更好的效果,更低的价格,听起来是不是像梦呓?

限制
首先,让我们来介绍一个词:RAG。
简单来说,RAG(Retrieval-Augmented Generation,检索增强生成) 的工作原理是将大型文档分割成多个小段落或片段。主要原因是,大语言模型的上下文窗口长度有限,无法一次处理超过上下文窗口长度的信息。
当我提出一个问题时,RAG 技术可以先从这些片段中检索相关信息,根据我提问的内容与这些片段的相似度,找出若干个与问题相关的片段,组合成一个上下文,然后将这些信息,连同我的提问一起输入到大语言模型中,然后期待大语言模型「更为精准」的回答。
然而,我们需要考虑一些潜在的局限性。对于一个足够长的文档和一个非常复杂的问题,单靠这几个(仅仅是疑似相关的)片段可能是不够的。真正的答案,也许根本就不在里面。
我们之前讨论了很多关于私有知识库。例如 Quivr, Elephas, GPTs, Obsidian Copilot …… 用久了你会发现,私有知识库提供的回答结果与通过数据微调模型获得的结果可能差异很大 —— 微调后的模型往往能够依据私有数据回答非常复杂的问题,而 RAG 这种简单粗暴的拼接方式,很多时候得到的答案并不理想。
图谱
这些问题就催生了 GraphRAG。GraphRAG 是一种创新的技术,它结合了知识图谱结构和 RAG 方法,旨在解决传统 RAG 方法的局限性。
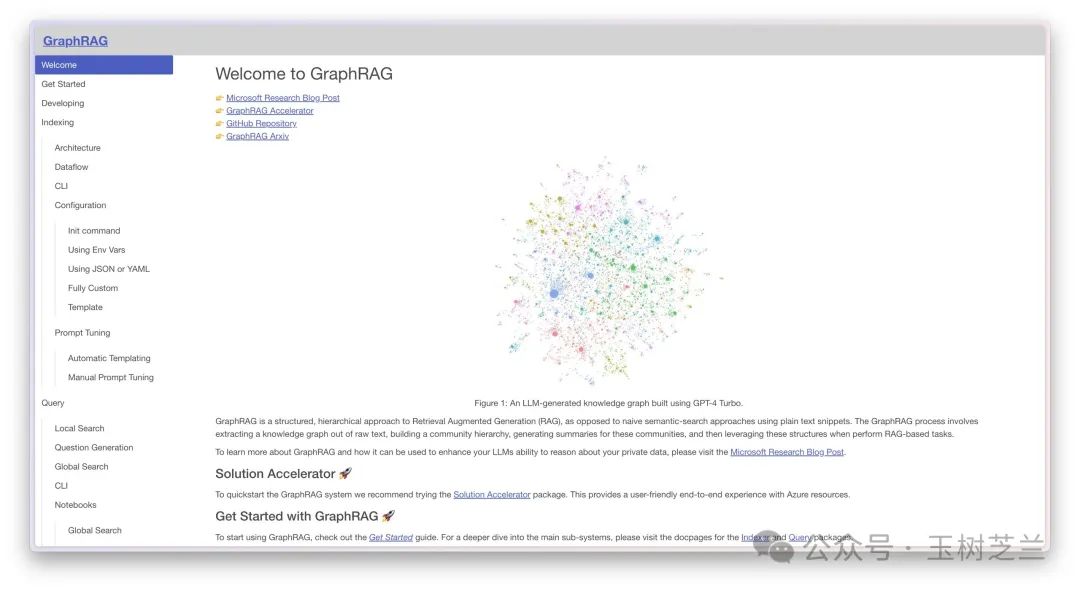
这是微软研发的一个创新产品,它代表了 RAG 技术的最新进展。微软还发布了相关的学术论文,详细阐述了 GraphRAG 的理论基础和技术实现。

那么,这里的 "Graph(图)" 究竟是什么意思呢?在 GraphRAG 的主页上,你会看到一个复杂的图谱。这个图谱不仅仅是一个简单的示意图,它代表了知识的结构化表示。在这个图谱中,每个节点可能代表一个概念或实体,而连接这些节点的边则表示它们之间的关系。
假设图谱中有一个节点是「老虎」,另一个是「兔子」,老虎与兔子之间连一条线,上面写着「吃」,代表二者的关联是「老虎吃兔子」。当然,这只是一个不够严谨的比喻。
有了这样的图谱,为什么要将其与刚才提到的 RAG 结合呢?因为之前提到的「满地找碎片」的传统 RAG 方式实际上效果不佳,所以我们希望将这些概念之间的复杂关系展现出来。在查询时,不再是大海捞针去找「可能相关」的信息碎片,而是根据图谱中已经掌握的关联,提取一整串相连的信息,让大语言模型来一并处理。
这里是 GraphRAG 的 GitHub 网址。它在 GitHub 上的受欢迎程度如何?已经获得超过一万一千颗星。
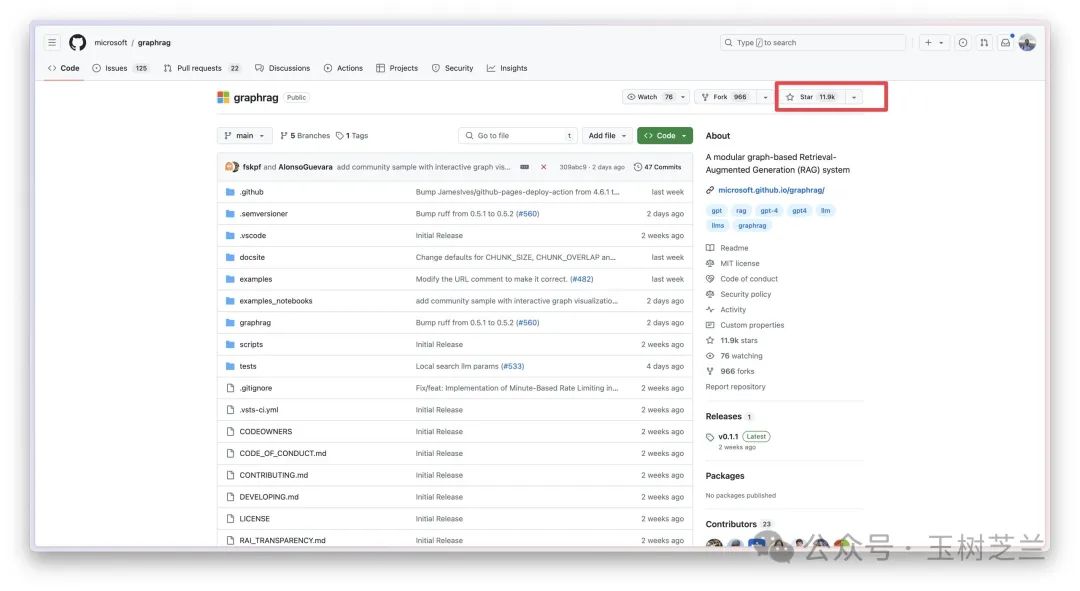
对于一个项目来说,这是一个非常好的成绩,我做梦都希望自己的项目能达到这样的水平。看来还得继续努力。
特点
我们来看看 GraphRAG 的特点。它融合了人工智能的两大流派,一个是深度学习,另一个是知识图谱。
曾经这两个流派是对立的。后来发现对立干啥啊?
