在人工智能的浪潮中,我们常常被各种技术术语和概念所包围,但智能的本质究竟是什么?香港大学计算与数据科学学院院长马毅教授,在第三届「知乎 AI 先行者沙龙」上的演讲,为我们提供了全新视角。香港大学马毅:如何理解智能的本质?
智能的起源与发展
智能,或人工智能,近年来引起了广泛关注。从生物进化的角度来看,生命本身就是智能的载体。自然界生物的进化,是智能机制作用的结果。从单细胞生物到高等动物,再到人类,智能的演进是生物适应环境、学习与适应的过程。

生物逐渐演进的过程呈现出越来越高级的智能生物,它越来越依赖个体进行后天学习与适应,通过改进自己的先天知识,使得它的适应性更加广泛、更强。
生命依赖智能而存在的根本原因:我们的世界不是随机的,而是可预测

人的智能的发展,最显著的特征是群体智能的发展,变成了社会的动物。尤其是发明了语言,知识可以开始相互交流、相互分享,甚至开始出现了抽象的能力,以及数学、科学等等有群体知识的积累。
技术智能的突破
人工智能的发展,特别是神经网络的兴起,标志着技术智能的一个重要突破。自上世纪40年代以来,人工神经元和计算模型的提出,开启了智能模拟的新篇章。尽管神经网络经历了起伏,但随着数据和算力的加持,现代神经网络,如Transformer模型,在多个领域取得了显著成效。

自从 2010 年以后,神经网络随着数据以及算力的加持,它的性能得到逐渐的提高,带来了下一代神经网络现代的蓬勃发展。到目前为止,基本上大家在相对统一的神经网络框架,比如说 Transformer 下,不管是文本、图像,甚至在一些各方面的数据上都取得了非常显著的成效。
黑盒模型的局限
当前的人工智能系统多是基于经验或试错的方式设计出来的,被称为黑盒模型。这种模型难以解释,存在性能和安全上的不确定性,且改进成本高昂,且容易被利用。这促使我们思考如何将黑盒变为白盒,即理解机器学习背后的原理和机制。

那如何把黑盒变成白盒呢?知道机器智能或者机器学习到底在做什么,我们很可能就要问几个非常重要的本质的问题。智能也好,或者机器学习也好,到底要学什么,到底要做什么事,它的目的是什么?简而言之,即学什么、怎么学、如何才能学正确!

学什么
从感知外部世界的数据里学习可用于预测的信息
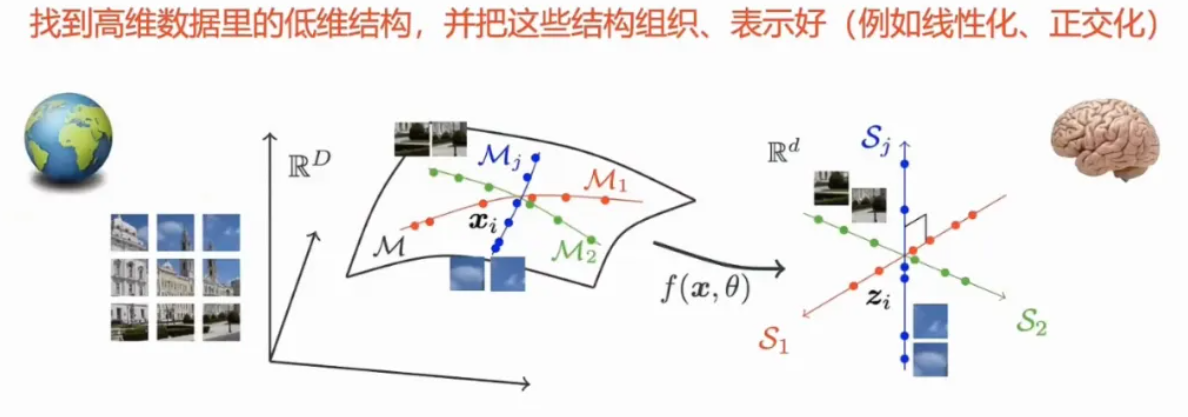
数学上,可预测的信息都统一以数据在高维空间中的低维结构体现出来
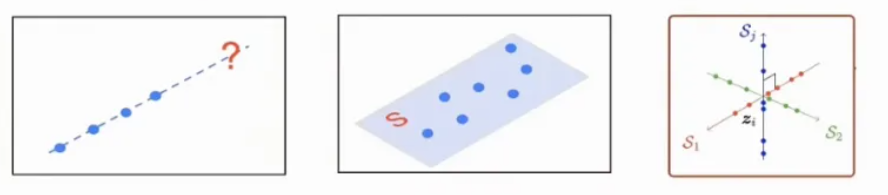
从生命起源开始,无论是人类还是动物,我们都生活在一个充满规律和可预测性的世界中。气候的变化、季节的更迭、天体的运动,甚至是物体的自由落体运动,都是我们可以预测的物理现象。这些规律性不仅体现在自然界的宏观现象中,也深植于我们的认知和记忆中。例如,动物和人类都能在大脑中形成对重力等物理现象的精准模型,这种模型帮助我们预测物体的运动轨迹和位置。巴甫洛夫的反射试验也表明,动物天生会对有规律、可预测的事件产生记忆。最近的研究进一步发现,所有可预测的信息都可以通过高维数据内在的低维结构来体现。无论是简单的直线运动还是复杂的多维空间运动,这些结构都是我们理解和预测世界的基础。简而言之,我们对世界的理解和预测能力,本质上是基于对这些内在结构的识别和利用。
学习所依赖的最本质的统一计算机制:同类相吸、异类相斥
怎么学
学习就要从这些观测到的高维数据(比如图像)里面的低维的结构学到,学到以后还要把它组织好、表示好。比如说非线性的变成线性,不正交的变成正交。如果这是一个目的的话,我们怎么从计算上去实现呢?它通过什么样的机制实现,怎么去组织,去找到这些结构,同时把它们组织规划好?自然界,包括人工智能,我们看到这么多的网络、算法,它的一个本质共同点,它们都在做同一件事情,就是对同类的物体、数据、信号相吸,异类相斥,把相似的东西聚在一起,不相似的东西分开,基本上就是做这个事情。

在计算上,这等价于最大化信息增益或者减少编码率(去噪压缩)。对世界的信息在增加,实际上也是一种编码减少的过程,就是一种压缩的概念,这个世界是可预测的,发生的事件存在的分布是被压缩的。
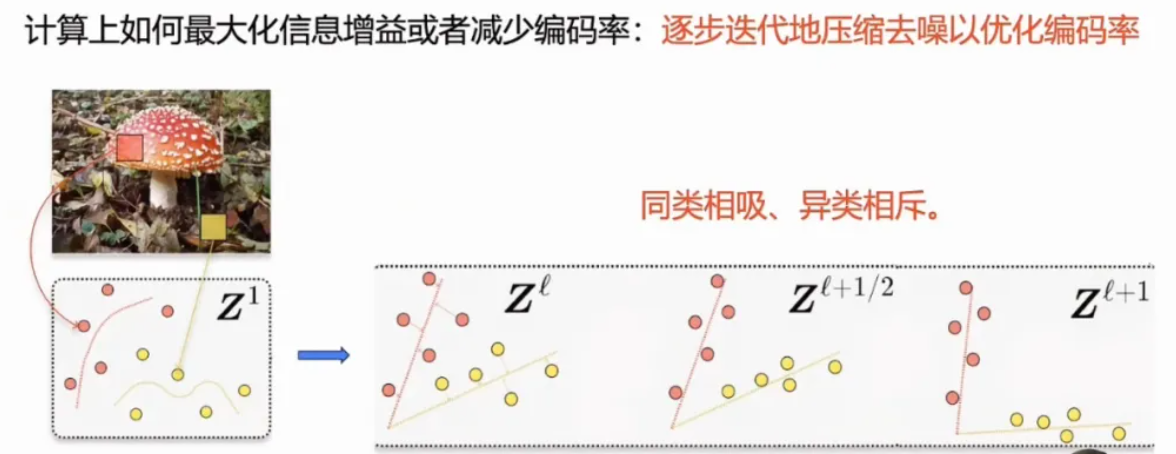
怎么高效做这个事情?一个很简单的办法,就是逐步去做。初始的时候可能离我们的目标还比较远,我们一步一步的对同类的东西进行去噪、压缩在一起,把不同类的东西逐渐的分开,这就是一个逐步迭代的压缩和去噪,去优化这个编码率,让信息增益得到增大。
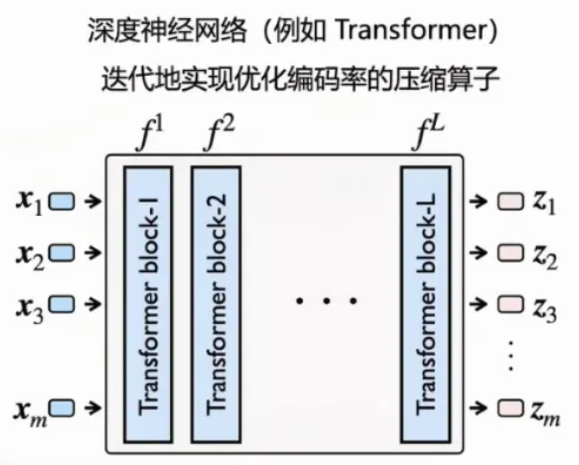
第一我们要学什么,第二是通过逐步迭代学习,事情就变得非常清晰了。比如说这个目标函数跟我们优化的编码率是相关的,我们要对得到表示的编码率进行优化。学过优化的同学就知道,逐渐优化的方法,就是做简单梯度下降。
深度网络的本质就是在实现这个逐步迭代优化的梯度下降算法。每一层就跟我刚才的图像一样,就是一步一步逐步的在进行优化,把数据的分布、数据的结构找到,然后逐渐地朝着我们所需要的方向去变化,所以每一层都是让这个分布变得越来越好。
如何正确对齐
如何保证你最后得到的记忆是正确的呢?通过压缩损失了一些关键信息便得不偿失了,其中一个方法来检验你学到的记忆,或者学到的数据的结构是正确的,一个简单的解决方式就是用它预测回到外部世界,帮它预测你所记忆下来的规律,是不是能够正确的预测现实世界会发生的事情,也就是所谓的解码,或者叫做生成、预测。
从外部的信号进入大脑,我们进行识别、记忆,然后再通过我们的识别或者记忆,对下一步会发生的事情进行重复、仿真、预测或者重现,这就是一个生成的过程,或者在数学上叫做解码的过程。整个过程从外到里、从里到外,就是一个自编码的过程,能帮助我们通过内部世界的模型,对外部世界进行预测。
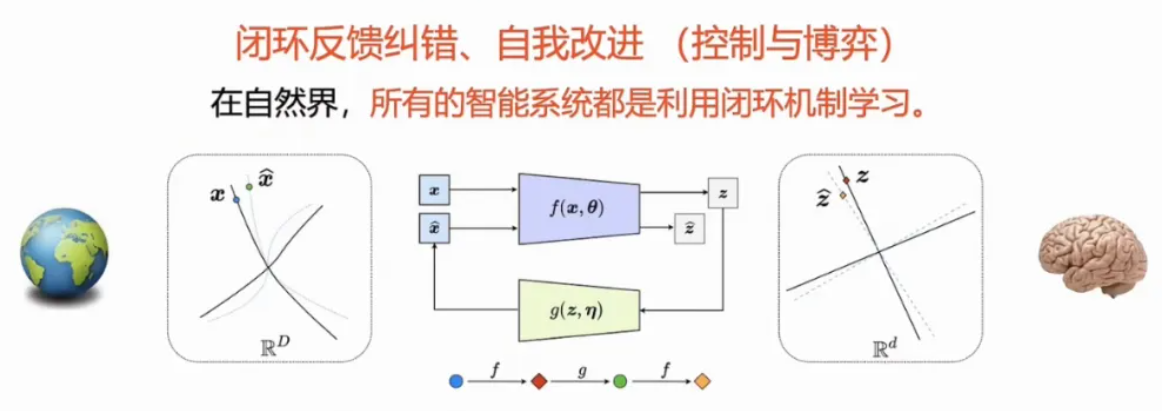
现在训练一个神经网络系统,从 X 到 Z、Z 到 X,我们提供相关的数据,让整个系统进行全局优化。但是在自然界,我们有时候并没有这个 option,相当于我们在训练一个神经网络的时候,对这个网络来说,我们是上帝,我们在纠正它的错误。在自然界,因为动物没有人去教它,它在一个环境中必须自己学习,这种机制是怎么回事呢?

自主学习的闭环机制
自然界中的智能系统,如动物,通过闭环反馈纠错机制进行自主学习。这种机制在现代人工智能系统中尚未普及。智能的定义应当包含自主改进和增加知识的能力。没有这种机制的系统,无论其能力多大,都不能称之为智能。
在20世纪40年代,维纳和冯诺伊曼洞察到自然界中的智能系统依赖于闭环反馈机制来实现自主学习和自我改进。这种机制通过不断的纠错和博弈,推动了智能系统的进化。反观现代人工智能,尤其是当下流行的大型模型,往往忽略了这种自然进化的智慧。真正的智能认知,不应仅仅是理论上的空谈,而应基于对计算复杂度的深刻理解。从Kolmogorov和Solomonoff的压缩理论,到图灵机的计算模型,智能的本质在于识别和解决那些在计算上可行的问题。尽管神经网络和反向传播算法在某些任务中表现出色,但面对高阶复杂度的挑战,它们仍有其局限性。自然界的智能系统展示了闭环纠错的力量,而我们对人工智能的探索,也应从这些自然机制中汲取灵感。

智能的未来
马毅教授提出,真正的智能是能够自主增加知识的系统。智能研究需要建立在对实现智能计算复杂度的正确认知上。理论的智能研究,如同盲人摸象,只有通过第一性原理和演绎方法,才能真正理解智能的本质。

智能的系统必须具有自主改进和增加自身知识的机制。任何一个系统,不管它能力多大,知识多少,只要不具备自主纠正或增加知识的计算机制,它是没有智能的。所以我们经常举的一个例子是 ChatGPT 和一个婴儿,谁更有智能、谁更有知识。
目前为止所有的人工智能算法,包括深度网络在做什么呢?无非在做数据的压缩而已。从某种意义上说,我们认为智能是能够增加知识的,是知识的微分,知识是通过智能活动所积累起来的,它是智能的一个积分。
结语
智能的本质探索,不仅是对过去的回顾,更是对未来的展望。技术智能的发展,需要我们深入理解其背后的原理和机制,从而推动人工智能向更高层次的智能进化。期待未来的智能系统能够更加透明、安全,并具备真正的自主学习能力。