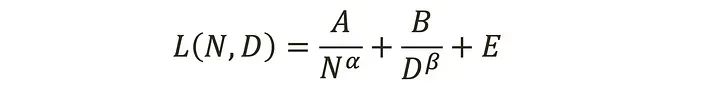目录
PerfTest工具
Incast traffic
Incast Traffic 的原因
Incast Traffic 的影响
解决方法
流量负载
简单解释
影响因素
影响
管理方法
LINKPACK
主要特点
LinkPack 的应用
运行结果
Quantum ESPRESSO
主要特点
TensorFlow
主要特点
主要组件
Incast与qp
Horovod
Horovod 的关键特性
Horovod 的工作原理
clos网络
Clos 网络的基本结构
网络拓扑
PoD
PoD 的特点
PoD 架构的组成
PoD 的设计
叶子交换机和主干交换机
叶子-主干架构
叶子交换机(Leaf Switch)
主干交换机(Spine Switch)
叶子-主干架构的优点
PFC
PFC的基本概念
PFC的工作原理
PFC的优点
异构流量
异构流量的类型
99th和99.9th百分位数的意义
TCP
TCP的主要特性
TCP连接的建立和终止
连接建立(三次握手)
连接终止(四次挥手)
TCP的核心机制
拥塞控制机制
Drop-tail机制
Drop-Tail机制的工作原理
Drop-Tail机制的优点
Drop-Tail机制的缺点
VDI
Exchange Server
Video Streaming
File Backup
IO深度
IO深度的作用和影响
示例
spine-leaf架构
Spine-Leaf架构的特点
Spine交换机和Leaf交换机的角色
Spine交换机
Leaf交换机
Spine-Leaf架构的优势
CDF
CDF的特点
重尾
PerfTest工具
PerfTest 是一种性能测试工具,用于评估计算机系统、网络和软件应用程序的性能。它的主要功能包括:
-
负载测试:模拟大量用户访问,测试系统在高并发条件下的表现。
-
压力测试:在系统上施加极限负载,确定系统的最大承载能力。
-
容量规划:通过性能测试数据,帮助规划和优化系统资源。
-
基准测试:评估不同系统或配置的性能。
-
监控和报告:实时监控系统性能,生成详细的性能报告。
常见的性能测试工具有 Apache JMeter、LoadRunner 和 Gatling。这些工具帮助你发现和解决性能瓶颈,确保系统在各种负载条件下的稳定性和可靠性。
Incast traffic
Incast traffic 是一种网络拥塞现象,特别常见于数据中心网络和分布式存储系统。当多个发送端(比如多台服务器)同时向同一个接收端发送数据时,接收端的网络接口会面临大量的数据流,导致其缓冲区快速填满,从而引发网络拥塞和数据包丢失。这种现象被称为 incast traffic。
Incast Traffic 的原因
-
高并发请求:在分布式系统中,多个节点可能会同时向同一个节点发送请求或数据,例如在分布式文件系统或分布式数据库中。
-
网络瓶颈:接收端的网络带宽有限,当同时有大量数据到达时,会超过其处理能力。
-
TCP 特性:TCP 协议在发生拥塞时会减少传输速度,但当多个 TCP 流同时发生拥塞时,会造成更严重的网络拥堵。
Incast Traffic 的影响
-
高延迟:网络拥塞会导致数据传输延迟增加。
-
数据丢包:缓冲区溢出会导致数据包丢失,必须重新传输。
-
性能下降:系统整体性能会受到影响,特别是在需要高吞吐量和低延迟的应用中。
解决方法
-
增加缓冲区大小:增大接收端的缓冲区,可以缓解瞬时的高流量压力。
-
优化 TCP 协议:调整 TCP 的窗口大小和重传机制,减少拥塞的影响。
-
负载均衡:通过负载均衡技术,将流量分散到多个接收端,避免单一节点成为瓶颈。
-
应用层控制:在应用层面进行流量控制,分批发送数据,避免同时发送大量数据。
流量负载
流量负载是指网络或系统中数据传输的量和频率。它表示在一定时间内,网络或系统所处理的流量多少和负荷情况。
