增加splitWithDelimiters()方法(JDK-8305486)
JDK-8305486 (core-libs/java.lang)
与split()方法只返回分割后的字符串不同,splitWithDelimiters()方法返回字符串和匹配分隔符的交替,而不仅仅是字符串。
示例代码:
@Test
void test4() {
var str = "赵钱孙李,周吴郑王。";
var list = Arrays.asList(str.splitWithDelimiters(",|。", 10));
System.out.printf("splitWithDelimiters:list共%s条记录,%s%n", list.size(), list);
list = Arrays.asList(str.split(",|。", 10));
System.out.printf("split:list共%s条记录,%s%n", list.size(), list);
}
执行结果:
splitWithDelimiters:list共5条记录,[赵钱孙李, ,, 周吴郑王, 。, ] split:list共3条记录,[赵钱孙李, 周吴郑王, ]
可以看到splitWithDelimiters返回了分隔符。
(4)java.net.http.HttpClient自动关闭 (JDK-8267140)
增加了以下方法:
-
void close(): 等待提交的请求完成后优雅地关闭客户端。 -
void shutdown(): 等待正在进行的任务完成后关闭,不再接收新任务。 -
void shutdownNow(): 立刻关闭。 -
boolean awaitTermination(Duration duration): 在给定的持续时间内等待客户端终止;如果客户端终止,则返回true,否则返回false。 -
boolean isTerminated(): 如果客户端已终止,则返回true。
(5)支持GB18030-2022编码 (JDK-8301119)
中国国家标准局(CESI)最近发布了GB18030-2022,这是GB18030标准的更新版本,使GB18030与Unicode 11.0版本同步。这个新标准的Charset实现现在已经取代了之前的2000标准。然而,这一新标准与之前的实施相比有一些不兼容的变化。对于那些需要使用旧映射的人,可以使用新的系统属性jdk.charset.GB18030,将其值设置为2000,可以使用以前JDK版本的GB18030字符集映射,这些映射基于2000标准。
(6)StringBuilder 和StringBuffer中新增repeat()方法 (JDK-8302323)
public StringBuilder repeat(int codePoint, int count) public StringBuilder repeat(CharSequence cs, int count)
增加了上面2个方法
@Test(priority = 4)
void test4() {
StringBuilder sb = new StringBuilder("赵钱孙李,周吴郑王。");
sb.repeat('-', 10); //增加10个-
sb.repeat(128584, 10); //增加10个🙈
System.out.println(sb); // 赵钱孙李,周吴郑王。----------🙈🙈🙈🙈🙈🙈🙈🙈🙈🙈
}
(7)正则表达式中支持Emoji表情判断 (JDK-8305107)
JDK-8303018中支持的Emoji表情判断,在正则表达式中也支持判断,使用\p{IsXXX} 结构进行判断。代码如下:
Pattern.compile("\\p{IsEmoji}").matcher("🉐").matches() //true
Pattern.compile("\\p{IsEmoji_Modifier_Base}").matcher("🉐").matches() //false
(8)使用-XshowSettings:locale 查看Tzdata版本 (JDK-8305950)
-XshowSettings启动器选项得到了增强,可以打印使用JDK配置的tzdata版本。tzdata版本显示为local showSettings选项的一部分。
C:\Users\LD_001>java -XshowSettings:locale -version
Locale settings:
default locale = 中文 (中国)
default display locale = 中文 (中国)
default format locale = 中文 (中国)
tzdata version = 2023c
available locales = , af, af_NA, af_ZA, af_ZA_#Latn, agq, agq_CM, agq_CM_#Latn,
ak, ak_GH, ak_GH_#Latn, am, am_ET, am_ET_#Ethi, ann, ann_NG,
…………
zh__#Hans, zh__#Hant, zu, zu_ZA, zu_ZA_#Latn
java version "21.0.2" 2024-01-16 LTS
Java(TM) SE Runtime Environment (build 21.0.2+13-LTS-58)
Java HotSpot(TM) 64-Bit Server VM (build 21.0.2+13-LTS-58, mixed mode, sharing)
(9)java.util.Formatter可能在double 和 float返回不同结果(JDK-8300869)
double和float通过java.util.Formatter转换为十进制('e', 'E', 'f', 'g', 'G')的实现与在与Double.toString(double)实现保持一致,后者在JDK 19中进行了更改。
因此,在某些特殊情况下,结果可能与早期版本中的结果略有不同。
比如double值2e23格式化为%.16e,新版本中结果为200000000000000e+23,而早期版本产生的结果为1.9999999999999998e+23。但是,如果精确到没有这么高(例如%.15e),那么他们的结果是相同的。
再比如double值9.9e-324通过%.2g格式化,新的结果是9.9e-324,但早期版本生成的结果是1.0e-323。
@Test
void test() {
double d1 = 2e23;
System.out.println(Double.toString(d1));
System.out.println(String.format("%.16e", d1));
}
执行结果
//java21 2.0E23 2.0000000000000000e+23 //早期版本 1.9999999999999998E23 1.9999999999999998e+23 //这个如果改成%.15e,那么结果是 2.000000000000000e+23
6、移除的APIs、工具、容器
参考:
-
Java SE 21中移除的API
-
Java SE 21中移除的工具和容器
Java 20
该版本推出的主要为孵化特性与预览特性,不详细介绍。
变动说明
官网:
Java Platform, Standard Edition Java Language Updates, Release 20
JDK 20 Release Notes, Important Changes, and Information
JDK 20
https://blogs.oracle.com/java/post/the-arrival-of-java-20
更多参考:
JDK 20 Documentation - Home 更多版本:Java Platform, Standard Edition Documentation - Releases
Java Platform, Standard Edition Oracle JDK Migration Guide, Release 20
1、移除的APIs、工具、容器
参考:
-
Java SE 20中移除的API
-
Java SE 20中移除的工具和容器
Java 19
变动说明
官网:
Java Platform, Standard Edition Java Language Updates, Release 19
JDK 19 Release Notes, Important Changes, and Information
JDK 19
https://blogs.oracle.com/java/post/the-arrival-of-java-19
更多参考:
JDK 19 Documentation - Home 更多版本:Java Platform, Standard Edition Documentation - Releases
Java Platform, Standard Edition Oracle JDK Migration Guide, Release 19
该版本推出的主要为孵化特性与预览特性,不详细介绍。
1、移除的APIs、工具、容器
参考:
-
Java SE 19中移除的API
-
Java SE 19中移除的工具和容器
Java 18
变动说明
官网:
Java Platform, Standard Edition Java Language Updates, Release 18
JDK 18 Release Notes, Important Changes, and Information
JDK 18
https://blogs.oracle.com/java/post/the-arrival-of-java-18
更多参考:
JDK 18 Documentation - Home 更多版本:Java Platform, Standard Edition Documentation - Releases
Java Platform, Standard Edition Oracle JDK Migration Guide, Release 18
1、JEP 400:默认UTF-8编码
JEP 400
在Java 18之前,Java的标准字符集(Charset)是根据操作系统的区域设置决定的。这意味着在不同的操作系统和区域设置下,Java程序的行为可能会不同,特别是在处理文本数据时。这种不一致性导致了许多问题,尤其是在跨平台部署和国际化应用程序时。而且 UTF-8 支持几乎所有语言的字符。所以 Java 18 将UTF-8设为Java平台的默认字符集,解决了跨平台的一致性问题。从此以后,Java 在处理文本数据时的行为在各种平台上就更加一致,减少了与字符编码相关的错误和混淆。
2、JEP 408:简易Web服务器
JEP 408
Java 18 引入该特性的主要目的为开发者提供一个轻量级、简单易用的 HTTP 服务器,用于原型制作、测试和开发环境。
Java 18 提供了一个命令:jwebserver。利用这个命令,我们可以启动一个简单的 、最小化的静态 Web 服务器,但是它不支持 CGI 和 Servlet,所以最好的使用场景是用来测试、教育以及演示等需求。
关于jwebserver需要注意:
-
构建目的是应用于测试与教学,不是为了替代
Jetty、Nginx等高级服务器 -
不提供身份验证、访问控制或加密等安全功能
-
仅支持
HTTP/1.1,不支持HTTPS -
仅支持
GET、HEAD请求 -
可以通过命令行、Java类启动
jwebserver的参数

示例1
准备页面
编写一个简单的页面
<html> <head> <meta charset="utf-8"> </head> </body> <h1>天地玄黄,宇宙洪荒</h1> </body> </html>
启动
在页面所在的目录,我这里是mytest中,使用命令行启动。
打开终端,输入jwebserver命令:我这里路径没有设置到Path里,所以使用全路径访问。如果设置了Path,直接使用入jwebserver即可。

访问控制台提示的路径http://127.0.0.1:8000/,就可以看到内容了。
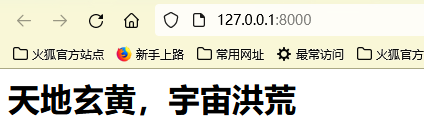
访问时可以看到终端输出日志
127.0.0.1 - - [27/2月/2024:18:53:19 +0800] "GET / HTTP/1.1" 200 - 127.0.0.1 - - [27/2月/2024:18:53:20 +0800] "GET /favicon.ico HTTP/1.1" 404 -
使用java启动
public class JWebServerTest {
public static void main(String[] args) {
System.out.println("服务器启动");
// System.out.println(Paths.get("").toAbsolutePath());
var addr = new InetSocketAddress(8001);
// 路径需要使用绝对路径
var server = SimpleFileServer.createFileServer(addr, Path.of(Paths.get("").toAbsolutePath().toString()),
SimpleFileServer.OutputLevel.INFO);
server.start();
}
}
如果使用jwebserver来实现,实际上就是下面的命令:路径根据直接实际情况调整
jwebserver -p 8001 -d F:\workspacenew2023-04\mylab\mytest[目录的绝对路径] -o info
3、JEP 421:弃用 Finalization 功能
JEP 421
Finalization是 Java 早期版本引入的功能,用于在对象被垃圾收集器销毁之前执行清理操作。然而,这个机制存在诸多问题,比如性能不佳、行为不可预测、容易导致内存泄漏等。
Java 18 将该功能标记为废弃,在将来的版本中移除。 finalize() 将不建议再被使用。目前默认情况下,Finalization仍处于启用状态,但可以禁用以便于早期测试。在将来的版本中,默认情况下它将被禁用,在以后的版本中它将被删除。使用了Finalization功能的库和应用程序的维护人员应该考虑迁移到其他资源管理技术,如try-with-resources statement 和 cleaners。
4、JEP 413:支持在 Java API 文档中加入代码片段
JEP 413 (tools/javadoc(tool))
在 Javadoc 工具中引入了 @snippet 标签,允许文档作者在 API 文档中嵌入源代码片段。
在之前的 Java 文档中,代码示例通常是文本形式,容易过时且难以验证正确性。通过这个特性,我们可以确保示例代码的准确性和时效性。
而且,我们还可以设置高亮(按字符串、按正则)、替换代码片段、源代码引用、链接到 API 文档的其他部分、甚至是自定义的 CSS 样式,使文档更加生动和易于阅读。
在Java 18之前,已经有一个@code标签,可以用于在JavaDoc中编写小段的代码内容,@snipppet对其进行了增强。具体可以参考JEP。
5、移除的APIs、工具、容器
参考:
-
Java SE 18中移除的API
-
Java SE 18中移除的工具和容器
Java 17(LTS)
概述
JDK 17 于 2021 年 9 月 14 日正式发布。
JDK 17 是自 2018 年JDK 11后的第二个长期支持版本,支持到 2029 年 9 月,支持时间长达8年。下一个长期支持版本是 JDK 21,时间为2023 年 9 月,这次长期支持版本发布计划改了,不再是原来的 3 年一次,而是改成了 2 年一次!非长期支持版本还是半年发一次不变。
JDK 17二进制文件在Oracle免费条款和条件许可下,可以在生产中免费使用(参考:Oracle Releases Java 17),也可以免费重新分发。开源协议为NFTC(Oracle No-Fee Terms and Conditions )。

Java 17及以后的版本可以免费使用了,包括商用,更详细的条款可以阅读:Oracle No-Fee Terms and Conditions (NFTC) License Agreement
Java的商用收费始于Java 8 从2019年1月份开始,Oracle JDK开始对Java SE 8之后的版本开始进行商用收费,确切的说是8u201/202之后的版本。如果你用 Java 开发的功能如果是用作商业用途的,如果还不想花钱购买的话,能免费使用的最新版本是8u201/202。当然如果是个人客户端或者个人开发者可以免费试用 Oracle JDK所有的版本。另外Oracle官方其实还提供了一个完全免费开源的JDK版本—— Open JDK,这是免费使用的。中间版本
商用免费
Java的商用收费始于Java 8 ,Oracle JDK宣布从2019年1月份开始对Java SE 8之后的版本开始进行商用收费,确切的说是8u201/202之后的版本。如果你用 Java 开发的功能如果是用作商业用途的,如果还不想花钱购买的话,能免费使用的最新版本是8u201/202。当然如果是个人客户端或者个人开发者可以免费试用 Oracle JDK所有的版本。另外Oracle官方其实还提供了一个完全免费开源的JDK版本—— Open JDK,这是免费使用的。
决定是否收费首先得看JDK使用的是什么协议?
-
BCL协议:即
Oracle Binary Code License Agreement,协议规定你可以使用JDK,但是不能进行修改。私用和商用都可以,但是JDK中的某些商业特性,是需要付费才可以使用的。 -
OTN协议:即
Oracle Technology Network License Agreement,目前新发布的JDK用的都是这个协议,可以私用,商用需要付费。
版本说明
-
Java 8以下版本,仍可免费使用。 -
Java 8(LTS) 部分免费,8u201/202及之前的版本是免费的,之后的商用收费。 -
Java 9是免费的,过渡版本且不再更新不建议使用。 -
Java 10是免费的,过渡版本且不再更新不建议使用。 -
Java 11(LTS) 开始Oracle JDK商用收费,同时提供免费版的Open JDK,下载地址。 -
Java 12、Java 13、Java 14、Java 15、Java 16,全版本商用收费。 -
Java 17(LTS) 开始,再次可以免费使用。 -
免费的JDK有 OpenJDK 、 AdoptOpenJDK 、 Amazon Corretto 、 Azul Zulu 、 BellSoft 、 IBM 、 jClarity 、 Red Hat 、 SAP 、 阿里巴巴 Dragonwell等。
JEP(Java Enhancement Proposal)Java增强提案
CSR(Compatibility & Specification Review) 兼容性和规范审查
变动说明
官网:
Java Platform, Standard Edition Java Language Updates, Release 17
JDK 17 Release Notes, Important Changes, and Information
JDK 17
https://blogs.oracle.com/java/post/the-arrival-of-java-17
更多参考:
JDK 17 Documentation - Home 更多版本:Java Platform, Standard Edition Documentation - Releases
Java Platform, Standard Edition Oracle JDK Migration Guide, Release 17
1、JEP 409:密封的类和接口(正式特性)
JEP 409
功能进化
| Java版本 | 特性类型 | JEP | 特性 |
|---|---|---|---|
| Java 15 | 预览特性 | JEP 360 | 引入了密封类作为预览特性。 |
| Java 16 | 预览特性 | JEP 397 | 第二次预览 |
| Java 17 | 正式特性 | JEP 409 | 成为正式特性 |
密封的类和接口限制了哪些其他类或接口可以扩展或实现它们。
继承,作为面向对象语言的三大特性之一,我们工作过程中经常使用,可以重写父类的方法。我们可以通过继承(extend)来实现类的能力复用、扩展与增强。但有的时候,有些能力我们不希望被继承了去做一些不可预知的扩展。所以,我们需要对继承关系有一些限制的控制手段。而密封类的作用就是限制类的继承。
通常开发项目时,我们会先将接口提供出来,然后根据情况给出不同的基础实现类,子类再基础这些基础实现类进行扩展,我们可能并不希望子类直接继承接口,当然直接继承接口的写法从代码上看没有任何问题,但存在安全隐患。一般我们会通过开发约束对,这样的情况说一些要求,但是这样并不能杜绝这类问题。
限制手段
对于继承能力的控制,目前主要通过下面两种方式控制:
-
final修饰类,这样类就无法被继承了 -
无修饰词修饰的类(即去掉
public修饰符,一般类修饰符是public),可以限制该类只能被同一个包下的类继承。
这两种限制方式的粒度都非常粗,对于一些要求比较细致的场景,是无法满足的。
密封类
为了进一步增强继承的限制能力,Java 15 引入密封类来精确控制类的继承问题 ,目前版本为预览特性。
什么是密封类
密封类的主要目的是提供一种更加精确地控制类继承的方法,通过这种方式,类的设计者可以指定一个类它能够被哪些类继承,它增强了类的封装性和安全性。由于密封类限制了类的继承,所以它使得代码更加可预测和易于维护。
-
密封类(接口)用
sealed修饰,则它的所有子类都必须在同一个模块或者包内,并且这些子类必须被显式地声明为该密封类的直接子类。 -
密封类(接口)的子类可以被声明为
non-sealed(非密封的)或final(最终的)。non-sealed的子类可以被进一步继承,而final的子类则不能。 -
密封类(接口)使用
permits来指定它的子类。
示例代码
这里我们以诗人为例,简化一下,我们这里只讨论汉朝诗人、唐朝诗人、宋朝诗人,代码如下:
// 诗人基类
public class Poet {
}
// 汉朝诗人
public class HanPoet extends Hero{
}
// 唐朝诗人
public class TangPoet extends Poet{
}
// 宋朝诗人
public class SongPoet extends Hero{
}
接下来我们每个类别下面定义2个诗人:
-
汉朝诗人(HanPoet):司马相如(SiMaXiangRu)、班固(BanGu)、
-
唐朝诗人(TangPoet):李白(Libai)、杜甫(DuFu)
-
宋朝诗人(SongPoet):苏轼(SuShi)、陆游(LuYou)
其中李白(Libai)继承自唐朝诗人(TangPoet),我们可以为唐朝诗人做一些公共处理,比如朝代是唐朝,但是有没有这种可能,有程序猿把李白的父类定义为诗人(Poet),那么我们为唐朝诗人定义的那些处理,李白就需要全部重新实现。这显然破坏了继承的实用性。
-
使用
sealed修饰Poet,permits限定子类为:HanPoet、TangPoet、SongPoet,只允许这3个类继承,如下:
// 英雄基类,限制子类为:汉朝诗人(HanPoet)、唐朝诗人(TangPoet)、宋朝诗人(SongPoet)
public sealed class Poet permits HanPoet,TangPoet,SongPoet {
}
-
第二层基类,继续使用
sealed修饰
// 汉朝诗人,限制子类为:司马相如(SiMaXiangRu)、班固(BanGu)
public sealed class HanPoet extends Hero permits SiMaXiangRu,BanGu{
}
// 唐朝诗人,限制子类为:李白(Libai)、杜甫(DuFu)
public sealed class TangPoet extends Hero permits Libai,DuFu{
}
// 宋朝诗人,限制子类为:苏轼(SuShi)、陆游(LuYou)
public sealed class SongPoet extends Hero permits SuShi,LuYou{
}
-
第三层为具体诗人,他们继承第二层的诗人类型,使用
extends继承即可,同时需要表示为non-sealed或final,由于我们不希望类再往下了,所以定义为final:
public final class SiMaXiangRu extends HanPoet{
}
public final class Libai extends TangPoet{
}
public final class SuShi extends SongPoet{
}
这样,子类就不能随便继承父类了。
2、JEP 356:增强型伪随机数生成器。
JEP 356
为伪随机数生成器 (PRNG) 提供新的接口类型和实现。
Java 17 之前的随机数生成
在 Java 17 之前,Java 的随机数生成主要依赖于下面两个核心类:
-
java.util.Random -
java.security.SecureRandom
Random
该类是最最基本的伪随机数生成器,它用于生成一系列不完全是真正随机的数字。Random 提供了多种方法来生成不同类型的随机数,包括整数、长整数、浮点数等。
-
生成随机整数
Random rand = new Random(); int randomInt = rand.nextInt(50); // 生成一个0到49之间的随机整数
-
生成随机浮点数
Random rand = new Random(); double randomDouble = rand.nextDouble(); // 生成一个0.0到1.0之间的随机浮点数
java.util.Random 使用起来很简单,但是它有两个很明显的缺陷。
-
具备可观测性:如果知道种子和算法,完全可以生成相同的随机序列。这在需要高安全性的随机数生成(如加密)时是不合适的。不是真的随机。
-
线程不安全:在多线程环境下,多个线程共享一个
Random实例可能导致竞争条件和数据不一致。
ThreadLocalRandom
ThreadLocalRandom 是一个适用于多线程环境下生成随机数的生成器,它通过为每个线程提供一个独立的随机数生成器实例来解决线程安全问题。
ThreadLocalRandom 使用线程局部变量(Thread-Local)的概念,每个线程访问 ThreadLocalRandom 时,实际上是访问它自己的一个独立实例,这就着不同线程之间的随机数生成器是完全隔离的,而且他们各自内部的种子是完全隔离的,这就保证了随机数生成的独立性,不会因为其他线程的操作而受到影响。
使用方法:
ThreadLocalRandom random = ThreadLocalRandom.current(); // 获取 ThreadLocalRandom 实例 int randomInt = random.nextInt(10, 50); // 生成10到49的随机整数 double randomDouble = random.nextDouble(1.0, 5.0); // 生成1.0到5.0的随机浮点数
虽然 ThreadLocalRandom 解决了 Random 多线程的问题,但是它依然是基于线性同余生成器,导致它生成的随机数序仍然是可预测的。
SecureRandom
由于 java.util.Random 生成的随机数具备可预测性,所以它不适用一些安全要求较高的场景。java.security.SecureRandom 是 Java 提供的一个用于生成加密强度随机数的类,它是 java.security 包的一部分,专门为需要高安全性的应用场景设计,比如加密、安全令牌生成、会话密钥以及数字签名应用。
SecureRandom 生成的随机数具有高安全性,这是因为它使用了更加复杂和不可预测的算法,而且这些算法通常都是基于操作系统提供的随机性源,例如 Unix/Linux 系统的 /dev/random 和 /dev/urandom,或 Windows 的 CryptGenRandom API。所以它更加适用于加密和安全相关的领域。
当然,我们也可以手动设置种子,但是一般不推荐这样做,因为会降低随机数的不可预测性。
SecureRandom 也提供了多种方法来生成不同类型的随机数:
SecureRandom secureRandom = new SecureRandom(); int randomInt = secureRandom.nextInt(); double randomDouble = secureRandom.nextDouble();
我们还可以指定特定的算法来创建 SecureRandom 实例:
SecureRandom secureRandom = SecureRandom.getInstance("SHA1PRNG");
虽然 SecureRandom 生成的随机数具有强大的安全性,但也恰恰如此,导致SecureRandom 在生成随机数时的性能开销比普通的随机数生成器更高。而且在某些情况下,SecureRandom 可能会因为等待足够的熵(随机性)而导致阻塞,尤其是在使用 /dev/random 作为随机性源的系统上。
Java 17 的随机数生成
Java 17 为随机数提供了一个全新的接口 RandomGenerator,该接口是 Java 生成随机数的顶层接口,用于定义所有伪随机数生成器的标准方法。它是所有新的和旧的随机数的顶层接口,包括 java.util.Random。
RandomGenerator 提供了两类生成随机数的方法:
-
生成随机数:例如
nextInt()、nextInt(0, 100)、nextLong() -
生成随机数流:例如
ints()、longs(),这些方法返回的是一个 Stream,对于生成大量随机数比较有用。
RandomGenerator 实例的创建方法如下:
-
使用
RandomGenerator.getDefault()
这是获取 RandomGenerator 实例最简单的方式,它返回默认的RandomGenerator实例,适用于大多数用途。
RandomGenerator randomGenerator = RandomGenerator.getDefault();
-
使用
RandomGenerator.of(String name)
RandomGenerator randomGenerator = RandomGenerator.of("Xoshiro256PlusPlus"); //生成器名称
-
使用工厂类
RandomGeneratorFactory创建
RandomGeneratorFactory<RandomGenerator> factory = RandomGeneratorFactory.of("Xoshiro256PlusPlus"); //随机数类型
RandomGenerator randomGenerator = factory.create();
得到了 RandomGenerator 实例,就可以调用对应的方法获取对应的随机数了。
RandomGeneratorFactory
RandomGeneratorFactory 是创建 RandomGenerator 实例的工具类,可以用它来创建不同类型的 RandomGenerator 实例,包括但不限于传统的线性同余生成器、梅森旋转算法(Mersenne Twister)、Xoroshiro128++ 算法等。同时它还允许用户根据需求定制随机数生成器的行为,比如设置种子或选择特定的算法。
RandomGeneratorFactory 的核心 API 如下:
-
of(String name):根据指定的名称创建一个RandomGenerator实例。 -
all():返回所有可用的RandomGeneratorFactory实例。 -
getDefault():返回默认的RandomGeneratorFactory实例。 -
create():使用工厂的配置创建一个新的RandomGenerator实例。
下面演示如何使用 RandomGeneratorFactory 创建并使用一个随机数生成器:
@Test
public void randomGeneratorFactoryTest() {
// 索取所有可用的 随机数类型
RandomGeneratorFactory.all().forEach(x -> {
System.out.println(x.name());
});
/*L32X64MixRandom
L64X128MixRandom
L64X128StarStarRandom
L64X256MixRandom
L64X1024MixRandom
L128X128MixRandom
L128X256MixRandom
L128X1024MixRandom
SecureRandom
Xoshiro256PlusPlus
Random
Xoroshiro128PlusPlus
SplittableRandom
*/
// 获取一个类型为 Xoroshiro128PlusPlus 的随机数生成器工厂
RandomGeneratorFactory<RandomGenerator> factory = RandomGeneratorFactory.of("Xoroshiro128PlusPlus");
// 使用工厂创建一个随机数生成器
RandomGenerator randomGenerator = factory.create();
// 生成 10 个随机数
randomGenerator.ints().limit(10).forEach(System.out::println);
}
下面是 Java 17 提供 11 个不同的随机数生成器:
| 类名 | 使用的算法 | 特点 |
|---|---|---|
L32X64MixRandom | LXM 算法 | 平衡性能和随机性,适用于多种通用应用 |
L32X64StarStarRandom | StarStar算法 | 提供较好的随机性和性能,适用于需要较快随机数生成的场景 |
L64X128MixRandom | LXM 算法 | 提供更长的周期和更高的随机性,适合更复杂的随机数生成需求 |
L64X128StarStarRandom | StarStar算法 | 结合了较长周期和良好的随机性,适用于复杂应用 |
L64X256MixRandom | LXM 算法 | 长周期,高随机性,适合于需求严格的随机数生成场景 |
L64X1024MixRandom | LXM 算法 | 高随机性,适用于特别需要长周期和高随机性的应用 |
L128X128MixRandom | LXM 算法 | 极长周期,高随机性,适合于高随机质量要求的应用 |
L128X256MixRandom | LXM 算法 | 提供极长的周期和优秀的随机性,适用于极高随机质量要求的应用 |
L128X1024MixRandom | LXM 算法 | 极高的随机性和更大的状态空间,适用于对随机数质量有极端要求的场合 |
Xoshiro256PlusPlus | Xoshiro算法 | 高性能,适用于需要快速、高质量随机数的应用 |
Xoroshiro128PlusPlus | Xoroshiro算法 | 提供良好的性能和随机性平衡,适用于多种应用场景 |
3、JEP 403:强封装JDK 内部API
JEP 403
限制外部对 JDK 内部类进行访问,此更改会使应用程序更安全,并减少对非标准、内部 JDK 实现细节的依赖。
4、移除的APIs、工具、容器
参考:
-
Java SE 17中移除的API
-
JDK 17中移除的特性和容器
Java 16
变动说明
官网:
Java Platform, Standard Edition Java Language Updates, Release 16
JDK 16 Release Notes
JDK 16
更多参考:
JDK 16 Documentation - Home 更多版本:Java Platform, Standard Edition Documentation - Releases
Java Platform, Standard Edition Oracle JDK Migration Guide, Release 16
1、JEP 395:Record类(正式特性)
JEP 395 (tools/javac)
功能进化
| Java版本 | 特性类型 | JEP | 特性 |
|---|---|---|---|
| Java 14 | 预览特性 | JEP 359 | 引入Record类作为预览特性 |
| Java 15 | 预览特性 | JEP 384 | 修正及优化,语法上同上一版没有区别 |
| Java 16 | 正式特性 | JEP 395 | 成为正式特性 |
在JDK14中,引入了一个新类java.lang.Record。这是一种新的类型声明。Records 允许我们以一种简洁的方式定义一个类,我们只需要指定其数据内容。对于每个Record类,Java 都会自动地为其成员变量生成 equals(), hashCode(), toString() 方法,以及所有字段的访问器方法(getter),为什么没有 setter方法呢?因为Record的实例是不可变的,它所有的字段都是 final 的,这就意味着一旦构造了一个Record实例,其状态就不能更改了。
与枚举一样,记录也是类的受限形式。它非常适合作为“数据载体”,即包含不想更改的数据的类,以及只包含最基本的方法(如构造函数和访问器)的类。
与前面介绍的其他预览特性一样,这个预览特性也顺应了减少Java冗余代码的趋势,能帮助开发者编写更精炼的代码。
一个示例类
定义一个长方形类
final class Rectangle implements Shape {
final double length;
final double width;
public Rectangle(double length, double width) {
this.length = length;
this.width = width;
}
double length() { return length; }
double width() { return width; }
}
它具有以下特点:
-
所有字段都是
final的 -
只包含构造器:
Rectangle(double length, double width)和2个访问器方法:length()和width()
您可以用record表示此类:
record Rectangle(float length, float width) { }
一个record由一个类名称(在本例中为Rectangle)和一个record属性列表(在本示例中为float length和float width)组成。
record会自动生成以下内容:
-
为每个属性生成一个
private final的字段 -
为每个属性生成一个与组件名相同的访问方法;在本例中,这些方法是
Rectangle::length()和Rectangle::width() -
一个公开的构造函数,参数包括所有属性。构造函数的参数与字段对应。
-
equals()和hashCode()方法的实现,如果两个record类型相同并且属性值相等,那么它们是相等的 -
toString()方法的实现,包括所有字段名和他们的值。
紧凑型构造函数
如果你想在record自定义一个构造函数。那么注意,它与普通的类构造函数不同,record的构造函数没有参数列表:这被称为紧凑型构造函数。
例如,下面的record``HelloWorld有一个字段message。它的自定义构造函数调用Objects.requireNonNull(message),如果message字段是用null值初始化的,则抛出NullPointerException。(自定义记录构造函数仍然会初始化所有字段)
record HelloWorld(String message) {
public HelloWorld {
java.util.Objects.requireNonNull(message);
}
}
测试代码:
@Test
public void test() {
HelloWorld h1 = new HelloWorld(null); // new HelloWorld("天地玄黄宇宙洪荒"); //用这个测试,可以发现字段还是会初始化的
System.out.println(h1);
}
这个测试代码执行报java.lang.NullPointerException异常。
使用限制
以下是record类使用的限制:
-
Record类不能继承任何类 -
Record类不能声明实例字段(与record组件相对应的private final字段除外);任何其他声明的字段都必须是静态的 -
Record类不能是抽象的;它是final的 -
Record类的成员变量是final的
除了这些限制之外,record类的行为类似于常规类:
-
可以在类中声明
record;嵌套record是static的 -
record可以实现接口 -
使用
new关键字实例化record -
您可以在
record的主体中声明静态方法、静态字段、静态初始值设定项、构造函数、实例方法和嵌套类型 -
可以对
record和record的属性进行注释
与record相关的API
java.lang.Class类有2个方法与record相关:
-
RecordComponent[] 返回类型getRecordComponents(): 返回
record的所有字段列表。 -
boolean isRecord(): 与
isEnum()类似,如果是record则返回true。
2、JEP 394:模式匹配的 instanceof(正式特性)
JEP 394 (tools/javac)
功能进化
| Java版本 | 特性类型 | JEP | 特性 |
|---|---|---|---|
| Java 14 | 预览特性 | JEP 305 | 引入instanceof模式匹配为预览特性 |
| Java 15 | 预览特性 | JEP 375 | 修正及优化,语法上同上一版没有区别 |
| Java 16 | 正式特性 | JEP 394 | 成为正式特性 |
在Java 14之前,instanceof主要用来检查对象的类型,检查匹配后,还需要对其进行类型强转才能使用该类型的变量,这显得很多余也很业余,而且存在手滑转错类型的可能。
Java SE 14为instanceof操作符引入了模式匹配;如果instanceof运算符的结果为true,则判断对象将自动绑定到声明的变量上。
在Java 14 之前的代码写法:
if (obj instanceof String) {
String s = (String) obj;
// 业务逻辑
}
在 Java 14 中,使用模式匹配的 instanceof,这可以被简化为:
if (obj instanceof String s) {
// 直接使用 s
}
如果 obj 是 String 类型的实例,s 就会被自动声明并初始化为 obj 强制转换后的值。这样就避免了单独的类型转换步骤,并使得代码更加简洁易读。
@Test
public void test() {
Object name = "初唐四杰";
// 旧写法
if (name instanceof String) {
String s = (String) name;
// 业务逻辑
System.out.println(s);
}
// 新写法
if (name instanceof String s) {
// 直接使用 s
System.out.println(s);
}
}
作用域
绑定变量的作用域一般是在instanceof内,但是在适当的条件下也可以扩展到外部
@Test
public void test() {
Object name = "初唐四杰";
if (!(name instanceof Integer i)) {
// 是为是!处理,不能直接使用 i,否则编译报错
// System.out.println(i);
return;
}
// 经过前面的return处理,i一定存在。这里可以使用i,你可以尝试将前面的return语句注释掉,看看,这里编译就报错了。因为情况变的不确定了。
System.out.println(i);
}
与运算符结合
// 这个语句可以运行,因为&&是短路运算符,前面满足条件才会走到后面
if (name instanceof Integer in && in > 10) {
// 处理
}
下面的语句编译不通过
// 这个语句编译会报错,因为in不一定存在
if (name instanceof Integer || in > 10) {
// 处理
}
3、细微改动
(1)增加Stream.toList()方法(JDK-8180352 )
java.util.Stream中添加了一个新的方法toList。可以就可以不使用stream.collect(Collectors.toList())来转成List了。生成的是unmodifiableList,不可修改。
@Test
public void test() {
// 出自《笠翁对韵》,与《声律启蒙》、和《训蒙骈句》合称吟诗作对三基。
String str = "天对地,雨对风。大陆对长空。山花对海树,赤日对苍穹。雷隐隐,雾蒙蒙。日下对天中。风高秋月白,雨霁晚霞红。牛女二星河左右,参商两曜斗西东。十月塞边,飒飒寒霜惊戍旅;三冬江上,漫漫朔雪冷渔翁。"
+ "河对汉,绿对红。雨伯对雷公。烟楼对雪洞,月殿对天宫。云叆叇,日曈朦。腊屐对渔蓬。过天星似箭,吐魄月如弓。驿旅客逢梅子雨,池亭人挹藕花风。茅店村前,皓月坠林鸡唱韵;板桥路上,青霜锁道马行踪。"
+ "山对海,华对嵩。四岳对三公。宫花对禁柳,塞雁对江龙。清暑殿,广寒宫。拾翠对题红。庄周梦化蝶,吕望兆飞熊。北牖当风停夏扇,南檐曝日省冬烘。鹤舞楼头,玉笛弄残仙子月;凤翔台上,紫箫吹断美人风。";
List<String> list = Arrays.asList(str.split("。"));
List<String> result = list.stream().filter(s -> s.contains("对")).filter(e -> e.length() > 5).toList();
System.out.printf("list 长度:%s 数据:%s%n", result.size(), result);
}
执行结果
list 长度:6 数据:[天对地,雨对风, 山花对海树,赤日对苍穹, 河对汉,绿对红, 烟楼对雪洞,月殿对天宫, 山对海,华对嵩, 宫花对禁柳,塞雁对江龙]
Stream.toList()和stream.collect(Collectors.toList())的区别
Stream.toList()返回是一个unmodifiableList不可变的List,而使用Stream.collect(Collectors.toList())返回的是一个普通的List,是可以做增删改操作的。
(2)java.time包的格式化支持一天中的数据段(JDK-8180352 )
日期格式新增字母 B 表示一天中的时间段(day period)(转换规则按Unicode Locale Data Markup Language (LDML) Part 4: Dates中的规定),在类 java.time.format.DateTimeFormatter/DateTimeFormatterBuilder 中提供了支持,可以表示一天中的时间段,如"in the morning"(上午)或"at night"(晚上),而不仅仅是am/pm。
// 时间是 13:45,输出:下午,其他还有上午、晚上等
DateTimeFormatter.ofPattern("B").format(LocalTime.now())
(3)HttpClient的默认实现返回可取消的Future对象(JDK-8245462)
默认的HttpClient是通过调用HttpClient.newHttpClient()或调用HttpClient.newBuilder()返回的构建器再调用build方法创建的。默认HttpClient中sendAsync方法的实现现在返回可取消的CompletableFuture对象。对未完成的可取消未来调用cancel(true),会尝试取消HTTP请求,以尽快释放底层资源。可以参考HttpClient::sendAsync方法的API文档。
上面创建HttpClient的方法可能抛出UncheckedIOException异常(JDK-8248006)。
(4)修正Path.of或Paths.get的第一个参数为null时不会抛出空指针异常的问题(JDK-8254876)
之前的版本中,Path.of()和Paths.get()方法的参数有多个时,第一个参数并没有进行不能为null的检查。在这个版本中,如果第一个参数为null则会跟其他参数为null一样抛出NullPointerException。
4、移除的APIs、工具、容器
参考:
-
Java SE 16中移除的API
-
JDK 16中移除的特性和容器
Java 15
变动说明
官网:
Java Platform, Standard Edition Java Language Updates, Release 15
JDK 15 Release Notes
JDK 15
更多参考:
JDK 15 Documentation - Home 更多版本:Java Platform, Standard Edition Documentation - Releases
Java Platform, Standard Edition Oracle JDK Migration Guide, Release 15
1、JEP 378:文本块(正式特性)
JEP 378 (tools/javac)
功能进化
| Java版本 | 特性类型 | JEP | 特性 |
|---|---|---|---|
| Java 13 | 预览特性 | JEP 355 | 引入文本块,支持多行字符串定义 |
| Java 14 | 预览特性 | JEP 368 | 改进文本块,增加了2个转义字符:\(不换行)和\s(空格)。 |
| Java 15 | 正式特性 | JEP 378 | 成为正式特性 |
此功能首次在Java SE 13中预览,在本版本中是永久性的。这意味着它可以用于为Java SE 15编译的任何程序,而无需启用预览功能。
将文本块添加到Java语言中。文本块是一个多行字符串文字,它避免了大多数转义序列的需要,以可预测的方式自动格式化字符串,并在需要时让开发人员控制格式。
文本块是通过三个双引号(""")来定义的,这标志着字符串的开始和结束。在这两个标志之间的所有文本,包括换行符和空格,都将被包含在字符串中。
我们以前从外部copy一段文本串到Java中,会被自动转义,如有一段以下字符串:
<html>
<body>
<p>天地玄黄,宇宙洪荒</p>
</body>
</html>
将其复制到Java的字符串中,会展示成以下内容:
"<html>\n" " <body>\n" " <p>天地玄黄,宇宙洪荒</p>\n" " </body>\n" "</html>\n";
即被自动进行了转义,这样的字符串看起来不是很直观,在JDK 13中,可以使用文本块定义。文本块是通过三个双引号(""")来定义的,这标志着字符串的开始和结束。在这两个标志之间的所有文本,包括换行符和空格,都将被包含在字符串中。
示例代码:
@Test
public void test() {
// 旧写法
String html = "<html>\n" + //
" <body>\n" + //
" <p>天地玄黄,宇宙洪荒</p>\n" + //
" </body>\n" + //
"</html>";
System.out.println(html);
// 新写法。
String html1 = """
<html>
<body>
<p>天地玄黄,宇宙洪荒</p>
</body>
</html>
""";
System.out.println(html1);
}
执行结果:
<html>
<body>
<p>天地玄黄,宇宙洪荒</p>
</body>
</html>
<html>
<body>
<p>天地玄黄,宇宙洪荒</p>
</body>
</html>
2者输出结果是一样的。但是显然新写法写起来也简单,也更易读。
SQL语句也可以使用:
String query = """
SELECT `id`, `name` FROM `users`
WHERE `sex` = 1
ORDER BY `age`, `create_time`;
""";
文本块可以用来定义一段格式化文本,而不需要想原来每一行都需要增加换行处理。
使用文本块好处:
-
多行字符串的简化:在之前的java中编写多行字符串时,只能需要通过使用
\n来实现换行,通过+来连接多个字符串。文本块则只需要将文本通过三个双引号(""")包裹起来。 -
格式化和缩进处理:采用字符串拼接的方式,是无法格式化和缩进处理的,而使用文本块则会自动处理字符串的格式化和缩进。
-
无需处理特殊字符:在之前的java中对于特殊字符需要进行转义处理,但使用文本块后,则不需要。
文本块接受另外两个转义序列,分别是:\ 和 \s:(参见《程序员文本块指南》)。
-
\(终止换行符):这个转义符用于去除行尾换行符,使当前文本的下一行不换行,而是直接拼在当前文本后面。 -
\s(空格标识符):这个转义符表示这是一个空格,在它前面的空格也会保留,如果没有这个标识,前面的空格不会保留。
示例代码:
@Test
public void test() {
// 注意里面三山,文本比较长,不方便阅读。但是如果直接换行会影响最后的输出。这里需要一个标识符,标识一下不换行,换行只为了方便阅读。这就是\的作用。
//
String text = """
三山五岳,汉语成语,泛指华夏大地各名山。
三山,有三种说法:(1)是指华夏远古神话传说中的三条龙脉:喜马拉雅山脉(盘古开天辟地、共工怒触不周山)、昆仑山脉(玉帝居庭玉京山、嫦娥奔月)、天山山脉(西王母娘居庭、女娲炼石补天);\
(2)是道教传说中的三座仙山:蓬莱(蓬壶)、方丈山(方壶)、瀛洲(瀛壶);\
(3)今人所喜欢的三座旅游名山:黄山、庐山、雁荡山。
五岳指东岳泰山、西岳华山、南岳衡山、北岳恒山、中岳嵩山。
三山五岳遍布华夏大地,是中华民族的摇篮,是华夏祖先最早定居的地方,对中华民族的历史文化发展与研究有着重要的意义。
""";
System.out.println(text);
// 这里面五岳后面分别跟了0、1、2、3、4个空格,但是直接输出最后的空格会被忽略掉。
String wuyue1 = """
东岳泰山
西岳华山
南岳衡山
北岳恒山
中岳嵩山
""";
System.out.println(wuyue1);
// 这里面五岳后面分别跟了0、1、2、3、4个空格,但是直接输出最后的空格会被忽略掉。用\s就不会忽略。注意\s本身标识空格,所以实际上最终输出的空格比前面说的多1个。
String wuyue2 = """
东岳泰山\s
西岳华山 \s
南岳衡山 \s
北岳恒山 \s
中岳嵩山 \s
""";
System.out.println(wuyue2);
}
执行结果:
三山五岳,汉语成语,泛指华夏大地各名山。 三山,有三种说法:(1)是指华夏远古神话传说中的三条龙脉:喜马拉雅山脉(盘古开天辟地、共工怒触不周山)、昆仑山脉(玉帝居庭玉京山、嫦娥奔月)、天山山脉(西王母娘居庭、女娲炼石补天);(2)是道教传说中的三座仙山:蓬莱(蓬壶)、方丈山(方壶)、瀛洲(瀛壶);(3)今人所喜欢的三座旅游名山:黄山、庐山、雁荡山。 五岳指东岳泰山、西岳华山、南岳衡山、北岳恒山、中岳嵩山。 三山五岳遍布华夏大地,是中华民族的摇篮,是华夏祖先最早定居的地方,对中华民族的历史文化发展与研究有着重要的意义。 东岳泰山 西岳华山 南岳衡山 北岳恒山 中岳嵩山 东岳泰山 [这是人为添加的一个符号为了显示空格的位置] 西岳华山 [这是人为添加的一个符号为了显示空格的位置] 南岳衡山 [这是人为添加的一个符号为了显示空格的位置] 北岳恒山 [这是人为添加的一个符号为了显示空格的位置] 中岳嵩山 [这是人为添加的一个符号为了显示空格的位置]
2、JEP 371:隐藏类
JEP 371 (core-libs/java.lang.invoke)
Java 15 引入隐藏类主要是为了改进框架和库的开发,尤其是那些需要动态生成类的场景,它主要针对的某些特定的使用场景,而不是为了日常应用程序开发。
隐藏类有如下几个特点:
-
不可见性:隐藏类对Java语言使用者是不可见的,也就是说,它们不能被常规Java代码直接使用或者通过反射API访问。
-
单一加载器局限性:隐藏类是由特定的类加载器加载的,它们的生命周期与加载它们的类加载器紧密相连。这意味着它们只对加载它们的类加载器可见。
-
非继承性:隐藏类不可以被显式继承,也就是说,你不能声明一个类显式地继承一个隐藏类。
-
链接上的限制:虽然隐藏类与常规类一样,会被链接到它们的定义类加载器中,但是它们不会被启动类加载器或任何其他类加载器所链接,这防止了它们被其他类加载器意外加载。
隐藏类的主要使用场景还是框架,他就是为框架而生,是 JVM 内部的一部分,对于 CRUD Boy来说,通常是透明的。
隐藏类示例
第一步:创建类
先创建一个普通的Java类
public class HiddenClassesModel {
public static String print() {
return "初唐四杰";
}
public String show() {
return "王勃、杨炯、卢照邻、骆宾王";
}
}
第二步:编译
编译一下获取class文件。然后使用Base64对文件内编码获取字符串,代码如下:
public static void main(String[] args) throws IOException, URISyntaxException {
String filePath = "HiddenClassesModel.class";
// 1、需要定义父目录的路径,这个需要根据实际路径修改
String parentDir = "target/test-classes/com/ld/mytest/test/java15/hiddenclasses";
System.out.println("Paths路径:" + Paths.get(parentDir, filePath).toAbsolutePath());
byte[] b = Files.readAllBytes(Paths.get(parentDir, filePath));
System.out.println(Base64.getEncoder().encodeToString(b));
// 2、根据当前类动态处理路径
String baseName = HiddenClassesTest.class.getName();
int index = baseName.lastIndexOf('.');
if (index != -1) {
filePath = baseName.substring(0, index).replace('.', '/') + "/" + filePath;
}
System.out.println("文件路径:" + filePath);
System.out.println("资源路径:" + HiddenClassesTest.class.getClassLoader().getResource(filePath));
b = Files.readAllBytes(Paths.get(HiddenClassesTest.class.getClassLoader().getResource(filePath).toURI()));
System.out.println(Base64.getEncoder().encodeToString(b));
}
执行一下,获取到内容如下:
yv66vgAAADwAFwcAAgEAOmNvbS9sZC9teXRlc3QvdGVzdC9qYXZhMTUvaGlkZGVuY2xhc3Nlcy9IaWRkZW5DbGFzc2VzTW9kZWwHAAQBABBqYXZhL2xhbmcvT2JqZWN0AQAGPGluaXQ+AQADKClWAQAEQ29kZQoAAwAJDAAFAAYBAA9MaW5lTnVtYmVyVGFibGUBABJMb2NhbFZhcmlhYmxlVGFibGUBAAR0aGlzAQA8TGNvbS9sZC9teXRlc3QvdGVzdC9qYXZhMTUvaGlkZGVuY2xhc3Nlcy9IaWRkZW5DbGFzc2VzTW9kZWw7AQAFcHJpbnQBABQoKUxqYXZhL2xhbmcvU3RyaW5nOwgAEQEADOWIneWUkOWbm+adsAEABHNob3cIABQBACfnjovli4PjgIHmnajngq/jgIHljaLnhafpgrvjgIHpqoblrr7njosBAApTb3VyY2VGaWxlAQAXSGlkZGVuQ2xhc3Nlc01vZGVsLmphdmEAIQABAAMAAAAAAAMAAQAFAAYAAQAHAAAALwABAAEAAAAFKrcACLEAAAACAAoAAAAGAAEAAAADAAsAAAAMAAEAAAAFAAwADQAAAAkADgAPAAEABwAAACMAAQAAAAAAAxIQsAAAAAIACgAAAAYAAQAAAAYACwAAAAIAAAABABIADwABAAcAAAAtAAEAAQAAAAMSE7AAAAACAAoAAAAGAAEAAAAKAAsAAAAMAAEAAAADAAwADQAAAAEAFQAAAAIAFg==
这个内容就是第一步写的类。
第三步:通过反射加载上面生成的类,并调用隐藏类中的hello函数,代码如下:
@Test
void testHiddenClasses() throws Throwable {
// 1. 加载encode之后的隐藏类。字符串即上面返回的结果
String classStr = "yv66vgAAADwAFwcAAgEAOmNvbS9sZC9teXRlc3QvdGVzdC9qYXZhMTUvaGlkZGVuY2xhc3Nlcy9IaWRkZW5DbGFzc2VzTW9kZWwHAAQBABBqYXZhL2xhbmcvT2JqZWN0AQAGPGluaXQ+AQADKClWAQAEQ29kZQoAAwAJDAAFAAYBAA9MaW5lTnVtYmVyVGFibGUBABJMb2NhbFZhcmlhYmxlVGFibGUBAAR0aGlzAQA8TGNvbS9sZC9teXRlc3QvdGVzdC9qYXZhMTUvaGlkZGVuY2xhc3Nlcy9IaWRkZW5DbGFzc2VzTW9kZWw7AQAFcHJpbnQBABQoKUxqYXZhL2xhbmcvU3RyaW5nOwgAEQEADOWIneWUkOWbm+adsAEABHNob3cIABQBACfnjovli4PjgIHmnajngq/jgIHljaLnhafpgrvjgIHpqoblrr7njosBAApTb3VyY2VGaWxlAQAXSGlkZGVuQ2xhc3Nlc01vZGVsLmphdmEAIQABAAMAAAAAAAMAAQAFAAYAAQAHAAAALwABAAEAAAAFKrcACLEAAAACAAoAAAAGAAEAAAADAAsAAAAMAAEAAAAFAAwADQAAAAkADgAPAAEABwAAACMAAQAAAAAAAxIQsAAAAAIACgAAAAYAAQAAAAYACwAAAAIAAAABABIADwABAAcAAAAtAAEAAQAAAAMSE7AAAAACAAoAAAAGAAEAAAAKAAsAAAAMAAEAAAADAAwADQAAAAEAFQAAAAIAFg==";
byte[] classInBytes = Base64.getDecoder().decode(classStr);
Lookup lookup = MethodHandles.lookup();
Class<?> hiddenCls = lookup.defineHiddenClass(classInBytes, true, MethodHandles.Lookup.ClassOption.NESTMATE).lookupClass();
// 输出类名
System.out.println(hiddenCls.getName());
// 输出类有哪些函数
for (Method method : hiddenCls.getDeclaredMethods()) {
System.out.println(method.getName());
}
// 2. 调用hello函数
var mh = lookup.findStatic(hiddenCls, "print", MethodType.methodType(String.class));
String result = (String) mh.invokeExact();
System.out.println("print方法执行:" + result);
// 创建隐藏类的实例
Object hiddenClsInstance = hiddenCls.getConstructor().newInstance();
mh = lookup.findVirtual(hiddenCls, "show", MethodType.methodType(String.class));
// 调用 print 方法
result = (String) mh.invoke(hiddenClsInstance);
System.out.println("show方法执行:" + result);
}
执行结果:
print show print方法执行:初唐四杰 show方法执行:王勃、杨炯、卢照邻、骆宾王
整体就分为两个步骤:
-
生成字节码。
-
反射调用方法。使用
Lookup、MethodHandles和MethodType来创建隐藏类和调用方法。
这里的classStr内容就是上一步我们处理好的隐藏类内容,先通过Base64将该内容解码,然后通过反射机制来将这个隐藏类的代理创建出来。
可以看到这里创建隐藏类的时候用的是java.lang.invoke.MethodHandles.Lookup#defineHiddenClass,而创建普通类则是用ClassLoader::defineClass(保护属性,无法直接在外部访问,一般使用反射的访问)的。
public Lookup defineHiddenClass(byte[] bytes, boolean initialize, ClassOption... options) throws IllegalAccessException
这里的三个参数分别是:
-
bytes:符合java虚拟机规范的字节码
-
initialize:是否要初始化类
-
options:java类的类型,详见
java.lang.invoke.MethodHandles.Lookup.ClassOption
我们需要注意的,隐藏类,是一个高级特性,主要用于库和框架的开发者,并不是面向普通的应用程序猿。而且,由于涉及到底层的字节码操作和类加载机制,所以在使用这一特性时,我们需要对Java的内部工作机制有深入的理解。
3、移除的APIs、工具、容器
移除了Nashorn JavaScript 引擎、禁用偏向锁、移除 Solaris 和 SPARC 平台的支持
参考:
-
Java SE 15中移除的API
-
JDK 15中移除的特性和容器
Java 14
变动说明
官网:
Java Platform, Standard Edition Java Language Updates, Release 14
JDK 14 Release Notes
JDK 14
更多参考:
JDK 14 Documentation - Home 更多版本:Java Platform, Standard Edition Documentation - Releases
Java Platform, Standard Edition Oracle JDK Migration Guide, Release 14
1、JEP 361:Switch 表达式(正式特性)
JEP 361 (tools/javac)
这仍然是一个预览特性。
功能进化
| java版本 | 特性类型 | JEP | 特性 |
|---|---|---|---|
| Java 5 | 首次引入,仅支持整型数据类型(如 byte, short, char, 和 int)及枚举类型 | ||
| Java 7 | 支持 String 类型 | ||
| Java 12 | 预览特性 | JEP 325 | 支持Switch表达式(箭头函数) |
| Java 13 | 预览特性 | JEP 354 | 加入 yield 语句来替代 break 语句,用于从 switch 表达式返回值 |
| Java 14 | 正式特性 | JEP 361 | 前2个版本的新特性转为正式特性 |
Switch 表达式是在 Java 12 中首次作为预览特性引入,而在 Java 13 中对 Switch 表达式做了增强改进:在块中引入了 yield 语句来返回值,而不是使用 break。在Java 14中成为一个标准特性。
Switch 表达式主要功能包括:
-
简化的语法:
switch表达式使用更简洁的箭头语法 (->)编写,可以直接返回一个值,且不再需要break语句。 -
多值匹配:每个
case分支可以同时匹配多个值,使用逗号分隔。 -
yield关键字:当使用switch表达式处理复杂逻辑时,可以根据情况使用yield在代码中返回一个值。
示例代码:
// 旧写法:冗长,切容易出错。漏掉break会穿透到下一条件。
public static String getTypeOfDay0(String name) {
String desp;
switch (name) {
case "稻":
desp = "dào,俗称水稻、大米";
break;
case "黍":
desp = "shǔ,俗称黄米";
break;
case "稷":
desp = "jì,又称粟,俗称小米";
break; // 可以注释掉看看
case "麦":
desp = "mài,俗称小麦";
break;
case "菽":
case "豆":
desp = "shū,俗称大豆";
break;
default:
throw new IllegalStateException("不是五谷之一: " + name);
}
return desp;
}
// java12写法
public static String getTypeOfDay1(String name) {
return switch (name) {
case "稻" -> "俗称水稻、大米";
case "黍" -> "shǔ,俗称黄米";
case "稷" -> "jì,又称粟,俗称小米";
case "麦" -> "俗称小麦";
case "菽", "豆" -> "shū,俗称大豆";
default -> {
throw new IllegalStateException("不是五谷之一: " + name);
}
};
}
// java12写法:条件中需要特殊处理的情况,需要在外部单独定义一个变量接收处理值
public static String getTypeOfDay2_1(String name) {
// 如果不需要特殊处理,可以直接返回
String desp;
switch (name) {
case "稻" -> desp = "俗称水稻、大米";
case "黍" -> desp = "shǔ,俗称黄米";
case "稷" -> desp = "jì,又称粟,俗称小米";
case "麦" -> desp = "俗称小麦";
case "菽", "豆" -> desp = "shū,俗称大豆";
default -> {
// 处理复杂逻辑
if (name == null || name.isEmpty()) {
desp = "名称为空";
} else {
throw new IllegalStateException("不是五谷之一: " + name);
}
}
}
return desp;
}
// java13写法,即java14写法
public static String getTypeOfDay2(String name) {
return switch (name) {
case "稻" -> "俗称水稻、大米";
case "黍" -> "shǔ,俗称黄米";
case "稷" -> "jì,又称粟,俗称小米";
case "麦" -> "俗称小麦";
case "菽", "豆" -> "shū,俗称大豆";
default -> {
// 处理复杂逻辑
if (name == null || name.isEmpty()) {
yield "名称为空";
} else {
throw new IllegalStateException("不是五谷之一: " + name);
}
}
};
}
@Test(priority = 0) // 不指定顺序时默认按字母顺序执行
public void test() {
String name = "稷";
System.out.printf("%s:%s%n", name, getTypeOfDay0(name));
System.out.printf("%s:%s%n", name, getTypeOfDay1(name));
System.out.printf("%s:%s%n", name, getTypeOfDay2(name));
}
2、JEP 358:改进 NullPointerExceptions 提示信息
JEP 358 (hotspot/runtime)
设置了-XX:+ShowCodeDetailsInExceptionMessages,当出现空指针异常时,可以提供更有效的信息。
如果设置了该选项,在遇到空指针时,JVM会分析程序以确定哪个引用为空,然后将详细信息作为NullPointerException.getMessage()的一部分提供。除了异常消息之外,还会返回方法、文件名和行号。
import lombok.Data;
@Data
public class TestUser {
private String name;
private Integer age;
private Like like;
}
@Data
class Like {
private String name;
private Fee fee;
}
@Data
class Fee {
private Double money;
}
测试方法:
@Test
public void test() {
TestUser user = new TestUser();
var name = user.getLike().getFee().getMoney();
System.out.println(name);
}
在Java 14之前,你可能会得到如下的错误:
Exception in thread "main" java.lang.NullPointerException
at com.ld.mytest.test.java14.NullExceptionTest.test(NullExceptionTest.java:9)
不幸的是,这一行多个方法调用,任何一个都可能会返回null。根本无法判断是谁导致了NullPointerException,这在调试bug的过程中非常的不方便。
而在Java 14中,输出结果:
java.lang.NullPointerException: Cannot invoke "com.ld.mytest.test.java14.Like.getFee()" because the return value of "com.ld.mytest.test.java14.TestUser.getLike()" is null at com.ld.mytest.test.java14.NullExceptionTest.test(NullExceptionTest.java:9) ……
可以看出,提示信息明确提示了空指针的原因是getLike()方法返回为空。
在Java 14中诊断信息只有在使用下述标志运行Java时才有效:
-XX:+ShowCodeDetailsInExceptionMessages
示例如下:
java -XX:+ShowCodeDetailsInExceptionMessages NullExceptionTest
这个配置在Java 15中已经设置为默认。
这项改进不仅对于方法调用有效,其他可能会导致NullPointerException的地方也有效,包括字段访问、数组访问、赋值等。
3、移除的APIs、工具、容器
参考:
-
Java SE 14中移除的API
-
JDK 14中移除的特性和容器
Java 13
变动说明
官网:
Java Platform, Standard Edition Java Language Updates, Release 13
JDK 13 Release Notes
JDK 13
更多参考:
JDK 13 Documentation - Home 更多版本:Java Platform, Standard Edition Documentation - Releases
Java Platform, Standard Edition Oracle JDK Migration Guide, Release 13
1、JEP 353:重构 Socket API
JEP 353 (core-libs/java.net)
java.net.Socket和java.net.ServerSocket的API底层实现在此版本中已被替换。
默认使用新的API,但是旧的实现(称为PlainSocketImpl或Plain实现)并没有删除,可以继续运行。可以通过增加系统属性jdk.net.usePlainSocketImpl或将其值设为true来使用旧实现,即使用-Djdk.net.usePlasinSocketImpl或-Djdk.net.usePlainSocketImpl=true=来运行。该属性也可以在JDK网络配置文件中进行配置,该文件位于${java.home}/conf/net.properties中。旧实现以及用于选择旧实现的系统属性将在将来的版本中删除。
新的API使用全新实现的 NioSocketImpl 来替换原来的PlainSocketImpl。可以查看java.net.SocketImpl的源代码
package java.net;
……
/**
* The abstract class {@code SocketImpl} is a common superclass
* of all classes that actually implement sockets. It is used to
* create both client and server sockets.
*
……
* removed in a future version.
