1. 基本概念
容器就是一种文件格式,比如flv、mkv、mp4等。包含下面5种流以及文件头信息。
流是一种视频数据信息的传输方式,5种流:音频,视频,字幕,附件,数据。
包在ffmpeg中代表已经编码好的一个单位的音频或者视频。
帧在ffmpeg中帧代表一幅静止的图像(yuv数据)或一些数量的音频采样。
编解码器是对视频进行压缩或者解压缩,CODEC =ENCode (编码) +DECode(解码)
复用/解复用(mux/demux)
-
把不同的流按照某种容器的规则放入容器,这种行为叫做复用(mux)
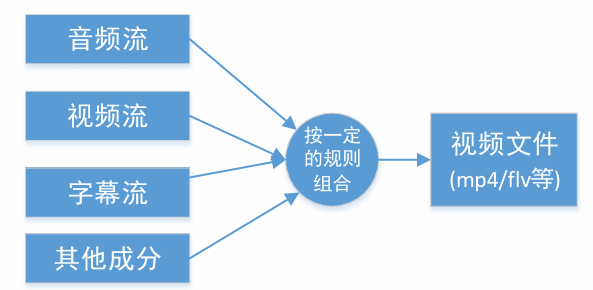
-
把不同的流从某种容器中解析出来,这种行为叫做解复用(demux)
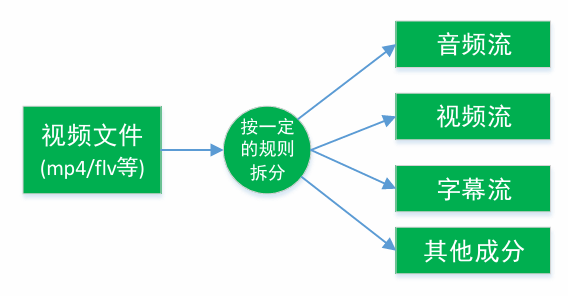
下面ffmpeg将h264+aac编码的flv文件转码为 h265+mp3编码的mp4文件的处理流程:
2. 解封装操作
2.1 封装相关API
◼ AVFormatContext* avformat_alloc_context();负责申请一个AVFormatContext结构的内存,并进行简单初始化
◼ avformat_free_context();释放该结构里的所有东西以及该结构本身
◼ avformat_close_input();关闭解复用器。关闭后就不再需要使用avformat_free_context 进行释放。
◼ avformat_open_input();打开输入视频文件
◼ avformat_find_stream_info():获取视频文件信息
◼ av_read_frame(); 读取音视频包
◼ avformat_seek_file(); 定位文件
◼ av_seek_frame():定位文件
2.2 解封装流程
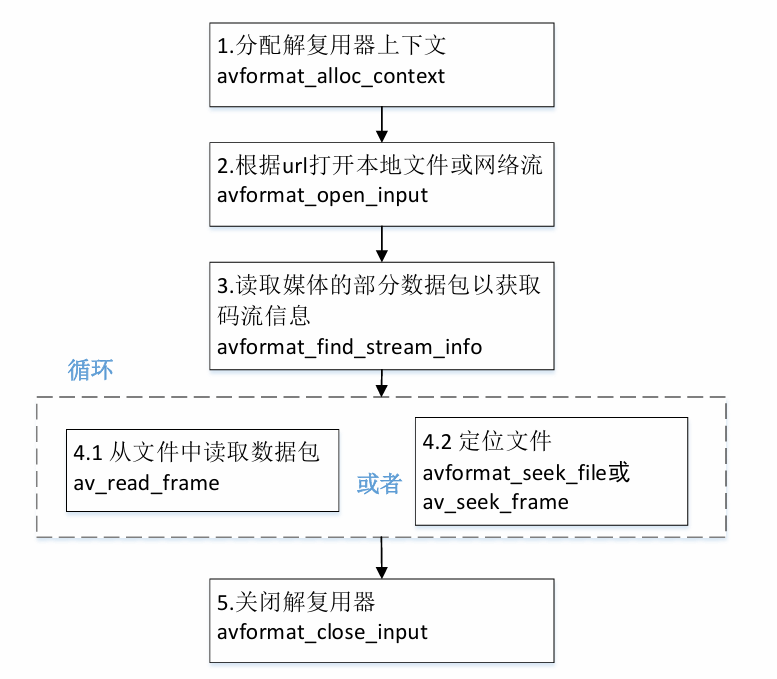
-
创建avformat上下文(可选)
AVFormatContext* avformat_alloc_context();因为调用
avformat_open_input函数时会创建, 所以不是必须调用,结束时必须使用avformat_free_context()销毁AVFormatContext指针 -
打开输入文件
// ps 指向AVFormatContext的指针,可以用avformat_alloc_context()提前申请,当然也可直接用 // avformat_open_input函数生成,不论哪种方式,都必须使用avformat_free_context()销毁该指针 //url 要打开的媒体流地址(或文件路径) //fmt 输入类型,如果此参数不为空,则强制设置输入媒体的类型(如flv、mp4等) //options 可选的选项,此处参考ffmpeg命令行操作里的一些输入参数,如reorder_queue_size、 // stimeout、scan_all_pmts 等等。使用av_dict_set()函数设置,使用av_dict_free()释放。 int avformat_open_input(AVFormatContext **ps, const char *url, ff_const59 AVInputFormat *fmt, AVDictionary **options);该函数作用是打开一个输入流(或者文件)并且读取媒体头信息(如音视频编码类型等等)。
任务结束时使用函数 avformat_close_input()关闭。 -
获取码流信息
区分不同的码流
◼ AVMEDIA_TYPE_VIDEO视频流 video_index = av_find_best_stream(ic, AVMEDIA_TYPE_VIDEO,-1,-1, NULL, 0) ◼ AVMEDIA_TYPE_AUDIO音频流 audio_index = av_find_best_stream(ic, AVMEDIA_TYPE_AUDIO,-1,-1, NULL, 0) AVPacket 里面也有一个index的字段由于需要读取数据包,avformat_find_stream_info接口会带来很大的延迟。
//读取媒体文件的数据包以获取流信息。 这个对于没有header的文件格式(例如MPEG)很有用。 // 总之使用该函数可以将输入流(文件)中的媒体信息(包括编码信息)解析出来。 // 通过ic->streams[i]访问,streams的个数由ic->nb_streams获取。 int avformat_find_stream_info(AVFormatContext *ic, AVDictionary **options) -
读取音视频包
//将输入文件或输入URL的流内容读取到AVPacket中 int av_read_frame(AVFormatContext *s, AVPacket *pkt);
2.3 解复用代码示例
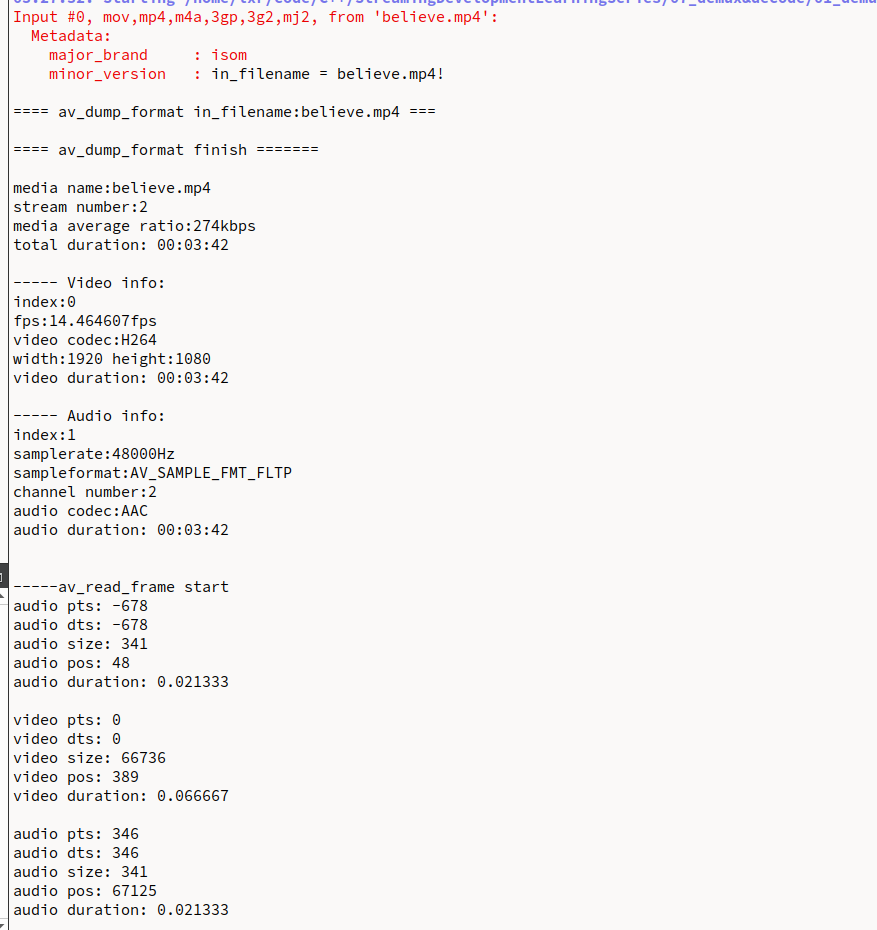
代码地址,打印信息如下
3. AAC ADTS格式分析
AAC⾳频格式:Advanced Audio Coding(⾼级⾳频解码),是⼀种由MPEG-4标准定义的有损⾳频压缩格式,由Fraunhofer发展,Dolby, Sony和AT&T是主要的贡献者。
-
ADIF:Audio Data Interchange Format ⾳频数据交换格式。这种格式的特征是可以确定的找到这个⾳频数据的开始,不需进⾏在⾳频数据流中间开始的解码,即它的解码必须在明确定义的开始处进⾏。故这种格式常⽤在磁盘⽂件中。
-
ADTS的全称是Audio Data Transport Stream。是AAC⾳频的传输流格式。AAC⾳频格式在MPEG-2(ISO-13318-7 2003)中有定义。AAC后来⼜被采⽤到MPEG-4标准中。这种格式的特征是它是⼀个有同步字的⽐特流,解码可以在这个流中任何位置开始。它的特征类似于mp3数据流格式。
简单说,ADTS可以在任意帧解码,也就是说它每⼀帧都有头信息。ADIF只有⼀个统⼀的头,所以必须得到所有的数据后解码。
且这两种的header的格式也是不同的,⽬前⼀般编码后的和抽取出的都是ADTS格式的⾳频流。两者具体的组织结构如下所示:

有的时候当你编码AAC裸流的时候,会遇到写出来的AAC⽂件并不能在PC和⼿机上播放,很⼤的可能就是AAC⽂件的每⼀帧⾥缺少了ADTS头信息⽂件的包装拼接, 比如MP4和FLV中的aac音频。解决方法:只需要加⼊头⽂件ADTS即可。⼀个AAC原始数据块⻓度是可变的,对原始帧加 上ADTS头进⾏ADTS的封装,就形成了ADTS帧。
AAC音频文件中的每一帧是由ADTS Header 和 AAC Audio Data组成,结构图如下:
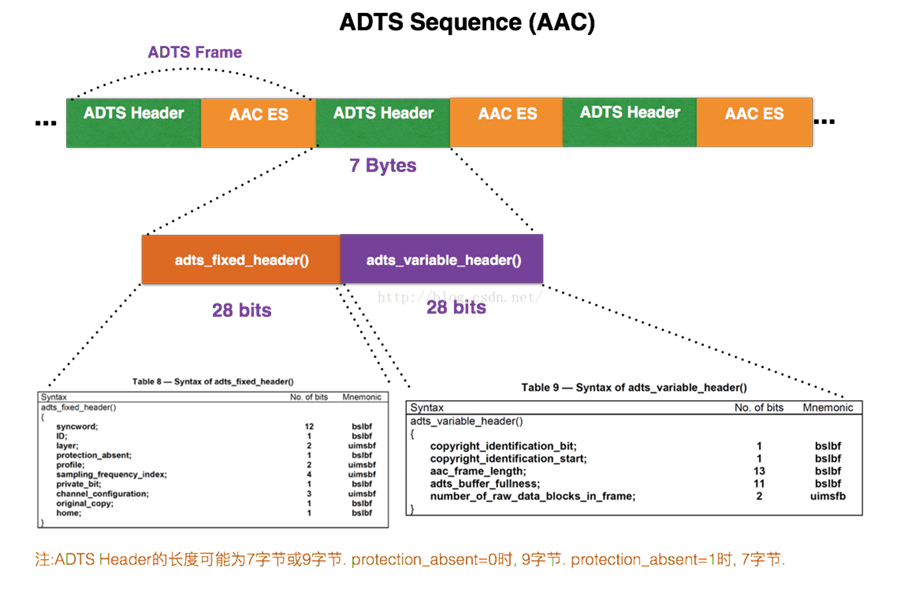
每⼀帧的ADTS的头⽂件都包含了⾳频的采样率,声道,帧⻓度等信息,这样解码器才能解析读取。
⼀般情况下ADTS的头信息都是7个字节,分为2部分:
adts_fixed_header();adts_variable_header();
adts_fixed_header为固定头信息,adts_variable_header是可变头信息。固定头信息中的数据每⼀帧都相同,⽽可变头信息则在帧与帧之间可变。
3.1 adts_fixed_header

-
syncword:同步头 总是0xFFF, all bits must be 1,代表着⼀个ADTS帧的开始 -
ID:MPEG标识符,0标识MPEG-4,1标识MPEG-2 -
Layer:always: ‘00’ -
protection_absent:表示是否误码校验。Warning, set to 1 if there is no CRC and 0 if there is CRC -
profile:表示使⽤哪个级别的AAC,如01 Low Complexity(LC)— AAC LC。有些芯⽚只⽀持AAC LC;MPEG-2 AAC中定义了3种:
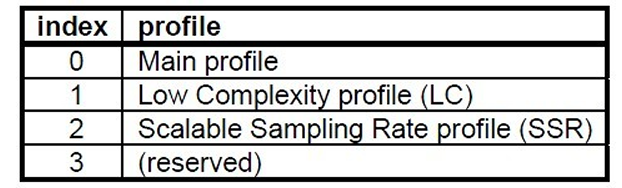
并且profile的值等于 Audio Object Type的值减1 profile = MPEG-4 Audio Object Type - 1
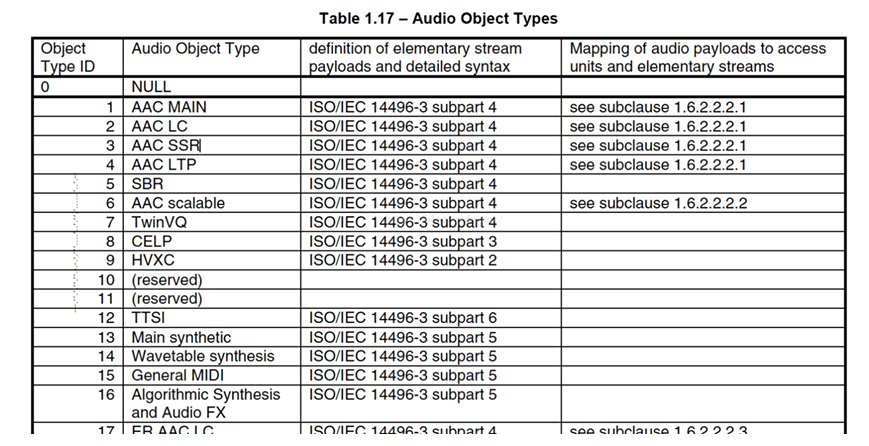
在ffmpeg源码中我们可以找到AAC级别被设成的值,就不用上面的那个公式来计算了:
/**
* profile
* - encoding: Set by user.
* - decoding: Set by libavcodec.
*/
int profile;
#define FF_PROFILE_UNKNOWN -99
#define FF_PROFILE_RESERVED -100
#define FF_PROFILE_AAC_MAIN 0
#define FF_PROFILE_AAC_LOW 1
#define FF_PROFILE_AAC_SSR 2
#define FF_PROFILE_AAC_LTP 3
#define FF_PROFILE_AAC_HE 4
#define FF_PROFILE_AAC_HE_V2 28
#define FF_PROFILE_AAC_LD 22
#define FF_PROFILE_AAC_ELD 38
#define FF_PROFILE_MPEG2_AAC_LOW 128
#define FF_PROFILE_MPEG2_AAC_HE 131
-
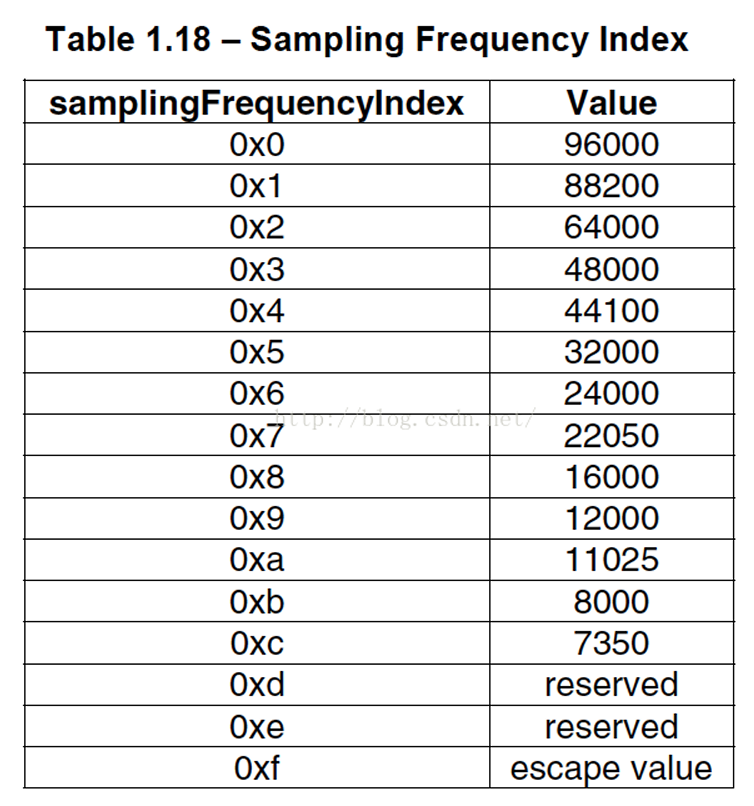
sampling_frequency_index:表示使⽤的采样率下标,通过这个下标在 Sampling Frequencies[ ]数组中查找得知采样率的值。
-
channel_configuration: 表示声道数,⽐如2表示⽴体声双声道

3.2 adts_variable_header

-
frame_length: ⼀个ADTS帧的⻓度包括ADTS头和AAC原始流. frame length, this value must include 7 or 9 bytes of header length: aac_frame_length = (protection_absent == 1 ? 7 : 9) + size(AACFrame)protection_absent=0时, header length=9bytes
protection_absent=1时, header length=7bytes -
adts_buffer_fullness:0x7FF 说明是码率可变的码流。number_of_raw_data_blocks_in_frame:表示ADTS帧中有 number_of_raw_data_blocks_in_frame + 1个AAC原始帧。所以说number_of_raw_data_blocks_in_frame == 0 表示说ADTS帧中有⼀个 AAC数据块
帧长度计算
unsigned int getFrameLength(unsigned char* str)
{
if ( !str )
{
return 0;
}
unsigned int len = 0;
int f_bit = str[3];
int m_bit = str[4];
int b_bit = str[5];
len += (b_bit>>5);
len += (m_bit<<3);
len += ((f_bit&3)<<11);
return len;
}
3.3 练习:提取MP4中的aac音频数据
代码可播放生成的aac文件
4. H264 NALU分析
⾳视频编码在流媒体和⽹络领域占有重要地位;流媒体编解码流程⼤致如下图所示:

4.1 h264编码原理
编码是为了将数据进行压缩,这样在传输的过程中就不会使资源被浪费,用一个简单的例子来说明编码的必要性:
⼀段分辨率为19201080,每个像素点为RGB占⽤3个字节,帧率是25的视频,对于传输带宽的要求是:19201080325/1024/1024=148.315MB/s,换成bps则意味着视频每秒带宽为1186.523Mbps,这样的速率对于⽹络存储是不可接受的。因此视频压缩和编码技术应运⽽⽣。
对于视频⽂件来说,视频由单张图⽚帧所组成,⽐如每秒25帧,但是图⽚帧的像素块之间存在相似性,因此视频帧图像可以进⾏图像压缩(内部压缩 | 空间压缩);H264采⽤了16*16的分块⼤⼩对,视频帧图像进⾏相似⽐较和压缩编码。如下图所示:

同理两帧图像之间也具有相似相似性,多个连续的图像帧也可以只记录差异,称为时间压缩|帧间压缩
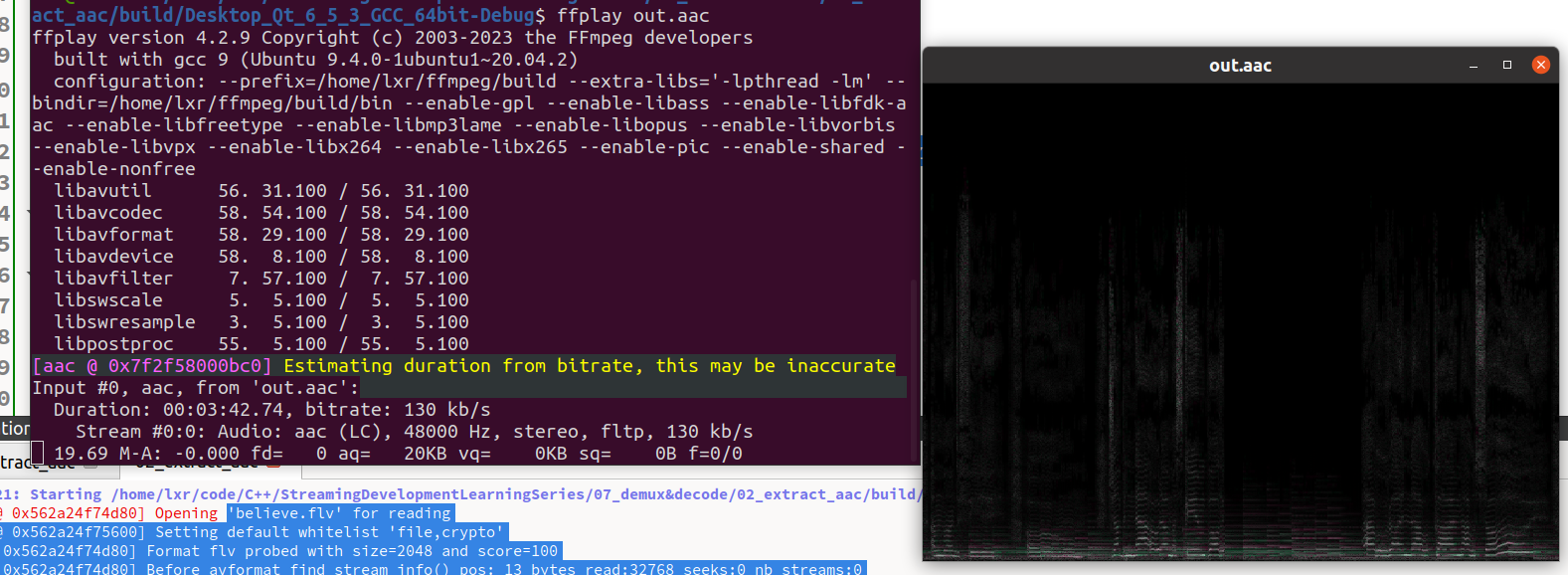
4.2 帧分类(IPB)
H264结构中,一个视频图像编码后的数据叫做一帧,一帧由一个片(slice)或多个片组成,一个片由一个或多个宏块(MB)组成,一个宏块由16x16的yuv数据组成。宏块作为H264编码的基本单位。
在H264协议内定义了三种帧,分别是I帧、B帧与P帧。I帧就是之前所说的一个完整的图像帧,而B、帧与P帧所对应的就是之前说的不编码全部图像的帧。P帧与B帧的差别就是P帧是参考之前的I帧 或 P帧而生成的,而B帧是参考前后图像帧(前一个I或P,以及后一个P)编码生成的。
压缩率 B > P > I
4.3 h264编码结构分析
H264除了实现了对视频的压缩处理之外,为了⽅便⽹络传输,提供了对应的视频编码和分⽚策略;类似于⽹络数据封装成I帧,在H264中将其称为组(GOP, group of pictures)、⽚(slice)、宏块(
Macroblock)这些⼀起组成了H264的码流分层结构;H264将其组织成为序列(GOP)、图⽚(pictrue)、⽚(Slice)、宏块(Macroblock)、⼦块(subblock)五个层次。
GOP (图像组)主要⽤作形容⼀个IDR帧 到下⼀个IDR帧之间的间隔了多少个帧。

H264将视频分为连续的帧进⾏传输,在连续的帧之间使⽤I帧、P帧和B帧。同时对于帧内⽽⾔,将图像分块为⽚、宏块和字块进⾏分⽚传输;通过这个过程实现对视频⽂件的压缩包装。
IDR(Instantaneous Decoding Refresh,即时解码刷新)
在编码解码中为了方便,将GOP中首个I帧要和其他I帧区别开,把第一个I帧叫IDR,这样方便控制编码和解码流程,所以IDR帧一定是I帧,但I帧不一定是IDR帧;IDR帧的作用是立刻刷新,使错误不致传播,从IDR帧开始算新的序列开始编码。I帧有被跨帧参考的可能,IDR不会。
I帧不用参考任何帧,但是之后的P帧和B帧是有可能参考这个I帧之前的帧的。IDR就不允许这样,例如:
- IDR1 P4 B2 B3 P7 B5 B6 I10 B8 B9 P13 B11 B12 P16 B14 B15 这里的B8可以跨过I10去参考P7
原始图像:IDR1 B2 B3 P4 B5 B6 P7 B8 B9 I10 - IDR1 P4 B2 B3 P7 B5 B6 IDR8 P11 B9 B10 P14 B11 B12 这里的B9就只能参照IDR8和P11,不可以参考IDR8前面的帧
作用:
H.264引入 IDR 图像是为了解码的重同步,当解码器解码到 IDR图像时,立即将参考帧队列清空,将已解码的数据全部输出或抛弃,重新查找参数集,开始一个新的序列。这样,如果前一个序列出现重大错误,在这里可以获得重新同步的机会。IDR图像之后的图像永远不会使用IDR之前的图像的数据来解码。
由于B帧需要一直等下一个P帧,所以会有延迟,所以直播一般不会插入B帧。
4.4 h264分层结构
H264的主要目标是为了有高的视频压缩比和良好的网络亲和性,为了达成这两个目标,H264的解决方案是将系统框架分为两个层面,分别是视频编码层面(VCL)和网络抽象层面(NAL),如图
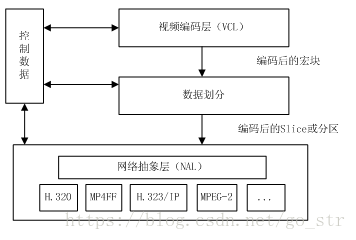
VLC层是对核心算法引擎、块、宏块及片的语法级别的定义,负责有效表示视频数据的内容,最终输出编码完的数据SODB;
NAL层定义了片级以上的语法级别(如序列参数集参数集和图像参数集,针对网络传输,后面会描述到),负责以网络所要求的恰当方式去格式化数据并提供头信息,以保证数据适合各种信道和存储介质上的传输。NAL层将SODB打包成RBSP然后加上NAL头组成一个NALU单元,具体NAL单元的组成也会在后面详细描述。
这里说一下SODB与RBSP的关联

SODB: 数据比特串,是编码后的原始数据;
RBSP: 原始字节序列载荷,是在原始编码数据后面添加了结尾比特,一个bit“1”和若干个比特“0”,用于字节对齐。
4.5 NALU 结构
在经过编码后的H264的码流如图所示, 从图中我们需要得到一个概念,H264码流是由一个个的NAL单元组成,其中SPS、PPS、IDR和SLICE是NAL单元某一类型的数据。
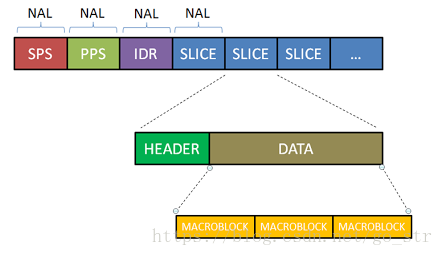
具体分析
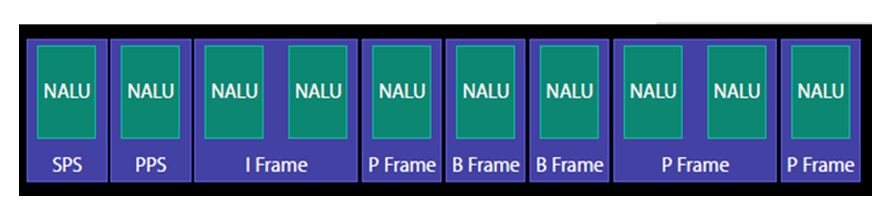
SPS:序列参数集,SPS中保存了⼀组编码视频序列(Coded video sequence)的全局参数。
PPS:图像参数集,对应的是⼀个序列中某⼀幅图像或者某⼏幅图像的参数。
I帧:帧内编码帧,可独⽴解码⽣成完整的图⽚。
P帧: 前向预测编码帧,需要参考其前⾯的⼀个I 或者B 来⽣成⼀张完整的图⽚。
B帧: 双向预测内插编码帧,则要参考其前⼀个I或者P帧及其后⾯的⼀个P帧来⽣成⼀张完整的图⽚。
发I帧之前,⾄少要发⼀次SPS和PPS。
H.264原始码流(裸流)是由⼀个接⼀个NALU组成,它的功能分为两层,VCL(视频编码层)和NAL(⽹络提取层):
- VCL:包括核⼼压缩引擎和块,宏块和⽚的语法级别定义,设计⽬标是尽可能地独⽴于⽹络进⾏⾼效的编码;
- NAL:负责将VCL产⽣的⽐特字符串适配到各种各样的⽹络和多元环境中,覆盖了所有⽚级以上的语法级别
在VCL进⾏数据传输或存储之前,这些编码的VCL数据,被映射或封装进NAL单元。
⼀个NALU = ⼀组对应于视频编码的NALU头部信息 + ⼀个原始字节序列负荷(RBSP,Raw Byte Sequence Payload)
NALU结构单元的主体结构如下所示;⼀个原始的H.264 NALU单元通常由[StartCode] [NALU Header] [NALU Payload]三部分组成,其中 Start Code ⽤于标示这是⼀个NALU 单元的开始,必须是"00 00 00 01" 或"00 00 01" ,除此之外基本相当于⼀个NAL header + RBSP;

(对于FFmpeg解复⽤后,MP4⽂件读取出来的packet是不带startcode,但TS⽂件读取出来的packet带startcode)
每个NAL单元是⼀个⼀定语法元素的可变⻓字节字符串,包括包含⼀个字节的头信息(⽤来表示数据类型),以及若⼲整数字节的负荷数据。
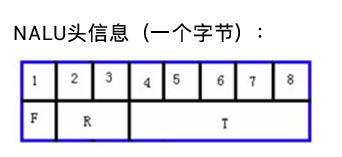
- F(forbiden):禁止位,占用NAL头的第一个位,当禁止位值为1时表示语法错误;
- NRI:参考级别,占用NAL头的第二到第三个位;值越大,该NAL越重要。
- Type:Nal单元数据类型,也就是标识该NAL单元的数据类型是哪种,占用NAL头的第四到第8个位;
(1~12由H.264使⽤,24~31由H.264以外的应⽤使⽤)
H.264标准指出,当数据流是储存在介质上时,在每个NALU 前添加起始码:0x000001 或0x00000001,⽤来指示⼀个NALU 的起始和终⽌位置:
- 在这样的机制下,在码流中检测起始码,作为⼀个NALU得起始标识,当检测到下⼀个起始码时,当前NALU结束。
- 3字节的0x000001只有⼀种场合下使⽤,就是⼀个完整的帧被编为多个slice(⽚)的时候,包含这些slice的NALU 使⽤3字节起始码。其余场合都是4字节0x00000001的。
例⼦:
0x00 00 00 01 67 …
0x00 00 00 01 68 …
0x00 00 00 01 65 …
67(NALU头):⼆进制:0110 0111 00111 = 7(⼗进制)
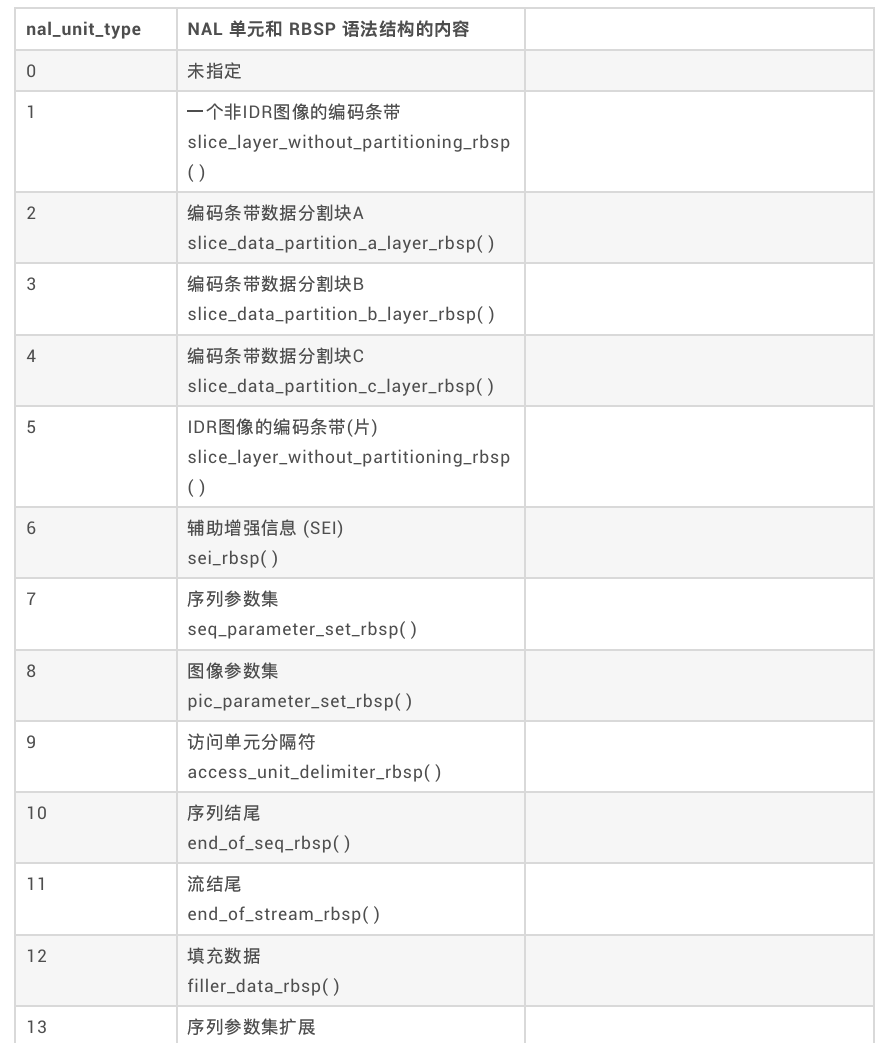
具体种类如下:

4.6 annexb模式
H264有两种封装
- ⼀种是annexb模式,传统模式,有startcode,SPS和PPS是在ES中
- ⼀种是mp4模式,⼀般mp4 mkv都是mp4模式,没有startcode,SPS和PPS以及其它信息被封装在container中,每⼀个frame前⾯4个字节是这个frame的⻓度
很多解码器只⽀持annexb这种模式,因此需要将mp4做转换:在ffmpeg中⽤h264_mp4toannexb_filter可以做转换(没有start_code 裸流无法播放)
实现:
const AVBitStreamFilter *bsfilter = av_bsf_get_by_name("h264_mp4toannexb");
AVBSFContext *bsf_ctx = NULL;
// 2 初始化过滤器上下⽂
av_bsf_alloc(bsfilter, &bsf_ctx); //AVBSFContext;
// 3 添加解码器属性
avcodec_parameters_copy(bsf_ctx->par_in, ifmt_ctx->streams[videoindex]->codecpar);
av_bsf_init(bsf_ctx);
补充:ts流可以不加start_code,与封装格式有关
具体测试代码见连接h264
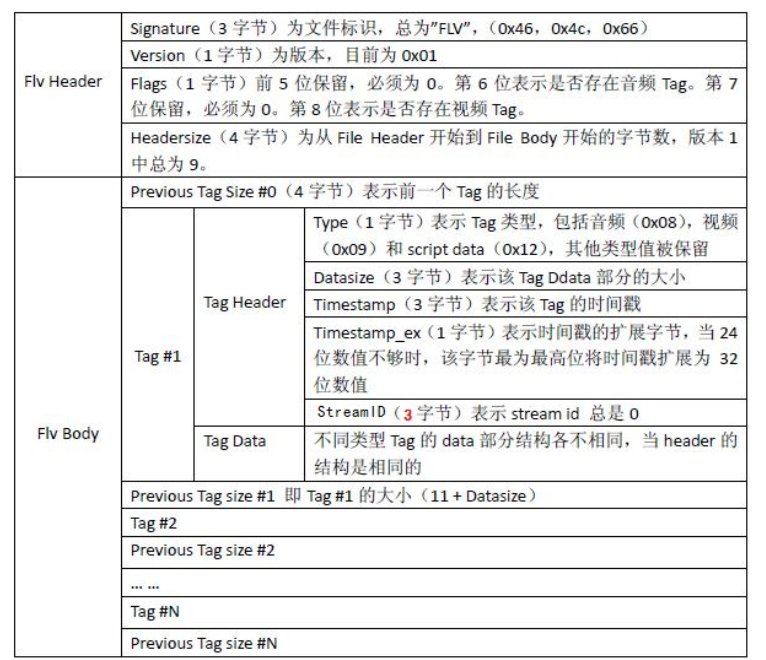
5. FLV格式解析
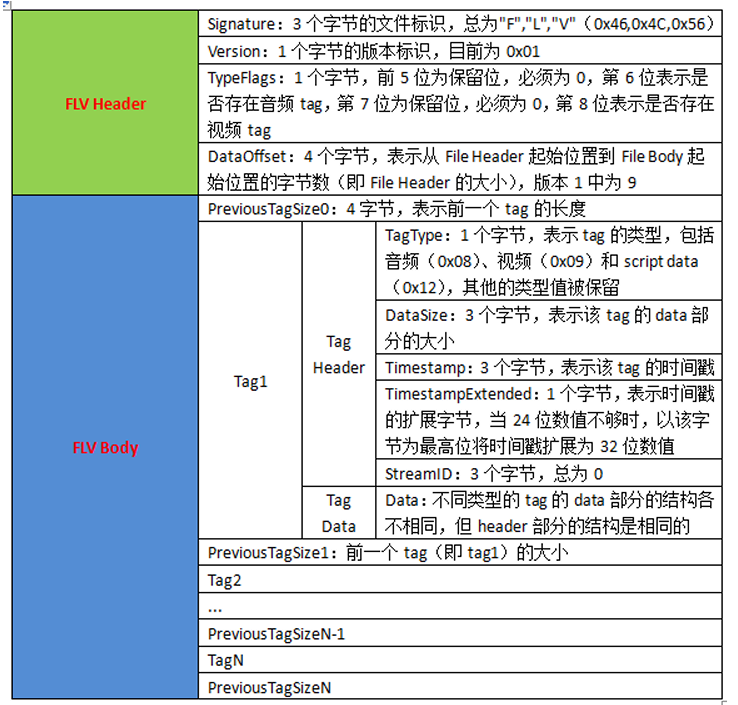
flv即flash video,是Adobe公司推出的一种音视频封装格式,这家公司在音视频、图像图形领域也算是神一般的存在,多少都用过他们家的产品。常见的Photoshop和Flash palyer就是他们家的。今天要讲到的flv也是他们推出来的,也是Flash palyer播放的标准音视频格式。在HTML5出来之前,想在web上播放音视频,基本都靠flash插件。
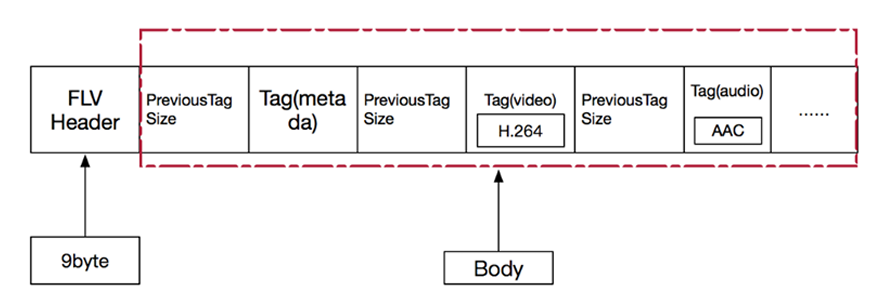
FLV封装格式是由⼀个⽂件头(file header)和 ⽂件体(file Body)组成。其中,FLV body由⼀对对的(Previous Tag Size字段 + tag)组成。Previous Tag Size字段 排列在Tag之前,占⽤4个字节。Previous Tag Size记录了前⾯⼀个Tag的⼤⼩,⽤于逆向读取处理。FLV header后的第⼀个Pervious Tag Size的值为0.
Tag⼀般可以分为3种类型:脚本(帧)数据类型、⾳频数据类型、视频数据。FLV数据以⼤端序
进⾏存储,在解析时需要注意。⼀个标准FLV⽂件结构如下图:
FLV⽂件的详细内容结构如下图:
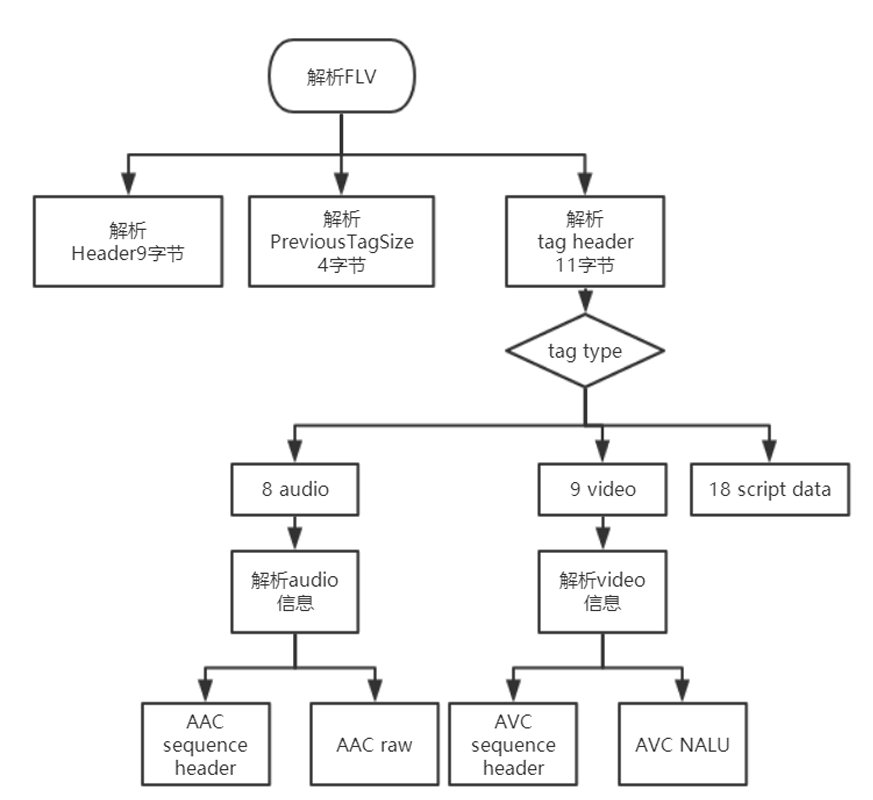
flv解析流程如下:
5.1 FLV Header
FLV头占9个字节,⽤来标识⽂件为FLV类型,以及后续存储的⾳视频流。⼀个FLV⽂件,每种类型的tag都属于⼀个流,也就是⼀个flv⽂件最多只有⼀个⾳频流,⼀个视频流,不存在多个独⽴的⾳视频流在⼀个⽂件的情况。
FLV头的结构如下:
| Field | Type | Comment |
|---|---|---|
| 签名 | UI8 | ‘F’(0x46) |
| 签名 | UI8 | ‘L’(0x4C) |
| 签名 | UI8 | ‘V’(0x56) |
| 版本 | UI8 | FLV的版本。0x01表示FLV版本为1 |
| 保留字段 | UB5 | 前五位都为0 |
| 音频流标识 | UB1 | 是否存在音频流 |
| 保留字段 | UB1 | 为0 |
| 视频流标识 | UB1 | 是否存在视频流 |
| 文件头大小 | UI32 | FLV版本1时填写9,表明的是FLV头的大小,为后期的FLV版本扩展使用。包括这四个字节。数据的起始位置就是从文件开头偏移这么多的大小。 |
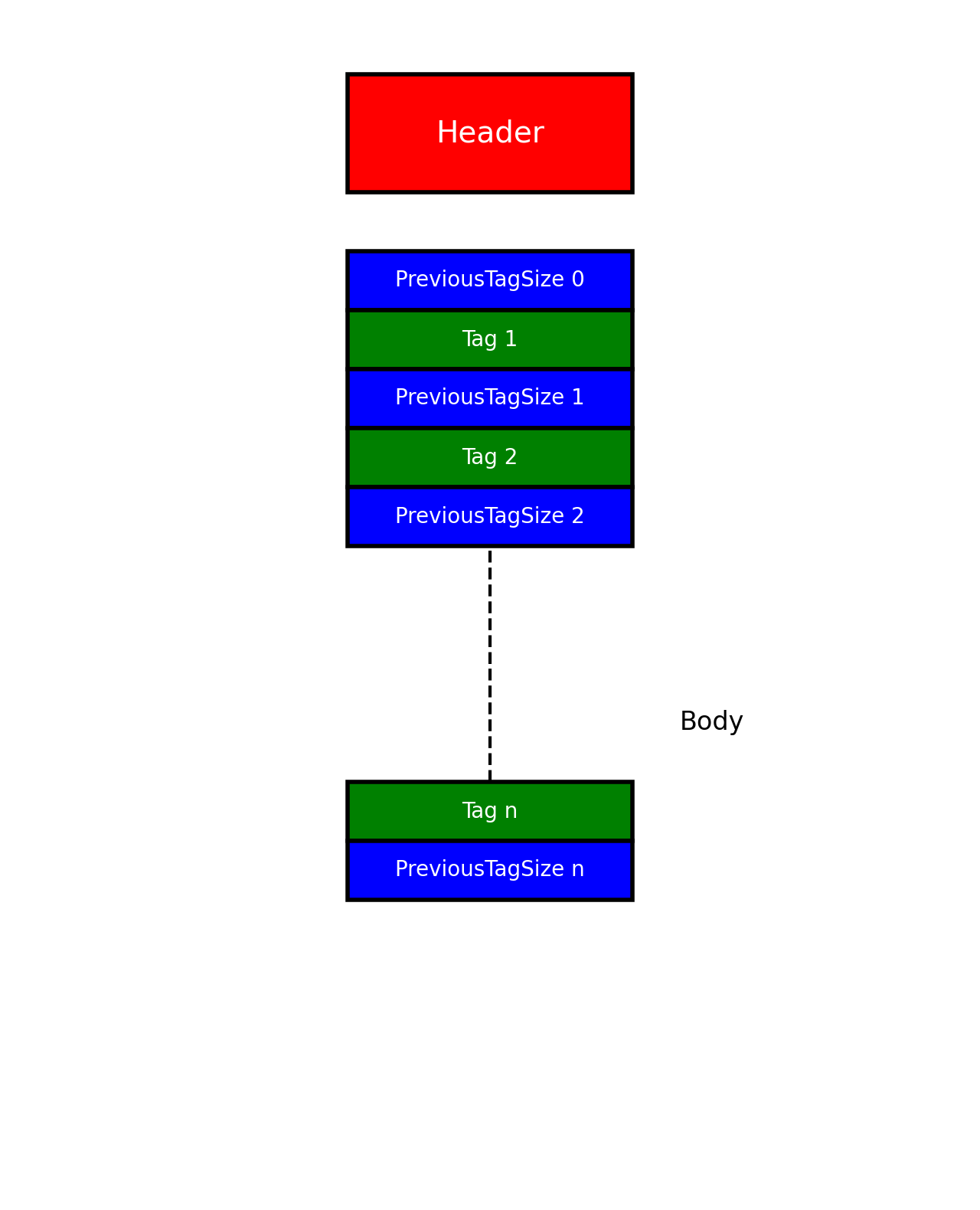
5.2 FLV_Body
FLV Header之后,就是FLV File Body。FLV File Body是由⼀连串的back-pointers + tags构成。Back-pointer表示Previous Tag Size(前⼀个tag的字节数据⻓度),占4个字节。00 00 01 7F计算出⼤⼩ 383= 0x0000017F
5.3 FLV_Tag
每⼀个Tag也是由两部分组成:tag header和tag data。Tag Header⾥存放的是当前tag的类型、数据区(tag data)的⻓度等信息。
- Tag Header
tag header⼀般占11个字节的内存空间。FLV tag结构如下:
| Field | Type | Comment |
|---|---|---|
| Tag类型 Type | UI8 | 8:audio 9:video 18:Script data(脚本数据) all Others:reserved 其他所有值未使用 |
| 数据区大小 | UI24 | 当前tag的数据域的大小,不包含tag header。 Length of the data in the Data field |
| 时间戳 Timestamp | UI24 | 当前帧时戳,单位是毫秒。相对值,第一个tag的时戳总是为0 |
| 时戳扩展字段 TimestampExtended | UI8 | 如果时戳大于0xFFFFFF,将会使用这个字节。这个字节是时戳的高8位,上面的三个字节是低24位。 |
| StreamID | UI24 | 总是为0 |
| 数据域 | UI[8*n] | 数据域数据 |
注意:
- flv⽂件中Timestamp和TimestampExtended拼出来的是dts。也就是解码时间。Timestamp和TimestampExtended拼出来dts单位为ms。(如果不存在B帧,当然dts等于pts)
- CompositionTime 表示PTS相对于DTS的偏移值, 在每个视频tag的第14~16字节,显示时间(pts) = 解码时间(tag的第5~8字节) + CompositionTime CompositionTime的单位也是ms
-
Script Tag Data结构(脚本类型、帧类型)
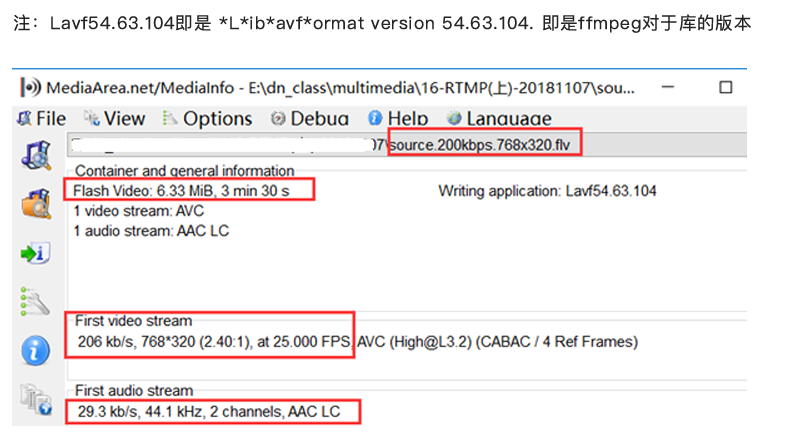
该类型Tag⼜被称为MetaData Tag,存放⼀些关于FLV视频和⾳频的元信息,⽐如:duration、width、height等。通常该类型Tag会作为FLV⽂件的第⼀个tag,并且只有⼀个,跟在File Header后。该类型TagDaTa的结构如下所示(source.200kbps.768x320.flv⽂件为例):

- 第⼀个AMF包: 第1个字节表示AMF包类型,⼀般总是0x02,表示字符串。第2-3个字节为UI16类型值,标识字符串的⻓度,⼀般总是0x000A(“onMetaData”⻓度)。后⾯字节为具体的字符串,⼀般总为“ onMetaData”(6F,6E,4D,65,74,61,44,61,74,61)。
- 第⼆个AMF包: 第1个字节表示AMF包类型,⼀般总是0x08,表示数组。第2-5个字节为UI32类型值,表示数组元素的个数。后⾯即为各数组元素的封装,数组元素为元素名称和值组成的对。常⻅的数组元素如下表所示
值 Comment 例如 duration 时长(秒) 210.732 width 视频宽度 768.000 height 视频高度 320.000 videodatarate 视频码率 207.260 framerate 视频帧率 25.000 videocodecid 视频编码ID 7.000 (H264为7) audiodatarate 音频码率 29.329 audiosamplerate 音频采样率 44100.000 stereo 是否立体声 1 audiocodecid 音频编码ID 10.000 (AAC为10) major_brand 格式规范相关 isom minor_version 格式规范相关 512 compatible_brands 格式规范相关 isomiso2avc1mp41 encoder 封装工具名称 Lavf54.63.104 filesize 文件大小(字节) 6636853.000
5.4. Audio Tag Data结构(⾳频类型)
⾳频Tag Data区域开始的:
- 第⼀个字节包含了⾳频数据的参数信息,
- 第⼆个字节开始为⾳频流数据。
(这两个字节属于tag的data部分,不是header部分)
第⼀个字节为⾳频的信息(仔细看spec发现对于AAC⽽⾔,⽐较有⽤的字段是
SoundFormat),格式如下:
| Field | Type | Comment |
|---|---|---|
| 音频格式 SoundFormat | UB4 | 0 = Linear PCM, platform endian 1 = ADPCM 2 = MP3 3 = Linear PCM, little endian 4 = Nellymoser 16–kHz mono 5 = Nellymoser 8–kHz mono 6 = Nellymoser 7 = G.711 A–law logarithmic PCM 8 = G.711 mu–law logarithmic PCM 9 = reserved 10 = AAC 11 = Speex 14 = MP3 8–KHz 15 = Device–specific sound |
| 采样率 SoundRate | UB2 | 0 = 5.5kHz 1 = 11kHz 2 = 22.05kHz 3 = 44.1kHz 对于AAC总是3。但实际上AAC是可以支持到48kHz以上的频率(这个参数对于AAC意义不大)。 |
| 采样精度 SoundSize | UB1 | 0 = snd8Bit 1 = snd16Bit 此参数仅适用于未压缩的格式,压缩后的格式都将其设为1 |
| 音频声道 SoundType | UB1 | 0 = sndMono 单声道 1 = sndStereo 立体声,双声道 对于AAC总是1 |
如果 SoundFormat 表示 AAC,SoundType 应设置为 1(立体声),SoundRate 应设置为 3(44 kHz)。然而,这并不意味着 FLV 中的 AAC 音频总是立体声、44 kHz 数据。相反,Flash Player 会忽略这些值,而是从 AAC 位流中提取声道和采样率数据。
第⼆个字节开始为⾳频数据(需要判断该数据是真正的⾳频数据,还是⾳频config信息)
| Field | Type | Comment |
|---|---|---|
| 音频数据 | UI[8*n] | if SoundFormat == 10 (AAC类型) AACAUDIODATA else Sound data—varies by format |
AACAUDIODATA
| Field | Type | Comment |
|---|---|---|
| AACPacketType | UI8 | 0: AAC sequence header 1: AAC raw |
| Data | UI8[n] | if AACPacketType == 0 AudioSpecificConfig else if AACPacketType == 1 Raw AAC frame data |
The AudioSpecificConfig is explained in ISO 14496-3. AAC sequence header存放的是AudioSpecificConfig结构,该结构则在“ ISO-14496-3 Audio”中描述。
如果是AAC数据,如果他是AAC RAW, tag data[3] 开始才是真正的AAC frame data。

5.5. Video Tag Data结构(视频类型)
视频Tag Data开始的:
- 第⼀个字节包含视频数据的参数信息,
- 第⼆个字节开始为视频流数据。
第⼀个字节包含视频信息,格式如下:
| Field | Type | Comment |
|---|---|---|
| 帧类型 | UB4 | 1: keyframe (for AVC, a seekable frame)——h264的IDR, 关键帧 2: inter frame (for AVC, a non– seekable frame)——h264的普通帧 3: disposable inter frame (H.263 only) 4: generated keyframe (reserved for server use only) 5: video info/command frame |
| 编码ID | UB4 | 使用哪种编码类型: 1: JPEG (currently unused) 2: Sorenson H.263 3: Screen video 4: On2 VP6 5: On2 VP6 with alpha channel 6: Screen video version 2 7: AVC |
第⼆个字节开始为视频数据
| Field | Type | Comment |
|---|---|---|
| 视频数据 | UI[8*n] | If CodecID == 2 H263VIDEOPACKET If CodecID == 3 SCREENVIDEOPACKET If CodecID == 4 VP6FLVIDEOPACKET If CodecID == 5 VP6FLALPHAVIDEOPACKET If CodecID == 6 SCREENV2VIDEOPACKET If CodecID == 7 (AVC格式) AVCVIDEOPACKET |
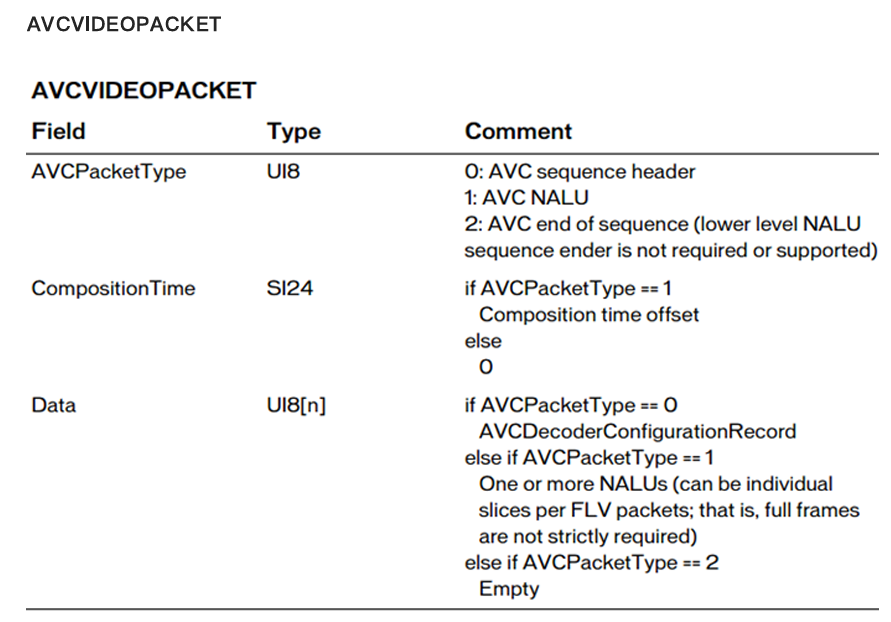
(1)CompositionTime 单位毫秒
CompositionTime 每个视频tag(整个tag)的第14~16字节(如果是tag data偏移[3]~[5], [0],[1][2:AVCPackettype] )(表示PTS相对于DTS的偏移值 )。
CompositionTime 单位为ms : 显示时间 = 解码时间(tag的第5~ 8字节,位置索引[4]~[7])+CompositionTime
(2)AVCDecoderConfigurationRecord
AVC sequence header就是AVCDecoderConfigurationRecord结构.
5.6 FlvParser
5.6.1 main函数
流程:
1、读取输入文件(flv类型的视频文件)
2、调用Process进行处理
3、退出
int main(int argc, char* argv[])
{
cout << "Hi, this is FLV parser test program!\n";
if (argc != 3)
{
cout << "FlvParser.exe [input flv] [output flv]" << endl;
return 0;
}
fstream fin;
fin.open(argv[1], ios_base::in | ios_base::binary);
if (!fin)
{
return 0;
}
Process(fin, argv[2]);
fin.close();
return 1;
}
5.6.2 处理函数Process
1、读取文件
2、开始解析
3、打印解析信息
4、把解析之后的数据输出到另外一个文件中
void Process(fstream &fin, const char *filename)
{
CFlvParser parser;
int nBufSize = 2000 * 1024;
int nFlvPos = 0;
unsigned char *pBuf, *pBak;
pBuf = new unsigned char[nBufSize];
pBak = new unsigned char[nBufSize];
while (1)
{
int nReadNum = 0;
int nUsedLen = 0;
fin.read((char *)pBuf + nFlvPos, nBufSize - nFlvPos);
nReadNum = fin.gcount();
if (nReadNum == 0)
break;
nFlvPos += nReadNum;
parser.Parse(pBuf, nFlvPos, nUsedLen);
if (nFlvPos != nUsedLen)
{
memcpy(pBak, pBuf + nUsedLen, nFlvPos - nUsedLen);
memcpy(pBuf, pBak, nFlvPos - nUsedLen);
}
nFlvPos -= nUsedLen;
}
parser.PrintInfo();
/*parser.DumpH264("parser.264");
parser.DumpAAC("parser.aac");*/
//dump into flv
parser.DumpFlv(filename);
delete []pBak;
delete []pBuf;
}
5.6.3 解析函数
1、解析flv的头部
2、解析flv的Tag
int CFlvParser::Parse(unsigned char *pBuf, int nBufSize, int &nUsedLen)
{
int nOffset = 0;
if (_pFlvHeader == 0)
{
CheckBuffer(9);
_pFlvHeader = CreateFlvHeader(pBuf+nOffset);
nOffset += _pFlvHeader->nHeadSize;
}
while (1)
{
CheckBuffer(15);
int nPrevSize = ShowU32(pBuf + nOffset); //nPrevSize(4字节) + Tag header(11字节)
nOffset += 4;
Tag *pTag = CreateTag(pBuf + nOffset, nBufSize-nOffset);
if (pTag == NULL)
{
nOffset -= 4;
break;
}
nOffset += (11 + pTag->_header.nDataSize);
_vpTag.push_back(pTag);
}
nUsedLen = nOffset;
return 0;
}
5.6.4 FLV相关的数据结构
CFlvParser表示FLV解析器
FLV由FLV头部和FLV体构成,其中FLV体是由一系列的FLV tag构成的
class CFlvParser
{
public:
CFlvParser();
virtual ~CFlvParser();
int Parse(unsigned char *pBuf, int nBufSize, int &nUsedLen);
int PrintInfo();
int DumpH264(const std::string &path);
int DumpAAC(const std::string &path);
int DumpFlv(const std::string &path);
private:
// flv的头
typedef struct FlvHeader_s FlvHeader;
// Tag头部
struct TagHeader;
// flv的tag(普通的script Tag)
class Tag;
// 视频类型Tag
class CVideoTag : public Tag;
// 音频类型Tag
class CAudioTag : public Tag;
// FLV的状态信息
struct FlvStat;
static unsigned int ShowU32(unsigned char *pBuf) { return (pBuf[0] << 24) | (pBuf[1] << 16) | (pBuf[2] << 8) | pBuf[3]; }
static unsigned int ShowU24(unsigned char *pBuf) { return (pBuf[0] << 16) | (pBuf[1] << 8) | (pBuf[2]); }
static unsigned int ShowU16(unsigned char *pBuf) { return (pBuf[0] << 8) | (pBuf[1]); }
static unsigned int ShowU8(unsigned char *pBuf) { return (pBuf[0]); }
static void WriteU64(uint64_t & x, int length, int value);
static unsigned int WriteU32(unsigned int n);
friend class Tag;
private:
FlvHeader *CreateFlvHeader(unsigned char *pBuf);
int DestroyFlvHeader(FlvHeader *pHeader);
Tag *CreateTag(unsigned char *pBuf, int nLeftLen);
int DestroyTag(Tag *pTag);
int Stat();
int StatVideo(Tag *pTag);
int IsUserDataTag(Tag *pTag);
private:
FlvHeader* _pFlvHeader;
vector<Tag *> _vpTag;
FlvStat _sStat;
CVideojj *_vjj;
// H.264
int _nNalUnitLength;
};
FlvHeader表示FLV的头部
// flv的头
typedef struct FlvHeader_s
{
int nVersion; // 版本
int bHaveVideo, bHaveAudio; // 是否包含音视频
int nHeadSize; // FLV头部长度
/*
** 指向存放FLV头部的buffer
** 上面的三个成员指明了FLV头部的信息,是从FLV的头部中“翻译”得到的,
** 真实的FLV头部是一个二进制比特串,放在一个buffer中,由pFlvHeader成员指明
*/
unsigned char *pFlvHeader;
} FlvHeader;
标签
标签包括标签头部和标签体,根据类型的不同,标签体可以分成三种:
script类型的标签,⾳频标签、视频标签
- 标签头部
// Tag头部
struct TagHeader
{
int nType; // 类型
int nDataSize; // 标签body的大小
int nTimeStamp; // 时间戳
int nTSEx; // 时间戳的扩展字节
int nStreamID; // 流的ID,总是0
unsigned int nTotalTS;
TagHeader() : nType(0), nDataSize(0), nTimeStamp(0), nTSEx(0), nStreamID(0), nTotalTS(0) {}
~TagHeader() {}
};
- 标签数据
- script类型的标签
// flv的tag
class Tag
{
public:
Tag() : _pTagHeader(NULL), _pTagData(NULL), _pMedia(NULL), _nMediaLen(0) {}
void Init(TagHeader *pHeader, unsigned char *pBuf, int nLeftLen);
TagHeader _header;
unsigned char *_pTagHeader; // 指向标签头部
unsigned char *_pTagData; // 指向标签body
unsigned char *_pMedia; // 指向标签的元数据
int _nMediaLen;
};
- 音频标签
class CAudioTag : public Tag
{
public:
CAudioTag(TagHeader *pHeader, unsigned char *pBuf, int nLeftLen, CFlvParser *pParser);
int _nSoundFormat; // 音频编码类型
int _nSoundRate; // 采样率
int _nSoundSize; // 精度
int _nSoundType; // 类型
// aac
static int _aacProfile;
static int _sampleRateIndex;
static int _channelConfig;
int ParseAACTag(CFlvParser *pParser);
int ParseAudioSpecificConfig(CFlvParser *pParser, unsigned char *pTagData);
int ParseRawAAC(CFlvParser *pParser, unsigned char *pTagData);
};
- 视频标签
class CVideoTag : public Tag
{
public:
CVideoTag(TagHeader *pHeader, unsigned char *pBuf, int nLeftLen, CFlvParser *pParser);
int _nFrameType; // 帧类型
int _nCodecID; // 视频编解码类型
int ParseH264Tag(CFlvParser *pParser);
int ParseH264Configuration(CFlvParser *pParser, unsigned char *pTagData);
int ParseNalu(CFlvParser *pParser, unsigned char *pTagData);
};
5.6.5 解析FLV头部
int CFlvParser::Parse(unsigned char *pBuf, int nBufSize, int &nUsedLen)
{
int nOffset = 0;
if (_pFlvHeader == 0)
{
CheckBuffer(9);
// 解析FLV头部
_pFlvHeader = CreateFlvHeader(pBuf+nOffset);
nOffset += _pFlvHeader->nHeadSize;
}
while (1)
{
CheckBuffer(15);
int nPrevSize = ShowU32(pBuf + nOffset);
nOffset += 4;
Tag *pTag = CreateTag(pBuf + nOffset, nBufSize-nOffset);
if (pTag == NULL)
{
nOffset -= 4;
break;
}
nOffset += (11 + pTag->_header.nDataSize);
_vpTag.push_back(pTag);
}
nUsedLen = nOffset;
return 0;
}
CFlvParser::FlvHeader *CFlvParser::CreateFlvHeader(unsigned char *pBuf)
{
FlvHeader *pHeader = new FlvHeader;
pHeader->nVersion = pBuf[3]; // 版本号
pHeader->bHaveAudio = (pBuf[4] >> 2) & 0x01; // 是否有音频
pHeader->bHaveVideo = (pBuf[4] >> 0) & 0x01; // 是否有视频
pHeader->nHeadSize = ShowU32(pBuf + 5); // 头部长度
pHeader->pFlvHeader = new unsigned char[pHeader->nHeadSize];
memcpy(pHeader->pFlvHeader, pBuf, pHeader->nHeadSize);
return pHeader;
}
5.6.6 解析Tag头部
1、CFlvParser::Parse调用CreateTag解析标签
2、CFlvParser::CreateTag首先解析标签头部
3、根据标签头部的类型字段,判断标签的类型
4、如果是视频标签,那么解析视频标签
5、如果是音频标签,那么解析音频标签
6、如果是其他的标签,那么调用Tag::Init进行解析
解析标签头部的函数
CFlvParser::Tag *CFlvParser::CreateTag(unsigned char *pBuf, int nLeftLen)
{
// 开始解析标签头部
TagHeader header;
header.nType = ShowU8(pBuf+0); // 类型
header.nDataSize = ShowU24(pBuf + 1); // 标签body的长度
header.nTimeStamp = ShowU24(pBuf + 4); // 时间戳
header.nTSEx = ShowU8(pBuf + 7); // 时间戳的扩展字段
header.nStreamID = ShowU24(pBuf + 8); // 流的id
header.nTotalTS = (unsigned int)((header.nTSEx << 24)) + header.nTimeStamp;
// 标签头部解析结束
cout << "total TS : " << header.nTotalTS << endl;
//cout << "nLeftLen : " << nLeftLen << " , nDataSize : " << pTag->header.nDataSize << endl;
if ((header.nDataSize + 11) > nLeftLen)
{
return NULL;
}
Tag *pTag;
switch (header.nType) {
case 0x09: // 视频类型的Tag
pTag = new CVideoTag(&header, pBuf, nLeftLen, this);
break;
case 0x08: // 音频类型的Tag
pTag = new CAudioTag(&header, pBuf, nLeftLen, this);
break;
default: // script类型的Tag
pTag = new Tag();
pTag->Init(&header, pBuf, nLeftLen);
}
return pTag;
}
解析视频标签
-
入口函数CreateTag
1、解析标签头部 2、判断标签头部的类型 3、根据标签头部的类型,解析不同的标签 4、如果是视频类型的标签,那么就创建并解析视频标签
CFlvParser::Tag *CFlvParser::CreateTag(unsigned char *pBuf, int nLeftLen)
{
// 开始解析标签头部
TagHeader header;
header.nType = ShowU8(pBuf+0); // 类型
header.nDataSize = ShowU24(pBuf + 1); // 标签body的长度
header.nTimeStamp = ShowU24(pBuf + 4); // 时间戳
header.nTSEx = ShowU8(pBuf + 7); // 时间戳的扩展字段
header.nStreamID = ShowU24(pBuf + 8); // 流的id
header.nTotalTS = (unsigned int)((header.nTSEx << 24)) + header.nTimeStamp;
// 标签头部解析结束
cout << "total TS : " << header.nTotalTS << endl;
//cout << "nLeftLen : " << nLeftLen << " , nDataSize : " << pTag->header.nDataSize << endl;
if ((header.nDataSize + 11) > nLeftLen)
{
return NULL;
}
Tag *pTag;
switch (header.nType) {
case 0x09: // 视频类型的Tag
pTag = new CVideoTag(&header, pBuf, nLeftLen, this);
break;
case 0x08: // 音频类型的Tag
pTag = new CAudioTag(&header, pBuf, nLeftLen, this);
break;
default: // script类型的Tag
pTag = new Tag();
pTag->Init(&header, pBuf, nLeftLen);
}
return pTag;
}
-
创建视频标签
1、初始化 2、解析帧类型 3、解析视频编码类型 4、解析视频标签
CFlvParser::CVideoTag::CVideoTag(TagHeader *pHeader, unsigned char *pBuf, int nLeftLen, CFlvParser *pParser)
{
// 初始化
Init(pHeader, pBuf, nLeftLen);
unsigned char *pd = _pTagData;
_nFrameType = (pd[0] & 0xf0) >> 4; // 帧类型
_nCodecID = pd[0] & 0x0f; // 视频编码类型
// 开始解析
if (_header.nType == 0x09 && _nCodecID == 7)
{
ParseH264Tag(pParser);
}
}
-
解析视频标签
1、解析数据包类型
2、如果数据包是配置信息,那么就解析配置信息
3、如果数据包是视频数据,那么就解析视频数据
int CFlvParser::CVideoTag::ParseH264Tag(CFlvParser *pParser)
{
unsigned char *pd = _pTagData;
/*
** 数据包的类型
** 视频数据被压缩之后被打包成数据包在网上传输
** 有两种类型的数据包:视频信息包(sps、pps等)和视频数据包(视频的压缩数据)
*/
int nAVCPacketType = pd[1];
int nCompositionTime = CFlvParser::ShowU24(pd + 2);
// 如果是视频配置信息
if (nAVCPacketType == 0)
{
ParseH264Configuration(pParser, pd);
}
// 如果是视频数据
else if (nAVCPacketType == 1)
{
ParseNalu(pParser, pd);
}
else
{
}
return 1;
}
-
解析视频配置信息
1、解析配置信息的长度2、解析sps、pps的长度
3、保存元数据,元数据即sps、pps等
int CFlvParser::CVideoTag::ParseH264Configuration(CFlvParser *pParser, unsigned char *pTagData)
{
unsigned char *pd = pTagData;
// 配置信息长度
pParser->_nNalUnitLength = (pd[9] & 0x03) + 1;
int sps_size, pps_size;
// sps(序列参数集)的长度
sps_size = CFlvParser::ShowU16(pd + 11);
// pps(图像参数集)的长度
pps_size = CFlvParser::ShowU16(pd + 11 + (2 + sps_size) + 1);
// 元数据的长度
_nMediaLen = 4 + sps_size + 4 + pps_size;
_pMedia = new unsigned char[_nMediaLen];
// 保存元数据
memcpy(_pMedia, &nH264StartCode, 4);
memcpy(_pMedia + 4, pd + 11 + 2, sps_size);
memcpy(_pMedia + 4 + sps_size, &nH264StartCode, 4);
memcpy(_pMedia + 4 + sps_size + 4, pd + 11 + 2 + sps_size + 2 + 1, pps_size);
return 1;
}
-
解析视频数据
1、如果一个Tag还没解析完成,那么执行下面步骤2、计算NALU的长度
3、获取NALU的起始码
4、保存NALU的数据
5、调用自定义的处理函数对NALU数据进行处理
int CFlvParser::CVideoTag::ParseNalu(CFlvParser *pParser, unsigned char *pTagData)
{
unsigned char *pd = pTagData;
int nOffset = 0;
_pMedia = new unsigned char[_header.nDataSize+10];
_nMediaLen = 0;
nOffset = 5;
while (1)
{
// 如果解析玩了一个Tag,那么就跳出循环
if (nOffset >= _header.nDataSize)
break;
// 计算NALU(视频数据被包装成NALU在网上传输)的长度
int nNaluLen;
switch (pParser->_nNalUnitLength)
{
case 4:
nNaluLen = CFlvParser::ShowU32(pd + nOffset);
break;
case 3:
nNaluLen = CFlvParser::ShowU24(pd + nOffset);
break;
case 2:
nNaluLen = CFlvParser::ShowU16(pd + nOffset);
break;
default:
nNaluLen = CFlvParser::ShowU8(pd + nOffset);
}
// 获取NALU的起始码
memcpy(_pMedia + _nMediaLen, &nH264StartCode, 4);
// 复制NALU的数据
memcpy(_pMedia + _nMediaLen + 4, pd + nOffset + pParser->_nNalUnitLength, nNaluLen);
// 解析NALU
pParser->_vjj->Process(_pMedia+_nMediaLen, 4+nNaluLen, _header.nTotalTS);
_nMediaLen += (4 + nNaluLen);
nOffset += (pParser->_nNalUnitLength + nNaluLen);
}
return 1;
}
- 自定义的视频处理
把视频的NALU解析出来之后,可以根据自己的需要往视频中添加内容
// 用户可以根据自己的需要,对该函数进行修改或者扩展
// 下面这个函数的功能大致就是往视频中写入SEI信息
int CVideojj::Process(unsigned char *pNalu, int nNaluLen, int nTimeStamp)
{
// 如果起始码后面的两个字节是0x05或者0x06,那么表示IDR图像或者SEI信息
if (pNalu[4] != 0x06 || pNalu[5] != 0x05)
return 0;
unsigned char *p = pNalu + 4 + 2;
while (*p++ == 0xff);
// 往NALU中写入SEI信息
const char *szVideojjUUID = "VideojjLeonUUID";
char *pp = (char *)p;
for (int i = 0; i < strlen(szVideojjUUID); i++)
{
if (pp[i] != szVideojjUUID[i])
return 0;
}
VjjSEI sei;
sei.nTimeStamp = nTimeStamp;
sei.nLen = nNaluLen - (pp - (char *)pNalu) - 16 - 1;
sei.szUD = new char[sei.nLen];
memcpy(sei.szUD, pp + 16, sei.nLen);
_vVjjSEI.push_back(sei);
return 1;
}
解析音频标签
-
入口函数CreateTag
1、解析标签头部
2、判断标签头部的类型
3、根据标签头部的类型,解析不同的标签
4、如果是视频类型的标签,那么就创建并解析视频标签
CFlvParser::Tag *CFlvParser::CreateTag(unsigned char *pBuf, int nLeftLen)
{
// 开始解析标签头部
TagHeader header;
header.nType = ShowU8(pBuf+0); // 类型
header.nDataSize = ShowU24(pBuf + 1); // 标签body的长度
header.nTimeStamp = ShowU24(pBuf + 4); // 时间戳
header.nTSEx = ShowU8(pBuf + 7); // 时间戳的扩展字段
header.nStreamID = ShowU24(pBuf + 8); // 流的id
header.nTotalTS = (unsigned int)((header.nTSEx << 24)) + header.nTimeStamp;
// 标签头部解析结束cout << "total TS : " << header.nTotalTS << endl;
//cout << "nLeftLen : " << nLeftLen << " , nDataSize : " << pTag->header.nDataSize << endl;
if ((header.nDataSize + 11) > nLeftLen)
{
return NULL;
}Tag *pTag;
switch (header.nType) {
case 0x09: // 视频类型的Tag
pTag = new CVideoTag(&header, pBuf, nLeftLen, this);
break;
case 0x08: // 音频类型的Tag
pTag = new CAudioTag(&header, pBuf, nLeftLen, this);
break;
default: // script类型的Tag
pTag = new Tag();
pTag->Init(&header, pBuf, nLeftLen);
}return pTag;
} -
创建音频标签
1、初始化
2、解析音频编码类型
3、解析采样率
4、解析精度和类型
5、解析音频标签
CFlvParser::CAudioTag::CAudioTag(TagHeader *pHeader, unsigned char *pBuf, int nLeftLen, CFlvParser *pParser)
{
// 初始化
Init(pHeader, pBuf, nLeftLen);
unsigned char *pd = _pTagData;
_nSoundFormat = (pd[0] & 0xf0) >> 4; // 音频编码类型
_nSoundRate = (pd[0] & 0x0c) >> 2; //采样率
_nSoundSize = (pd[0] & 0x02) >> 1; // 精度
_nSoundType = (pd[0] & 0x01); // 类型
// 解析音频标签
if (_nSoundFormat == 10) // AAC
{
ParseAACTag(pParser);
}
}
-
解析音频标签
1、获取数据包的类型2、判断数据包的类型
3、如果数据包是音频配置信息,那么解析有音频配置信息
4、如果是原始音频数据,那么对原始音频数据进行处理
int CFlvParser::CAudioTag::ParseAACTag(CFlvParser *pParser)
{
unsigned char *pd = _pTagData;
// 数据包的类型:音频配置信息,音频数据
int nAACPacketType = pd[1];
// 如果是音频配置信息
if (nAACPacketType == 0)
{
// 解析配置信息
ParseAudioSpecificConfig(pParser, pd);
}
// 如果是音频数据
else if (nAACPacketType == 1)
{
// 解析音频数据
ParseRawAAC(pParser, pd);
}
else
{
}
return 1;
}
-
处理始⾳频配置
1、解析AAC的采样率2、解析采样率索引
3、解析声道
int CFlvParser::CAudioTag::ParseAudioSpecificConfig(CFlvParser *pParser, unsigned char *pTagData)
{
unsigned char *pd = _pTagData;
// AAC的profile
_aacProfile = ((pd[2]&0xf8)>>3) - 1;
// 采样率索引
_sampleRateIndex = ((pd[2]&0x07)<<1) | (pd[3]>>7);
// 声道
_channelConfig = (pd[3]>>3) & 0x0f;
_pMedia = NULL;
_nMediaLen = 0;
return 1;
}
- 处理原始音频数据
主要的功能是为原始的音频数据添加元数据,可以根据自己的需要进行改写
int CFlvParser::CAudioTag::ParseRawAAC(CFlvParser *pParser, unsigned char *pTagData)
{
uint64_t bits = 0;
// 数据长度
int dataSize = _header.nDataSize - 2;
// 制作元数据
WriteU64(bits, 12, 0xFFF);
WriteU64(bits, 1, 0);
WriteU64(bits, 2, 0);
WriteU64(bits, 1, 1);
WriteU64(bits, 2, _aacProfile);
WriteU64(bits, 4, _sampleRateIndex);
WriteU64(bits, 1, 0);
WriteU64(bits, 3, _channelConfig);
WriteU64(bits, 1, 0);
WriteU64(bits, 1, 0);
WriteU64(bits, 1, 0);
WriteU64(bits, 1, 0);
WriteU64(bits, 13, 7 + dataSize);
WriteU64(bits, 11, 0x7FF);
WriteU64(bits, 2, 0);
_nMediaLen = 7 + dataSize;
_pMedia = new unsigned char[_nMediaLen];
// 把元数据放进临时数组中
unsigned char p64[8];
p64[0] = (unsigned char)(bits >> 56);
p64[1] = (unsigned char)(bits >> 48);
p64[2] = (unsigned char)(bits >> 40);
p64[3] = (unsigned char)(bits >> 32);
p64[4] = (unsigned char)(bits >> 24);
p64[5] = (unsigned char)(bits >> 16);
p64[6] = (unsigned char)(bits >> 8);
p64[7] = (unsigned char)(bits);
// 把临时数组的数据复制给元数据
memcpy(_pMedia, p64+1, 7);
// 把读取到的数据复制到后面
memcpy(_pMedia + 7, pTagData + 2, dataSize);
return 1;
}
解析其他标签
-
⼊⼝函数CreateTag
1、解析标签头部2、判断标签头部的类型
3、根据标签头部的类型,解析不同的标签
4、如果是视频类型的标签,那么就创建并解析视频标签
CFlvParser::Tag *CFlvParser::CreateTag(unsigned char *pBuf, int nLeftLen)
{
// 开始解析标签头部
TagHeader header;
header.nType = ShowU8(pBuf+0); // 类型
header.nDataSize = ShowU24(pBuf + 1); // 标签body的长度
header.nTimeStamp = ShowU24(pBuf + 4); // 时间戳
header.nTSEx = ShowU8(pBuf + 7); // 时间戳的扩展字段
header.nStreamID = ShowU24(pBuf + 8); // 流的id
header.nTotalTS = (unsigned int)((header.nTSEx << 24)) + header.nTimeStamp;
// 标签头部解析结束
cout << "total TS : " << header.nTotalTS << endl;
//cout << "nLeftLen : " << nLeftLen << " , nDataSize : " << pTag->header.nDataSize << endl;
if ((header.nDataSize + 11) > nLeftLen)
{
return NULL;
}
Tag *pTag;
switch (header.nType) {
case 0x09: // 视频类型的Tag
pTag = new CVideoTag(&header, pBuf, nLeftLen, this);
break;
case 0x08: // 音频类型的Tag
pTag = new CAudioTag(&header, pBuf, nLeftLen, this);
break;
default: // script类型的Tag
pTag = new Tag();
pTag->Init(&header, pBuf, nLeftLen);
}
return pTag;
}
- 解析普通标签
没有太大的功能,就是数据的复制
void CFlvParser::Tag::Init(TagHeader *pHeader, unsigned char *pBuf, int nLeftLen)
{
// 复制标签头部信息
memcpy(&_header, pHeader, sizeof(TagHeader));
_pTagHeader = new unsigned char[11];
memcpy(_pTagHeader, pBuf, 11);
// 复制标签body
_pTagData = new unsigned char[_header.nDataSize];
memcpy(_pTagData, pBuf + 11, _header.nDataSize);
}
6. 音频解码(裸流)
6.1 解码过程
6.2 ffmpeg处理流程
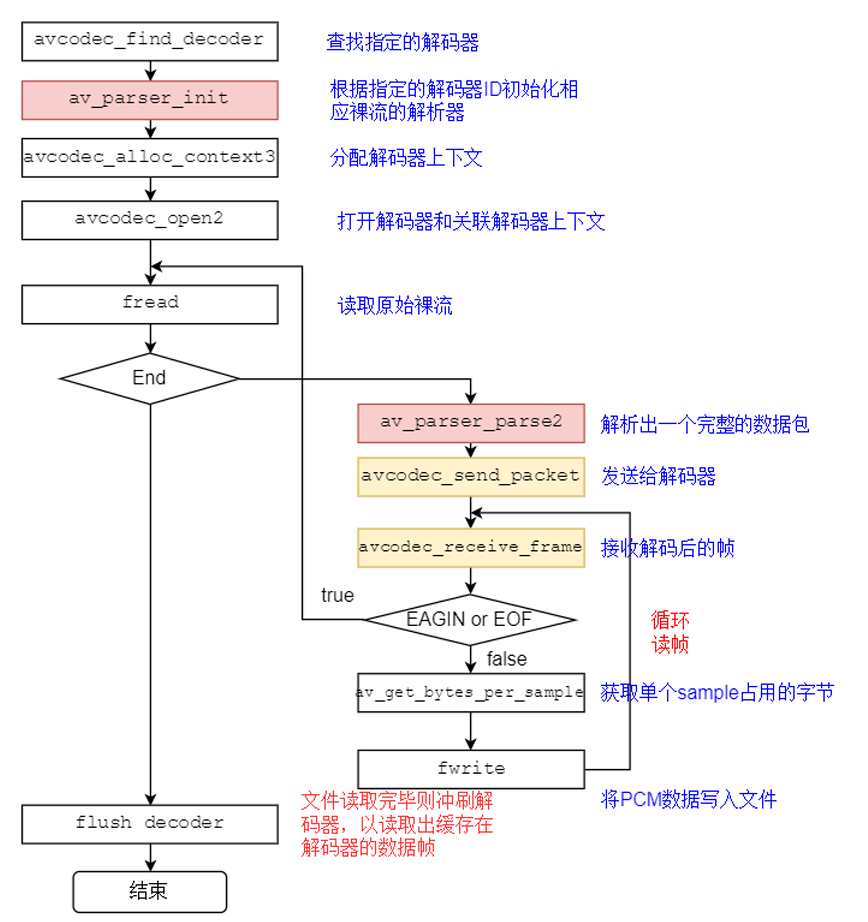
关键函数说明:
avcodec_find_decoder:根据指定的AVCodecID查找注册的解码器。av_parser_init:初始化AVCodecParserContext。avcodec_alloc_context3:为AVCodecContext分配内存。avcodec_open2:打开解码器。av_parser_parse2:解析获得⼀个Packet。avcodec_send_packet:将AVPacket压缩数据给解码器。avcodec_receive_frame:获取到解码后的AVFrame数据。av_get_bytes_per_sample: 获取每个sample中的字节数。
关键数据结构
- AVCodecParser:⽤于解析输⼊的数据流并把它分成⼀帧⼀帧的压缩编码数据。⽐较形象的说法就是把⻓⻓的⼀段连续的数据“切割”成⼀段段的数据。
AVCodecParser ff_aac_parser = {
codec_ids = { AV_CODEC_ID_AAC },
priv_data_size = sizeof(AACAC3ParseContext),
parser_init = aac_parse_init,
parser_parse = = ff_aac_ac3_parse,
parser_close = ff_parse_close,
};
从AVCodecParser结构的实例化我们可以看出来,不同编码类型的parser是和CODE_ID进⾏绑定的。所
以也就可以解释parser = av_parser_init(codec->id);
6.3 avcodec编解码API介绍
FFmpeg提供了两组函数,分别⽤于编码和解码:
- 解码:avcodec_send_packet()、avcodec_receive_frame()。
- 解码:avcodec_send_frame()、avcodec_receive_packet()。
建议的使⽤流程如下:
-
像以前⼀样设置并打开AVCodecContext。
-
输⼊有效的数据:
- 解码:调⽤avcodec_send_packet()给解码器传⼊包含原始的压缩数据的AVPacket对象。
- 编码:调⽤ avcodec_send_frame()给编码器传⼊包含解压数据的AVFrame对象。
- 两种情况下推荐AVPacket和AVFrame都使⽤refcounted(引⽤计数)的模式,否则libavcodec可能不得不对输⼊的数据进⾏拷⻉。
-
在⼀个循环体内去接收codec的输出,即周期性地调⽤avcodec_receive_*()来接收codec输出的数据:
- 解码:调⽤avcodec_receive_frame(),如果成功会返回⼀个包含未压缩数据的AVFrame。
- 编码:调⽤avcodec_receive_packet(),如果成功会返回⼀个包含压缩数据的AVPacket。
反复地调⽤avcodec_receive_packet()直到返回 AVERROR(EAGAIN)或其他错误。返回AVERROR(EAGAIN)错误表示codec需要新的输⼊来输出更多的数据。对于每个输⼊的packet或frame,codec⼀般会输出⼀个frame或packet,但是也有可能输出0个或者多于1个。
-
流处理结束的时候需要flush(冲刷) codec。因为codec可能在内部缓冲多个frame或packet,出于性能或其他必要的情况(如考虑B帧的情况)。 处理流程如下:
- 调⽤avcodec_send_*()传⼊的AVFrame或AVPacket指针设置为NULL。 这将进⼊draining mode(排⽔模式)。
- 反复地调⽤avcodec_receive_*()直到返回AVERROR_EOF,该⽅法在draining mode时不会返回AVERROR(EAGAIN)的错误,除⾮你没有进⼊draining mode。
- 当重新开启codec时,需要先调⽤ avcodec_flush_buffers()来重置codec。
说明:
5. 编码或者解码刚开始的时候,codec可能接收了多个输⼊的frame或packet后还没有输出数据,直到内部的buffer被填充满。上⾯的使⽤流程可以处理这种情况。
6. 理论上,只有在输出数据没有被完全接收的情况调⽤avcodec_send_()的时候才可能会发⽣AVERROR(EAGAIN)的错误。你可以依赖这个机制来实现区别于上⾯建议流程的处理⽅式,⽐如每次循环都调⽤avcodec_send_(),在出现AVERROR(EAGAIN)错误的时候再去调⽤avcodec_receive_()。
7. 并不是所有的codec都遵循⼀个严格、可预测的数据处理流程,唯⼀可以保证的是 “调⽤avcodec_send_()/avcodec_receive_()返回AVERROR(EAGAIN)的时候去avcodec_receive_()/avcodec_send_*()会成功,否则不应该返回AVERROR(EAGAIN)的错误。”⼀般来说,任何codec都不允许⽆限制地缓存输⼊或者输出。
8. 在同⼀个AVCodecContext上混合使⽤新旧API是不允许的,这将导致未定义的⾏为。
6.4 avcodec_send_packet
函数:int avcodec_send_packet(AVCodecContext *avctx, const AVPacket *avpkt);
作⽤:⽀持将裸流数据包送给解码器
警告:
- 输⼊的avpkt-data缓冲区必须⼤于AV_INPUT_PADDING_SIZE,因为优化的字节流读取器必须⼀次读取32或者64⽐特的数据
- 不能跟之前的API(例如avcodec_decode_video2)混⽤,否则会返回不可预知的错误
备注:在将包发送给解码器的时候,AVCodecContext必须已经通过avcodec_open2打开
参数:
avctx:解码上下⽂
avpkt:输⼊AVPakcet.通常情况下,输⼊数据是⼀个单⼀的视频帧或者⼏个完整的⾳频帧。调⽤者保留包的原有属性,解码器不会修改包的内容。解码器可能创建对包的引⽤。如果包没有引⽤计数将拷⻉⼀份。跟以往的API不⼀样,输⼊的包的数据将被完全地消耗,如果包含有多个帧,要求多次调⽤avcodec_recvive_frame,直到avcodec_recvive_frame返回VERROR(EAGAIN)或AVERROR_EOF。输⼊参数可以为NULL,或者AVPacket的data域设置为NULL或者size域设置为0,表示将刷新所有的包,意味着数据流已经结束了。第⼀次发送刷新会总会成功,第⼆次发送刷新包是没有必要的,并且返回AVERROR_EOF,如果×××缓存了⼀些帧,返回⼀个刷新包,将会返回所有的解码包
返回值:
- 0: 表示成功
- AVERROR(EAGAIN):当前状态不接受输⼊,⽤户必须先使⽤avcodec_receive_frame() 读取数据帧;
- AVERROR_EOF:解码器已刷新,不能再向其发送新包;
- AVERROR(EINVAL):没有打开解码器,或者这是⼀个编码器,或者要求刷新;
- AVERRO(ENOMEN):⽆法将数据包添加到内部队列。
6.5 avcodec_receive_frame
函数:int avcodec_receive_frame ( AVCodecContext * avctx, AVFrame * frame )
作⽤:从解码器返回已解码的输出数据。
参数:
- avctx: 编解码器上下⽂
- frame: 获取使⽤reference-counted机制的audio或者video帧(取决于解码器类型)。请注意,在执⾏其他操作之前,函数内部将始终先调⽤av_frame_unref(frame)。
返回值:
- 0: 成功,返回⼀个帧
- AVERROR(EAGAIN): 该状态下没有帧输出,需要使⽤avcodec_send_packet发送新的packet到解码器
- AVERROR_EOF: 解码器已经被完全刷新,不再有输出帧
- AVERROR(EINVAL): 编解码器没打开
- 其他<0的值: 具体查看对应的错误码
MP3解析
7. 视频解码

8. MP4分析
mp4⽂件由box组成,每个box分为Header和Data。其中Header部分包含了box的类型和⼤⼩,Data包含了⼦box或者数据,box可以嵌套⼦box。下图是⼀个典型mp4⽂件的基本结构:

链接
代码是前边的h264+aac




![[计算机基础]一、计算机组成原理](https://i-blog.csdnimg.cn/direct/145fc12067ee430b90c6dcba5bce79bd.png)






![[Armbian] 部署Docker版Home Assistent,安装HACS并连接米家设备](https://i-blog.csdnimg.cn/direct/7b9f2e9e010744b1ba5ce60c17636ed9.png#pic_center)




