前言:Elasticsearch 也是使用 Java 编写的,它的内部使用 Lucene 做索引与搜索,支持结构化文档数据的分布式存储,并提供准实时的查询,全文检索,数据聚合;
1 为什么要使用ES:
ES 本身存在哪些特性使得我们放弃传统关系型数据库,ES的特点:
(1)ES支持PB级别(100万G) 数据的查询,并且检索效率很高;
(2)提供按照文档的相关性评分的全文检索;
(3)支持分布式文档的存储,动态伸缩容;
(4)API形式进行交互使用简单,使用json进行数据扁平化存储;
(5)提供多种方式的数据聚合;
2 了解一些概念:
在学习ES 之前我们需要了解一些概念以便更好的使用
2.1 ES 中的索引:
类比mysql ; 一个索引等价于 一个库;一个 索引 应该是因共同的特性被分组到一起的文档集合。 例如,你可能存储所有的产品在索引 products 中,而存储所有销售的交易到索引 sales 中。 虽然也允许存储不相关的数据到一个索引中,但这通常看作是一个反模式的做法,一个索引名,这个名字必须小写,不能以下划线开头,不能包含逗号。我们用 website 作为索引名举例。
2.2 索引的类型(新版本已经去除了类型):
类比mysql ; 一个类型等价于一个具体的表;数据可能在索引中只是松散的组合在一起,但是通常明确定义一些数据中的子分区是很有用的。 例如,所有的产品都放在一个索引中,但是你有许多不同的产品类别,比如 “electronics” 、 “kitchen” 和 “lawn-care”。一个 _type 命名可以是大写或者小写,但是不能以下划线或者句号开头,不应该包含逗号, 并且长度限制为256个字符. 我们使用 blog 作为类型名举例。
2.3 索引中存储的文档原数据:
一个个文档以JSON 扁平化的结果存入到ES中,当存入了一个文档如何知道该文档的位置;
_index :文档在哪个索引存放
_type:文档在索引下的哪个类型
_id:文档在索引中的唯一标识,类似与Mysql 中表的唯一主键id;
3 ES 中数据类型:
类似与Mysql 表中的每个字段都对应一个数据类型,那么在ES 中是否也有数据类型,如果存在它都支持哪些类型;ex:存储一个日期字符串 “2023-01-01” ,ES 需要知道它是一个日期而不仅仅是个字符串,显然ES中是有数据类型的:
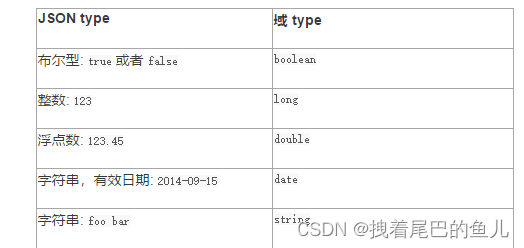
3.1 Elasticsearch 支持如下简单域类型:
- 字符串: string
- 整数 : byte, short, integer, long
- 浮点数: float, double
- 布尔型: boolean
- 日期: date
当你索引一个包含新域的文档—之前未曾出现-- Elasticsearch 会使用 动态映射 ,通过JSON中基本数据类型,尝试猜测域类型,使用如下规则:
注意:
(1)对于字符串类型的数据: string 类型域会被认为包含全文,默认会被分析(默认进行分词)。就是说,它们的值在索引前,会通过一个分析器,针对于这个域的查询在搜索前也会经过一个分析器,搜索的关键词可以被拆分成不同的此条,从而可以用于文档相关度的查询。
(2)其他简单类型(例如 long , double , date 等)不会被分析,对于改类型字段的查询,只会用于精确查询;
(3)虽然ES 可以在存入文档时尝试猜测数据类型,但是我们最好在创建索引时就手动为其设置,避免因为数据类型造成数据无法存入问题;
创建索引时手动设置类型:
PUT /my_index0
{
"mappings": {
"properties": {
"age": {
"type": "integer"
},
"birstTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"email": {
"type": "keyword"
},
"sex": {
"type": "keyword"
},
"iqscore": {
"type": "float"
},
"idCardNumber": {
"type": "keyword"
}
}
}
}
3.2 复杂核心域类型:
除了我们提到的简单标量数据类型, JSON 还有 null 值,数组,和对象,这些 Elasticsearch 都是支持的;
3.2.1 多值域:
很有可能,ES中的字段并不是只有一个值,如我们希望 tag 域包含多个标签。我们可以以数组的形式索引标签:
{ "tag": [ "search", "nosql" ]}
注意:数组是以多值域 索引的—可以搜索,但是无序的。 在搜索的时候,你不能指定 “第一个” 或者 “最后一个”。 更确切的说,把数组想象成 装在袋子里的值 。
3.2.2 空域:
当然,数组可以为空。这相当于存在零值。 事实上,在 Lucene 中是不能存储 null 值的,所以我们认为存在 null 值的域为空域。
下面三种域被认为是空的,它们将不会被索引:
"null_value": null,
"empty_array": [],
"array_with_null_value": [ null ]
3.2.3 地理坐标点:
地理坐标点 是指地球表面可以用经纬度描述的一个点。 地理坐标点可以用来计算两个坐标间的距离,还可以判断一个坐标是否在一个区域中,或在聚合中。
地理坐标点不能被动态映射(dynamic mapping)自动检测,而是需要显式声明对应字段类型为 geo-point :
PUT /attractions
{
"mappings": {
"restaurant": {
"properties": {
"name": {
"type": "string"
},
"location": {
"type": "geo_point"
}
}
}
}
}
如上例,location 字段被声明为 geo_point 后,我们就可以索引包含了经纬度信息的文档了。经纬度信息的形式可以是字符串、数组或者对象:
PUT /attractions/restaurant/1
{
"name": "Chipotle Mexican Grill",
"location": "40.715, -74.011"
}
PUT /attractions/restaurant/2
{
"name": "Pala Pizza",
"location": {
"lat": 40.722,
"lon": -73.989
}
}
PUT /attractions/restaurant/3
{
"name": "Mini Munchies Pizza",
"location": [ -73.983, 40.719 ]
}
注意:地理坐标点用字符串形式表示时是纬度在前,经度在后( “latitude,longitude” ),而数组形式表示时是经度在前,纬度在后( [longitude,latitude] )—顺序刚好相反。
3.2.3 对象类型存储:
(1) 普通对象:类型object
{
"gb": {
"tweet": {
"properties": {
"tweet": { "type": "string" },
"user": {
"type": "object",
"properties": {
"id": { "type": "string" },
"gender": { "type": "string" },
"age": { "type": "long" },
"name": {
"type": "object",
"properties": {
"full": { "type": "string" },
"first": { "type": "string" },
"last": { "type": "string" }
}
}
}
}
}
}
}
}
内部对象 经常用于嵌入一个实体或对象到其它对象中,对象的嵌套关系会丢失:

因为扁平化的存储导致数据关系丢失:
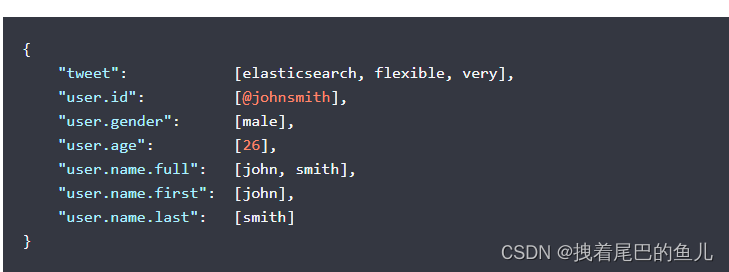
(2) 嵌套对象nested :
为了解决对象属性被拆分进行扁平化存储造成的关系丢失,ES需要提供一个新的数据类型来处理;
将字段类型设置为 nested 而不是 object 后,每一个嵌套对象都会被索引为一个 隐藏的独立文档;
在独立索引每一个嵌套对象后,对象中每个字段的相关性得以保留。我们查询时,也仅仅返回那些真正符合条件的文档。
不仅如此,由于嵌套文档直接存储在文档内部,查询时嵌套文档和根文档联合成本很低,速度和单独存储几乎一样。
嵌套文档是隐藏存储的,我们不能直接获取。如果要增删改一个嵌套对象,我们必须把整个文档重新索引才可以。值得注意的是,查询的时候返回的是整个文档,而不是嵌套文档本身;
"idCard": {
"type": "nested",
"properties": {
"idCardNumber": {
"type": "keyword"
},
"idCardName": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
},
"analyzer": "standard"
},
"idCardUrl": {
"type": "keyword"
},
"iStatus": {
"type": "integer"
}
}
}
(3)父子关系文档:
对于内嵌对象来说,我们不能单独修改对象属性,必须要重新存入改文档;并且查询返回的是一个文档的全部,而不是单独的嵌套对象;ES 使用父子级关系来处理这个问题,使得在父-子关系文档中,父对象和子对象都是完全独立的文档,可以单独的修改和删除,并且只检索对应的子文档。
“type”: “branch” :标记employee 文档 是 branch 文档的子文档。
PUT /company
{
"mappings": {
"branch": {},
"employee": {
"_parent": {
"type": "branch"
}
}
}
}
注意:
多代文档的联合查询(查看 祖辈与孙辈关系)虽然看起来很吸引人,但必须考虑如下的代价:
- 联合越多,性能越差。每一代的父文档都要将其字符串类型的 _id 字段存储在内存中,这会占用大量内存。
- 当你考虑父子关系是否适合你现有关系模型时,请考虑下面这些建议:
尽量少地使用父子关系,仅在子文档远多于父文档时使用。
避免在一个查询中使用多个父子联合语句。
在 has_child 查询中使用 filter 上下文,或者设置 score_mode 为 none 来避免计算文档得分。
保证父 IDs 尽量短,以便在 doc values 中更好地压缩,被临时载入时占用更少的内存。
最重要的是: 先考虑下我们之前讨论过的其他方式来达到父子关系的效果。
参考:
ES权威指南







![[引擎开发] 现代图形API - metal篇](https://img-blog.csdnimg.cn/c19d958db1554003a3d8d33cfbf57956.png)


