文章目录
- 一、urllib
- 1. urlparse 实现 URL 的识别和分段
- 2. urlunparse 用于构造 URL
- 3. urljoin 用于两个链接的拼接
- 4. urlencode 将 params 字典序列化为 params 字符串
- 5. parse_qs 和 parse_qsl 用于将 params 字符串反序列化为 params 字典或列表
- 6. quote 和 unquote 对 URL的中文字符进行编码和解码
- 二、requests
- 1. GET 请求
- 2. POST 请求
- 3. Session 维持
- 4. 响应
- 5. 身份认证
- 6. 设置代理
- 7. Prepared Request
- 三、httpx
- 1. Requests Compatibility
- 2. 异步
- 四、基础爬虫实战
一、urllib
urllib 类似于 python 底层构建请求,构建相对于其他的库来说较为复杂,不过 urllib 解析链接非常好用
1. urlparse 实现 URL 的识别和分段
如果需要合并 params 和 query 可以使用 urlsplit
from urllib.parse import urlparse
urlparse('https://www.baidu.com/')
# ParseResult(scheme='https', netloc='[www.baidu.com](https://www.baidu.com/)', path='/', params='', query='', fragment='')
2. urlunparse 用于构造 URL
urlunparse 这个方法接收的参数是一个可迭代对象,且其长度必须为 6;同样的,如果需要合并 params 和 query 可以使用 urlunsplit
from urllib.parse import urlunparse
data = ['https','www.baidu.com','index.html','user','a=6','comment']
urlunparse(data)
# https://www.baidu.com/index.html;user?a=6#comment
3. urljoin 用于两个链接的拼接
urljoin 首先会解析 new_url,判断其 scheme,netloc,path 是否出现了缺失,如果确实使用 base_url 中的 scheme,netloc,path 对应缺失部分代替;
from urllib.parse import urljoin
base_url = 'https://www.baidu.com'
new_url = 'FAQ.html'
urljoin(base_url, new_url)
# https://www.baidu.com/FAQ.html
4. urlencode 将 params 字典序列化为 params 字符串
from urllib.parse import urlencode
params = {
'name': 'germey',
'age': 2,
}
base_url = 'https://www.baidu.com?'
base_url + urlencode(params)
# https://www.baidu.com?name=germey&age=2
5. parse_qs 和 parse_qsl 用于将 params 字符串反序列化为 params 字典或列表
from urllib.parse import parse_qs, parse_qsl
params = 'name=germey&age=25'
parse_qs(params, separator='&')
# {'name': ['germey'], 'age': ['25']}
parse_qsl(params, separator='&')
[('name', 'germey'), ('age', '25')]
6. quote 和 unquote 对 URL的中文字符进行编码和解码
from urllib.parse import quote, unquote
url = "https://www.baidu.com/s?wd=爬虫"
# utf8编码,指定安全字符
quote(url, safe=";/?:@&=+$,", encoding="utf-8")
# https://www.baidu.com/s?wd=%E7%88%AC%E8%99%AB
# gbk编码,指定安全字符
quote(url, safe=";/?:@&=+$,", encoding="gbk")
# https://www.baidu.com/s?wd=%C5%C0%B3%E6
# utf8解码
unquote('https://www.baidu.com/s?wd=%E7%88%AC%E8%99%AB', encoding='utf-8')
# https://www.baidu.com/s?wd=爬虫
# gbk解码
unquote('https://www.baidu.com/s?wd=%C5%C0%B3%E6', encoding='gbk')
# https://www.baidu.com/s?wd=爬虫
二、requests
1. GET 请求
测试 URL: www.httpbin.org/get
cookies 可以单独设置,也可以放在 headers 的 cookie 字段下传入请求之中,timeout 可以控制超时时间,headers 是请求头,params 是参数构建完整的 url;
import requests
params = {}
headers = {}
cookies = {}
# vertify 设置为 False 可以避免 ssl 认证
requests.get(url=url, params=params, headers=headers, cookies=cookies, vertify=False, timeout=None)
2. POST 请求
测试 URL: www.httpbin.org/post
POST 是上传东西的常用请求,POST 请求中除了 GET 请求中的那些参数,还有一些参数可以使用,如 data 和 file;其中 data 主要用来传表单,而 file 主要用来传文件;
import requests
params = {}
headers = {}
cookies = {}
data = {}
file = {}
# vertify 设置为 False 可以避免 ssl 认证
requests.post(url=url, params=params, headers=headers, cookies=cookies, vertify=False, timeout=None, data=data, file=file)
3. Session 维持
多次直接利用 requests 库中的 get 或 post 方法模拟网络请求,相当于打开了多个不同的浏览器,而使用 Session 维持 搭配 get 和 post 方法去模拟网络请求,相当于打开了一个浏览器中的多个页面;
import requests
s = requests.Session(headers=headers)
s.get(url_1)
s.get(url_2)
# 这里在第一次 get 请求中获得到的 cookie 就会保持进而在第二次 get 请求中得到
4. 响应
import requests
resp = requests.get()
# 状态码
resp.status_code
# 响应头
resp.headers
# cookies
resp.cookies
# 最终 url 搭配重定向使用 requests.get(url, allow_redirects=False)
resp.url
# 请求历史
resp.history
# 在获取 resp.text 先配置 encoding
resp.encoding
# 响应结果字符串形式,需要搭配 resp.encoding = 'utf-8' or 'gbk' 使用
resp.text
# 二进制相应结果,通常对应于文件
resp.content
# resp.text 转化为 json 数据,如果不是json 数据格式,则会出现解析错误,抛出 json.decoder.JSONDecodeError 异常
resp.json
5. 身份认证
在访问启用了基本身份认证的网站时,首先会弹出一个认证窗口,认证正确会弹出 200状态码,如果认证错误或者不进行认证会弹出 401 错误;
import requests
from requests.auth import HTTPBasicAuth
# 第一行是第二行的简写
r = requests.get('https://ssr3.scrape.center/',auth=('admin','admin'))
r = requests.get('https://ssr3.scrape.center/',auth=HTTPBasicAuth('admin','admin'))
r.status_code
# 200
requests 库还提供了其他的认证方式,如 OAuth 认证,需要安装 oauth 包;
6. 设置代理
首先是基本的 HTTP 代理
import requests
proxies = {
'http':'http://10.10.10,10:1080',
'https':'https://10.10.10.10:1080',
}
requests.get('https://www.httpbin.org/get', proxies=proxies)
除了基本的 HTTP 代理外,还支持 SOCKS 协议的代理,首先需要安装 socks 库 pip install requests[socks]
import requests
proxies = {
'http':'socks5://10.10.10,10:1080',
'https':'socks5://10.10.10.10:1080',
}
requests.get('https://www.httpbin.org/get', proxies=proxies)
7. Prepared Request
因此多个 get 或者 post 请求相当于多个 Session,尽量避免对同一网页使用多个 get 或者 post 请求
from requests import Request,Session
url = 'https://www.httpbin.org/post'
data = {'name':'germey'}
headers = {}
# 请求的底层
s = Session()
req = Request('POST', url, data=data, headers=headers)
prepped = s.prepare_request(req)
r = s.send(prepped)
# 等价
r = requests.post(url, data=data, headers=headers)
三、httpx
HTTPX 建立在 requests 完善的可用性之上,支持 HTTP/2 并支持异步;HTTPX (python-httpx.org)
可选安装如下:
h2- HTTP/2 支持。 (可选,带有httpx[http2])socksio- SOCKS 代理支持。 (可选,带有httpx[socks])brotli或brotlicffi- 解码“brotli”压缩响应。 (可选,带有httpx[brotli])
HTTPX 与 requests 的 API 广泛兼容,在少部分地方存在一些设计差异:Requests Compatibility - HTTPX (python-httpx.org)
1. Requests Compatibility
重定向:与 requests 不同,HTTPX 默认情况下是不遵循 重定向 (redirects) 的,开启重定向如下所示
client = httpx.Client(follow_redirects=True)
response = client.get(url, follow_redirects=True)
Client:等价于 requests.Session 维持,即等价
session = requests.Session(**kwargs)
client = httpx.Client(**kwargs)
URL:访问 response.url 将返回 url 实例,requests 返回的是字符串
重定向请求:requests 库公开了一个属性 response.next ,该属性可用于获取下一个重定向请求。在 HTTPX 中,此属性被命名为 response.next_request 。
# requests
session = requests.Session()
request = requests.Request("GET", ...).prepare()
while request is not None:
response = session.send(request, allow_redirects=False)
request = response.next
# httpx
client = httpx.Client()
request = client.build_request("GET", ...)
while request is not None:
response = client.send(request)
request = response.next_request
请求内容:对于上传原始文本或二进制内容,httpx 使用 content 参数,以便更好地将这种用法与上传表单数据的情况分开。使用 content=... 上传原始内容,并使用 data=... 发送表单数据;
httpx.post(..., content=b"Hello, world")
httpx.post(..., data={"message": "Hello, world"})
上传文件:HTTPX 严格强制上传文件必须以二进制模式打开,以避免尝试上传以文本模式打开的文件可能导致的字符编码问题。
内容编码:HTTPX 使用 utf-8 来编码 str 请求正文。例如,当使用 content=<str> 时,请求正文将在通过线路发送之前编码为 utf-8 。
Cookie,trust_env 、 verify 和 cert 参数:如果使用客户端实例,应始终在客户端实例化时传递,而不是传递给请求方法。
2. 异步
requests 是不支持异步的,通常我们会使用 aiohttp 来进行异步操作,而 httpx 不仅支持同步还支持异步
import asyncio
import httpx
async def main():
async with httpx.AsyncClient() as client:
response = await client.get('https://www.example.com/')
print(response)
asyncio.run(main())
四、基础爬虫实战
任务:
- 使用爬虫基本库爬取 https://ssr1.scrape.center/ 每一页的电影列表,顺着列表再爬取每个电影的详细页
- 使用正则表达式提取每部电影的名称,封面,类别,上映时间,剧情简介等内容;
- 使用多进程实现爬取的加速;
流程:
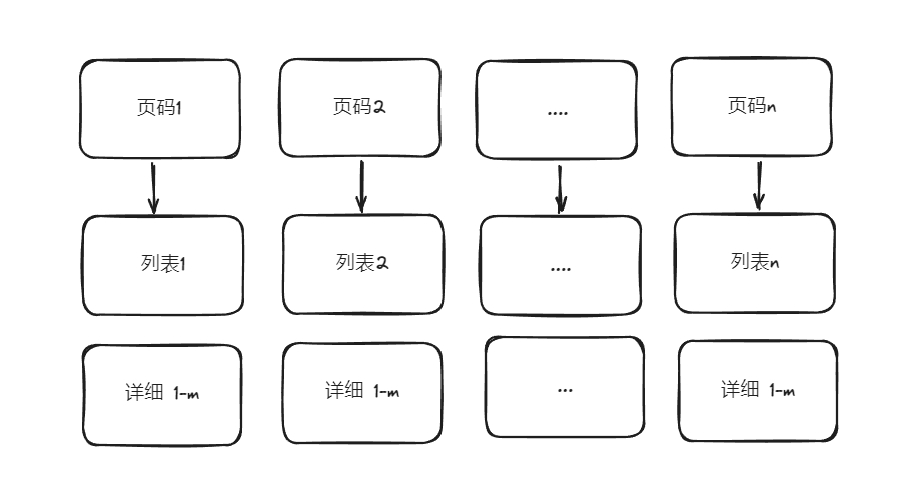
代码:
import os
import re
import httpx
import json
from multiprocessing import Pool
from urllib.parse import urljoin
base_url = "https://ssr1.scrape.center"
def scrape_index(page):
"""获得page的url"""
page_url = f"{base_url}/page/{page}"
return page_url
def scrape_list(html):
"""获得列表的url"""
url_list = re.findall(r'<a data.* href="(.*)" class="name">', html)
url_list = [urljoin(base_url, item) for item in url_list]
return url_list
def scrape_detail(html):
"""获得详细页信息"""
detail_dic = {}
detail_dic["名称"] = (
re.search(r'<h2 data.*? class="m-b-sm">(.*?)</h2>', html, re.S).group(1)
if re.search(r'<h2 data.*? class="m-b-sm">(.*?)</h2>', html, re.S)
else None
)
detail_dic["封面"] = (
re.search(
r'class="item.*?<img.*?src="(.*?)".*?class="cover">', html, re.S
).group(1)
if re.search(r'class="item.*?<img.*?src="(.*?)".*?class="cover">', html, re.S)
else None
)
detail_dic["类别"] = re.findall(
r"<button.*?category.*?<span>(.*?)</span>.*?</button>", html, re.S
)
detail_dic["上映时间"] = (
re.search(r"<span>.*?(\d{4}-\d{2}-\d{2}) 上映", html, re.S).group(1)
if re.search(r"<span>.*?(\d{4}-\d{2}-\d{2}) 上映", html, re.S)
else None
)
detail_dic["剧情简介"] = (
re.search(r"剧情简介</h3>.*?<p.*?>(.*?)</p>", html, re.S).group(1).strip()
if re.search(r"剧情简介</h3>.*?<p.*?>(.*?)</p>", html, re.S)
else None
)
return detail_dic
def validateTitle(title):
"""命名规范性"""
rstr = r"[\/\\\:\*\?\"\<\>\|]" # '/ \ : * ? " < > |'
new_title = re.sub(rstr, "_", title) # 替换为下划线
return new_title
def save_json(detail_dic):
"""保存数据到json文件夹下"""
os.makedirs("./json", exist_ok=True)
name = detail_dic["名称"]
data_path = f"./json/{validateTitle(name)}.json"
json.dump(
detail_dic, open(data_path, "w", encoding="utf-8"), ensure_ascii=False, indent=2
)
def main(page):
client = httpx.Client()
page_url = scrape_index(page)
resp_page = client.get(page_url).text
url_list = scrape_list(resp_page)
for detail_url in url_list:
resp_detail = client.get(detail_url).text
detail_dic = scrape_detail(resp_detail)
save_json(detail_dic)
if __name__ == "__main__":
pool = Pool(10)
pages = range(1, 10 + 1)
pool.map(main, pages)
pool.close()
pool.join()
得到结果如下: