在
ArrayList任意位置插入或者删除元素时,就需要将后序元素整体往前或者往后搬移,时间复杂度为O(n),效率比较低,因此ArrayList不适合做任意位置插入和删除比较多的场景。因此:java 集合中又引入了LinkedList,即链表结构。
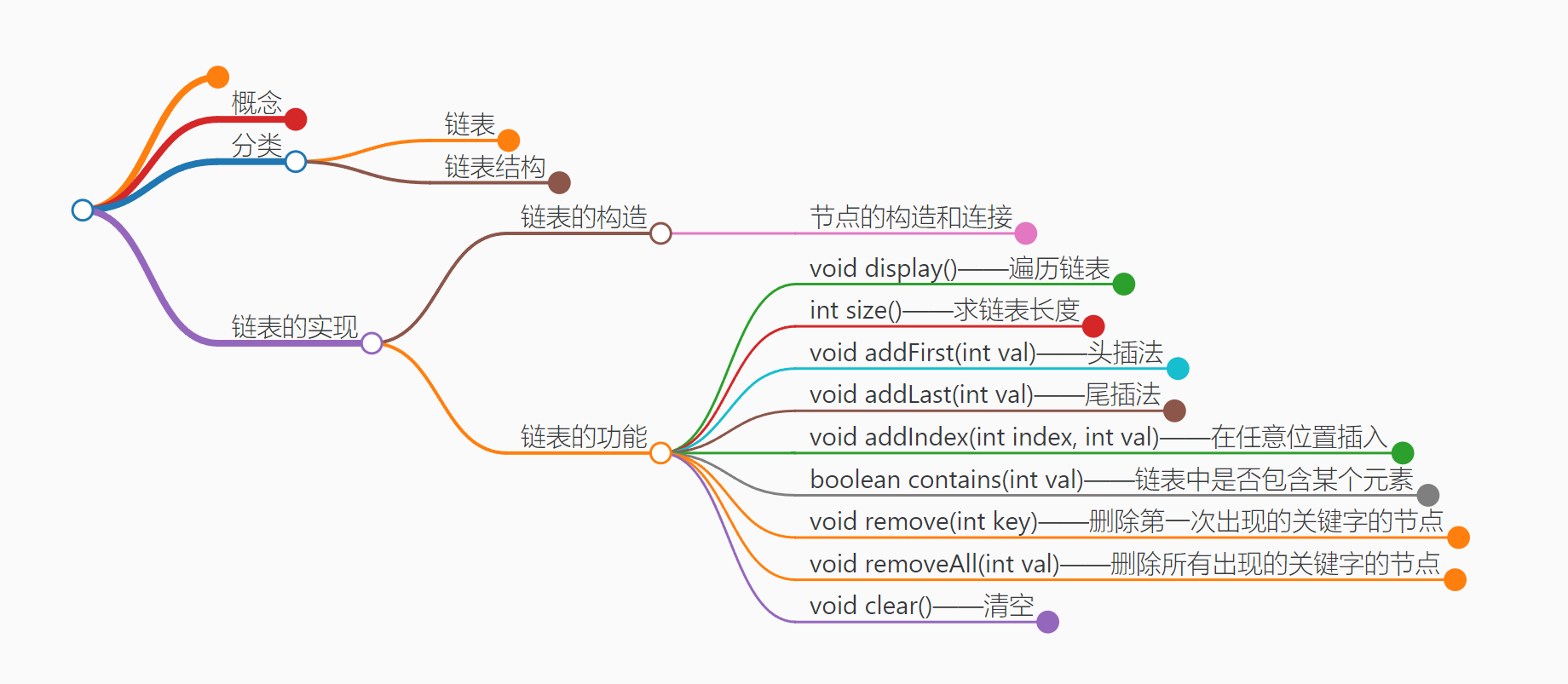
概念
顺序表是物理上连续,逻辑上也是连续的
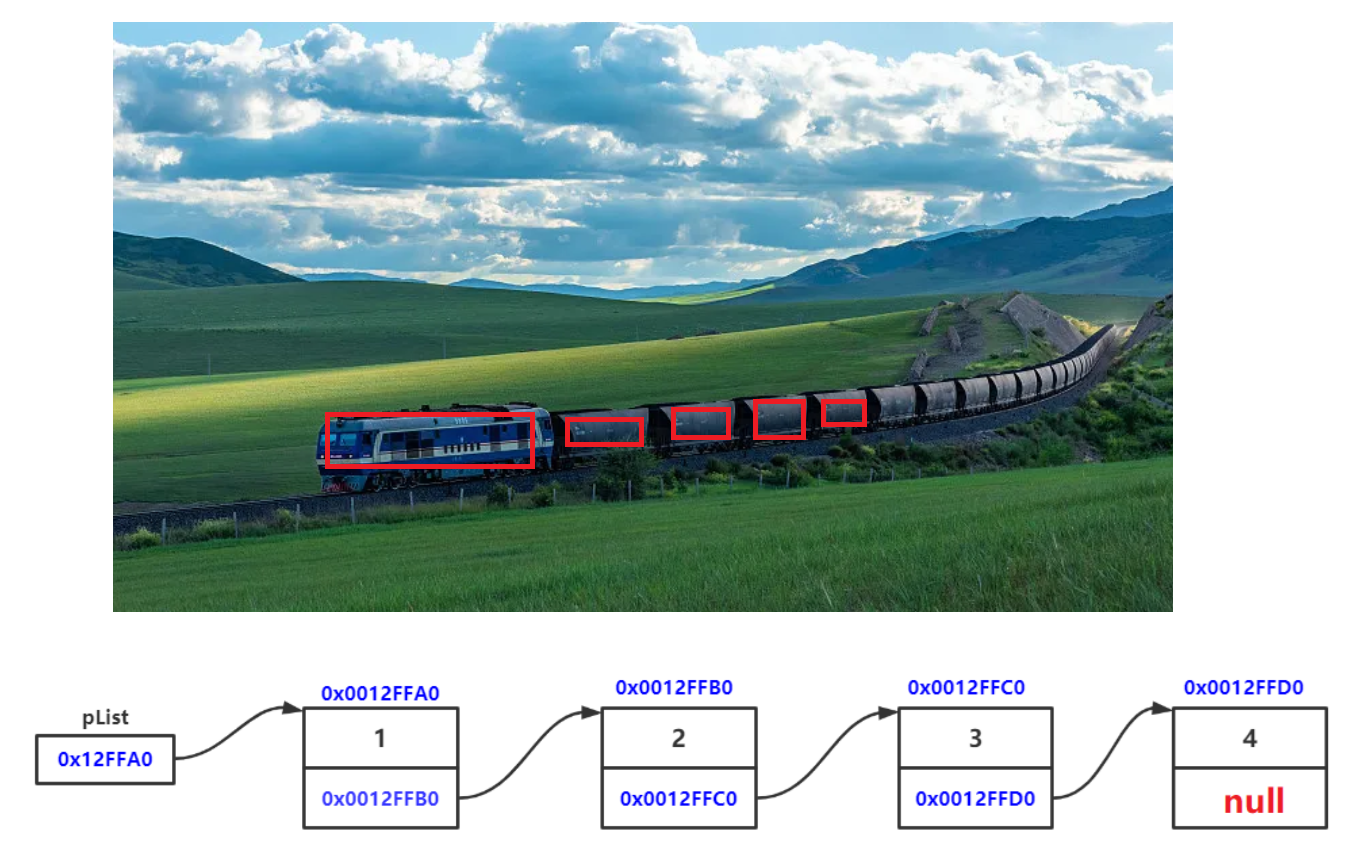
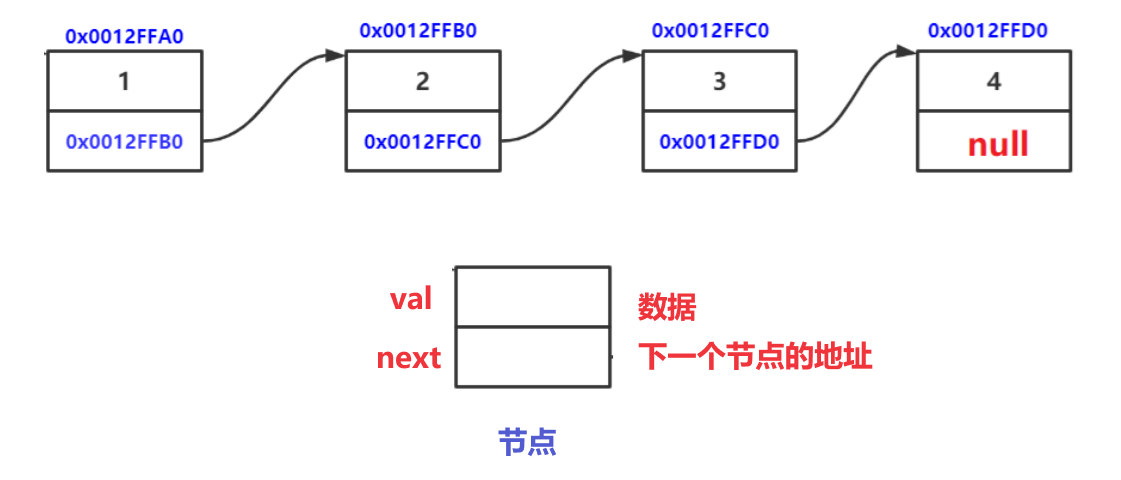
链表是一种物理存储结构上非连续存储结构,数据元素的逻辑顺序是通过链表中的引用链接次序实现的 。
链表是由一个一个的节点组织起来的,整体的组织就叫链表
注意:
- 从上图可看出,链式结构在逻辑上是连续的,但在物理上不一定连续
- 现实中的节点一般都是从堆上申请出来的
- 从堆上申请的空间,是按照一定的策略来分配的,两次申请的空间可能连续,也可能不连续
节点可以认为是节点对象,对象里面有两个节点属性,
val用来存储数据,next用来存储下一个节点的地址
分类
链表
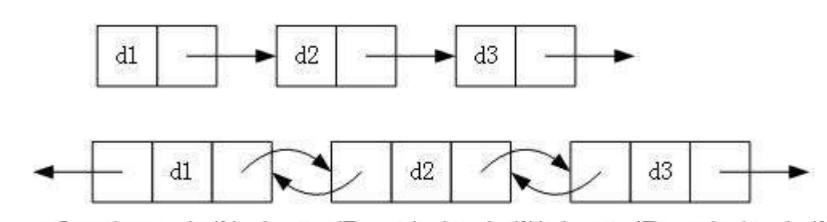
- 单向/双向
- 带头/不带头: 带头就是带一个头节点,头结点的数据域可以不存储任何信息,也可以用来存储一些附加信息,如链表的长度等。
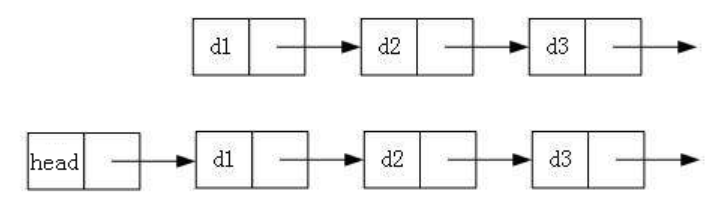
- 循环/不循环: 循环就是将最后一个节点里面地址改为第一个节点的地址
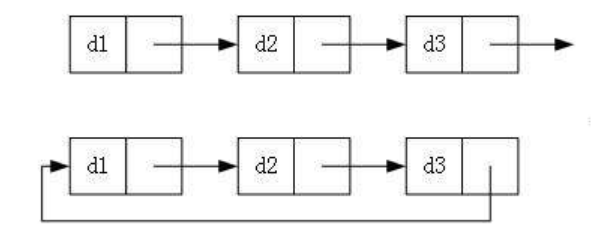
链表结构
- 单向带头循环
- 单向带头非循环
- 单向不带头循环
- 单向不带头非循环(重点)
- 双向带头循环
- 双向带头非循环
- 双向不带头循环
- 双向不带头非循环(重点)
链表的实现
链表的构造
节点的构造和连接
如何构造节点?
- 当一个事物的内部,还有一个部分需要一个完整的结构进行描述,而这个内部的完整的结构又只为外部食物提供服务,那么这个内部类的完整结构最好使用
内部类 - 因为链表是由若干节点组成,而节点又是一个完整的结构,所以将节点定义为内部类。其最少有两个域,一个是数值域,一个是
next域,且next的类型为节点类型 - 最后对节点进行构造,只需要实例化这个内部类的对象即可,
实例化出来的对象便是节点
class ListNode {
public int val;
public ListNode next;
public ListNode(int val) {
this.val = val;
}
}
public ListNode head;
public void createList() {
ListNode node1 = new ListNode(12);
ListNode node2 = new ListNode(23);
ListNode node3 = new ListNode(34);
ListNode node4 = new ListNode(45);
ListNode node5 = new ListNode(56);
}
如何让它与第一个节点相关联?
- 通过访问
node1存储地址的变量next,将其的值赋为下一个节点的地址 - 以此类推
- 最后让头节点指向第一个节点
node1
node1.next = node2;
node2.next = node3;
node3.next = node4;
node4.next = node5;
this.head = node1;
当
createList方法走完之后,实例化的各个节点对象就没有了,只保留了一个head对象
因为这些都是局部变量,方法调用完成之后,局部变量就被回收了
但不代表节点就没人引用了,他们被地址引用,谁引用了他们的地址,谁就引用他们
链表的功能
void display()——遍历链表
- 当
head == null的时候,链表就遍历完了。若写成head.next == null,则不会打印出最后一个节点的数据 - 要从第一个节点走到第二个节点,只需要
head == head. next即可。 - 但若想完成多次打印,
head的位置就不能变,需要一直在首位,所以我们就定义一个cur节点,来做head的遍历工作,head只负责站在最前面定位即可
node中的数据与其是否为null是两个独立的概念。在编程和数据结构中,node通常是一个对象或结构,它包含数据字段和一个或多个指向其他节点的指针或引用。
- 当我们说
node != null时,我们是在检查node这个变量是否指向了一个有效的内存地址,即它是否已经被初始化并且分配了内存。node中的数据字段可以包含任何类型的值,包括null(如果数据字段的类型允许)。但是,即使数据字段是null,node本身仍然可以是一个有效的对象,只是它的数据字段没有包含有用的信息。因此,
node != null并不表示node中的数据一定非空或有效。它只表示node这个变量已经指向了一个在内存中的对象
//遍历链表
public void display() {
ListNode cur = head;
while (cur != null) {
System.out.print(cur.val + " ");
cur = cur.next;
} System.out.println();
}
int size()——求链表长度
- 定义一个
count变量,用来记录cur向后走的次数 - 每向后走一步,
count++
不能写成:
cur.next != null,因为最后一个节点的 next 为空,若是这样判断的话最后一个节点就不会进循环了,就会少算一个
//计算链表长度
public int size() {
int count = 0;
ListNode cur = head;
while (cur != null) {
count++;
cur = cur.next;
} return count;
}
void addFirst(int val)——头插法
- 将此时头结点的地址传给 node 的 next 变量
- 将头节点前移到 node 的地方
这里两步的顺序不可以交换,不然就是自己指向自己了
插入节点的时候,一般先绑后面,再插入前面
//头插
public void addFirst(int val) {
ListNode node = new ListNode(val);
node.next = head;
head = node;
}
void addLast(int val)——尾插法
- 为了避免产生空指针异常报错,我们先对
head == null的情况进行讨论- 若头节点为空,则
head = node; - 记得加上
return,否则程序会继续执行下去
- 若头节点为空,则
- 若链表不为空,找到链表的尾巴
- 当
cur. next == null时,cur指向的就是尾巴
- 当
- 最后让
head.next == node;即可
//尾插
public void addLast(int val) {
ListNode node = new ListNode(val);
if (head == null) {
head = node;
return;
} ListNode cur = head;
while (cur.next != null) {
cur = cur.next;
} cur.next = node;
}
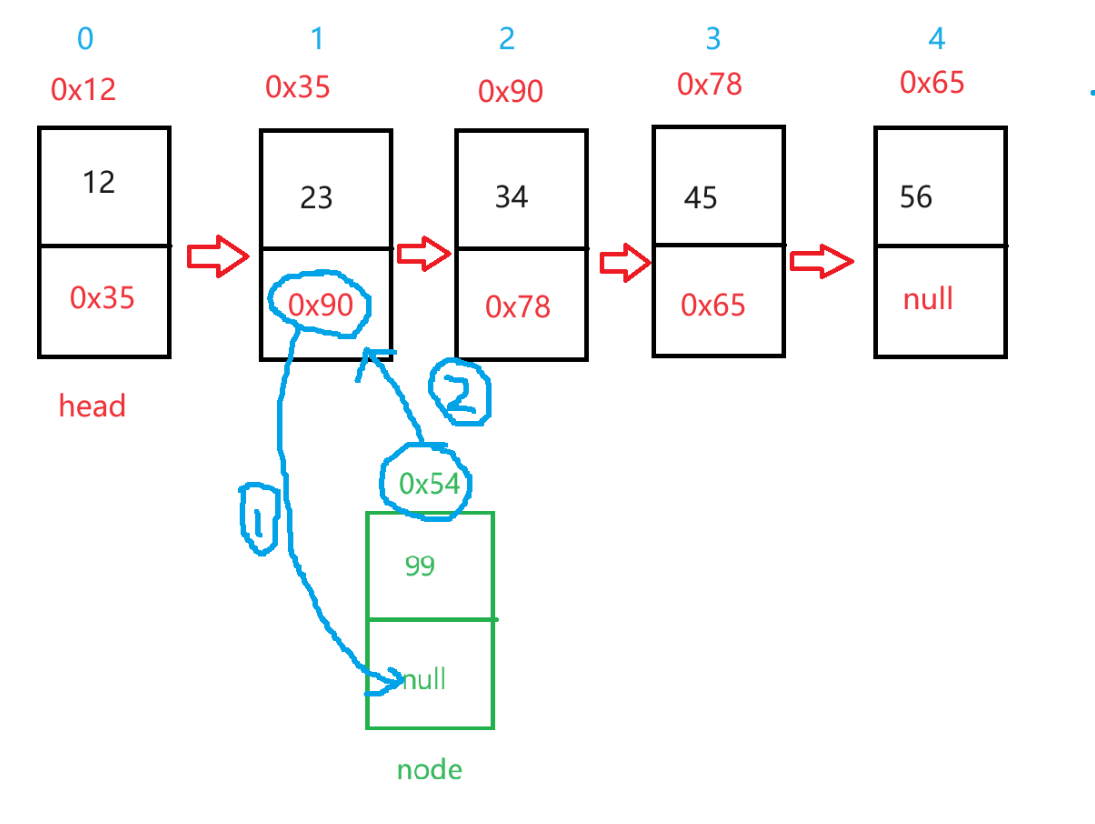
void addIndex(int index, int val)——在任意位置插入
- 判断
index的合法性- 定义一个
checkIndex(int index)方法用来检查index的合法性 - 若不合法,则抛出一个自定义异常:
IndexNotLeagalException
- 定义一个
index == 0 || index == size();- 前者相当于是头插,直接调用
addFirst() - 后者相当于是尾插,直接调用
addLast()
- 前者相当于是头插,直接调用
- 找到
index的前一个位置- 创建一个
findIndexSubOne(int index)方法 - 创建一个节点
cur来接收调用方法的返回值 - 最后
cur就是index位置的前一个节点了
- 创建一个
- 进行连接
- 实例化一个所带数据为
val的节点node node.next = cur.next;cur.next = node;
- 实例化一个所带数据为
//在任意位置插入
public void addIndex(int index, int val) {
//1. 判断index的合法性
try {
checkIndex(index);
} catch (IndexNotLegalException e) {
e.printStackTrace();
}
//2. index == 0 || index == size()
if(index == 0){
addFirst(val);
return;
} else if(index == this.size()){
addLast(val);
return;
}
//3. 找到 index 的前一个位置
ListNode cur = findIndexSubOne(index);
//4. 进行连接
ListNode node = new ListNode(val);
node.next = cur.next;
cur.next = node;
}
//用来检查输入的 index 是否合法的方法
public void checkIndex(int index) {
if(index < 0 || index > size()){
//若不合法则抛出一个异常
throw new IndexNotLegalException("index位置不合法");
}
}
//用来找到 index 前一位对应的节点的函数
private ListNode findIndexSubOne(int index) {
ListNode cur = head;
for (int i = 0; i < index - 1; i++) {
cur = cur.next;
} return cur;
}
boolean contains(int val)——链表中是否包含某个元素
- 遍历链表
- 若能在链表元素中找到
val值,则返回true - 否则返回
false
//判断链表中是否包含某个元素
public boolean contains(int val) {
ListNode cur = head;
while(cur != null){
if(cur.val == val){
return true;
}
}
return false;
}
void remove(int key)——删除第一次出现的关键字的节点
- 首先判断是否为空链表
- 遍历链表
- 循环条件为:
cur.next != null
- 循环条件为:
- 找到 val 值的前一个节点 cur
- 当
cur.next.val == val时,找到目标
- 当
- 进行删除
- 找到之后,将其创建为
del节点 cur.next = del.next或者cur.next = cur.next.next- 看表达式可知,删除的判断是从第二个元素开始的,无法对第一个元素进行判断,所以需要针对第一个元素再加上一个删除判断:
head.val == val
- 找到之后,将其创建为
//删除第一次出现的关键字的节点
public void remove(int val) {
//链表为空
if(head == null){
return;
} //当第一个元素就为 val
if(head.val == val){
head = head.next;
return;
}
ListNode cur = head;
while(cur.next != null){
if(cur.next.val == val){
ListNode del = cur.next;
cur.next = del.next;
}
cur = cur.next;
}
}
void removeAll(int val)——删除所有出现的关键字的节点
在原有的链表上进行修改
只遍历一遍链表
- 定义两个引用变量
- cur 代表当前需要删除的节点
- prev 代表当前需要删除节点的前驱
- 若
cur.val == valprev.next = cur.nextcur = cur.next
- 否则:
prev = curcur = cur.next
- 处理头节点
//删除所有出现的关键字节点
public void removeAll(int val) {
//1. 判空
if (head == null) {
return;
}
//2. 定义 prev 和 cur
ListNode prev = head;
ListNode cur = head.next;
//3. 开始判断并删除
while (cur != null) {
if (cur.val == val) {
prev.next = cur.next;
} else {
prev = cur;
}
cur = cur.next;
}
//4. 处理头结点
if (head.val == val) {
head = head.next;
}
}
void clear()——清空
回收对象,防止内存浪费
head = null
//清空链表
public void clear() {
head = null;
}