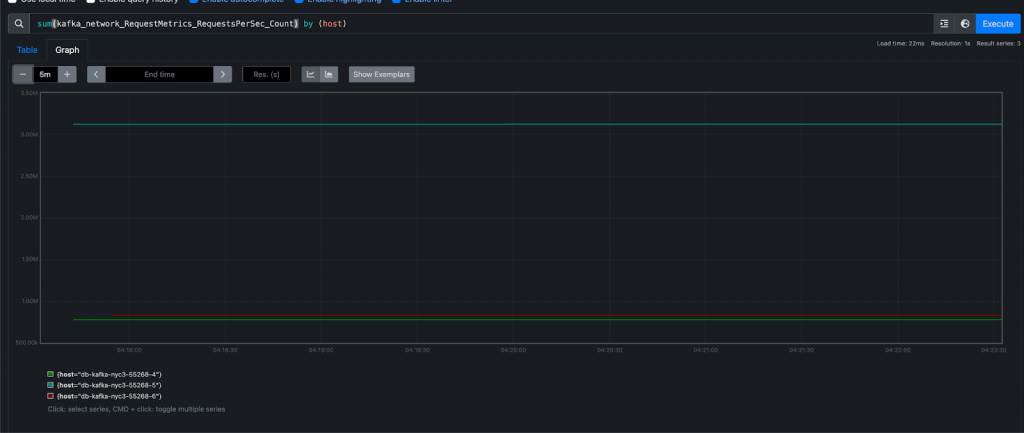
一、块组的宏观理解
1、分区和分组
首先一台电脑就一个磁盘,一般800GB到1TB,为了管理这么大的内存数据,我们就对磁盘进行分区,分区之后才是我们看到的C盘,D盘等。

但是其实分区之后空间还是太大不好管理,我们需要进行分组,这样才能管理好磁盘中文件数据。
这种思想就是分治。
2、理解组块

(1)Data Blocks
数据区,内存占比90%,里面存放的都是4KB大小的数据块。
(2)Block Bitmap
块位图,用比特位0,1来记录数据区的数据块是否被占用。
(3)inode Table
inode表,也是数据块,存放文件属性(大小,所有者,ACM时间,但是没有文件名)。
(4)inode Bitmap
inode位图,用比特位0,1来记录inode表中inode是否被写入。

Linux文件属性是一个大小固定的128字节的集合体
struct inode
{
int size;
mode_t mode;
int datablocks[N]; 记录文件占用的数据块编号,用来LBA寻址
int inode_number; 每一个文件都有一个inode编号用来标识文件
};
指令 ll -li 显示文件inode编号。

(5)GDT Group Descriptor Table
块组描述符,描述Block Group的使用情况,是一个管理字段。
(6)SB Super Block
超级块,存放一个分区的信息,所以超级块不是每一个组块都有,也不是只有一个组块有超级块(便于数据恢复),记录Block , inode的总量,使用情况和大小等,超级块相当于一个文件系统。
(7)格式化
在每一个分区分组,然后写入文件系统的管理数据。
本质:在磁盘中写入文件系统(清空里面的数据,只剩文件系统这个框架)
二、细节问题讨论
1、inode 编号与 datablock
inode编号在分区中是唯一的,在分区中分组就是确定每一个组块的起始inode编号和终止inode编号,拿到一个inode编号先找到对应的分区和组块,然后减去组块的起始inode编号,在bitmap中找到对应的属性和内容。datablock也是如此。
2、datablock[N]
在上文中我们提到,结构体inode中有一个datablock[N]来记录文件占据的数据块编号,在ext2下,N = 15,其中下标0~11是直接指向数据块,大小4KB,后三个下标会进行一级二级寻找数据块(利用一个或多个数据块里面存放指向其他数据块的指针的方法让文件对应的数据块增多)以此来达到扩大存放文件的作用。
3、了解目录和文件的增删查改
目录也是文件,所以目录有文件属性和文件内容,目录的属性好理解,目录的内容存放的是目录里面文件的inode与文件名的映射关系。找文件的顺序:文件名 -> 文件inode
目录的r权限:允许我们读取目录中文件名与文件inode的映射关系。
目录的w权限:创建文件后一定要向目录内容里面写入文件的文件名与文件inode映射关系。而文件的删除就是把文件对应的inode和inode_bitmap清空,但对应数据块不会清空,所以理论上如果误删文件是可以恢复出来的,但是如果误删之后做了其他操作把原来的文件对应数据块内容覆盖那就无法恢复了。
4、如何找到文件
找到文件所在目录 -> 打开目录 -> 根据文件名和inode关系找到inode -> 在inode table 找到文件属性 -> 找到文件占用数据块编号 -> LBA寻址
如何找到文件所在目录?
要根据路径逆向解析,是操作系统做的,一直解析到根目录,由于根目录名称与inode是已知的,再顺着路径依次打开目录最后找到文件。
有时我们写的代码指令是不带路径的,但是在启动进程时自带的cwd会找到当前路径,最后帮我们带上路径,这样我们才能顺利找到目录。
如何确定文件分区?
分区 -> 写入文件系统(格式化) -> 挂载到目录 -> 进入目录就能在指定分区中进行文件操作
所以目录就确定了文件在哪个分区。例如Linux中一般根目录就挂载一个分区,其下的目录文件就在这分区找。




![【2024最新华为OD-C/D卷试题汇总】[支持在线评测] LYA的朋友排队(100分) - 三语言AC题解(Python/Java/Cpp)](https://i-blog.csdnimg.cn/direct/2f1994343e92421abbe221b5000075d6.png)