学习心得:探索Diffusion扩散模型
在我最近对生成模型的学习中,尤其是Diffusion模型,我发现这是一种极具潜力的技术,特别是在图像生成领域。Diffusion模型的核心概念是通过一个逐步的去噪过程,将纯噪声数据转换成有意义的图像数据。这种方法与我之前了解的GAN和VAE等生成模型有很大的不同,它提供了一种全新的方式来理解和生成数据。
1. Diffusion模型的基本理解
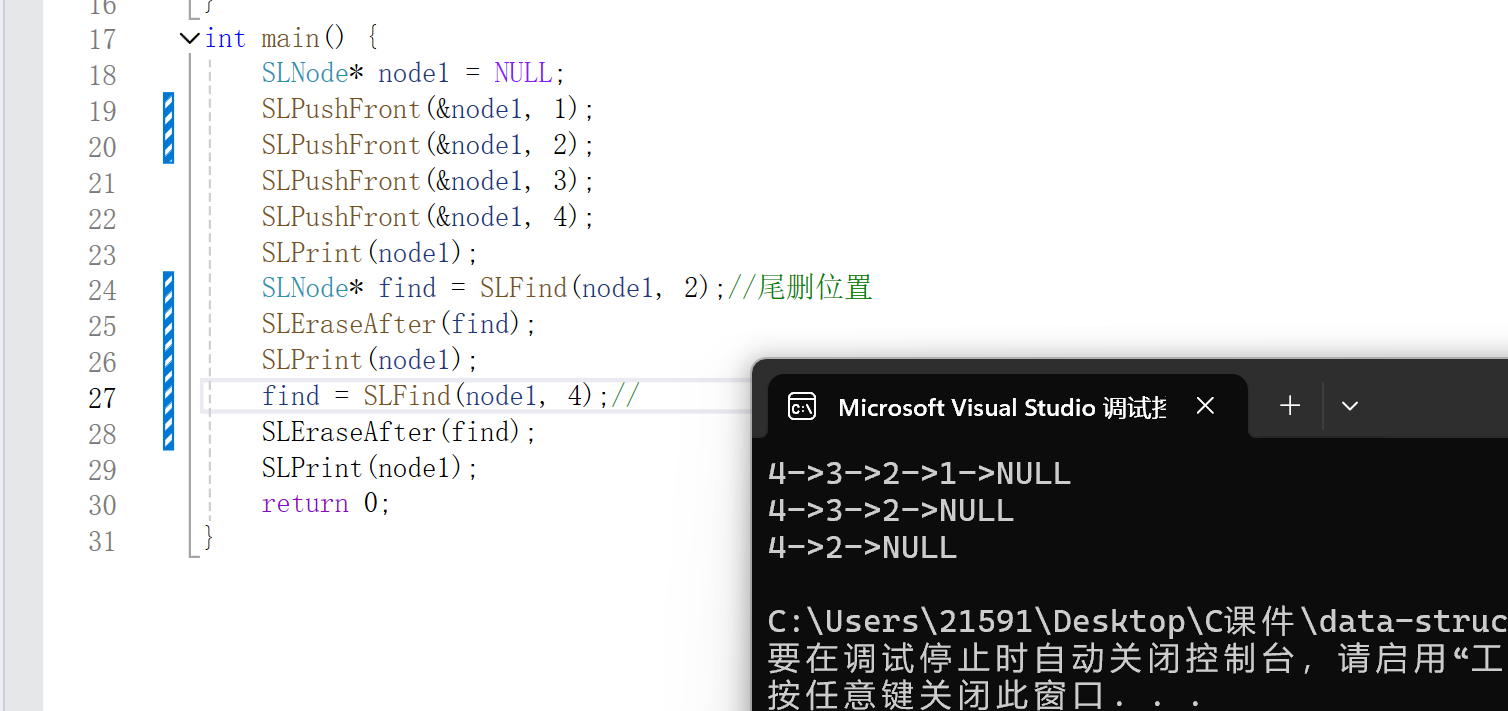
Diffusion模型的操作可以分为两个主要过程:正向过程和逆向过程。在正向过程中,模型逐步向数据中引入噪声,直至完全变为高斯噪声;逆向过程则是一个学习过程,神经网络学习如何逐步从噪声中恢复出原始数据。这种逐步的去噪和生成的思想,给我带来了关于数据生成的全新视角。
2. 与传统生成模型的比较
与GAN或VAE相比,Diffusion模型在训练和生成过程中具有较高的计算需求,因为它需要多次正向和反向传播来完成一个生成周期。然而,这种模型的一个显著优势是其生成的图像质量往往更高,更少见到模式崩溃的情况,这在传统的GAN模型中是一个常见问题。
3. 模型的应用前景
从我对最近几篇论文的学习中看到,Diffusion模型已经被用于多种复杂的图像生成任务,包括条件图像生成和文本到图像的应用。特别是OpenAI的DALL-E 2就是基于Diffusion模型,能够生成高质量的图像,并且能根据文本描述来生成特定内容的图像,显示出了极大的应用潜力。
4. 实验感受
在自己动手实验Diffusion模型的过程中,我体会到了模型训练的复杂性,特别是在模型配置和训练过程中需要调整的参数众多。通过实验,我逐渐理解了不同参数对模型性能的影响,比如噪声的添加程度、扩散时间步的选择等,这些都直接关系到生成图像的质量。
5. 面临的挑战与展望
虽然Diffusion模型展示了优越的性能,但其高计算成本仍是一个挑战。当前,如何减少模型的训练和生成时间,是许多研究正在努力的方向。此外,如何进一步提高模型在复杂场景下的适用性和稳定性,也是未来研究可以探索的问题。
结论
通过这次的学习和实验,我对Diffusion模型有了更深的认识和理解。虽然它在实际应用中还面临一些技术挑战,但无疑是一个非常有前景的研究方向。我期待将这种模型应用到更多的实际场景中,探索其在艺术创作、科学研究等领域的潜能。