阿里巴巴最新推出的音频处理模型Qwen2-Audio,不仅能直接用语音聊天,还能像一位专业的听觉大师一样分析各种声音,功能强大得令人难以置信。
Qwen2-Audio可以通过语音聊天和音频分析两种方式与用户互动,用户无需区分这两种模式,模型能够智能识别并在实际使用中无缝切换。


语音聊天,未来式交互体验
在语音聊天模式下,用户可以自由地与模型进行语音互动,而无需文本输入。
你只需开口即可,Qwen2-Audio就能够精准地理解你的语音指令,并提供自然流畅的语音回复,仿佛与真人对话一样轻松自然。

音频分析,化身“声音侦探”
在音频分析模式下,用户可以在互动过程中提供音频和文本指令对音频进行分析。
只需上传一段音频,Qwen2-Audio就能帮你精准地分析音频中的各种声音。不管是识别讲话者的情绪、判断音乐的节奏和类型,还是分辨各种环境声音,都能轻松应对。它甚至能理解混合音频的含义,例如从一段包含警报声、刹车声和引擎声的音频中,推测出可能是交通事故现场。

核心功能,样样精通
Qwen2-Audio在自动语音识别、语音到文本翻译、语音情感识别、声音分类等多个领域都展现出了强大的实力。
-
高精度语音识别:在专业测试中,Qwen2-Audio的识别准确率远超其他模型,能够轻松识别包括中文、英语、以及其他语言。
-
多语言语音翻译:支持多种语言之间的语音翻译,能够实时翻译不同语言的对话,让你与世界无缝交流。
-
精准情感分析:具备强大的情感识别能力,能够准确捕捉并理解语音中的情感色彩,如愤怒、快乐、悲伤等。

技术过硬,实力出众
Qwen2-Audio的模型架构由大语言模型和音频编码器组成:
-
基础组件是Qwen-7B大语言模型
-
音频编码器基于Whisper-large-v3模型
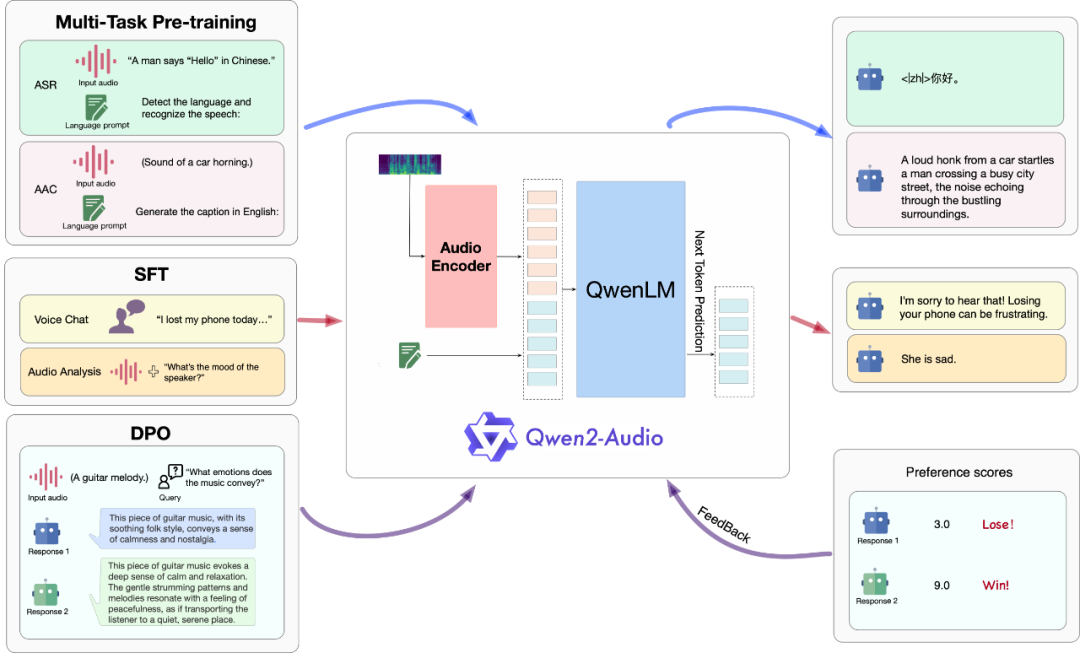
并采用了多任务预训练、监督微调、直接偏好优化等先进技术。在多个测试中表现优异,能够准确识别和翻译语音,并进行情感识别和声音分类等任务,其卓越的性能得到了业界的高度认可。
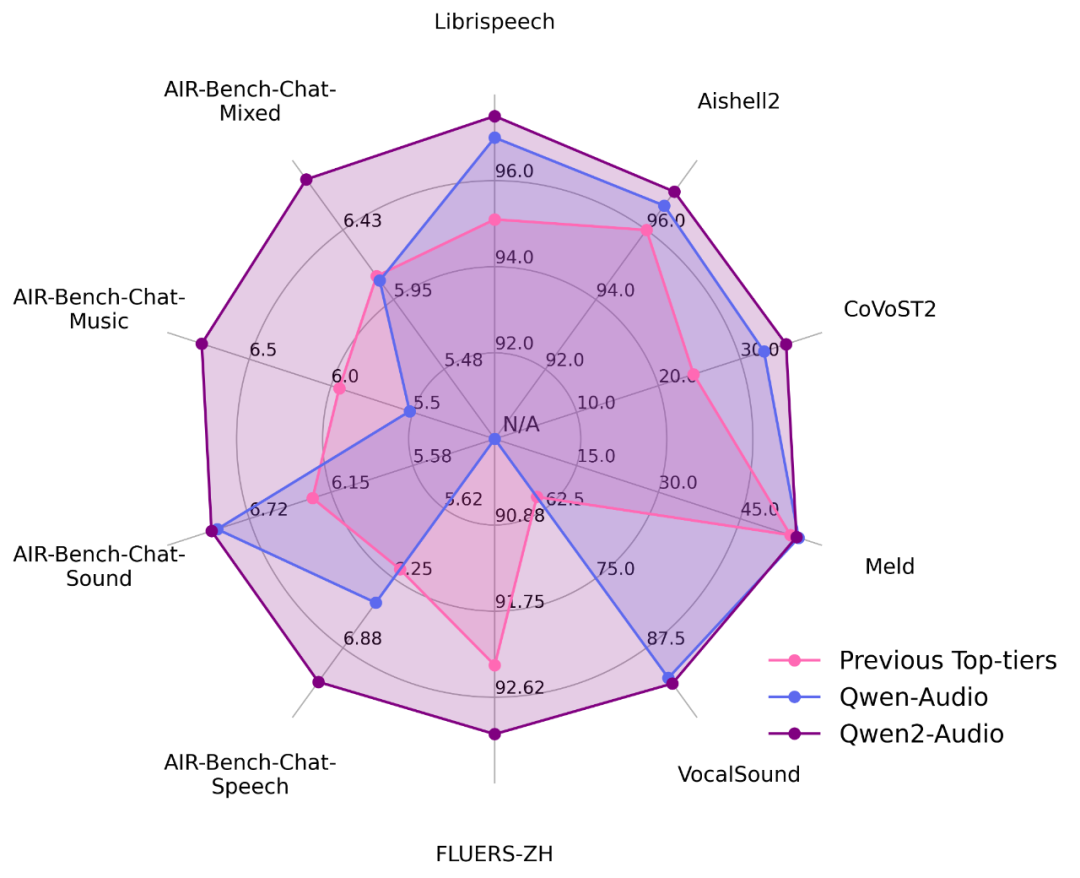
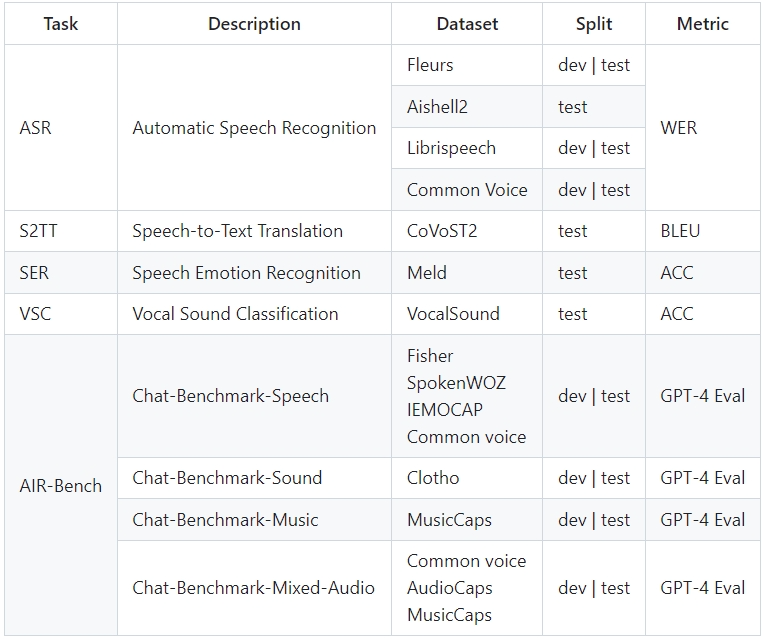
在标准的13个学术数据集上评测了模型的能力如下:
并采用了多任务预训练、监督微调、直接偏好优化等先进技术。在多个测试中表现优异,能够准确识别和翻译语音,并进行情感识别和声音分类等任务,其卓越的性能得到了业界的高度认可。
在标准的13个学术数据集上评测了模型的能力如下: