欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://spike.blog.csdn.net/article/details/140281680
免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。
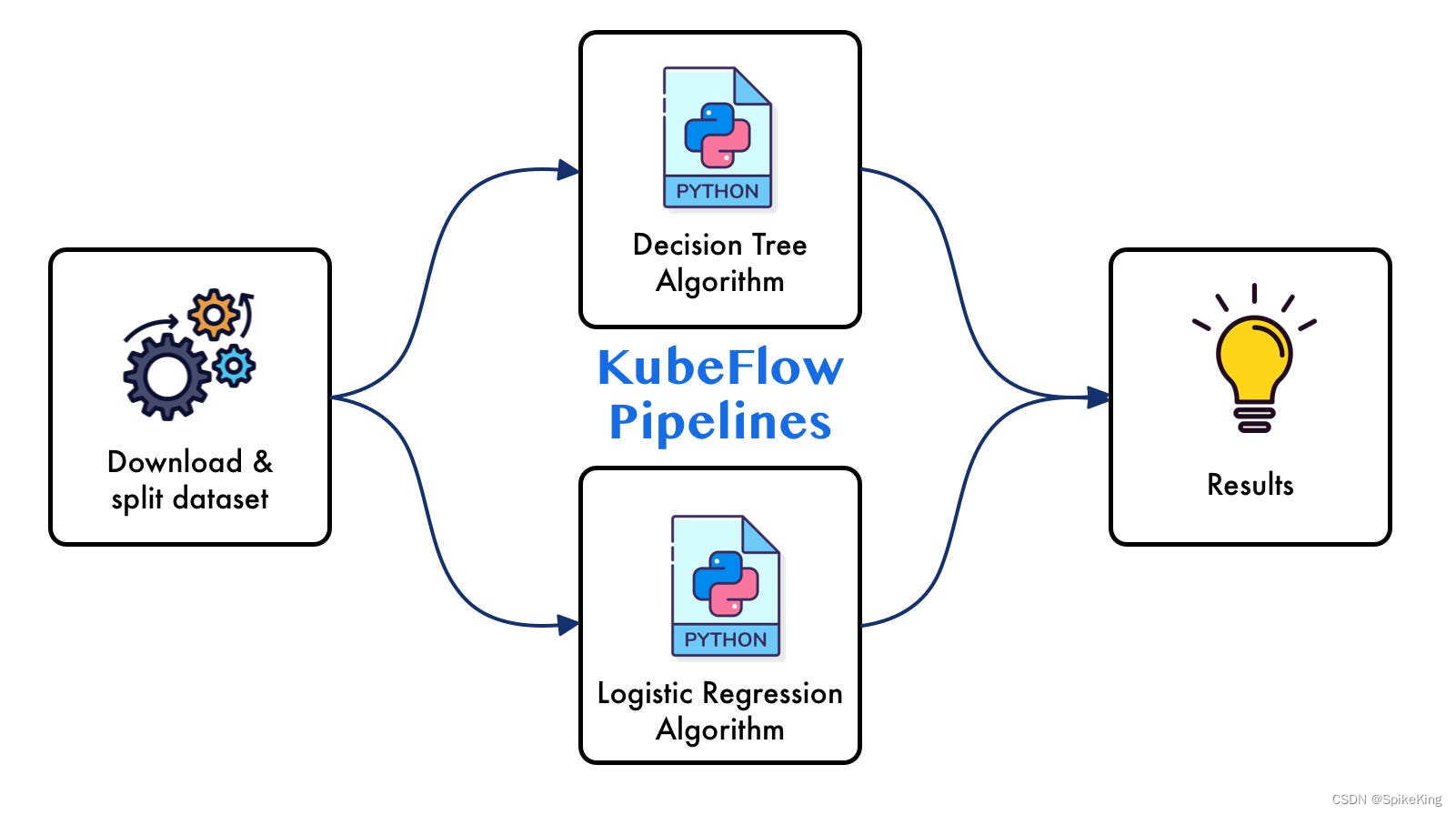
Kubernetes 的 KFP(Kubeflow Pipelines)是一个平台,用于构建和部署可扩展和可移植的机器学习(ML)工作流。允许用户以简单、可复用和可组合的方式定义机器学习任务,并支持各种 ML 框架。KFP 包括一个用于构建 ML 管道的 SDK,以及用于运行这些管道的运行时环境。通过 KFP,用户可以轻松地将机器学习模型从实验转移到生产环境,同时保持模型的可追溯性和版本控制。
KFP 的建议版本 1.8.19 或 1.8.22:
Name: kfp
Version: 1.8.22
Summary: KubeFlow Pipelines SDK
Home-page: https://github.com/kubeflow/pipelines
Author: The Kubeflow Authors
Author-email:
License:
Location: /Users/wang/venv_ml_p3/lib/python3.9/site-packages
Requires: absl-py, click, cloudpickle, Deprecated, docstring-parser, fire, google-api-core, google-api-python-client, google-auth, google-cloud-storage, jsonschema, kfp-pipeline-spec, kfp-server-api, kubernetes, protobuf, pydantic, PyYAML, requests-toolbelt, strip-hints, tabulate, typer, uritemplate, urllib3
Required-by:
Name: PyYAML
Version: 6.0.1
Summary: YAML parser and emitter for Python
Home-page: https://pyyaml.org/
Author: Kirill Simonov
Author-email: xi@resolvent.net
License: MIT
Location: /Users/wang/venv_ml_p3/lib/python3.9/site-packages
Requires:
Required-by: kfp, kubernetes
注意:不要安装最新的版本,否则会报错在
component_factory.py中,Missing type annotation for argument
在安装 kfp 过程中,如果遇到 AttributeError: cython_sources 问题,即错误:
running egg_info
writing lib3/PyYAML.egg-info/PKG-INFO
writing dependency_links to lib3/PyYAML.egg-info/dependency_links.txt
writing top-level names to lib3/PyYAML.egg-info/top_level.txt
AttributeError: cython_sources
[end of output]
# ...
note: This error originates from a subprocess, and is likely not a problem with pip.
error: subprocess-exited-with-error
参考: GitHub - AttributeError: cython_sources when installing KFP SDK + running Python components
Seeing this issue on GCP Vertex that uses Kubeflow internally. Forcing pyyaml==5.3.1 with non-working kfp==1.8.21 fixes the issue (following already mentioned comment)
即预先安装 pyyaml==5.3.1,即可:
pip uninstall cython
pip install pyyaml==5.3.1
pip install kfp==1.8.19
pip install pyyaml==6.0.1
pip install kfp==1.8.22
构建生成脚本 afm_pipeline.py,包括 2 个Jobs,Job1 在 Job2 之后运行,即:
from string import Template
import kfp
import kfp.dsl as dsl
import yaml
msa_job_yaml = Template("""
apiVersion: batch/v1
kind: Job
metadata:
name: afm-msa-search # 训练名字
spec:
completions: 2 # 总pod数量
parallelism: 2 # 并行运行的pod数量
backoffLimit: 0 # 重试次数,这里失败后不需要重试
template:
metadata:
annotations:
sidecar.istio.io/inject: "false"
labels:
file-mount: "true" # 这两个label必须加,kubeflow帮你自动配置一些基本环境
user-mount: "true"
spec:
nodeSelector:
service: "[your service name]" # device是gpu类型,比如a10,a100
tolerations:
- key: role
operator: Equal
value: [your group name]
effect: NoSchedule
containers:
- name: sp
image: "af2:v1.04" # 统一用这个镜像,提供一个基础conda和cuda环境
imagePullPolicy: Always
resources:
limits:
cpu: "62"
memory: 124G
requests:
cpu: "62"
memory: 124G
command: [
"/bin/sh",
"-cl",
"python -u [msa_script]"] # 执行的命令
workingDir: "af2/" # 默认的工作目录,就是你启动脚本的所在目录
env: # 这是把每个pod的名字注入环境变量,以便能够在程序里区分当前是在哪一个pod中
- name: PODNAME
valueFrom:
fieldRef:
fieldPath: metadata.name
restartPolicy: Never
""")
model_job_yaml = Template("""
apiVersion: batch/v1
kind: Job
metadata:
name: afm-model-infer # 训练名字
spec:
completions: 2 # 总pod数量
parallelism: 2 # 并行运行的pod数量
backoffLimit: 0 # 重试次数,这里失败后不需要重试
template:
metadata:
annotations:
sidecar.istio.io/inject: "false"
labels:
file-mount: "true" # 这两个label必须加,kubeflow帮你自动配置一些基本环境
user-mount: "true"
spec:
nodeSelector:
gpu.device: "a100"
tolerations:
- key: role
operator: Equal
value: [your group name]
effect: NoSchedule
containers:
- name: sp
image: "af2:v1.04" # 统一用这个镜像,提供一个基础conda和cuda环境
imagePullPolicy: Always
resources:
limits:
cpu: 4
memory: "64G"
nvidia.com/gpu: 1
command: [
"/bin/sh",
"-cl",
"python -u [model_script]"] # 执行的命令
workingDir: "af2/" # 默认的工作目录,就是你启动脚本的所在目录
env: # 这是把每个pod的名字注入环境变量,以便能够在程序里区分当前是在哪一个pod中
- name: PODNAME
valueFrom:
fieldRef:
fieldPath: metadata.name
restartPolicy: Never
""")
@dsl.pipeline(
name="psp-multimer-ag2-afm",
)
def job_pipeline(input_fasta_path, output_dir):
job_msa = yaml.safe_load(msa_job_yaml.substitute(
{
'input_fasta_path': input_fasta_path,
'output_dir': output_dir,
}
))
job_model = yaml.safe_load(model_job_yaml.substitute(
{
'input_fasta_path': input_fasta_path,
'output_dir': output_dir,
}
))
print(f"[Info]: job_msa: {job_msa}")
print(f"[Info]: job_model: {job_model}")
msa = dsl.ResourceOp(name='psp-multimer-ag2-afm-msa', k8s_resource=job_msa,
set_owner_reference=True,
success_condition='status.conditions.0.type==Complete',
failure_condition='status.failed >0')
model = dsl.ResourceOp(name='psp-multimer-ag2-afm-model', k8s_resource=job_model,
set_owner_reference=True,
success_condition='status.conditions.0.type==Complete',
failure_condition='status.failed >0')
model.after(msa)
if __name__ == '__main__':
kfp.compiler.Compiler().compile(job_pipeline, 'psp-multimer-ag2-afm.yaml')
运行脚本,生成 YAML 文件 psp-multimer-ag2-afm.yaml,即:
python afm_pipeline.py
运行日志:
[Info]: job_msa: {'apiVersion': 'batch/v1', 'kind': 'Job', 'metadata': {'name': 'afm-msa-search'}, 'spec': {'completions': 2, 'parallelism': 2, 'backoffLimit': 0, 'template': {'metadata': {'annotations': {'sidecar.istio.io/inject': 'false'}, 'labels': {'file-mount': 'true', 'user-mount': 'true'}}, 'spec': {'nodeSelector': {'service': 'ai2-msa-only'}, 'tolerations': [{'key': 'role', 'operator': 'Equal', 'value': 'ai2-msa-only', 'effect': 'NoSchedule'}], 'containers': [{'name': 'sp', 'image': 'af2:v1.04', 'imagePullPolicy': 'Always', 'resources': {'limits': {'cpu': '62', 'memory': '124G'}, 'requests': {'cpu': '62', 'memory': '124G'}}, 'command': ['/bin/sh', '-cl', 'python -u [msa_script]'], 'workingDir': 'af2/', 'env': [{'name': 'PODNAME', 'valueFrom': {'fieldRef': {'fieldPath': 'metadata.name'}}}]}], 'restartPolicy': 'Never'}}}}
[Info]: job_model: {'apiVersion': 'batch/v1', 'kind': 'Job', 'metadata': {'name': 'afm-model-infer'}, 'spec': {'completions': 2, 'parallelism': 2, 'backoffLimit': 0, 'template': {'metadata': {'annotations': {'sidecar.istio.io/inject': 'false'}, 'labels': {'file-mount': 'true', 'user-mount': 'true'}}, 'spec': {'nodeSelector': {'gpu.device': 'a100'}, 'tolerations': [{'key': 'role', 'operator': 'Equal', 'value': 'algo2', 'effect': 'NoSchedule'}], 'containers': [{'name': 'sp', 'image': 'af2:v1.04', 'imagePullPolicy': 'Always', 'resources': {'limits': {'cpu': 4, 'memory': '64G', 'nvidia.com/gpu': 1}}, 'command': ['/bin/sh', '-cl', 'python -u [model_script]'], 'workingDir': 'af2/', 'env': [{'name': 'PODNAME', 'valueFrom': {'fieldRef': {'fieldPath': 'metadata.name'}}}]}], 'restartPolicy': 'Never'}}}}
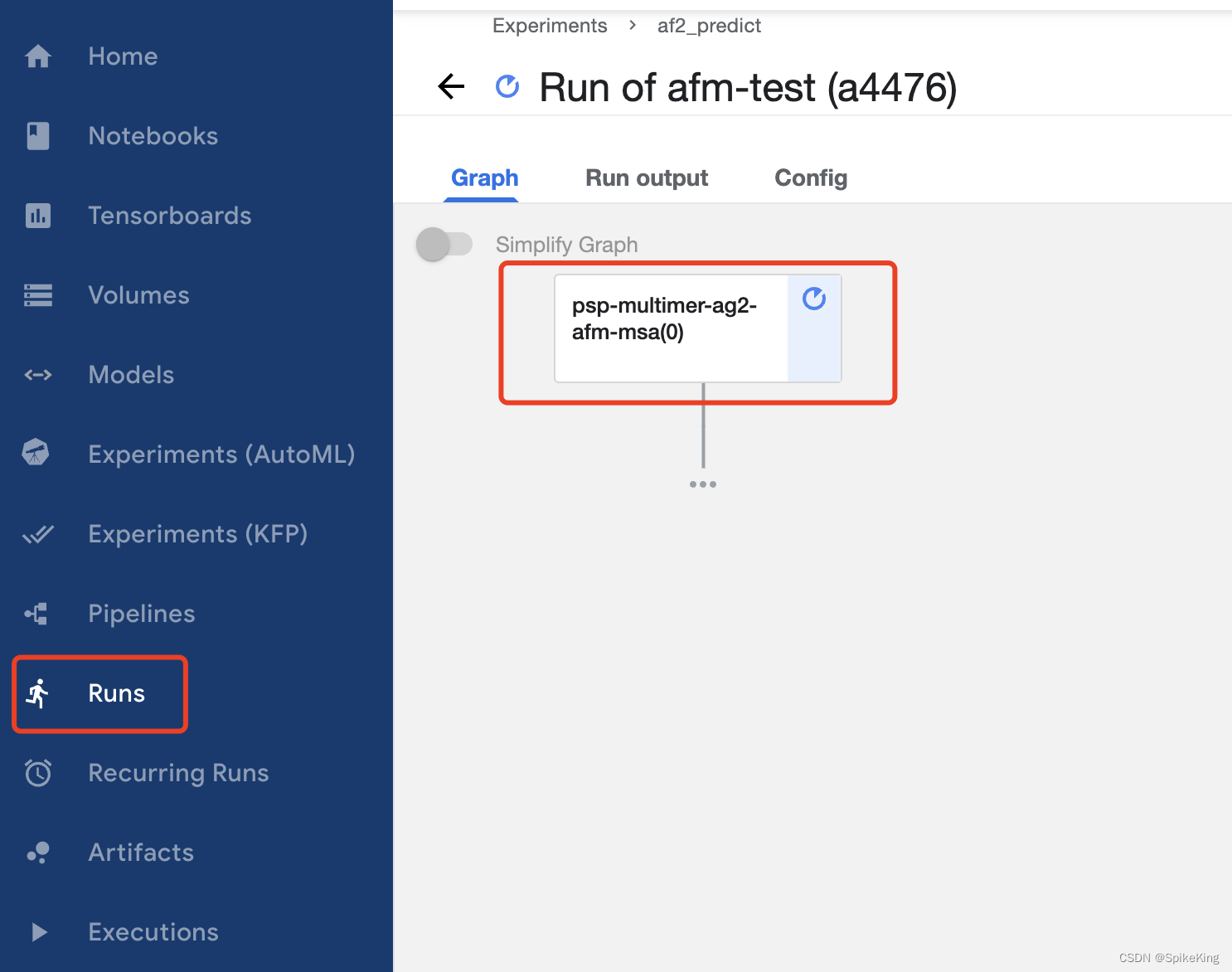
使用 Kubernetes 构建 Pipeline,上传生成的 YAML 文件,即:
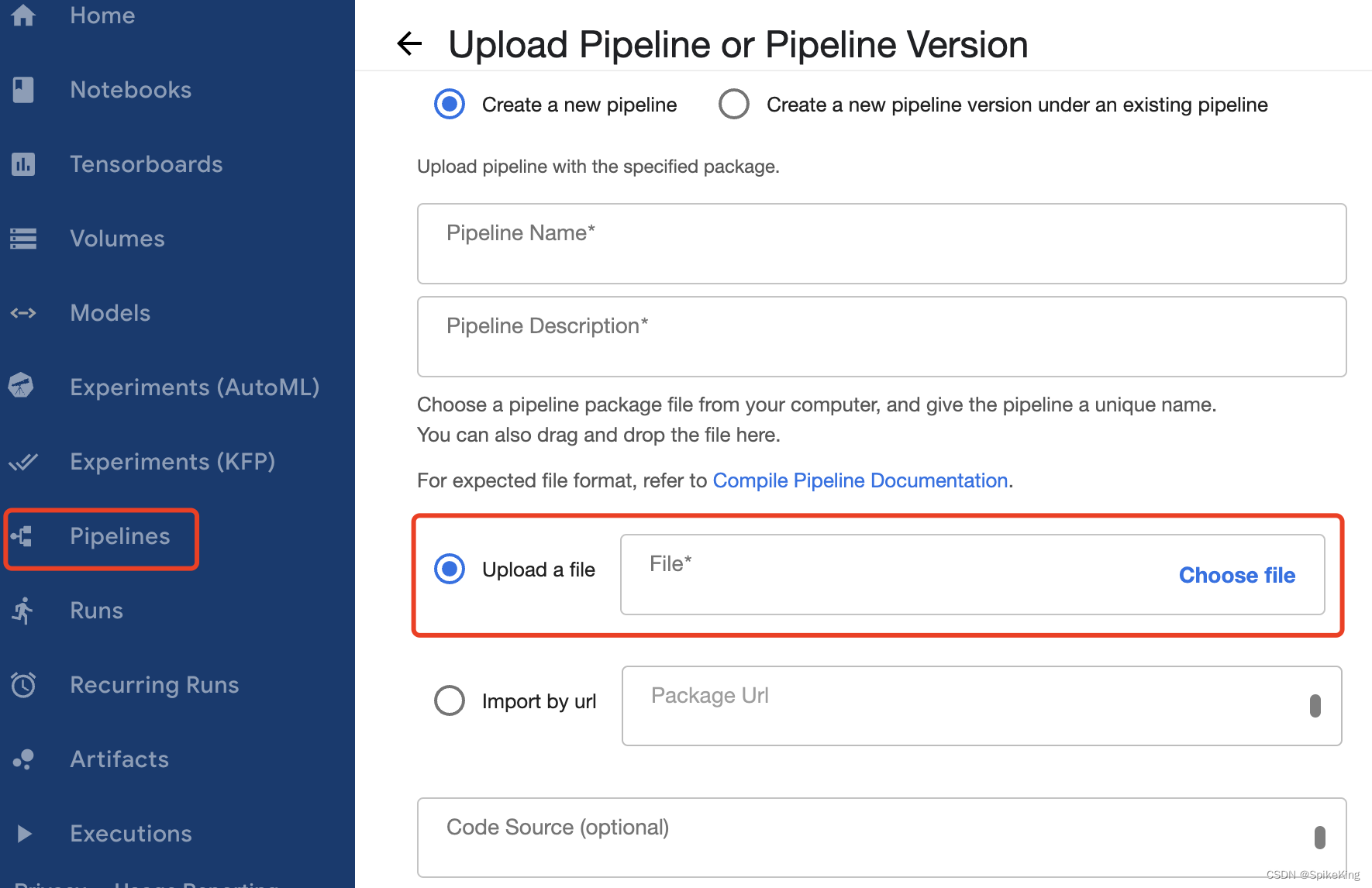
运行 Pipeline,即: