文章目录
- 前言
- Spark RPC模型概述
- RpcEndpoint
- RpcEndpointRef
- RpcEnv
- 基于Netty的RPC实现
- NettyRpcEndpointRef
- NettyRpcEnv
- 消息的发送
- 消息的接收
- RpcEndpointRef的构造方式
- 直接通过RpcEndpoint构造RpcEndpointRef
- 通过消息发送RpcEndpointRef
- Endpoint的注册
- Dispatcher
- 消息的投递
- 消息的处理
- 引用
前言
在我的TODO这篇文章中讲解了我们线上的一次由于SparkContext构造超时导致的事故的详细过程,SparkContext构造过程的重要一步,就是Driver、ApplicationMaster以及Executor之间的协调和通信过程,这是基于RPC进行的。这里的Spark RPC是基于Netty的通信过程,而Netty的通信其实是基于Reactor架构进行的,Reactor架构其实是基于Java NIO模型进行的:

在我的另外一篇文章中,讲述了Hadoop中基于Reactor模型的Protobuf RPC通信模型《Hadoop RPC Server基于Reactor模式和Java NIO 的架构和原理》,对Reactor模型有非常详细的讲解。
Spark RPC是基于Netty的, 而Netty本身就是基于JavaNIO 的Reactor模型的实现,从具体分类来讲,是基于多Reactor、多线程的Reactor模型的实现。本文关注的重点不再是下层的Netty和Reactor框架,而是Spark RPC的上层实现。关于Netty和Reactor模型,读者可以参考本文末尾的参考文献,本文不再赘述。
Spark RPC模型概述
Spark中的RPC通信框架定义了一组通信接口,这些接口并不关心任何具体的实现方式,比如底层的网络通信框架(Jetty, Netty等), 序列化方式,消息体的定义则依赖底层的具体实现。
在Spark中,具体的实现是一个基于Netty框架的实现,包括服务端Socket的启动(以及后来的关闭),消息派发到正确地Endpoint,消息的编码和解码等。
Spark RPC模型的接口层RpcEndpoint、RpcEndpointRef、RpcEnv定义了一些网络通信的基本要素:
- 连接的地址,
- 连接的建立和断开,
- 消息的发送,
- 消息的接收,
- 响应的发送,
- 同步和异步的选择
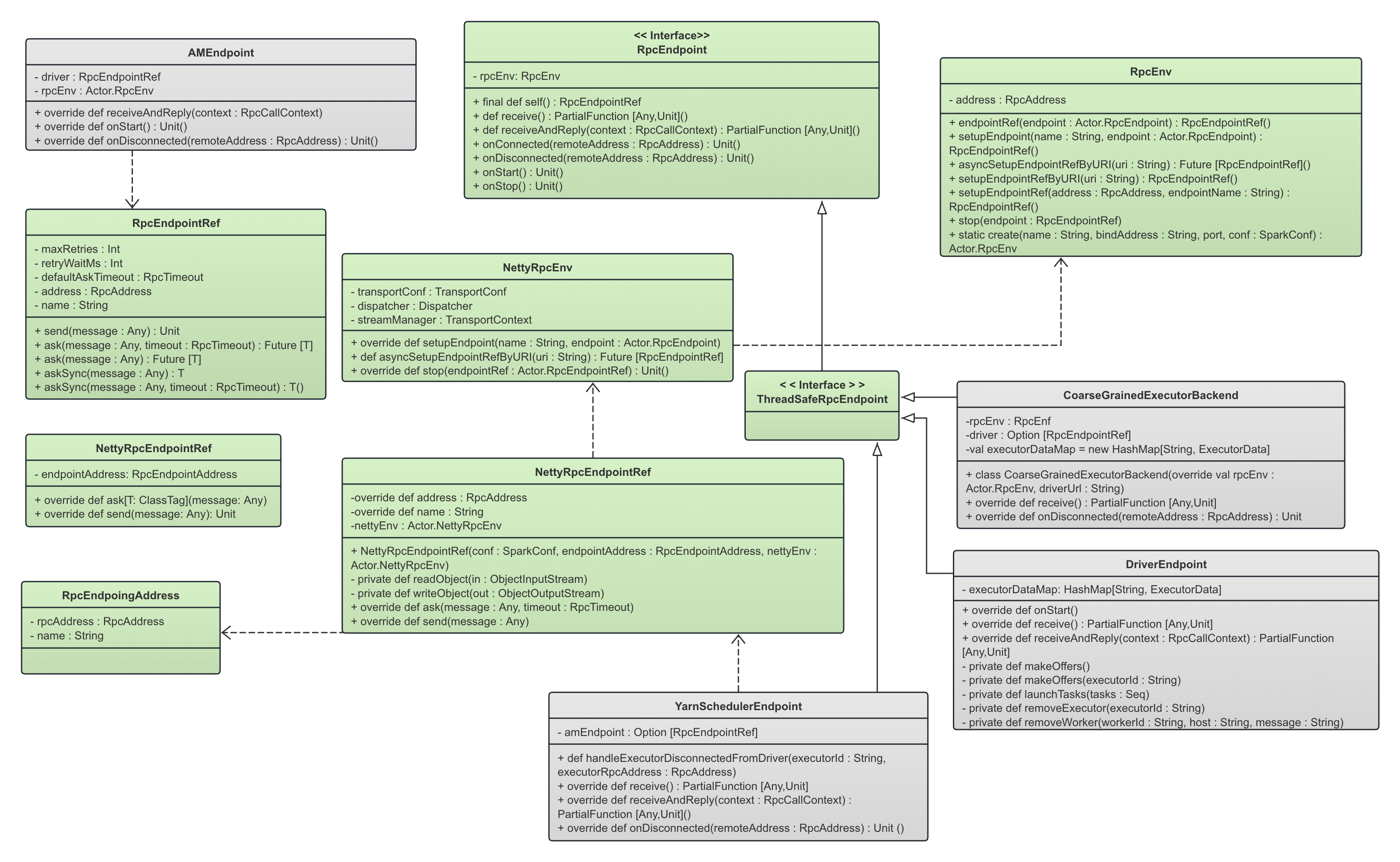
下面的静态UML图显式了Spark RPC模型的基本结构框架以及接口。绿色部分是模型本身的一些角色,灰色部分就是Spark中基于这个RPC模型所定义的各种实体(具体实现),比如各个角色都需要有自己的RpcEndpoint实现,代表一个RPC连接的Endpoint。
本文关注的重点就是下图中的绿色部分,即Spark RPC本身。
RpcEndpoint
一个RpcEndpoint定义了收到消息以后对消息的处理逻辑。RpcEndpoint看到的是经过网络传输以后解码完成的消息,它不需要关心消息是怎么传输过来的,也不需要关心消息的解码过程,只在乎具体的处理逻辑。
我们从上面的UML图可以看到,Spark端的各种类实现了RpcEndpoint(通过实现RpcEndpoint的子类ThreadSafeRpcEndpoint以实现线程安全),比如:
- DriverEndpoint: 运行在Driver端,本地的CoarseGrainedSchedulerBackend 持有了这个DriverEndpoint, Spark根据需求向DriverEndpoint发送比如KillExecutorsOnHost、KillTask、ReviveOffers、StatusUpdate 等消息。DriverEndpoint在其具体实现中处理消息,比如,如果KillTask,则会向远程的Task的RpcEndpoint发送KillTask消息,如果是KillExecutors,那么会通过YarnSchedulerEndpoint来和远程的ApplicationMaster通信以kill掉对应的container。每一个Executor是知道Driver的地址的,因此会向Driver注册自己,注册消息就是通过向DriverEndpoint发送RegisterExecutor消息来完成的。
- YarnSchedulerEndpoint:是Driver端运行的第二个Endpoint,由YarnSchedulerBackend管理,是用来和ApplicationMaster进行通信的endpoint,因此其作用是在Yarn这一层根据需求进行资源的调度。
-
问题: YarnSchedulerEndpoint是怎么知道ApplicationMaster的地址的?
-
- AMEndpoint: 运行在ApplicationMaster端,顾名思义,就是ApplicationMaster对应的RpcEndpoint。
- 在Spark Client模式下,ApplicationMaster运行在Yarn上,Driver运行在客户端,因此这时候不在一个Process中。在ApplicationMaster启动的时候,会向Driver的RpcEndpoint注册自己,即发送一条RegisterClusterManager消息给Driver;
- 如果是Cluster模式,二者在一个进程中,发送过程其实是一样的,只不过变成了进程内的通信;
- Driver收到消息以后,立刻根据消息中的Address信息,构造对应的ApplicationMaster的RpcEndpointRef,从而可以向ApplicationMaster发送消息以进行必要的资源请求;
-
问题: Driver是怎么知道每一个Executor的地址和当前的ApplicationMaster的地址的?
- CoarseGrainedExecutorBackend: 运行在Executor端,就是Executor端的RpcEndpoint实现(虽然这个类名不是*Endpoint)。
RpcEndpoint 这个trait主要定义了消息接收的相应接口,对应接口方法如下:
-------------------------------------------------- RpcEndpoint -----------------------------------------------
private[spark] trait RpcEndpoint {
/**
* 这个RpcEndpoint所注册到的RpcEnv
*/
val rpcEnv: RpcEnv
/**
* 这个RpcEndpoint自身对应的RpcEndpointRef
*/
final def self: RpcEndpointRef = {
require(rpcEnv != null, "rpcEnv has not been initialized")
rpcEnv.endpointRef(this)
}
/**
* 处理来自于RpcEndpointRef.send() 和 RpcCallContext.reply()方法发送的消息。即,消息的发送者通过send()发送的消息或者消息的接受中通过reply()回复的消息会在这个发送中被收到,并且不要求回复这个消息。
*/
def receive: PartialFunction[Any, Unit] = {
case _ => throw new SparkException(self + " does not implement 'receive'")
}
/**
* 处理来自远程的RpcEndpointRef.ask()发送的消息,即ask()发送的消息会在这个方法里面收到,同时消息的发送者需要我们对消息进行回复。
*/
def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case _ => context.sendFailure(new SparkException(self + " won't reply anything"))
}
所以,处理消息的接收主要是两个接口方法:
- 来自
RpcEndpointRef.send()和RpcCallContext.reply()方法(下文会讲解RpcEndpointRef和RpcCallContext)发送的消息会被RpcEnv调度给RpcEndpoint的receive()方法来进行处理,从这两个方法发送过来的消息不要求消息的接收者对消息进行回复。这种类型的消息叫做单向消息,OneWayMessage。 - 来自
RpcEndpointRef.ask()(当然包括了ask()和askAsync())方法发送的消息会被RpcEnv调度给RpcEndpoint的receiveAndReply()方法来进行处理,ask()方法发送的消息要求接受者在receiveAndReply()方法中进行回复,消息的回复通过RpcCallContext进行回复,很显然,RpcCallContext维护了当前的通信信道。这种消息叫做RpcMessage。
RpcEndpointRef
顾名思义, RpcEndpointRef就是对一个RpcEndpointRef的引用。最简单的理解,RpcEndpointRef就代表了一个远程的RpcEndpoint,它定义了跟消息发送相关的接口方法,用来让我们向其对应的远程的RpcEndpoint发送消息,因此远程的RpcEndpoint就会在receive()方法或者receiveAndReply()方法中收到传输、解码(注意是解码decrypt,不是解析)完成以后的消息:
----------------------------------------------- RpcEndpointRef -------------------------------------------------
private[spark] abstract class RpcEndpointRef(conf: SparkConf)
extends Serializable with Logging {
................
def address: RpcAddress // 远程的RpcEndpoint的地址
def name: String
/**
* Sends a one-way asynchronous message. Fire-and-forget semantics.
* 发送一个单向的一部消息,发送以后即返回,不进行响应的等待。
*/
def send(message: Any): Unit
/**
* 发送给远程RpcEndpoint一个消息,同时返回一个Future句柄用来获取消息的响应。远程的RpcEndpoint会在方法[[RpcEndpoint.receiveAndReply)]]中收到消息并进行响应。
* 这个方法不负责重试,调用者自己负责进行重试发送。
* 这个方法指定了timeout
*/
def ask[T: ClassTag](message: Any, timeout: RpcTimeout): Future[T]
/**
* 发送给远程RpcEndpoint一个消息,同时返回一个Future句柄用来获取消息的响应。远程的RpcEndpoint会在方法[[RpcEndpoint.receiveAndReply)]]中收到消息并进行响应。
* 这个方法不负责重试,调用者自己负责进行重试发送。
* 这个方法使用默认的spark.rpc.askTimeout配置的RPC timeout
*/
def ask[T: ClassTag](message: Any): Future[T] = ask(message, defaultAskTimeout)
/**
* ask()方法的同步版本,返回值是对方直接返回的结果。
* 最多等待timeout时间以后返回。
*/
def askSync[T: ClassTag](message: Any, timeout: RpcTimeout): T = {
val future = ask[T](message, timeout)
timeout.awaitResult(future)
}
我们看到RpcEndpointRef本身居然继承了Serializable,这说明一个RpcEndpointRef trait的实现类的对象要求是可以被序列化的,即可以进行序列化、传输到远端然后反序列化为RpcEndpointRef。我们下面在将基于Netty的RPC的实现的时候,会详细讲到对RpcEndpointRef进行序列化的动机、方式和其特殊之处。
所以,要获取一个远程RpcEndpoint的对应的RpcEndpointRef以向其发送消息,有两种方式:
- 调用RpcEnv的setupEndpointRef()方法,我们提供对应的远程的RpcEndpoint地址和名字,返回远程的RpcEndpoint的RpcEndpointRef
- 发送者直接将自己的RpcEndpointRef作为消息的一部分发送给远程,接收者的NettyRpcEnv在收到消息以后,反序列化的过程中,自动帮我们反序列化RpcEndpointRef,并将对应的TransportClient设置到RpcEndpointRef中,就好像这个RpcEndpointRef中包括网络通信在内的东西也可以序列化和反序列化一样。下文会详细讲解这种模式的实现细节。
接口中,send()方法是单向发送,即不要求接收方(这个RpcEndpointRef对应的远程的RpcEndpoint)进行回复。
而ask*()方法是要求消息的接收方进行回复的。这里分为同步和异步两种情况。
def ask[T: ClassTag](message: Any, timeout: RpcTimeout): Future[T]方法是异步的,方法返回一个Future句柄给调用者,调用者可以通过这个句柄异步获取消息接收方的相应def ask[T: ClassTag](message: Any): Future[T]是上面的ask方法的同名的重载方法,使用默认的timeout调用了上面的方法:def ask[T: ClassTag](message: Any): Future[T] = ask(message, defaultAskTimeout)def askSync[T: ClassTag](message: Any, timeout: RpcTimeout): T是同步方法,直接返回响应的结果,最长等待时间是timeout。其实根本上还是基于上面的异步方法ask()进行的,只不过在方法内部帮我们进行了阻塞等待:def askSync[T: ClassTag](message: Any, timeout: RpcTimeout): T = { val future = ask[T](message, timeout) timeout.awaitResult(future) }def askSync[T: ClassTag](message: Any): T = askSync(message, defaultAskTimeout)也是上面的askSync的同名的重载方法,使用了默认的超时时间。这里不赘述:def askSync[T: ClassTag](message: Any): T = askSync(message, defaultAskTimeout)
所以,我们可以看到,上面的两个同步方法、两个异步方法都是基于异步方法def ask[T: ClassTag](message: Any, timeout: RpcTimeout): Future[T]实现的,因此,RpcEndpointRef的实现类只需要实现def ask[T: ClassTag](message: Any, timeout: RpcTimeout): Future[T]这一个异步方法就行了。后文将NettyRpcEndpointRef的时候会详细讲解。
RpcEnv
一个RPC服务环境。在区分Cluster模式和Client模式以前,我们可以简单将一个RpcEnv和一个Listening Socket Server对应起来。所以,这里的环境,首先有Rpc所监听的端口(比如,0.0.0.0:8082),即这个Socket的监听端口。然后,还应该有对应的路由规则,即收到一个Rpc请求以后,应该把这个请求交付给哪一个RpcEndpoint进行处理。
所以,一个仅仅定义了对应的业务处理逻辑的RpcEndpoint必须注册到RpcEnv,才算接入到了网络,从而会接收到远程的Rpc请求并经过Rpc进行路由转发让RpcEndpoint接收。
我们后面会讲到RpcEnv打开端口监听,只是它的其中一种模式(叫做Cluster模式),它还有另外一种运行模式叫Client模式。
---------------------------------------------------- RpcEnv ------------------------------------------------------
private[spark] abstract class RpcEnv(conf: SparkConf) {
.......
/**
* 这个RpcEnv所监听的Socket地址
*/
def address: RpcAddress
/**
* 注册(接入)一个RpcEndpoint,指定对应的名称,返回对应的RpcEndpointRef对象。
* 只有注册的RpcEndpoint,RpcEnv才会将对应的消息转发给这个RpcEndpoint
*/
def setupEndpoint(name: String, endpoint: RpcEndpoint): RpcEndpointRef
/**
* 这发生在我们需要知道了一个远程的RpcEndpoint的uri,因此需要获取这个远程的RpcEndpoint对应的RpcEndpointRef
* , 从而向这个远程的Endpoint发送消息
*/
def asyncSetupEndpointRefByURI(uri: String): Future[RpcEndpointRef]
/**
* 这发生在我们需要知道了一个远程的RpcEndpoint的地址和端口以及uri
* 因此需要构造远程的RpcEndpoint对应的RpcEndpointRef以向这个远程的Endpoint发送消息
*/
def setupEndpointRefByURI(uri: String): RpcEndpointRef = {
defaultLookupTimeout.awaitResult(asyncSetupEndpointRefByURI(uri))
}
.....
基于Netty的实现中,最主要的实现细节都在实现RpcEnv这个接口,即包括编解码的方式,接收到消息以后向RpcEndpoint进行消息的交付,Socket的启动、关闭等等逻辑。
基于Netty的RPC实现
NettyRpcEndpointRef
基于Netty的RPC框架中,RpcEndpointRef的实现类是NettyRpcEndpointRef。我们在介绍RpcEndpointRef的时候说过,RpcEndpointRef对消息的发送接口进行了定义,实现者需要进行具体的网络通信的实现。
我们看到NettyRpcEndpointRef的构造如下:
private[netty] class NettyRpcEndpointRef(
@transient private val conf: SparkConf,
private val endpointAddress: RpcEndpointAddress, // 这个RpcEndpointRef对应的RpcEndpoint的地址
// 这个RpcEndpointRef对应的RpcEndpoint的RpcEnv的地址,即远程的那个RpcEndpointRef
@transient @volatile private var nettyEnv: NettyRpcEnv)
extends RpcEndpointRef(conf) {
// 这个NettyRpcEndpoingRef的TransportClient,在postToOutbox()中使用到
// 声明为transient,表示该字段属于NettyRpcEndpointRef中不可以被序列化的字段
@transient @volatile var client: TransportClient = _
override def address: RpcAddress =
if (endpointAddress.rpcAddress != null) endpointAddress.rpcAddress else null
一个NettyRpcEndpointRef代表了一个基于Netty通信框架的、远程的一个RpcEndpoint。endpointAddress代表了远程的RpcEndpoint的地址。nettyEnv代表了远程的RpcEndpoint所在的RpcEnv,而不是当前维护的NettyRpcEndpointRef对象的RpcEnv。
我们上文讲过,RpcEndpointRef继承了scala.Serializable 这个 trait,因此NettyRpcEndpointRef需要是可序列化的。但是,nettyEnv和client都和网络通信相关,显然无法序列化,因此声明为transient,表明在序列化NettyRpcEndpointRef的时候可以跳过对nettyEnv和client的序列化。其余没有声明为transient的变量则必须序列化。
NettyRpcEndpointRef实现了基于Netty的消息发送功能。消息发送的接口上文在介绍RpcEndpointRef的时候已经介绍,虽然发送有同步、异步以及多个不同的重载,但是其实都是基于def ask[T: ClassTag](message: Any, timeout: RpcTimeout)实现的,因此RpcEndpointRef接口的实现者只需要实现这一个方法就行。这里来看看具体实现。
override def ask[T: ClassTag](message: Any, timeout: RpcTimeout): Future[T] = {
// 客户端构造一个RequestMessage方法,传入当前的nettyEnv的address,这个地址将会序列化到RequestMessage中,
// 接收者接收到以后,会保存这个Address,从而基于长连接,向客户端发送消息,而不需要客户端单独启动一个监听端口进行监听
// 这个this是当前的 NettyRpcEndpointRef 对象,这个address是这个NettyRpcEndpointRef中的address
nettyEnv.ask(new RequestMessage(nettyEnv.address, this, message), timeout)
}
可以看到,这里会调用当前NettyRpcEndpointRef对象中的nettyEnv的ask方法进行消息发送。所以我们看到,核心的实现方法其实都在NettyRpcEnv中。
我们上面说过,ask()方法是要求消息的接收方进行响应的,因此其返回值是一个Future[T],即要求对方收到消息以后返回一个类型为T的响应。
发送的时候,会将接收方的RpcAddress、当前的RpcEndpointRef(对应了接收方的RpcEndpoint)实例以及消息体message封装成一个RequestMessage对象,交付给NettyRpcEnv进行发送。
private[netty] class RequestMessage(
val senderAddress: RpcAddress, // 发送方的地址信息,即对应的NettyRpcEnv.senderAddress,只有以Cluster模式启动的NettyRpcEnv才会有senderAddress
val receiver: NettyRpcEndpointRef, // 发送者
val content: Any) { // 消息体,这个消息体目前还没有进行序列化,序列化在后面才发生
NettyRpcEnv
NettyRpcEnv是Spark中基于Netty的RpcEnv的具体实现类。我们看看他的大致实现,容易理解实现一套RpcEnv需要做什么。
在SparkContext启动的时候,会调用静态的RpcEnv.create()方法来启动一个RpcEnv,对于一个服务来说,就是启动一个端口监听:
------------------------------------------------- RpcEnv ---------------------------------------------
private[spark] object RpcEnv {
def create(
name: String, // 这个Env的名字
bindAddress: String, // 绑定的地址,对于ApplicationMaster,就是本地地址
advertiseAddress: String, // 绑定的地址,对于ApplicationMaster,就是本地地址
port: Int, // 绑定的端口号,如果是-1,应该代表随机端口
.......
clientMode: Boolean) // 是否是client模式
: RpcEnv = {
val config = RpcEnvConfig(conf, name, bindAddress, advertiseAddress, port, securityManager,
numUsableCores, clientMode)
new NettyRpcEnvFactory().create(config) // 调用NettyRpcEnvFactory,创建NettyRpcEnv
}
NettyRpcEnvFactory.create()会创建NettyRpcEnv对象:
------------------------------------------------- NettyRpcEnvFactory ---------------------------------------------
private[rpc] class NettyRpcEnvFactory extends RpcEnvFactory with Logging {
def create(config: RpcEnvConfig): RpcEnv = {
val sparkConf = config.conf
// Use JavaSerializerInstance in multiple threads is safe. However, if we plan to support
// KryoSerializer in future, we have to use ThreadLocal to store SerializerInstance
// 在多线程中使用 JavaSerializerInstance 是安全的
val javaSerializerInstance =
new JavaSerializer(sparkConf).newInstance().asInstanceOf[JavaSerializerInstance]
// 创建一个NettyEnv
val nettyEnv =
new NettyRpcEnv(sparkConf, javaSerializerInstance, config.advertiseAddress,
config.securityManager, config.numUsableCores)
if (!config.clientMode) { // 如果是cluster模式,则需要启动对应监听端口进行持续监听
/**
* 定义了一个函数 startNettyRpcEnv,它接受一个整数参数 actualPort,并返回一个元组,
* 其中包含 NettyRpcEnv 实例和实际使用的端口号。这个函数的目的是在指定端口上启动 NettyRpcEnv 的服务。
*/
val startNettyRpcEnv: Int => (NettyRpcEnv, Int) = { actualPort =>
nettyEnv.startServer(config.bindAddress, actualPort)
(nettyEnv, nettyEnv.address.port)
}
try {
Utils.startServiceOnPort(config.port, startNettyRpcEnv, sparkConf, config.name)._1
} catch {
上面的创建方法创建了一个NettyRpcEnv对象。其基本过程是:
- 准备好序列化的实例,这里使用的是默认的JavaSerializer
val javaSerializerInstance = new JavaSerializer(sparkConf).newInstance().asInstanceOf[JavaSerializerInstance] - 创建一个NettyEnv对象。对象中包含了spark配置,包含了刚刚构造的序列化实现,这个RpcEnv的地址,跟安全相关的SecurityManager实现,以及分配给当前进程的核心数(比如当前可能是Driver,可能是Executor,可能是ApplicationMaster,那么对应的配置的核心数会传入到这里,目的是根据核心数来决定后面的Dispatcher线程池的线程池):
创建Netty对象的时候,会创建对应的Dispatcher,而构造NettyEnv的时候传入的核心数决定了Dispatcher中进行消息分派的并发数量。关于Dispatcher我们会在后文中详细讲解。// 创建一个NettyEnv val nettyEnv = new NettyRpcEnv(sparkConf, javaSerializerInstance, config.advertiseAddress, config.securityManager, config.numUsableCores)private val dispatcher: Dispatcher = new Dispatcher(this, numUsableCores) - 判断这个NettyEnv是Cluster模式还是Client模式。如果是Cluster模式,那么在指定的端口上启动Netty服务。如果是Client模式,则不需要启动服务:
这里的启动服务,就是启动一个Netty服务。关于Netty,本文不再详细介绍。if (!config.clientMode) { // 如果是cluster模式,则需要启动对应监听端口进行持续监听 /** * 定义了一个函数 startNettyRpcEnv,它接受一个整数参数 actualPort,并返回一个元组, * 其中包含 NettyRpcEnv 实例和实际使用的端口号。这个函数的目的是在指定端口上启动 NettyRpcEnv 的服务。 */ val startNettyRpcEnv: Int => (NettyRpcEnv, Int) = { actualPort => nettyEnv.startServer(config.bindAddress, actualPort) (nettyEnv, nettyEnv.address.port) } try { // startNettyRpcEnv是对应的启动function,启动NettyRpcEnv Utils.startServiceOnPort(config.port, startNettyRpcEnv, sparkConf, config.name)._1
注意,这里说的Client模式和Cluster模式,跟Spark提交时候的Cluster和Client模式是两件事情:- 这里RpcEnv的Cluster模式就是我们直觉上很容易理解的,即,以服务的方式打开一个端口监听,其它的客户端都可以连接进来。但是,Client模式又是什么呢?
- 看到Client模式以后,我们的第一直觉是,打开一个Client模式,以Client的方式发送消息到远程的某一个RpcEnv,远程的RpcEnv收到消息以后可以对Client模式的RpcEnv进行回复,这个过程显然是没有问题的。但是,假如远程的RpcEnv需要主动向这个Client模式的RpcEnv发送消息怎么办呢?因为毕竟是Client模式,因此并没有打开一个监听端口。答案是长连接。我们在下面将消息的发送的时候会讲Client模式下客户端和远程建立一个长连接、以及接收端维护这个长连接并持续使用这个连接与这个Client模式的RpcEnv进行专用Peer-to-Peer Channel通信的过程。
- 比如,Spark的Driver端和Executor端都是调用
SparkEnv.create()->RpcEnv.create()方法创建对应的NettyRpcEnv实例。我们很容易从代码层面看到,如果创建的是Driver,那么NettyRpcEnv就是以Cluster模式创建,因此会创建监听端口,如果创建的是Executor,那么RpcEnv就是以Client模式启动:---------------------------------------------- SparkEnv -------------------------------------------------- /** * Helper method to create a SparkEnv for a driver or an executor. */ private def create( conf: SparkConf, executorId: String, ......): SparkEnv = { // 当前的SparkEnv是一个Driver还是Executor val isDriver = executorId == SparkContext.DRIVER_IDENTIFIER ...... /* * 如果是Driver进程,就以Cluster模式打开RpcEnv,因此会打开端口。 * 如果是Executor,就是以Client Mode启动RpcEnv,因此不会打开对应监听端口 */ val rpcEnv = RpcEnv.create(systemName, bindAddress, advertiseAddress, port.getOrElse(-1), conf, securityManager, numUsableCores, !isDriver)
!isDriver,这意味着,如果是Driver进程,就以Cluster模式打开RpcEnv,因此会打开端口。如果是Executor,就是以Client Mode启动RpcEnv,因此不会打开对应监听端口。为什么会这样?
首先来看一下RpcEnv的Client模式与Cluster模式的区别:- Client模式启动的RpcEnv无法首先接收连接请求,而是必须先发起连接请求。即,通信信道必须是这个以Client模式启动的NettyRpcEnv主动向远程的某一个以Cluster模式启动固定NettyRpcEnv发起连接,然后这个以Cluster模式启动的NettyRpcEnv保存好这个通信信道以进行后续的通信。
- Client模式下的连接不可能被其它客户端共享,即,客户端NettyRpcEnv以Client模式连接到远程的NettyRpcEnv,因此这个通信信道在客户端和远程都有对应的端口号,但是第三方无法通过客户端的这个端口连接到这个以Client模式启动的NettyRpcEnv。但是以Cluster模式启动的NettyRpcEnv,却可以接受很多的连接。
由于Driver首先需要接收Executor的注册请求,因此Driver必须以Cluster模式启动以在对应端口监听来自随后启动的Executor的请求。Executor在启动以后,需要向Driver注册自己,随后Driver就会复用这个连接通道和Executor进行通信,因此Executor是以Client模式启动,不需要开启监听端口。- 注意,Executor之间的通信肯定是需要端口监听的, 但是不是走的这条通信链路。不在这里讨论,
消息的发送
上面讲过,消息的发送是通过NettyRpcEndpointRef进行对方,实际上是通过调用对应的NettyRpcEnv进行发送的:
----------------------------------------- NettyRpcEnv ----------------------------------------------------
private[netty] def ask[T: ClassTag](message: RequestMessage, timeout: RpcTimeout): Future[T] = {
val promise = Promise[Any]()
// 从message中提取对应的 NettyRpcEndpoingRef对象,从NettyRpcEndpoingRef中获取地址
val remoteAddr = message.receiver.address // 发送的目标地址,即接收方的地址
def onFailure(e: Throwable): Unit = {
........
}
def onSuccess(reply: Any): Unit = reply match {
....
}
try {
if (remoteAddr == address) { // 如果是本地地址
.....
dispatcher.postLocalMessage(message, p)
} else {
// 序列化这个NettyRpcEndpointRef,然后封装成 RpcOutboxMessage,将通过Outbox发送出去
val rpcMessage = RpcOutboxMessage(message.serialize(this),
onFailure,
// 发送成功以后的回调
(client, response) => onSuccess(deserialize[Any](client, response)))
// receiver就是RequestMessage中对应的 NettyRpcEndpoingRef
postToOutbox(message.receiver, rpcMessage)
.....
}(ThreadUtils.sameThread)
}
....
promise.future.mapTo[T].recover(timeout.addMessageIfTimeout)(ThreadUtils.sameThread)
}
消息发送的基本流程如下图所示:
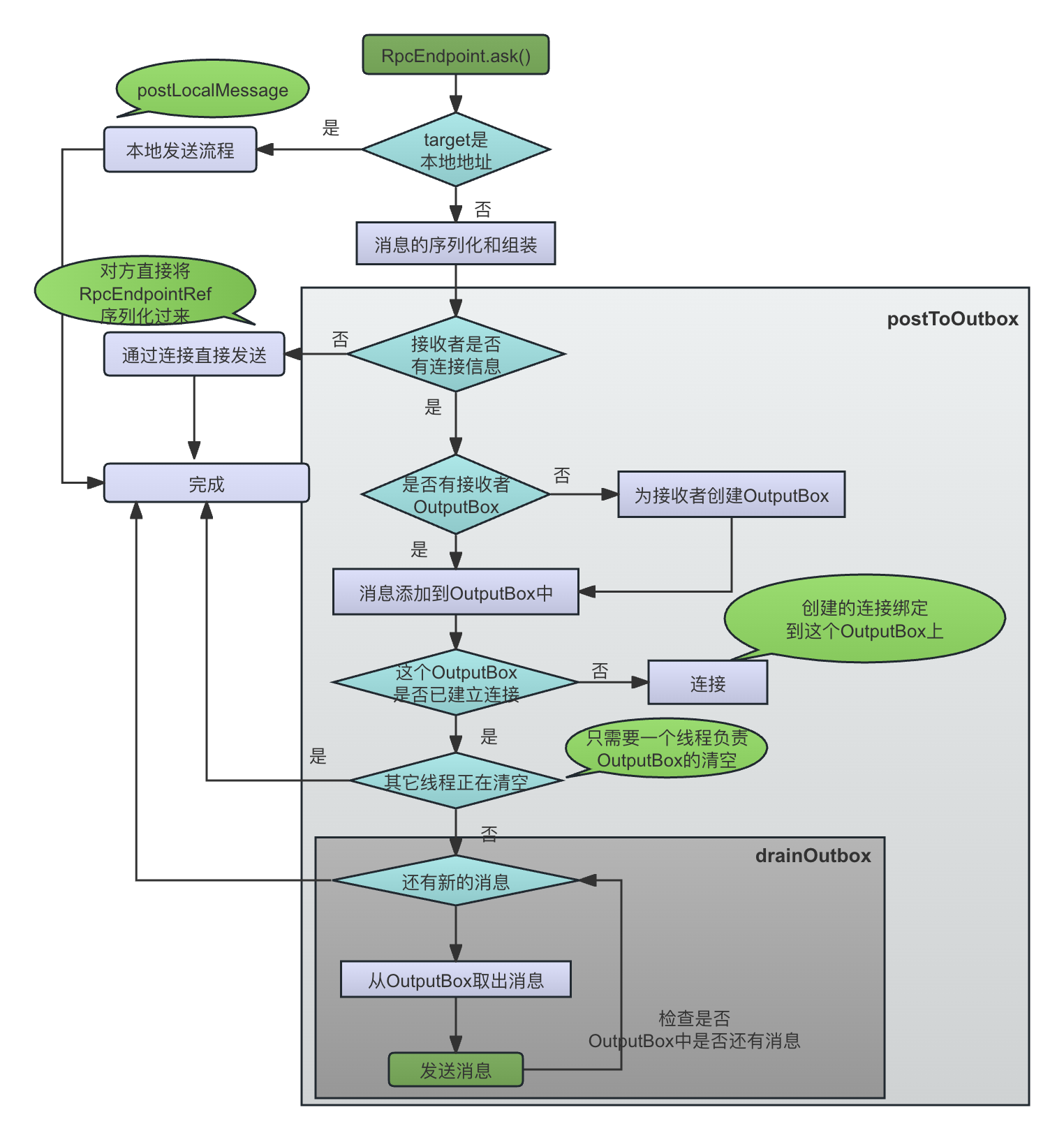
可以看到:
ask() 方法接收的待发送消息是一个RequestMessage对象,一个RequestMessage对象中包含了发送者本身的RpcAddress、接收者的RpcEndpointRef(对应了接收方的RpcEndpoint)和尚未序列化的消息体(一个对象)。
-
首先,方法定义了onSuccess()和onFailure()两个回调函数,代表发送成功和失败以后的操作。
-
然后,比较接收方的地址是不是就是本地,如果是本地,调用dispatcher.postLocalMessage()方法来进行本地的消息传递:
if (remoteAddr == address) { // 如果是本地地址 ..... dispatcher.postLocalMessage(message, p) }在TODO中讲过,调用RpcEndpointRef的ask()方法的进程可能和RpcEndpoint在一起的,比如,TaskScheduler和Driver是运行在一起的,TaskScheduler的一些调度决策需要依赖Driver进行处理,比如ReviveOffers(可用资源更新触发任务调度),KillTask(杀死一个Task)等,这时候也是同一套通信模式,即通过持有的DriverEndpointRef发送消息给Driver,Driver进行响应的处理。
这里的dispatch对象是NettyRpcEnv的成员变量,本来是负责消息接收以后的分派的,但是由于消息的发送者和接收者属于同一个NettyRpcEnv,因此直接调用Dispatcher的postLocalMessage()方法传递进程内的本地消息。 -
如果不是本地地址,则使用正常的基于Netty的RPC通信进行发送。首先会进行消息的序列化:
val rpcMessage = RpcOutboxMessage(message.serialize(this),// 序列化 onFailure, // 发送成功以后的回调 (client, response) => onSuccess(deserialize[Any](client, response)))即调用RequestMessage的序列化函数serialize(),这个函数的参数是当前NettyRpcEndpointRef中的RpcEnv,返回序列化完成的一个ByteBuffer:
def serialize(nettyEnv: NettyRpcEnv): ByteBuffer = { val bos = new ByteBufferOutputStream() val out = new DataOutputStream(bos) try { writeRpcAddress(out, senderAddress) // 写入RPC地址 writeRpcAddress(out, receiver.address) // 写入接收者的地址 out.writeUTF(receiver.name) // 写入接受者的名字 val s = nettyEnv.serializeStream(out) try { s.writeObject(content) // 写入对象 } finally { s.close() } } finally { out.close() } bos.toByteBuffer }从上面的序列化方法可以看到,这个序列化方法会依次写入如下信息:
- 写入发送者的RPC地址信息。
- 这里的地址,是这个发送者的RpcEnv的监听地址,所以,只有当发送者的RpcEnv是以Cluster模式运行即启动了端口监听的时候,才会有senderAddress。如果RpcEnv是以Client模式启动,senderAddress就是空的。我们看NettyRpcEnv的address就可以看出来。这个senderAddress会在发送的时候用来构造RequestMessage:
// 只有在Cluster模式下才需要启动对应端口,才会有对应的TransportServer server @Nullable override lazy val address: RpcAddress = { if (server != null) RpcAddress(host, server.getPort()) else null }
- 这里的地址,是这个发送者的RpcEnv的监听地址,所以,只有当发送者的RpcEnv是以Cluster模式运行即启动了端口监听的时候,才会有senderAddress。如果RpcEnv是以Client模式启动,senderAddress就是空的。我们看NettyRpcEnv的address就可以看出来。这个senderAddress会在发送的时候用来构造RequestMessage:
- 写入接收者(当前的RpcEndpointRef对应的远程的RpcEndpoint)的RPC地址信息,
- 写入接收者(当前的RpcEndpointRef对应的远程的RpcEndpoint)的名字,这个名字决定了接收方在收到消息以后将消息分派给正确的接收者RpcEndpoint
- 写入消息体content。很显然,这个content必须是serializable的。
- 写入发送者的RPC地址信息。
-
完成了消息的序列化以后,将序列化的消息进一步封装成为RpcOutboxMessage对象。一个RpcOutboxMessage对象封装了序列化的消息以及发送失败或者成功的回调函数:
val rpcMessage = RpcOutboxMessage(message.serialize(this), onFailure, // 发送成功以后的回调 (client, response) => onSuccess(deserialize[Any](client, response)))这是RpcOutboxMessage对象的实现:
-------------------------------------------- RpcOutboxMessage ----------------------------------------- private[netty] case class RpcOutboxMessage( // 需要发送的已经进行了序列化的消息 content: ByteBuffer, // 发送失败的回调 _onFailure: (Throwable) => Unit, // 发送成功的回调 _onSuccess: (TransportClient, ByteBuffer) => Unit) -
然后,调用NettyRpcEndpoint的postToOutbox()方法,进行消息的发送。这里可以看到,整个消息发送的模式是一个基于队列的异步模式,而不是简单的同步发送。所以这里消息发送并不是真的把消息发出去,而是把消息放入到一个OutputBox中,随后会有其他线程异步发送。
// receiver就是RequestMessage中对应的 NettyRpcEndpoingRef postToOutbox(message.receiver, rpcMessage) -
发送完毕以后,返回对应的Future句柄供调用者获取通信结果:
promise.future.mapTo[T].recover(timeout.addMessageIfTimeout)(ThreadUtils.sameThread)
可以看到,消息发送的时候,会将消息组装成一个RpcOutputMessage对象,然后通过调用postToOutbox() 进行异步、批量发送。
顾名思义,一个Outbox是一个或者多个消息的集合,这些消息都是发送到一个远程的客户端的,每一条消息对应了一个OutboxMessage。
下图显示了每一个OutputBox和远程的一个RpcEndpoint对应:
为什么只有Cluster模式下连接过来的RpcEndpoint才会有OutputBox?
-
可以看到,在RpcEndpoint A发送消息给RpcEndpoint B的时候,如果RpcEndpoinRef B中没有Transport,那么消息会先放入到RpcEndpoint B的OutputBox中再一起发送。如果有,那么是通过RpcEndpointRef B所包含的Transport直接发送,没有经过OutputBox。
其实无论是通过OutputBox发送还是通过对方的RpcEndpointRef直接发送,整个通信模式没有任何区别,区别仅仅在于对方的Transport连接是放在对应的OutputBox中还是RpcEndpointRef中。但是,如果我们持有的RpcEndpointRef中有Transport信息,说明这个RpcEndpointRef是对方主动发送过来的,一般情况下,这说明是对方主动和我方建立的连接,很有可能,对方是Client的RpcEnv模式。
因此,从对方的角度考虑,为其构建OutputBox似乎没有太多的必要。因为对方B是Client模式启动,对方的RpcEnv基本上只处理这一个连接(比如,Executor端用来和Driver通信的RpcEnv基本上只维护了和这个Driver的通信链接),因此没有必要考虑消息的批量发送和对方的处理能力,对方大概率是由独立线程处理这个连接消息,而不是像一个Cluster模式启动的RpcEnv,通过一个几十个线程的线程池处理成百上千的连接故而需要考虑效率。
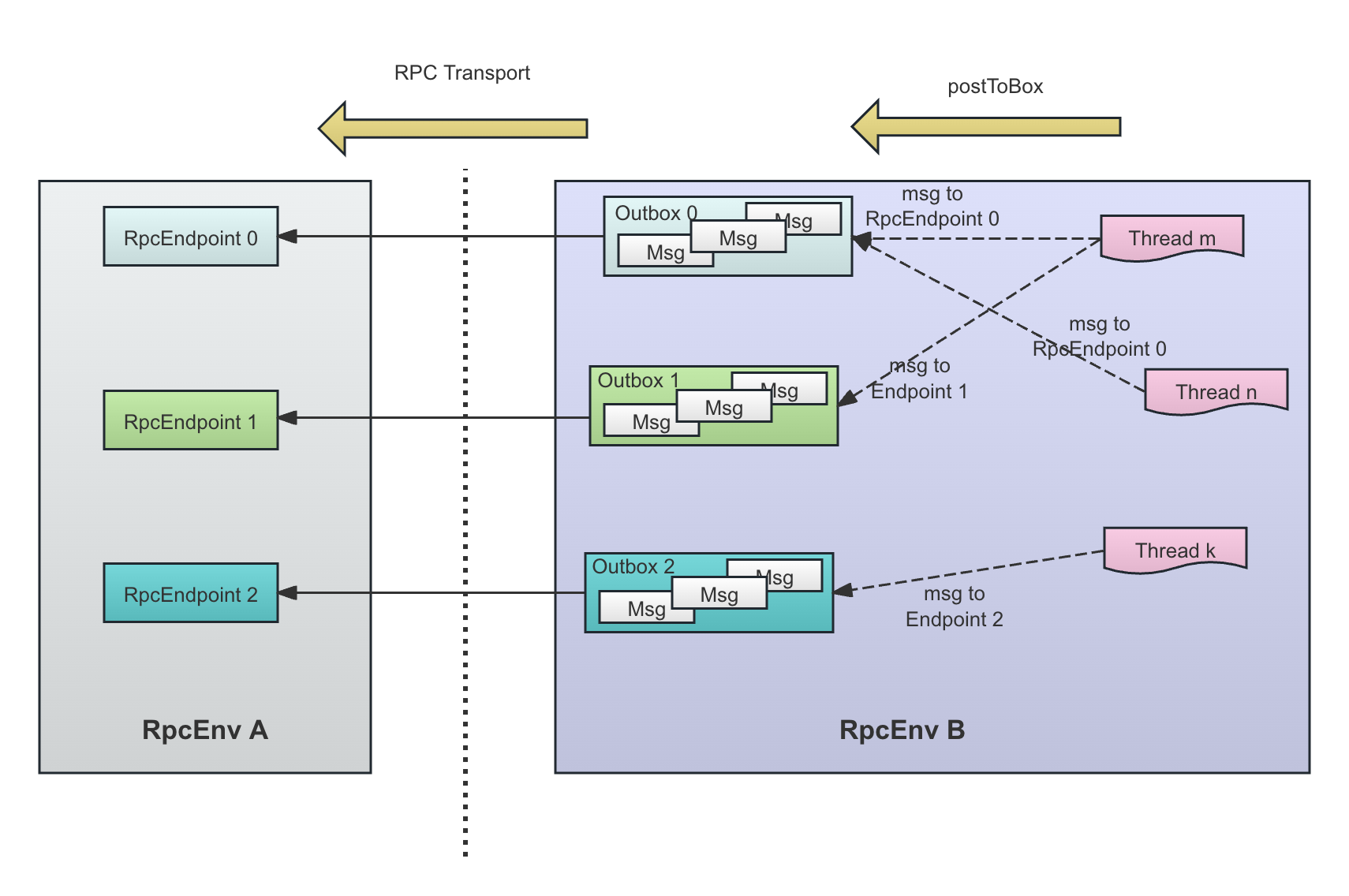
为什么每条消息不直接发送,而是先放入到自己对应的Outbox中呢?
- 这是为了降低连接数,保证两个RpcEnv之间只有一个连接(Spark中一个TransportClient代表了一个连接)。客户端通过RpcEndpoingRef发送消息的时候,这些消息可能来自多个线程,但是,我们和一个远程的RpcEndpoint通信的时候,需要做到,即使有很多的线程,我们只应该为一对Peer创建一个TransportClient,即一个通信信道。所以可以猜到,通信信道的创建必须是线程安全的。在基于一个通信信道的通信时,在消息数量很多的情况下,一个线程获得了发送锁,就干脆一次性完全发送完对应的这个endpoint的OutputBox中的所有的OutputBoxMessage:
下面就是postToOutbox()方法的具体实现,即基于队列的异步发送:
------------------------------------------------ NettyRpcEnv --------------------------------------------------
private def postToOutbox(receiver: NettyRpcEndpointRef, message: OutboxMessage): Unit = {
// 如果接收方的client变量不为空
if (receiver.client != null) {
// 保存这个client变量在 Outbot Message中,然后发送出去,这里会使用保存在这个NettyRpcEndpointRef中的TransportClient把消息发送出去
message.sendWith(receiver.client)
} else { // 如果receiver.client为空,那么receiver.address不可以为空
.....
val targetOutbox = {
// 获取这个receiver的Output的list
val outbox = outboxes.get(receiver.address)
if (outbox == null) {
// 为这条消息创建一个Outbox
val newOutbox = new Outbox(this, receiver.address)
val oldOutbox = outboxes.putIfAbsent(receiver.address, newOutbox)
if (oldOutbox == null) {
newOutbox
} else {
oldOutbox
}
} else {
outbox
}
}
targetOutbox.send(message) // 通过Output发送这个Outbox Message
}
}
该方法的基本流程是:
- 首先判断这个RpcEndpointRef中是否已经有了对应的连接,即一个TransportClient对象。如果有,那么是不走Outbox的流程的,直接将消息发送出去:
我们下文会讲到,在什么情况下一个RpcEndpointRef中会直接持有了远程的消息接收方(即这个RpcEndpointRef)对应的RpcEndpoint的连接信息。总之,在这里,当我们发现RpcEndpointRef已经有了连接信息,那么不走Outbox渠道,直接使用这个RpcEndpointRef中的TransportClient将消息发送出去。if (receiver.client != null) { // 保存这个client变量在 Outbot Message中,然后发送出去,这里会使用保存在这个NettyRpcEndpointRef中的TransportClient把消息发送出去 message.sendWith(receiver.client) - 如果这个RpcEndpointRef中没有client信息,这说明接收方是一个在某个固定端口监听的服务,因此,这时候开始走Outbox通道。上文说过,一个Outbox中存放了需要发送到远程的某个固定服务的消息集合,这些消息可能被某个发送线程一次性全部清空并发送出去,而不是每一个发送线程各自负责自己的消息。通过Outbox渠道发送的渠道,每一个Outbox都会维护一个TransportClient,负责这个Outbox中的所有消息的发送。
// 获取这个receiver的Output的list val outbox = outboxes.get(receiver.address) if (outbox == null) { // 为这条消息创建一个Output val newOutbox = new Outbox(this, receiver.address) val oldOutbox = outboxes.putIfAbsent(receiver.address, newOutbox) - 然后,调用这个对应的Outbox的send方法,准备发送消息。其实就是将消息存放到这个Outbox中,然后尝试清空这个Outbox中的所有消息。
targetOutbox.send(message)
下面的方法就是Outbox的send()方法,用来将属于这个Outbox的消息放入这个 Outbox,然后尝试进行一次性发送:
def send(message: OutboxMessage): Unit = {
synchronized { // 放入消息的过程必须线程安全
.....
messages.add(message)
}
drainOutbox() // 清空这个Output中所有的Message,即尝试全部一次性发送
}
drainOutbox()方法如果发现连接还没有建立,则会建立连接,然后尝试将Outbox中的所有的OutboxMessage一次性发送出去。
前面说过,一个Outbox中的所有OutboxMessage肯定是发往同一个远程的RpcEnv的。
private def drainOutbox(): Unit = {
var message: OutboxMessage = null
// 标记为draining,其它线程发现这个状态以后,直接退出,让当前获得锁的线程一次性发送消息
synchronized {
....
if (client == null) {
// There is no connect task but client is null, so we need to launch the connect task.
launchConnectTask() // 如果当前还没建立连接,那么需要先建立一个长连接
return
}
if (draining) {
// There is some thread draining, so just exit
return
}
.....