简单解释
-
高流量负载:当大量数据在短时间内传输,网络或系统承受较大压力。
-
低流量负载:当数据传输较少,网络或系统承受压力较小。
影响因素
-
用户数量:同时在线的用户越多,流量负载越高。
-
数据量:传输的数据越大,流量负载越高。
-
应用类型:视频流、文件传输等需要高带宽的应用会增加流量负载。
影响
-
高流量负载:可能导致网络拥塞、延迟增加和性能下降。
-
低流量负载:系统运行更顺畅,响应更快。
管理方法
-
负载均衡:将流量分配到多个服务器,避免单一服务器过载。
-
流量控制:限制每个用户的最大流量,避免个别用户占用过多资源。
LINKPACK
inkPack 是一种用于测试计算机系统浮点计算能力的基准测试程序。它主要用于评估系统的性能,特别是在高性能计算(HPC)领域。LinkPack 测试的是系统解决线性方程组的能力,通常用来衡量浮点运算的每秒性能(FLOPS)。
主要特点
-
浮点计算能力:LinkPack 专注于测试系统的浮点计算性能。
-
高性能计算应用:常用于评估 HPC 系统,如超级计算机。
-
标准化测试:提供一个统一的标准来比较不同系统的计算性能。
LinkPack 的应用
-
系统性能评估:通过运行 LinkPack,可以了解系统在处理复杂计算任务时的表现。
-
硬件优化:制造商和工程师使用 LinkPack 来测试和优化硬件设计。
-
学术研究:在科学研究中,用于比较不同计算方法和系统配置的性能。
运行结果
LinkPack 的测试结果通常以 FLOPS(每秒浮点运算次数)表示。较高的 FLOPS 值表示系统具有更强的计算能力。
Quantum ESPRESSO
Quantum ESPRESSO 是一个开源的集成套件,用于电子结构计算和材料模拟,特别适用于密度泛函理论(DFT)计算。它基于平面波基组和伪势方法,广泛应用于计算材料科学、凝聚态物理和量子化学领域。
主要特点
-
密度泛函理论(DFT):主要用于进行基于 DFT 的电子结构计算。
-
开源软件:免费使用,并且用户可以修改和扩展代码。
-
模块化设计:包括多个相互关联的程序模块,每个模块都专注于特定的计算任务,如能量计算、结构优化、分子动力学模拟等。
-
高效并行计算:支持并行计算,能够在高性能计算环境中有效运行。
-
多功能:适用于各种材料系统,包括金属、半导体、绝缘体、分子和表面。
TensorFlow
TensorFlow 是一个由 Google Brain 团队开发的开源机器学习框架,广泛用于研究和生产中的机器学习任务。其核心理念是使用数据流图(Data Flow Graph)来进行数值计算,节点表示操作(operation),边表示多维数组(tensor)在节点间的传递。
主要特点
-
开源和社区驱动:TensorFlow 是开源软件,拥有庞大的用户和开发者社区,提供丰富的资源和支持。
-
跨平台:支持在多种平台上运行,包括桌面、服务器、移动设备和嵌入式系统。
-
高性能计算:支持 CPU、GPU 和 TPU(Tensor Processing Unit)加速,能够处理大规模的计算任务。
-
灵活性:提供多种 API,包括高层次的 Keras API 和低层次的核心 API,适合不同的开发需求。
-
可扩展性:通过 TensorFlow Extended (TFX) 等工具,可以扩展到生产环境,支持机器学习模型的训练、验证和部署。
主要组件
-
TensorFlow Core:核心库,用于构建和训练机器学习模型,支持数据流图的构建和执行。
-
Keras:高级 API,用于快速构建和训练深度学习模型,简化了模型的定义和训练过程。
-
TensorFlow Extended (TFX):用于构建机器学习工作流的端到端平台,包括数据验证、特征工程、模型训练、评估和部署。
-
TensorFlow Lite:用于在移动和嵌入式设备上部署机器学习模型,提供优化的模型和推理引擎。
-
TensorFlow.js:在浏览器和 Node.js 环境中运行 TensorFlow,支持直接在网页中进行机器学习计算。
-
TensorBoard:用于可视化和调试 TensorFlow 程序的工具,可以展示模型的结构、训练过程中的指标变化等。
Incast与qp
Incast表示多少个发送方向同一接收方发送信息
qp代表每个发送方与接收方之间进行数据传输所需要的队列数量
Horovod
Horovod 是一个开源框架,用于在分布式训练中高效地并行化深度学习模型。它由 Uber 开发,并被广泛应用于各类深度学习任务中。Horovod 最初设计用于 TensorFlow,但现在也支持 PyTorch、MXNet 和 Keras。
Horovod 的关键特性
-
易用性:Horovod 通过 MPI(Message Passing Interface)标准提供了简洁的 API,使得用户可以在现有的深度学习代码基础上快速集成分布式训练。
-
高性能:利用 MPI 和 NCCL(NVIDIA Collective Communication Library)等高效通信库,Horovod 实现了快速的数据传输和同步,能够显著提升分布式训练的性能。
-
弹性伸缩:Horovod 支持弹性伸缩,可以根据计算资源的变化动态调整训练过程中的节点数量。
Horovod 的工作原理
Horovod 使用了一种名为 AllReduce 的技术来同步不同节点上的模型参数。在分布式训练中,每个节点计算一小部分数据的梯度,然后这些梯度通过 AllReduce 操作在所有节点间进行聚合和同步,最终每个节点都获得相同的模型更新。这种方法确保了模型在每个节点上保持一致,从而实现有效的分布式训练。
clos网络
Clos 网络是一种多级网络拓扑结构,通常用于数据中心和大型交换网络中,以实现高带宽、低延迟和高可靠性。它由 Charles Clos 于 1952 年提出,原本用于电话交换系统。Clos 网络通过分层和多路径设计,避免了单点故障和瓶颈问题。
Clos 网络的基本结构
Clos 网络由以下几个部分组成:
-
输入层(Ingress Stage):包含多个输入交换单元,每个单元连接到多个中间层交换单元。
-
中间层(Middle Stage):包含多个交换单元,每个中间层交换单元连接到输入层和输出层的所有交换单元。
-
输出层(Egress Stage):包含多个输出交换单元,每个单元连接到多个中间层交换单元。
网络拓扑
一个典型的 Clos 网络可以表示为 C(m, n, r),其中:
m 是输入层和输出层的交换单元数目。
n 是中间层的交换单元数目。
r 是每个交换单元的端口数目。
三级clos网络

PoD
在数据中心网络设计中,PoD(Pod)是一种模块化的架构,用于简化网络的构建和管理。PoD架构允许网络以模块化的方式进行扩展,每个PoD可以独立设计、部署和管理,然后通过标准化的接口连接到其他PoD,形成一个大规模的数据中心网络。
PoD 的特点
-
模块化:每个PoD是一个独立的模块,包含一定数量的服务器、存储设备和网络设备。
-
可扩展性:可以通过添加更多的PoD来扩展数据中心的规模,而无需重新设计整个网络。
-
简化管理:每个PoD可以独立管理和维护,减少了管理的复杂性。
-
标准化接口:PoD之间通过标准化的网络接口互连,确保不同PoD之间的互操作性。
PoD 架构的组成
一个典型的PoD架构通常包含以下部分:
-
计算节点:大量的服务器,提供计算资源。
-
存储节点:存储设备,用于数据存储和管理。
-
网络设备:交换机和路由器,用于连接计算和存储节点,并提供与其他PoD的互连。
-
电源和冷却:电源分配单元(PDU)和冷却系统,确保所有设备正常运行。
PoD 的设计
一个PoD的设计通常包括以下步骤:
-
确定需求:根据数据中心的业务需求,确定每个PoD需要支持的计算、存储和网络资源。
-
选择设备:选择适合的服务器、存储设备和网络设备,确保它们可以满足PoD的需求。
-
设计拓扑:设计PoD内部的网络拓扑,确保高带宽和低延迟。可以采用Clos网络等高性能拓扑结构。
-
标准化接口:定义PoD与其他PoD之间的标准化接口,确保互操作性。
-
部署和配置:按照设计部署设备,并进行配置和测试,确保PoD正常运行。
叶子交换机和主干交换机
叶子-主干架构
叶子-主干架构是数据中心网络设计的一种模式,其中网络设备被组织成两层:叶子层(leaf layer)和主干层(spine layer)。
叶子交换机(Leaf Switch)
叶子交换机是连接服务器和存储设备的网络设备。在叶子-主干架构中,叶子交换机直接连接到主干交换机,并通过这些主干交换机相互通信。
特点:
-
接入层:叶子交换机通常位于网络的接入层,直接连接到服务器和存储设备。
-
多对多连接:每个叶子交换机连接到多个主干交换机,确保多路径冗余和负载均衡。
-
低延迟:叶子交换机与服务器之间的连接具有较低的延迟,有助于提高应用程序的性能。
优势:
-
高可扩展性:可以轻松增加更多叶子交换机来扩展网络容量。
-
低延迟:由于叶子交换机与服务器之间的连接较短,数据传输延迟较低。
主干交换机(Spine Switch)
主干交换机是连接叶子交换机的核心设备。在叶子-主干架构中,所有的叶子交换机都连接到主干交换机,从而形成网络的骨干。
特点:
-
核心层:主干交换机位于网络的核心层,负责在叶子交换机之间转发数据。
-
高带宽:主干交换机通常具有高带宽端口,能够处理大量的数据流量。
-
全互联:每个主干交换机通常连接到所有的叶子交换机,确保全网的可达性。
优势:
-
高带宽:主干交换机之间的高带宽连接确保了网络的高吞吐量。
-
高可用性:多路径冗余设计提高了网络的可靠性和可用性。
叶子-主干架构的优点
-
可扩展性:通过添加更多的叶子和主干交换机,可以轻松扩展网络的容量。
-
简化管理:叶子-主干架构的对称性和一致性使网络管理和配置更加简单。
-
高性能:叶子和主干交换机的多路径设计提供了高带宽和低延迟的连接,有助于提高整体网络性能。
-
故障隔离:由于叶子-主干架构中的交换机连接是多路径的,单个交换机的故障不会导致整个网络的瘫痪,提高了网络的可靠性。
PFC
PFC(Priority Flow Control,优先级流量控制)是一种用于数据中心网络的流量控制机制,属于数据链路层的标准,具体规范由IEEE 802.1Qbb定义。PFC旨在解决数据中心网络中可能出现的流量拥塞问题,确保关键流量在网络拥塞时得到优先传输。
PFC的基本概念
PFC扩展了传统的以太网流量控制(802.3x PAUSE)机制。传统的802.3x PAUSE机制在检测到拥塞时会停止所有的流量传输,这样虽然可以避免拥塞蔓延,但也会导致重要的数据流被阻塞,影响整体性能。
与此不同,PFC允许对不同的优先级流进行独立的流量控制。以太网帧中的优先级字段(Priority Code Point,PCP)被用来标识流量的优先级。PFC可以根据这些优先级字段有选择性地暂停某些特定优先级的流量,而不影响其他优先级的流量。
PFC的工作原理
PFC通过在数据包中添加优先级信息来实现优先级流量控制。以下是其基本工作流程:
-
标记优先级:网络设备(如交换机或网卡)在发送数据帧时,根据数据流的类型和重要性在以太网帧的头部标记优先级。
-
检测拥塞:接收端(如交换机或网卡)检测到拥塞时,根据数据帧的优先级决定是否发送PAUSE帧来暂停特定优先级的流量。
-
发送PAUSE帧:如果检测到某个优先级的流量导致了拥塞,接收端会向发送端发送包含该优先级信息的PAUSE帧,指示发送端暂停发送该优先级的流量。
-
恢复传输:当拥塞消除后,接收端会发送一个新的PAUSE帧,指示发送端恢复被暂停的流量传输。
PFC的优点
-
精细化控制:PFC能够基于优先级对流量进行精细化控制,只暂停某些特定优先级的流量,而不影响其他优先级的流量,保证了重要流量的传输。
-
提高可靠性:通过有效控制流量拥塞,PFC减少了丢包现象,提高了网络的可靠性和稳定性。
-
支持多样化业务:PFC支持在同一网络中传输多种类型的业务数据,如存储流量(如iSCSI、FCoE)、普通数据流量(如文件传输)等,确保关键业务数据的优先传输。
异构流量
Heterogeneous Traffic(异构流量)是指在网络中存在多种不同类型和特征的流量,这些流量可能在性质、优先级、带宽需求、延迟敏感性等方面有所不同。异构流量广泛存在于现代网络环境中,如企业网络、数据中心网络和互联网。
异构流量的类型
-
实时流量:包括语音、视频会议和在线游戏等,这类流量对延迟和抖动非常敏感,通常需要较高的优先级和较低的延迟。
-
数据流量:包括文件传输、数据库同步和备份等,这类流量通常对带宽需求较高,但对延迟要求较低。
-
控制流量:用于网络设备的管理和控制,如路由协议、网络管理协议等,这类流量的优先级较高,但带宽需求较低。
-
交互流量:包括网页浏览、在线聊天等,这类流量对延迟和带宽都有一定要求,但不如实时流量敏感。
-
批处理流量:如大规模数据分析和科学计算等,这类流量对带宽需求高,但可以容忍较高的延迟。
99th和99.9th百分位数的意义
99th percentile FCT:表示在所有数据流中,有99%的流完成时间小于或等于这个值,只有1%的流完成时间大于这个值。这个指标用来识别网络性能中最慢的1%的数据流。
99.9th percentile FCT:表示在所有数据流中,有99.9%的流完成时间小于或等于这个值,只有0.1%的流完成时间大于这个值。这个指标用来识别网络性能中最慢的0.1%的数据流。
TCP(Transmission Control Protocol,传输控制协议)是一个面向连接的、可靠的传输层协议,广泛应用于因特网和局域网中的数据传输。TCP提供了确保数据可靠传输的机制,如序列控制、确认、重传和流量控制等。
TCP
TCP的主要特性
-
面向连接:TCP在传输数据之前需要在发送方和接收方之间建立一个连接(三次握手)。
-
可靠传输:通过序列号、确认和重传机制,确保数据不丢失、不重复,并且按顺序到达。
-
流量控制:通过滑动窗口机制,控制发送方的发送速率,以避免网络拥塞和接收方的缓冲区溢出。
-
拥塞控制:使用慢启动、拥塞避免、快速重传和快速恢复等机制,防止网络拥塞。
TCP连接的建立和终止
连接建立(三次握手)
-
第一次握手:客户端发送一个SYN(同步)包给服务器,表示请求建立连接。SYN包包含初始序列号。
-
第二次握手:服务器收到SYN包后,回复一个SYN-ACK包,表示同意建立连接,并确认客户端的序列号。
-
第三次握手:客户端收到SYN-ACK包后,发送一个ACK包给服务器,确认服务器的序列号。此时,连接建立完成,双方可以开始传输数据。
连接终止(四次挥手)
-
第一次挥手:客户端发送一个FIN(终止)包,表示请求终止连接。
-
第二次挥手:服务器收到FIN包后,发送一个ACK包确认,然后进入CLOSE-WAIT状态。
-
第三次挥手:服务器发送一个FIN包,表示同意终止连接。
-
第四次挥手:客户端收到FIN包后,发送一个ACK包确认,然后进入TIME-WAIT状态,等待一段时间(通常是两倍的最大段生存时间),以确保服务器收到ACK包,最后关闭连接。
TCP的核心机制
-
序列号和确认号:每个TCP段都有一个序列号,接收方会用确认号确认已经收到的数据。通过序列号和确认号,TCP可以确保数据的顺序和完整性。
-
重传机制:如果发送方在一定时间内没有收到接收方的确认,会重传未确认的数据,以保证数据不丢失。
-
滑动窗口:滑动窗口机制用于流量控制,限制发送方在等待确认之前可以发送的数据量。窗口大小动态调整,以适应网络条件。
-
拥塞控制:包括慢启动、拥塞避免、快速重传和快速恢复等算法,以防止和缓解网络拥塞。
拥塞控制机制
-
慢启动(Slow Start):在连接开始或重传超时后,TCP的拥塞窗口(cwnd)从一个较小的值开始,并在每次收到确认时指数增长,直到达到一个阈值(ssthresh)。
-
拥塞避免(Congestion Avoidance):达到阈值后,拥塞窗口以线性增长的方式增加,以避免网络拥塞。
-
快速重传(Fast Retransmit):当发送方收到三个重复的确认(即相同的ACK)时,认为该段已丢失,立即重传该段数据,而不必等待重传计时器超时。
-
快速恢复(Fast Recovery):在快速重传后,不进入慢启动,而是将拥塞窗口减半,并开始线性增长。
Drop-tail机制
Drop-Tail机制是一种简单的队列管理策略,广泛用于网络设备(如路由器和交换机)中的TCP流量控制。它的主要特征是在缓冲区满时丢弃到达的任何新数据包。尽管这种机制易于实现和理解,但它存在一些问题,特别是在高流量或拥塞的网络环境中。
Drop-Tail机制的工作原理
-
队列缓冲区:网络设备为每个输出端口维护一个队列缓冲区,用于暂时存储即将发送的数据包。
-
队列满:当队列缓冲区满时,任何新到达的数据包将被直接丢弃,不会进入队列。
-
FIFO顺序:Drop-Tail机制按照先进先出(FIFO)的原则处理数据包,即先到的数据包先发送。
Drop-Tail机制的优点
-
简单易实现:由于其简单的逻辑,Drop-Tail机制易于实现和部署,不需要复杂的计算或算法。
-
低开销:该机制的实现对计算资源的开销较低,因为它仅需检测队列是否已满即可决定是否丢弃数据包。
Drop-Tail机制的缺点
-
全局同步(Global Synchronization):当多个TCP流同时检测到数据包丢失时,它们会同时进入拥塞控制阶段,减少发送速率。这会导致网络中的整体传输速率下降,形成“全局同步”问题。
-
不公平性:由于所有流都受到相同的处理,某些流可能会占用更多的带宽,而其他流可能会因为频繁的数据包丢失而遭受不公平的待遇。
-
缓冲区拥塞:在高流量情况下,缓冲区容易被填满,导致新到达的数据包被丢弃。这会引起TCP的重传机制,进一步加剧网络拥塞。
VDI
(Virtual Desktop Infrastructure,虚拟桌面基础架构):
-
特点:支持虚拟桌面环境,用户通过网络访问虚拟桌面。
-
读写比率:2:8,表示写操作多于读操作。
-
块大小:1KB-64KB,适合频繁的写操作。
Exchange Server
特点:用于电子邮件和协作服务,如Microsoft Exchange。需要处理大量的邮件和附件。
读写比率:6:4,表示读操作多于写操作。
块大小:32KB-512KB,适合中等大小的数据块。
Video Streaming
视频流
特点:用于实时传输视频内容,如在线视频播放。需要连续、顺畅的数据传输。
读写比率:2:8,表示写操作多于读操作,可能因为视频上传较多。
块大小:64KB,适合连续的数据流。
File Backup
文件备份
特点:用于数据备份和恢复。需要处理大量的文件和数据块。
读写比率:4:6,表示写操作多于读操作。
块大小:16KB-64KB,适合批量数据备份操作。
IO深度
IO深度(I/O Depth,或者叫Queue Depth)是指存储系统中并发处理的输入/输出(I/O)请求的数量。它是衡量存储系统性能的重要指标之一,尤其是在评估存储设备(如硬盘、固态硬盘、以及存储网络)的性能时。
IO深度的作用和影响
-
并发性:
-
定义:IO深度越高,表示系统可以同时处理的I/O请求越多。
-
影响:更高的IO深度可以提高存储设备的吞吐量,因为设备可以更有效地利用其内部并行处理能力。
-
-
性能:
-
延迟(Latency):过高的IO深度可能会增加每个I/O请求的等待时间,从而增加整体延迟。
-
吞吐量(Throughput):适中的IO深度可以提高系统的整体吞吐量,因为它允许设备更好地处理并行任务。
-
平衡:需要在延迟和吞吐量之间找到平衡点,选择合适的IO深度来优化性能。
-
-
应用场景:
-
数据库应用:通常需要较低的IO深度以减少延迟,提高单个事务的响应速度。
-
批处理任务:可以利用较高的IO深度来提高吞吐量,因为这些任务通常对延迟不敏感。
-
示例
假设一个存储系统可以同时处理8个I/O请求:
-
IO深度为1:系统一次只处理一个请求,其他请求必须等待当前请求完成后才能被处理。这种情况下,系统的并发性较低,但延迟可能较低。
-
IO深度为8:系统可以同时处理8个请求,从而提高了吞吐量,因为更多的请求可以并行处理。但如果请求过多,可能会增加每个请求的等待时间。
spine-leaf架构
Spine-leaf结构是一种现代数据中心网络架构,旨在提供高带宽、低延迟和高可扩展性的网络解决方案。这个架构由两个主要层次组成:spine交换机和leaf交换机。
Spine-Leaf架构的特点
-
扁平化设计:
-
Leaf层:包含连接到服务器和存储设备的交换机。所有的服务器和存储设备都直接连接到leaf交换机。
-
Spine层:包含高带宽、低延迟的核心交换机,每个leaf交换机都连接到每一个spine交换机。
-
-
全网状结构:
-
Leaf交换机连接到每一个spine交换机,确保任意两个leaf交换机之间的流量都可以通过一个spine交换机转发。这种设计提供了多个路径,提高了网络的冗余性和容错能力。
-
Spine交换机和Leaf交换机的角色
Spine交换机
-
高带宽:Spine交换机通常具有非常高的端口密度和带宽,以处理大量来自leaf交换机的流量。
-
低延迟:Spine交换机设计为具有极低的延迟,以确保快速的数据传输。
-
核心路由:Spine交换机负责在网络的核心层进行流量转发,连接所有的leaf交换机。
Leaf交换机
-
接入层:Leaf交换机直接连接到服务器和存储设备,处理东西向流量(服务器之间的流量)。
-
连接Spine层:每个leaf交换机都连接到每一个spine交换机,确保全网状结构和多路径冗余。
Spine-Leaf架构的优势
-
高可扩展性:
-
通过添加更多的spine和leaf交换机,可以轻松扩展网络的容量和性能,以支持更多的服务器和更高的流量需求。
-
-
高可靠性和冗余性:
-
由于每个leaf交换机都连接到每一个spine交换机,网络具有多路径冗余,单点故障不会导致网络中断,提高了网络的可靠性。
-
-
低延迟和高带宽:
-
扁平化的网络结构减少了网络层次,降低了延迟,同时高带宽的spine交换机可以处理大量的东西向流量。
-
-
简化的网络管理:
-
统一的架构设计使得网络管理和故障排查更加简便高效。
-
CDF
CDF 是 累积分布函数(Cumulative Distribution Function)的缩写,是统计学中用来描述随机变量分布情况的一个重要工具。它表示的是随机变量 XXX 小于或等于某个值 xxx 的概率。用数学公式表示,CDF 可以定义为:
F(x)=P(X≤x)F(x) = P(X \leq x)F(x)=P(X≤x)
CDF的特点
-
范围:
-
CDF 的值范围从 0 到 1,随着 xxx 从负无穷增加到正无穷,CDF 从 0 单调递增到 1。
-
-
单调性:
-
CDF 是单调不减的函数,即对于任意 x1<x2x_1 < x_2x1<x2,都有 F(x1)≤F(x2)F(x_1) \leq F(x_2)F(x1)≤F(x2)。
-
-
极限值:
-
当 xxx 趋向负无穷时,CDF 的值趋向于 0;当 xxx 趋向正无穷时,CDF 的值趋向于 1。
-
重尾
重尾(Heavy-tailed)分布是一类在概率论和统计学中具有重要意义的分布,其特征是分布的尾部(即远离平均值的部分)比一般的分布衰减得更慢。这意味着在重尾分布中,大值出现的概率比在轻尾分布中(如正态分布)要高得多。