Elasticsearch 是什么?
Elasticsearch 是一个高度可扩展的开源全文搜索和分析引擎。它允许你以极快的速度存储、搜索和分析大量数据。Elasticsearch 基于 Apache Lucene 构建,提供了一个分布式、多租户能力的全文搜索引擎,带有 HTTP web 接口和无模式 JSON 文档。这意味着你可以用 Elasticsearch 存储、搜索、分析的数据种类非常广泛,几乎可以适用于任何类型的用例。
当项目中需要使用到搜索查询功能时,光靠MySqld的模糊查询就显得心有余而力不足了,模糊查询的匹配要求非常严格,需要搜索结果中必须带有相关关键字,而且当搜索量大了之后,使用MySql进行大量的查询操作效率也会大打折扣。而在Elasticsearch 搜索引擎中,用户输入出现个别错字,或者用拼音搜索、同义词搜索都能正确匹配到数据。
Elasticsearch 安装
基于docker环境下的安装命令:
docker run -d \
--name 容器名 \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network 网络名 \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:版本号kibana安装
kibanna用于图形化展示Elasticsearch,可以对Elasticsearch进行控制台操作:
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network 网络名 \
-p 5601:5601 \
kibana:7.12.1倒排索引和正向索引
正向索引机制
在讨论数据库(如MySQL)的查询优化时,重要的是要理解索引的作用及其在模糊查询中的局限性。例如,当对数据库中某一张拥有成千上万条数据的表进行模糊查询时,如使用SQL的LIKE语句,查询性能可能受到影响。假设我们对该表的一个字段使用模糊查询,可能使用类似LIKE '%关键字%'的查询条件。即使查询的第一条记录就是我们需要找的数据,查询操作并不会因此停止。原因在于数据库系统需要找出所有匹配的记录,而不仅仅是第一条匹配的记录。因此,系统不得不继续扫描整张表,以确保没有遗漏任何符合条件的数据。
这种查询效率不高的原因部分在于,标准索引主要优化了精确匹配或范围查询的性能。对于以通配符开始的模糊查询(例如LIKE '%关键字%'),标准索引往往无法被有效利用,因为这违背了索引设计的预期使用方式。
倒排索引机制
倒排索引(Inverted Index)是一种数据库索引方式,它与前面讨论的正向索引或数据库中常用的标准索引不同。倒排索引在文档检索系统,如搜索引擎,以及在一些特定类型的数据库优化中非常关键。它的主要思想是根据文档内容中出现的词汇来建立索引,而不是文档到词汇的映射,这与正向索引正相反。
倒排索引主要由两个部分组成:一是词表(Term List),二是倒排列表(Inverted List)。词表中包含了所有文档中出现的词汇,而对于每个词汇,倒排列表则记录了该词汇出现在哪些文档中,通常还包括词在文档中出现的位置、频率等信息。
也就是说倒排索引会将每个文档中出现的词汇提取出来,记录于倒排列表之中,当查询时,直接根据查询输入中的词汇去找相关词汇的倒排列表记录,就可以直接找到有记录相关词汇的文档了,而不必向正向索引一样每次查询都遍历全表。
倒排索引最典型的应用是在搜索引擎中,它使得用户能在短时间内从互联网的海量信息中找到所需的内容。此外,在一些特定的数据库产品中,特别是那些面向文本检索的数据库系统,也广泛采用倒排索引来优化查询性能和存储效率。
总体而言,倒排索引因其特有的结构和优势,成为了处理大规模文本数据,特别是搜索和文本分析领域的重要技术之一。
那么为什么一个叫做正向索引,一个叫做倒排索引呢?
-
正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
-
而倒排索引则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
正向索引:
-
优点:
-
可以给多个字段创建索引
-
根据索引字段搜索、排序速度非常快
-
-
缺点:
-
根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描。
-
倒排索引:
-
优点:
-
根据词条搜索、模糊搜索时,速度非常快
-
-
缺点:
-
只能给词条创建索引,而不是字段
-
无法根据字段做排序
-
文档和字段
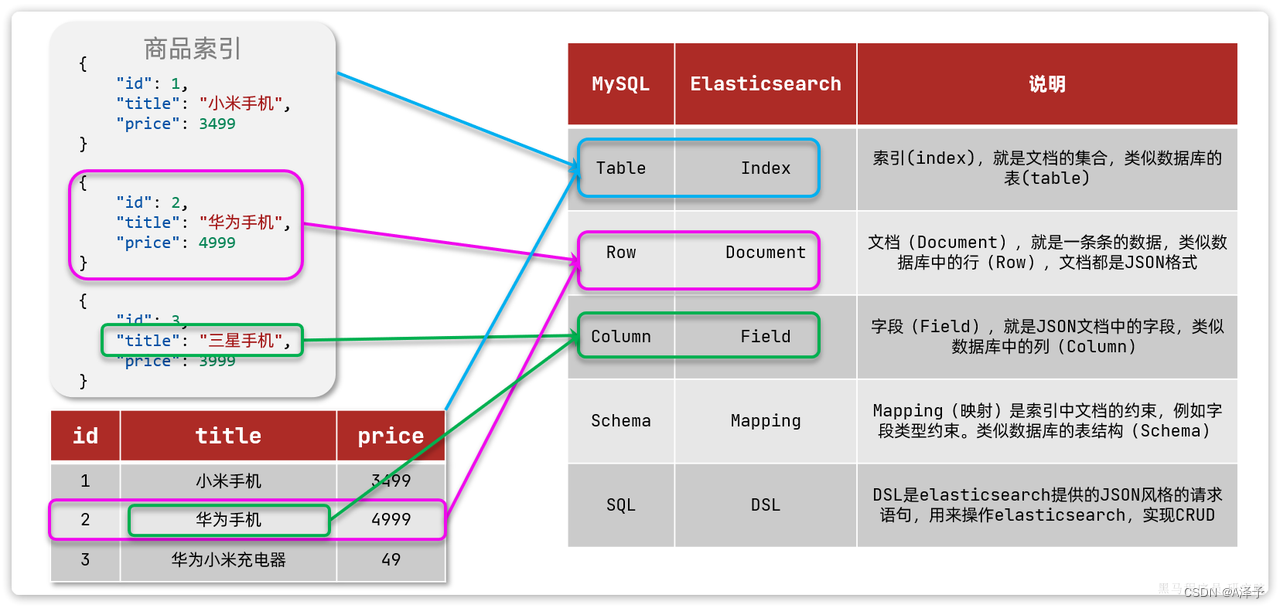
elasticsearch是面向文档(Document)存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中:

因此,原本数据库中的一行数据就是ES中的一个JSON文档;而数据库中每行数据都包含很多列,这些列就转换为JSON文档中的字段(Field)。
索引和映射
随着业务发展,需要在es中存储的文档也会越来越多,比如有商品的文档、用户的文档、订单文档等等。
所有文档都散乱存放显然非常混乱,也不方便管理。
因此,我们要将类型相同的文档集中在一起管理,称为索引(Index)。
例如:
商品索引
{
"id": 1,
"title": "小米手机",
"price": 3499
}
{
"id": 2,
"title": "华为手机",
"price": 4999
}
{
"id": 3,
"title": "三星手机",
"price": 3999
}用户索引
{
"id": 101,
"name": "张三",
"age": 21
}
{
"id": 102,
"name": "李四",
"age": 24
}
{
"id": 103,
"name": "麻子",
"age": 18
}-
所有用户文档,就可以组织在一起,称为用户的索引;
-
所有商品的文档,可以组织在一起,称为商品的索引;
因此,我们可以把索引当做是数据库中的表。
数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。因此,索引库中就有映射(mapping),是索引中文档的字段约束信息,类似表的结构约束。
mysql与elasticsearch
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
IK分词器
Elasticsearch的关键就是倒排索引,而倒排索引依赖于对文档内容的分词,而分词则需要高效、精准的分词算法,IK分词器就是这样一个中文分词算法。
安装Ik分词器
方法一
下载好分词器,然后上传到Elasticsearch挂载的插件目录。
方法二
在线安装,运行命令,然后重启容器:
docker exec -it es ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zipIK分词器的使用
IK分词器包含两种模式:
-
ik_smart:智能语义切分 -
ik_max_word:最细粒度切分
只需要在创建索引库时指定"analyzer"字段的值为IK分词器,相当于告诉Elasticsearch用什么分词器对该索引库进行分词:
"analyzer": "ik_smart",当然,虽然IK分词器可以对大部分常规的词汇进行分词,但对于紧跟时代潮流涌现的那些时下热词之类的,依旧是无法进行分词的,此时就需要自己拓展词典。
拓展词典
1)打开IK分词器config目录:
注意,如果采用在线安装的通过,默认是没有config目录的,需要自行下载config目录上传至对应目录。
在IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic</entry>
</properties>
在IK分词器的config目录新建一个 ext.dic:
蔡徐坤
坤哥
坤坤
鸡你太美
666
这下对于那些网络热词也可以进行分词了