目录
设计模式?
创建型模式
单例模式?
啥情况需要单例模式
实现单例模式的关键点?
常见的单例模式实现?
01、饿汉式如何实现单例?
02、懒汉式如何实现单例?
03、双重检查锁定如何实现单例?
04、静态内部类如何实现单例?
05、枚举如何实现单例?
工厂模式?
工厂模式的主要类型
建造者模式
适用性
参与者
类图
示例
结构型模式
装饰模式
一、概述
二、适用性
三、参与者
四、类图
行为型模式
责任链模式?
基本概念
工作流程
应用场景
优缺点
实现示例
策略模式?
一、概述
二、适用性
三、参与者
模板方法
一、概述
二、适用性
三、参与者
示例
Git
IDEA中使用Git,文件不同颜色代表的含义
当你在操作同一个分支且本地代码未提交时,另一个用户已经修改并提交了代码,以下是处理这种情况的步骤:
Git工作流程
常见操作
git rebase和merge的区别
linux
Linux 常用命令
linux 如何查看进程状态?
linux 如何查看线程状态?
文件操作的命令有哪些?
系统管理的命令有哪些?
chmod 的参数讲一下?
网络管理的命令有哪些?
压缩和解压的命令有哪些?
查找文件的命令有哪些?
Liunx 下查找一个文件怎么做?
tail命令
日志文件每行都是一个异常,统计基数排序
开放题 (智力题)
如果给你一个省所有人的高考成绩,我想要知道第100名是谁,我需要用啥数据结构?
100个数 不排序 找中位数
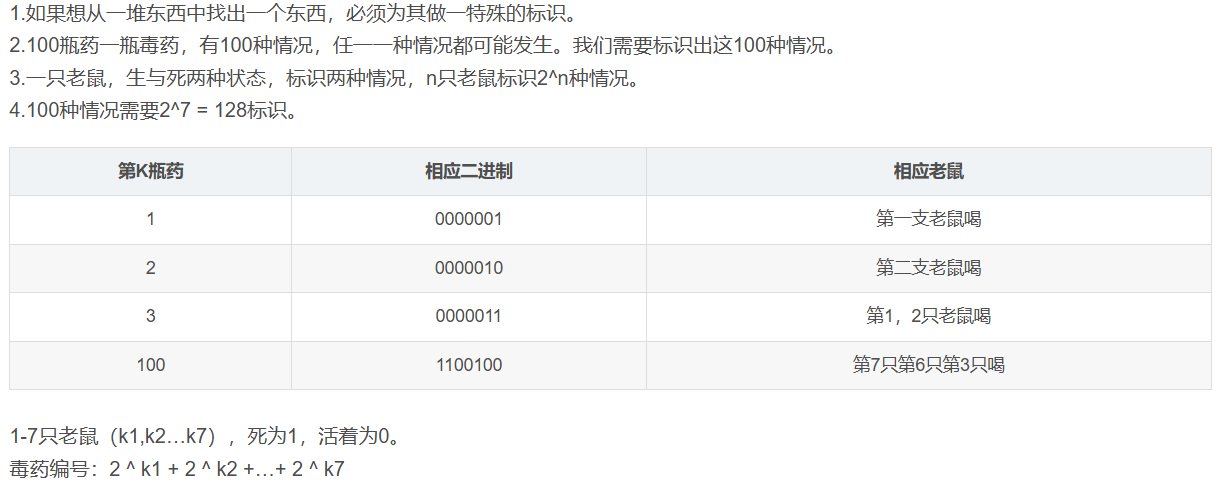
有100瓶药水,其中有一瓶是毒药。如果老鼠喝了毒药,它将在24小时内死亡。通过使用老鼠测试,你需要确定哪瓶是毒药,并希望在一轮测试中使用最少数量的老鼠。
设计模式?
大致按照模式的应用目标分类,设计模式可以分为创建型模式、结构型模式和行为型模式。
- 创建型模式,是对对象创建过程的各种问题和解决方案的总结,包括各种工厂模式(Factory、Abstract Factory)、单例模式(Singleton)、建造者模式(Builder)、原型模式(ProtoType)。
- 结构型模式,是针对软件设计结构的总结,关注于类、对象继承、组合方式的实践经验。常见的结构型模式,包括桥接模式(Bridge)、适配器模式(Adapter)、装饰者模式(Decorator)、代理模式(Proxy)、组合模式(Composite)、外观模式(Facade)、享元模式(Flyweight)等。
- 行为型模式,是从类或对象之间交互、职责划分等角度总结的模式。比较常见的行为型模式有策略模式(Strategy)、解释器模式(Interpreter)、命令模式(Command)、观察者模式(Observer)、迭代器模式(Iterator)、模板方法模式(Template Method)、访问者模式(Visitor)、责任链模式。
- 生产者消费者模式是并发模式
主流开源框架,如Spring等如何在API设计中使用设计模式。你至少要有个大体的印象,如:
- BeanFactory和ApplicationContext应用了工厂模式。
- 在Bean的创建中,Spring也为不同scope定义的对象,提供了单例和原型等模式实现。
- AOP领域则是使用了代理模式、装饰器模式、适配器模式等。
- 类似JdbcTemplate等则是应用了模板模式。
创建型模式
单例模式?
单例模式(Singleton Pattern)是一种创建型设计模式,它确保一个类只有一个实例,并提供一个全局访问点来获取该实例。
单例模式主要用于控制对某些共享资源的访问,例如配置管理器、连接池、线程池、日志对象等。
啥情况需要单例模式
单例模式通常在以下情况下被使用:
1.当一个类需要在整个系统中只有一个实例,以便于协调系统中各个部分的功能时,可以使用单例模式。
2.当一个类的实例占用的资源过多,例如内存和文件句柄等,只能创建一个实例时,可以使用单例模式来减少资源的消耗。
3.当一个类希望控制所有实例的生成和管理,以及对实例化进行严格的控制时,可以使用单例模式。
实现单例模式的关键点?
- 私有构造方法:确保外部代码不能通过构造器创建类的实例。
- 私有静态实例变量:持有类的唯一实例。
- 公有静态方法:提供全局访问点以获取实例,如果实例不存在,则在内部创建。
常见的单例模式实现?
01、饿汉式如何实现单例?
将构造函数私有化,其他类无法直接实例化 Singleton 类的对象。
在静态变量中直接创建了一个 Singleton 类的唯一实例,并在 getInstance() 方法中直接返回该实例。简单但不支持延迟加载实例。
由于使用了静态变量,所以在类加载时就会创建唯一实例,因此不需要考虑线程安全性和懒加载。每次调用 getInstance() 方法时,都会返回相同的实例。
//饿汉式 不考虑线程安全
public class Singleton {
// 创建一个Singleton的一个对象
private static final Singleton instance = new Singleton();
// 让构造函数为 private,这样该类就不会被实例化
private Singleton() {}
// 获取唯一可用的对象
public static Singleton getInstance() {
return instance;
}
}02、懒汉式如何实现单例?
懒汉式单例(Lazy Initialization)在实际使用时才创建实例。这种实现方式需要考虑线程安全问题,因此一般会带上 synchronized 关键字。
//懒汉式
public class Singleton {
// 创建一个Singleton的对象引用
private static Singleton instance;
// 让构造函数为 private,这样该类就不会被实例化
private Singleton() {}
// 获取唯一可用的对象,使用同步锁确保线程安全
public static synchronized Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}03、双重检查锁定如何实现单例?
双重检查锁定(Double-Checked Locking)结合了懒汉式的延迟加载和线程安全,同时又减少了同步的开销,主要是用 synchronized 同步代码块来替代同步方法。
通过私有化构造函数来限制实例的创建,并通过一个公共的静态方法getInstance提供全局访问点。
在getInstance方法中,使用了两次检查(双检锁):第一次检查避免了每次调用时的同步,第二次检查则是在同步块内部,确保只有一个实例被创建。
此外,instance变量被声明为volatile,以确保多线程环境下的可见性和防止指令重排序,从而安全地实现延迟初始化。
-------------------------------------------------------------------------------------------------
使用volatile是为了防止instance实例化时产生的指令重排问题(instance = new Singleton();,确保在instance被初始化之后,其他线程读取到的instance对象一定是初始化完成的。
- 分配内存空间:首先,会为单例对象分配内存空间。这个步骤会在堆内存中为对象分配足够的空间,用于存储它的成员变量和方法。
- 初始化对象:接下来,会对分配的内存空间进行初始化。这个步骤包括调用构造函数来初始化对象的状态,为成员变量赋初值等。
- 将实例引用指向分配的内存空间:最后一步是将实例引用指向分配的内存空间,使得其他代码可以通过该引用来访问单例对象。
第二步和第三步可能会发生重排,导致报错
public class Singleton {
// 使用volatile关键字确保多线程环境下的可见性和禁止指令重排序
private static volatile Singleton instance;
// 私有构造函数,防止外部通过new创建实例
private Singleton() {}
// 获取实例的公共静态方法
public static Singleton getInstance() {
// 第一次检查,避免不必要的同步
if (instance == null) {
// 同步块,确保线程安全
synchronized (Singleton.class) {
// 第二次检查,确保在null的情况下创建实例
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}04、静态内部类如何实现单例?
利用 Java 的静态内部类(Static Nested Class)和类加载机制来实现线程安全的延迟初始化。
public class Singleton {
private Singleton() {}
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
public static Singleton getInstance() {
return SingletonHolder.INSTANCE;
}
}05、枚举如何实现单例?
使用枚举(Enum)实现单例是最简单的方式,不仅不需要考虑线程同步问题,还能防止反射攻击和序列化问题。
public enum Singleton {
INSTANCE;
// 可以添加实例方法
}工厂模式?
工厂模式(Factory Pattern)属于创建型设计模式,主要用于创建对象,而不暴露创建对象的逻辑给客户端。
其在父类中提供一个创建对象的方法, 允许子类决定实例化对象的类型。
举例来说,卡车 Truck 和轮船 Ship 都必须实现运输工具 Transport 接口,该接口声明了一个名为 deliver 的方法。
卡车都实现了 deliver 方法,但是卡车的 deliver 是在陆地上运输,而轮船的 deliver 是在海上运输。

调用工厂方法的代码(客户端代码)无需了解不同子类之间的差别,只管调用接口的 deliver 方法即可。
工厂模式的主要类型
①、简单工厂模式(Simple Factory):它引入了创建者的概念,将实例化的代码从应用程序的业务逻辑中分离出来。简单工厂模式包括一个工厂类,它提供一个方法用于创建对象,无需指定它们具体的类。
class SimpleFactory {
public static Transport createTransport(String type) {
if ("truck".equalsIgnoreCase(type)) {
return new Truck();
} else if ("ship".equalsIgnoreCase(type)) {
return new Ship();
}
return null;
}
public static void main(String[] args) {
Transport truck = SimpleFactory.createTransport("truck");
truck.deliver();
Transport ship = SimpleFactory.createTransport("ship");
ship.deliver();
}
}②、工厂方法模式(Factory Method):定义一个创建对象的接口,但由子类决定要实例化的类是哪一个。工厂方法让类的实例化推迟到子类进行。
interface Transport {
void deliver();
}
class Truck implements Transport {
@Override
public void deliver() {
System.out.println("在陆地上运输");
}
}
class Ship implements Transport {
@Override
public void deliver() {
System.out.println("在海上运输");
}
}
interface TransportFactory {
Transport createTransport();
}
class TruckFactory implements TransportFactory {
@Override
public Transport createTransport() {
return new Truck();
}
}
class ShipFactory implements TransportFactory {
@Override
public Transport createTransport() {
return new Ship();
}
}
public class FactoryMethodPatternDemo {
public static void main(String[] args) {
TransportFactory truckFactory = new TruckFactory();
Transport truck = truckFactory.createTransport();
truck.deliver();
TransportFactory shipFactory = new ShipFactory();
Transport ship = shipFactory.createTransport();
ship.deliver();
}
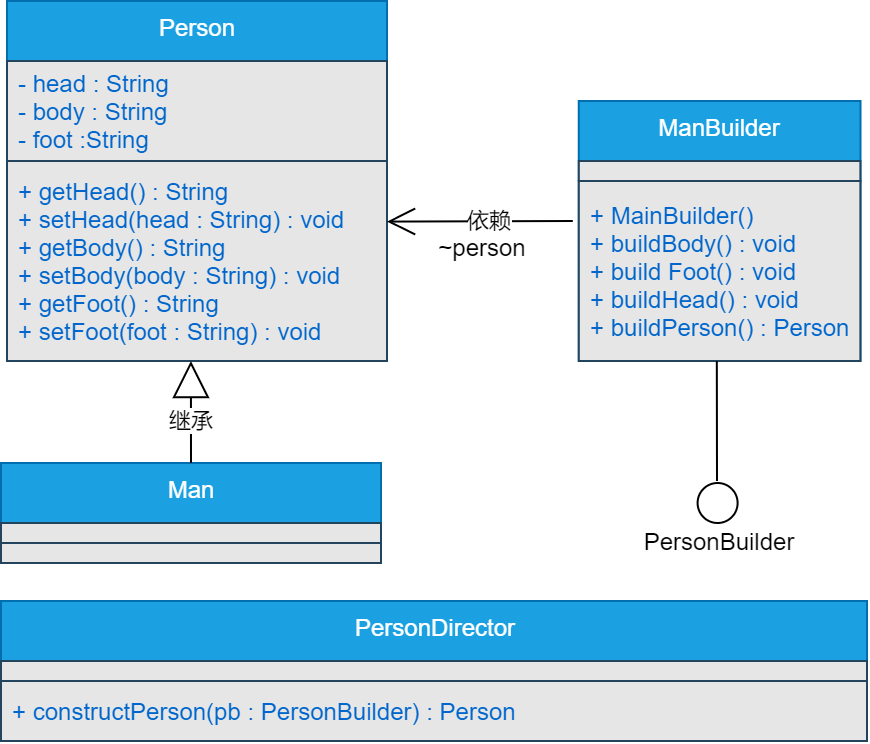
}建造者模式
将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。
适用性
1.当创建复杂对象的算法应该独立于该对象的组成部分以及它们的装配方式时。
2.当构造过程必须允许被构造的对象有不同的表示时。
参与者
1.Builder 为创建一个Product对象的各个部件指定抽象接口。
2.ConcreteBuilder 实现Builder的接口以构造和装配该产品的各个部件。 定义并明确它所创建的表示。 提供一个检索产品的接口。
3.Director 构造一个使用Builder接口的对象。
4.Product 表示被构造的复杂对象。ConcreteBuilder创建该产品的内部表示并定义它的装配过程。 包含定义组成部件的类,包括将这些部件装配成最终产品的接口。
类图
示例
Builder
public interface PersonBuilder {
void buildHead();
void buildBody();
void buildFoot();
Person buildPerson();
}ConcreteBuilder
public class ManBuilder implements PersonBuilder{
Person person;
public ManBuilder() {
person = new Man();
}
@Override
public void buildBody() {
person.setBody("建造男人的身体");
}
@Override
public void buildFoot() {
person.setFoot("建造男人的脚");
}
@Override
public void buildHead() {
person.setHead("建造男人的头");
}
@Override
public Person buildPerson() {
return person;
}
}Director
public class PersonDirector {
public Person constructPerson(PersonBuilder pb) {
pb.buildHead();
pb.buildBody();
pb.buildFoot();
return pb.buildPerson();
}
}Product
public class Person {
private String head;
private String body;
private String foot;
public String getHead() {
return head;
}
public void setHead(String head) {
this.head = head;
}
public String getBody() {
return body;
}
public void setBody(String body) {
this.body = body;
}
public String getFoot() {
return foot;
}
public void setFoot(String foot) {
this.foot = foot;
}
}
public class Man extends Person{
}结构型模式
装饰模式
一、概述
动态地给一个对象添加一些额外的职责。就增加功能来说,Decorator模式相比生成子类更为灵活。
二、适用性
1.在不影响其他对象的情况下,以动态、透明的方式给单个对象添加职责。
2.处理那些可以撤销的职责。
3.当不能采用生成子类的方法进行扩充时。
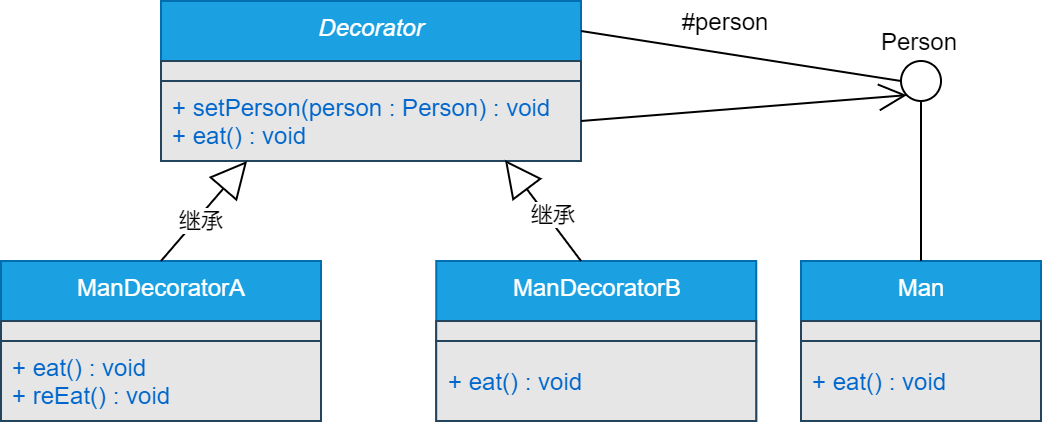
三、参与者
1.Component 定义一个对象接口,可以给这些对象动态地添加职责。
2.ConcreteComponent 定义一个对象,可以给这个对象添加一些职责。
3.Decorator 维持一个指向Component对象的指针,并定义一个与Component接口一致的接口。
4.ConcreteDecorator 向组件添加职责。
四、类图
https://binghe.gitcode.host/md/core/design/java/2023-07-15-%E3%80%8AJava%E6%9E%81%E7%AE%80%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F%E3%80%8B%E7%AC%AC07%E7%AB%A0-%E8%A3%85%E9%A5%B0%E6%A8%A1%E5%BC%8F.html
行为型模式
责任链模式?
责任链模式(Chain of Responsibility Pattern)是一种行为设计模式,它使多个对象都有机会处理请求,从而避免了请求的发送者和接收者之间的耦合关系。
请求会沿着一条链传递,直到有一个对象处理它为止。这种模式常用于处理不同类型的请求以及在不确定具体接收者的情况下将请求传递给多个对象中的一个。
基本概念
责任链模式主要包括以下几个角色:
- Handler(抽象处理者):定义了一个处理请求的接口或抽象类,其中通常会包含一个指向链中下一个处理者的引用。
- ConcreteHandler(具体处理者):实现抽象处理者的处理方法,如果它能处理请求,则处理;否则将请求转发给链中的下一个处理者。
- Client(客户端):创建处理链,并向链的第一个处理者对象提交请求。
工作流程
- 客户端将请求发送给链上的第一个处理者对象。
- 处理者接收到请求后,决定自己是否有能力进行处理。
-
- 如果可以处理,就处理请求。
- 如果不能处理,就将请求转发给链上的下一个处理者。
- 过程重复,直到链上的某个处理者能处理该请求或者链上没有更多的处理者。
应用场景
责任链模式适用于以下场景:
- 有多个对象可以处理同一请求,但具体由哪个对象处理则在运行时动态决定。
- 在不明确指定接收者的情况下,向多个对象中的一个提交请求。
- 需要动态组织和管理处理者时。
优缺点
优点:
- 降低耦合度:它将请求的发送者和接收者解耦。
- 增加了给对象指派职责的灵活性:可以在运行时动态改变链中的成员或调整它们的次序。
- 可以方便地增加新的处理类,在不影响现有代码的情况下扩展功能。
缺点:
- 请求可能不会被处理:如果没有任何处理者处理请求,它可能会达到链的末端并被丢弃。
- 性能问题:一个请求可能会在链上进行较长的遍历,影响性能。
- 调试困难:特别是在链较长时,调试可能会比较麻烦。
实现示例
假设有一个日志系统,根据日志的严重性级别(错误、警告、信息)将日志消息发送给不同的处理器处理。
创建了一个日志处理链。不同级别的日志将被相应级别的处理器处理。责任链模式让日志系统的扩展和维护变得更加灵活。
策略模式?
一、概述
策略模式(Strategy Pattern)是一种行为型设计模式,它定义了一系列的算法,将每个算法封装起来,使得它们可以相互替换。这种模式通常用于实现不同的业务规则或策略,其中每种策略封装了特定的行为或算法。
二、适用性
特别适合用于优化程序中的复杂条件分支语句(if-else),将不同的分支逻辑封装到不同的策略类中,然后通过上下文类来选择不同的策略。
三、参与者
在策略模式中,有三个角色:上下文(Context)、策略接口(Strategy Interface)和具体策略(Concrete Strategy)。
- 策略接口:定义所有支持的算法的公共接口。策略模式的核心。
- 具体策略:实现策略接口的类,提供具体的算法实现。
- 上下文:使用策略的类。通常包含一个引用指向策略接口,可以在运行时改变其具体策略。
模板方法
一、概述
定义一个操作中的算法的骨架,将一些步骤延迟到子类中。 TemplateMethod使得子类可以不改变一个算法的结构即可重新定义该算法的某些特定步骤。
二、适用性
1.一次性实现一个算法的不变的部分,并将可变的行为留给子类来实现。
2.各子类中公共的行为应被提取出来并集中到一个公共父类中以避免代码重复。 首先识别现有代码中的不同之处,并且将不同之处分离为新的操作。 最后,用一个调用这些新的操作的模板方法来替换这些不同的代码。
3.控制子类扩展。
三、参与者
1.AbstractClass 定义抽象的原语操作(primitive operation),具体的子类将重新定义它们以实现一个算法的各个步骤。 实现一个模板方法,定义一个算法的骨架。 该模板方法不仅调用原语操作,也调用定义在AbstractClass或其他对象中的操作。
2.ConcreteClass 实现原语操作以完成算法中与特定子类相关的步骤。
示例
AbstractClass
public abstract class Template {
public abstract void print();
//公共部分
public void update() {
System.out.println("开始打印");
for (int i = 0; i < 10; i++) {
print();
}
}
}ConcreteClass
public class TemplateConcrete extends Template{
@Override
public void print() {
System.out.println("这是子类的实现");
}
}Test
public class Test {
public static void main(String[] args) {
Template temp = new TemplateConcrete();
temp.update();
}
}Result
开始打印
这是子类的实现
这是子类的实现
这是子类的实现
这是子类的实现
这是子类的实现
这是子类的实现
这是子类的实现
这是子类的实现
这是子类的实现
这是子类的实现Git
IDEA中使用Git,文件不同颜色代表的含义
- 绿色——已经加入控制暂未提交;
- 红色——未加入版本控制;
- 蓝色——加入,已提交,有改动;
- 白色——加入,已提交,无改动;
- 灰色——版本控制已忽略文件;
- 黄色——被git忽略,不跟踪
当你在操作同一个分支且本地代码未提交时,另一个用户已经修改并提交了代码,以下是处理这种情况的步骤:
- 保存本地修改:首先使用 git stash 保存你当前的修改。这会将你的改动临时存储在一个堆栈中,并恢复工作目录为干净状态。
git stash- 拉取最新修改:然后从远程仓库拉取最新的修改。
git pull origin <branch_name>- 应用本地修改:将你之前保存的修改重新应用到当前的代码上。
git stash pop- 解决冲突(如果有):在应用你的修改时,可能会出现冲突。你需要手动解决这些冲突。打开冲突的文件,按照标记(例如 <<<<, ====, >>>>)来找到冲突的部分,并手动修改代码以解决冲突。
# 冲突文件会显示在 `git status` 中
git status- 提交你的修改:一旦解决了所有冲突,添加修改并提交。
git add <conflict_files>
git commit -m "Resolved conflicts and added my changes"- 推送到远程仓库:最后,将你的修改推送到远程仓库。
git push origin <branch_name>Git工作流程
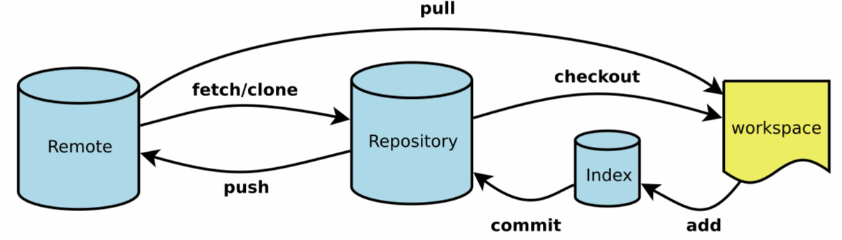
- Workspace: 工作区,平时存放项目代码的地方
- Index / Stage: 暂存区,用于临时存放改动,事实上它只是一个文件,保存即将提交到文件列表信息
- Repository: 仓库区(或版本库),安全存放数据的位置,这里面有提交到所有版本的数据。其中HEAD指向最新放入仓库的版本
- Remote: 远程仓库,托管代码的服务器,可以简单的认为是项目组中的一台电脑用于远程数据交换
cherry-pick 是 Git 中一个非常有用的命令,它允许你从一个分支中选择特定的提交并将其应用到另一个分支。这个过程称为 "cherry-picking"。
常见操作
这些是与版本控制系统(如Git)相关的常见操作。下面是对每个操作的简要说明:
- Pull(拉取):从远程代码仓库(如GitHub)获取最新的代码并合并到本地分支。它结合了
fetch(获取远程代码)和merge(合并代码)操作。通常在本地分支落后于远程分支时使用。 - Push(推送):将本地代码变更上传到远程代码仓库,使得远程分支与本地分支保持同步。
- Rebase(变基):将一系列提交应用到另一个提交的基础上,使得提交历史更加线性和清晰。通过变基,可以将本地的提交移动到另一个分支上,或者合并多个提交为一个提交。它可以用于整理提交历史、解决冲突、保持分支干净等。
- Stash(储藏):暂时保存未提交的修改,以便切换到其他分支进行工作。当你需要切换到其他任务或分支时,但又不想提交当前的修改,可以使用stash命令将修改保存在一个临时区域中。之后,你可以在任何时候应用这些修改。
git rebase和merge的区别
- Rebase(变基)是将一个分支上的提交逐个地应用到另一个分支上,使得提交历史变得更加线性。当执行rebase时,Git会将目标分支与源分支的共同祖先以来的所有提交挪到目标分支的最新位置。这个过程可以看作是将源分支上的每个提交复制到目标分支上。简而言之,rebase可以将提交按照时间顺序线性排列。
- Merge(合并)是将两个分支上的代码提交历史合并为一个新的提交。在执行merge时,Git会创建一个新的合并提交,将两个分支的提交历史连接在一起。这样,两个分支的修改都会包含在一个合并提交中。合并后的历史会保留每个分支的提交记录。
linux
Linux 常用命令
常用的 Linux 命令有 top 查看系统资源、ps 查看进程、netstat 查看网络连接、ping 测试网络连通性、find 查找文件、chmod 修改文件权限、kill 终止进程、df 查看磁盘空间、free 查看内存使用、service 启动服务、mkdir 创建目录、rm 删除文件、rmdir 删除目录、cp 复制文件、mv 移动文件、zip 压缩文件、unzip 解压文件等等这些。
linux 如何查看进程状态?
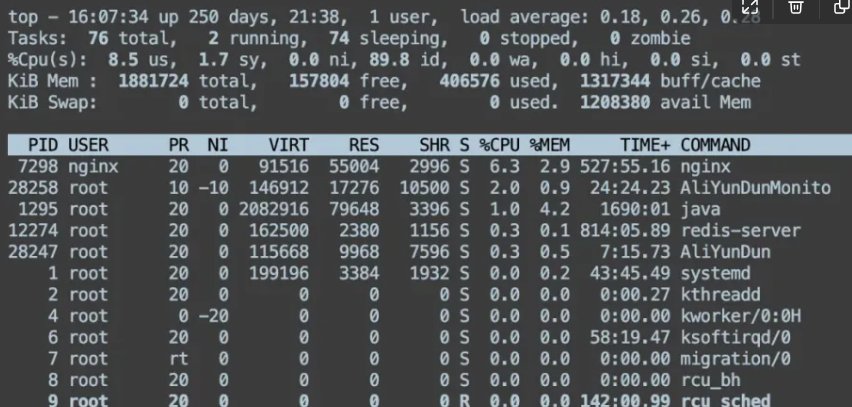
可以通过 ps 命令或者 top 命令来查看进程的状态。比如我想看 nginx 进程的状态,可以在 linux 输入这条命令:

top 命令除了能看进程的状态,还能看到系统的信息,比如系统负载、内存、cpu 使用率等等
linux 如何查看线程状态?
在 ps 和 top 命令加一下参数,就能看到线程状态了:
top -H
ps -eT | grep <进程名或线程名>
ps:显示当前系统的进程状态。
-e:显示所有进程。
-T:显示每个进程的所有线程。文件操作的命令有哪些?
ls:列出目录内容。ls -l显示详细信息,ls -a显示隐藏文件。cd:更改当前目录。cd ..回到上级目录,cd ~回到用户的主目录。pwd:显示当前工作目录的完整路径。cp:复制文件或目录。cp source_file target_file复制文件,cp -r source_directory target_directory复制目录。mv:移动或重命名文件或目录。rm:删除文件或目录。rm -r递归删除目录及其内容。mkdir:创建新目录。cat:查看文件内容。cat file1 file2合并文件内容显示。
系统管理的命令有哪些?
ps:显示当前运行的进程。ps aux显示所有进程。top:实时显示进程动态。kill:终止进程。kill -9 PID强制终止。df:显示磁盘空间使用情况。df -h以易读格式显示。du:显示目录或文件的磁盘使用情况。free:显示内存和交换空间的使用情况。chmod:更改文件或目录的权限。chown:更改文件或目录的所有者和所属组。
chmod 的参数讲一下?
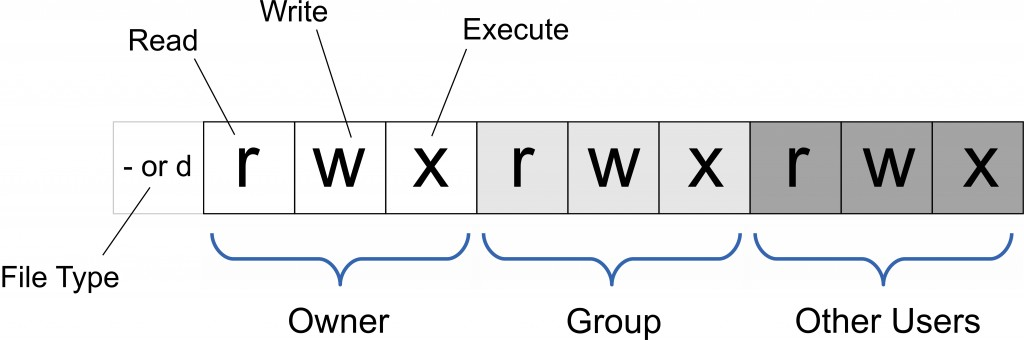
chmod 命令在 Linux 中用来改变文件或目录的访问权限。这个命令的使用可以基于符号表示法(也称为文本方法)或者八进制数表示法。
像 chmod 777 file 赋予文件所有权限,就属于八进制数表示法。7=4+2+1,分别代表读、写、执行权限。
Linux 中的权限可以应用于三种类别的用户:
- 文件所有者(u)
- 与文件所有者同组的用户(g)
- 其他用户(o)
①、符号模式
符号模式使用字母来表示权限,如下:
- 读(r)
- 写(w)
- 执行(x)
- 所有(a)
例如:
chmod u+w file:给文件所有者添加写权限。chmod g-r file:移除组用户的读权限。chmod o+x file:给其他用户添加执行权限。chmod u=rwx,g=rx,o=r file:设置文件所有者具有读写执行权限,组用户具有读执行权限,其他用户具有读权限。
②、数字模式
数字模式使用三位八进制数来表示权限,每位数字代表不同的用户类别(所有者、组、其他用户),数字是其各自权限值的总和:
- 读(r)= 4
- 写(w)= 2
- 执行(x)= 1
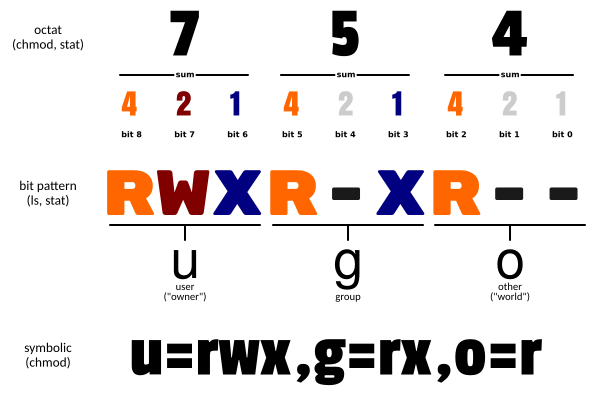
因此,权限模式可以是从 0(无权限)到 7(读写执行权限)的任何值。
- chmod 755 file:使得文件所有者有读写执行(7)权限,组用户和其他用户有读和执行(5)权限。
- chmod 644 file:使得文件所有者有读写(6)权限,而组用户和其他用户只有读(4)权限。
网络管理的命令有哪些?
ping:检查与远程服务器的连接。wget:从网络上下载文件。ifconfig:显示网络接口的配置信息。netstat:显示网络连接、路由表和网络接口信息。
压缩和解压的命令有哪些?
tar:打包或解包.tar文件。tar cvf archive.tar files打包,tar xvf archive.tar解包。gzip/gunzip:压缩或解压.gz文件。zip/unzip:压缩或解压.zip文件。
查找文件的命令有哪些?
find:在目录树中查找文件。find /directory/ -name filename。
Liunx 下查找一个文件怎么做?
在 Linux 环境下查找文件,有多种命令和方法可以使用。find 命令是最常用的文件查找工具之一,它可以在指定目录下递归查找符合条件的文件和目录。
例如:在当前目录及其子目录中查找名为 "example.txt" 的文件
find . -name "example.txt"例如:查找 /home 目录中所有 .txt 结尾的文件:
find /home -name "*.txt"例如:查找 /var/log 目录中修改时间在 7 天以前的 .log 文件
find /var/log -name "*.log" -mtime +7tail命令
tail 是一个常用的命令行工具,用于显示文件的末尾内容。它的基本语法是:
tail [选项] 文件名其中,常用的选项包括:
- -n <行数>:显示文件末尾的指定行数,默认为10行。
- -f:实时追踪文件的新增内容,常用于查看日志文件。
例如,要查看文件 example.txt 的末尾10行,可以使用:
tail example.txt如果想显示末尾20行,可以使用:
tail -n 20 example.txt对于日志文件,要实时查看新增内容,可以使用 -f 选项:
tail -f logfile.txt这样可以方便地查看正在写入的日志信息。
日志文件每行都是一个异常,统计基数排序
假设你有一个日志文件,每行都记录了一个异常。你希望统计每种异常的出现次数,并对这些异常进行基数排序。以下是一个示例解决方案。
开放题 (智力题)
如果给你一个省所有人的高考成绩,我想要知道第100名是谁,我需要用啥数据结构?
找到第100名的高考成绩,可以使用[最小堆]数据结构。将所有人的高考成绩放入最小堆中,然后从堆中弹出99个最小元素,此时堆顶的元素就是第100名的高考成绩。这种方法的时间复杂度为0(n+ 100logn),其中n是省内参加高考的人数。
100个数 不排序 找中位数
- 创建一个最大堆和一个最小堆。
- 遍历100个数,将前50个数插入最大堆,后50个数插入最小堆。
- 如果最大堆的根节点大于最小堆的根节点,交换两个根节点。
- 重复步骤 3,直到最大堆的根节点小于或等于最小堆的根节点。
- 最终,最大堆的根节点即为中位数。
这种方法的时间复杂度为O(nlogn),其中n为原始数组的长度。虽然它需要对100个数进行堆的插入和调整操作,但相对于完全排序整个数组而言,它是一种较为高效的方法。
有100瓶药水,其中有一瓶是毒药。如果老鼠喝了毒药,它将在24小时内死亡。通过使用老鼠测试,你需要确定哪瓶是毒药,并希望在一轮测试中使用最少数量的老鼠。