前言
llama3 刚出来时,其长度只有8K对于包括我司在内的大模型开发者是个小小的缺憾,好在很快,在7.23日,Meta发布了Llama 3.1,其意义在于
- 很明显,随着llama的影响力越来越大,Meta想让llama类似Linux一样,成为开发者的行业标准(毕竟,正如Zuckerberg所说,Linux 已成为云计算和运行大多数移动设备的操作系统的行业标准基础)
- 长度终于达到了128K,这个长度使得可以直接通过我司的paper-review数据集去微调了
如此,便有了本文:解读下llama3.1的paper,结果一看92页,好在昨天我司上线了基于大模型的翻译系统,那先翻译一下 快速看下大概 然后慢慢抠
第一部分 Meta推出llama3.1:8B和70B版本都均超越同等尺寸的其他开源模型
7月23日,Meta推出了llama3.1,其405B的版本可以与GPT4正面干(可能是目前唯一一个可以与GPT4全方位分庭抗礼的开源模型),而其8B和70B版本都均超越同等尺寸的其他开源模型

1.1 模型架构、指令微调
1.1.1 模型架构:仅解码器的transformer、直接偏好优化、GQA
为了更好的理解llama3.1,我们先来回顾下我之前介绍过的llama3(来自此文一文速览Llama 3:从Llama 3的模型架构到如何把长度扩展到100万的第一部分)
和Llama 2一样,Llama 3 继续采用相对标准的decoder-only transformer架构,但做了如下几个关键的改进
- Llama 3 使用具有 128K tokens的tokenizer
相当于,一方面,分词器由 SentencePiece 换为了 Tiktoken,与 GPT4 保持一致,可以更有效地对语言进行编码
二方面,Token词表从LLAMA 2的32K拓展到了128K
基准测试显示,Tiktoken提高了token效率,与 Llama 2 相比,生成的token最多减少了 15%「正由于llama3具有更大的词表,比llama2的tokenizer具有更大的文本压缩率,所以你会看到在此文《从提升大模型数据质量的三大要素(含审稿GPT第4.6版、第4.8版、第5版)到Reviewer2的实现》中,我司七月审稿项目组发现,在统计同样的paper-review数据集时,llama3统计到的token数更少」- 为了提高推理效率,Llama 3在 8B 和 70B 都采用了分组查询注意力(GQA),根据相关实验可以观察到,尽管与 Llama 2 7B 相比,模型的参数多了 1B,但改进的分词器效率和 GQA 有助于保持与 Llama 2 7B 相同的推理效率
值得指出的是,上一个版本的llama 2的34B和70B才用到了GQA「详见LLaMA的解读与其微调(含LLaMA 2):Alpaca-LoRA/Vicuna/BELLE/中文LLaMA/姜子牙的第3.2节LLaMA2之分组查询注意力——Grouped-Query Attention」
- 在 8,192 个token的序列上训练模型,且通过掩码操作以确保自注意力不会跨越文档边界
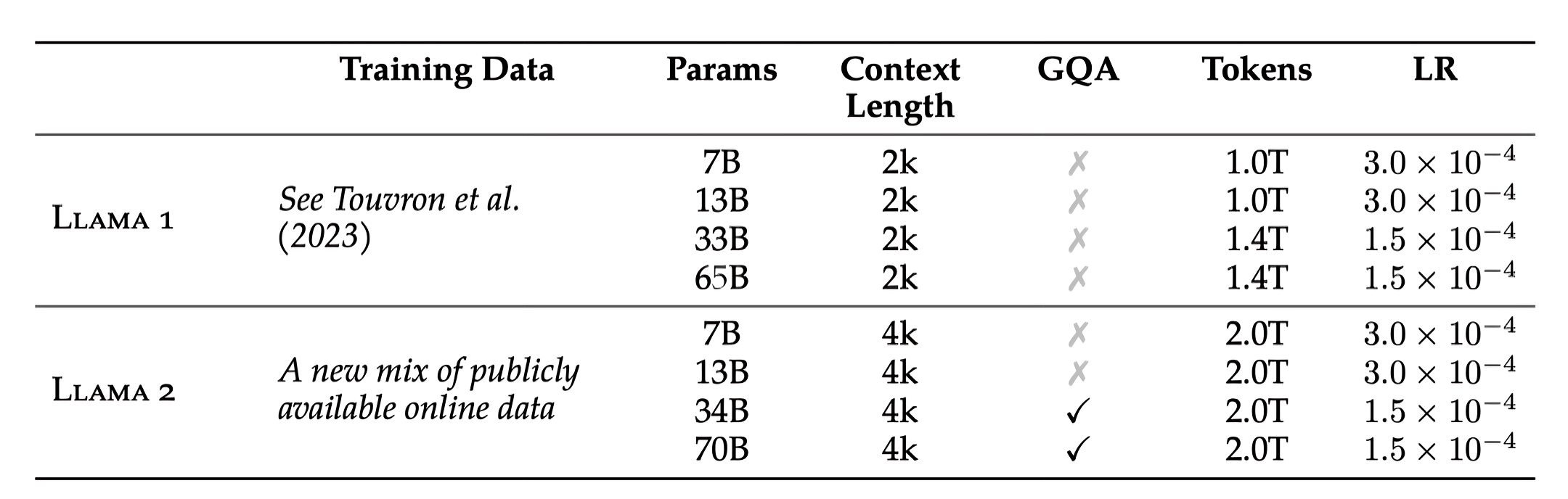
本次的llama3.1 无论哪个尺寸,都和llama3一样,都选择的标准的仅解码器的变压器模型架构,并进行了细微的改动,而不是混合专家模型

此外

- 在词汇表上
与llama3一样,使用了一个包含128Ktoken的词汇表,这个token词汇表结合了来自 tiktoken3的100K token和28K额外token,以更好地支持非英语语言
与Llama 2 tokenizer相比,llama3或3.1的新tokenizer在一组英语数据上的压缩率从每个token的17个字符提高到94个字符,这使得模型能够在相同的训练计算量下“读取”更多文本
且使用一种注意力掩码,以防止在同一序列内不同文档之间的自注意力 - 在注意力机制上
与llama3一样,也使用了GQA,且是32个注意力头(相当于32个query头)、8个键值头(8个key/value头,意味着query头数是key/value头的4倍,与下图中间部分所示的query头数是key/value头数的2倍,不一样)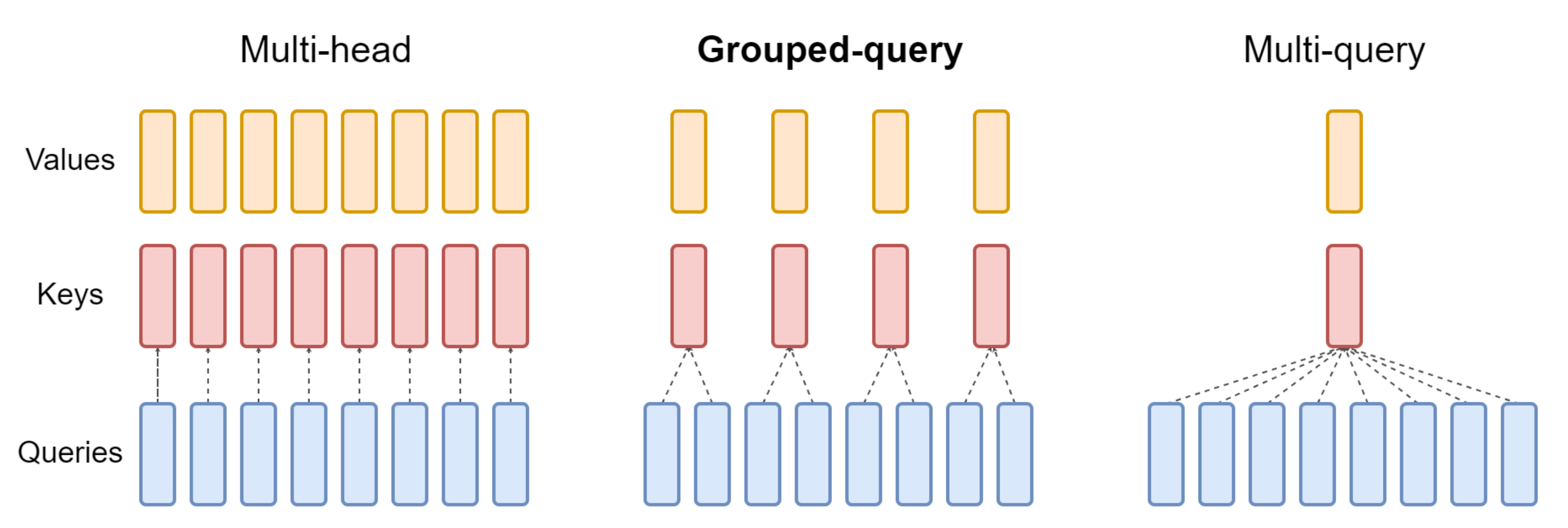
- 在模型长度上
将RoPE基频超参数提高到500,000,这使得llama3.1能够更好地支持更长的上下文「Xiong等人(2023)表明这个值对于上下文长度达到32,768是有效的」
这点其实就是我之前在这篇文章《一文速览Llama 3:从Llama 3的模型架构到如何把长度扩展到100万》第二部分的所介绍过的
而对于Llama 3 405B 使用了一个具有 126 层、16,384 的token表示维度和 128 个注意力头的架构,且他们为了支持 405B 规模模型的大规模生产推理,将模型从 16 位 (BF16) 量化为 8 位 (FP8) 数字,有效降低了所需的计算要求并允许模型在单个服务器节点内运行
1.1.2 指令和chat微调:组合SFT、RS、DPO
借助 Llama 3.1 405B,我们努力提高模型对用户指令的响应能力、质量和详细指令遵循能力,同时确保高水平的安全性。我们面临的最大挑战是支持更多功能、128K 上下文窗口和更大的模型大小。
在后期训练中,通过在预训练模型的基础上进行几轮对齐来生成最终的聊天模型。每轮都涉及监督微调 (SFT)、拒绝抽样 (RS) 和直接偏好优化 (DPO)
// 待更
第二部分 通过我司7方面review的paper-review数据集微调llama3.1 8B
// 待更



