你现在用深度学习直接回答效果不好,但如果结合图谱,效果就会强很多。
另一方面,构建知识图谱原来得人工根据规则去抽取其中的实体和关联,那是一个砸钱堆人力的活计。后来发现用上深度学习可以有效提升实体抽取效率。特别是有了大语言模型,人们发现抽取实体和关联变得更加准确、简单且低成本。所以,二者的融合,是大势所趋。
那么融合之后的 GraphRAG 擅长什么呢?它能够把实体之间的复杂关系和上下文串联起来。
正如刚才我们提到的这个过程,它可以连接多个信息点进行复杂查询。这种查询不是简单地提取一部分信息就能完成的。原先根据相似度找出来的这些信息碎片,可能根本不足以支撑问题解答。但现在,根据实际关联获取相关信息,效果要好很多。
另外 GraphRAG 由于对数据集有了整体的刻画,因此概念语义信息得到了充分的表达。
两个特点相夹持,使得 GraphRAG 的表现有了非常显著的改进。后面的例子里,你也能观察到这点。
局限
不过,这个技术也不是那么完美。它遇到的问题,最为显著的就是一个字 —— 贵。
官方的例子提到一本书,稍后我们会看到,实体书篇幅大概 200 页左右。把它图谱化 RAG ,需要花多少钱?
11 美金。
有的人觉得这太贵了,为了索引一本电子书耗费的钱都快赶上一本实体书了。
那么我们有没有解决办法呢?我们需要分析。
GraphRAG 实施成本为什么会那么高?因为它使用的是 GPT-4 Turob Preview 模型。这个模型 token 成本较高,由于在图谱构建过程中,需要反复调用它,因此 GraphRAG 成本居高不下。
既然找到了原因,我们是否可以使用一个更经济的模型来替代它呢?
这是个很自然就能联想到的问题。许多人也已经做了尝试。例如,有人尝试在本地运行 Ollama 这样的本地小型模型,但最终效果不好,构建过程中常常出现问题。
有的人使用 Groq 来做,而且成功了,但需要进行不少复杂的设置变更,对于初级用户来说非常麻烦。
最简便的方法,自然是期待 OpenAI 推出一个更经济实惠的模型。
期盼着,期盼着,好消息来了。
OpenAI 最近给我发了信,说它新推出了一个 GPT-4o mini 模型。

不要被名称忽悠了——GPT-4o mini 的对标模型,其实是GPT-3.5 Turbo,但它甚至比3.5 Turbo还要便宜60%。
我不得不钦佩 OpenAI 现在的命名方式。如果你把它叫做 GPT 3.5 Turbo Plus,效果可能就不好,因为人们会觉得这不就是一个改进版的 3.5 吗?虽然便宜一点,但依然觉得不太满意。
你把它叫做 GPT-4o mini ,人们就会脑补这是一个好的模型,多模态、快速又便宜。大家就会觉得自己占了便宜,竟然能用一个跟 GPT-4o 对标的模型,居然比原来的 3.5 还便宜那么多,这无论如何,也是个甜买卖啊。
我拿到 GPT-4o mini 的使用权限后,立即测试了一下它的中文写作。我把测试结果分享到了知识星球。
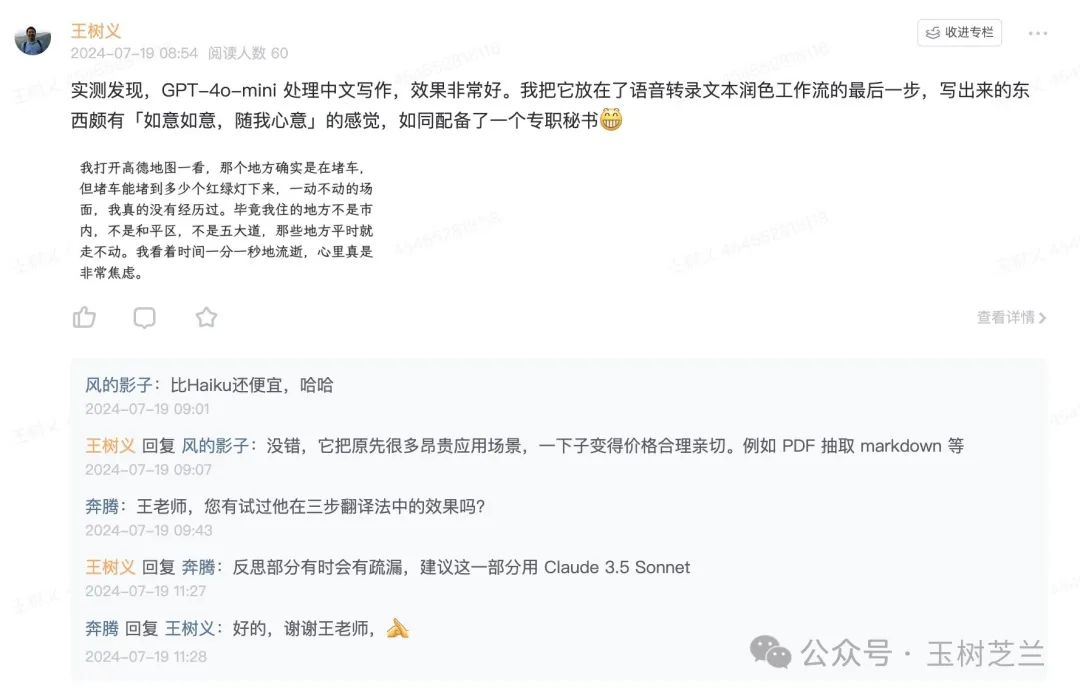
不过你不要误解,GPT-4o mini 毕竟是个小模型,你可以指望它的中文输出能力,但千万不要以为它的推理与逻辑思考能力也可以赶上 GPT-4o 或者 Claude 3.5 Sonnet 。所以我是把它放在了工作流里合适的位置上,物尽其用。
突然,我想到 GPT-4o mini 不仅可以用来输出文字,还可以用它和 GraphRAG 「双剑合璧」啊。
想到这里都觉得兴奋不已,那咱们下面就来看看效果究竟如何。
安装
首先,我们需要把 GraphRAG 安装上,这里使用 pip install,非常简单。
pip install graphrag```
它会安装一系列的依赖,包括了 GraphRAG 所需的各种库和工具。安装过程可能需要一些时间,取决于你的网络速度和电脑性能。
安装完成后,我们找一个目录,新建一个目录,然后在下面执行这一句。
mkdir -p ./ragtest/input
这里的 input 是什么呢?就是我们存放输入的文本 —— 像刚刚提到的 200 页的书或者文章 —— 的地方。
我在 Visual Studio Code 下给你演示吧,比较直观。
执行这条命令后,侧边栏会出现一个新的文件夹。
接下来,我们要把书籍资料下载下来。这里 GraphRAG 官网样例使用的是古腾堡计划,上面有很多免费的图书。古腾堡计划是一个致力于创建和分发免费电子书的志愿者项目,它提供了大量版权已过期的经典文学作品。
GraphRAG 官网给的样例是《圣诞颂歌》,是查尔斯・狄更斯创作的一部著名小说,讲述了一个守财奴在圣诞节前夜经历的奇妙故事,最终改变了自己的人生态度。
执行下面这条命令下载即可:
curl https://www.gutenberg.org/cache/epub/24022/pg24022.txt > ./ragtest/input/book.txt
我查看了一下,下载的文件在本地显示为 189KB。大吗?对于文本来说,不算太少。不过相对于今天动辄上 GB 的存储内容来说,那是真不大。
下载完成后,我们需要进行初始化。
python -m graphrag.index --init --root ./ragtest
这个步骤是为了设置 GraphRAG 的基本环境和配置,确保后续操作能够顺利进行。

我们来看一下,执行很快,因为这里面不做任何实际索引操作,只是新建几个文件和文件夹。
刚才有一个 input 是你自己建的,现在 GraphRAG 创建了 output 文件夹、prompts 文件夹,还有两个设定文件。
我们先设置这个 .env 文件,里面需要填入一些配置。这些配置通常包括 API 密钥、模型选择等重要参数,它们对于 GraphRAG 的正常运行至关重要。
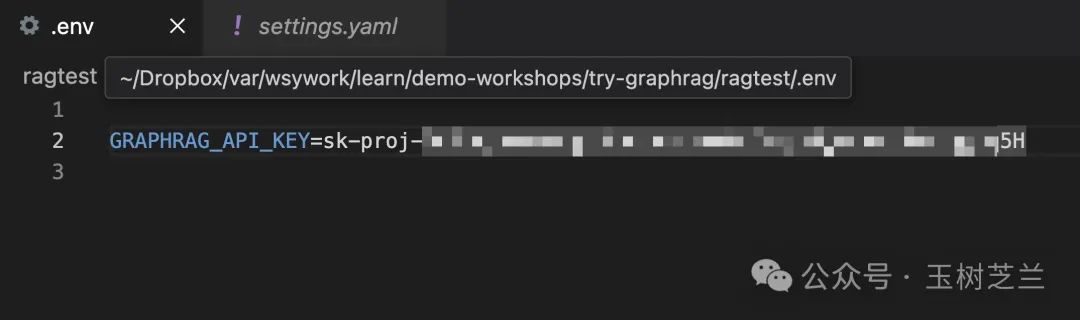
你需要将 OpenAI 提供的 API 密钥填入 GRAPHRAG_API_KEY 即可。
另外,settings.yaml 文件也需要修改。
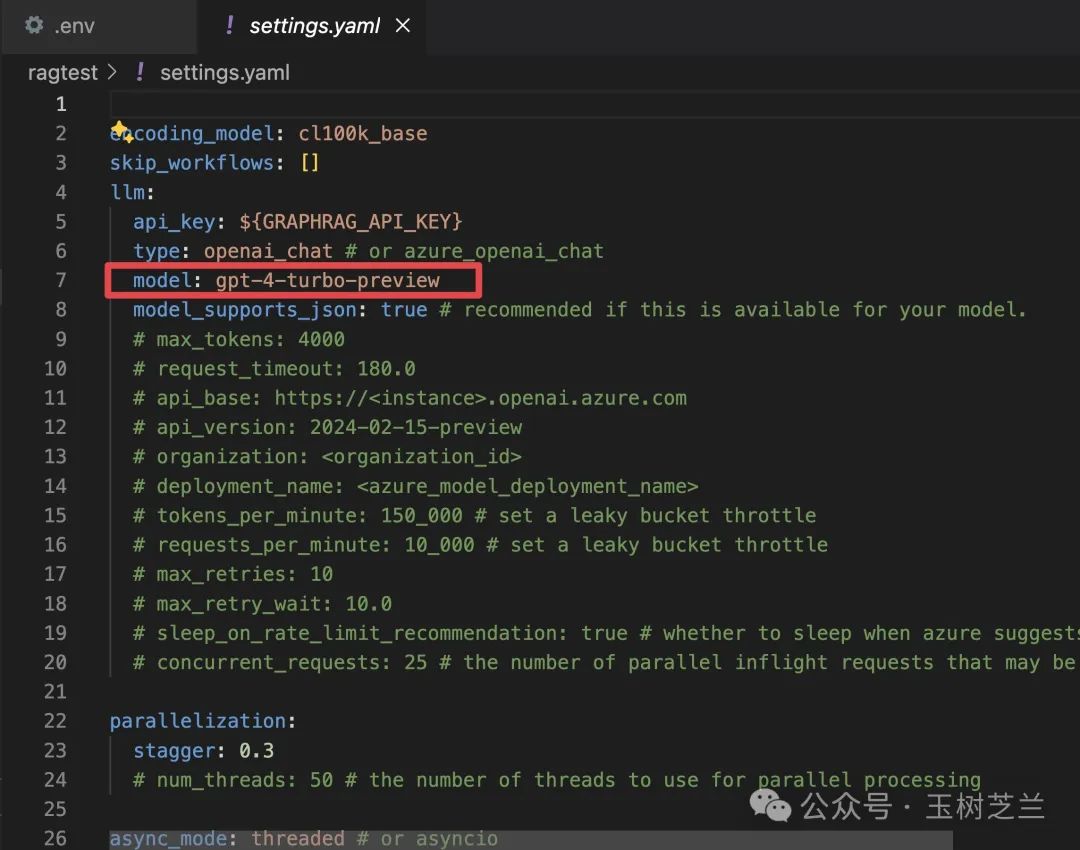
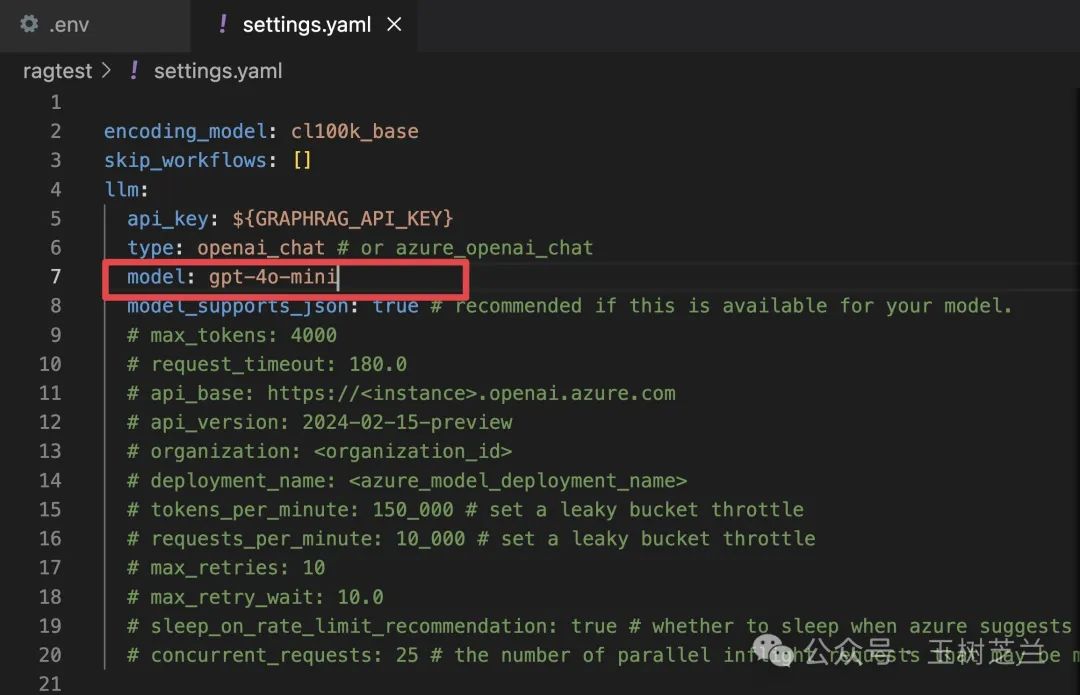
这里面有一项尤其需要注意。原来默认使用的是 GPT-4 Turbo preview,这一定要改为 GPT-4o mini,因为我们要尝试降低成本。其他设置无需更改。
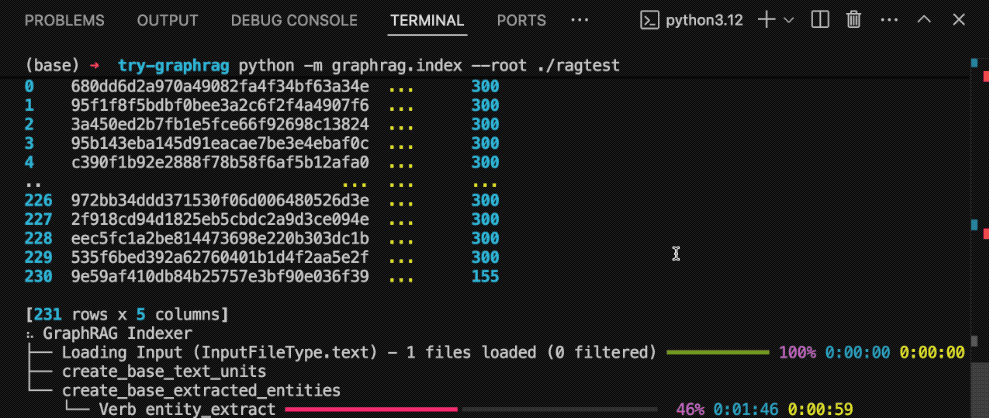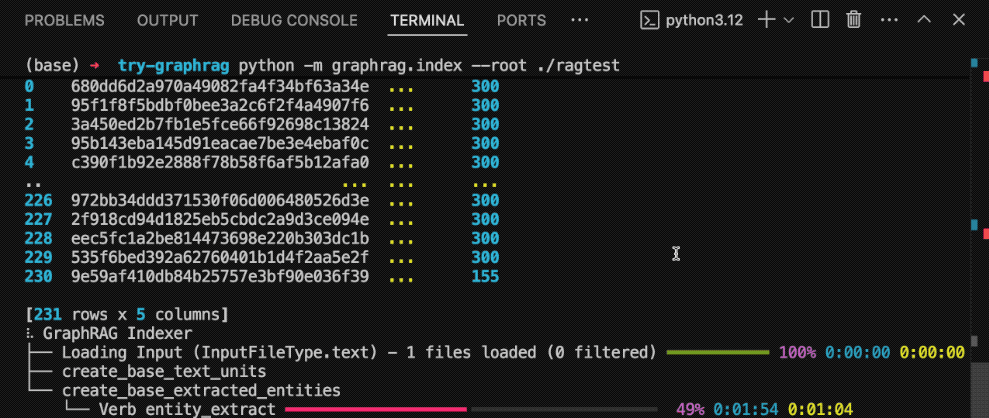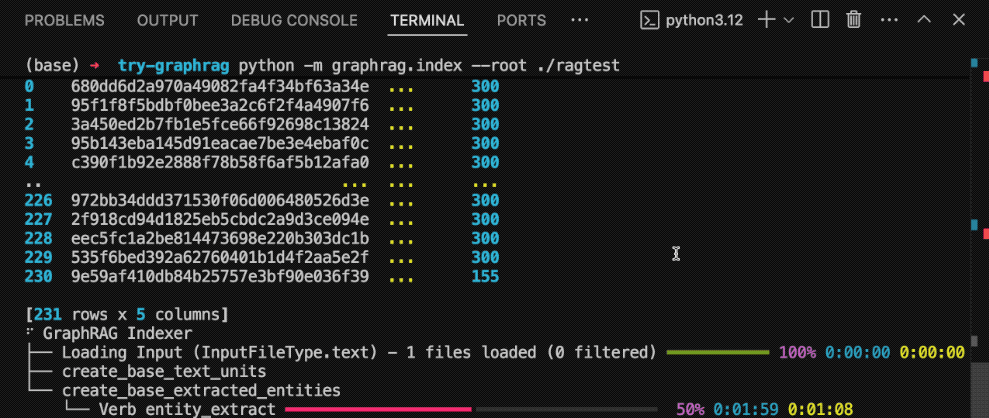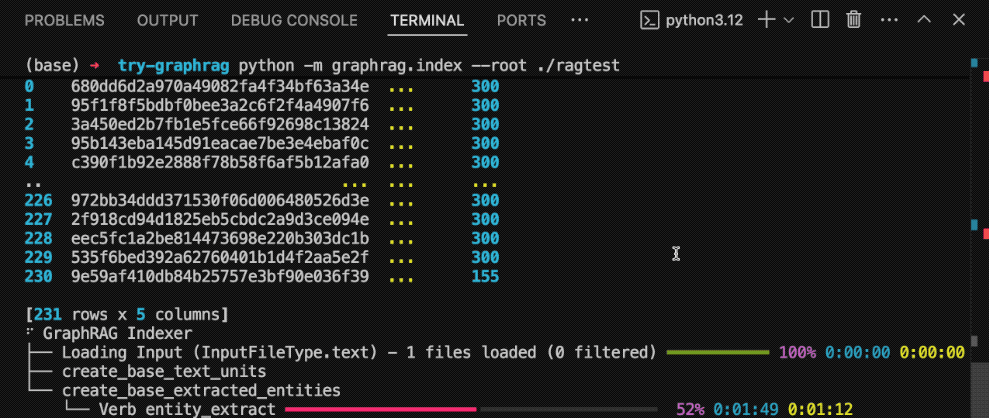
接下来我们来建立索引。回到终端,执行以下命令。
python -m graphrag.index --root ./ragtest
这条命令建立一个图谱化的知识库。这个过程花了足足五分钟的时间,咱们就不详细展示了。
查询
终于,图谱构建完毕。下面我们做一个查询。
python -m graphrag.query \ --root ./ragtest \ --method global \ "What are the top themes in this story?"
注意这里的命令,Global(全局)代表我对整本书提问。我们问的问题是:这个故事有哪些最主要的主题?
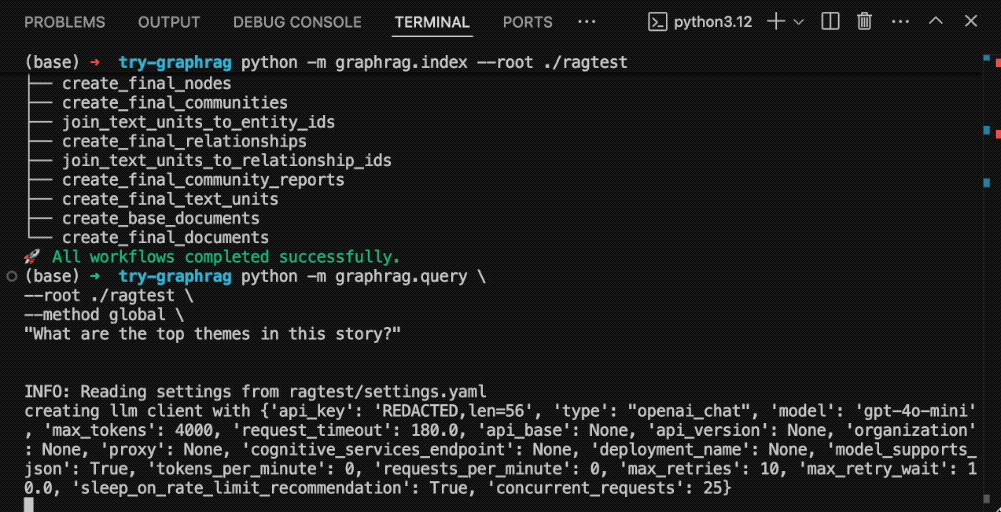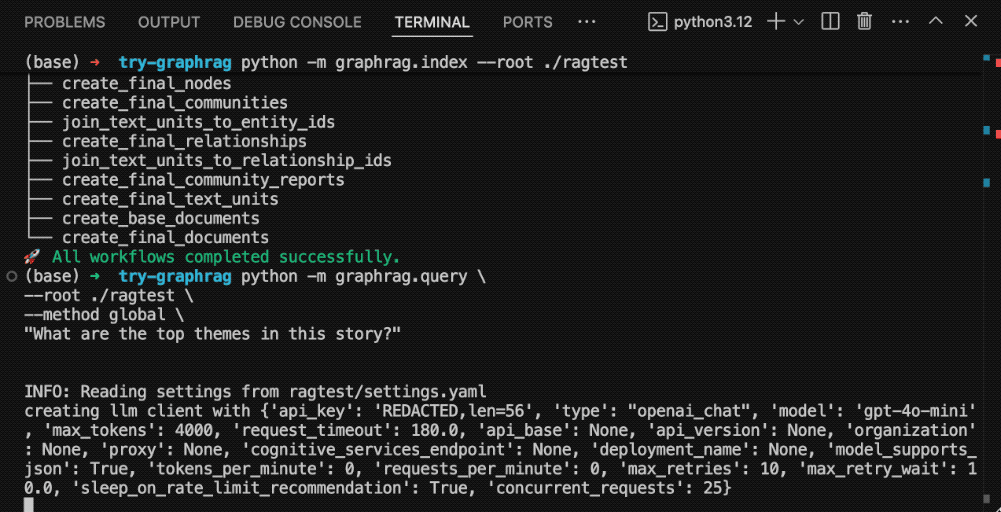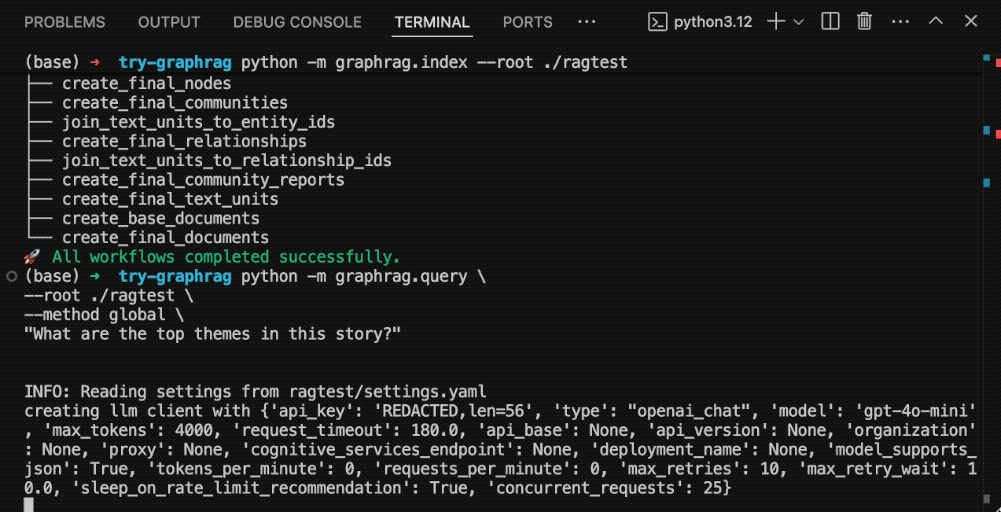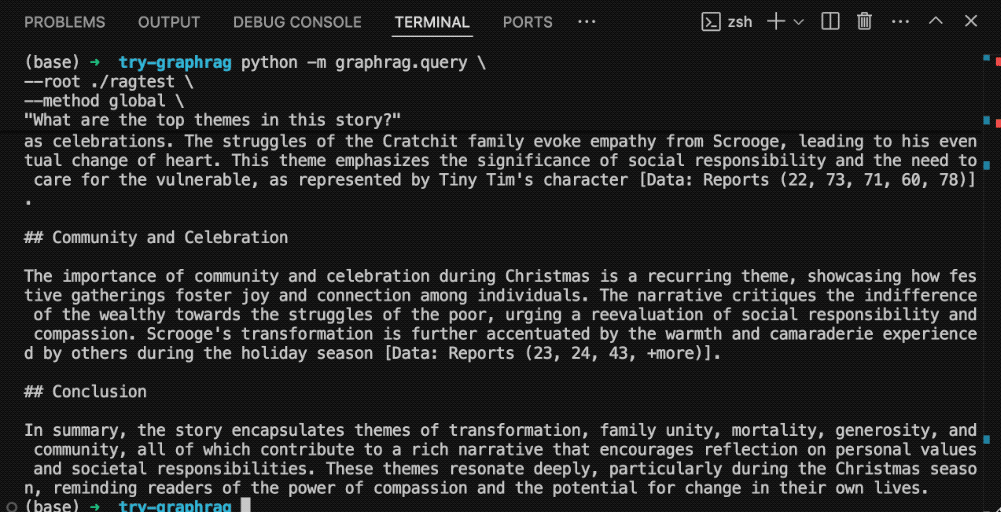
来看一下结果。

结果显示了若干主题,每个答案后面都有一系列的内容来源标号,这一点很重要。它强调了大语言模型没有幻觉,而确实是利用你提供的资料来给出答案。
为了让你看得更加清楚,我给你把上面的答案翻译一下。这里我们使用的是吴恩达老师的三步反思翻译法。
为了让 AI 工作流更加简单,我做了一个工具,并且开放在了 Github 上面,网址在这里。(https://github.com/wshuyi/workflows_with_litellm_pub)如果你觉得好用,别忘了给加颗星啊。
这个项目可以帮助我们快捷地执行工作流程。它包含了一系列预设的脚本和配置文件,使得我们能够轻松地设置环境、运行查询。
这个项目不仅可以提高效率,还能确保工作流程的一致性。你可以将复杂的工作流程简化为一个配置文件。这个文件可以清晰地定义每一个步骤,使得整个流程变得更加透明和可管理。
这就是一个配置文件的例子。
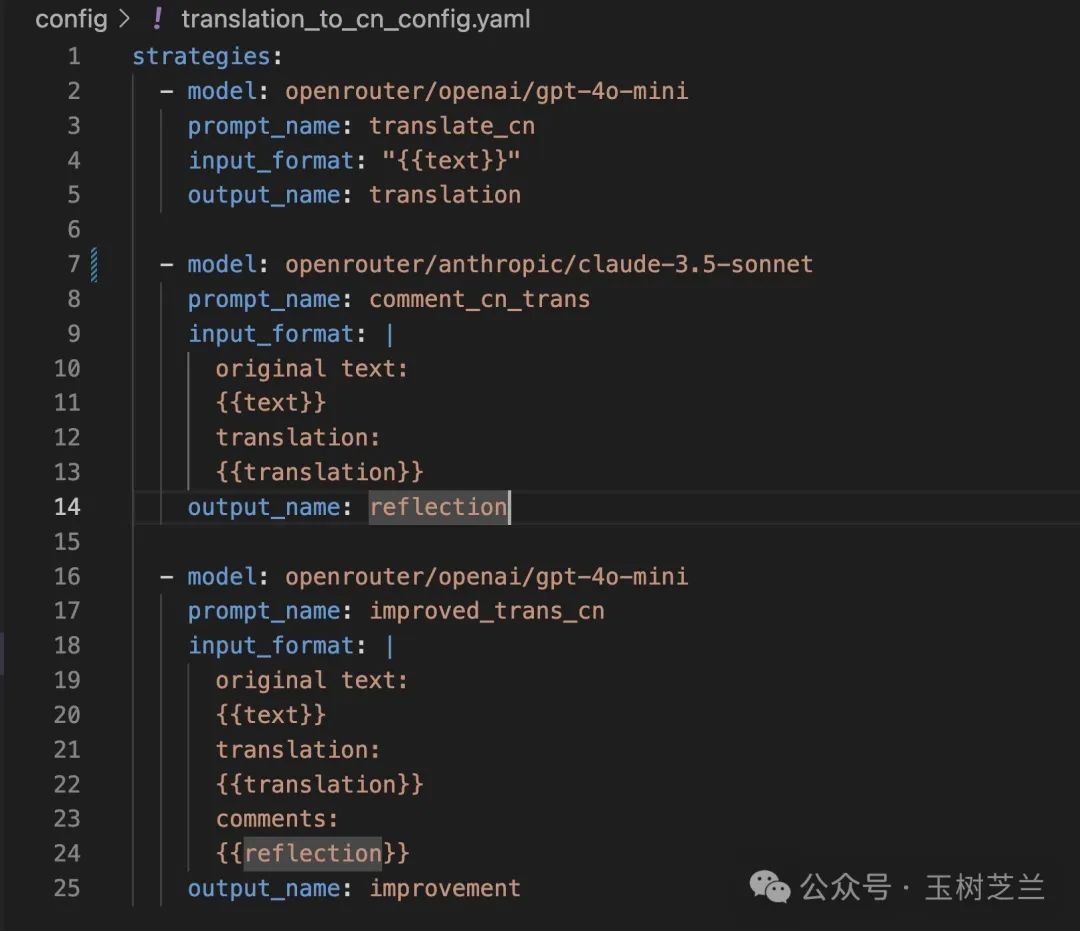
这里我说你要进行三步操作,这三步操作构成了一个完整的工作流程。
第一步是执行一个叫做 “翻译成中文”(translate_cn) 的工作提示词。这个步骤的目的是将输入的英文内容转换为中文。使用的输入来自于用户提供的信息,模型调用的还是 GPT-4o mini。
第二步是对刚才的翻译结果进行评价。这一步的目的是确保翻译的质量,通过客观的评价来识别可能存在的问题或改进空间。它的输入相对多一些,除了原文,还应该包括刚才第一步给出的直译结果。为了保证修改建议的有效性和可靠性,我们使用思辨能力更强的 Claude 3.5 Sonnet 模型。
第三步则是综合原文、直译和反思建议,进行精细翻译。这里我们还是使用 GPT-4o mini 模型,以降低成本,提升输出速度。
这种方法的优势在于它的灵活性和可定制性,你可以根据具体需求来调整每一步的提示词,从而优化整个工作流程。具体安装和使用方式,请参考《如何轻松定制和调用你自己的 AI 工作流》一文。

闲言少叙,我们来看翻译的结果。这个结果是经过我们刚才描述的三步工作流程处理后得到的。通过这个例子,你也可以直观看到工作流的效果。

验证
我们该不该相信这个结果?我觉得尽管在回答中,GraphRAG 给出了来源片段信息,但这还不够。
假设你根本就没有读过狄更斯的这本小说,该如何验证刚才给出的答案呢?
你可以写一个提示词:
你是一名资深英语文学教师,现在你就狄更斯小说 "A Christmas Carol" 提出来了一个问题 "What are the top themes in this story?",下面我提供给你的文档,是一个学生的回答。请你根据你对这本小说的理解,一段段核对,看答案是否有事实性错误,以及是否有可改进的地方
然后,把这个提示词,连同刚刚 GraphRAG 给出的结果(英文即可)交给 Claude 3.5 Sonnet 。
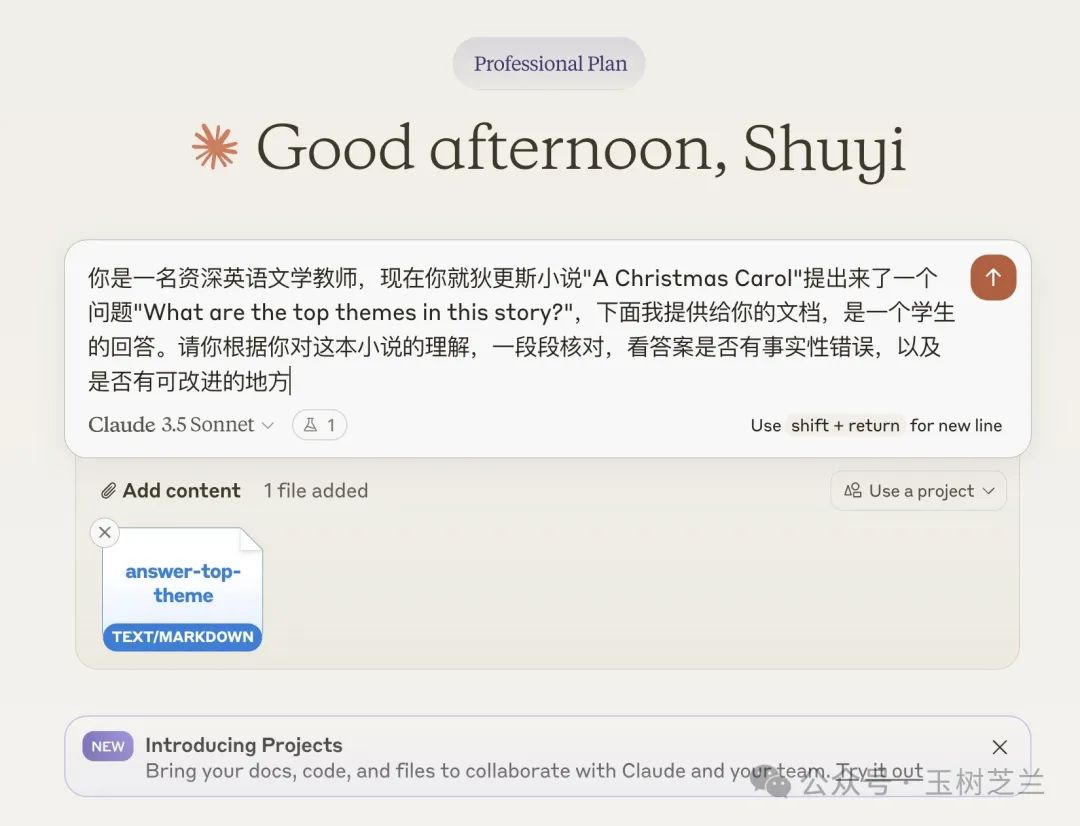
然后,这是 Claude 3.5 Sonnet 给出的回答质量分析结果。让我们来看看它的评价。

Claude 3.5 Sonnet 给出总体评价:这是一个非常优秀的分析。这个结果证明了我们利用知识图谱进行检索的方法非常有效。到此为止,我们是否可以完全相信这个答案呢?
当然不行。
刚才看到的是大语言模型基于自己训练时对数据的记忆得出的结果,这依然可能会产生幻觉。因此,我们需要让 AI 连接网络进行查询,以验证信息的准确性。
在这方面,一个比较好的工具就是 Perplexity。它能够网络查询,验证信息的准确性。
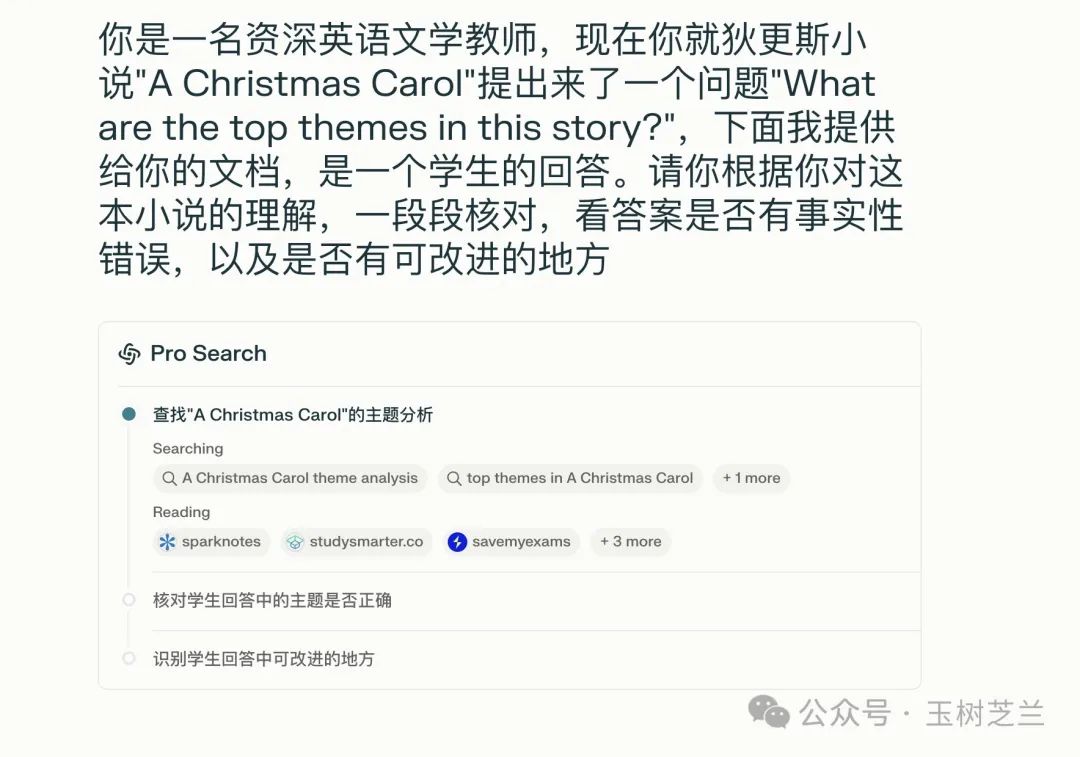
首先,Perplexity 会查找与输入内容相关的信息,列出了多个相关的信息来源。然后,Perplexity 会核对主题识别的准确性。

在 Perplexity 的分析中,你可以看到它使用了这些词语来评价:准确地捕捉、准确地识别、很好的捕捉,准确地指出、很好的总结。它还指出没有明显的事实性错误,主题的选择和分析都很到位。
通过这两种方法的交叉验证,我们对大语言模型根据我们的图谱式知识库给出的答案就更有信心了。
成本
使用这种方法的成本如何呢?
