人工智能的世界正在经历一场革命,大型语言模型正处于这场革命的前沿,它们似乎每天都在变得更加强大。从BERT到GPT-3再到PaLM,这些AI巨头正在推动自然语言处理可能性的边界。但你有没有想过是什么推动了它们能力的飞速提升?
在这篇文章中,我们将介绍使这些模型运作的秘密武器——一个由三个关键部分组成的法则:模型大小、训练数据和计算能力。通过理解这些因素如何相互作用和规模化,我们将获得关于人工智能语言模型过去、现在和未来的宝贵见解。
引言
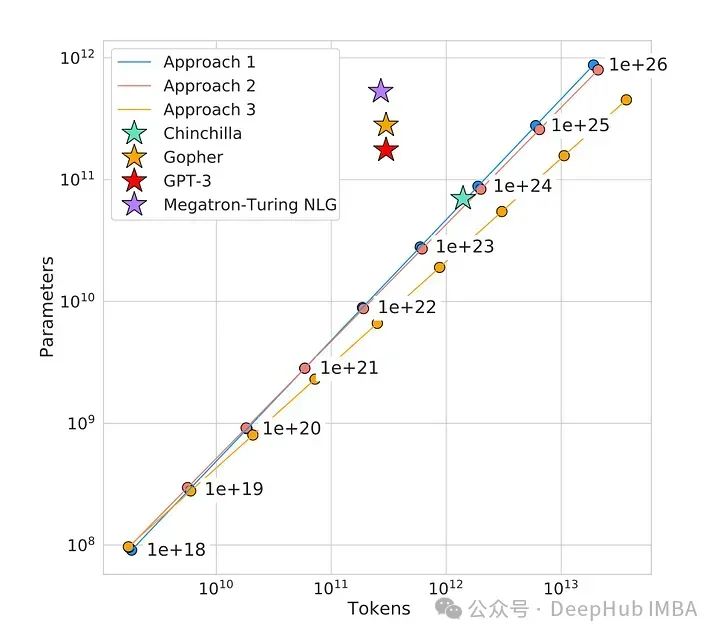
过去几年中,语言模型的发展迅速扩大。如下图所示,语言模型从2018年的BERT-base的1.09亿参数规模,增长到2022年的PaLM的5400亿参数。每个模型不仅在大小上增加(即参数数量),还在训练令牌的数量和训练计算量(以浮点运算或FLOPs计)上都有所增加。

“这三个因素之间有什么关系?”模型大小和训练数据对模型性能(即测试损失)的贡献是否相等?哪一个更重要?如果我想将测试损失降低10%,我应该增加模型大小还是训练数据?需要增加多少?
这些问题的答案在于大型语言模型(LLMs)的规模化法则行为中。但在深入答案之前,让我们先回顾一下幂律分布。
幂律分布
幂律是两个量x和y之间的非线性关系,可以通用地建模为:
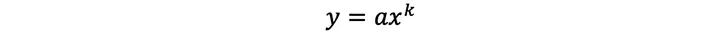
其中k和a是常数。
如果我在对数-对数图中绘制幂律关系,它将是一条直线,因为
让我们为两个不同的k值绘制幂律图,以观察其不同的行为。如果k是正的,y和x之间有增加的关系。然而,如果k是负的,它们之间则有减少的关系。这里有一个简单的代码来绘制幂律曲线。
import numpy as np
import matplotlib.pyplot as plt
def plot_power_law(k, x_range=(0.1, 100), num_points=10000):
"""
Plot the power law function y = x^k for any non-zero k.
Parameters:
k (float): The exponent for the power law (can be positive or negative, but not zero).
x_range (tuple): The range of x values to plot (default is 0.1 to 10).
num_points (int): Number of points to calculate for a smooth curve.
"""
if k == 0:
raise ValueError("k cannot be zero")
# Generate x values
x = np.linspace(x_range[0], x_range[1], num_points)
# Calculate y values
y = x**k
# Create the plot
plt.figure(figsize=(10, 6))
plt.plot(x, y, 'b-', label=f'y = x^{k}')
plt.title(f'Power Law: y = x^{k}')
plt.xlabel('x')
plt.ylabel('y')
plt.grid(True)
plt.legend()
plt.show()
我们把k为正时的情况画成这样
plot_power_law(2) # y = x^2

如果我们选择一个负数关系就会减小
plot_power_law(-0.5) # y = x^(-0.5)
上面的图在x轴和y轴上都是线性刻度。如果我们用对数标度表示它们,它们将是一条直线,如公式2所示。现在,让我们把这些联系在一起,展示幂律是如何与llm的测试损失联系起来的。
语言模型中的Scaling Law
语言模型中的规模化法则行为(Scaling Law)指的是模型性能与模型大小、数据集大小和计算资源等多种因素之间观察到的关系。随着模型的扩展,这些关系遵循可预测的模式。规模化法则行为的关键因素如下:
- 模型大小:随着模型中参数数量的增加,性能通常会按照幂律改善。
- 数据集大小:更大的训练数据集通常带来更好的性能,也遵循幂律关系。
- 计算:用于训练的计算资源(浮点运算次数)与性能改善相关。
下图展示了大型语言模型中的规模化法则。
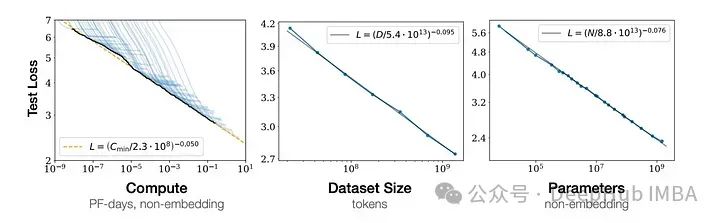
所有三个图都在对数-对数空间中是线性的,这证明了测试损失与计算、数据集大小和模型参数之间遵循幂律关系。此外这些图表还显示,随着模型大小、数据集大小和用于训练的计算量的增加,语言建模性能得到了提升。
我们已经看到了这三个因素与测试损失之间的单独关系。但是现在有几个问题:这三个因素本身之间的关系是什么?这些因素如何对测试损失产生贡献?它们的贡献是否相等?还是说其中一个比其他的更重要?
因素间的相互作用
对于模型中的每个参数和每个训练示例,大约需要6次浮点运算。因此,这三个因素之间的关系如下:

每个参数和每个训练实例需要大约6次浮点运算(FLOPs)的原因如下:
考虑在训练中的一个参数w:
- 在前向传播中,需要恰好2次FLOPs将w与输入节点相乘,并将其添加到语言模型的计算图的输出节点中。(1次乘法和1次加法)
- 在计算损失对w的梯度时,需要恰好2次FLOPs。
- 在用损失的梯度更新参数w时,需要恰好2次FLOPs。
以α ≈ 6为基础,如果我们知道模型的大小和使用的训练数据量,就可以估计训练语言模型的计算需求。
那么我们就可以回答这个问题:模型大小和训练数据这两个因素是如何对模型性能产生贡献的?
Chinchilla:改变游戏规则的研究
Chinchilla[1]是DeepMind在2022年发布的一篇论文。作者发现,由于专注于在保持训练数据不变的情况下扩大模型大小,当前的大型语言模型实际上训练不足!作者训练了从7000万到超过160亿参数的400多个语言模型,这些模型使用的训练令牌从50亿到5000亿不等,并得出结论,对于计算优化的训练,模型大小和训练令牌数量应该同等规模化。
他们提出了以下经验预测公式,将模型大小和训练数据与模型性能联系起来。
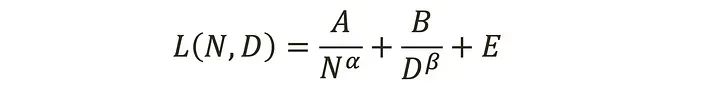
N 是参数数量(即模型大小),D 是训练令牌。符号 L(N,D) 指的是一个拥有 N 个参数并且在 D 个令牌上训练的模型的性能或测试损失。E 是一个常数,代表不可约减的损失,即模型在完美训练的情况下能够达到的最小损失。它考虑了模型所训练的任务的固有难度和数据中的噪声。
常数 A 和 B 以及指数 α 和 β 通过实验和数据拟合经验性地确定。具体来说,他们发现 α≈0.50 和 β≈0.50。这加强了论文的主要发现,即每翻倍增加模型大小时,训练令牌的数量也应该翻倍,以实现计算最优训练[1]。
边际效益递减
在大语言模型中,边际效益递减是指随着模型规模的增大,每增加相同数量的参数或计算资源,获得的性能提升逐渐减少的现象。这是Scaling Law中非常关键的一个方面,它对于理解和决策模型设计及其部署策略有着重要的指导意义。
1、主要原因和表现
- 对数关系:在很多研究中观察到,模型性能(如测试集上的准确率或其他指标)与模型大小(通常是参数数量或计算复杂度)呈对数关系。这意味着随着模型规模的扩大,要获得同样幅度的性能提升,需要的资源增加将更为显著。
- 资源效率的降低:当模型规模达到一定阶段后,继续增加模型的大小,其性能提升不再明显,而相对应的训练成本、时间和能源消耗却显著增加。这种现象表明,从成本效益角度出发,模型规模的无限扩大并非总是合理的。
- 技术挑战:较大的模型更难训练,可能会面临梯度消失或爆炸、过拟合等问题,这些技术挑战也限制了模型性能的持续提升。
2、应对策略
- 模型和算法创新:通过改进模型架构、优化算法或引入新的训练技术(如稀疏化、量化等),可以在不显著增加参数的情况下提高模型的效率和效果。
- 多任务学习和迁移学习:利用多任务学习和迁移学习技术可以提高模型的泛化能力,使得模型在多个任务上具有更好的性能,这种方式可以在一定程度上克服单一任务上的边际效益递减问题。
- 选择适当的规模:根据应用场景的实际需求和可用资源,选择合适的模型规模,避免资源的浪费,实现性能与成本的最优平衡。
总结
语言模型的规模化法则为这些强大的人工智能系统的发展和优化提供了关键洞察。正如我们所探讨的,模型大小、训练数据和计算资源之间的关系遵循可预测的幂律模式。这些法则对人工智能研究者和工程师具有重大意义:
- 平衡规模化:Chinchilla 的发现强调了同时对模型大小和训练数据进行等比例规模化以达到最佳性能的重要性。这挑战了之前仅增加模型大小的重点。
- 资源分配:理解这些关系可以更有效地分配计算资源,可能导致更具成本效益和环境可持续的人工智能发展。
- 性能预测:这些法则使研究人员能够根据可用资源做出有根据的模型性能预测,帮助设定现实的目标和期望。
随着人工智能领域的快速发展,牢记这些规模化法则对于做出有关模型发展、资源分配和研究方向的明智决策至关重要。通过理解和利用这些关系,我们可以朝着创建更高效、更强大、更负责任的语言模型的未来努力。
参考文献:
https://avoid.overfit.cn/post/9867397a40334064b0bbd470e588c4c2
作者:Mina Ghashami