*
* @author unascribed
* @since 1.0
*/
public abstract class SocketImpl implements SocketOptions {
private static final boolean USE_PLAINSOCKETIMPL = usePlainSocketImpl();
/**
* Creates an instance of platform's SocketImpl
*/
@SuppressWarnings("unchecked")
static <S extends SocketImpl & PlatformSocketImpl> S createPlatformSocketImpl(boolean server) {
if (USE_PLAINSOCKETIMPL) {
return (S) new PlainSocketImpl(server); // 旧
} else {
return (S) new NioSocketImpl(server); //新
}
}
……
}
2、移除的APIs、工具、容器
参考:
-
Java SE 13中移除的API、工具和容器
Java 12
变动说明
官网:
Java Platform, Standard Edition Java Language Updates, Release 12
JDK 12 Release Notes
JDK 12
更多参考:
JDK 12 Documentation - Home 更多版本:Java Platform, Standard Edition Documentation - Releases
Java Platform, Standard Edition Oracle JDK Migration Guide, Release 12
1、新增String API
为了进一步增加对 String 的处理能力,Java 12 对 String 进一步增强,引入几个方法:
| 方法名 | 描述 |
|---|---|
indent(int n) | 根据参数n对字符串进行缩进 |
transform() | 将字符串转换为 R 形式的结果。 |
describeConstable() | 该方法用于支持新的常量 API,它返回一个 Optional,描述字符串的常量描述。 |
resolveConstantDesc() | 则与 describeConstable() 相关,用于解析常量描述 |
indent()
public String indent(int n)
indent(int n) 会根据参数n对字符串进行缩进。规则如下:
-
当
n>0时,会在字符串的每一行开头插入n个空格,字符串整体右移。 -
当
n<0时,会在字符串的每一行开头删除n个空格,如果实际的空格数小于n,删除该行所有空格,但是并不会换行。
@Test
public void test() {
String text = " 金 \n 木 \n 水 \n 火 \n 土";
System.out.println("缩进前");
System.out.println(text);
System.out.println("往右缩进2个字符");
String indent2 = text.indent(2);
System.out.println(indent2);
System.out.println("往左缩进3个字符,实际不够只有2个空格");
String indent3 = text.indent(-3);
System.out.println(indent3);
}
执行结果:
缩进前
金
木
水
火
土
往右缩进2个字符
金
木
水
火
土
往左缩进3个字符,实际不够只有2个空格
金
木
水
火
土
注意:这个方法执行后最后会多加一个换行。
transform()
public <R> R transform(Function<? super String, ? extends R> f)
该方法接受一个函数作为参数,对字符串进行转换,并返回转换的结果。该方法非常强大,强大之处在于它的泛型和功能性特点,它允许我们对字符串执行任意类型的操作并返回所需的类型。例如:
@Test
public void test1() {
String txt = "金木水火土 ";
String s = txt.transform(str -> str.repeat(2));
System.out.println(s);
String s1 = txt.transform(str -> "五行:" + str.indent(2));
System.out.println(s1);
}
执行结果:
金木水火土 金木水火土 五行: 金木水火土
该方法在对字符串执行复杂转换的场景中特别有用。
describeConstable()和resolveConstantDesc()
describeConstable()和resolveConstantDesc()比较底层,主要主要是为了支持 Java 中的常量描述功能,在日常的 Java 应用程序开发中可能不是经常使用,这里就不介绍了。
2、新增Files API
Java 12 在Files工具类中增加了一个新的静态方法Files.mismatch(Path,Path),用来找两个文件内容(byte)不一样的地方,返回两个文件内容中第一个不匹配字节的位置,如果完全相同,则返回-1L 。
@Test
public void test() throws IOException {
// 文件对比
Path p1 = Files.createTempFile("file1", "txt");
Path p2 = Files.createTempFile("file2", "txt");
Files.writeString(p1, "金木水火土");
Files.writeString(p2, "金木水火土");
// -1L 二者内容相同。该方法用于比较两个文件的内容,它返回两个文件内容第一次不匹配的位置索引。如果文件完全相同,则返回 -1。
long mismatch = Files.mismatch(p1, p2);
System.out.println(mismatch);
}
该方法和另外一个方法Files.isSameFile(Path, Path)的比较:
| 文件关系 | isSameFile(Path,Path) | mismatch(Path,Path) |
|---|---|---|
| 同一文件 | true | -1(等同于true) |
| 复制文件 | false | -1(等同于true) |
| 不同文件 | false | 看内容,内容相同-1,内容不同返回第一次不匹配的位置索引 |
| 硬链接 | true | -1(等同于true) |
| 软连接 | true | -1(等同于true) |
-
isSameFile(Path, Path)比较的是路径 -
mismatch(Path, Path)比较的是内容
该方法可用于确认两个文件内容是否完全相同。
3、新增 NumberFormat API
core-libs/java.text
NumberFormat增加了新的基于区域对以紧凑形式格式化数字的支持。紧凑数字格式是指以简短或人类可读的形式表示数字。例如,在en_US区域设置中,1000可以格式化为1K,1000000可以格式为1M,具体取决于NumberFormat指定的样式。压缩数字格式由LDML的压缩数字格式规范定义。
要获得一个实例,请使用NumberFormat提供的工厂方法之一进行紧凑的数字格式设置。示例如下:
@Test
public void test() throws IOException {
// 中国格式
NumberFormat chnFormat = NumberFormat.getCompactNumberInstance(Locale.CHINA, NumberFormat.Style.SHORT);
chnFormat.setMaximumFractionDigits(2);// 1.23亿
String cformat = chnFormat.format(123456789);
System.out.println(cformat);
// 美国格式
NumberFormat usFormat = NumberFormat.getCompactNumberInstance(Locale.US, NumberFormat.Style.SHORT);
usFormat.setMaximumFractionDigits(2);// 123.46M
String uformat = usFormat.format(123456789);
System.out.println(uformat);
}
4、新增 Collectors API
对Stream流的聚合操作Collector进一步增强,增加了teeing操作来实现一些复杂的聚合操作。它接受两个收集器(Collector)和一个二元运算函数(BiFunction),可以并行地将数据发送到两个不同的收集器,并在最后将这两个收集器的结果合并。
public static <T, R1, R2, R>
Collector<T, ?, R> teeing(Collector<? super T, ?, R1> downstream1,
Collector<? super T, ?, R2> downstream2,
BiFunction<? super R1, ? super R2, R> merger)
-
downstream1和downstream2:两个不同的Collector实例。 -
merger:一个BiFunction,用于合并两个Collector的结果。
teeing() 适合于那些需要对同一个数据集进行多次处理的情景。
使用场景举例:同时计算一个数字列表的平均值和总和,或者找出一个员工列表中工资最高和最低的员工。
比如有一个整数列,我们需要计算出这个列的最大值和平均值。
举个例子,我如果想统计一个数组的平均数在总和的占比,首先要计算平均数,然后再计算总和,然后再相除,这样需要三个步骤。
@Test
public void test() throws IOException {
List<Double> renkou = List.of(54.058, 62.113, 67.665, 95.992, 108.997);
// 潍坊最近5年出生人口(万)平均值为77.765(万)
Double average = renkou.stream().collect(Collectors.averagingDouble(i -> i));
// 潍坊最近5年出生人口(万)总数为 388.825(万)
Double total = renkou.stream().collect(Collectors.summingDouble(i -> i));
System.out.printf("平均值:%s 总数:%s%n", average, total);
// 因为存在双精度问题,临时使用乘以10000,最后结果再除以10000解决
Map<String, Double> meanPercentage = renkou.stream().collect(Collectors.teeing(Collectors.averagingDouble(i -> i * 10000),
Collectors.summingDouble(i -> i * 10000), (avg, totals) -> Map.of("averag", avg / 10000, "total", totals / 10000)));
System.out.println(meanPercentage);
}
运行结果:注意这里面存在浮点型数据计算不准确的问题,这里我们先不讨论这个问题。
平均值:77.76500000000001 总数:388.82500000000005
{averag=77.765, total=388.825}
显然新的代码更简洁,但是它可能会带来一些性能开销,尤其是在处理大数据集时。所以使用时,最好做好评估。
5、移除的APIs、工具、容器
参考:
-
Java SE 12中移除的API、工具和容器
Java 11(LTS)
概述
Java 11 在 2018 年 9 月 25 日正式发布,与 Java 9 和 Java 10 这两个被称为”功能性的版本”不同,Java 11 提供长期支持服务(LTS, Long-Term-Support),将作为从发布日期开始的 Java 平台的默认支持版本,并且会提供技术支持直至 2023 年 9 月,对应的补丁和安全警告等支持将持续至 2026 年。
Java 11 是继 Java 8 之后的第二个 LTS 版本。自Java 11起,Oracle JDK 将不再免费用于商业用途。
您可以在开发阶段使用它,但若想将其用于商业环境,您需要购买许可证。 如果不这样做,可能会面临来自Oracle的法律诉讼。
Java 10 是最后一个可以免费使用的 Oracle JDK。
Oracle 从 2019 年 1 月起停止 Java 8 支持。您需要为更多支持付费。您可以继续使用Java 8,但是不会再收到任何补丁或安全更新。
从Java 11开始,Oracle 将不再为任何单一 Java 版本提供免费的长期支持 (LTS)。
尽管Oracle JDK不再免费,但您始终可以从 Oracle 或其他提供商(例如 AdoptOpenJDK、Azul、IBM、Red Hat 等)下载 Open JDK 版本。在我看来,除非您正在寻找有兴趣的企业级使用 支付支持费用,您可以使用 OpenJDK 并在必要时对其进行升级。
商用收费
Java的商用收费始于Java 8 ,Oracle JDK宣布从2019年1月份开始对Java SE 8之后的版本开始进行商用收费,确切的说是8u201/202之后的版本。如果你用 Java 开发的功能如果是用作商业用途的,如果还不想花钱购买的话,能免费使用的最新版本是8u201/202。当然如果是个人客户端或者个人开发者可以免费试用 Oracle JDK所有的版本。另外Oracle官方其实还提供了一个完全免费开源的JDK版本—— Open JDK,这是免费使用的。
决定是否收费首先得看JDK使用的是什么协议?
-
BCL协议:即
Oracle Binary Code License Agreement,协议规定你可以使用JDK,但是不能进行修改。私用和商用都可以,但是JDK中的某些商业特性,是需要付费才可以使用的。 -
OTN协议:即
Oracle Technology Network License Agreement,目前新发布的JDK用的都是这个协议,可以私用,商用需要付费。
版本说明
-
Java 8以下版本,仍可免费使用。
-
Java 8 (LTS) 部分免费,
8u201/202及之前的版本是免费的,之后的商用收费。 -
Java 9 是免费的,过渡版本且不再更新不建议使用。
-
Java 10 是免费的,过渡版本且不再更新不建议使用。
-
Java 11 (LTS) 开始
Oracle JDK商用收费,同时提供免费版的Open JDK,下载地址。
补充说明
-
从2019年4月开始,
Oracle JDK 8更新将具有商业使用限制。 -
Java 10.0.2(2018年7月),Java 8u201/202(2019年1月)是 Oracle 发布的最后的免费的Oracle JDK。
-
从 Java 11 开始,每6个月发布一个新的版本,即 11 → 12 → 13 → 14。
-
从 Java 11 开始,每3个月更新一个补丁版本,即 11.0.1 → 11.0.2。
-
从 Java 11(2018年9月,LTS)开始,Oracle将提供基于
GPLv2 + CPE协议的OpenJDK,Oracle JDK构建和OpenJDK构建将基本相同。 -
免费的JDK有 OpenJDK 、 AdoptOpenJDK 、 Amazon Corretto 、 Azul Zulu 、 BellSoft 、 IBM 、 jClarity 、 Red Hat 、 SAP 、 阿里巴巴 Dragonwell等。
变动说明
官网:
Java Platform, Standard Edition Java Language Updates, Release 11
JDK 11 Release Notes, Important Changes, and Information
JDK 11
更多参考:
JDK 11 Documentation - Home 更多版本:Java Platform, Standard Edition Documentation - Releases
https://docs.oracle.com/en/java/javase/11/migrate/index.htm
1、JEP 323:局部变量类型推导的升级
JEP 323
Java 10 引入了 局部变量类型推导这一关键特性。类型推导允许使用关键字 var 作为局部变量的类型而不是实际类型,编译器根据分配给变量的值推导出类型。这一改进简化了代码编写、节省了开发者的工作时间,因为不再需要显式声明局部变量的类型,而是使用关键字 var替代。
在 Java 10 中,var声明局部变量还有下面几个限制:
-
定义的时候必须初始化
-
只能用于定义局部变量
-
不能用于定义成员变量、方法参数、返回类型
-
不能在 Lambda 表达式中使用
其中不能在 Lambda参数使用var,这条限制在Java 11中得到了改进。Java 11 允许开发者在Lambda表达式中使用var进行参数声明。
下面我们回顾一下var声明局部变量的使用,如果只想看更新部分,可以直接看下面总结的第5部分:
可以使用关键字 var 声明局部变量,示例如下:
try {
URL url = new URL("http://www.oracle.com/");
URLConnection conn = url.openConnection();
Reader reader = new BufferedReader(new InputStreamReader(conn.getInputStream()));
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
您可以通过使用var标识符声明局部变量来重写此示例。变量的类型是从上下文中推导出来的:
try {
var url = new URL("http://www.oracle.com/");
var conn = url.openConnection();
var reader = new BufferedReader(new InputStreamReader(conn.getInputStream()));
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
显然下面的代码更简练。
var是一个保留的类型名称,而不是关键字,这意味着使用var作为变量、方法或包名称的现有代码不受影响。但是,使用var作为类或接口名称的代码会受到影响,需要重命名该类或接口。
var可用于以下类型的变量:
-
带有初始值设定项的局部变量声明:
var list = new ArrayList<String>(); // 推导为 ArrayList<String> var stream = list.stream(); // 推导为 Stream<String> var path = Paths.get(fileName); // 推导为 Path var bytes = Files.readAllBytes(path); // 推导为 bytes[]
-
增加循环中声明索引变量:
List<String> myList = Arrays.asList("礼", "乐", "射", "御", "书", "数"); //六艺
for (var element : myList) {...} // 推导为 String
-
传统for循环中声明索引变量:
for (var counter = 0; counter < 10; counter++) {...} // 推导为 int
-
try with resources变量:
try (var input = new FileInputStream("唐宋八大家.txt")) {...} // 推导为 FileInputStream
-
隐式类型lambda表达式的形参声明:
BiFunction<Integer, Integer, Integer> = (a, b) -> a + b;
在JDK11及更高版本中,可以使用var标识符声明隐式类型lambda表达式的每个形参:
(var a, var b) -> a + b;
因此,隐式类型lambda表达式中的形参声明的语法与局部变量声明的语法一致;将var标识符应用于隐式类型lambda表达式中的每个形参,其效果与不使用var完全相同。
既然如此,那为什么我们要对lambda参数使用var?
与局部变量声明的语法保持一致的一个好处是:可以为lambda参数添加注解:
Function<String, String> msgWarpper = m -> "'" + m + "'";
Function<String, String> msgWarpper1 = (@NotNull var m) -> "'" + m + "'";
System.out.println(msgWarpper.apply("李商隐")); //结果 '李商隐'
System.out.println(msgWarpper1.apply("杜牧")); // 结果 '杜牧'
System.out.println(msgWarpper1.apply(null)); // 结果 'null' 这里notnull单独使用没有效果,还要加上其他处理才能生效
需要注意:不能在隐式类型的lambda表达式中混合隐式声明的参数和var声明的形参,也不能在显式类型的lambda表达式中混合var声明的正式参数和显式类型。以下示例是不允许的:
(var x, y) -> x.process(y) // 不能混合var声明和隐式类型声明 (var x, int y) -> x.process(y) // 不能混合var声明和显示类型声明
局部变量类型推导原则
局部变量声明可以通过消除冗余信息来提高代码的可读性。然而,它也会通过省略有用的信息来降低代码的可读性。因此,要根据实际情况来判断是否应该使用此功能;关于何时应该使用和不应该使用,没有严格的规则。
局部变量声明不是孤立存在的;周围的代码可能会影响甚至压倒var声明的效果。局部变量类型推导:风格指南 检查了周围代码对var声明的影响,解释了显式和隐式类型声明之间如何权衡,可以为有效使用var声明提供指导。
2、新增String API
String 是 Java 中最常用的一个类,Java 11 为了更好地处理字符串,新增了几个新的 API:
| 方法名 | 描述 |
|---|---|
isBlank() | 检查字符串是否为空或仅包含空白字符 |
lines() | 分割获取字符串流(Stream) |
strip() | 去除字符串首尾的空白字符 |
repeat(n) | 复制字符串 |
isBlank()
用于判断字符串是否为空或者只包含空白字符。
"".isBlank(); // true " ".isBlank(); // true " \n\t ".isBlank() // true "大音希声".isBlank(); // false
该方法是对isEmpty()的补充,isEmpty() 只能检查字符串长度是否为0,而isBlank()则回进一步检查了字符串的内容是否也只包含空白字符。
lines()
该方法返回一个流(Stream),该流由字符串中的行组成,使用行结束符作为分隔符。
"象形\n指事\n会意\n形声\n转注\n假借".lines().forEach(System.out::println);
执行结果:
象形 指事 会意 形声 转注 假借
该方法可以处理不同平台上的换行符,无论是\n,\r还是\r\n。
strip()
去除字符串首尾的空白字符。如果字符串中间有空白字符,它们不会被去掉。
System.out.println(" 汉字六书 ".strip());
执行结果:
汉字六书
在原来老的 Java 版本中有一个方法:trim(),该方法也可以去掉空格,但是它只能去掉除半角空格。看下面例子
// 全角
System.out.printf("strip[全角] :%s%n", "[" + " 汉字 六书 ".strip() + "]"); // [汉字 六书]
System.out.printf("trim[全角] :%s%n", "[" + " 汉字 六书 ".trim() + "]"); // [ 汉字 六书 ]
// Unicode空白字符
char ch = '\u2000'; // Unicode空白字符
System.out.printf("strip[Unicode空白字符]:%s%n", "[" + (ch + "汉字 六书" + ch).strip() + "]");
System.out.printf("trim[Unicode空白字符] :%s%n", "[" + (ch + "汉字 六书" + ch).trim() + "]");
// 半角
System.out.printf("strip[半角] :%s%n", "[" + " 汉字 六书 ".strip() + "]");
System.out.printf("trim[半角] :%s%n", "[" + " 汉字 六书 ".trim() + "]");
// tab键、换行符
System.out.printf("strip[tab键、换行符] :%s%n", "[" + "\n汉字 六书\t".strip() + "]");
System.out.printf("trim[tab键、换行符] :%s%n", "[" + "\n汉字 六书\t".trim() + "]");
运行结果:
strip[全角] :[汉字 六书] trim[全角] :[ 汉字 六书 ] strip[Unicode空白字符]:[汉字 六书] trim[Unicode空白字符] :[ 汉字 六书 ] strip[半角] :[汉字 六书] trim[半角] :[汉字 六书] strip[tab键、换行符] :[汉字 六书] trim[tab键、换行符] :[汉字 六书]
trim()早在Java早期就存在,当时Unicode还没有完全发展到我们今天广泛使用的标准。
trim()方法移除字符串两侧的空白字符(空格、tab键、换行符),无法删除掉Unicode空白字符,但用Character.isWhitespace方法可以判断出来
所以:
-
trim()只移除ASCII字符集中定义的空白字符。 -
strip()移除所有Unicode字符集中定义的空白字符。
strip() 还有两个方法:
-
stripLeading():仅移除开头的空白字符。 -
stripTrailing():仅移除末尾的空白字符。
这里就不具体介绍了
repeat()
将字符串重复指定的次数,并将这些重复的字符串连接为一个新的字符串。
System.out.println("汉字六书;".repeat(6));
运行结果:
汉字六书;汉字六书;汉字六书;汉字六书;汉字六书;汉字六书;
注意
-
如果传入的次数为0,结果是一个空字符串。
-
如果次数小于0,会抛出
IllegalArgumentException。
3、新增Files API
Java 11 对java.nio.file.Files新增了三个 API:
-
readString():读取文件内容 -
writeString():写入文件内容 -
isSameFile():比较两个路径是否指向文件系统中的同一个文件
这三个 API 简化了我们对文件的操作,使得操作文件变得更加简便了。
writeString()
该方法可以将字符串写入文件中。
public static Path writeString(Path path, CharSequence csq, OpenOption... options) throws IOException public static Path writeString(Path path, CharSequence csq, Charset cs, OpenOption... options) throws IOException
第一个方法等效于writeString(path, csq, StandardCharsets.UTF_8, options)。
@Test
public void writeStringTest() throws IOException {
Path path = Paths.get("file.txt");
String content = "“谷”原来是指有壳的粮食;像稻、稷(jì计,即谷子)、黍(亦称黄米)等外面都有一层壳,所以叫做谷。谷字的音,就是从壳的音来的。五谷原是中国古代所称的五种谷物,后泛指粮食类作物。关于五谷主要有两种说法,主流的是稻(俗称水稻、大米)、黍(shǔ,俗称黄米)、稷(jì,又称粟,俗称小米)、麦(俗称小麦,制作面粉用)、菽(俗称大豆)。因为有的地方气候干旱,不利于水稻的种植,因此有将麻(俗称麻子)代替稻,作为五谷之一。";
Files.writeString(path, content);
}
####
readString()
该方法可以读取文件的全部内容,返回一个字符串。有2个重载方法。
第一种方法将文件中的所有内容读取为字符串,并使用 UTF-8 字符集将其从字节解码为字符。该方法可确保在所有内容均已关闭时关闭文件读取或抛出I/O错误或其他运行时异常。 第二种方法与仅使用指定字符集的方法相同。
请注意,这些方法不适用于读取非常大的文件。否则,如果文件过大,例如,文件可能会抛出 OutOfMemoryError。
public static String readString(Path path) throws IOException public static String readString(Path path, Charset cs) throws IOException
第一个方法等效于readString(path,StandardCharsets.UTF_8)。
@Test
public void readStringTest() throws IOException {
Path path = Paths.get("file.txt");
System.out.println(path.toAbsolutePath()); // 打印路径
String content = Files.readString(path);
System.out.println(content);
}
isSameFile()
该方法用于比较两个路径是否指向文件系统中的同一个文件,可以用来检查符号链接或文件快捷方式是否指向同一个文件。
@Test
public void isSameFileTest() throws IOException {
Path path1 = Paths.get("file_01.txt");
Path path2 = Paths.get("file_02.txt");
boolean result = Files.isSameFile(path1,path2);
System.out.println(result);
}
文件路径相同返回 true,否则返回 false。
4、JEP 330:运行单文件源码程序
JEP 330
增强java启动器以运行作为java源代码的单个文件提供的程序,包括通过“shebang”文件和相关技术在脚本中使用。
这个功能尤其适合初学Java编程的新手,或想迅速体验编写简短代码的用户。此功能与 jshell 一起,将成为Java初学者的重要助手。对于有经验的开发者,它可以用来简化代码验证和测试工具。
这项特性允许开发者直接运行一个包含源代码的单个Java文件,而无需事先将其编译成字节码。
-
此功能允许使用 Java 解释器直接执行 Java 源代码。
-
源代码在内存中编译,然后由解释器执行。但是有个限制条件是所有相关的类必须定义在同一个 Java 文件中。
我们可以使用 Java 命令直接运行一个单文件的Java源代码,比如我们有一个名为 LaunchSourceTest.java 的文件,内容如下:
public class LaunchSourceTest {
public static void main(String[] args) {
System.out.println("天地玄黄,宇宙洪荒!");
}
}
我们可以使用下面命令来执行这个 Java 文件
cd F:\workspacenew2023-04\mylab\mytest\src\test\java\com\ld\mytest\test\java11[java文件所在目录] # windows下修改编码,改为utf-8编码,因为上面使用了中文,不改编码会乱码。 F:\workspacenew2023-04\mylab\mytest\src\test\java\com\ld\mytest\test\java11>chcp 65001 java LaunchSourceTest.java
执行结果:
天地玄黄,宇宙洪荒!
传参
java java文件名 [参数……] #参数可以有多个,空格分隔,如果参数本身待空格,用引号包裹
public class LaunchSourceTest {
public static void main(String[] args) {
if (args == null || args.length < 1) {
System.err.println("谁说的?");
System.exit(1);
}
System.out.println(String.format("%s说:天地玄黄,宇宙洪荒!", args[0]));
}
}
运行
java LaunchSourceTest.java kk
执行结果:
kk说:天地玄黄,宇宙洪荒!
如果不传参
运行
java LaunchSourceTest.java
执行结果:
谁说的?
上面我们文件后缀是java,如果后缀不是java,那么jvm会用文件名+.class搜寻文件,找不到就会报错。当然也开业使用—source选项指定源文件:
java --source version[jdk版本] [java文件名] # 如 java --source 11 LaunchSourceTest.java kk
一个文件中多个类
上面提到所有需要执行的代码是在同一个java文件中即可,这同一个文件中可以存在多个类。
下面这个java文件,在IDE中是编译不通过的,因为一个java文件中只能有一个public类。但是用java命令是可以运行的。
public class LaunchSourceTest {
public static void main(String[] args) {
BaijiaXing.write();
}
}
// 下面类的public去掉,在IDE中就不报错了
public class BaijiaXing {
public static void write() {
System.out.println("赵钱孙李,周吴郑王!");
}
public static void main(String[] args) {
System.out.println("第二个类的main方法");
}
}
运行
java LaunchSourceTest.java
执行结果:
赵钱孙李,周吴郑王!
执行的是第一个类的main方法,后面的不会执行。
Shebang文件
shebang,Linux中常见的符号。#!,其中she指代#,而bang指代!。
Shebang文件是Unix系统中常见的文件,以#!/path/executable(#!开头后面跟一个可执行文件路径)作为文件的开头第一行,shebang通常出现在类Unix系统的脚本中第一行,作为前两个字符,用于命令解释器声明,如:
#!/bin/sh #!/bin/bash
如果脚本文件中没有#!这一行或者指定的不是一个可执行文件,那么执行时会默认采用当前Shell去解释这个脚本(即:$SHELL环境变量)。
我们来创建一个shebang文件:
在文件第一行增加
#!/path/java --source version
#!/home/ubuntu/jdk/jdk-11.0.12/bin/java --source 11
public class LaunchSourceTest {
public static void main(String[] args) {
BaijiaXing.write();
}
}
// 下面类的public去掉,在IDE中就不报错了
public class BaijiaXing {
public static void write() {
System.out.println("赵钱孙李,周吴郑王!");
}
public static void main(String[] args) {
System.out.println("第二个类的main方法");
}
}
将上面内容为LaunchSourceTest的文件中。按下面的方式来运行:
~$ cd /home/ubuntu/workdir[java文件所在路径] ~$ ./LaunchSourceTest 赵钱孙李,周吴郑王! #执行结果
5、JEP 321:标准 HTTP Client 升级
JEP 321
在Java 9的时候,引入了一个新的HTTP客户端API(HttpClient)作为作为实验特性,到了 Java 11,则被标准化并正式成为Java标准库的一部分。经过前面两个版本中的孵化,Http Client 几乎被完全重写,并且现在完全支持异步非阻塞。新版 Java 中,Http Client 的包名由 jdk.incubator.http 改为java.net.http,该 API 通过 CompleteableFutures 提供非阻塞请求和响应语义。
全新的 HTTP 客户端 API 具有如下几个优势:
-
HTTP/2支持:全新的 HttpClient 支持 HTTP/2 协议的所有特性,包括同步和异步编程模型。
-
WebSocket支持:支持WebSocket,允许建立持久的连接,并进行全双工通信。
-
同步和异步:提供了同步和异步的两种模式。这意味着我们既可以等待HTTP响应,也可以使用回调机制处理HTTP响应。
-
链式调用:新的HttpClient 允许链式调用,使得构建和发送请求变得更简单。
-
更好的错误处理机制:新的HttpClient 提供了更好的错误处理机制,当HTTP请求失败时,可以通过异常机制更清晰地了解到发生了什么。
下面是一个使用新的 HttpClient 示例:
@Test
public void testHttpRequest() {
try {
URI uri = URI.create("http://www.baidu.com/"); // new URI("https://www.baidu.com");
HttpClient httpClient = HttpClient.newBuilder()
// 超时时间10秒,
.connectTimeout(Duration.of(10, ChronoUnit.SECONDS))
//HTTP版本为HTTP/2
.version(HttpClient.Version.HTTP_2).build();
// 默认get请求,想用post,增加.POST()
HttpRequest request = HttpRequest.newBuilder(uri).build();
// 1、同步调用
HttpResponse<String> response = httpClient.send(request, BodyHandlers.ofString());
int statusCode = response.statusCode();
String body = response.body();
System.out.println(statusCode);
System.out.println(body);
// 2、异步调用
// 使用 sendAsync() 方法发送异步请求,发送请求后会立刻返回 CompletableFuture,使用CompletableFuture中的方法来设置异步处理器
httpClient.sendAsync(request, HttpResponse.BodyHandlers.ofString()) // 第二个参数,这里是使用了返回字符串,可以返回数组、行、输入流等
// 申请结果处理,这里是返回body
.thenApply(HttpResponse::body)
// 把结果打印
.thenAccept(System.out::println)
//
.join();
} catch (Exception e) {
e.printStackTrace();
}
}
异步处理如果想直接处理结果可以改成如下方式:
httpClient.sendAsync(request, HttpResponse.BodyHandlers.ofString()) // 第二个参数,这里是使用了返回字符串,可以返回数组,按行返回,或者返回流等
// 这里少了thenApply
// 把结果打印
.thenAccept(response -> {
System.out.println(response.statusCode());
System.out.println(response.body());
})
//
.join();
6、移除的APIs、工具、容器
移除 Java EE和CORBA模块
Java 10
变动说明
官网:
Java Platform, Standard Edition Java Language Updates, Release 10
JDK 10 Release Notes
JDK 10
更多参考:
JDK 10 Documentation
Java Platform, Standard Edition Oracle JDK Migration Guide, Release 10
1、JEP 286:局部变量的类型推导
JEP 286
目前为止,局部变量类型推导是 Java 10 中最受人瞩目的特性。在经过激烈的争议之后,此特性才被引入 Java 10 中,它允许编译器推导局部变量的类型,而不是要求程序员明确指定变量类型。局部变量类型推导有助于缩短代码,并提高可读性。
简单类型
以String类型为例,示例代码:
// 无类型推导 String name = "四书五经"; // 使用类型推导 var name = "四书五经";
可以看到,唯一的区别在于使用了保留类型名称 var 。使用右侧的表达式,编译器可以推导出变量 name 的类型为 String 。
复杂类型
以List为例,示例代码:
// 无类型推导 List<String> list = new ArrayList<>(); // 使用类型推导,注意右侧泛型也可以不加,不加就相当于泛型为Object var list = new ArrayList<String>();
编译器可以推导出变量 list 的类型为 ArrayList 。
在早期Java引入泛型的时候,我们申明具体类型的时候需要这样写(等号两边都需要):
List<String> list = new ArrayList<String>(); Map<String, String> map = new HashMap<String,String>();
后来在Java 7推出之后,简化为(只需要在左边申明类型即可):
List<String> list = new ArrayList<>(); Map<String, String> map = new HashMap<>();
而这次Java 10中,对类型的推导进一步优化,只需要这样即可(类型在等号右边决定):
var list = new ArrayList<String>(); var map = new HashMap<String, String>();
对于var的使用还有几点要注意的:
-
定义的时候必须初始化
-
只能用于定义局部变量
-
不能用于定义成员变量、方法参数、返回类型
-
每次只能定义一个变量,不能复合声明变量
-
大量使用var可能会导致代码的可读性下降,因此尽量在情况明显的情况下才使用它。
顾名思义,局部变量类型推导特性只能用于局部变量。不能将它用于定义实例或类变量,也不能在方法参数或返回类型中使用它。但是,在可以从迭代器推导类型的经典和增强的 for 循环中, 可以 使用 var 。
for(var user : users){
}
for(var i = 0; i < 10; i++){
}
var的问题
1. var 让类型变得模糊
前面已经提到var 有一些好处,但是另一方面,它也有可能让类型变得模糊。
var result = userService.search();
上面的代码中,我们必须猜测返回类型。让代码更加难以维护。
2. var 无法与 lambda 结合使用
在用于 lambda 表达式时,类型推导的效果不是很好,主要由于缺乏可供编译器使用的类型信息。清单 8 中的 lambda 表达式不会执行编译。
示例代码:
Function<String, String> msgWarpper = m -> "'" + m + "'"; var msgWarpper1 = m -> "'" + m + "'"; //这行编译会报错,需要使用上一行的形式
在上述代码中,右侧表达式中没有足够的类型信息供编译器推导变量类型。Lambda 语句必须始终声明一个显式类型。
Java官方表示,它不能用于以下几个地方:
-
方法参数
-
构造函数参数
-
方法返回类型
-
字段
-
捕获表达式(或任何其他类型的变量声明)
2、删除的工具
Java 10 删除了一些工具:
-
命令行工具
javah,但您可以使用javac -h代替它。 -
命令行选项
-X:prof,但您可以使用jmap工具来访问探查信息。 -
policytool。
一些由于 Java 1.2 被永久删除而被标记为弃用的 API。这些 API 包括 java.lang.SecurityManager.inCheck 字段和以下方法:
-
java.lang.SecurityManager.classDepth(java.lang.String) -
java.lang.SecurityManager.classLoaderDepth() -
java.lang.SecurityManager.currentClassLoader() -
java.lang.SecurityManager.currentLoadedClass() -
java.lang.SecurityManager.getInCheck() -
java.lang.SecurityManager.inClass(java.lang.String) -
java.lang.SecurityManager.inClassLoader() -
java.lang.Runtime.getLocalizedInputStream(java.io.InputStream) -
java.lang.Runtime.getLocalizedOutputStream(java.io.OutputStream)
3、弃用的API
JDK 10也弃用了一些 API。 java.security.acl 包被标记为弃用, java.security 包中的各种相关类( Certificate 、 Identity 、 IdentityScope 、 Singer 、 auth.Policy )也是如此。此外, javax.management.remote.rmi.RMIConnectorServer 类中的 CREDENTIAL_TYPES 也被标记为弃用。 java.io.FileInputStream 和 java.io.FileOutputStream 中的 finalize() 方法已被标记为弃用。 java.util.zip.Deflater / Inflater / ZipFile 类中的 finalize() 方法也是如此。
Java 9
变动说明
官网:
Java Platform, Standard Edition What’s New in Oracle JDK 9, Release 9
Java Platform, Standard Edition Java Language Updates, Release 9
JDK 9
更多内容:Oracle JDK 9 Documentation
1、JEP 222:交互式编程环境Jshell
JEP 222
交互式编程环境是一种让程序员能够即时输入代码并立即获得反馈的开发环境。每输入一行代码,系统就会立刻执行并显示结果,使得用户可以快速验证想法、进行简单计算等操作。尽管这种环境不太适合处理复杂的工程需求,但在快速验证和简单计算等场景下非常实用。尽管其他高级编程语言(比如Python)早就拥有了交互式编程环境,Java直到Java 9才正式推出了类似的工具。
下面就来一起学习下,这个Java中的交互式编程环境Jshell。
使用
启动Jshell
打开终端,然后执行命令:jshell,执行效果如下:我这里以java11为例
F:\Program Files\Java\jdk-11.0.12\bin>jshell | 欢迎使用 JShell -- 版本 11.0.12 | 要大致了解该版本, 请键入: /help intro jshell>
执行计算
在jshell中可以快速的执行计算操作并获得结果,比如这样:
jshell> 1+1 $1 ==> 2 # 注意上面的返回,这是里一个临时变量。下面是定义变量计算的情况,注意返回结果的不同。 jshell> int c = 1+1 c ==> 2 jshell> 2*3 $2 ==> 6 # 注意char类型和String类型的区别 jshell> 'a'+'b' $3 ==> 195 jshell> "a"+"b" $4 ==> "ab"
定义变量
在jshell中也可以定义变量与方法:
jshell> int a=1, b=2; a ==> 1 b ==> 2 jshell> a+b $7 ==> 3
定义方法
在jshell中也可以函数来封装操作,比如下面就是一个定义求和函数并调用它的例子:
jshell> int sum(int a, int b){
...> return a + b;
...> }
| 已创建 方法 sum(int,int)
jshell> sum(1,2)
$10 ==> 3
定义类
既然变量和方法都可以定义,那么合理推测,在jshell中,定义类,也是可以的,上示例:
jshell> public class MyCls {
...> public int a;
...> public int b;
...>
...> public int add(){
...> return a+b;
...> }
...>
...> public int mul(){
...> return a*b;
...> }
...>
...> }
| 已创建 类 MyCls
jshell> MyCls m = new MyCls()
m ==> MyCls@39c0f4a
jshell> m.a = 2
$21 ==> 2
jshell> m.b = 3
$22 ==> 3
# 相加
jshell> m.add()
$23 ==> 5
# 相乘
jshell> m.mul()
$24 ==> 6
帮助命令:/help
关于jshell常用命令,我们可以通过/help来查看
jshell> /help | 键入 Java 语言表达式, 语句或声明。 | 或者键入以下命令之一: | /list [<名称或 id>|-all|-start] | 列出您键入的源 | /edit <名称或 id> | 编辑源条目 | /drop <名称或 id> | 删除源条目 | /save [-all|-history|-start] <文件> | 将片段源保存到文件 | /open <file> | 打开文件作为源输入 | /vars [<名称或 id>|-all|-start] | 列出已声明变量及其值 | /methods [<名称或 id>|-all|-start] | 列出已声明方法及其签名 | /types [<名称或 id>|-all|-start] | 列出类型声明 | /imports | 列出导入的项 | /exit [<integer-expression-snippet>] | 退出 jshell 工具 | /env [-class-path <路径>] [-module-path <路径>] [-add-modules <模块>] ... | 查看或更改评估上下文 | /reset [-class-path <路径>] [-module-path <路径>] [-add-modules <模块>]... | 重置 jshell 工具 | /reload [-restore] [-quiet] [-class-path <路径>] [-module-path <路径>]... | 重置和重放相关历史记录 -- 当前历史记录或上一个历史记录 (-restore) | /history [-all] | 您键入的内容的历史记录 | /help [<command>|<subject>] | 获取有关使用 jshell 工具的信息 | /set editor|start|feedback|mode|prompt|truncation|format ... | 设置配置信息 | /? [<command>|<subject>] | 获取有关使用 jshell 工具的信息 | /! | 重新运行上一个片段 -- 请参阅 /help rerun | /<id> | 按 ID 或 ID 范围重新运行片段 -- 参见 /help rerun | /-<n> | 重新运行以前的第 n 个片段 -- 请参阅 /help rerun | | 有关详细信息, 请键入 '/help', 后跟 | 命令或主题的名称。 | 例如 '/help /list' 或 '/help intro'。主题: | | intro | jshell 工具的简介 | keys | 类似 readline 的输入编辑的说明 | id | 片段 ID 以及如何使用它们的说明 | shortcuts | 片段和命令输入提示, 信息访问以及 | 自动代码生成的按键说明 | context | /env /reload 和 /reset 的评估上下文选项的说明 | rerun | 重新评估以前输入片段的方法的说明
查看定义的变量:/vars
jshell> /vars | int $1 = 2 | int $2 = 6 | int $3 = 195 | String $4 = "ab" | int a = 1 | int b = 2 | int $7 = 3 | int $10 = 3 | int c = 2 | int $15 = 2 | MyCls m = MyCls@39c0f4a | int $21 = 2 | int $22 = 3 | int $23 = 5 | int $24 = 6
查看定义的函数:/methods
jshell> /methods | int sum(int,int)
查看定义的类:/types
jshell> /types | class MyCls
列出输入源条目:/list
这个命令看到之前在jshell中输入的所有执行内容:
jshell> /list
1 : 1+1
2 : 2*3
3 : 'a'+'b'
4 : "a"+"b"
5 : int a=1, b=2;
6 : int a=1, b=2;
7 : a+b
9 : int sum(int a,int b){
return a+b;
}
10 : sum(1,2)
12 : int c = 1+1;
19 : public class MyCls {
public int a;
public int b;
public int add(){
return a+b;
}
public int mul(){
return a*b;
}
}
20 : MyCls m = new MyCls();
21 : m.a = 2
22 : m.b = 3
23 : m.add()
24 : m.mul()
左侧的数字为条目id,可以利用该id,进行编辑和删除操作
编辑源条目:/edit
通过/list列出了所有输入的条目信息,下面我们通过/edit修改一下第一条内容:
jshell> /edit 1
此时会弹出修改框:
修改完成后,点击Accept。此时可以看到jshell窗口的输出结果发生了变化。
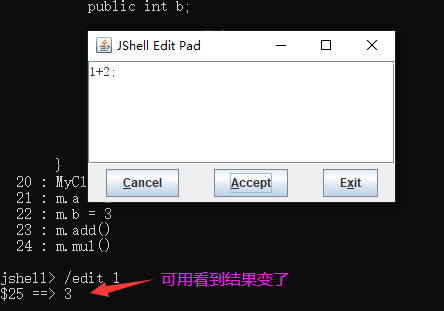
退出,点击Exit按钮。
删除源条目:/drop
/drop命令可以用来删除某个源条目,我们删除6条int a=1, b=2;
jshell> /drop 6 | 已删除 变量 b
执行后可以看到提示,实际上这种多个变量定义到一行上的,只会删除最后一个变量,可以试一下a还在,b已经没有了。
jshell> b | 错误: | 找不到符号 | 符号: 变量 b | 位置: 类 | b | ^ jshell> a a ==> 1
保存文件:/save
如果想把这次编辑的内容保存下来,以便下次继续使用,可以通过/save来保存到文件里,比如这样:
# 路径是jdk的bin目录 jshell> /save my1.txt
打开文件:/open
当我们换了jshell环境后,可以通过打开之前保存的文件来快速还原之前的执行内容,比如:
jshell> /open my1.txt
重置jshell:/reset
当我们要换一个内容编写的时候,需要清空之前执行的条目(清空/list的内容),这个时候就可以这样来实现:
jshell> /reset | 正在重置状态。
查看引入的包:/imports
jshell> /imports | import java.io.* | import java.math.* | import java.net.* | import java.nio.file.* | import java.util.* | import java.util.concurrent.* | import java.util.function.* | import java.util.prefs.* | import java.util.regex.* | import java.util.stream.*
退出jshell:/exit
jshell> /exit | 再见
2、JEP 269:集合工厂方法
JEP 269
用过谷歌Guava类库的知道,Guava提供了创建不可变集合的静态工厂方法,而且能够推断泛型,举个例子:
List<String> list = ImmutableList.of("诗", "书", "礼", "易", "春秋");
// ImmutableSet、ImmutableMap也有类似的方法
在 Java 9 之前,要构建一个不可变集合往往需要经历若干繁琐的步骤,如初始化集合、添加元素以及对其进行封装处理。Java 9 通过引入专门的不可变集合(包括List、Set、Map)特性,旨在简化这一流程,提供了一个既简洁又安全的方法来创建不可变集合,确保了集合内容的不变性和线程安全性。
其内容包括:
-
List.of():创建一个不可变的 List,可以传递任意数量(与其他工具类注意区分)的元素,注意里面不能有null。 -
Set.of():创建一个不可变的 Set,可以传递任意数量(与其他工具类注意区分)的元素,注意里面不能有null。 -
Map.of()和Map.ofEntries():用于创建一个不可变的 Map。Map.of()可以直接传递键值对,而Map.ofEntries()可以通过Map.entry(k, v)创建条目,注意key和value都能为null。以上方法创建的集合为不可变对象,不能添加、修改、删除。
一般写法
以往我们创建一些集合的时候,通常是这样写的:
// Set
Set<String> set = new HashSet<>();
set.add("秦");
set.add("汉");
set.add("唐");
set.add("宋");
// 如果想不可变
set = Collections.unmodifiableSet(set);
// List
List<String> list = new ArrayList<>();
list.add("诗");
list.add("书");
list.add("礼");
list.add("易");
list.add("春秋");
// 如果想不可变
list = Collections.unmodifiableList(list);
Java8的写法
在Java 8中可以使用Stream API简化一下:
Set<String> set = Stream.of("秦", "汉", "唐", "宋").collect(Collectors.toSet());
List<String> list = Stream.of("诗", "书", "礼", "易", "春秋").collect(Collectors.toList());
// 如果想不可变
Set<String> set = Collections.unmodifiableSet(Stream.of("秦", "汉", "唐", "宋").collect(Collectors.toSet()));
List<String> list = Collections.unmodifiableList(Stream.of("诗", "书", "礼", "易", "春秋").collect(Collectors.toList()));
Java9的写法
到了Java 9,这一操作变的更为简单,只需要这样:
Set<String> set = Set.of("秦", "汉", "唐", "宋");
List<String> list = List.of("诗", "书", "礼", "易", "春秋");
Map类型可以这样写:
Map<String, String> map = Map.of("诗仙", "李白", "诗圣", "杜甫", "诗佛", "王维");
需要注意的是,Map.of的参数是key和value成对出现的,所以参数数量一定是偶数:
Map.of() Map.of(k1, v1) Map.of(k1, v1, k2, v2) Map.of(k1, v1, k2, v2, k3, v3) ...
List.of与asList的区别
我们也可以使用asList来快速创建集合
List<String> list2 = Arrays.asList(new String[] { "诗", "书", "礼", "易", "春秋" });
看起来看List.of和Arrays.asList比较类似,那他们之间除了长的不一样外,还有什么区别吗?
-
Java 9中推出List.of创建的是不可变集合,而Arrays.asList是可变集合(长度不可变,值可变) -
List.of和Arrays.asList都不允许add和remove元素,但Arrays.asList可以调用set更改值,而List.of不可以,会报java.lang.UnsupportedOperationException异常 -
List.of中不允许有null值,Arrays.asList中可以有null值
3、JEP 213:细微调整
JEP 213
接口支持私有方法
接口进化过程:
Java 8 支持接口的默认方法和静态方法》Java 9 可定义 private 私有方法。
接口中私有方法的特点:
-
私有方法不能定义为抽象的
-
私有方法只能在接口内部使用,实现该接口的类或其他外部类无法调用这些方法
-
私有方法不会继承给接口的子接口,每个接口都必须自己定义自己的私有方法。
1、定义接口
public interface IWriter {
/**
* 测试抽象方法,需要被子类实现。
*/
void skill();
/**
* 测试默认实现方法。如果大部分子类都是相同的实现,可直接使用默认方法实现。
*/
default void write() {
System.out.println("=====这是一个默认方法====");
System.out.println("创作ing…………");
// 调用私有方法
thinking();
// 调用私有静态方法。非静态方法可以调用静态方法,反之不行。
hideTag();
System.out.println("创作完成…………");
}
/**
* 测试私有方法
*/
private void thinking() {
System.out.println("=====这是一个私有方法=====");
System.out.println("构思ing…………");
}
/**
* 测试静态方法。
*/
static void tag() {
System.out.println("=====这是一个静态方法=====");
System.out.println("标签是:文人");
// 调用私有静态方法
hideTag();
}
/**
* 测试私有静态方法
*/
private static void hideTag() {
System.out.println("=====这是一个私有静态方法=====");
System.out.println("隐藏标签:读书人");
}
}
2、定义接口实现
public class TangWriter implements IWriter {
@Override
public void skill() {
System.out.println("=====这是一个抽象方法的实现====");
System.out.println("技能:唐诗");
}
}
3、测试类
public class MyTest {
public static void main(String[] args) {
IWriter writer = new TangWriter();
// 调用抽象方法的实现
writer.skill();
// 调用默认方法
writer.write();
// 调用静态方法
writer.tag();
}
}
try-with-resources 优化
在Java 7 中引入了try-with-resources功能,保证了每个声明了的资源在语句结束的时候都会被关闭。
任何实现了java.lang.AutoCloseable接口的对象,和实现了java.io.Closeable接口的对象,都可以当做资源使用。
在Java 7中需要这样写:
try (BufferedInputStream bufferedInputStream = new BufferedInputStream(System.in);
BufferedInputStream bufferedInputStream1 = new BufferedInputStream(System.in)) {
// do something
} catch (IOException e) {
e.printStackTrace();
}
而到了Java 9无需为 try-with-resource 临时声明变量,简化为:
BufferedInputStream bufferedInputStream = new BufferedInputStream(System.in);
BufferedInputStream bufferedInputStream1 = new BufferedInputStream(System.in);
//变量 定义在try外边,在 try 中包裹,也会自动释放
try (bufferedInputStream;
bufferedInputStream1) {
// do something
} catch (IOException e) {
e.printStackTrace();
}
不支持下划线(_)作为标识符
在早期版本的 Java 中,下划线(_)已用作标识符或创建 变量名称。从 Java 9 开始,下划线字符是一个保留关键字,不能用作标识符或变量名。如果我们使用单个下划线作为标识符,程序将无法编译并抛出编译时错误,因为现在它是一个 关键字,并且在 Java 9 或更高版本中不能用作变量名称。
以下代码java9之前(比如java8)是可以的,java9及其后续版本,编译不通过
int _ = 50; // 解决办法,多加一个下划线,int __ = 50;
允许匿名类使用 <>(省略泛型的标记)
如果推断类型的参数类型是可忽略的,则允许使用匿名类的菱形。
在 Java 7 中引入的钻石操作符简化了泛型实例的创建,但它不能用于匿名内部类。由于这个限制,开发者不得不在使用匿名内部类时指定泛型参数,这增加了代码的冗余和复杂性。
在 Java 9 中,钻石操作符得到了改进,允许与匿名内部类配合使用。现在,当我们实例化一个具有泛型参数的匿名内部类时,无需显式指定这些参数,因为 Java 编译器能够利用上下文信息自动推导出正确的类型。
下面的代码在 Java 8 及以下版本是无法编译通过的,在 Java 9 及以上版本中可以:
public class MyTest {
class InnerC<T> {}
@Test
public void testJep213() {
InnerC<String> stringValue = new InnerC<>() {
}; // 这里java8会报错
}
}
4、Stream API 增强
Stream API 是在Java 8 中闪亮登场的,Java 9 对 Stream API 做了一些增强。
ofNullable
Stream<T> ofNullable(T t) 返回包含单个元素的顺序Stream ,如果非空,否则返回空Stream 。
这就意味着我们可以使用 Stream.ofNullable() 方法来快速创建一个只包含非空元素的 Stream,且无需担心处理 null 值的边界情况。比如,我们有一个 List 包含一些可能为 null 的字符串,我们可以使用 Stream.ofNullable() 来创建一个只包含非空字符串的 Stream:
public static void main(String[] args) {
Stream<String> stream1 = Stream.ofNullable(null);
System.out.println("Stream记录:");
stream1.forEach(System.out::println);
Stream<List<String>> stream2 = Stream.ofNullable(List.of("大学", "中庸", "论语", "孟子"));
System.out.println("Stream记录:");
stream2.forEach(System.out::println);
// 有null值,flatMap将集合扁平化处理
List<String> list = Arrays.asList("大学", null, "中庸", "论语", null, "孟子");
list.stream().flatMap(Stream::ofNullable).forEach(System.out::println);
}
iterate
Java 8 中的 iterate() 用于创建一个无限流,其元素由给定的初始值和一个生成下一个元素的函数产生,为了终止流我们需要使用一些限制性的函数来操作,例如 limit():
Stream.iterate(1,v -> v * 2).limit(10).forEach(System.out::println);
在 Java 9 中为了限制流的长度,增加了断言谓词,方法定义如下:
Stream<T> iterate(T seed, Predicate<? super T> hasNext, UnaryOperator<T> next)
这个是用来生成有限流的新迭代实现。
-
seed初始种子值 -
hasNext用来判断何时结束流,如果hasNext返回true,则next函数就会继续生成下一个元素;一旦hasNext返回false,序列生成将停止。 -
next函数用来计算下一个元素值。
示例:
//大约等于5时停止计算,返回结果 0 1 2 3 4 Stream.iterate(0, i -> i < 5, i -> i + 1).forEach(System.out::println);
等同于传统的:
for (int i = 0; i < 5; ++i) {
System.out.println(i);
}
takeWhile
Stream.takeWhile(Predicate) 从流的开头开始,选择满足断言Predicate条件的所有元素,直到找到第一个不满足条件的元素,一旦找到该元素,将会终止选择元素(即使未断言中的元素有满足条件的),并返回一个新的流,其中包含了前缀元素。
// 输出结果 2, 4, 6, 8。遇到10不满足条件终止,即使后面有2这个符合条件的元素也不再处理。 Stream.of(2, 4, 6, 8, 10, 2).takeWhile(x -> 1 < x && x < 10).forEach(System.out::println); // 返回结果为空。这里如果将1改为3,那么返回结果为空,因为第一个元素就不满足条件,后面的直接跳过 Stream.of(2, 4, 6, 8, 10, 2).takeWhile(x -> 3 < x && x < 10).forEach(System.out::println); // 输出结果 2, 4。遇到6不满足条件终止,即使后面有2这个符合条件的元素也不再处理。 Stream.of(2, 4, 6, 8, 10, 2).takeWhile(x -> 1 < x && x < 6).forEach(System.out::println);
dropWhile
这个API和takeWhile机制类似,也用来筛选Stream中的元素。
-
方法会从流的开头开始,跳过满足断言条件的所有元素,直到找到第一个不满足条件的元素。一旦找到第一个不满足条件的元素,
dropWhile()将停止跳过元素,并返回一个新的流,其中包含了剩余的元素。 -
如果流的所有元素都满足谓词条件,那么返回一个空流。
// 输出结果 10 3。大于1小于10的被跳过,知道遇到第一个不满足条件的10,后面的直接返回不再处理。 Stream.of(2, 4, 6, 8, 10, 3).dropWhile(x -> 1 < x && x < 10).forEach(System.out::println);
5、Optional 的增强
Optional增加了三个有用的API。
-
stream()Optional现在可以转Stream。 -
ifPresentOrElse(Consumer<? super T> action, Runnable emptyAction)如果有值了怎么消费,没有值了怎么消费。 -
or(Supplier<? extends Optional<? extends T>> supplier)该方法接受一个Supplier作为参数,如果当前Optional有值就返回当前Optional,当前Optional为空时,将执行Supplier获取一个新的Optional对象。可以用于提供默认值。
ifPresentOrElse
Java 8 有一个 ifPresent(),它用于在 Optional 包含非空值时执行指定的操作,Java 9 对其进行了改进增加了一个else处理。
public void ifPresentOrElse(Consumer<? super T> action, Runnable emptyAction)
它有两个参数:
-
action:是一个Consumer函数式接口,用于在Optional包含非空值时执行的操作。 -
emptyAction:是一个 Runnable 函数式接口,用于在Optional为空时执行的操作,通常是一些默认操作或错误处理。
private void testJava9(User user1) {
System.err.println("=====java 9=====");
Optional.ofNullable(user1).ifPresentOrElse(u -> {
System.err.printf("姓名%s 年龄%s %n", user1.getName(), user1.getAge());
}, () -> {
System.err.println("user 对象为null");
});
}
private void testJava8(User user1) {
System.err.println("=====java 8=====");
Optional.ofNullable(user1).ifPresent(u -> {
System.err.printf("姓名%s 年龄%s %n", user1.getName(), user1.getAge());
});
}
private void testCommon(User user1) {
System.err.println("=====直接判断=====");
if (user1 != null) {
System.err.printf("姓名%s 年龄%s %n", user1.getName(), user1.getAge());
} else {
System.err.println("user 对象为null");
}
}
@Test
public void testOptionalIfPresent() {
User user1 = null;
testCommon(user1);
testJava8(user1);
testJava9(user1);
System.err.println();
System.err.println();
System.err.println("*****赋值之后*****");
user1 = User.builder().name("kevin").build();
testCommon(user1);
testJava8(user1);
testJava9(user1);
}
结果
=====直接判断===== user 对象为null =====java 8===== =====java 9===== user 对象为null *****赋值之后***** =====直接判断===== 姓名kevin 年龄null =====java 8===== 姓名kevin 年龄null =====java 9===== 姓名kevin 年龄null
or
public Optional<T> or(Supplier<? extends Optional<? extends T>> supplier)
Optional.or()接受一个 Supplier作为参数,如果当前Optional有值就返回当前Optional,当前Optional 为空时,将执行Supplier获取一个新的Optional 对象。可以用于提供默认值。
@Test
public void testOptionalOr() {
// 创建一个 optional
Optional<String> optional = Optional.of("曹植");
// 创建一个 Supplier(生产者)
Supplier<Optional<String>> supplierString = () -> Optional.of("未设置");
// 输出 作者: 曹植
System.out.println("作者: " + optional.or(supplierString).get());
// option置空后。输出的是:作者: 未设置
optional = Optional.empty();
System.out.println("作者: " + optional.or(supplierString).get());
}
stream
public Stream<T> stream()
stream() 方法使得 Optional 对象能够被转换成一个流(Stream)。这样就可以利用 Stream 的各种功能来处理 Optional 中的值。
@Test
public void testOptionalStream() {
List<Optional<String>> list = List.of(
Optional.of("曹操"),
Optional.of("曹植"),
Optional.empty(),
Optional.of("曹丕"),
Optional.empty());
list.stream().flatMap(Optional::stream).filter(o -> o.equals("曹植")).map(val -> val + " —— 建安七子之一").forEach(System.out::println);
}
6、JEP 110:HTTP2客户端
JEP 110
定义一个新的 HTTP 客户端 API 来实现 HTTP/2 和 WebSocket,并且可以替换旧的HttpURLConnectionAPI。Java以前原生的确实难用,所以诞生了Apache Http Components 、OkHttp等好用的客户端。
@Test
public void testHttpRequest() {
try {
URI uri = new URI("https://www.baidu.com");
HttpRequest httpRequest = HttpRequest.newBuilder(uri).header("Content-Type", "*/*").GET().build();
HttpClient httpClient = HttpClient.newBuilder().connectTimeout(Duration.of(10, ChronoUnit.SECONDS))
.version(HttpClient.Version.HTTP_2).build();
HttpResponse<String> response = httpClient.send(httpRequest, BodyHandlers.ofString());
int statusCode = response.statusCode();
String body = response.body();
System.out.println(statusCode);
System.out.println(body);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
7、JEP 266:CompletableFuture增强
JEP 266
CompletableFuture 是 Java 8 中引入用于处理异步编程的核心类,它引入了一种基于 Future 的编程模型,允许我们以更加直观的方式执行异步操作,并处理它们的结果或异常。
但是在实际使用过程中,发现 CompletableFuture 还有一些改进空间,所以 Java 9 对它做了一些增强,主要内容包括:
-
新的工厂方法
-
支持延迟执行和超时(timeout)机制
-
支持子类化
支持超时机制
如果执行超时, orTimeout() 方法直接抛出了一个异常,而 completeOnTimeout() 方法则是返回默认值
// 允许为 CompletableFuture 设置一个超时时间。如果在指定的超时时间内未完成,将抛出 TimeoutException 异常 public CompletableFuture<T> orTimeout(long timeout, TimeUnit unit) // 允许为 CompletableFuture 设置一个超时时间。如果在指定的超时时间内未完成,则返回默认值value public CompletableFuture<T> completeOnTimeout(T value, long timeout, TimeUnit unit)
示例:
@Test
public void testTimeout() {
// 如果执行超时, orTimeout() 方法直接抛出了一个异常,而 completeOnTimeout() 方法则是返回默认值
try {
// orTimeout() 超时抛出了一个异常java.util.concurrent.TimeoutException
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(this::longLongAfter).orTimeout(1, TimeUnit.SECONDS);
future.get(); // 显式等待超时
} catch (Exception e) {
System.out.println(e);
}
try {
int defaultValue = 1987;
// completeOnTimeout() 超时返回默认值
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(this::longLongAfter).completeOnTimeout(defaultValue, 1,
TimeUnit.SECONDS);
Integer result = future.get(); // 显式等待超时
System.out.println(result);
} catch (Exception e) {
System.out.println(e);
}
}
// 这是一个超时方法
private Integer longLongAfter() {
try {
Thread.sleep(Integer.MAX_VALUE); // 一直睡,就是为了超时
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
return 666;
}
执行结果:
java.util.concurrent.ExecutionException: java.util.concurrent.TimeoutException 1987
支持延迟执行
CompletableFuture 类通过 delayedExecutor() 方法提供了对延迟执行的支持,该方法负责生成一个具有延后执行功能的 Executor,使得任务可以在未来指定的时间点才开始执行。
public static Executor delayedExecutor(long delay, TimeUnit unit)
示例:
@Test
public void testDelay() {
System.out.println(LocalDateTime.now());
// 创建一个延迟执行的Executor.5秒后执行
Executor delayedExecutor = CompletableFuture.delayedExecutor(5, TimeUnit.SECONDS);
// 使用延迟的Executor执行一个简单任务
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
System.out.println(LocalDateTime.now());
System.out.println("任务延迟后执行...");
}, delayedExecutor);
// 等待异步任务完成
future.join();
}
执行结果:
2024-02-20T16:07:00.314069600 2024-02-20T16:07:05.322898
可以看到相隔5秒。
8、JEP 102:Process API
JEP 102
在 Java 9 之前,Java 在进程控制方面的功能较为匮乏,获取系统进程的详尽信息及管理这些进程具有一定的难度。这迫使开发者不得不依赖特定于平台的解决方案来执行这些操作,从而影响了代码的跨平台兼容性和便捷性。
为了提升在操作系统级别管理和控制进程的便捷性和效率,Java 9 推出了新的 Process API。这一举措旨在增强对操作系统进程的控制和管理,同时确保跨不同操作系统的行为一致性。新 API 的主要功能如下:
-
增强的 Process 类:Java 9 增强了
Process类,提供了更多方法来管理和控制进程。 -
ProcessHandle 接口:引入了
ProcessHandle接口,它提供了获取进程的 PID(进程标识符)、父进程、子进程、进程状态等信息的能力。 -
流式 API:利用流式 API,可以更方便地处理进程的信息和状态。
下面是获取本地所有进程的相关信息:
@Test(priority = 1) // 不指定顺序时默认按字母顺序执行
public void testStream() {
ProcessHandle.allProcesses() // 获取所有进程
.forEach(processHandle -> {
System.out.printf("进程ID: %s, 命令: %s, 启动时间: %s, 用户: %s%n", //
processHandle.pid(), // 获取进程ID
processHandle.info().command().orElse("未知"), // 获取进程的命令信息
processHandle.info().startInstant().map(i -> i.toString()).orElse("未知"), // 获取进程的启动时间
processHandle.info().user().orElse("未知")); // 获取运行进程的用户
});
}
执行结果(部分):
进程ID: 2796, 命令: C:\Program Files (x86)\Notepad++\notepad++.exe, 启动时间: 2024-02-20T00:46:59.797Z, 用户: lk-202304051138\LD_001 进程ID: 18516, 命令: C:\Program Files\Typora\Typora.exe, 启动时间: 2024-02-20T00:52:34.161Z, 用户: lk-202304051138\LD_001 进程ID: 22920, 命令: C:\Windows\explorer.exe, 启动时间: 2024-02-20T01:02:48.523Z, 用户: lk-202304051138\LD_001 进程ID: 24468, 命令: C:\Program Files\Mozilla Firefox\firefox.exe, 启动时间: 2024-02-20T01:50:04.012Z, 用户: lk-202304051138\LD_001 进程ID: 24972, 命令: C:\Windows\ImmersiveControlPanel\SystemSettings.exe, 启动时间: 2024-02-20T01:57:29.345Z, 用户: lk-202304051138\LD_001 进程ID: 18072, 命令: C:\Program Files\WindowsApps\Microsoft.Windows.Photos_2023.10030.27002.0_x64__8wekyb3d8bbwe\Microsoft.Photos.exe, 启动时间: 2024-02-20T02:07:29.693Z, 用户: lk-202304051138\LD_001 进程ID: 1452, 命令: C:\Windows\System32\RuntimeBroker.exe, 启动时间: 2024-02-20T02:07:42.743Z, 用户: lk-202304051138\LD_001 进程ID: 22752, 命令: C:\Program Files (x86)\WXWork\4.1.20.6015\updated_web\WXWorkWeb.exe, 启动时间: 2024-02-20T03:11:06.533Z, 用户: lk-202304051138\LD_001 进程ID: 29060, 命令: C:\Program Files (x86)\Tencent\WeChat\WeChat.exe, 启动时间: 2024-02-20T04:07:25.283Z, 用户: lk-202304051138\LD_001 进程ID: 29372, 命令: C:\Program Files (x86)\Tencent\WeChat\WeChatWeb.exe, 启动时间: 2024-02-20T04:07:27.310Z, 用户: lk-202304051138\LD_001 进程ID: 30340, 命令: C:\Program Files (x86)\Tencent\WeChat\WeChatApp.exe, 启动时间: 2024-02-20T04:08:03.707Z, 用户: lk-202304051138\LD_001 进程ID: 28952, 命令: 未知, 启动时间: 未知, 用户: 未知 进程ID: 18232, 命令: C:\Program Files (x86)\Tencent\QQPCMgr\13.10.21936.216\QMUsbGuard.exe, 启动时间: 2024-02-20T04:31:27.884Z, 用户: lk-202304051138\LD_001 进程ID: 14000, 命令: C:\Users\LD_001\AppData\Local\SogouExplorer\SogouExplorer.exe, 启动时间: 2024-02-20T04:44:55.455Z, 用户: lk-202304051138\LD_001 进程ID: 28584, 命令: F:\eclipse-2023-12\eclipse.exe, 启动时间: 2024-02-20T05:40:41.543Z, 用户: lk-202304051138\LD_001 进程ID: 30864, 命令: 未知, 启动时间: 未知, 用户: 未知 进程ID: 33500, 命令: 未知, 启动时间: 未知, 用户: 未知 进程ID: 31136, 命令: F:\Program Files\Java\jdk-11.0.12\bin\javaw.exe, 启动时间: 2024-02-20T05:46:38.871Z, 用户: lk-202304051138\LD_001
9、JEP 259:Stack-Walking API
JEP 259
提供一个堆栈遍历API,允许轻松筛选和延迟访问堆栈跟踪中的信息。
API既支持在符合给定条件的处停止的搜索,也支持遍历整个堆栈。可参阅类java.lang.Stackwalker。
@Test
public void testJep213() {
System.out.println(StackWalker.getInstance().walk(s -> s.limit(5).collect(Collectors.toList())));
System.out.println(StackWalker.getInstance().walk(s -> s.collect(Collectors.toList())));
}
10、JEP 277:增强的@Deprecated注解
JEP 277
@Deprecated 注解用于标记过时的 API,Java 9 对其进行了改进,增加了两个的属性:
-
since:指明从哪个版本开始 API 被弃用。 -
forRemoval:指出这个 API 是否计划在未来的版本中被移除。
11、JEP 261:模块化系统
JEP 261
设计理念非常好,但目前对于开发人员来说比较鸡肋。
模块化系统是 Java9 架构的一次重大变革,它旨在解决长期以来 Java 应用所面临的一些结构性问题,特别是在大型系统和微服务架构中。
如果把 Java 8 比作单体应用,那么引入模块系统之后,从 Java 9 开始,Java 就华丽的转身为微服务。模块系统,项目代号 Jigsaw,最早于 2008 年 8 月提出,2014 年跟随 Java 9 正式进入开发阶段,最终跟随 Java 9 发布于 2017 年 9 月。
要想充分发挥模块化的优势,整个 Java 生态系统中的开发者必须遵循规范,将各自的 JAR 文件模块化。此外,在日常的开发实践中,确切地定义自己的模块以及妥善管理模块间的依赖关系,本身就是一项颇具挑战性的任务。
那么我们常用的 Spring 有没有被模块化打动,也按规范进行模块化了呢?至少到 Spring5 还没有,但是这里有一些答案:
1:Declare Spring modules with JDK 9 module metadata
SpringFramework 官方的回答: Declare Spring modules with JDK 9 module metadata [SPR-13501] · Issue #18079 · spring-projects/spring-framework · GitHub
机器翻译:JDK 9 的 Jigsaw 计划旨在允许将模块元数据 (module-info.java) 添加到框架和库 jar 中,同时保持它们与 JDK 8 的兼容性。让我们对 Spring Framework 5.0 的模块尽可能地这样做。然而,我们可能无法以这种方式表达我们的可选依赖安排,在这种情况下,我们可能不得不采用 “自动模块” 方法来实现 #18289 中更温和的目的。
2:Any plans for Java 9 Jigsaw (module) of Spring projects?
Any plans for Java 9 Jigsaw (module) of Spring projects? - Stack Overflow
###
Oracle JDK和OpenJDK之间的差异
尽管官方已经声明了让OpenJDK和Oracle JDK二进制文件尽可能接近的目标,但截止到JDK 21两者之间仍然存在一些差异。
目前的差异是:
-
Oracle JDK提供了安装程序(msi、rpm、deb等),它们不仅将JDK二进制文件放置在系统中,还包含更新规则,在某些情况下还可以处理一些常见的配置,如设置常见的环境变量(如Windows中的JAVA_HOME)和建立文件关联(如使用JAVA启动.jar文件)。OpenJDK仅作为压缩档案(tar.gz或.zip)提供。 -
Usage Logging仅在Oracle JDK中可用。 -
Oracle JDK要求使用Java加密扩展(JCE(Java Cryptography Extension ))代码签名证书对第三方加密提供程序进行签名。OpenJDK继续允许使用未签名的第三方加密提供程序。 -
java -version命令输出结果不同。Oracle JDK将输出java并包含LTS。Oracle生成的OpenJDK将显示OpenJDK,不包括Oracle特定的LTS标识符。 -
Oracle JDK 17及之后的版本在Oracle No-Fee Terms and Conditions License协议下发布。OpenJDK将在GPLv2wCP下发布,并将包括GPL许可证。因此,许可证文件是不同的。 -
Oracle JDK将在FreeType许可证下分发FreeType,而OpenJDK则将在GPLv2下分发。因此,\legal\java.desktop\freetype.md的内容将有所不同。 -
Oracle JDK有Java cup和steam图标,而OpenJDK有Duke图标。 -
Oracle JDK源代码包括ORACLE PROPRIETARY/CONFIDENTIAL. 使用受许可条款约束的说明(OTN(Oracle Technology Network License Agreement for Oracle Java SE )协议),OpenJDK源代码包含GPL协议。