draining = true
}
while (true) {
val _client = synchronized { client }
message.sendWith(_client)
synchronized {
// 不断取出新的消息进行发送
message = messages.poll()
if (message == null) {
draining = false // 消息已经发送完毕
return
}
}
}
}
关键看一下上面的synchronized过程。可以看到,连接建立的过程以及从Outbox中取出消息的过程处在两个不同的synchronized代码块中。
-
如果还没有为当前的Outbox建立一个TransportClient,则通过方法launchConnectTask()同远程的RpcEnv建立连接:
if (client == null) { // There is no connect task but client is null, so we need to launch the connect task. launchConnectTask() // 如果当前还没建立连接,那么需要先建立一个长连接 return } -
并且,通过变量draining,保证一个线程在尝试清空并发送当前的Outbox中的消息的时候,其它线程会立刻退出方法,避免重复工作。这里的含义是,其它线程只是将消息放进Outbox,而不负责消息的发送:
if (draining) { // There is some thread draining, so just exit return } -
进入了消息发送的同步代码块的线程会反复检查并发送OutBox的所有消息直到清空。由于在synchronized代码块中,其它线程此时不可能在操作这个Outbox,也不可能也在进行消息发送:
synchronized { .... // 不断取出新的消息进行发送 message = messages.poll() ..... } -
所有消息发送完毕以后,draining置位false,退出同步代码块。此时其它线程就可以往Outbox中添加消息,并且如果获得了这个同步代码块的同步锁,就可以负责消息的发送
if (message == null) { draining = false // 消息已经发送完毕 return }
从上面可以看到,当NettyRpcEndpointRef中没有携带对应的TransportClient的时候,Outbox就会创建一个专门用来发送这个Outbox中所有消息的TransportClient,即一个RPC连接。跟踪代码我们可以看到,其实就是一个Netty客户端创建的基本流程,并且使用了连接池,以实现连接复用以降低连接建立的开销。
同时,我们可以看到,在创建连接的时候设置SO_KEEPALIVE为true,即客户端不会主动关闭连接,而是保持住连接。我们上文说过,NettyRpcEnv可能以Cluster模式也可能以Client模式启动。即使以Client模式启动,由于连接建立的时候客户端是KEEPALIVE的,因此,远程的接收方只要持续的持有这个通信信道,就可以向远程的以Client模式启动的NettyRpcEnv了。再次重申,Client模式与Cluster模式的区别是:
- 这个连接的建立必须是客户端主动发起。即,通信信道必须是这个以Client模式启动的NettyRpcEnv主动向远程的某一个以Cluster模式启动固定NettyRpcEnv发起连接,然后这个以Cluster模式启动的NettyRpcEnv保存好这个通信信道以进行后续的通信。
- 这个连接不可能被其它客户端共享,即,客户端NettyRpcEnv以Client模式连接到远程的NettyRpcEnv,因此这个通信信道在客户端和远程都有对应的端口号,但是第三方无法通过客户端的这个端口连接到这个以Client模式启动的NettyRpcEnv。但是以Cluster模式启动的NettyRpcEnv,却可以接受很多的连接。
消息的接收
上面已经说过,消息接收的处理逻辑是RpcEndpoint来定义的。即,RpcEndpoint的职责是定义以下两个内容:
- 指定我所关心的是哪个类别的消息。这是通过将自己注册给所在的RpcEnv实现的;
- 收到指定消息点以后的处理逻辑。
上文讲过,Spark中根据业务需要实现了各种RpcEndpoint,比如Driver端的DriverEndpoint、ApplicationMaster端的YarnSchedulerEndpoint、Executor端的CoarseGrainedExecutorBackend。我们以DriverEndpoint为例,讲述其注册、消息的反序列化、处理的基本流程。
从RpcEndpoint收到的原始消息是被NettyRpcHandler处理的。
我们看一下NettyRpcHandler收到消息以后的处理过程:
----------------------------------------------------- NettyRpcHandler ---------------------------------------------
override def receive(
client: TransportClient,
message: ByteBuffer,
callback: RpcResponseCallback): Unit = {
val messageToDispatch = internalReceive(client, message)
dispatcher.postRemoteMessage(messageToDispatch, callback)
}
可以看到,在收到了原始消息以后:
- 通过调用internalReceive()方法,将消息解析和反序列化,并封装为一个RequestMessage对象。这个RequestMessage对象包含了消息反序列化以后的结果:
private[netty] class RequestMessage( val senderAddress: RpcAddress, // 发送方的RpcAddress,包括发送方的地址和端口 val receiver: NettyRpcEndpointRef, // 接收方(自己) 的NettyRpcEndpoingRef val content: Any) { // 将ByteBuffer消息进行反序列化以后的结果 - 使用dispatcher进行消息的分发,即,将消息分发给应该接收该消息的对应的RpcEndpoint中去:
消息派发的具体流程我们将在下文将Dispatcher中详细讲解。dispatcher.postRemoteMessage(messageToDispatch, callback)
刚刚说过,internalReceive()最重要的是进行了消息的反序列化,我们看看其具体实现:
------------------------------------------------ NettyRpcHandler ------------------------------------------------
private def internalReceive(client: TransportClient, message: ByteBuffer): RequestMessage = {
// 收到消息以后,获取这个channel的socket address
val addr = client.getChannel().remoteAddress().asInstanceOf[InetSocketAddress]
val clientAddr = RpcAddress(addr.getHostString, addr.getPort)
val requestMessage = RequestMessage(nettyEnv, client, message)
if (requestMessage.senderAddress == null) { // 发送方的senderAddress是null,说明发送方是Client模式启动的NettyRpcEnv
new RequestMessage(clientAddr, requestMessage.receiver, requestMessage.content)
} else { // 发送方的senderAddress不是null,说明发送方是Cluster模式启动的NettyRpcEnv
val remoteEnvAddress = requestMessage.senderAddress // 取出senderAddress
// 当收到远程的一个消息,那么就记录这个remoteAddress
if (remoteAddresses.putIfAbsent(clientAddr, remoteEnvAddress) == null) {
dispatcher.postToAll(RemoteProcessConnected(remoteEnvAddress)) // 第一次收到这个remoteAddress的消息,就给所有的RpcEndpoint进行广播
}
requestMessage
}
}
internalReceive()这段代码的基本逻辑是对ByteBuffer中的数据进行反序列化,然后构造出RequestMessage对象。
上面讲过,一个RequestMessaged对象应该含有发送者的RpcAddress信息、接收者的RpcEndpointRef信息以及消息反序列化以后的对象。这三个信息的作用分别为:
- 发送者的RpcAddress主要用来在这个发送者第一次连接过来,会将这个发送者的信息广播给当前接收者的RpcEnv中注册的所有的RpcEndpoint;
- 接收者(自己)的RpcEndpointRef,Dispatcher将根据RpcEndpointRef中的RpcEndpoint信息将消息交付给RpcEnv中正确的RpcEndpoint;
- 反序列的消息体就不必说,即消息本身。反序列化会将消息还原成在远程序列化以前的对象。
所以,总的说来,消息经过反序列化并封装成RequestMessage,基本上包含了发送者、接收者和消息体三个基本要素。
因此,理解internalReceive()这段代码的关键是看看这三项信息的来源。
- 从通信信道中解析出对应的InetSocketAddress,并从中提取出发送者的RpcAddress:
val addr = client.getChannel().remoteAddress().asInstanceOf[InetSocketAddress] assert(addr != null) val clientAddr = RpcAddress(addr.getHostString, addr.getPort) - 构造出对应的RequestMessage:
- RequestMessage中的sendAddress来自消息流的Header。查看上文所讲解的消息发送的序列化过程,可以知道消息的头部格式。
// 读取存放在消息头中的发送者的地址,即发送者在发送消息的时候,会将对应的RpcEndpoint的address放在消息头中 val senderAddress = readRpcAddress(in) - RequestMessage中的RpcEndpointRef中的endpoint地址和endpoint名字也都来自消息流中的头部。查看上文将消息发送的序列化过程了解消息的头部格式。
// 接受者的地址和接收者的名字,也是发送者在发送消息的时候,会将接收者的地址放在第二个消息头里,随后是接收者的名字 val endpointAddress = RpcEndpointAddress(readRpcAddress(in), in.readUTF()) val ref = new NettyRpcEndpointRef(nettyEnv.conf, endpointAddress, nettyEnv) - 将channel中解析的TransportClient放入到刚刚构造的RpcEndpointRef中
- 构造对应的RequestMessage
new RequestMessage( senderAddress, // 从消息头中读取到的发送者的地址信息,有可能为空,如果为空,则从client中提取 ref, // The remaining bytes in `bytes` are the message content. // 在bytes中剩下的部分就是消息体部分,需要进行解码 nettyEnv.deserialize(client, bytes))
- RequestMessage中的sendAddress来自消息流的Header。查看上文所讲解的消息发送的序列化过程,可以知道消息的头部格式。
- 如果RequestMessage中的sendAddress是空的,那么就通过解析当前的通信信道的发送方地址来构造sendAddress:
上文讲过,只有当发送者的RpcEnv是以Cluster模式运行即启动了端口监听的时候,才会有senderAddress。如果RpcEnv是以Client模式启动,senderAddress就是空的。这时候接收方需要以通信信道中获取对应的地址作为senderAddress。if (requestMessage.senderAddress == null) { new RequestMessage(clientAddr, requestMessage.receiver, requestMessage.content) - sendAddress的作用很简单,就是当我们第一次收到某一个RpcAddress的消息的时候,会向当前RpcEnv的所有RpcEndpoint进行广播,即发送一个RemoteProcessConnected消息告知所有的RpcEndpoint这个新的remote process,对应的RpcEndpoint可以在callback 方法onConnected()中收到通知。与之对应的,当远程的某一个RpcEnv断开连接,会有广播消息RemoteProcessDisconnected通过RpcEndpoint的callback方法onDisconnected()通知所有的RpcEndpoint:
if (remoteAddresses.putIfAbsent(clientAddr, remoteEnvAddress) == null) { dispatcher.postToAll(RemoteProcessConnected(remoteEnvAddress)) // 通过postToAll,广播一个全新的RpcEndpointRef连接进来 }
RpcEndpointRef的构造方式
上文讲过,生成一个远程的RpcEndpoint的RpcEncpointRef有两种方式:
- 调用RpcEnv的setupEndpointRef()方法,我们提供对应的远程的RpcEndpoint地址和名字,返回远程的RpcEndpoint的RpcEndpointRef
- 发送者直接将自己的RpcEndpointRef作为消息的一部分发送给远程,接收者的NettyRpcEnv在收到消息以后,反序列化的过程中,自动帮我们反序列化RpcEndpointRef,并将对应的TransportClient设置到RpcEndpointRef中,就好像这个RpcEndpointRef中包括网络通信在内的东西也可以序列化和反序列化一样。
直接通过RpcEndpoint构造RpcEndpointRef
在知道了远程的RpcEndpoint的RpcAddress和对应的Endpoint 的名字以后,我们可以通过RpcEnv提供的方法直接构造远程的RpcEndpoint的RpcEndpointRef:
def setupEndpointRef(address: RpcAddress, endpointName: String): RpcEndpointRef = {
setupEndpointRefByURI(RpcEndpointAddress(address, endpointName).toString)
}
比如, Yarn上的ApplicationMaster启动以后,需要向Driver注册,因此需要构造远程的Driver的RpcEndpointRef:
private def createSchedulerRef(host: String, port: String): RpcEndpointRef = {
rpcEnv.setupEndpointRef( // 设置Driver的Endpoint Reference
RpcAddress(host, port.toInt),
YarnSchedulerBackend.ENDPOINT_NAME)
}
显然,这种方式构造的RpcEdnpointRef中包含了远程的RpcEndpoint的连接信息。我们在讲消息发送的时候说过,这时候,发送端是为这个Endpoint的所有消息统一构建对应的TransportClient进行批量发送。
通过消息发送RpcEndpointRef
消息的发送者也可以将RpcEndpointRef作为消息的一部分发送给消息的接收者,我们上面说过,NettyRpcEndpointRef是声明为Serializable的,因此可以被序列化。
在这种情况下,NettyRpcEndpointRef 的处理比较特殊:消息的接收者收到的反序列化的NettyRpcEndpointRef对象中自动包含了双方的连接(即长连接),因此客户端可以直接通过这个反序列化的NettyRpcEndpointRef发送消息。这里的连接就是client: TransportClient对象:
private[netty] class NettyRpcEndpointRef(
@transient private val conf: SparkConf,
private val endpointAddress: RpcEndpointAddress, // 这个RpcEndpointRef对应的RpcEndpoint的地址
@transient @volatile private var nettyEnv: NettyRpcEnv) // 这个RpcEndpointRef对应的RpcEndpoint的RpcEnv的地址,即远程的那个RpcEndpointRef
extends RpcEndpointRef(conf) {
// 声明为transient,表示该字段属于NettyRpcEndpointRef中不可以被序列化的字段
@transient @volatile var client: TransportClient = _
可以看到,client变量是一个RPC 连接,显然无法被序列化和反序列化,因此声明为了transient。那么,NettyRpcEndpointRef是怎么被序列化和反序列化,并且反序列化的NettyRpcEndpointRef中又包含了RPC 连接的呢?
先理解为什么需要这样:
我们上文说过,NettyRpcEnv在构造的时候存在一种Client模式,这种模式的NettyRpcEnv并不打开端口监听,这意味着远程的任何进程无法主动连接到以Client模式打开的RpcEnv,只能是这个以Client模式启动的RpcEnv主动连接到远程的某一个以Cluster模式打开的NettyRpcEnv。远程的以Cluster模式打开的NettyRpcEnv收到消息以后,保存这个长连接并复用这个长连接进行双方的通信,以便在后来随时向这个以Client模式打开的RpcEnv发送消息,就好像这个以Client模式打开的RpcEnv存在一个监听端口一样。
这个通信信道怎么保存的?就是通过传递NettyRpcEndpointRef来进行的。我们知道,普通对象的序列化和反序列化是没有问题的,但是TCP连接显然是无法序列化和反序列化的。那么,NettyRpcEndpointRef在反序列化完成以后,是怎么包含了当前的连接信息的呢?
上面讲过,在收到消息以后,会调用RequestMessage.apply()进行消息的反序列化,其实是调用NettyRpcEnv.deserialize()
--------------------------------------------------- RequestMessage -------------------------------------------------
def apply(nettyEnv: NettyRpcEnv, client: TransportClient, bytes: ByteBuffer): RequestMessage = {
......
new RequestMessage(
senderAddress, // 从消息头中读取到的发送者的地址信息,有可能为空,如果为空,则从client中提取
ref,
// The remaining bytes in `bytes` are the message content.
// 在bytes中剩下的部分就是消息体部分,需要进行解码
nettyEnv.deserialize(client, bytes))
....
}
}
我们看到,反序列化的时候传入了当前的连接信息TransportClient client:
--------------------------------------------------- NettyRpcEnv ---------------------------------------------------
private[netty] def deserialize[T: ClassTag](client: TransportClient, bytes: ByteBuffer): T = {
NettyRpcEnv.currentClient.withValue(client) { // 临时将currentClient设置为当前的client对象,方法执行结束以后恢复原值
deserialize { () =>
javaSerializerInstance.deserialize[T](bytes)
}
}
反序列化时,通过withValue()将NettyRpcEnv的currentClient设置为当前的连接,然后进行消息的反序列化。如果消息中含有NettyRpcEndpointRef对象,那么就会对NettyRpcEndpointRef反序列化,即NettyRpcEndpointRef的readObject()方法会被调用:
------------------------------------------------ NettyRpcEndpointRef ----------------------------------------------
/**
* 自定义反序列化方法,用来进行反序列化NettyRpcEndpointRef对象
*/
private def readObject(in: ObjectInputStream): Unit = {
in.defaultReadObject()
nettyEnv = NettyRpcEnv.currentEnv.value // 设置NettyRpcEnv
client = NettyRpcEnv.currentClient.value // 设置自己的TransportClient
}
可以看到,NettyRpcEndpointRef重写了readObject()方法,主要是设置了自己的TransportClient,即将当前的TransportClient偷偷保存在了自己的client中。这样,消息的接收者受到的反序列化的NettyRpcEndpointRef的client中就是当前的长连接。持有反序列化的RpcEndpointRef的调用者在调用NettyRpcEndpointRef.ask()发送消息的时候,下层的postToOutbox()方法就直接使用它持有的长连接发送消息,而不用走Output的消息发送渠道。
而NettyRpcEndpointRef在序列化的时候并没有任何特殊处理逻辑:
------------------------------------------------ NettyRpcEndpointRef ----------------------------------------------
/**
* 自定义序列化方法,用来序列化NettyRpcEndpointRef对象
*/
private def writeObject(out: ObjectOutputStream): Unit = {
out.defaultWriteObject()
}
总而言之:
- 为了能让RpcEndpoint能主动给远程的以Client模式启动的RpcEnv发送消息,需要在收到远程的以Client模式启动的RpcEnv发送过来的请求以后保存这个长连接
- 这个长连接会在反序列化的过程中偷偷保存到反序列化的NettyRpcEndpointRef中,看起来就好像RPC Connection也被序列化和反序列化一样
- 在使用NettyRpcEndpointRef发送消息的时候,如果其已经保存了客户端连接,那么直接使用这个连接发送消息。否则,只能建立连接,但是显然,主动和远程建立连接的前提是,远程的RpcEnv是以Cluster模式启动。
在Spark中,典型的场景是ApplicationMaster通过RegisterClusterManager消息向Driver注册自己,以及Executor通过RegisterExecutor向Driver注册自己。可以看到,这两个消息都封装了一个RpcEndpoingRef,这样,在收到连接请求以后,Driver就可以在任何时候主动和Executor和ApplicationMaster进行通信:
----------------------------------------- YarnSchedulerBackend --------------------------------------------
override def receive: PartialFunction[Any, Unit] = {
case RegisterClusterManager(am) => // 收到ApplicationMaster启动的时候发过来的RegisterClusterManager请求
logInfo(s"ApplicationMaster registered as $am")
amEndpoint = Option(am) // 收到了远程的AM的注册信息,设置这个am的RpcEndpointRef
reset()
同理,Executor注册的时候,会发送RegisterExecutor消息给DriverEndpoint,DriverEndpoint收到消息以后,已经获取了解码完成、设置了当前连接的对应的Executor的RpcEndpointRef:
--------------------------------------------- CoarseGrainedcClusterMessage -------------------------------------
// Executors to driver
case class RegisterExecutor(
executorId: String,
executorRef: RpcEndpointRef,
hostname: String,
cores: Int,
logUrls: Map[String, String])
extends CoarseGrainedClusterMessage
------------------------------------------------ DriverEndpoint -----------------------------------------------
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
// 收到 RegisterExecutor 请求,这个请求发生在Executor启动以后,向Driver发送的信息
case RegisterExecutor(executorId, executorRef, hostname, cores, logUrls) =>
if (executorDataMap.contains(executorId)) {
executorRef.send(RegisterExecutorFailed("Duplicate executor ID: " + executorId))
context.reply(true)
Endpoint的注册
上面讲过RpcEnv的构建过程,包括RpcEnv中的Cluster模式和Client模式的区别。
无论以什么模式启动,对应的RpcEndpoint必须首先向RpcEnv注册自己,才有可能受到消息。因为RpcEnv就像一个消息总线,只有注册到了RpcEnv,RpcEnv才会根据策略将消息交付给注册的RpcEndpoint。
比如,在TODO中讲过,在Driver启动的时候,会将DriverEndpoint注册到自己的RpcEnv:
------------------------------------------- CoarseGrainedSchedulerBackend ----------------------------------------------
protected def createDriverEndpointRef(
properties: ArrayBuffer[(String, String)]): RpcEndpointRef = {
rpcEnv.setupEndpoint(ENDPOINT_NAME, createDriverEndpoint(properties))
}
这里的RpcEnv还是NettyRpcEnv,具体实现如下。上面将RpcEnv的setupEndpoint()方法讲过,该方法接收一个RpcEndpoint对象和对应的名字,返回这个RpcEndpoint对应的RpcEndpointRef:
------------------------------------------------ NettyRpcEnv ----------------------------------------------
override def setupEndpoint(name: String, endpoint: RpcEndpoint): RpcEndpointRef = {
dispatcher.registerRpcEndpoint(name, endpoint)
}
实际上是调用Dispatcher的registerRpcEncdpoint()方法,即,将当前的RpcEndpoint注册给Dispatcher,注册以后得RpcEndpoint,才会收到来自Dispatcher所分派的消息:
------------------------------------------------ Dispatcher -------------------------------------------------
def registerRpcEndpoint(name: String, endpoint: RpcEndpoint): NettyRpcEndpointRef = {
val addr = RpcEndpointAddress(nettyEnv.address, name)
val endpointRef = new NettyRpcEndpointRef(nettyEnv.conf, addr, nettyEnv)
synchronized {
// 不可重复注册
if (endpoints.putIfAbsent(name, new EndpointData(name, endpoint, endpointRef)) != null) {
throw new IllegalArgumentException(s"There is already an RpcEndpoint called $name")
}
val data = endpoints.get(name)
endpointRefs.put(data.endpoint, data.ref)
receivers.offer(data) // for the OnStart message
}
endpointRef // 返回这个endpoint对应的reference
}
从上面的代码可以看到,这个RpcEnd的注册其实是委托给Dispatcher进行的。注册的基本过程是:
- 构造对应的RpcEndpointRef对象
- 将对应的RpcEndpoint保存在一个HashMap中,key就是RpcEndpoint的名字,value就是这个RpcEndpoint的相关信息构成的一个EndpointData对象。必须注意到,同一个name是不允许多次注册的。
- 将对应的RpcEndpointRef保存在一个HashMap中,key是这个RpcEndpoint,value是这个RpcEndpointRef对象
- 返回这个RpcEndpoint对应的RpcEndpointRef
因此,可以想见,这个Dispatcher负责消息的派发,对于收到的消息,应该是根据消息所请求的RpcEndpoint的名字,交付给对一个的RpcEndpoint进行处理.
Dispatcher
消息的投递
上面讲registerRpcEncdpoint()方法的时候,可以看到每一个RpcEndpoint都会有一个EndpointData对象与之对应,EndpointData中最重要的是一个消息队列Inbox,用来存放这个RpcEndpoint收到的、还没有交付(dispatch)给对应的RpcEndpoint的消息。这个Inbox与消息发送的时候的Outbox对应。
------------------------------------------------ Dispatcher -------------------------------------------------
private class EndpointData(
val name: String,
val endpoint: RpcEndpoint,
val ref: NettyRpcEndpointRef) {
val inbox = new Inbox(ref, endpoint)
}
上面说过,RpcEnv收到的原始消息交给NettyRpcHandler处理,在将消息封装为RequestMessage以后,就交给Dispatcher:
------------------------------------------------ NettyRpcEnv ----------------------------------------------
override def receive(
client: TransportClient,
message: ByteBuffer,
callback: RpcResponseCallback): Unit = {
val messageToDispatch = internalReceive(client, message)
dispatcher.postRemoteMessage(messageToDispatch, callback)
}
在Dispatcher.postRemoteMessage()中,会提取出接收方的endpointName,将对应消息组装成RpcMessage对象,投递到对应Endpoint的收件箱(Inbox):
------------------------------------------------ Dispatcher -------------------------------------------------
/** Posts a message sent by a remote endpoint. */
def postRemoteMessage(message: RequestMessage, callback: RpcResponseCallback): Unit = {
val rpcCallContext =
new RemoteNettyRpcCallContext(nettyEnv, callback, message.senderAddress)
val rpcMessage = RpcMessage(message.senderAddress, message.content, rpcCallContext)
postMessage(message.receiver.name, rpcMessage, (e) => callback.onFailure(e))
}
- 构造了RpcCallContext:我们在上面介绍RpcEndpoint的receiveAndReply()方法的时候说过,RpcCallContext对象是进行消息回复的句柄。从RpcCallContext的构造方法可以看到,它包含了接收者的NettyRpcEnv,消息回复以后的回调,以及发送者的地址信息:
val rpcCallContext = new RemoteNettyRpcCallContext(nettyEnv, callback, message.senderAddress) - 构造RpcMessage:可以看到,一个RpcMessage对象封装了RequestMessage中的发送者地址,消息体(已经反序列化完成),以及刚刚构造的RpcCallContext。
val rpcMessage = RpcMessage(message.senderAddress, message.content, rpcCallContext) - 调用postMessage进行消息的派发
postMessage(message.receiver.name, rpcMessage, (e) => callback.onFailure(e))
postMessage()方法进行消息分发的基本过程就是根据RequestMessage中的接收者名字(即RpcEndpoint的名字),获取对应的Inbox,然后将这个消息投递到其对应的Inbox中:
------------------------------------------------ Dispatcher -------------------------------------------------
private def postMessage(
endpointName: String,
message: InboxMessage,
callbackIfStopped: (Exception) => Unit): Unit = {
val error = synchronized {
val data = endpoints.get(endpointName) // 获取对应的RpcEndpoint的EndpointData对象
.....
data.inbox.post(message) // 将消息放入的inbox中
receivers.offer(data) // 将这个inbox放入到receivers中,代表的含义是这个Inbox中有待处理的消息
None
}
}
}
- 先获取对应的Endpoint,进而取出这个Endpoint对应的EndpointData。上面讲过,EndpointData中最重要的就是一个Inbox对象,代表这个Endpoint所收到的但是还没有处理的消息。
val data = endpoints.get(endpointName) // 获取对应的RpcEndpoint的EndpointData对象 - 将消息投递到Inbox中,即这个RpcEndpoint的EndpointData的Inbox中:
data.inbox.post(message) // 将消息放入的inbox中 - 将这个消息的EndpointData放入到receivers中,其含义是,目前这个Receiver的Inbox中含有新消息,这样,后面在进行异步的消息处理的时候,就可以在一个线程里面尽可能一次性处理完这个Receiver的inbox里面的所有消息,而不是每次只处理一条消息。如果不这样,同一个Inbox的不同消息可能在线程池的不同线程中处理,由于同步的原因,消息处理的效率显然会很低。
一个Dispatcher对象含有一个receivers.offer(data) // 将这个inbox放入到receivers中,代表的含义是这个Inbox中有待处理的消息LinkedBlockingQueue[EndpointData] receivers,即一系列有新消息的Inbox的集合。
消息的处理
Dispatcher内部维护了一个线程池进行消息的异步处理。上面讲过,这个线程池中的线程会根据系统分配给当前角色的cpu数量决定线程池的并发度。线程池的的Task是一个叫做MessageLoop的Runnable:
---------------------------------------------------- Dispatcher --------------------------------------------------
/** Thread pool used for dispatching messages. */
private val threadpool: ThreadPoolExecutor = {
val availableCores =
if (numUsableCores > 0) numUsableCores else Runtime.getRuntime.availableProcessors()
val numThreads = nettyEnv.conf.getInt("spark.rpc.netty.dispatcher.numThreads",
math.max(2, availableCores)) // 智能决定线程池的并发度
val pool = ThreadUtils.newDaemonFixedThreadPool(numThreads, "dispatcher-event-loop")
for (i <- 0 until numThreads) {
pool.execute(new MessageLoop) // 提交MessageLoop这个Runnable,不断获取消息并进行派发
}
pool
}
线程池的每一个Runnable的实现类是MessageLoop:
---------------------------------------------------- MessageLoop --------------------------------------------------
/** Message loop used for dispatching messages. */
private class MessageLoop extends Runnable {
override def run(): Unit = {
while (true) {
try {
val data = receivers.take()
.....
data.inbox.process(Dispatcher.this)
}
}
}
}
一个MessageLoop线程在运行过程中:
- 取出一个receiver:上面讲过,收到一条消息,就会将对应的EndpointData存入到receivers中,代表这个EndpointData含有未处理的消息,这样做主要是为了避免对那些没有收到任何消息的Inbox进行不必要的检查,而是从receivers中取出一定含有未处理消息的RpcEndpoint的EndpointData:
val data = receivers.take() // 取出对应的EndpointData - 消息的处理:
data.inbox.process(Dispatcher.this)
Inbox.process()的基本过程,就是取出目前Inbox中的所有消息,交付给对应的Receiver(RpcEndpoint)的receive()方法(不需要回复)或者receiveAndReply()方法(需要回复)进行处理:
---------------------------------------------------- Inbox --------------------------------------------------
def process(dispatcher: Dispatcher): Unit = {
var message: InboxMessage = null
inbox.synchronized {
message = messages.poll()
numActiveThreads += 1
}
while (true) {
safelyCall(endpoint) {
message match {
case RpcMessage(_sender, content, context) =>
endpoint.receiveAndReply(context).applyOrElse[Any, Unit](content, { msg =>
throw new SparkException(s"Unsupported message $message from ${_sender}")
case OneWayMessage(_sender, content) =>
endpoint.receive.applyOrElse[Any, Unit](content, { msg =>
throw new SparkException(s"Unsupported message $message from ${_sender}")
})
case OnStart =>
.....
}
case OnStop =>
.....
}
}
inbox.synchronized {
message = messages.poll()
if (message == null) {
numActiveThreads -= 1
return
}
}
}
}
- 从消息队列中取出消息:
inbox.synchronized { message = messages.poll() numActiveThreads += 1 } - 根据消息类型是RpcMessage(需要回复的消息)还是OneWayMessage(不需要回复的消息),分别调用RpcEndpoint的receive()或者receiveAndReply()方法:
message match { case RpcMessage(_sender, content, context) => endpoint.receiveAndReply(context).applyOrElse[Any, Unit](content, { msg => throw new SparkException(s"Unsupported message $message from ${_sender}") case OneWayMessage(_sender, content) => endpoint.receive.applyOrElse[Any, Unit](content, { msg => throw new SparkException(s"Unsupported message $message from ${_sender}") }) - 继续尝试从Inbox中取出消息,如果还有消息,则继续上面的处理:
可以看到,inbox的处理是需要同步的,因此一个Inbox的消息的处理在多线程环境下会有竞争,因此最好在一个线程中一次性尽量处理完所有的消息,并且通过receivers,针对性的只处理有新消息的Inbox,避免对没有任何消息的receiver进行不必要的检查。inbox.synchronized { message = messages.poll() if (message == null) { numActiveThreads -= 1 return } }
引用
- 五分钟快速理解Reactor模型
- 彻底搞懂Reactor和Proactor模型