代码随想录算法训练营
Day25代码随想录算法训练营第 25 天 | LeetCode491.递增子序列 LeetCode46.全排列 LeetCode47.全排列ii
目录
- 代码随想录算法训练营
- 前言
- LeetCode491.递增子序列
- LeetCode46.全排列
- LeetCode47.全排列ii
- 一、LeetCode491.递增子序列
- 1.题目链接
- 2.思路
- 3.题解
- 二、LeetCode46.全排列
- 1.题目链接
- 2.思路
- 3.题解
- 三、LeetCode47.全排列 II
- 1.题目链接
- 2.思路
- 3.题解
- 总结
前言
LeetCode491.递增子序列
讲解文档
LeetCode46.全排列
讲解文档
LeetCode47.全排列ii
讲解文档
一、LeetCode491.递增子序列
1.题目链接
LeetCode491.递增子序列
2.思路
(1)这道题和子集很像,都是保存大部分节点,所以保存答案是单层递归的一部分,每层保存一次答案,保存答案以后不进行返回
(注意,如果要写边界条件返回,要写在保存答案的后面,否则达到边界条件的答案无法保存)
(2)这道题和子集也有不同
1)不能预先排序
2)去重的操作不同:由于不能预先排序,所以不能用子集问题的与前一个元素比较的方法判断重复,只能用哈希表记录是否在同一层用过
- 这道题要求不能有重复的组合,所以同一层不能用同样的数字
- 数字范围[-100,100],用数组实现哈希表。我们将数字映射成数组下标:nums[i]+100
- used数组在单层递归中定义,每一层都有自己used数组,所以回溯后不要把used数组变成0
3.题解
class Solution {
public:
vector<vector<int>> res;
vector<int> path;
void func(vector<int>& nums, int start) {
if (path.size() >= 2) {
res.push_back(path);
}
int used[205] = {0};
for (int i = start; i < nums.size(); i++) {
if (path.size() && path.back() > nums[i] || used[nums[i] + 100])
continue;
path.push_back(nums[i]);
used[nums[i] + 100] = 1;
func(nums, i + 1);
path.pop_back();
}
}
vector<vector<int>> findSubsequences(vector<int>& nums) {
func(nums, 0);
return res;
}
};
二、LeetCode46.全排列
1.题目链接
LeetCode46.全排列
2.思路
(1)参数:
为什么不用start:因为start在组合类问题里控制开始遍历的下标,而排列添加元素的顺序不一定是从前向后
(2)边界条件:
path里面包含所有元素时,存答案并返回
(3)单层递归
从头到尾遍历nums
1)如果元素已经在排列里面,跳过
2)used标记为true,加入排列
3)递归
4)回溯,used标记为false
3.题解
class Solution {
public:
vector<vector<int>> res;
vector<int> path;
vector<bool> used;
void func(vector<int>& nums) {
if (path.size() == nums.size()) {
res.push_back(path);
return;
}
for (int i = 0; i < nums.size(); i++) {
if (used[i])
continue;
path.push_back(nums[i]);
used[i] = true;
func(nums);
used[i] = false;
path.pop_back();
}
}
vector<vector<int>> permute(vector<int>& nums) {
for (int i = 0; i < nums.size(); i++) {
used.push_back(false);
}
func(nums);
return res;
}
};
三、LeetCode47.全排列 II
1.题目链接
LeetCode47.全排列 II
2.思路
(1)与前一题区别在nums有重复元素,所以要去重,确保不会有重复的排列(重复的树枝)
(2)去重的两种方法
1)树层去重:避免在同一个树层讨论同一个数字
参考组合ii和子集ii的去重
如果元素和上一个元素相等,并且上一个元素在排列没出现,将在同一层竞争,跳过
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1]==flase)
continue;
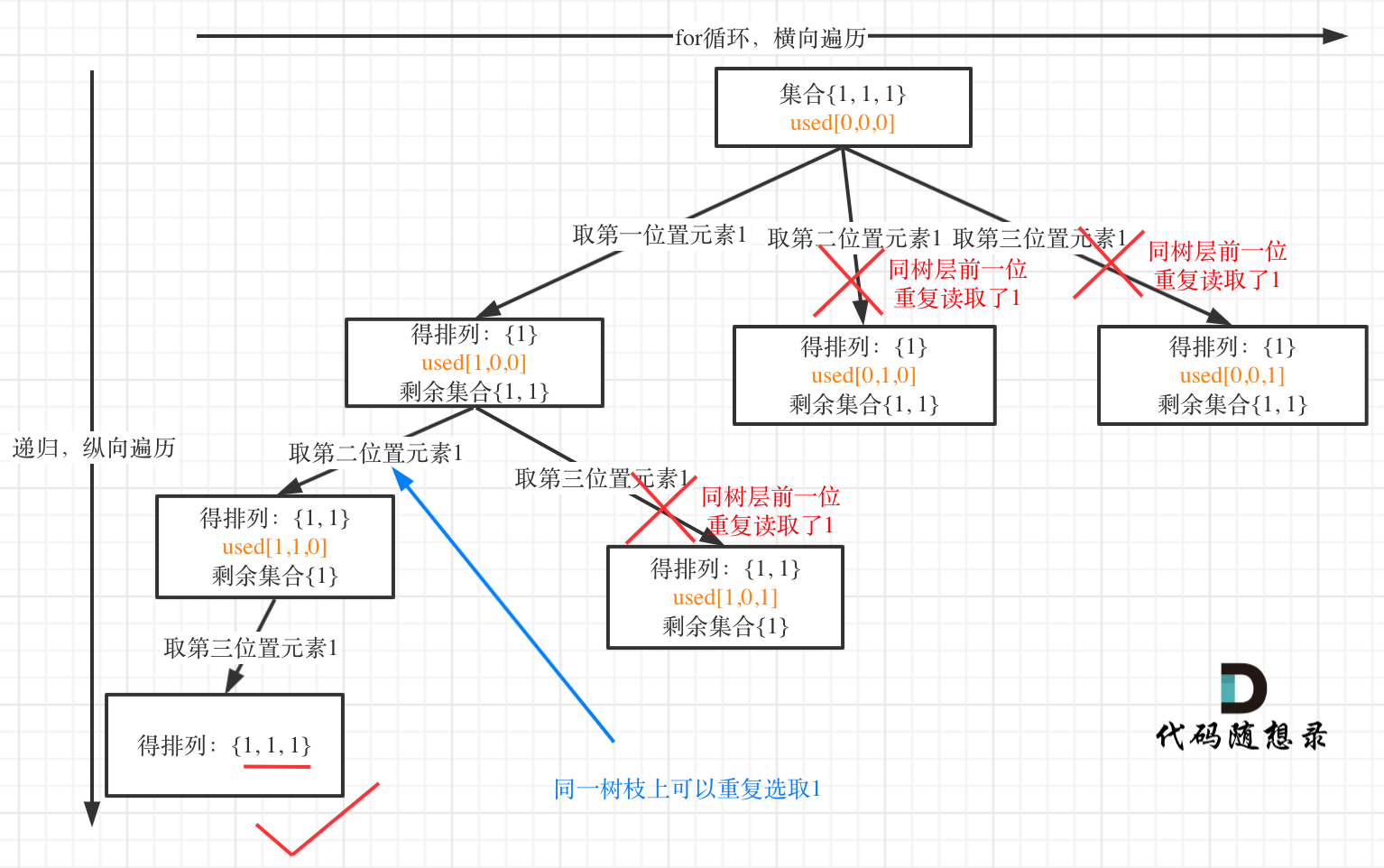
树层去重
2)树枝去重
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1])
continue;

树枝去重示意图
3.题解
树层去重
class Solution {
public:
vector<vector<int>> res;
vector<int> path;
vector<bool> used;
void func(vector<int>& nums) {
if (nums.size() == path.size()) {
res.push_back(path);
return;
}
for (int i = 0; i < nums.size(); i++) {
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false)
continue;
if (used[i])
continue;
used[i] = true;
path.push_back(nums[i]);
func(nums);
path.pop_back();
used[i] = false;
}
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
sort(nums.begin(), nums.end());
for (int i = 0; i < nums.size(); i++) {
used.push_back(false);
}
func(nums);
return res;
}
};
树枝去重
class Solution {
public:
vector<vector<int>> res;
vector<int> path;
vector<bool> used;
void func(vector<int>& nums) {
if (nums.size() == path.size()) {
res.push_back(path);
return;
}
for (int i = 0; i < nums.size(); i++) {
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1])
continue;
if (used[i])
continue;
used[i] = true;
path.push_back(nums[i]);
func(nums);
path.pop_back();
used[i] = false;
}
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
sort(nums.begin(), nums.end());
for (int i = 0; i < nums.size(); i++) {
used.push_back(false);
}
func(nums);
return res;
}
};
总结
-
注意数字去重和元素去重:
元素去重:元素下标=used数组下标
数字去重:数字映射成used数组下标 -
区分分割/组合和子集问题
分割组合:保存叶节点,将保存答案看作边界条件处理的一部分,保存后返回
子集问题:保存所有节点,将保存答案看作单层递归的一部分,保存后不返回
子集问题注意把保存答案写在返回的前面 -
排列和组合在写法上不同
- 排列不需要start,因为每次都从头到尾全部遍历nums
- 排列需要全局定义used数组标记是否在排列里用了
-
去重问题
子集、组合、全排列和子集ii、组合ii、全排列ii的区别是后者的nums有重复元素,然而我们不希望收集到重复的子集、组合、元素 -
如果能预先排序,则先排序,全局定义used数组,用下面的代码判断是否重复
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false)
continue;
- 如果不可以预先排序,则在每次递归定义used数组,如果used 为真,说明本层用过对应的元素了,跳过。回溯的时候不要把used变回false