近日,中山大学和 Pixocial 联合发布了 CatVTON,提出更加轻量化的架构与参数高效训练策略,助力图像虚拟试衣技术向落地应用迈进! 项目已公开论文并开源权重和代码,更有在线 Demo 可以试玩!

给钢铁侠穿上奇异博士的披风战袍?
让寡姐换上国风花草 Polo 衫?
又或者让马斯克穿着做旧牛仔走红毯?
只需要上传两张图像给 🐈 CatVTON,不到半分钟就可以得到!

相关链接
项目主页: https://zheng-chong.github.io/CatVTON
论文地址: https://arxiv.org/abs/2407.15886
论文阅读

摘要
基于扩散模型的虚拟试戴方法 实现真实的试穿效果,但复制骨干 网络作为参考网或利用额外的图像编码器来处理条件输入,导致高训练和推理成本。在这项工作中,我们重新思考了ReferenceNet和图像编码器的必要性,并对其进行了创新 设计了一种简单高效的虚拟试戴扩散模型CatVTON。 它可以方便地将任意类别的店内或穿过的服装无缝转移到目标人群 将它们在空间维度上连接起来作为输入。模型的有效性体现在三个方面:
-
轻量级的网络。只有原来的扩散模块,不需要额外的网络模块。正文编码器和正文注入的交叉注意事项,进一步降低参数167.02M。
-
参数高效训练。我们确认了试穿 通过对相关模块进行实验,仅训练49.57M个参数即可达到高质量的试戴效果 (约占骨干网络参数的5.51%)。
-
简化推理。CatVTON消除了所有不必要的东西条件和预处理步骤,包括姿态估计、人工解析和文本输入,只需要服装参考、目标人物图像和虚拟试穿过程的面具。
大量实验证明与基线方法相比,CatVTON以更少的先决条件和可训练的参数获得了更好的定性和定量结果。此外,CatVTON表示在野外场景中很好的泛化只有73K样本的开源数据集。
方法
轻量化模型架构
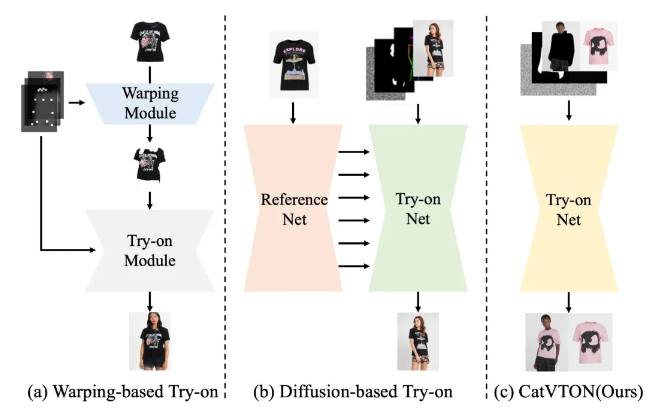
CatVTON 通过在输入上把人物、服装在通道维度拼接(Concatenate),在结构上摆脱了对额外的 ReferenceNet 的依赖,跳过了对图像虚拟试衣来说没有显著帮助的文本交叉注意力,同时也不需要任何额外的图像编码器来辅助生成。

CatVTON 在功能上丰富多样, 但其模型架构却十分简洁高效:
-
2 个网络模块(VAE+UNet)
-
899.06M 总参数量
-
<8G 推理显存(输出图像1024×768)
轻量化的架构来源于 CatVTON 对现有方法模块冗余 的观察: 基于 Warping 的方法依靠几何匹配对服装进行形变再利用试穿模块融合,结果生硬不自然; 基于扩散模型的方法引入ReferenceNet,加重了训练和推理的负担;
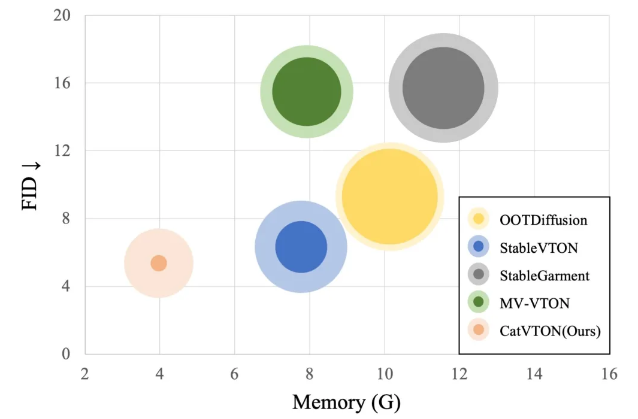
下表详细地比较了不同方法与 CatVTON 的模块数量、参数量、可训练参数量、显存占用、推理条件。
在网络模块上,CatVTON 只需要 VAE+UNet,无需任何额外的编码器;在模型总参数量上,CatVTON 比其他方法至少缩减了 44% ;在显存占用上,CatVTON 也只有其他方法的一半甚至更低,体现了 CatVTON 在 模型架构轻量化 上的优势。

参数高效训练
在训练上,CatVTON 探究了在将预训练扩散模型迁移到 TryOn 任务时去噪 UNet 中真正起作用的模块。
首先,去噪 UNet 在结构上是由不同特征尺度的ResNet 和 Transformer Blocks 堆叠而成(如下图)。其中 ResNet 是卷积网络,具有空间不变性,适用于特征的提取,并不负责跨空间的特征交互,这一部分在扩散模型进行大规模预训练时,已经具备了足够的特征编码能力,因此与迁移到 TryOn任务关联性不强。

Transformer Block 内部结构又可以细化为三个部分:Self Attention, Cross Attention 和 FFN。其中Cross Attention在 T2I 任务中用于与文本信息交互,FFN 起到特征映射的作用,因此与服装、人物特征交互最相关的便是 Self Attention。
理论上确定了需要训练的模块后,在实验上,CatVTON 文中还进行了消融,发现对 UNet、Transformer Block 和 Self Attention 分别进行解锁训练,其可视化结果并没有明显的差异,同时在指标上也十分接近,验证了“Self Attention是将预训练扩散模型迁移到 TryOn 任务的关键模块”的假设。
最后通过理论和实验锁定的Self Attention 部分,只有 49.57M 参数,仅占总参数量 5.71% 的部分,对其进行微调,就可以实现逼真的试穿效果,在上一节表格中可以看到,相较于其他方法,CatVTON 将可训练参数量减少了 10 倍 以上。
效果
多任务+多品类的虚拟换装

CatVTON 不仅可以实现传统的平铺服装图到人物的换装,而且同时支持上衣、裤子、裙子、套装 等不同品类服装,服装的形状和精细纹理都能保持较高的一致性。

另外,CatVTON 还可以实现人物A到人物B的换装,无需显式地指定类别,根据 Mask 的不同即可完成目标服装的试穿,支持单独的上衣、裤子、裙子或者全身多件服装同时更换。
结论
CatVTON 重新思考和设计了基于扩散模型的虚拟试穿框架,将多任务、多品类的虚拟试衣集成到同一模型中,以轻量化的框架和参数高效的训练策略实现了 SOTA 的试穿效果,降低了模型的训练、推理计算需求,推动了虚拟试衣模型走向落地与应用。