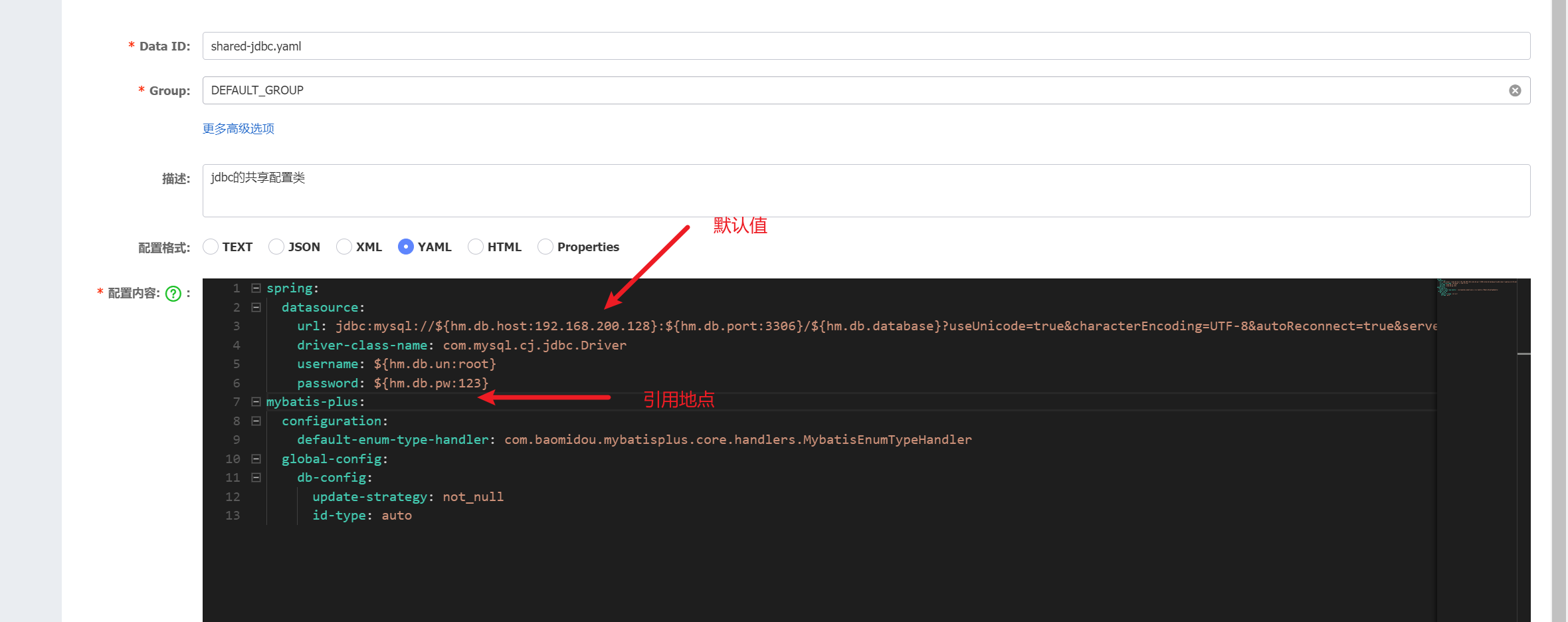
c
在本教程中,我们将介绍一个简单的示例,旨在帮助初学者入门时间序列预测和 PyTorch 的使用。通过这个示例,你可以学习如何使用 LSTMCell 单元来处理时间序列数据。
我们将使用两个 LSTMCell 单元来学习从不同相位开始的正弦波信号。模型在学习了这些正弦波之后,将尝试预测未来的信号值。
使用方法
-
生成正弦波信号:
python generate_sine_wave.py -
训练模型:
python train.py
生成正弦波训练数据
在这一步中,我们将生成用于训练的正弦波信号数据。以下是代码及其详细解释:
import numpy as np
import torch
# 设置随机种子,以确保结果的可重复性
np.random.seed(2)
# 定义常数 T、L 和 N
T = 20
L = 1000
N = 100
# 创建一个空的 numpy 数组 x,用于存储生成的序列
x = np.empty((N, L), 'int64')
# 为数组 x 赋值,每行都是一个按顺序排列的整数序列,
# 并加入了一个随机偏移量
x[:] = np.array(range(L)) + np.random.randint(-4 * T, 4 * T, N).reshape(N, 1)
# 对 x 进行正弦变换,以此生成正弦波数据
data = np.sin(x / 1.0 / T).astype('float64')
# 将生成的正弦波数据保存为一种 PyTorch 可读的格式
torch.save(data, open('traindata.pt', 'wb'))
代码解析
- 导入库
numpy:用于数值计算torch:用于深度学习中的数据处理和模型训练
- 设置随机种子
- 通过
np.random.seed(2)设置随机种子,以保证每次运行代码时生成相同的随机数,从而使结果可重复。
- 定义常量
T:周期长度L:每行的序列长度N:生成的样本数量
- 生成随机序列
- 创建一个空的 numpy 数组
x,用于存储生成的整数序列。 - 对数组
x进行赋值,每一行是一个按顺序排列的整数序列,加上一个随机的偏移量。偏移量的范围由np.random.randint(-4 * T, 4 * T, N).reshape(N, 1)确定。
- 生成正弦波数据
- 对
x进行正弦变换,生成标准的正弦波数据。np.sin(x / 1.0 / T).astype('float64')将整数序列转换为浮点数序列,并进行正弦变换。
- 保存数据
- 使用
torch.save将生成的正弦波数据保存为traindata.pt,方便后续训练时加载使用。
搭建与训练时间序列预测模型
在本教程中,我们将详细讲解如何使用 PyTorch 搭建一个LSTM模型,进行时间序列预测。以下是代码及其逐行解释,我们将整个过程分为三个部分:模型定义、数据加载与预处理,以及模型训练与预测。
模型定义
首先,我们定义一个 LSTM 模型,该模型包含两个 LSTMCell 层和一个全连接层用于输出。
from __future__ import print_function
import argparse
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
# 定义一个序列模型
class Sequence(nn.Module):
def __init__(self):
super(Sequence, self).__init__()
# 定义两个LSTMCell层和一个全连接层
self.lstm1 = nn.LSTMCell(1, 51)
self.lstm2 = nn.LSTMCell(51, 51)
self.linear = nn.Linear(51, 1)
# 定义前向传播
def forward(self, input, future = 0):
outputs = []
# 初始化LSTMCell的隐藏状态和细胞状态
h_t = torch.zeros(input.size(0), 51, dtype=torch.double)
c_t = torch.zeros(input.size(0), 51, dtype=torch.double)
h_t2 = torch.zeros(input.size(0), 51, dtype=torch.double)
c_t2 = torch.zeros(input.size(0), 51, dtype=torch.double)
# 遍历输入序列
for input_t in input.split(1, dim=1):
# 更新LSTMCell的隐藏状态和细胞状态
h_t, c_t = self.lstm1(input_t, (h_t, c_t))
h_t2, c_t2 = self.lstm2(h_t, (h_t2, c_t2))
# 通过全连接层得到输出
output = self.linear(h_t2)
outputs += [output]
# 如果需要预测未来值
for i in range(future):
h_t, c_t = self.lstm1(output, (h_t, c_t))
h_t2, c_t2 = self.lstm2(h_t, (h_t2, c_t2))
output = self.linear(h_t2)
outputs += [output]
# 将输出序列拼接起来
outputs = torch.cat(outputs, dim=1)
return outputs
这段代码是一个简单的序列模型,包括两个LSTMCell层和一个全连接层。它接受一个输入序列,通过LSTMCell层和全连接层对输入进行处理,最终输出一个序列。如果需要预测未来值,则可以在forward函数中传入future参数来进行预测。
具体解释如下:
- 首先导入必要的库,包括torch、torch.nn等。
- 定义了一个名为Sequence的序列模型,继承自nn.Module。
- 在初始化函数中,定义了两个LSTMCell层和一个全连接层,分别是lstm1、lstm2和linear。
- forward函数用来定义模型的前向传播过程,接受输入input和可选的future参数,返回处理后的输出序列。
- 在forward函数中,首先初始化了LSTMCell的隐藏状态和细胞状态h_t、c_t、h_t2、c_t2。
- 遍历输入序列input,对每个输入进行处理,更新LSTMCell的隐藏状态和细胞状态,通过全连接层得到输出,并将输出保存在outputs列表中。
- 如果future参数大于0,表示需要预测未来值,进入一个for循环,通过当前输出不断更新LSTMCell的状态,并将预测得到的输出保存在outputs中。
- 最后将所有输出序列拼接起来,返回最终的输出。
这段代码主要实现了对输入序列的处理和未来值的预测,是一个简单的序列预测模型。
数据加载与预处理
接下来,我们加载生成的训练数据,并构建训练集和测试集。
if __name__ == '__main__':
# 定义命令行参数
parser = argparse.ArgumentParser()
parser.add_argument('--steps', type=int, default=15, help='steps to run')
opt = parser.parse_args()
# 设置随机种子
np.random.seed(0)
torch.manual_seed(0)
# 加载数据并构建训练集
data = torch.load('traindata.pt')
input = torch.from_numpy(data[3:, :-1])
target = torch.from_numpy(data[3:, 1:])
test_input = torch.from_numpy(data[:3, :-1])
test_target = torch.from_numpy(data[:3, 1:])
这段代码是一个Python脚本的入口点,通常用于定义和设置命令行参数,加载数据,并准备训练数据。让我逐行解释:
-
if __name__ == '__main__':这是Python中用来判断是否当前脚本被当做程序入口执行的一种常见方式。如果当前脚本被当做主程序执行,而不是被其他模块导入,这个条件会成立。 -
parser = argparse.ArgumentParser()创建了一个命令行参数解析器。 -
parser.add_argument('--steps', type=int, default=15, help='steps to run')定义了一个名为steps的命令行参数,指定了参数的类型为整数,默认值为15,以及参数的帮助信息。 -
opt = parser.parse_args()解析命令行参数,并将结果存储在opt变量中。 -
np.random.seed(0)和torch.manual_seed(0)设置了随机数生成器的种子,用于确保实验结果的可复现性。 -
data = torch.load('traindata.pt')从名为traindata.pt的文件中加载数据。 -
input = torch.from_numpy(data[3:, :-1])创建了一个PyTorch张量input,用于存储数据中第4列到倒数第2列之间的数据。 -
target = torch.from_numpy(data[3:, 1:])创建了一个PyTorch张量target,用于存储数据中第4列到最后一列之间的数据。 -
test_input = torch.from_numpy(data[:3, :-1])创建了一个PyTorch张量test_input,用于存储数据中第1列到倒数第2列之间的数据,这是用于测试的输入数据。 -
test_target = torch.from_numpy(data[:3, 1:])创建了一个PyTorch张量test_target,用于存储数据中第2列到最后一列之间的数据,这是用于测试的目标数据。
这段代码的主要作用是准备数据,设置随机种子和命令行参数,为后续的数据处理和模型训练做准备。
模型训练与预测
最后,我们进行模型训练并进行预测。
# 构建模型
seq = Sequence()
seq.double()
criterion = nn.MSELoss()
# 使用LBFGS作为优化器,因为我们可以将所有数据加载到训练中
optimizer = optim.LBFGS(seq.parameters(), lr=0.8)
# 开始训练
for i in range(opt.steps):
print('STEP: ', i)
def closure():
optimizer.zero_grad()
out = seq(input)
loss = criterion(out, target)
print('loss:', loss.item())
loss.backward()
return loss
optimizer.step(closure)
# 开始预测,不需要跟踪梯度
with torch.no_grad():
future = 1000
pred = seq(test_input, future=future)
loss = criterion(pred[:, :-future], test_target)
print('test loss:', loss.item())
y = pred.detach().numpy()
# 绘制结果
plt.figure(figsize=(30,10))
plt.title('Predict future values for time sequences\n(Dashlines are predicted values)', fontsize=30)
plt.xlabel('x', fontsize=20)
plt.ylabel('y', fontsize=20)
plt.xticks(fontsize=20)
plt.yticks(fontsize=20)
def draw(yi, color):
plt.plot(np.arange(input.size(1)), yi[:input.size(1)], color, linewidth = 2.0)
plt.plot(np.arange(input.size(1), input.size(1) + future), yi[input.size(1):], color + ':', linewidth = 2.0)
draw(y[0], 'r')
draw(y[1], 'g')
draw(y[2], 'b')
plt.savefig('predict%d.pdf'%i)
plt.close()
这段代码是一个简单的 PyTorch 深度学习模型训练和预测的示例。让我为您解释一下代码的主要部分:
-
首先,代码创建了一个名为 “seq” 的序列模型。然后转换这个模型为双精度数据类型。接着定义了均方误差损失函数 “criterion”。LBFGS 作为优化器,学习速率为 0.8。
-
在训练过程中,通过一个循环来进行多次优化迭代。在每次迭代中,通过闭包函数 “closure()” 来计算损失并执行反向传播,然后优化器根据损失进行参数更新。
-
接着,使用 torch.no_grad() 上下文管理器来禁止跟踪梯度,开始进行预测。在这里,预测未来的 1000 个时间步。然后计算预测结果和测试目标之间的损失,并打印损失值。
-
接下来是绘制结果的部分。代码会使用 matplotlib 库绘制预测的结果图。其中,将实线用于已知的数据部分,虚线用于预测的数据部分。最后,结果图被保存为名为 ‘predict%d.pdf’ 的文件,其中 %d 是迭代的次数。
在GPU上运行
这段代码的默认配置是使用CPU进行训练和预测。如果你想利用GPU加速训练过程,可以通过以下步骤修改代码将模型和数据放到GPU上进行计算。
以下是针对GPU的修改:
- 检查是否有可用的GPU:一般使用
torch.cuda.is_available()来检查是否有可用的GPU。 - 将模型和数据移动到GPU:将数据和模型移动到GPU设备上进行计算。
所有涉及到数据和模型的地方都需要做相应的改动,使其可以在GPU上执行。
以下是修改后的代码:
from __future__ import print_function
import argparse
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
# 定义一个序列模型
class Sequence(nn.Module):
def __init__(self):
super(Sequence, self).__init__()
# 定义两个LSTMCell层和一个全连接层
self.lstm1 = nn.LSTMCell(1, 51)
self.lstm2 = nn.LSTMCell(51, 51)
self.linear = nn.Linear(51, 1)
# 定义前向传播
def forward(self, input, future = 0):
outputs = []
# 初始化LSTMCell的隐藏状态和细胞状态
h_t = torch.zeros(input.size(0), 51, dtype=input.dtype, device=input.device)
c_t = torch.zeros(input.size(0), 51, dtype=input.dtype, device=input.device)
h_t2 = torch.zeros(input.size(0), 51, dtype=input.dtype, device=input.device)
c_t2 = torch.zeros(input.size(0), 51, dtype=input.dtype, device=input.device)
# 遍历输入序列
for input_t in input.split(1, dim=1):
# 更新LSTMCell的隐藏状态和细胞状态
h_t, c_t = self.lstm1(input_t, (h_t, c_t))
h_t2, c_t2 = self.lstm2(h_t, (h_t2, c_t2))
# 通过全连接层得到输出
output = self.linear(h_t2)
outputs += [output]
# 如果需要预测未来值
for i in range(future):
h_t, c_t = self.lstm1(output, (h_t, c_t))
h_t2, c_t2 = self.lstm2(h_t, (h_t2, c_t2))
output = self.linear(h_t2)
outputs += [output]
# 将输出序列拼接起来
outputs = torch.cat(outputs, dim=1)
return outputs
if __name__ == '__main__':
# 定义命令行参数
parser = argparse.ArgumentParser()
parser.add_argument('--steps', type=int, default=15, help='steps to run')
opt = parser.parse_args()
# 设置随机种子
np.random.seed(0)
torch.manual_seed(0)
# 检查是否有可用的GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载数据并构建训练集
data = torch.load('traindata.pt')
input = torch.from_numpy(data[3:, :-1]).double().to(device)
target = torch.from_numpy(data[3:, 1:]).double().to(device)
test_input = torch.from_numpy(data[:3, :-1]).double().to(device)
test_target = torch.from_numpy(data[:3, 1:]).double().to(device)
# 构建模型
seq = Sequence().double().to(device)
criterion = nn.MSELoss()
# 使用LBFGS作为优化器,因为我们可以将所有数据加载到训练中
optimizer = optim.LBFGS(seq.parameters(), lr=0.8)
# 开始训练
for i in range(opt.steps):
print('STEP: ', i)
def closure():
optimizer.zero_grad()
out = seq(input)
loss = criterion(out, target)
print('loss:', loss.item())
loss.backward()
return loss
optimizer.step(closure)
# 开始预测,不需要跟踪梯度
with torch.no_grad():
future = 1000
pred = seq(test_input, future=future)
loss = criterion(pred[:, :-future], test_target)
print('test loss:', loss.item())
y = pred.detach().cpu().numpy() # 将结果移回CPU以便绘图
# 绘制结果
plt.figure(figsize=(30,10))
plt.title('Predict future values for time sequences\n(Dashlines are predicted values)', fontsize=30)
plt.xlabel('x', fontsize=20)
plt.ylabel('y', fontsize=20)
plt.xticks(fontsize=20)
plt.yticks(fontsize=20)
def draw(yi, color):
plt.plot(np.arange(input.size(1)), yi[:input.size(1)], color, linewidth = 2.0)
plt.plot(np.arange(input.size(1), input.size(1) + future), yi[input.size(1):], color + ':', linewidth = 2.0)
draw(y[0], 'r')
draw(y[1], 'g')
draw(y[2], 'b')
plt.savefig('predict%d.pdf'%i)
plt.close()
修改解释
-
检查GPU:
- 使用
torch.cuda.is_available()检查是否有可用的GPU。如果有,将device设置为cuda,否则为cpu。
- 使用
-
数据和模型移到GPU:
- 使用
.to(device)方法将数据和模型移到指定设备(CPU或GPU)。 - 初始化隐藏状态和细胞状态时,指定相应的设备
device和数据类型dtype。
- 使用
-
绘图前将数据移回CPU:
- 由于
matplotlib需要在 CPU 上的 numpy 数组,因此在绘图前将预测数据移回 CPU,并调用.detach().cpu().numpy()。
- 由于
通过这些修改,你可以利用GPU来加速模型训练过程。当然,前提是你的计算机上配备了兼容的GPU。如果没有,代码将自动退回到使用CPU进行训练。
可以看到GPU明显上升

结果
STEP: 0
loss: 0.5023738122475573
loss: 0.4985663937943564
loss: 0.479011960611529
loss: 0.44633490214842303
loss: 0.35406310257493023
loss: 0.2050701661768143
loss: 1.3960531561166554
loss: 0.03249441148471743
...
test loss: 6.382565835674331e-06
STEP: 13
loss: 3.76246839739177e-06
test loss: 6.382565835674331e-06
STEP: 14
loss: 3.76246839739177e-06
test loss: 6.382565835674331e-06
得到图像:
第1次训练后:

第5次训练后:

第10次:

第15次: