背景
学习极客实践课程《检索技术核心20讲》https://time.geekbang.org/column/article/215243,文档形式记录笔记。
相关问题:
- ES全文检索是如何进行相关性打分的?
- ES中计算相关性得分的时机?
- 如何加速TopK检索?三种思路
精准TopK检索
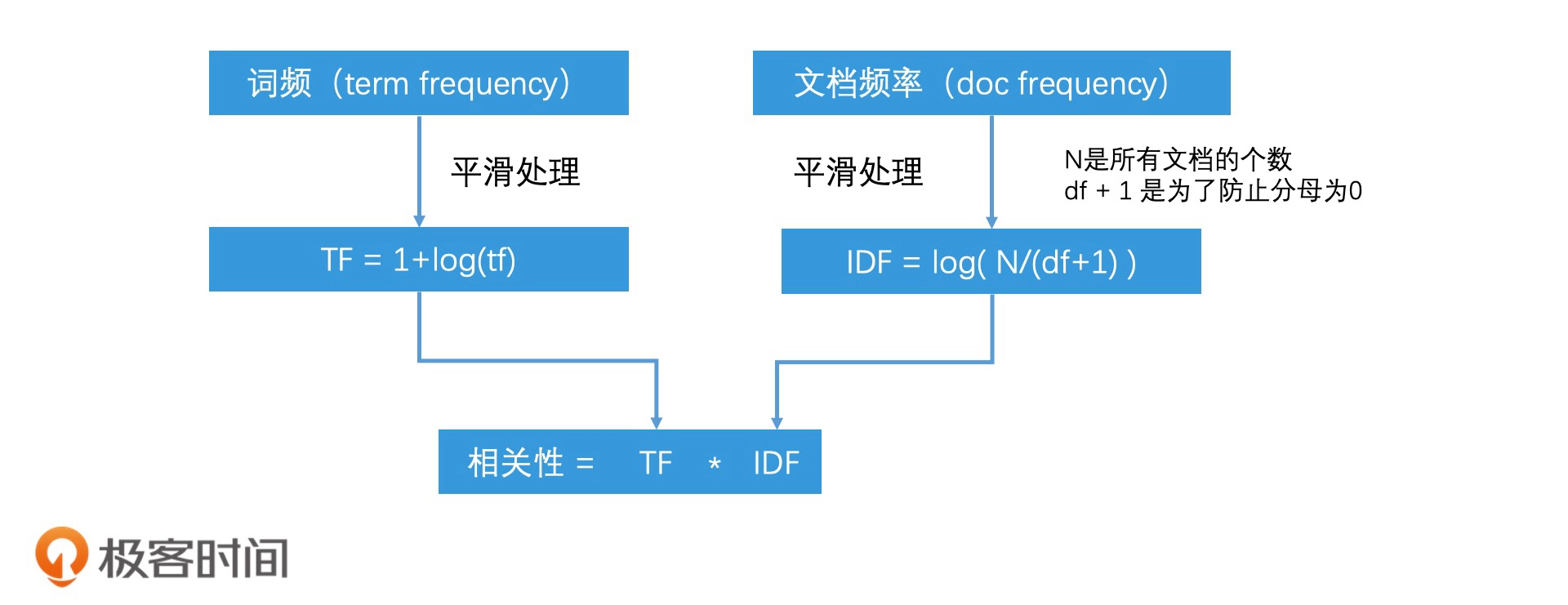
基础TF-IDF算法
TF 是词频(Term Frequency),IDF 是逆文档频率(Inverse Document Frequency)。
核心思想:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
参考:https://zhuanlan.zhihu.com/p/31197209
实际使用会以TF-IDF算法为基础,结合向量模型、概率模型进行相关性打分。
ES中计算相关性得分的时机
思考:如果我搜索"极客 时间 检索 技术", 它会被拆分成4个token, 返回4个 posting list, 然后作多路归并, 得到同时含有4个token 的doc id列表. 4个token在每个doc 里的 TF 都不一样, 每个token的IDF也不一样, 最后怎么影响 搜索结果的排序?
大致思路:tf和idf值其实在索引构建的时候就可以统计好的,在完整的索引里,doc的信息会包含了tf值。然后idf的信息可以存在token里。因此,完整的流程如下:
- 在索引构建时,在建立posting list时,在doc信息中存入tf的值,在token存入idf值。
- 在四个posting list做了归并以后,这时候我们会得到符合检索条件的候选doc列表。在归并的时候,同时累加每个词项的tf*idf的值。就能得到每个doc的打分结果。
- 接下来,对于打好分的文档进行排序。就是最终结果。
概率模型BM25
Best Matching 25算法,可以看作是基础TF-IDF算法的升级概率模型,相比基础的TF-IDF的算法,BM25算法考虑了
- 词频
- 查询词中词项权重:认为词频和相关性的关系并不是线性的,随着词频的增加,相关性会越来越不明显,到达一个阈值之后,即使词频率再增加,相关性也不增加了。公式:

,当tf无限大的时候,值会趋紧一个k1,作为权重,因此给k1最大值可能是1.2、3会影响最终的相关性。 - 文档中词项权重:同样一个词,出现在长度不同的文档,那么认为出现在较短文档中这个词更重要。公式:

,其中b是可调整参数,范围是[0,1]表示文档长度的重要性,当b为0的时候就不考虑词项权重。参数l是当前文档长度,L是整体文档平均长度。l越大,分母就越大,整体结果就会越小。
- 查询词中词项权重:认为词频和相关性的关系并不是线性的,随着词频的增加,相关性会越来越不明显,到达一个阈值之后,即使词频率再增加,相关性也不增加了。公式:
- 词项的逆文档频率:可以采用TF-IDF算法的逆文档频率IDF算法,也可做一些改进,比如基于二值独立模型对它进行退化处理,公式:


公式中 3 个可以人工调整大小的参数,分别是 :k1、k2 和 b,影响最终的相关性。
机器学习逻辑回归模型
考虑更多的相关因子,加入更多参数作为相关性判断的分数。
把不同的打分因子进行加权求和。比如说,有 n 个打分因子,分别为 x1到 xn,而每个因子都有不同的权重,我们记为 w1到 wn,那打分公式就是: Score = w1 * x1 + w2 * x2 + w3 * x3 + …… + wn * xn
而权重w1、w2等等需要机器学习训练数据得出。最后再使用 Sigmoid函数,公式:1 / (1 + e -x) 处理 score 边界到 (0,1)范围
Sigmoid 函数的特点就是:x 值越大,y 值越接近于 1;x 值越小,y 值越接近于 0。并且,x 值在中间一段范围内,相关性的变化最明显,而在两头会发生边际效应递减的现象,这其实也符合我们的日常经验。
除了逻辑回归模型的表现形式就是Sigmoid函数,机器学习还支持向量机模型、梯度下降树等,更复杂的是深度学习算法如DNN和相关的变种。
关于DNN简单理解,DNN有时也叫做多层感知机(Multi-Layer perceptron,MLP)。
https://blog.csdn.net/qq_41665685/article/details/105762611
精准TopK检索结果排序
一般思路如采用全排序快排等算法,快排算法的时间复杂度是O (n log N),数据量大的时候,效率也不会很高。
需要考虑场景,比如搜索引擎一般只显示几页数据,也就是只需要选出TopK即可,不必进行全排,因此可以考虑使用堆排序。
因此我们可以使用堆排序来代替全排序。这样我们就能把排序的时间代价降低到 O(n) + O(k log n)(即建堆时间 + 在堆中选择最大的 k 个值的时间),而不是原来的 O(n log n)。举个例子,如果 k 是 1000,n 是 1000 万,那排序性能就提高了近 6 倍!这是一个非常有效的性能提升。
堆排序
堆排序的时间复杂度:https://www.cnblogs.com/GHzcx/p/9635161.html
使用堆排序的两种做法
- 先对k个元素建立一个堆,时间代价是O(k),接下来遍历n个元素,判断替换堆中哪个元素,判断和处理时间复杂度是 O(log k),过程中堆一致保持k个元素,处理完全部n个元素时间复杂度为 O(n log k)。
- 先对n个元素建立一个堆,时间代价是O(n),接下来我们在这个堆中,进行k次操作,将堆顶的最大值取出。每次取出堆顶元素,调整的时间代价是O(log n)。因此,处理完k个元素,时间代价就是O(k log n)。
当n很大的时候,第二种方法要比第一种方法效率高,会比第一种方法O(n log k)快上接近log k倍。
假设 𝑛 很大,我们可以考虑以下几种情况:
- 如果 𝑘 是常数:
- 𝑂(𝑛log𝑘) 简化为 𝑂(𝑛)(因为 log𝑘 是常数)。
- 𝑂(𝑘log𝑛) 简化为 𝑂(log𝑛)(因为 𝑘 是常数)。
- 在这种情况下,𝑂(𝑛) 比 𝑂(log𝑛) 增长得更快,所以 𝑂(𝑛log𝑘) 更大。
- 如果 𝑘 和 𝑛 是同数量级(例如 𝑘=𝑛):
- 𝑂(𝑛log𝑘) 简化为 𝑂(𝑛log𝑛)。
- 𝑂(𝑘log𝑛) 也简化为 𝑂(𝑛log𝑛)。
- 在这种情况下,两者是相等的。
- 如果 𝑘 比 𝑛 小得多(例如 𝑘=log𝑛):
- 𝑂(𝑛log𝑘) 简化为 𝑂(𝑛loglog𝑛)。
- 𝑂(𝑘log𝑛) 简化为 𝑂(log𝑛log𝑛) 或 𝑂((log𝑛^2))。
- 在这种情况下,𝑂((log𝑛^2)) 比 𝑂(𝑛loglog𝑛) 增长得更慢,所以 𝑂(𝑛log𝑘) 更大。
- 如果 𝑘 比 𝑛 大得多(例如 𝑘=𝑛2):
- 𝑂(𝑛log𝑘) 简化为 𝑂(𝑛log𝑛2 = O𝑛⋅2log𝑛 = O𝑛log𝑛)。
- 𝑂(𝑘log𝑛) 简化为 𝑂(𝑛2log𝑛)。
- 在这种情况下,𝑂(𝑛2log𝑛) 比 𝑂(𝑛log𝑛) 增长得更快,所以 𝑂(𝑘log𝑛) 更大。
综上所述,当 𝑛 很大时,哪一个更大取决于 𝑘 和 𝑛 的相对大小。一般来说:
- 如果 𝑘 是常数或比 𝑛 小得多,𝑂(𝑛log𝑘) 更大。
- 如果 𝑘 和 𝑛 是同数量级,两者相等。
- 如果 𝑘 比 𝑛 大得多,𝑂(𝑘log𝑛) 更大。
面试经典TopK问题
问题:100 GB 的 URL 文件,进程中使用最多 1 GB 内存,计算出现次数 Top 100 的 URL 和各自的出现次数,性能越快越好。
分析:主要考察1.分治处理 2.哈希统计 3.堆 4.内存与磁盘利用
一种思路:
- 顺序读取文件,直接往内存的hash表中放,统计相同的url的个数,当hash表满时(到达内存上限),我再将hash表以key-value形式写入小文件。这样可以生成n个k-v小文件。
- 然后对多个小文件合并,小文件中的key可能会重复,如果每个小文件的key都是有序的,那么可以用归并排序,快速进行key的合并。可以写成合并成一个有序大文件,文件内容是有序的key-value。
- 最后使用堆,读取该文件,保留top 100。
思考:ES分片对相关性计算的影响
一个在使用 Elasticsearch 时需要注意的问题。让我们更详细地探讨一下。
1.对于一个完整的检索系统,检索结果的排序是无法回避的问题,包括在前面的课程中,留言已经有人提问,说如果检索出来的结果很多该怎么办?因此,这一篇文章能补全这个知识点,让我们知道搜索引擎,广告引擎和推荐系统是如何处理检索结果的。
2.索引构建和打分机制其实是有关系的。如果你在使用elastic search,并且使用了基于文档的索引拆分,然后又选择了系统自带的tf-idf或者bm25进行相关性打分,那么如果处理不当,相关性计算会变差。(因为idf没有在全局被更新)。
索引拆分与相关性打分
在 Elasticsearch 中,索引是由一个或多个分片(shard)组成的。每个分片是一个独立的 Lucene 索引。默认情况下,Elasticsearch 使用 BM25 作为相关性打分算法,之前的版本使用的是 TF-IDF。
TF-IDF 和 BM25
● TF-IDF(Term Frequency-Inverse Document Frequency):
○ TF:词频,表示一个词在文档中出现的频率。
○ IDF:逆文档频率,表示一个词在整个文档集合中出现的频率。IDF 的计算依赖于整个索引中的文档数量和包含该词的文档数量。
● BM25:BM25 是 TF-IDF 的一种改进,它引入了词频饱和和文档长度归一化等机制,使得相关性打分更加合理。
分片对 IDF 的影响
当索引被拆分成多个分片时,每个分片独立计算其 IDF 值。这意味着同一个词在不同分片中的 IDF 可能会有所不同,尤其是在文档分布不均匀的情况下。这会导致以下问题:
1. IDF 不一致:由于每个分片独立计算 IDF,导致同一个词在不同分片中的 IDF 值不同,从而影响相关性打分的准确性。
2. 相关性计算变差:如果某个词在某些分片中频繁出现,而在其他分片中很少出现,那么在全局计算相关性时,这种不一致会导致相关性打分变差。
解决方案
1. 全局 IDF:为了避免 IDF 不一致的问题,可以使用全局 IDF。Elasticsearch 提供了一些机制来实现这一点,例如使用 search_type=dfs_query_then_fetch。这种搜索类型会先进行一个分布式频率统计,然后再进行查询,以确保使用全局 IDF。
2. 调整分片策略:合理规划分片策略,确保文档在各个分片中的分布尽可能均匀。这可以通过预估数据量和查询模式来进行规划。
3. 自定义打分机制:如果默认的 BM25 或 TF-IDF 不能满足需求,可以考虑自定义打分机制。Elasticsearch 允许用户通过脚本或插件的方式自定义相关性打分。
实践建议
● 使用 dfs_query_then_fetch:在查询时使用 dfs_query_then_fetch 搜索类型,以确保 IDF 在全局范围内计算。
● 监控和调整分片:定期监控分片的文档分布情况,必要时进行重新分片(reindexing)。
● 测试和优化:在实际应用中,测试不同的打分机制和分片策略,找到最适 ...
https://www.cnblogs.com/novwind/p/15177871.html
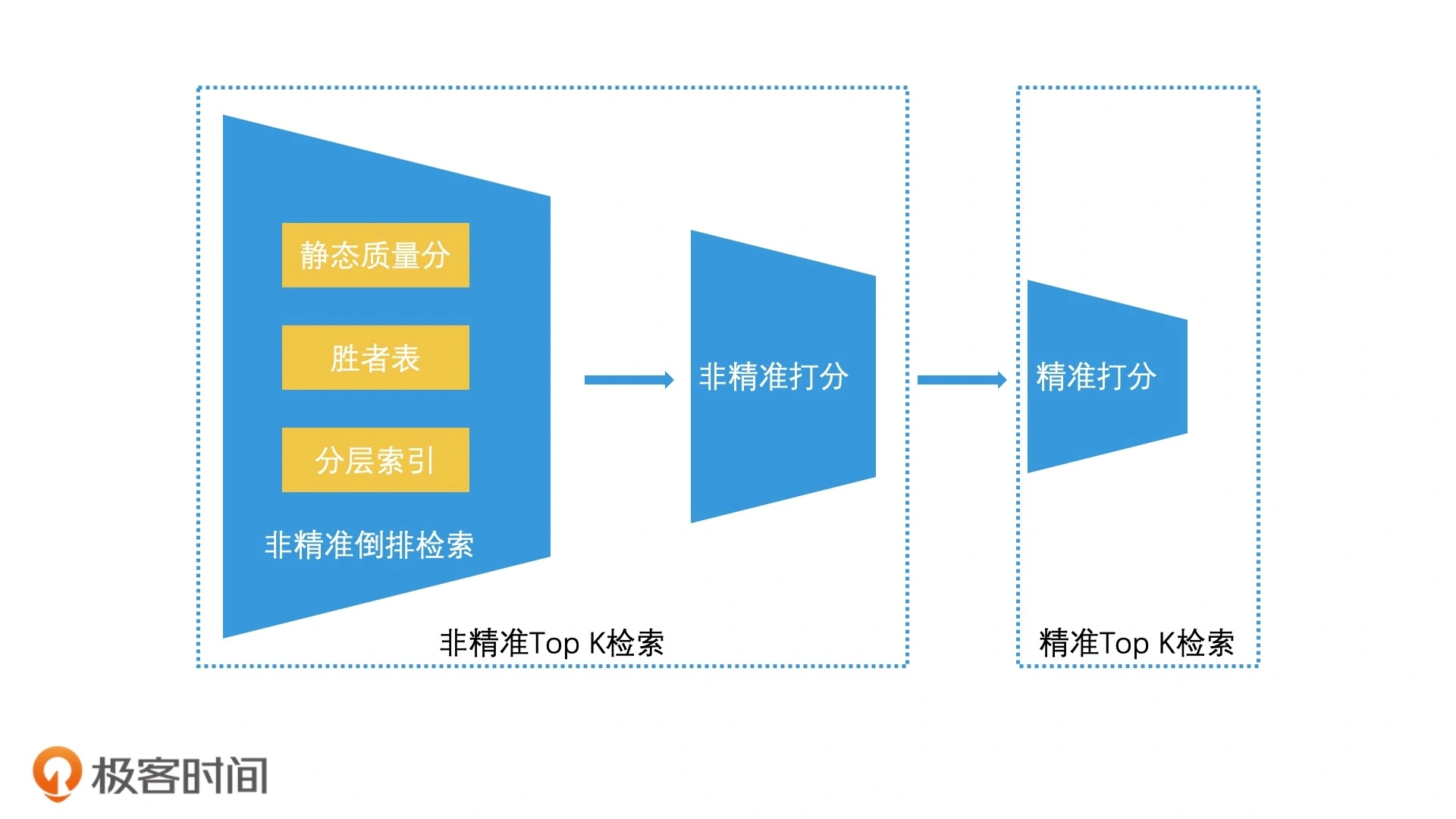
加速检索之非精准TopK检索
高质量的检索结果并不一定要非常精准,只需要保证质量高的结果包含在TopK个结果中就行,也就是并无精准严格要求,这就是非精准TopK检索,分为 召回 + 重排两个阶段,然后再筛选出高质量的TopK数据。
非精准TopK相比精准TopK,可以将计算放到离线环节,可以降低打分复杂度,从而加速TopK检索过程。
下面三种方法的核心思路都是,尽可能地将计算从在线环节转移到离线环节,让我们在在线环节中,也就是在倒排检索的时候,只需要进行少量的判断,就能快速截断 Top K 个结果,从而大幅提升检索引擎的检索效率。
根据静态质量得分排序截断TopK
一个极端的方案就是根据检索结果的静态质量得分进行打分和截断,就可以加速检索过程了。
静态质量得分,指的是不考虑检索结果和实时检索词的相关性,打分只和结果自身的质量有关,这样即使不进行检索也能离线的计算一个结果排序,也就是说,只需要根据离线算好的静态质量得分直接截断,就能起到检索加速了。
以搜索引擎为例,我们可以不考虑搜索词和网页之间复杂的相关性计算,只根据网站自身的质量打分排序。比如说,使用 Page Rank 算法(Google 的核心算法,通过分析网页链接的引用关系来判断网页的质量 )离线计算好每个网站的质量分,当一个搜索词要返回多个网站时,我们只需要根据网站质量分排序,将质量最好的 Top K 个网站返回即可。
另外就是需要改造下posting list,保证静态质量得分高的排在前面,对于分数相同的,再按照ID排序。
- 如果是单关键字检索,这样可以直接取前N个;
- 如果是多关键字检索,可以把多个posting list做归并取交集,留下分数和文档ID都相同的条目,达到k个的时候,结束归并。
根据词频得分排序截断TopK
词频记录了关键字在文档出现的次数,可以代表关键词在文档中的重要性,而且次频的计算是在索引构建的时候完成,按照次频值从大到小将docId存储在posting list中,因此可以考虑根据词频截断posting list。
- 如果是单关键词检索,找出关键词对应的posting list,截取前k个结果就行;
- 如果是多个关键词检索,情况复杂点,如果关键词是A、B。文档1包含2个A,1个B,文档2包含2个B,1个A,那么在关键词A的posting list中,Score(1) = 2,Score(2) = 1。在关键词B的posting list中,Score(1) = 1,Score(2) = 2。此时,就不太好归并截取了,因此需要换一个思路,先根据词频大小选出远多于k的结果集合,然后这个集合按文档ID排序(便于归并),这样就兼顾了相关性和快速归并截断的问题,这种根据某种权重将posting list中元素排序并提前截取r个最优结果的方案,叫做胜者表。
胜者表,既用上词频的分值,又保证ID有序
- 优点:排序方案更加灵活,相比静态质量得分,可以同时结合词频和静态质量得分作为权重筛选结果。
- 缺点:提前截断是有风险的,特别是多关键字检索的时候容易丢失结果,它可能造成归并后的结果不满k个,比如说文档1同时包含关键词A和B,但是它既不在关键词A的前r个结果,也不在关键词B的前r个结果中,那它就不会被选出来,另外有一个极端情况就是关键词A的前r个结果都是仅包含A的文档,而关键词B的前r个结果都是仅包含B的文档,那么归并的结果就是空的。
使用分层索引
解决胜者表可能丢失数据的问题,采用索引拆分的思想,将数据拆分为高质量索引、低质量索引。
分层索引思路:我们可以同时考虑相关性和结果质量,用离线计算的方式先给所有文档完成打分,然后将得分最高的 m 个文档作为高分文档,单独建立一个高质量索引,其他的文档则作为低质量索引。高质量索引和低质量索引的 posting list 都可以根据静态质量得分来排序
思考:分层索引是如何区分高质量、低质量索引呢?
分层索引不是根据词频类似的打分方式来对文档进行分层,它更多的还是根据静态质量分来区分。
比如说,来自门户网站的文章会被打上更高的质量分,而个人站点的类似文章会被打上较低的质量分。它们分别被划分到了高质量文档集合a,以及普通文档集合b中。
我们在建立倒排索引时,会针对a建立一个倒排索引,针对b建立一个倒排索引。
在检索时,先检索a索引,得到x个文档。如果不满足k个结果,那么再去索引b中,以“极客”和“时间”为key,单独在索引b中找到符合条件的y个文档,然后将x个文档和y个文档合并,再取top k。
那为什么不是在索引a中用“极客”检索posting list,再在索引b中用“时间”检索出posting list然后合并呢?因为这两个posting list的文档集合是空。(索引a和索引b中的文档是无交集的)。
此外,我们还能将非精准 Top K 检索拓展到线上环节,通过引入“非精准打分”的环节,来进一步减少参与“精准打分”的检索结果数量。

![[数据集][目标检测]蝗虫检测数据集VOC+YOLO格式1501张1类别](https://i-blog.csdnimg.cn/direct/b200dcef74704c1eaffb8201d0bd1007.png)