1. 主从结构引入
在分布式系统中,涉及到一个严重问题:单点问题
即如果某个服务器程序只有一个节点(单台机器提供服务),就会出现以下两个问题:
- 可用性问题,如果这台机器挂了,意味着服务中断
- 并发性能问题,单台机器承受的并发量是有上限的
引入分布式系统,也就是为了能解决上述的单点问题,因此往往在redis中会部署多台redis服务器构建redis集群,此时就可以通过这个集群提供更高性能/更稳定的服务,主要的部署结构有以下几种:
- 主从模式
- 主从+哨兵模式
- 集群模式
主从模式:
在若干个redis节点中,有的是"主节点",有的是"从节点",假设有三台物理服务器,分别部署了一个redis-server进程,此时就可以把其中一个节点作为"主节点",另外两个节点作为"从节点",此时引入从节点后主节点上保存的数据就需要同步给从节点,后续主节点进行的数据修改也要同步给从节点
💡 注意:在redis主从模式中,不允许从节点修改数据!
配置主从模式后,就可以实现 “读写分离” ,即通过主节点来处理写操作,从节点处理读操作,这样的结构就可以完美的解决上述出现的"单点问题":
- 在可用性方面:如果有一个从节点挂了,那么问题不大,可以继续从其他从节点上读取数据,但是如果挂的是主节点,在当前结构来看还是有一定影响的,但是也可以通过哨兵机制来解决(此处先不介绍),总之相比于单点服务器程序提升了可用性
- 在性能方面:实际业务场景读操作频率 >> 写操作频率,因此配置一主多从节点,每个从节点都能分摊请求压力,引入了更多的硬件资源,因此性能也就提高了
2. 主从结构搭建
当前为了简化部署流程,我们使用单台物理服务器,启动多个redis-server进程来模拟多个物理服务器
💡 提示:此处需要保证redis-server进程启动的端口号各不相同!可以在启动时用选项配置或者在配置文件中进行配置
我们需要保存三份redis.conf配置,设置daemonize为yes以后台方式启动,port必须不同
# 绑定ip
bind=0.0.0.0
# 启动端口号
port=6379
# 关闭保护模式
protect-mode=no
# 以后台方式运行
daemonize=yes

但是当前几个redis服务还是各自为政的,我们还需要进一步通过以下方式配置成主从结构:
- 方式一:在配置文件中配置
slaveof [masterIP] [masterPort] - 方式二:在redis-server启动命令后使用
--slaveof [masterIP] [masterPort] - 方式三:在redis客户端中使用
slaveof [masterIP] [masterPort]
此处我们希望能够使配置永久生效,因此选择在配置文件中修改,比如此处将6379端口进程作为主节点,6380和6181端口进程作为从节点,因此需要在从节点的配置文件中配置slaveof [127.0.0.1] [6379]并重启redis服务!
💡 注意:此处如果是使用redis-server方式启动进程,需要搭配kill -9杀死进程,但是如果是使用service redis-server start方式启动,使用kill -9杀死后仍会自动重启,此时必须要搭配service redis-server stop停止

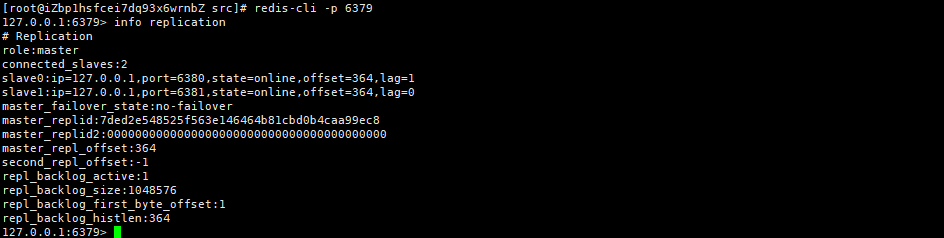
此时下面几个进程就是redis主节点和从节点之间建立的TCP连接,后续同步机制就是通过这些TCP连接进行通信的,我们可以尝试登陆主节点使用info replication查看主从配置信息:
3. 主从复制过程
3.1 replid和offset字段含义
redis提供了psync命令用于完成数据同步(psync命令不需要手动执行,redis服务器会在建立好主从关系后,自动执行psync命令),比如从节点就会执行psync replicationid offset从主节点拉取数据
replicationid:当主节点启动时生成 / 从节点晋升成为主节点的时候生成(注意:就算是同一个主节点,每次启动生成的replicationid也是不重复的)我们可以通过info replication进行查看:

💡 注意:此处replid2在一般情况下是用不到的,但是可能存在以下场景:比如主节点A与从节点B之间配置主从关系,但是由于网络抖动导致B节点认为A主节点挂了,此时B自动晋升为主节点,给自己生成一个replid,同时还会记录之前的主节点信息保存在replid2上,后续如果主节点A恢复就可以手动配置恢复
offset:偏移量,用来记录从节点和主节点之间的数据同步进度,此处主节点和从节点都需要维护双方的偏移量,主节点会收到很多的修改命令,每一个命令都占据相应字节数,主节点就会把这些命令字节数累加作为偏移量,而从节点的偏移量就描述了从节点当前的同步进度,同时从节点每秒都需要上报给主节点当前的复制偏移量
此时replicationid和offset就构成了一组"数据集合",如果说某两台机器上的replid和offset都相同那就说明两者的数据是完全一致的!
3.2 主从数据复制
在redis中使用psync replicationid offset进行数据同步,但是数据同步有两种方式:1、全量同步,2、增量同步主要就是根据offset这个字段值进行区分:
- 如果是全量复制,就将offset值置为-1
- 如果offset值为正整数,则从当前偏移量开始进行部分复制
3.2.1 全量复制过程
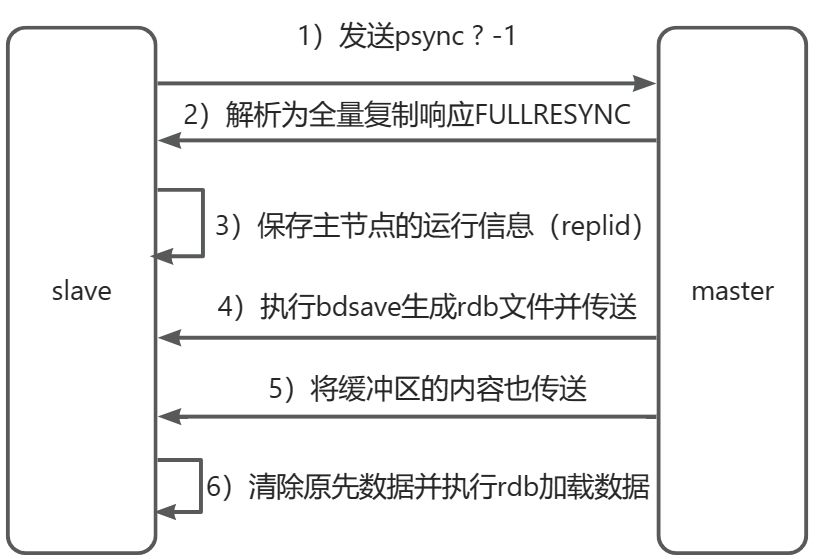
- 从节点发送
psync命令给主节点进行数据同步,由于是第一次通信不知道主节点replid因此发送psync ? -1 - 主节点根据命令判定为全量同步,返回
FULLRESYNC响应 - 从节点将主节点的replid进行保存
- 主节点使用
bgsave命令生成rdb持久化文件,同时在这期间接收到的修改命令保存到缓冲区 - 主节点生成完毕rdb文件后发送给从节点
- 发送完rdb文件后将缓冲区中的数据也以rdb文件格式追加写入,保证主从一致
- 从节点清空自身数据信息
- 重放rdb文件中的内容复制数据
- 如果还开启了AOF持久化功能,则会执行
bgrewriteaof重写,得到最近的AOF文件
🍬 提示:主节点进行全量复制的过程也支持无硬盘模式(diskless),即主节点生成rdb文件的过程可以不保存在硬盘上,而是直接将数据进行网络传输(省去了多次硬盘IO操作)同理从节点加载数据也可以直接进行加载,但是网络传输的开销仍然很大,因此全量复制的开销也是比较大的!
runid和replicationid的区别:
在一个redis服务器上会出现replid和runid两个概念,但是这两个是不一样的,我们可以通过info replication查看replid,可以通过info server查看runid:
-
slave1:


-
slave2:


他们之间的区别概括如下:
- 在应用场景上:replid主要作用于主从复制的场景,runid则主要作用于哨兵模式中
- 在产生方式上:replid是在主从结构中由主节点启动的时候分配的(主从结构中replid相同),而runid则是每一个节点启动后系统分配的(每个节点均不同)
3.2.2 部分复制过程
在全量复制过程中,开销是比较大的,有些情况下从节点已经复制了主节点上的大部分数据,此时就需要"部分复制"了:比如说出现了网络抖动,此时主节点上最新的修改内容就无法及时同步给从节点,当从节点恢复之后就需要重新建立连接并进行部分同步
部分复制:

- 当出现网络抖动时,主从节点之间超过
repl-timeout时间,主节点就会认为从节点故障并中断连接 - 在这期间主节点依旧响应客户端命令,暂时将这些内容写入复制积压缓冲区(repl-backlog-buffer)中
- 当从节点恢复后就会重新建立与主节点之间的连接
- 从节点将之前保存的
replicationid和offset作为psync参数发送给主节点,请求部分复制 - 主节点接收到psync请求后解析出部分复制,就会尝试在复制积压缓冲区查找合适数据,并响应continue给从节点
- 主节点将同步的数据发送给从节点,保证数据一致性
repl-backlog-buffer:
就是内存中类似于一个环形队列这样的数据结构,会保存最近的一些修改操作,但是总量毕竟还是有上限的,随着时间推移,会逐步删除最早的一些数据

当主节点接收到从节点的psync replid offset的时候就会先根据offset的值去repl-backlog-buffer查找有无这部分数据,如果有就会从该偏移量开始将后续的数据返回给从节点,如果没有那就只能进行全量复制了
3.2.3 实时复制过程
实时复制:描述的是主从已经完成数据同步之后,主节点这边不断地接收到数据修改操作,就需要实时同步给从节点
从节点和主节点之间会建立TCP的长连接,然后主节点就可以将自己收到的修改数据的请求发送给从节点,从节点再根据这些请求修改内存中的数据,同时为了实时复制能够处于可用状态,还需要借助 心跳包 机制:
主节点:默认每隔10s给从节点发送一个ping命令,从节点收到返回poing
从节点:默认每隔1s给主节点发送特定的请求,就会上报当前的节点同步数据的进度(offset)
4. 主从故障处理
当前配置的主从结构还需要考虑故障处理的问题:
- 如果挂了的是从节点,那问题不大
- 如果挂了的是主节点,此时就需要进行处理
当前主从断开连接有两种情况:
- 从节点和主节点之间断开连接:比如执行
slaveof no one命令,这个时候从节点就会晋升成为主节点 - 主节点挂了:此时不会自动将从节点晋升成为主节点,于是引入了哨兵机制的概念(下次讲)