我打开 OpenAI 控制台查看,一开始吓了一跳 —— 今天的账单又起飞了?
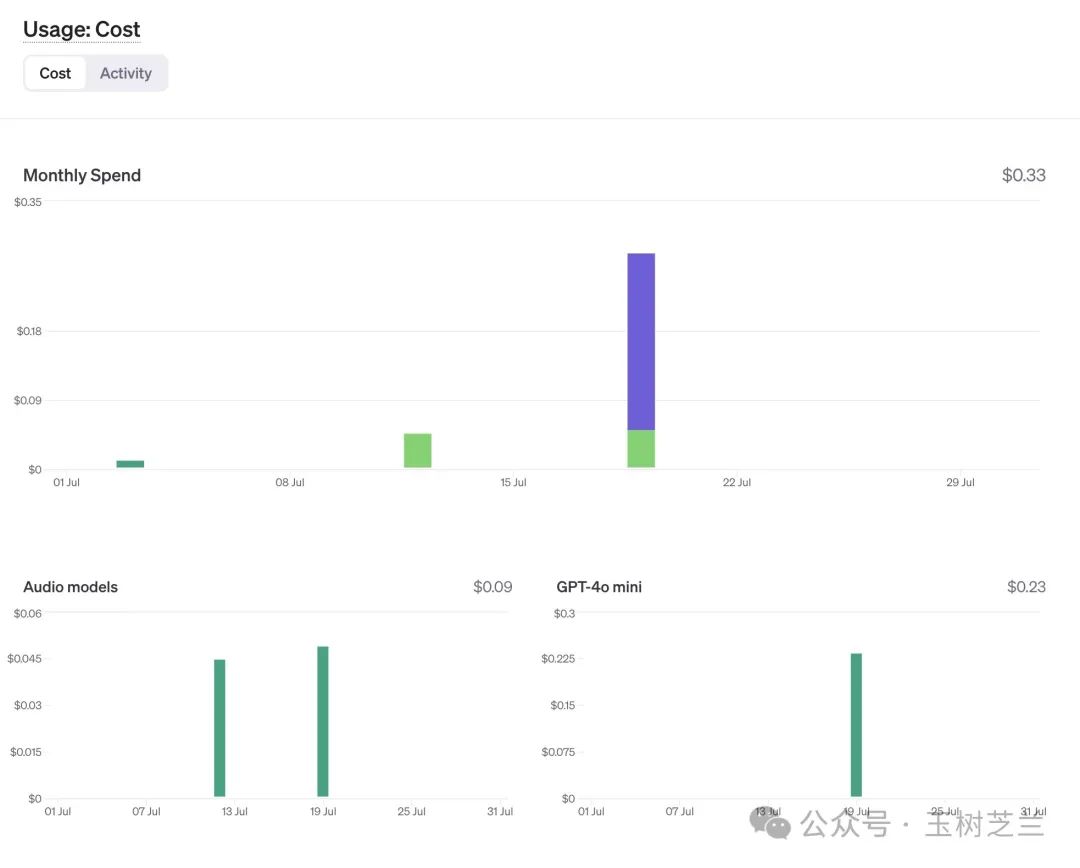
好在仔细一看,实际花费仅仅 0.28 美金。下面是明细。
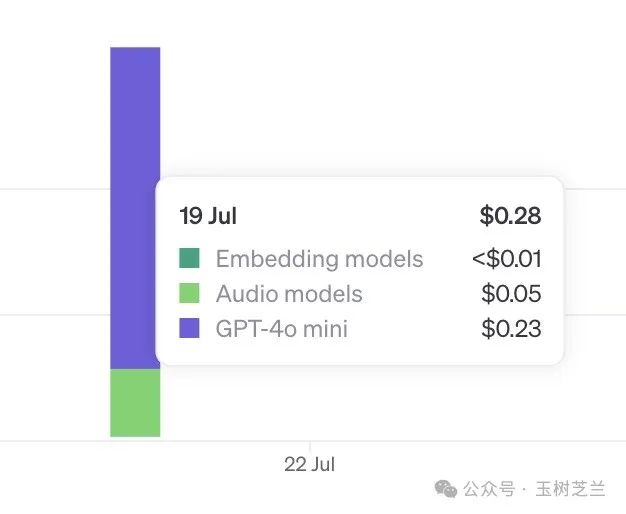
有 0.05 美金(将近五分之一)是用于语音识别的,这与我们当前的任务无关。
换句话说,我们用于总结这本书、构建知识图谱型知识库,以及进行查询的实际花费是多少呢?仅需要 0.23 美金。
考虑到使用官方样例花费 11 美金,你会发现 GPT-4o mini 带来的成本改善令人惊叹。
小结
通过本文的讲解,你可以发现 GraphRAG 技术能帮助我们更准确地回答全局性的复杂问题,这对许多应用场景来说至关重要。
进一步,结合 GPT-4o mini 模型,我们不仅提高了处理效率和速度,还有效降低了成本。对于个人用户、研究人员和企业来说,这都是一个好消息。
自己动手试一试吧,欢迎你把自己的测试结果分享在留言区,咱们一起交流讨论。
祝基于知识图谱的 AI 知识库使用愉快!
点赞 +「在看」,转发给你身边有需要的朋友。收不到推送?那是因为你只订阅,却没有加星标。
欢迎订阅我的小报童付费专栏,每月更新不少于3篇文章。订阅一整年价格优惠。

如果有问题咨询,或者希望加入社群和热爱钻研的小伙伴们一起讨论,订阅知识星球吧。不仅包括小报童的推送内容,还可以自由发帖与提问。之前已经积累下的帖子和问答,就有数百篇。足够你好好翻一阵子。知识星球支持72小时内无条件退款,所以你可以放心尝试。

若文中部分链接可能无法正常显示与跳转,可能是因为微信公众平台的外链限制。如需访问,请点击文末「阅读原文」链接,查看链接齐备的版本。
延伸阅读
开发文档 RAG 的 GPTs 如何更高效地帮你 AI 编程?
如何用人工智能帮你读论文?
文科生用机器学习做论文,该写些什么?
如何用人工智能帮你高效寻找研究选题?
如何用人工智能帮你找论文?








![BUU [BSidesCF 2020]Cards](https://img-blog.csdnimg.cn/img_convert/fc815173b45648d2acce81deaf088f2b.png)