ResNet网络介绍
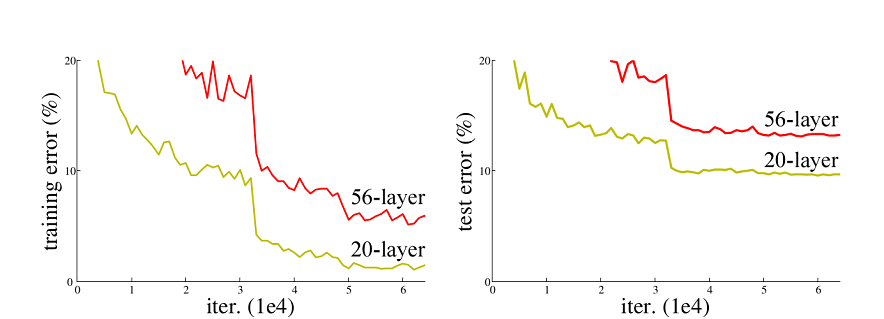
ResNet50网络是2015年由微软实验室的何恺明提出,获得ILSVRC2015图像分类竞赛第一名。在ResNet网络提出之前,传统的卷积神经网络都是将一系列的卷积层和池化层堆叠得到的,但当网络堆叠到一定深度时,就会出现退化问题。下图是在CIFAR-10数据集上使用56层网络与20层网络训练误差和测试误差图,由图中数据可以看出,56层网络比20层网络训练误差和测试误差更大,随着网络的加深,其误差并没有如预想的一样减小。
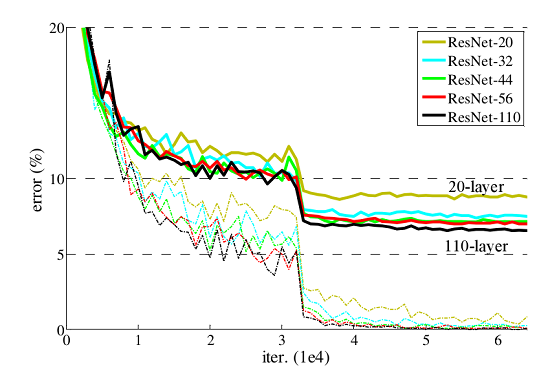
ResNet网络提出了残差网络结构(Residual Network)来减轻退化问题,使用ResNet网络可以实现搭建较深的网络结构(突破1000层)。论文中使用ResNet网络在CIFAR-10数据集上的训练误差与测试误差图如下图所示,图中虚线表示训练误差,实线表示测试误差。由图中数据可以看出,ResNet网络层数越深,其训练误差和测试误差越小。
了解ResNet网络更多详细内容,参见ResNet论文。
数据集准备与加载
CIFAR-10数据集共有60000张32*32的彩色图像,分为10个类别,每类有6000张图,数据集一共有50000张训练图片和10000张评估图片。首先,如下示例使用download接口下载并解压,目前仅支持解析二进制版本的CIFAR-10文件(CIFAR-10 binary version)。
代码示例:
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/cifar-10-binary.tar.gz"
download(url, "./datasets-cifar10-bin", kind="tar.gz", replace=True)
下载后的数据集目录结构如下:
datasets-cifar10-bin/cifar-10-batches-bin
├── batches.meta.text
├── data_batch_1.bin
├── data_batch_2.bin
├── data_batch_3.bin
├── data_batch_4.bin
├── data_batch_5.bin
├── readme.html
└── test_batch.bin
然后,使用mindspore.dataset.Cifar10Dataset接口来加载数据集,并进行相关图像增强操作。
import mindspore as ms
import mindspore.dataset as ds
import mindspore.dataset.vision as vision
import mindspore.dataset.transforms as transforms
from mindspore import dtype as mstype
data_dir = "./datasets-cifar10-bin/cifar-10-batches-bin" # 数据集根目录
batch_size = 256 # 批量大小
image_size = 32 # 训练图像空间大小
workers = 4 # 并行线程个数
num_classes = 10 # 分类数量
def create_dataset_cifar10(dataset_dir, usage, resize, batch_size, workers):
data_set = ds.Cifar10Dataset(dataset_dir=dataset_dir,
usage=usage,
num_parallel_workers=workers,
shuffle=True)
trans = []
if usage == "train":
trans += [
vision.RandomCrop((32, 32), (4, 4, 4, 4)),
vision.RandomHorizontalFlip(prob=0.5)
]
trans += [
vision.Resize(resize),
vision.Rescale(1.0 / 255.0, 0.0),
vision.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]),
vision.HWC2CHW()
]
target_trans = transforms.TypeCast(mstype.int32)
# 数据映射操作
data_set = data_set.map(operations=trans,
input_columns='image',
num_parallel_workers=workers)
data_set = data_set.map(operations=target_trans,
input_columns='label',
num_parallel_workers=workers)
# 批量操作
data_set = data_set.batch(batch_size)
return data_set
# 获取处理后的训练与测试数据集
dataset_train = create_dataset_cifar10(dataset_dir=data_dir,
usage="train",
resize=image_size,
batch_size=batch_size,
workers=workers)
step_size_train = dataset_train.get_dataset_size()
dataset_val = create_dataset_cifar10(dataset_dir=data_dir,
usage="test",
resize=image_size,
batch_size=batch_size,
workers=workers)
step_size_val = dataset_val.get_dataset_size()
对CIFAR-10训练数据集进行可视化。
import matplotlib.pyplot as plt
import numpy as np
data_iter = next(dataset_train.create_dict_iterator())
images = data_iter["image"].asnumpy()
labels = data_iter["label"].asnumpy()
print(f"Image shape: {images.shape}, Label shape: {labels.shape}")
# 训练数据集中,前六张图片所对应的标签
print(f"Labels: {labels[:6]}")
classes = []
with open(data_dir + "/batches.meta.txt", "r") as f:
for line in f:
line = line.rstrip()
if line:
classes.append(line)
# 训练数据集的前六张图片
plt.figure()
for i in range(6):
plt.subplot(2, 3, i + 1)
image_trans = np.transpose(images[i], (1, 2, 0))
mean = np.array([0.4914, 0.4822, 0.4465])
std = np.array([0.2023, 0.1994, 0.2010])
image_trans = std * image_trans + mean
image_trans = np.clip(image_trans, 0, 1)
plt.title(f"{classes[labels[i]]}")
plt.imshow(image_trans)
plt.axis("off")
plt.show()

构建网络
残差网络结构(Residual Network)是ResNet网络的主要亮点,ResNet使用残差网络结构后可有效地减轻退化问题,实现更深的网络结构设计,提高网络的训练精度。本节首先讲述如何构建残差网络结构,然后通过堆叠残差网络来构建ResNet50网络。
构建残差网络结构
残差网络结构图如下图所示,残差网络由两个分支构成:一个主分支,一个shortcuts(图中弧线表示)。主分支通过堆叠一系列的卷积操作得到,shotcuts从输入直接到输出,主分支输出的特征矩阵 F ( x ) F(x) F(x)加上shortcuts输出的特征矩阵 x x x得到 F ( x ) + x F(x)+x F(x)+x,通过Relu激活函数后即为残差网络最后的输出。
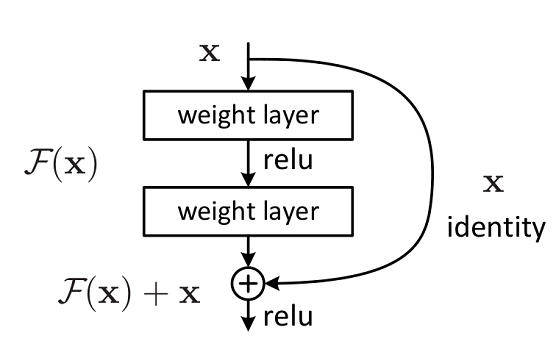
残差网络结构主要由两种,一种是Building Block,适用于较浅的ResNet网络,如ResNet18和ResNet34;另一种是Bottleneck,适用于层数较深的ResNet网络,如ResNet50、ResNet101和ResNet152。
Building Block
Building Block结构图如下图所示,主分支有两层卷积网络结构:
- 主分支第一层网络以输入channel为64为例,首先通过一个 3 × 3 3\times3 3×3的卷积层,然后通过Batch Normalization层,最后通过Relu激活函数层,输出channel为64;
- 主分支第二层网络的输入channel为64,首先通过一个 3 × 3 3\times3 3×3的卷积层,然后通过Batch Normalization层,输出channel为64。
最后将主分支输出的特征矩阵与shortcuts输出的特征矩阵相加,通过Relu激活函数即为Building Block最后的输出。
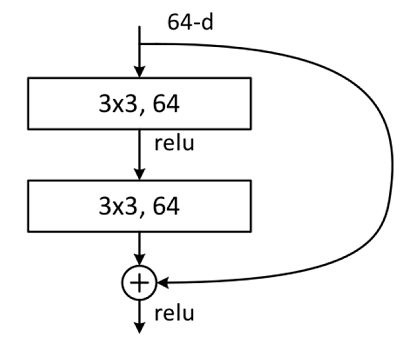
主分支与shortcuts输出的特征矩阵相加时,需要保证主分支与shortcuts输出的特征矩阵shape相同。如果主分支与shortcuts输出的特征矩阵shape不相同,如输出channel是输入channel的一倍时,shortcuts上需要使用数量与输出channel相等,大小为
1
×
1
1\times1
1×1的卷积核进行卷积操作;若输出的图像较输入图像缩小一倍,则要设置shortcuts中卷积操作中的stride为2,主分支第一层卷积操作的stride也需设置为2。
如下代码定义ResidualBlockBase类实现Building Block结构。
from typing import Type, Union, List, Optional
import mindspore.nn as nn
from mindspore.common.initializer import Normal
# 初始化卷积层与BatchNorm的参数
weight_init = Normal(mean=0, sigma=0.02)
gamma_init = Normal(mean=1, sigma=0.02)
class ResidualBlockBase(nn.Cell):
expansion: int = 1 # 最后一个卷积核数量与第一个卷积核数量相等
def __init__(self, in_channel: int, out_channel: int,
stride: int = 1, norm: Optional[nn.Cell] = None,
down_sample: Optional[nn.Cell] = None) -> None:
super(ResidualBlockBase, self).__init__()
if not norm:
self.norm = nn.BatchNorm2d(out_channel)
else:
self.norm = norm
self.conv1 = nn.Conv2d(in_channel, out_channel,
kernel_size=3, stride=stride,
weight_init=weight_init)
self.conv2 = nn.Conv2d(in_channel, out_channel,
kernel_size=3, weight_init=weight_init)
self.relu = nn.ReLU()
self.down_sample = down_sample
def construct(self, x):
"""ResidualBlockBase construct."""
identity = x # shortcuts分支
out = self.conv1(x) # 主分支第一层:3*3卷积层
out = self.norm(out)
out = self.relu(out)
out = self.conv2(out) # 主分支第二层:3*3卷积层
out = self.norm(out)
if self.down_sample is not None:
identity = self.down_sample(x)
out += identity # 输出为主分支与shortcuts之和
out = self.relu(out)
return out
Bottleneck
Bottleneck结构图如下图所示,在输入相同的情况下Bottleneck结构相对Building Block结构的参数数量更少,更适合层数较深的网络,ResNet50使用的残差结构就是Bottleneck。该结构的主分支有三层卷积结构,分别为 1 × 1 1\times1 1×1的卷积层、 3 × 3 3\times3 3×3卷积层和 1 × 1 1\times1 1×1的卷积层,其中 1 × 1 1\times1 1×1的卷积层分别起降维和升维的作用。
- 主分支第一层网络以输入channel为256为例,首先通过数量为64,大小为 1 × 1 1\times1 1×1的卷积核进行降维,然后通过Batch Normalization层,最后通过Relu激活函数层,其输出channel为64;
- 主分支第二层网络通过数量为64,大小为 3 × 3 3\times3 3×3的卷积核提取特征,然后通过Batch Normalization层,最后通过Relu激活函数层,其输出channel为64;
- 主分支第三层通过数量为256,大小 1 × 1 1\times1 1×1的卷积核进行升维,然后通过Batch Normalization层,其输出channel为256。
最后将主分支输出的特征矩阵与shortcuts输出的特征矩阵相加,通过Relu激活函数即为Bottleneck最后的输出。
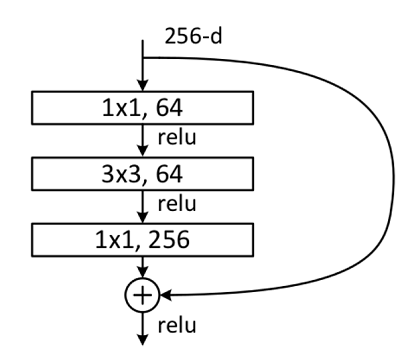
主分支与shortcuts输出的特征矩阵相加时,需要保证主分支与shortcuts输出的特征矩阵shape相同。如果主分支与shortcuts输出的特征矩阵shape不相同,如输出channel是输入channel的一倍时,shortcuts上需要使用数量与输出channel相等,大小为
1
×
1
1\times1
1×1的卷积核进行卷积操作;若输出的图像较输入图像缩小一倍,则要设置shortcuts中卷积操作中的stride为2,主分支第二层卷积操作的stride也需设置为2。
如下代码定义ResidualBlock类实现Bottleneck结构。
class ResidualBlock(nn.Cell):
expansion = 4 # 最后一个卷积核的数量是第一个卷积核数量的4倍
def __init__(self, in_channel: int, out_channel: int,
stride: int = 1, down_sample: Optional[nn.Cell] = None) -> None:
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channel, out_channel,
kernel_size=1, weight_init=weight_init)
self.norm1 = nn.BatchNorm2d(out_channel)
self.conv2 = nn.Conv2d(out_channel, out_channel,
kernel_size=3, stride=stride,
weight_init=weight_init)
self.norm2 = nn.BatchNorm2d(out_channel)
self.conv3 = nn.Conv2d(out_channel, out_channel * self.expansion,
kernel_size=1, weight_init=weight_init)
self.norm3 = nn.BatchNorm2d(out_channel * self.expansion)
self.relu = nn.ReLU()
self.down_sample = down_sample
def construct(self, x):
identity = x # shortscuts分支
out = self.conv1(x) # 主分支第一层:1*1卷积层
out = self.norm1(out)
out = self.relu(out)
out = self.conv2(out) # 主分支第二层:3*3卷积层
out = self.norm2(out)
out = self.relu(out)
out = self.conv3(out) # 主分支第三层:1*1卷积层
out = self.norm3(out)
if self.down_sample is not None:
identity = self.down_sample(x)
out += identity # 输出为主分支与shortcuts之和
out = self.relu(out)
return out
构建ResNet50网络
ResNet网络层结构如下图所示,以输入彩色图像 224 × 224 224\times224 224×224为例,首先通过数量64,卷积核大小为 7 × 7 7\times7 7×7,stride为2的卷积层conv1,该层输出图片大小为 112 × 112 112\times112 112×112,输出channel为64;然后通过一个 3 × 3 3\times3 3×3的最大下采样池化层,该层输出图片大小为 56 × 56 56\times56 56×56,输出channel为64;再堆叠4个残差网络块(conv2_x、conv3_x、conv4_x和conv5_x),此时输出图片大小为 7 × 7 7\times7 7×7,输出channel为2048;最后通过一个平均池化层、全连接层和softmax,得到分类概率。
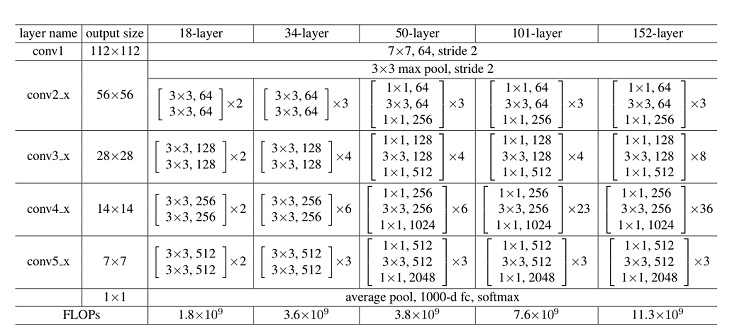
对于每个残差网络块,以ResNet50网络中的conv2_x为例,其由3个Bottleneck结构堆叠而成,每个Bottleneck输入的channel为64,输出channel为256。
如下示例定义make_layer实现残差块的构建,其参数如下所示:
last_out_channel:上一个残差网络输出的通道数。block:残差网络的类别,分别为ResidualBlockBase和ResidualBlock。channel:残差网络输入的通道数。block_nums:残差网络块堆叠的个数。stride:卷积移动的步幅。
def make_layer(last_out_channel, block: Type[Union[ResidualBlockBase, ResidualBlock]],
channel: int, block_nums: int, stride: int = 1):
down_sample = None # shortcuts分支
if stride != 1 or last_out_channel != channel * block.expansion:
down_sample = nn.SequentialCell([
nn.Conv2d(last_out_channel, channel * block.expansion,
kernel_size=1, stride=stride, weight_init=weight_init),
nn.BatchNorm2d(channel * block.expansion, gamma_init=gamma_init)
])
layers = []
layers.append(block(last_out_channel, channel, stride=stride, down_sample=down_sample))
in_channel = channel * block.expansion
# 堆叠残差网络
for _ in range(1, block_nums):
layers.append(block(in_channel, channel))
return nn.SequentialCell(layers)
ResNet50网络共有5个卷积结构,一个平均池化层,一个全连接层,以CIFAR-10数据集为例:
- conv1:输入图片大小为 32 × 32 32\times32 32×32,输入channel为3。首先经过一个卷积核数量为64,卷积核大小为 7 × 7 7\times7 7×7,stride为2的卷积层;然后通过一个Batch Normalization层;最后通过Reul激活函数。该层输出feature map大小为 16 × 16 16\times16 16×16,输出channel为64。
- conv2_x:输入feature map大小为 16 × 16 16\times16 16×16,输入channel为64。首先经过一个卷积核大小为 3 × 3 3\times3 3×3,stride为2的最大下采样池化操作;然后堆叠3个 [ 1 × 1 , 64 ; 3 × 3 , 64 ; 1 × 1 , 256 ] [1\times1,64;3\times3,64;1\times1,256] [1×1,64;3×3,64;1×1,256]结构的Bottleneck。该层输出feature map大小为 8 × 8 8\times8 8×8,输出channel为256。
- conv3_x:输入feature map大小为 8 × 8 8\times8 8×8,输入channel为256。该层堆叠4个[1×1,128;3×3,128;1×1,512]结构的Bottleneck。该层输出feature map大小为 4 × 4 4\times4 4×4,输出channel为512。
- conv4_x:输入feature map大小为 4 × 4 4\times4 4×4,输入channel为512。该层堆叠6个[1×1,256;3×3,256;1×1,1024]结构的Bottleneck。该层输出feature map大小为 2 × 2 2\times2 2×2,输出channel为1024。
- conv5_x:输入feature map大小为 2 × 2 2\times2 2×2,输入channel为1024。该层堆叠3个[1×1,512;3×3,512;1×1,2048]结构的Bottleneck。该层输出feature map大小为 1 × 1 1\times1 1×1,输出channel为2048。
- average pool & fc:输入channel为2048,输出channel为分类的类别数。
如下示例代码实现ResNet50模型的构建,通过用调函数resnet50即可构建ResNet50模型,函数resnet50参数如下:
num_classes:分类的类别数,默认类别数为1000。pretrained:下载对应的训练模型,并加载预训练模型中的参数到网络中。
from mindspore import load_checkpoint, load_param_into_net
class ResNet(nn.Cell):
def __init__(self, block: Type[Union[ResidualBlockBase, ResidualBlock]],
layer_nums: List[int], num_classes: int, input_channel: int) -> None:
super(ResNet, self).__init__()
self.relu = nn.ReLU()
# 第一个卷积层,输入channel为3(彩色图像),输出channel为64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, weight_init=weight_init)
self.norm = nn.BatchNorm2d(64)
# 最大池化层,缩小图片的尺寸
self.max_pool = nn.MaxPool2d(kernel_size=3, stride=2, pad_mode='same')
# 各个残差网络结构块定义
self.layer1 = make_layer(64, block, 64, layer_nums[0])
self.layer2 = make_layer(64 * block.expansion, block, 128, layer_nums[1], stride=2)
self.layer3 = make_layer(128 * block.expansion, block, 256, layer_nums[2], stride=2)
self.layer4 = make_layer(256 * block.expansion, block, 512, layer_nums[3], stride=2)
# 平均池化层
self.avg_pool = nn.AvgPool2d()
# flattern层
self.flatten = nn.Flatten()
# 全连接层
self.fc = nn.Dense(in_channels=input_channel, out_channels=num_classes)
def construct(self, x):
x = self.conv1(x)
x = self.norm(x)
x = self.relu(x)
x = self.max_pool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avg_pool(x)
x = self.flatten(x)
x = self.fc(x)
return x
def _resnet(model_url: str, block: Type[Union[ResidualBlockBase, ResidualBlock]],
layers: List[int], num_classes: int, pretrained: bool, pretrained_ckpt: str,
input_channel: int):
model = ResNet(block, layers, num_classes, input_channel)
if pretrained:
# 加载预训练模型
download(url=model_url, path=pretrained_ckpt, replace=True)
param_dict = load_checkpoint(pretrained_ckpt)
load_param_into_net(model, param_dict)
return model
def resnet50(num_classes: int = 1000, pretrained: bool = False):
"""ResNet50模型"""
resnet50_url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/models/application/resnet50_224_new.ckpt"
resnet50_ckpt = "./LoadPretrainedModel/resnet50_224_new.ckpt"
return _resnet(resnet50_url, ResidualBlock, [3, 4, 6, 3], num_classes,
pretrained, resnet50_ckpt, 2048)
模型训练与评估
本节使用ResNet50预训练模型进行微调。调用resnet50构造ResNet50模型,并设置pretrained参数为True,将会自动下载ResNet50预训练模型,并加载预训练模型中的参数到网络中。然后定义优化器和损失函数,逐个epoch打印训练的损失值和评估精度,并保存评估精度最高的ckpt文件(resnet50-best.ckpt)到当前路径的./BestCheckPoint下。
由于预训练模型全连接层(fc)的输出大小(对应参数num_classes)为1000, 为了成功加载预训练权重,我们将模型的全连接输出大小设置为默认的1000。CIFAR10数据集共有10个分类,在使用该数据集进行训练时,需要将加载好预训练权重的模型全连接层输出大小重置为10。
此处我们展示了5个epochs的训练过程,如果想要达到理想的训练效果,建议训练80个epochs。
代码示例:
# 定义ResNet50网络
network = resnet50(pretrained=True)
# 全连接层输入层的大小
in_channel = network.fc.in_channels
fc = nn.Dense(in_channels=in_channel, out_channels=10)
# 重置全连接层
network.fc = fc
# 设置学习率
num_epochs = 5
lr = nn.cosine_decay_lr(min_lr=0.00001, max_lr=0.001, total_step=step_size_train * num_epochs,
step_per_epoch=step_size_train, decay_epoch=num_epochs)
# 定义优化器和损失函数
opt = nn.Momentum(params=network.trainable_params(), learning_rate=lr, momentum=0.9)
loss_fn = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
def forward_fn(inputs, targets):
logits = network(inputs)
loss = loss_fn(logits, targets)
return loss
grad_fn = ms.value_and_grad(forward_fn, None, opt.parameters)
def train_step(inputs, targets):
loss, grads = grad_fn(inputs, targets)
opt(grads)
return loss
import os
# 创建迭代器
data_loader_train = dataset_train.create_tuple_iterator(num_epochs=num_epochs)
data_loader_val = dataset_val.create_tuple_iterator(num_epochs=num_epochs)
# 最佳模型存储路径
best_acc = 0
best_ckpt_dir = "./BestCheckpoint"
best_ckpt_path = "./BestCheckpoint/resnet50-best.ckpt"
if not os.path.exists(best_ckpt_dir):
os.mkdir(best_ckpt_dir)
import mindspore.ops as ops
def train(data_loader, epoch):
"""模型训练"""
losses = []
network.set_train(True)
for i, (images, labels) in enumerate(data_loader):
loss = train_step(images, labels)
if i % 100 == 0 or i == step_size_train - 1:
print('Epoch: [%3d/%3d], Steps: [%3d/%3d], Train Loss: [%5.3f]' %
(epoch + 1, num_epochs, i + 1, step_size_train, loss))
losses.append(loss)
return sum(losses) / len(losses)
def evaluate(data_loader):
"""模型验证"""
network.set_train(False)
correct_num = 0.0 # 预测正确个数
total_num = 0.0 # 预测总数
for images, labels in data_loader:
logits = network(images)
pred = logits.argmax(axis=1) # 预测结果
correct = ops.equal(pred, labels).reshape((-1, ))
correct_num += correct.sum().asnumpy()
total_num += correct.shape[0]
acc = correct_num / total_num # 准确率
return acc
# 开始循环训练
print("Start Training Loop ...")
for epoch in range(num_epochs):
curr_loss = train(data_loader_train, epoch)
curr_acc = evaluate(data_loader_val)
print("-" * 50)
print("Epoch: [%3d/%3d], Average Train Loss: [%5.3f], Accuracy: [%5.3f]" % (
epoch+1, num_epochs, curr_loss, curr_acc
))
print("-" * 50)
# 保存当前预测准确率最高的模型
if curr_acc > best_acc:
best_acc = curr_acc
ms.save_checkpoint(network, best_ckpt_path)
print("=" * 80)
print(f"End of validation the best Accuracy is: {best_acc: 5.3f}, "
f"save the best ckpt file in {best_ckpt_path}", flush=True)
运行结果:

可视化模型预测
定义visualize_model函数,使用上述验证精度最高的模型对CIFAR-10测试数据集进行预测,并将预测结果可视化。若预测字体颜色为蓝色表示为预测正确,预测字体颜色为红色则表示预测错误。
由上面的结果可知,5个epochs下模型在验证数据集的预测准确率在70%左右,即一般情况下,6张图片中会有2张预测失败。如果想要达到理想的训练效果,建议训练80个epochs。
代码示例:
import matplotlib.pyplot as plt
def visualize_model(best_ckpt_path, dataset_val):
num_class = 10 # 对狼和狗图像进行二分类
net = resnet50(num_class)
# 加载模型参数
param_dict = ms.load_checkpoint(best_ckpt_path)
ms.load_param_into_net(net, param_dict)
# 加载验证集的数据进行验证
data = next(dataset_val.create_dict_iterator())
images = data["image"]
labels = data["label"]
# 预测图像类别
output = net(data['image'])
pred = np.argmax(output.asnumpy(), axis=1)
# 图像分类
classes = []
with open(data_dir + "/batches.meta.txt", "r") as f:
for line in f:
line = line.rstrip()
if line:
classes.append(line)
# 显示图像及图像的预测值
plt.figure()
for i in range(6):
plt.subplot(2, 3, i + 1)
# 若预测正确,显示为蓝色;若预测错误,显示为红色
color = 'blue' if pred[i] == labels.asnumpy()[i] else 'red'
plt.title('predict:{}'.format(classes[pred[i]]), color=color)
picture_show = np.transpose(images.asnumpy()[i], (1, 2, 0))
mean = np.array([0.4914, 0.4822, 0.4465])
std = np.array([0.2023, 0.1994, 0.2010])
picture_show = std * picture_show + mean
picture_show = np.clip(picture_show, 0, 1)
plt.imshow(picture_show)
plt.axis('off')
plt.show()
# 使用测试数据集进行验证
visualize_model(best_ckpt_path=best_ckpt_path, dataset_val=dataset_val)
运行结果:

截图时间