一、MySQL索引为何使用B+树结构?
MySQL的索引机制中,默认使用B+Tree作为底层的数据结构,但为什么要选择B+树呢?有人会说树结构是以二分法查找数据,所以会在很大程度上提升检索性能,这点确实没错,但树结构有那么多,MySQL为什么不选二叉树、AVL树、红黑树或B树呢?
对于索引为什么不支持数组、链表、队列等结构就不做过多解释了,因为这些结构中的元素都是按序并排存储,如果选择这些结构来实现索引,那走索引依旧等价于走全表,并未带来查询时的效率提升,反而带来了额外的存储开销,这是没有意义的。
1.1、普通SQL的全表扫描过程
想要真正理解MySQL为何选B+树结构之前,你必须要先了解一条普通SQL的全表扫描过程,否则你很难真正切身感受出有索引和没索引的区别。当然,这里就不再以伪逻辑的形式讲解全表扫描了,而是真正的为大家讲解MySQL全表扫描的实际过程。以下面这张用户表为例:

表数据
首先假设表中不存在任何索引,此时来执行下述这条SQL:
SELECT * FROM `zz_user` WHERE `name` = "黑熊";因为表中不具备索引,所以这里会走全表扫描的形式检索数据,但不管是走全表亦或索引,本质上由于数据都存储在磁盘中,因此首先都会触发磁盘IO,所以先来说说磁盘寻道的过程:
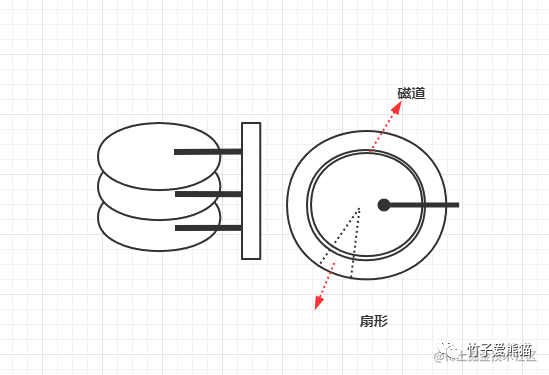
磁盘寻道
如果磁盘不是SSD类型,大致长上面这个样子,里面有一个个的盘面和磁针,当发生磁盘IO时,首先会根据给出的磁盘地址,在盘面上寻道。这个寻道过程是怎么回事呢?就跟小时候VCD、DVD放光碟类似,盘面会开始转圈圈,在盘面上有一个磁道的概念,当转到了对应的地址时,磁道和磁针会相互吸引,然后以一上一下的方式读取0、1二进制数据,最终从磁盘中将目标地址中的数据读取出来。
磁盘寻道的大致过程如上,具体的细节没写出来,重点是大家要感受这个过程即可。
当走全表扫描时,会发生磁盘IO,但是磁盘寻道是需要有一个地址的,这个地址最开始就是本地表数据文件中的起始地址,也就是从表中的第一行数据开始读,读到数据后会载入内存,然后MySQL-Server会根据SQL条件对读到的数据做判断,如果不符合条件则继续发生磁盘IO读取其他数据(如果表比较大,这里不会以顺序IO的形式走全表检索,而是会触发随机的磁盘IO)。
那来看一下,上面给出的用户表中,「黑熊」这条数据位于表的第五行,那这里会发生五次磁盘IO吗?答案是NO,为什么呢?因为OS、MySQL中都有一个优化措施,叫做局部性读取原理。
1.1.1、局部性原理
局部性原理的思想比较简单,比如目前有三块内存页x、y、z是相连的,CPU此刻在操作x页中的数据,那按照计算机的特性,一般同一个数据都会放入到物理相连的内存地址上存储,也就是当前在操作x页的数据,那么对于y,z这两页内存的数据也很有可能在接下来的时间内被操作,因此对于y,z这两页数据则会提前将其载入到高速缓冲区(L1/L2/L3),这个过程叫做利用局部性原理“预读”数据。
但是一次性到底预读多大的数据放入到高速缓冲区中呢?
这个是由缓存行大小决定的,比如因特尔的MESI协议中,缓存行的默认大小为64Bytes,也就是说在因特尔的CPU中,一次性会将“当前操作数据”附近的64Bytes数据(2页数据)提前载入进高速缓冲区。
上述内容讲的是操作系统高速缓冲区的知识,在
CPU中利用局部性原理,提前将数据从内存先放入L1/L2/L3三级缓冲区中,主要是为了减小CPU寄存器与内存之间的性能差异。
由于CPU寄存器和内存之间的性能差异太大,所以逐个读数据的形式会导致CPU工作期间的大量时间会处于等待数据状态,所以利用局部性原理将数据“预读”到高速区。而对于MySQL而言,亦是同理,存储数据的磁盘和内存之间的性能差异也是巨大的,因为MySQL也会利用局部性原理,提前“预读”数据。
这是什么意思呢?其实就是指
MySQL一次磁盘IO不仅仅只会读取一条表数据,而是会读取多条数据,那到底读多少条数据呢?在InnoDB引擎中,一次默认会读取16KB数据到内存。
1.1.2、全表扫描过程
回到前面分析全表扫描的阶段,由于MySQL中会使用局部性原理的思想,所以对于给出的用户表数据而言,可能只需发生一次磁盘IO就能将前五条数据全部读到内存,然后会在内存中对本次读取的数据逐条判断,看一下每条数据的姓名字段是否为「黑熊」:
-
• 如果发现不符合
SQL条件的行数据,则会将当前这条数据放弃,同时在本次SQL执行过程中会排除掉这条数据,不会对其进行二次读取。 -
• 如果发现当前的数据符合
SQL条件要求,则会将当前数据写入到结果集中,然后继续判断其他数据。
当本次磁盘IO读取到的所有数据全部筛选完成后,紧接着会看一下表中是否还有其他数据,如果还有则继续触发磁盘IO检索数据,如果没有则将内存中的结果集返回。
有人或许会疑惑,为什么这里已经读到了符合条件的数据,还需要继续发生磁盘
IO呢?因为表中的字段没有建立唯一索引或唯一约束,因此MySQL不确定是否还有其他同名的数据,所以需要将整个表全部扫描一遍,才能得到最终结论。
好的,到这里就将MySQL全表扫描的过程讲明白了,紧着来看看全表扫描有什么问题呢?
其实按目前的情况来看,似乎不会有太大的问题,因此表中数据不多,一次磁盘
IO几乎就能读完。但思考一下,如果当表的数据量变为百万级别、千万级别呢?假设表中一条数据大小为512Byte,一次磁盘IO也只能读32条,假设表中有320w条数据,一次全表就有可能会触发10W次磁盘IO,每次都需要在硬件上让那个盘面转啊转,其过程的开销可想而知.....
因此建立索引的原因就在于此处,为了避免查询时走全表扫描,因此全表扫描的开销会随着数据量增长而越来越大。
1.2、索引为何不选择二叉树?
数据结构与算法,这门学科从诞生到现在,自始至终都让人难以理解,但国外有一个比较厉害的程序员,为了帮助他人更好的理解数据结构,自己搭建了一个数据结构的动画演示平台,里面提供了非常多丰富的数据结构类型,我们在其中能以动画的形式观测数据结构的变化。
回归话题本身,全表扫描由于走的是线性查询,因此数据越多,开销越大,此时先来看看二叉搜索树。
Binary Search Tree二叉搜索树是遵守二分搜索法实现的一种数据结构,咱们先来看看这种数据结构为何不适合用来做索引结构呢?
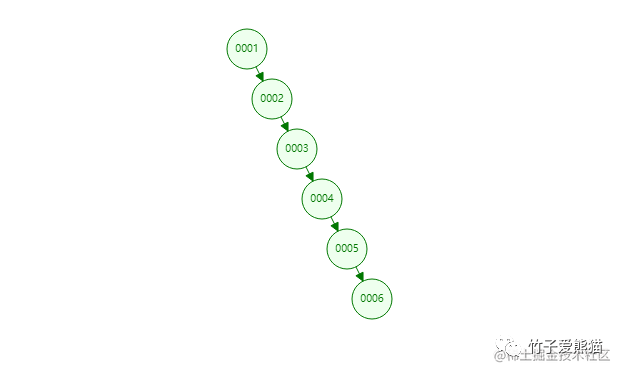
二叉搜索树
上图是我提前构建的二叉树,其中存在6个节点,按咱们前面给出的案例,「黑熊」这条数据位于表的第五行,那假设以二叉树作为索引结构,想要定位到第五行数据,需要经过几次磁盘IO呢?来看动图演示效果:

二叉树查找动画
从动画中可以明显看到,想要查到第五条数据,需要经过五次查询,由于树结构在磁盘中存储的位置也不连续,因此无法利用局部性原理读取后续的节点,所以最终需要发生五次磁盘IO才能读取到数据。
-
• 二叉树不适合作为索引结构的原因:
-
• ①如果索引的字段值是按顺序增长的,二叉树会转变为链表结构。
-
• ②由于结构转变成了链表结构,因此检索的过程和全表扫描无异。
-
• ③由于树结构在磁盘中,各节点的数据并不连续,因此无法利用局部性原理。
1.3、索引为何不选择红黑树?
上面简单的分析二叉树后,很明显的可以看出,二叉树并不适合作为索引结构,那接下来再看看大名鼎鼎的Red-Black Tree红黑树:
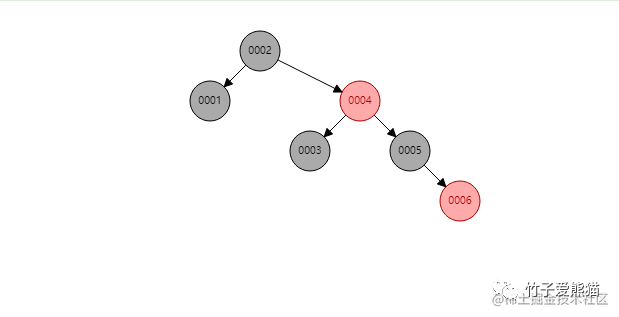
红黑树
同样提前先构建好了六个节点,相较于之前的二叉树,红黑树则进一步做了优化,它是一种自适应的平衡树,会根据插入的节点数量以及节点信息,自动调整树结构来维持平衡,从树的高度上来看,明显比之前的6层减少到了4层,那此时再来看看检索的过程:
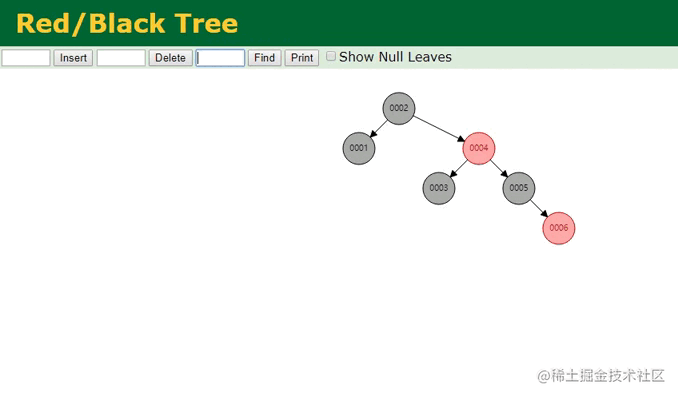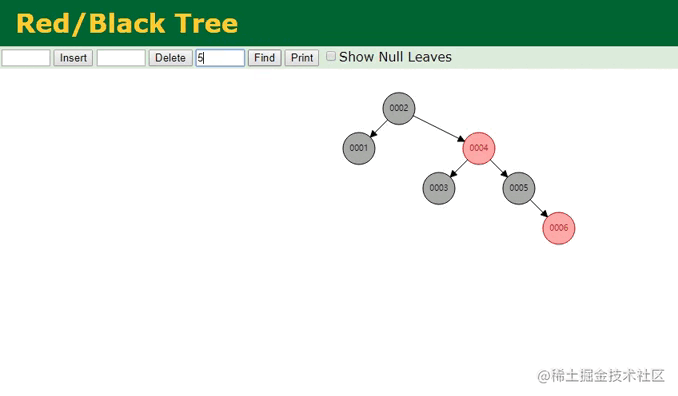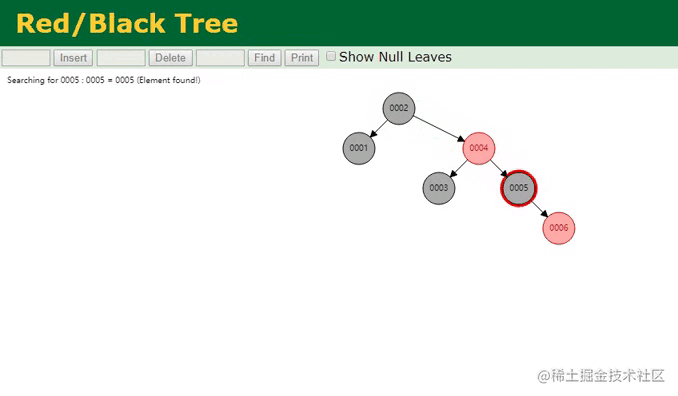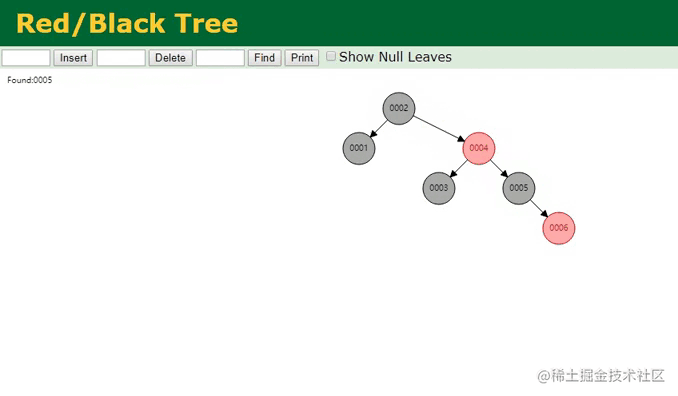
红黑树查找动画
由于树变矮了,其效果也很明显,在红黑树中只需要经过三次查找,就能定位到第五个节点,似乎看起来还不错对嘛?但MySQL为啥不用这颗名声远扬的红黑树呢?
-
• 红黑树不适合作为索引结构的原因:
-
• ①虽然对比二叉树来说,树高有所降低,但数据量一大时,依旧会有很大的高度。
-
• ②每个节点中只存储一个数据,节点之间还是不连续的,依旧无法利用局部性原理。
对于上述两个缺点罗列的很明白,其本质上的原因就在于:单个节点中只能存储一个数据,因此一方面树会随着数据量增长越来越高,第二方面也无法利用局部性原理减少磁盘IO。
那是不是把红黑树稍微改造一下,让其单个节点中可存储多个数据是不是可以了呢?
B树就是这样干的,一起来看看。
1.4、索引为何不选择B-Tree?
在前面提到过,将红黑树稍微改造一下,让其单节点可容纳多个数据,就能在很大程度上改善其性能,事实上B-Tree就是这么做的,B树可以理解成红黑树的一个变种,如下:
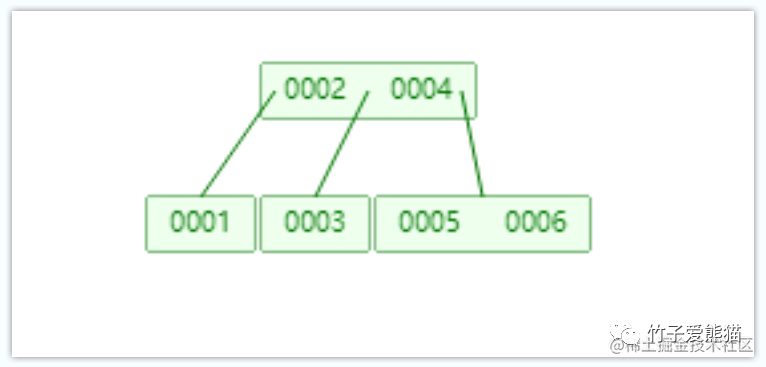
B树
此时给B树结构也添加了6个节点,此时观测上述结构,一方面树仅有2层,同时一个节点中也存储了多个数据,再来看看B树的查找过程:
B树查找动画
两次就查到了数据,同时一个节点中还能存储多个数据,可充分利用局部性原理,让一次磁盘IO读取多个数据!!但有人可能会问,上面的一个节点也只存两个数据啊,没太大的区别似乎。但你要这么想就错了,B树中一个节点可容纳的数据个数,可以自己控制的,例如:
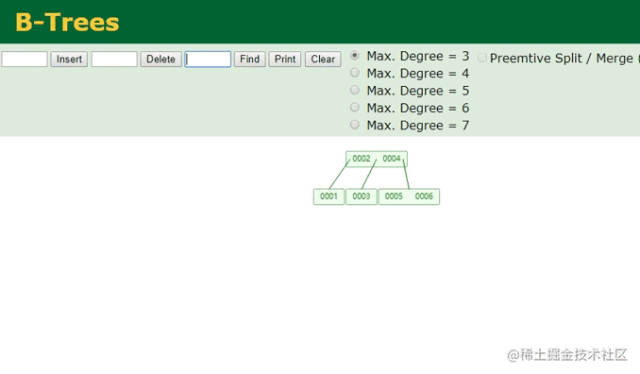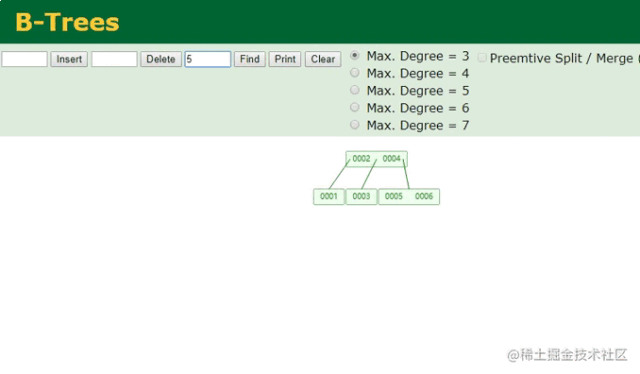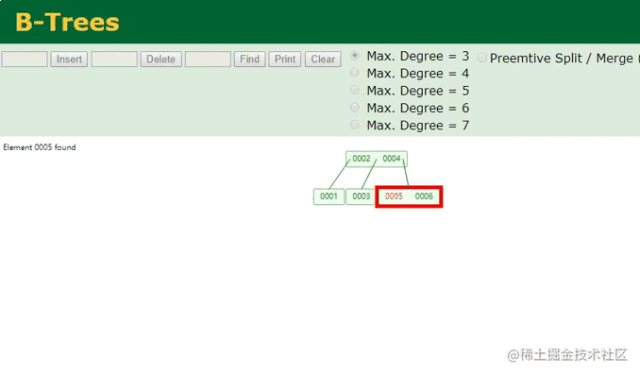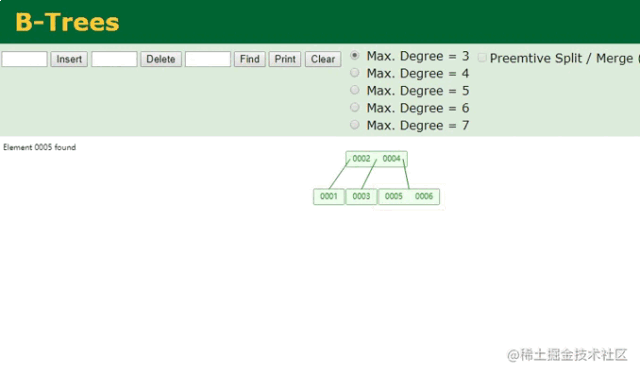
https://p6-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/c021eb32725847489e162b2772ea73b4tplv-k3u1fbpfcp-watermark.image。
在这里将Max.Degree更改后,B树单节点的容量也会随之更改,从上图中可清晰看到一个节点同时将6个数据全存储进去了,这也就代表着只需要一次磁盘IO就能检索出5这个数据,是不是很完美?先别急着下定律,毕竟咱们目前是站在索引设计者的角度来看待问题的,此时虽然看起来很美好了,但想一个问题:
MySQL由于是关系型数据库,因此经常会碰到范围查询的需求,举例:SELECT * FROM zz_user WHERE ID BETWEEN 2 AND 5;
比如上述这条SQL语句,需要查询表中ID在2~5的所有数据,那也就代表着需要查四条数据,在这里因为2~5在同一个节点中,因此仅触发一次IO就可拿到数据,但实际业务中往往不会有这么小的范围查询,假设此时是查ID=2~1000之间的数据呢?这么多数据定然不会在一个节点中,因此这里又会触发多次磁盘IO。
-
•
B树不适合作为索引结构的原因: -
• 虽然对比之前的红黑树更矮,检索数据更快,也能够充分利用局部性原理减少
IO次数,但对于大范围查询的需求,依旧需要通过多次磁盘IO来检索数据。
1.5、索引为何要选择B+Tree?
上面聊到的B-Tree相对来说已经较为完美了,但最后也谈到:它并不适合用于范围查询,但这种查询需求在关系型数据库中又很常见,那这里怎么优化呢?一起来看看B+Tree:
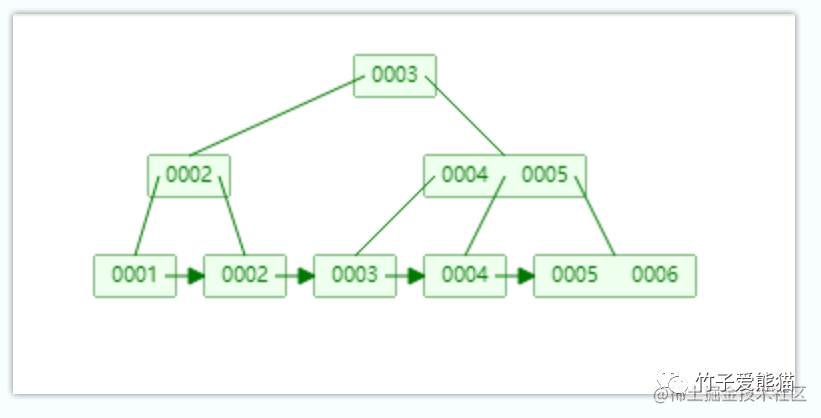
B+树
相较于B树而言,B+树的结构又出现了新的变化,一方面节点分为了叶节点和叶子节点两类,这里先有这两个概念即可,后续介绍这两类节点在索引中的作用。B+树中除开节点分为两类外,还有一个最大的变化就是:最下面的一排节点之间,都存在一个单向指针,指向下一个节点所在的位置,这也是B+树对B树的最大改造点:
前面讲过,由于
B树不适合于大范围查询操作,因此B+树中多了个指针,当需要做范围查询时,只需要定位第一个节点,然后就可以直接根据各节点之间的指针,获取到对应范围之内的所有节点,也就是只需要发生一次IO,就能够确定所查范围之内的所有数据位置。
到现在为止,B+树以接近完美的形式解决之前其他数据结构中的所有问题,因此B+Tree正式成为了MySQL默认的索引结构,因此对于MySQL索引为何要选择B+Tree的原因大家应该也懂了,MySQL的设计者在研发时,也绝对是对比了多种数据结构后,逐步推导其缺陷,然后采用更好的数据结构代替,从而最终推导出了B+Tree。
接下来再说一下前面抛出的一个问题:叶节点和叶子节点在
MySQL索引中的作用。
要弄明白这个问题,首先得搞清楚叶节点和叶子节点是什么?其实很简单:
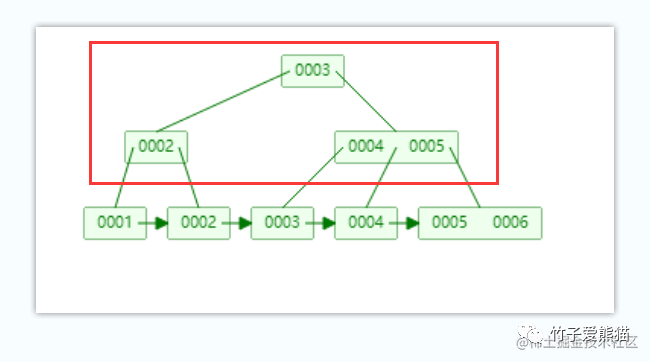
B+树-叶节点
B+Tree上面这些节点则被称为叶节点,在MySQL中不会存储数据,仅存储指向叶子节点的指针,这样做的好处在于能够让一个叶节点中存储更多的元素,从而确保树的高度不会由于数据增长而变得很高。
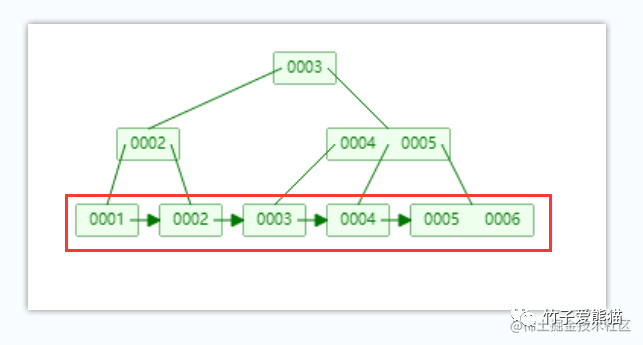
B+树-叶子节点
同时,B+Tree最下面这排节点则被称为叶子节点,这些节点中会存储实际的数据,例如聚簇索引中就直接存储对应的行数据,非聚簇索引中则存储指向主键/聚簇索引的字段值。同时每个叶子节点之间都有一根单向指针指向下一个节点,从而使得最下面的一排叶子节点之间又形成了一个单向链表结构,方便范围取值。
1.5.1、B+Tree结构为何会存在叶节点呢?
其实在之前的数据结构中,从来没有叶节点的这个概念出现,每个节点信息在整棵树结构中只会存储一份,但为什么B+树中会用叶节点,同时冗余一份节点信息呢?因为你从前面的B+Tree结构中,也能明显观测到2、3、4、5节点都会出现了两次。在这里如果想要搞明白为什么要冗余节点,你得想明白一个问题:
能不能将所有的索引数据、表数据全部放入到一个节点中存储呢?这样树的高度永远为
1呀,是不是只需要经过一次磁盘IO啊?
其实乍一听似乎有道理,实则是行不通的,因为一次磁盘IO读取的数据量是有限制的,如果将所有的数据全放入到一个节点中存储,那一次磁盘IO只能读取节点的一部分数据,将整个节点读完,本质上就和之前走一次全表没区别了。
理解这个点之后,再来看看抛出的问题:
B+Tree为何会有叶节点冗余数据呢?
因为B+Tree的每个节点大小会有限制,所以如果将数据存储在叶节点上,会导致单个树节点存的索引键很少。但如果树的叶节点不存实际的行数据,就代表单个节点可以存更多的索引键,单个节点存的越多也就代表着树的高度会越小,树的高度越小就等价于查询时会发生的磁盘IO次数越少,IO次数越少就相当于数据检索速度会更快,到这里相信大家应该能明白为什么会有叶节点冗余索引键了。
但索引中除开索引键外,也必须要存数据,如果不存数据索引就失去了意义,因此
B+tree最下面一排的叶子节点,其中就会存储对应的索引键与行数据/聚簇索引字段值。
一句话来概述,B+Tree的叶节点仅是作为一个“过渡者”的角色,主要是为了提升索引效率的,实际的数据会保存在最下面的叶子节点中,叶节点中仅有一个指针指向罢了。
1.5.2、千万级别的表B+Tree会有多高?
搞清楚B+Tree的一些疑惑后,此时来倒推一个问题,MySQL中一张千万级别的数据表,如果基于自增ID的主键字段建立B+树索引,那此时树会有多高呢?有人或许会认为,虽然B+Tree结构很优异,但千万级别的表至少有1000W条数据,再怎么样应该也有几十、几百的树高吧?但实际上答案会让你大吃一惊。
想要科学的弄懂这个问题,那必须建立在实际的依据上来计算,想要计算出树高,首先得有三个值:
①索引字段值的大小。
②MySQL中B+Tree单个节点的大小。
③MySQL中单个指针的大小。
如何计算索引字段值的大小呢?
这点要依据字段所使用的数据类型来决定。假设此时表的自增ID,创建表时使用的int类型,int类型在计算机中占4Bytes,那此时基于ID字段建立主键索引时,B+Tree每个节点的索引键大小就为4Bytes。
如何得知MySQL中B+树单个节点的大小呢?
对于索引单个节点的容量是多少呢?在MySQL中默认使用引擎的一页大小作为单节点的容量,假设此时表的存储引擎为InnoDB,就可以通过下述这条命令查询:
SHOW GLOBAL STATUS LIKE "Innodb_page_size";
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| Innodb_page_size | 16384 |
+------------------+-------+从上述查询结果来看,InnoDB引擎的一页大小为16384Bytes,也就是16KB,此时也就代表着B+Tree的每个节点容量为16KB。
MySQL中的指针是多大呢?
一般来说,操作系统的指针为了方便寻址,一般都与当前的操作系统位数对应,例如32位的系统,指针就是32bit/4Bytes,64位的操作系统指针则为64bit/8Bytes,但由于64bit的指针寻址范围太大,目前的计算机根本用不上这么大的寻址范围,因此在MySQL-InnoDB引擎的源码中,单个指针被缩小到6Bytes大小。
千万级别的索引树高计算
从上述三条可得知:单个索引节点容量为16KB,主键字段值为4B,指针大小为6B,一个完整的索引信息是由主键字段值+指针组成的,也就是4+6=10B,那此时先来计算一下单个节点中可存储多少个索引信息呢?
16KB / 10B ≈ 1638个。
那此时来计算一下,对于一颗高度为2的B+树,根节点可存储1638个叶子节点指针,也就代表着B+Tree的第二层有1638个叶子节点,因为叶子节点要存储实际的行数据,假设表中每行数据为1KB,这也就是代表着一个叶子节点中可存储16条行数据,那么一颗高度为2的B+树可存储的索引信息为:1638 * 16 = 26208条数据。
再来算算树高为
3的B+树可以存多少呢?因为最下面一排才是叶子节点,此时树高为3,也就代表着中间一排是叶节点,只存储指针并不存储数据,而每个节点可容纳1638个索引键+指针信息,因此计算过程是:1638 * 1638 * 16 = 42928704条。
是不是很令你惊讶?树高为3的B+Tree,竟然可以存储四千多万条数据,也就代表着千万级别的表,走索引查询的情况下,大致只需要发生三次磁盘IO即可获取数据。
当然,上述的这个数据是基于主键为
int类型、表的一行数据为1KB来计算的,实际情况中会不一样,因为主键有可能是bigint类型或其他类型,而一行数据也可能不仅仅只有1KB。因此对于一张实际的千万级别表,它的主键索引实际树高有多少,你结合主键的数据类型以及一行数据的大小,也可以计算出来,它同时不会太高。
对实际的千万表索引树高感兴趣的,我提供一个计算公式:索引键大小=索引字段类型所占的空间、一行表数据大小=所有表字段的类型+隐藏字段(20Bytes)所占大小总和,得到这两个值之后,再套入前面的例子中既可得知。
看到这里,对于索引凭啥那么快?为啥能够提升查询性能?相信大家也有了答案,毕竟索引树高才是个位数,发生的磁盘IO次数也那么少,检索数据的速度不快才来了个鬼。
不过B+Tree中的每个索引页中,还会存储页头(页号、指针、伪记录等)、页目录、页尾等信息,大概一共占用128Bytes左右,因此想要真正的计算出来接近实际情况的索引树高,还需要把这点考虑在内~
1.5.3、MySQL索引底层的真正结构
以为B+Tree就是索引的终点了嘛?实则不然,MySQL的追求可不止于此,虽然B+Tree已经特别特别优秀了,但B+Tree的叶子节点之间是单向指针组成的链表结构,这对于倒排序查询时,显然并不友好,因为只有单向指针,那么只能先正序获取数据后再倒排一次,因此MySQL真正的索引结构还对B+Tree做了变种设计!
啥意思呢?也就是
MySQL在设计索引结构时,对于原始的B+Tree又一次做了改造,叶子节点之间除开一根单向的指针之外,又多新增了一根指针,指向前面一个叶子节点,也就是MySQL索引底层的结构,实际是B+Tree的变种,叶子节点之间是互存指针的,所有叶子节点是一个双向链表结构。
这样做的好处在于:即可以快速按正序进行范围查询,而可以快速按倒序进行范围操作,在某些业务场景下又能进一步提升整体性能!
1.5.4、前缀索引为何能提升索引性能?
因为前缀索引可以选用一个字段的前N个字符来创建索引,相较于使用完整字段值做为索引键,前缀索引的索引键,显然占用的空间更少,一个索引键越小,代表一个B+Tree节点中可以存储更多的索引键,等价于树高会越小,也就代表磁盘IO更少,检索数据时自然效率更高。
二、建立索引时那些不为人知的内幕
弄明白了索引的底层数据结构后,再一起来聊一聊创建索引后会发生什么事情呢?一般我们都会以下述方式创建索引:
-- ①通过CREATE语句创建
CREATE INDEX indexName ON tableName (columnName(length) [ASC|DESC]);
-- ②通过ALTER语句创建
ALTER TABLE tableName ADD INDEX indexName(columnName(length) [ASC|DESC]);
-- ③建表时通过DML语句创建
CREATE TABLE tableName(
columnName1 INT(8) NOT NULL,
columnName2 ....,
.....,
INDEX [indexName] (columnName(length))
);在咱们通过SQL命令创建索引时,MySQL首先会判断一下当前表的存储引擎,索引机制本身是由存储引擎层提供实现的,不同的引擎实现的索引也不同,因此创建索引时第一步就会先判断存储引擎,然后根据不同的存储引擎创建索引,这里重点聊一下常用的MyISAM、InnoDB。
2.1、常用存储引擎的数据存储
首先为了能够实际观察到两个引擎之间的区别,分别使用MyISAM、InnoDB两个引擎创建两张表:
-- 创建一张使用MyISAM引擎的表:zz_myisam_index
CREATE TABLE `zz_myisam_index` (
`z_m_id` int(8) NOT NULL,
`z_m_name` varchar(255) NULL DEFAULT ''
)
ENGINE = MyISAM
CHARACTER SET = utf8
COLLATE = utf8_general_ci
ROW_FORMAT = Compact;
-- 创建一张使用InnoDB引擎的表:zz_innodb_index
CREATE TABLE `zz_innodb_index` (
`z_i_id` int(8) NOT NULL,
`z_i_name` varchar(255) NULL DEFAULT ''
)
ENGINE = InnoDB
CHARACTER SET = utf8
COLLATE = utf8_general_ci
ROW_FORMAT = Compact;上述过程中创建了两张表:zz_myisam_index、zz_innodb_index,分别使用了不同的引擎,而MySQL中对于所有的数据都会放入到磁盘中存储,因此先来找一下这两张表的本地位置,默认位于C:\ProgramData\MySQL\MySQL Server 5.x\data这个目录中,在这里保存着所有已创建的数据库磁盘文件,首先从这里面找到对应的数据库并进入目录,如下:
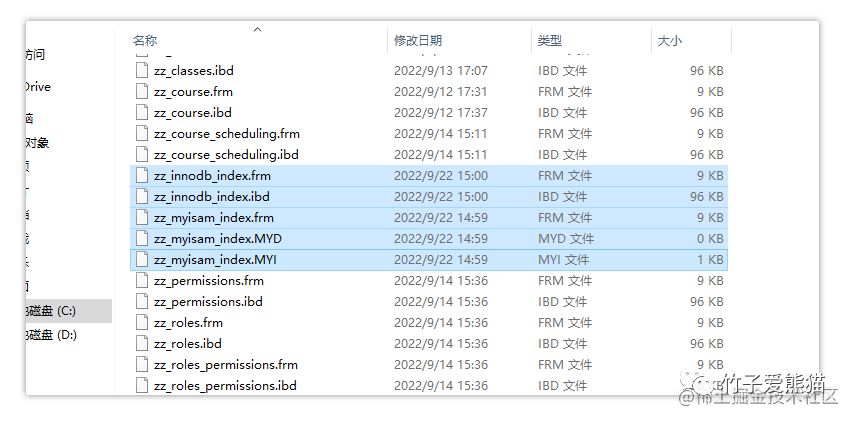
磁盘文件
此时分别来看看使用不同引擎的两张表有何不同。
2.1.1、使用MyISAM引擎的表
zz_myisam_index这张表是使用MyISAM引擎的表,在磁盘中有三个文件:
-
•
zz_myisam_index.frm:该文件中存储表的结构信息。 -
•
zz_myisam_index.MYD:该文件中存储表的行数据。 -
•
zz_myisam_index.MYI:该文件中存储表的索引数据。
也就是说,MyISAM引擎的表数据和索引数据,是分别放在两个不同的磁盘文件中存储的,这也意味着MyISAM引擎并不支持聚簇索引,因为聚簇索引要求表数据和索引数据一起存储在同一块空间,而MyISAM的.MYI索引文件中,存储的是表数据所在的地址指针。
2.1.2、使用InnoDB引擎的表
zz_innodb_index这张表是使用InnoDB引擎的表,在磁盘中仅有两个文件:
-
•
zz_innodb_index.frm:该文件中存储表的结构信息。 -
•
zz_innodb_index.ibd:该文件中存储表的行数据和索引数据。
因为InnoDB引擎中,表数据和索引数据都一起放在.ibd文件中,也就代表着索引数据和表数据是处于同一块空间存储的,这符合聚簇索引的定义,因此InnoDB支持聚簇索引。
同时也正由于这个原因,所以如果使用
InnoDB引擎的表未主动创建聚簇索引,它会自动选择表中的主键字段,作为聚簇索引的字段。但如果表中未声明主键字段,那则会选择一个非空唯一索引来作为聚簇索引。但如果表中依旧没有非空的唯一索引,InnoDB则会隐式定义一个主键来作为聚簇索引(这个列在上层是不可见的,是一个按序自增的值)。
搞明白两种常用引擎的底层存储区别后,接下来再聊聊手动创建索引后究竟会发生什么?
2.2、手动创建索引后发生的事情
当手动创建索引后,MySQL会先看一下当前表的存储引擎是谁,接着会判断一下表中是否存在数据,如果表中没有数据,则直接构建一些索引的信息,例如索引字段是谁、索引键占多少个字节、创建的是啥类型索引、索引的名字、索引归属哪张表、索引的数据结构.....,然后直接写入对应的磁盘文件中,比如MyISAM的表则写入到.MYI文件中,InnoDB引擎的表则写入到.ibd文件中。
上述这个过程,是表数据为空时,创建索引会干的工作,还算比较简单,但当表中有数据时,过程也一样吗?
NO,会多出很多步骤。
当表中有数据时,首先MySQL-Server会先看一下目前要创建什么类型的索引,然后基于索引的类型对索引字段的值,进行相应的处理,比如:
-
• 唯一索引:判断索引字段的每个值是否存在重复值,如果有则抛出错误码和信息。
-
• 主键索引:判断主键字段的每个值是否重复、是否有空值,有则抛出错误信息。
-
• 全文索引:判断索引字段的数据类型是否为文本,对索引字段的值进行分词处理。
-
• 前缀索引:对于索引字段的值进行截取工作,选用指定范围的值作为索引键。
-
• 联合索引:对于组成联合索引的多个列进行值拼接,组成多列索引键。
-
•
........
根据索引类型做了相应处理后,紧接着会再看一下当前索引的数据结构是什么?是B+Tree、Hash亦或是其他结构,然后根据数据结构对索引字段的值进行再次处理,如:
-
•
B+Tree:对索引字段的值进行排序,按照顺序组成B+树结构。 -
•
Hash:对索引字段的值进行哈希计算,处理相应的哈希冲突,方便后续查找。 -
•
.......
到这一步为止,已经根据索引结构,对索引字段的值处理好了,此时就会准备将内存中处理好的字段数据,写入到本地相应的磁盘文件中,但如果此时为InnoDB引擎,那在写入前还会做最后一个判断,也就是判断当前的索引是否为主键/聚簇索引:
-
• 如果当前创建索引的字段是主键字段,则在写入时重构
.ibd文件中的数据,将索引键和行数据调整到一块区域中存储。
当然,如果这里创建的不是主键/聚簇索引,或者目前是MyISAM引擎,则意味着现在需要创建的是非聚簇索引,因此会先会为每个索引键(索引字段值)寻找相应的行数据,找到之后与索引键关联起来,不过InnoDB、MyISAM引擎两者之间的非聚簇索引也会存在些许差异,所以在这里也会有一点点不同:
-
•
InnoDB:因为有聚簇索引存在,所以非聚簇索引在与行数据建立关联时,存放的是主键/聚簇索引的字段值。 -
•
MyISAM:由于表数据在单独的.MYD文件中,因此可以直接以指针的形式关联起来。
也就是说,InnoDB引擎中的非聚簇索引,都是主键/聚簇索引的“附庸”,因此每个索引信息中是以「索引键:聚簇字段值」这种形式关联的。
但MyISAM引擎中由于表数据和索引数据都是分开存储的,所以MyISAM的每个非聚簇索引都是独立的,因此每个索引信息则是以「索引键:行数据的地址指针」这种形式关联。
由于
MyISAM引擎的非聚簇索引,关联的是行数据的指针,而InnoDB引擎关联的是聚簇索引的索引键,所以InnoDB的非聚簇索引在查询时需要回表,再查一次聚簇索引才能得到数据。而MyISAM每个非聚簇索引都能直接获取到行数据的地址,可以直接根据指针获取数据,从整体而言,MyISAM检索数据的效率会比InnoDB快上不少。
到这里,索引键和行数据关联好之后,就会开始根据引擎的不同,将内存中的索引信息分别写入到不同的磁盘文件中。写完完成后,B+Tree的根节点会放到内存中维护,以便于后续索引查询时再次从磁盘读取根节点信息。
到这里为止,大家也应该明白了为什么创建表之后,立马建索引会很快,但当表中有不少数据时创建索引会很慢的原因,就是因为表中有数据时,创建索引要做一系列判断、处理工作。
最后再放上一个聚簇索引和非聚簇索引的结构区别:
https://p1-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/18f461b68ada474ab66ca63666311d79tplv-k3u1fbpfcp-watermark.image
在上图中给出了一张用户表,然后基于ID字段建立主键/聚簇索引,基于name字段建立普通/非聚簇索引,最终索引结构如图中所示。
-
• 在
InnoDB聚簇索引的示意图中,由于不方便画出每行数据,就用row_data代替行数据。 -
• 在
InnoDB非聚簇索引中,每个索引信息中存储聚簇索引的ID值。 -
•
MyISAM非聚簇索引中,每个索引信息中则直接存储行数据的指针。
当然,这里也是画出的伪结构,因为不可能按照
MySQL单节点16KB的尺寸1:1还原,毕竟画不下这么大(实际MySQL对于上述这些数据,一个节点就全放下了)。
索引键的大小会随着值长度变化吗?
这个问题很有趣,比如现在基于一个int类型的字段建立了一个索引,但目前的字段值是1,按理来说这个值只占1bits对不对?那在索引键中,或数据库中占多少呢?答案是4Bytes/32bits,这是因为一个int类型在操作系统中就会占用32bit空间,不会根据实际值而减少占用空间。
但大家也都知道,数据库中还有不少文本类型,例如
varchar类型,它是固定的长度吗?并不是,它是一个变长类型,而非一个定长类型,也就是一个varchar字段值,占用的空间会随着实际所存储的数据而变化。
所以对于一个索引键的大小是否会发生变化,这要取决于你是基于什么字段类型建立的索引,如果是定长类型就不会变化,但如果是变长类型就会随之发生改变。
三、索引内部查询与维护的过程
建立索引时会发生的内部过程,上一段落已经阐述明白了,接着再来说说查询SQL执行时,如果选中了索引,索引内部的检索过程是什么样的呢?也包括当写类型的SQL更改表中数据后,MySQL又会如何维护索引的内部结构呢?
3.1、聚簇索引查找数据的过程
当查询SQL来到MySQL后,经过一系列处理后,最终会来到优化器,此时会由优化器来为SQL语句选择出一个合适的索引,当然,你也可以手动强制指定索引。那当SQL命中索引时,索引内部是如何查找对应的行数据的?
工作线程执行查询SQL时,首先会先看一下当前索引的结构,如果是Hash索引就很简单了,直接对索引字段的值进行哈希计算,然后直接根据哈希值,从索引中找到相应的索引信息,最后获取数据即可。
但如果索引结构是默认的
B+Tree呢?内部又会发生什么工作?
如果当前SQL使用的是主键/聚簇索引,比如:
SELECT * FROM `zz_user` WHERE `ID` = 12;此时首先会根据条件字段,去内存中找到聚簇索引的根节点,然后根据节点中记录的地址去找次级的叶节点,最后再根据叶节点中的指针地址,找到最下面的叶子节点,从而获取其中的行数据,动画过程如下:
https://p6-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/4bf555145bbb4077af7bc27fb557f170~tplv-k3u1fbpfcp-watermark.image
B+树查找动画
B+Tree结构的索引似乎查找过程也并不复杂对不对?但有一个细节点需要注意,B+Tree的单个节点可存储多个数据,也就是当磁盘IO发生后,MySQL一次读取的数据中有多个索引信息,此时MySQL会如果查找单个节点中的索引信息呢?全部判断一次嘛?
其实并不会全部判断一次,因为B+Tree是一种有序的数据结构,小的会放左边,大的会放右边,单个节点中的索引信息,同样遵循这个原理。既然单个节点中的数据也是有序的,所以MySQL同样会采用二分查找法去检索数据。对于单个节点中的索引信息,先从索引中间开始查询,然后判断一下当前SQL中ID=12这个条件,是大于还是小于最中间的索引键,小于则去节点左边取中间的索引键继续判断,大于则去右边.....,以此类推直至定位到单节点中对应索引键为止。
如果是范围取值,比如取
ID>=2的所有数据,则会先定位到ID=2的索引键,然后通过叶子节点之后的指针,直接将2之后的数据全部取出。
聚簇索引中,定位到了索引键,即代表着取到了数据,毕竟索引和行数据是一起存储的。
3.2、非聚簇索引查找数据的过程
相较于聚簇索引而言,非聚簇索引前面的步骤都是相同的,仅是最后一步有些许不同罢了,非聚簇索引经过一系列查询步骤后,最终会取到一个聚簇索引的字段值,然后再做一次回表查询,也就是再去聚簇索引中查一次才能取到数据。
如果是
MyISAM引擎,则直接根据索引树中记录的指针地址,直接触发磁盘IO再次读取数据即可。
3.3、写SQL执行时索引的维护过程
前面分析了查询SQL执行时,索引查找数据的过程,那当出现增、删、改SQL时呢?索引会怎么维护呢?其实这里也要分索引类型,如果是Hash结构的索引,直接增删改对应的索引键即可,但B+Tree结构的索引,因为要内部节点是有序的,所以需要维护有序性。
也就是代表着,插入、更改、删除数据时,都会对
B+Tree索引造成影响。
但先说清一个误区,表中不同的索引在本地有不同的索引记录,比如ID、Name字段分别建立了两个索引,那么就会有两颗不同的索引树写入到本地磁盘文件中。
3.3.1、插入数据时索引的变化
B+Tree索引是有序的,对于这点在前面已经反复提到了,但如果索引字段是数值类型,例如int、bigint、long等,本身就能区分大小顺序,此时可以直接做排序工作。但如果是基于字符串或其他类型的字段建立索引呢?又该如何排序呀?其实对于这个问题也并不难回答,大家还记得在建库建表时,干的一件事情嘛?
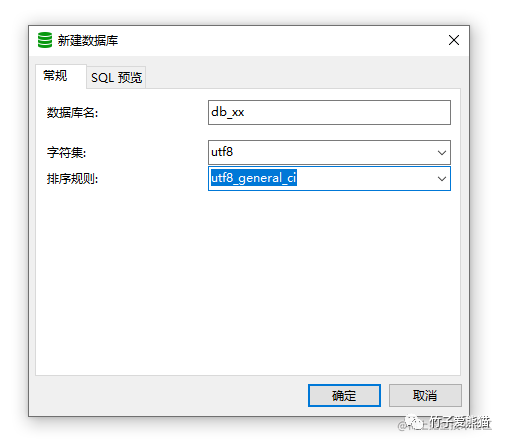
排序规则
在创建库表时,咱们通常都会指定一个排序规则,而这个规则就是MySQL对非数值类型字段的排序规则,比如字符串类型的字段,MySQL就会基于该规则对值先做计算处理,然后得到一个数值用于排序。
当然,具体排序处理的过程暂且不去纠结,重点只需搞清楚一点:数据库中任何字段都能排序即可。
那此时像数据库中插入一条数据时,还是以之前的用户表为例,比如:
INSERT INTO `zz_user` VALUES(6,"上海市黄浦区xx街道666号","棕熊","男",30);同样假设用户表上有两个索引,一是基于自增ID建立的主键索引,第二个则是基于姓名字段建立的普通索引。当表中插入这条数据后,索引又会发生什么变化呢?
主键/聚簇索引的变化
因为主键索引字段,也就是ID字段是顺序递增的,因此只需要在本地索引文件的B+Tree结构中,按照树结构找到最后的位置,将当前插入的ID:6作为索引键,以当前插入的行数据作为索引值,然后插入到最后的节点中即可。如下:
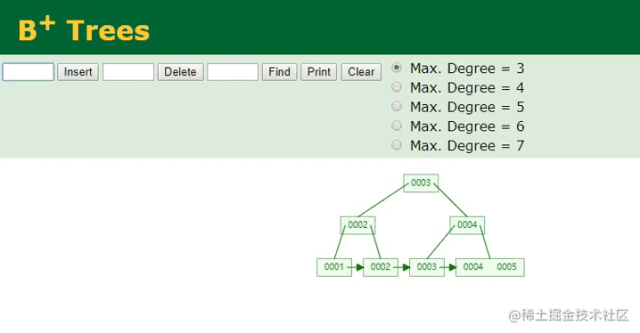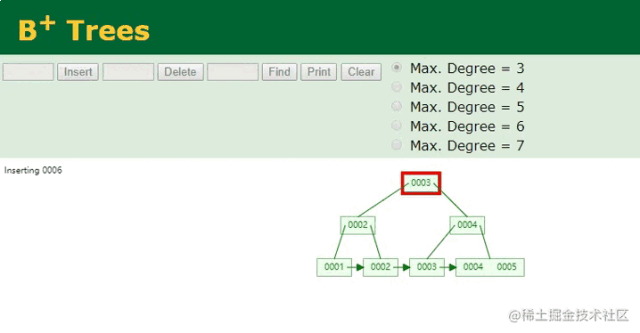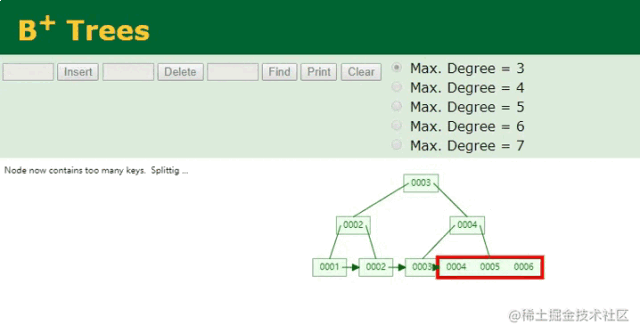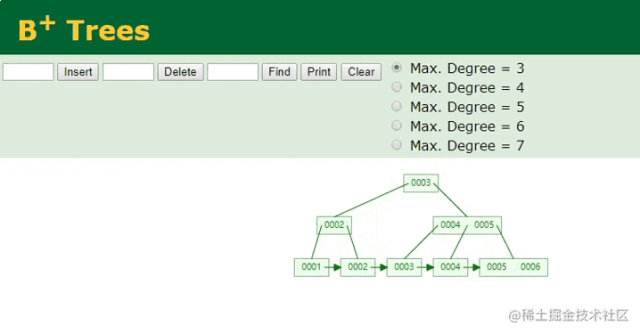
B+树插入ID动画
按序递增的索引维护,就是这么简单~
普通/非聚簇索引的变化
因为姓名字段本身的数据类型是字符串,与数值型字段天生的有序不同,字符串类型是无序的,因此首先需要根据已经配置好的排序规则,先对插入的name:棕熊这个值进行计算,然后根据计算出的值,决定当前数据在B+Tree中的索引位置,计算好之后再执行插入工作,过程如下:
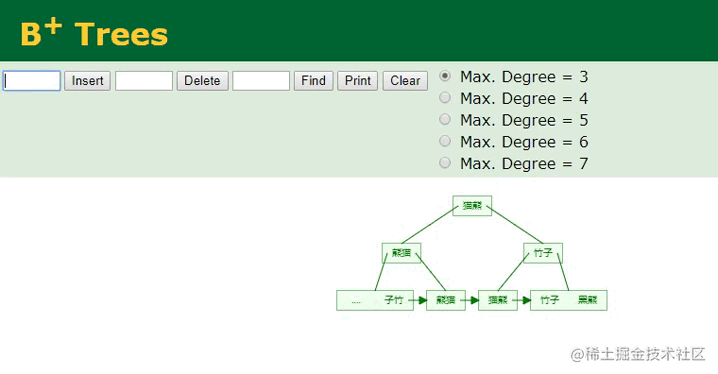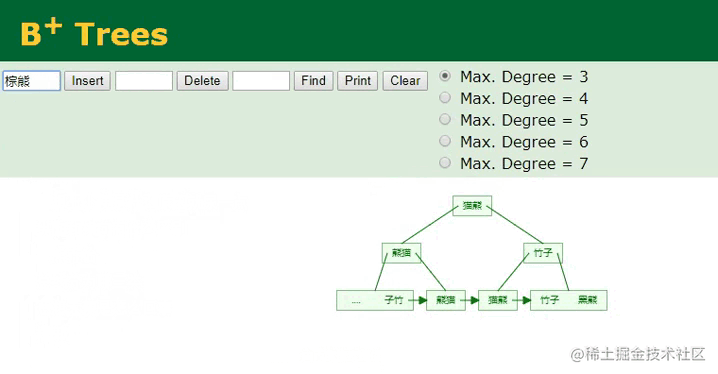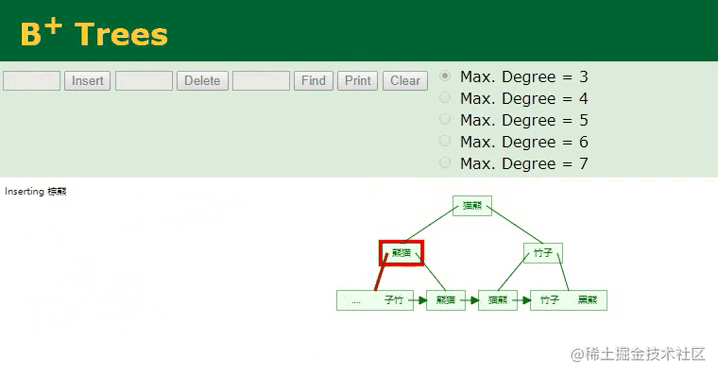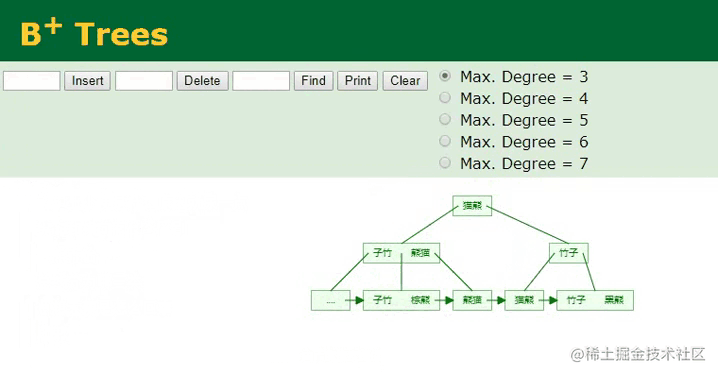
B+树插入字符串
相较于主键字段的顺序ID,插入字符串类型的name值会复杂一些,因为从这里可以明显看到,插入的“棕熊”数据经过计算后,它并不排最后面,而是排中间,所以要将这个值插入到对应的位置,此时树的节点就会发生裂变,后续的所有叶子节点都需要往后移动,这个开销是较大的。
同时,在插入索引信息时,会以“棕熊”作为索引键,以
ID:6作为索引值,然后一同插入,也就是要与行数据建立关联(MyISAM引擎则是行数据的地址指针)。
3.3.2、删除数据时索引的变化
DELETE FROM `zz_user` WHERE ID = 5;例如上述这条删除语句,当执行后则会先根据ID在索引树中查找索引信息,然后先删除非聚簇索引上的索引信息,紧接着再去聚簇索引上删除主键索引信息和行数据。
过程大致是相同的,就不再制作动图演示其过程了,重点要记住的是:先删非聚簇索引信息,再删聚簇索引的信息,因为聚簇索引上存放着行数据,如果先把聚簇索引删了,就无法找到非聚簇索引上的信息了。
3.3.3、更改数据时索引的变化
UPDATE `zz_user` SET name = "狗熊" WHERE ID = 6;对于上述这条修改语句,索引维护的过程相信大家自己也能推测出来,毕竟修改的本质就是先删再插入,首先在聚簇索引上查到ID=6这条数据,获取原本的name字段值:“棕熊”,然后以该值去非聚簇索引上找到对应的索引信息,然后先将聚簇索引中的数据行改掉,接着删除次级(非聚簇)索引的信息,最后再插入一个“狗熊”的次级索引信息。
会先更新数据行,再修改次级索引的值,但次级索引的修改是先删后改,而聚簇索引不会删数据,因为聚簇索引上保存着行数据,是直接对行数据进行修改(先读到内存中,改完覆盖原本的数据)。
修改聚簇索引数据行的过程:首先会在聚簇索引上根据ID=6找到对应的行数据,然后将行数据中的name字段更新为“狗熊”。
至此,对于写
SQL执行后,索引的维护过程就做了简单分析,实际上也并不难。
PS:实际索引更新数据时,具体的过程也会复杂一些,会牵扯到锁机制,也包括会判断修改的新值与原值的大小,如果大小相同则直接在原空间做修改(直接插入覆盖),如果不同才会先删再改。
3.4、主键为何推荐使用自增整数ID?
推荐大家使用自增的整数ID作为主键,而并不是使用随机的UUID这类字符串等类型,这是为何呢?因为观察前面name索引字段的插入过程,能够很明显的观察到一个现象,字符串是无序的,当使用字符串作为主键字段时,在插入数据的时候会频繁破坏原有的树结构,造成树分裂以及后续节点的挪动,一两个条数据插入倒还没关系,但是每一条插入的数据都有可能导致树的结构调整一次,这个过程的开销可想而知.....
但是自增的整数
ID就不会有这个问题,因为插入的ID本身就是按序递增的,因此插入的每一条新数据,都会直接放到B+Tree最后的节点中存储。
同时,除开上述原因外,还有一个原因就是UUID比整数自增ID长,UUID至少占位32字节,但int类型只占4字节,存储一个UUID的空间,可以存8个自增整数ID。也就代表着单个节点中,能存储的自增ID会比UUID多很多,单个节点存储的索引键越多.....
四、索引原理篇总结
聚簇索引和非聚簇索引的根本区别:
-
• 聚簇索引中,表数据和索引数据是按照相同顺序存储的,非聚簇索引则不是。
-
• 聚簇索引在一张表中是唯一的,只能有一个,非聚簇索引则可以存在多个。
-
• 聚簇索引在逻辑+物理上都是连续的,非聚簇索引则仅是逻辑上的连续。
-
• 聚簇索引中找到了索引键就找到了行数据,但非聚簇索引还需要做一次回表查询。
InnoDB-非聚簇索引与MyISAM-非聚簇索引的区别:
-
•
InnoDB中的非聚簇索引是以聚簇索引的索引键,与具体的行数据建立关联关系的。 -
•
MyISAM中的非聚簇索引是以行数据的地址指针,与具体的行数据建立关联关系的。
一般来说,由于MyISAM引擎中的索引可以根据指针直接获取数据,不需要做二次回表查询,因此从整体查询效率来看,会比InnoDB要快上不少。
MySQL 分库分表后的“副作用”解决方案
一、垂直分表后带来的隐患
垂直分表后当试图读取一条完整数据时,需要连接多个表来获取,对于这个问题只要在切分时,设置好映射的外键字段即可。当增、删、改数据时,往往需要同时操作多张表,并且要保证操作的原子性,也就是得手动开启事务来保证,否则会出现数据不一致的问题。
这里可以看到,垂直分表虽然会有后患问题,但带来的问题本质上也不算大问题,就是读写数据的操作会相对麻烦一些,下面来看看其他的分库分表方案,接下来是真正的重头戏。
二、水平分表后带来的问题
水平分表就是将一张大表的数据,按照一定的规则划分成不同的小表,当原本的一张表变为多张表时,虽然提升了性能,但问题随之也来了~
2.1、多表联查问题(Join)
之前在库中只存在一张表,所以非常轻松的就能进行联表查询获取数据,但是此时做了水平分表后,同一张业务的表存在多张小表,这时再去连表查询时具体该连接哪张呢?似乎这时问题就变的麻烦起来了,怎么办?解决方案如下:
-
• ①如果分表数量是固定的,直接对所有表进行连接查询,但这样性能开销较大,还不如不分表。
-
• ②如果不想用①,或分表数量会随时间不断变多,那就先根据分表规则,去确定要连接哪张表后再查询。
-
• ③如果每次连表查询只需要从中获取
1~3个字段,就直接在另一张表中设计冗余字段,避免连表查询。
第一条好理解,第二条是啥意思呢?好比现在是按月份来分表,那在连表查询前,就先确定要连接哪几张月份的表,才能得到自己所需的数据,确定了之后再去查询对应表即可,这里该如何落地实现呢?
2.2、增删改数据的问题
当想要增加、删除、修改一条数据时,因为存在多张表,所以又该去哪张表中操作呢?这里还是前面那个问题,只要在操作前确定好具体的表即可。但还有一种情况,就是批量变更数据时,也会存在问题,要批量修改的数据该具体操作哪几张分表呢?依旧需要先定位到具体分表才行。
2.3、聚合操作的问题
之前因为只有一张表,所以进行sum()、count()....、order by、gorup by....等各类聚合操作时,可以直接基于单表完成,但此刻似乎行不通了呀?对于这类聚合操作的解决方案如下:
-
• ①放入第三方中间件中,然后依赖于第三方中间件完成,如
ES。 -
• ②定期跑脚本查询出一些常用的聚合数据,然后放入
Redis缓存中,后续从Redis中获取。 -
• ③首先从所有表中统计出各自的数据,然后在
Java中作聚合操作。
前面两种操作比较好理解,第三种方案是什么意思呢?比如count()函数,就是对所有表进行统计查询,最后在Java中求和,好比分组、排序等工作,先从所有表查询出符合条件的数据,然后在Java中通过Stream流进行处理。
上述这三种方案都是比较合理且常规的方案,最好是选择第一种,这也是一些大企业选用的方案。
三、垂直分库后产生的问题
垂直分库是按照业务属性的不同,直接将一个综合大库拆分成多个功能单一的独享库,分库之后能够让性能提升N倍,但随之而来的是需要解决更多的问题,而且问题会比单库分表更复杂!
3.1、跨库Join问题
因为将不同业务的表拆分到了不同的库中,而往往有些情况下可能会需要其他业务的表数据,在单库时直接join连表查询相应字段数据即可,但此时已经将不同的业务表放到不同库了,这时咋办?跨库Join也不太现实呀,此时有如下几种解决方案:
-
• ①在不同的库需要数据的表中冗余字段,把常用的字段放到需要要数据的表中,避免跨库连表。
-
• ②选择同步数据,通过广播表/网络表/全局表将对应的表数据直接完全同步一份到相应库中。
-
• ③在设计库表拆分时创建
ER绑定表,具备主外键的表放在一个库,保证数据落到同一数据库。 -
• ④
Java系统中组装数据,通过调用对方服务接口的形式获取数据,然后在程序中组装后返回。
这四种方案都能够解决需要跨库Join的问题,但第二、三种方案提到了广播表/网络表/全局表、ER绑定表似乎之前没听说过对嘛?往往垂直分库的场景中,第四种方案是最常用的,因为分库分表的项目中,Java业务系统那边也绝对采用了分布式架构,因此通过调用对端API接口来获取数据,是分布式系统最为常见的一种现象。
3.2、分布式事务问题
分布式事务应该是分布式系统中最核心的一个问题,这个问题绝对不能出现,一般都要求零容忍,也就是所有分布式系统都必须要解决分布式事务问题,否则就有可能造成数据不一致性。
在之前单机的
MySQL中,数据库自身提供了完善的事务管理机制,通过begin、commit/rollback的命令可以灵活的控制事务的提交和回滚,在Spring要对一组SQL操作使用事务时,也只需在对应的业务方法上加一个@Transactional注解即可,但这种情况在分布式系统中就不行了。
为什么说MySQL的事务机制会在分布式系统下失效呢?因为InnoDB的事务机制是建立在Undo-log日志的基础上完成的,以前只有一个Undo-log日志,所以一个事务的所有变更前的数据,都可以记录在同一个Undo-log日志中,当需要回滚时就直接用Undo-log中的旧数据覆盖变更过的新数据即可。
但垂直分库之后,会存在多个
MySQL节点,这自然也就会存在多个Undo-log日志,不同库的变更操作会记录在各自的Undo-log日志中,当某个操作执行失败需要回滚时,仅能够回滚自身库变更过的数据,对于其他库的事务回滚权,当前节点是不具备该能力的,所以此时就必须要出现一个事务管理者来介入,从而解决分布式事务问题。
上述提到的通过第三方:事务管理者来介入,这只属于分布式事务问题的一种解决方案,解决方案如下:
-
• ①
Best Efforts 1PC模式。 -
• ②
XA 2PC、3PC模式。 -
• ③
TTC事务补偿模式。 -
• ④
MQ最终一致性事务模式。
上述是解决分布式事务问题的四种思想,目前最常用的Seata的两种模式就是基于XA-3PC和TCC思想实现的。
3.3、部分业务库依旧存在性能瓶颈问题
这种情况前面说到过,经过垂直分库之后,某些核心业务库依旧需要承载过高的并发流量,因此一单节点模式部署,依然无法解决所存在的性能瓶颈,对于这种情况直接再做水平分库即可,具体过程请参考阶段二。
四、水平分库后需要解决的问题
水平分库这种方案,能够建立在垂直分库的基础上,进一步对存储层做拓展,能够让某些业务库具备更高的并发处理能力,不过水平分库虽然带来的性能收益巨大,但产生的问题也最多!
4.1、聚合操作和连表问题
对单个业务库做了水平分库后,也就是又对单个业务库做了横向拓展后,一般都会将库中所有的表做水平切分,也就是不同库中的所有表,每个水平库节点中存储的数据是不同的,这时又会出现4.2阶段聊到的一些问题,如单业务的聚合操作、连表操作会无法进行,这种情况的解决思路和水平分表时一样,先确定读写的数据位于哪个库表中,然后再去生成SQL并执行。
当然,对于这类情况,如果只是因为并发过高导致出现性能瓶颈,最好的选择是直接做业务库集群,也就是拓展出的所有节点,数据都存一模一样的,这样无论在任何库中都具备完整数据,所以就无需先定位目标数据所处的库再操作。
但如果数据量也比较大,就只能做水平分库分表了,相同业务不同的数据库节点,存储不同范围的数据,能够在最大程度上提升存储层的吞吐能力,但会让读写操作困难度增高,因为读写之前需要先定位读写操作到底要落到哪个节点中处理。
4.2、数据分页问题
以MySQL数据库为例,如果是在之前的单库环境中,可以直接通过limit index,n的方式来做分页,而水平分库后由于存在多个数据源,因此分页又成为了一个难题,比如10条数据为1页,那如果想要拿到某张表的第一页数据,就必须通过如下手段获取:
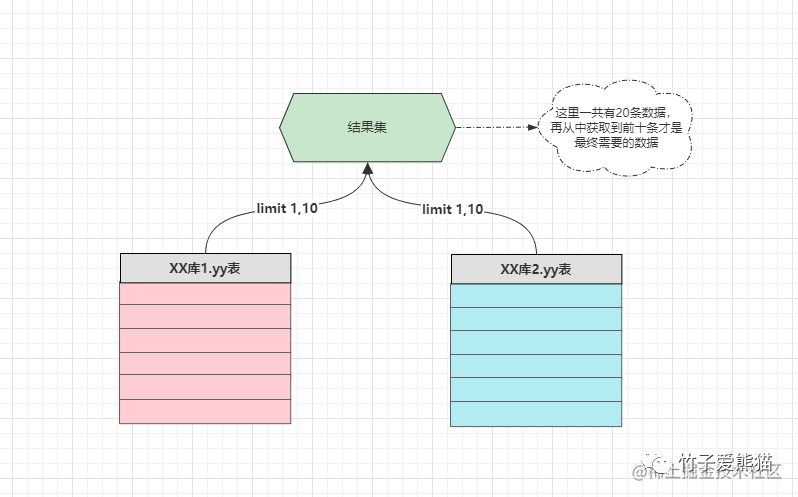
分页情况
这种方式可以是可以,但略微有些繁杂,同时也会让拓展性受限,比如原本有两个水平分库的节点,因此只需要从两个节点中拿到第一页数据,然后再做一次过滤即可,但如果水平库从两节点扩容到四节点,这时又要从四个库中各自拿10条数据,然后做过滤操作,读取前十条数据显示,这显然会导致每次扩容需要改动业务代码,对代码的侵入性有些强,所以合理的解决方案如下:
-
• ①常用的分页数据提前聚合到
ES或中间表,运行期间跑按时更新其中的分页数据。 -
• ②利用大数据技术搭建数据中台,将所有子库数据汇聚到其中,后续的分页数据直接从中获取。
-
• ③上述聊到的那种方案,从所有字库中先拿到数据,然后在
Service层再做过滤处理。
上述第一种方案是较为常用的方案,但这种方案对数据实时性会有一定的影响,使用该方案必须要能接受一定延时。第二种方案是最佳的方案,但需要搭建完善的大数据系统作为基础,成本最高。第三种方案成本最低,但对拓展性和代码侵入性的破坏比较严重。
4.3、ID主键的唯一性问题
在之前的单库环境时,对于一张表的主键通常会选用整数型字段,然后通过数据库的自增机制来保证唯一性,但在水平分库多节点的情况时,假设还是以数据库自增机制来维护主键唯一性,这就绝对会出现一定的问题,可能会导致多个库中出现ID相同、数据不同的情况,如下:
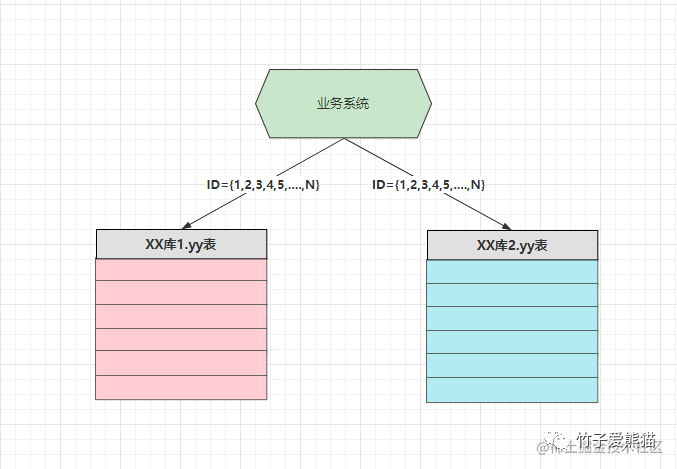
插入数据
上述两个库需要存储不同的数据,当插入数据的请求被分发到对应节点时,如果再依据自增机制来确保ID唯一性,因为这里有两个数据库节点,两个数据库各自都维护着一个自增序列,因此两者ID值都是从1开始往上递增的,这就会导致前面说到的ID相同、数据不同的情况出现,那此时又该如何解决呢?如下:
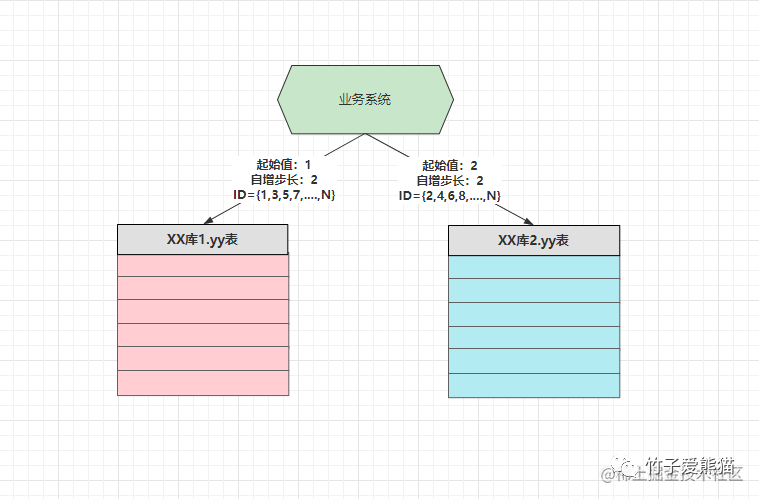
自增步长
这时可以根据水平库节点的数量来设置自增步长,假设此时有两个库,那自增步长为2,两个库的ID起始值为:{DB1:1}、{DB2:2},最终达到上图中的效果,无论在插入数据的操作落入哪个节点,都能够确保ID的唯一性。当然,保障分布式系统下ID唯一性的解决方案很多,如下:
-
• ①通过设置数据库自增机制的起始值和步长,来控制不同节点的
ID交叉增长,保证唯一性。 -
• ②在业务系统中,利用特殊算法生成有序的分布式
ID,比如雪花算法、Snowflake算法等。 -
• ③利用第三方中间件生产
ID,如使用Redis的incr命令、或创建独立的库专门做自增ID工作。
上述这几种方案都是较为主流的分布式ID生成的方案,同时也能够保证ID的有序性,能够最大程度上维护索引的性能,相对来说第一种方案成本最低,但是会限制节点的拓展性,也就是当后续扩容时,数据要做迁移,同时要重新修改起始值和自增步长。
一般企业中都会使用第二种方案,也就是通过分布式
ID生成的算法,在业务系统中生成有序的分布式ID,以此来确保ID的唯一性。
4.4、数据的落库问题
对数据库做了水平拆分后,数据该怎么存储呢?写操作究竟该落到哪个库呢?读操作又如何确定数据在哪个库中呢?比如新增一条ID=987215的数据,到底插入到哪个库中,需要这条数据时又该如何查询?这显然是做了水平拆分之后必须要思考的问题,这定然不能随便写,因为写过的数据在后续业务中肯定会用到,所以写数据时需要根据一定规则去落库,这样才能在需要时能定位到数据。
但数据的拆分规则,或者被称之为路由规则,具体的还是要根据自己的业务来进行选择,在拆分时只需遵循:数据分布均匀、查询方便、扩容/迁移简单这几点原则即可。
一般简单常用的数据分片规则如下:
-
• ①随机分片:随机分发写数据的请求,但查询时需要读取全部节点才能拿取数据,一般不用。
-
• ②连续分片:每个节点负责存储一个范围内的数据,如
DB1:1~500W、DB2:500~1000W....。 -
• ③取模分片:通过整数型的
ID值与水平库的节点数量做取模运算,最终得到数据落入的节点。 -
• ④一致性哈希:根据某个具备唯一特性的字段值计算哈希值,然后再通过哈希值做取模分片。
-
•
..........
总之想要处理好数据的落库问题,那首先得先确定一个字段作为分片键/路由键,然后基于这个字段做运算,确保同一个值经计算后都能分发到同一个节点,这样才能确保读写请求正常运转。
4.5、流量迁移、容量规划、节点扩容等问题
流量迁移、容量规划、节点扩容等这些问题,在做架构改进时基本上都会碰到,接着依次聊一聊。
4.5.1、流量迁移
线上环境从单库切换到分库分表模式,数据该如何迁移才能保证线上业务不受影响,对于这个问题来说,首先得写脚本将老库的数据同步到分库分表后的各个节点中,然后条件允许的情况下先上灰度发布,划分一部分流量过来做运营测试。
如果没有搭建完善的灰度环境,那先再本地再三测试确保没有问题后,采用最简单的方案,先挂一个公告:“今日凌晨两点后服务器会进入维护阶段,预计明日早晨八点会恢复正常运转”!然后停机更新,但前提工作做好,如:Java代码从单库到分库分表要改进完善、数据迁移要做好、程序调试一切无误后再切换,同时一定要做好版本回滚支持,如果迁移流量后出现问题,可以快捷切换回之前的老库。
4.5.2、容量规划
关于分库分表首次到底切分成多少个节点合适,对于这点业内没有明确规定,更多的要根据自身业务的流量、并发情况决定,根据实际情况先做垂直分库,然后再对于核心库做水平分库,但水平分库的节点数量要保证的是2的整倍数,方便后续扩容。
4.5.3、节点扩容
扩容一般是指水平分库,也就是当一个业务库无法承载流量压力时,需要对相应的业务的节点数量,但扩容时必须要考虑本次增加节点会不会影响之前的业务,因为很多情况下,当节点的数量发生改变时,可能会影响数据分片的路由规则,这时就要考虑扩容是否会影响原本的路由规则。
扩容一般都是基于水平分库的基础上,进一步对水平库做节点扩容,目前业内有两种主流做法:水平双倍扩容法、异步双写扩容法。
水平双倍扩容法
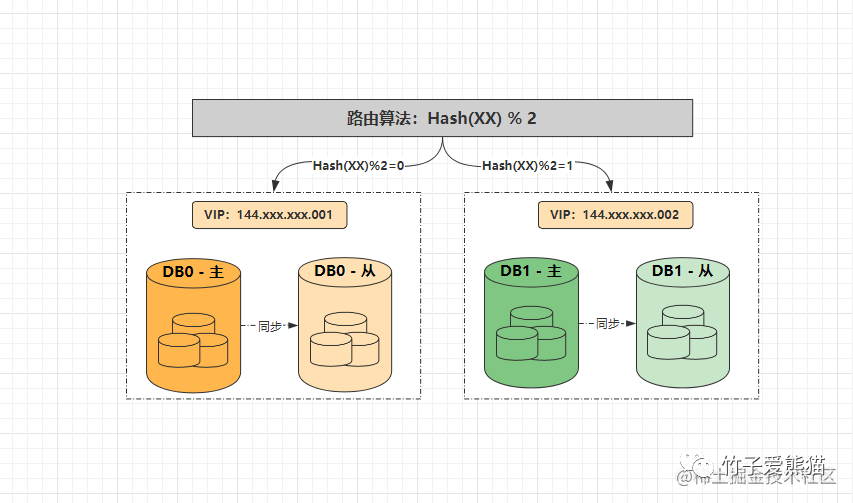
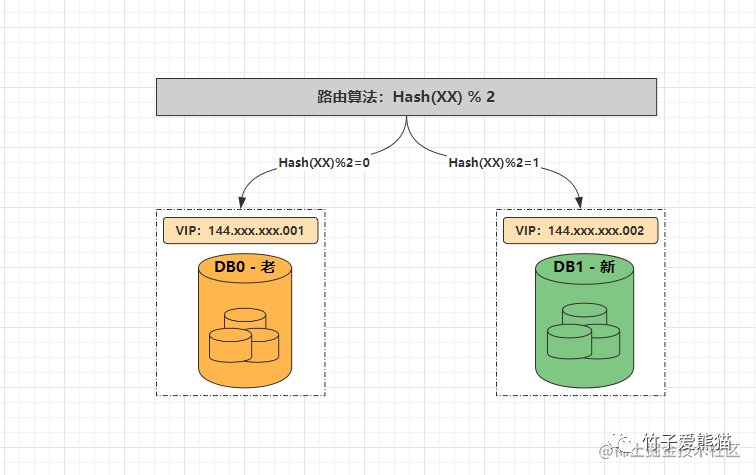
想要使用双倍扩容法对节点进行扩容,首先必须要求原先节点数为2的整数倍,同时路由规则必须要为数值取模法、或Hash取模法,否则依旧会造成扩容难度直线提升。同时双倍扩容法还有一种进阶做法,被称之为从库升级法,也就是给原本每个节点都配置一个从库,然后同步主节点的所有数据,当需要扩容时仅需将从库升级为主节点即可,过程如下:
水平分库-两节点
起初某个业务的水平库节点数量为2,因此业务服务中的数据源配置为{DB0:144.xxx.xxx.001、DB1:144.xxx.xxx.002},当读写数据时,如果路由键经哈希取模运算后的结果为0,则将对应请求落到DB0处理,如若取模结果为1,则将数据落到DB1中处理,此时两节点的数据如下:
-
•
DB0:{2、4、6、8、10、12、14、16.....} -
•
DB1:{1、3、5、7、9、11、13、15......}
同时DB0、DB1两个节点都各有一个从节点,从节点会同步各自主节点的所有数据,此时假设两个节点无法处理请求压力时,需要进一步对水平库做扩容,这时可直接将从节点升级为主节点,过程如下:
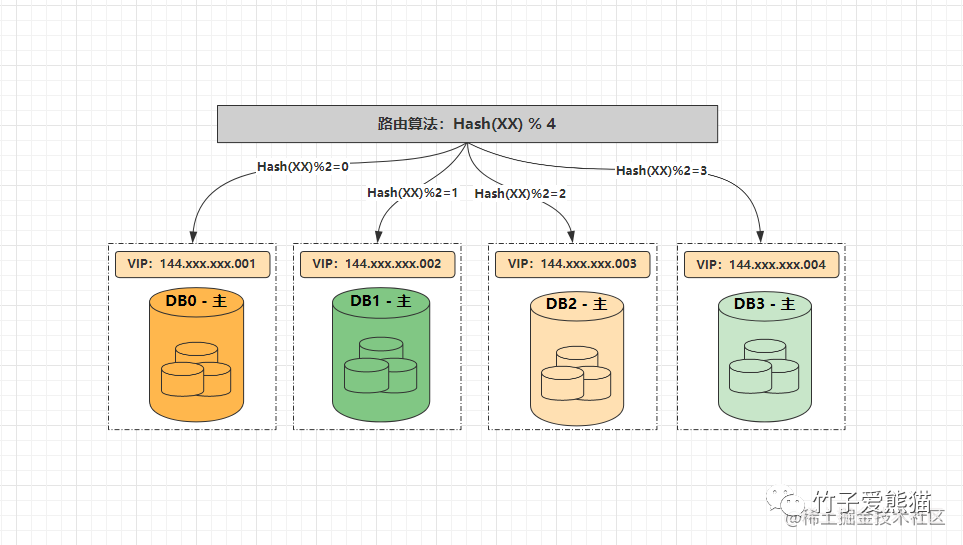
水平扩容-四节点
经过扩容之后,节点数量变成了4,所有首先得修改业务服务中的数据源配置为{DB0:144.xxx.xxx.001、DB1:144.xxx.xxx.002}、{DB2:144.xxx.xxx.003、DB3:144.xxx.xxx.004},然后将路由算法修改为%4,最终数据分片如下:
-
•
DB0:{4, 8, 12, 16, 20, 24.....} -
•
DB1:{1, 5, 9, 13, 17, 21......} -
•
DB2:{2, 6, 10, 14, 18, 22.....} -
•
DB3:{3, 7, 11, 15, 19, 23.....}
此时要注意,因为DB2原本属于DB0的从库,所以具备原本DB0的所有数据,现在再观察上述的数据分片情况,对比如下:
-
• 扩容后的
DB2:{2, 6, 10, 14, 18, 22.....} -
• 扩容前的
DB0:{2、4、6、8、10、12、14、16.....}
此时大家应该会发现,扩容后DB2中落入的分片数据,原本都是存在于DB0中的,而DB2原先就是DB0的从库,所以也具备之前DB0中数据,因此采用这种扩容法,基本上无需做数据迁移!
好比现在要查询
ID=10的数据,根据原本Hash(XX)%2的路由算法,会落入到DB0中读取数据,而根据现在Hash(XX)%4的路由算法,应该落入到DB2中读取数据,因为DB2具备原本DB0的数据,所以也无需在扩容后,再次从DB0中将数据迁移过来(DB1、DB3亦是同理)。
为了不占用存储空间,也可以在凌晨两点到六点这段业务低峰期,去跑脚本删除重复的数据,因为目前DB0、DB2之间的数据完全相同,都包含了对方要负责的分片数据,所以在跑脚本的时候就是要从自身库中删除对方的数据(DB1、DB3亦是同理)。
这种从库升级扩容法是双倍扩容法的进阶实现,但这种情况会浪费一倍的机器,所以适用于一些流量特别大的场景,因为在这种扩容法中无需做数据迁移,同时扩容之后的
4个节点,也可以再为其配置4个从库,以便于下次扩容。
当然,如果你感觉这种做法太浪费机器,也可以使用传统的双倍扩容法,即每次扩容之后,要手动从原本的库中将分片数据迁移过来,如果数据量较大时,迁移数据的时间会较长,所以只能做离线迁移。
同时在离线迁移的过程中,线上数据还有可能发生变更,所以离线迁移后还需要核对数据的一致性,过程会更繁琐一些,所以省机器还是省麻烦,需要诸位在两者之间做抉择。
推荐从库升级法,因为从库升级法不仅仅能够避免数据迁移,而且还能保证高可用,当主节点宕机时可以让从节点直接上线顶替,再配合Keepalived+VIP做重启,基本上能够让数据库真正达到7x24小时不间断运行。
异步双写扩容法
前面聊到的水平双倍扩容法,仅仅只是扩容时的一种方案,除此之外还有另一种方案称之为异步双写扩容法,大体示意图如下:
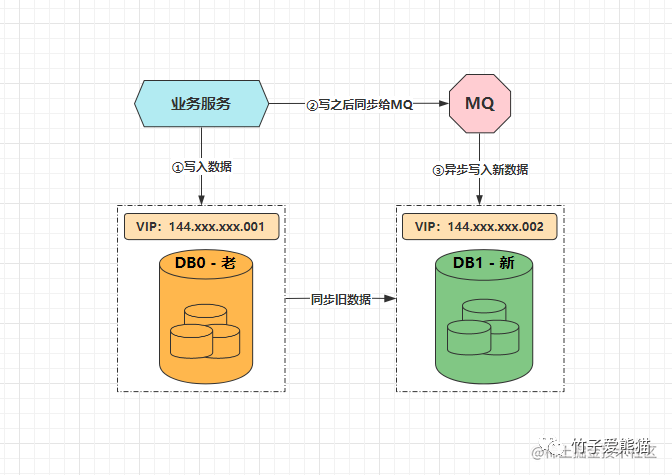
双写扩容法
对于需要扩容时的情况,首先依旧把新的数据写入到老库中,然后写完之后同步给MQ一份,后续再由MQ的消费者去将新数据写到新库中,同时新库在这期间,会去同步老库中原有的数据,这个动作持续到所有旧数据全部同步完成后,再以老库作为校验基准,核对数据无误后,再将模式切换为扩容后的分库模式:
双写扩容
切换到分库模式后,记得在业务代码中去掉双写的逻辑,改为路由分片的逻辑,稍微总结一下整个流程,如下:
-
• 第一步:修改应用服务代码,加上
MQ双写方案,配置新库同步老库数据,然后部署。 -
• 第二步:等待新库同步复制老库中所有老数据,期间新写入的数据也会通过
MQ写入新库。 -
• 第三步:老库中的所有老数据全部同步完成后,以老库作为校验基准,校对新库中的数据。
-
• 第四步:校对新老库之间的数据无误后,修改应用配置和代码,将双写改为路由分片,再次部署。
看到这里相信诸位已经明白了两种扩容方法,这两种方案都是分库分表扩容时最常用的方案,但异步双写扩容法,更适用于垂直分库后的第一次单节点扩容。而水平双倍扩容法,则适用于水平分库后的第N次扩容。
其实异步双写方案,也可以用来做后续的节点扩容,但会相对来说比较麻烦一些。
4.6、分库后的多维度查询问题
之前单库的一张表,好比以zz_users用户表为例,既可以通过user_id检索数据,如:
-
•
select * from zz_users where user_id = 10086;
也可以通过user_name进行数据的查找,如:
-
•
select * from zz_users where user_name = '竹子爱熊猫';
但是现在水平分库后呢,执行SQL究竟该落入哪个库是根据路由键和路由算法来决定的,假设这里路由键为user_id,此时通过user_id查询当然没有问题,但通过user_name查询时,就无法通过路由键定位具体DB了,那又该怎么办呢?解决方案如下:
-
• ①淘宝方案:对于订单库实现了多库多维路由键拆分,直接用了三个水平库集群,一个以用户
ID作为路由键,一个以商户ID作为路由键,一个以订单时间作为路由键,三个分库集群中数据完全相同,从而满足不同维度查询数据的业务需求。 -
• ②数据量小的时候时,可以通过
ES维护路由键的二级索引,如1:竹子、2:熊猫....。
如果业务数据量特别巨大,可以选择第一种方案做分库集群,但如果数据量不是百亿级别的规模,则可以通过ES建立路由键的二级索引,当基于非路由键字段查询时,先从ES中查到路由键值,然后再根据路由键查询数据库的数据返回。
4.7、外键约束问题
一般的项目基本上都会存在主外键,虽然不会在表上添加主外键约束,但也会从逻辑上保障主外键关系,但经过水平分库后,所有的读写操作会基于路由键去分片,那此时以订单表、订单详情表为例,假设用户选择了三个购物车的商品提交订单,此时会产生一条订单记录、以及对应的三条订单详情记录,关系大致如下:
-
• 订单数据:
order_id=1, pay_money=8888, user_id=666, shop_order_row=3, ...... -
• 订单详情数据:
-
•
order_info_id=1, shop_name='黄金竹子', shop_count=1, unit_price=6000..... -
•
order_info_id=2, shop_name='白玉竹子', shop_count=2, unit_price=1111..... -
•
order_info_id=3, shop_name='翠绿竹子', shop_count=1, unit_price=666.....
-
假设商品库有两个水平节点,两个商品库都具备订单表、订单详情表,而订单表的路由键是order_id,订单详情表的路由键是order_info_id,数据分片的路由算法为取模,那此时数据的落库情况为:
-
•
order_id % 2:1 % 2 = 1,order_id=1的订单数据落入DB1商品库中。 -
•
order_info_id % 2:-
•
1 % 2 = 1、3 % 2 = 1,order_info_id = 1、3的订单详情数据落入DB1商品库中。 -
•
2 % 2 = 0,order_info_id = 2的订单详情数据落入DB0商品库中。
-
但此时order_id=1,order_info_id=1、2、3的数据是存在外键关系的,如果按照上述的路由方式去对数据做分片,最终就会导致通过order_id=1的订单ID查询订单详情时,只能在DB1中查询到两条订单详情数据,这个问题显然是业务上无法接受的。
所以面对于这种业务上存在主外键关系的表,必须要能够确保外键所在的数据记录,必须要和主键数据记录落到同一个库中去,否则后续无法通过主键值查询到完整的数据,对于这种情况的解决方案是通过绑定表去实现(绑定表也是分库分表中的一个新概念)。
五、分库后程序怎么访问数据库?
在之前的单库模式下,业务系统需要使用数据库时,只需要在相关的配置文件中,配置单个数据源的地址、用户、密码等信息即可。但分库分表后由于存在多个数据源,程序怎么样访问数据库,配置和代码该怎么写呢?这是一个更应该关心的问题,具体可分为几种方式:
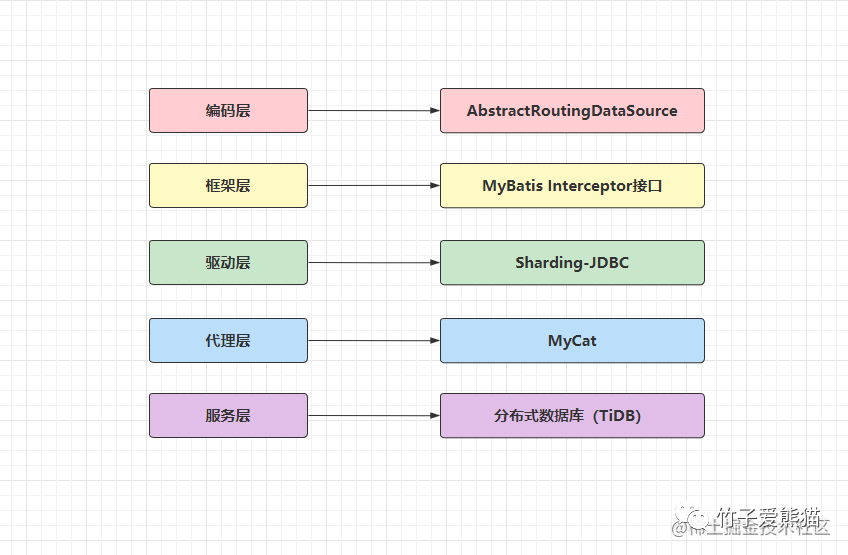
切库方案
-
• 编码层:在代码中通过框架提供的数据源动态切换类实现,如
Spring.AbstractRoutingDataSource类。 -
• 框架层:一般的
ORM框架也会提供切换数据源的实现类,比如MyBatis.Interceptor接口拦截SQL实现。 -
• 驱动层:在
JDBC驱动层拦截SQL语句,然后改写SQL实现,如Sharding-JDBC框架的原理就是如此。 -
• 代理层:所有使用数据库的业务服务都连接代理中间件,由中间件来决定落库位置,如
MyCat实现。 -
• 服务层:如今较为流行的分布式数据库,基本上都自带分库分表功能,如
TiDB、OceanBase....
一般编码层或框架层都无法单独实现数据源的切换,两者必须配合起来完成,用MyBatis.Interceptor接口拦截SQL语句,然后根据SQL中的路由键做运算,最终再通过Spring.AbstractRoutingDataSource类去动态切换数据源。但这种方案的工程量很大,实现过程也较为繁杂,所以下面直接来看一些成熟的方案,如下:
-
• 工程(依赖、
Jar包、不需要独立部署,可集成在业务项目中)-
• 淘宝网:TDDL
-
• 蘑菇街:TSharding
-
• 当当网:Sharding-Sphere-JDBC
-
-
• 进程(中间件、需要独立部署的第三方进程)
-
• 早年最热门、基于阿里Cobar二开的MyCat
-
• 阿里B2B:Cobar
-
• 奇虎360:Atlas
-
• 58同城:Oceanus
-
• 谷歌开源:Vitess
-
• 当当网:Sharding-Sphere-Proxy
-
先如今要考虑做分库分表时,可首先选用当当网的
Sharding-Sphere框架,早些年原本只有Sharding-JDBC驱动层的分库分表,但到了后续又推出了代理层的Sharding-Proxy中间件,最终合并成立了Sharding-Sphere项目。
近几年该项目也交由Apache软件基金会来孵化,并且列入到顶级项目孵化列表,随着Apache接手后也有了充实的后背保障,因此更建议分库分表时选用Sharding-Sphere来实现,官网:《Sharding-Sphere官网》。
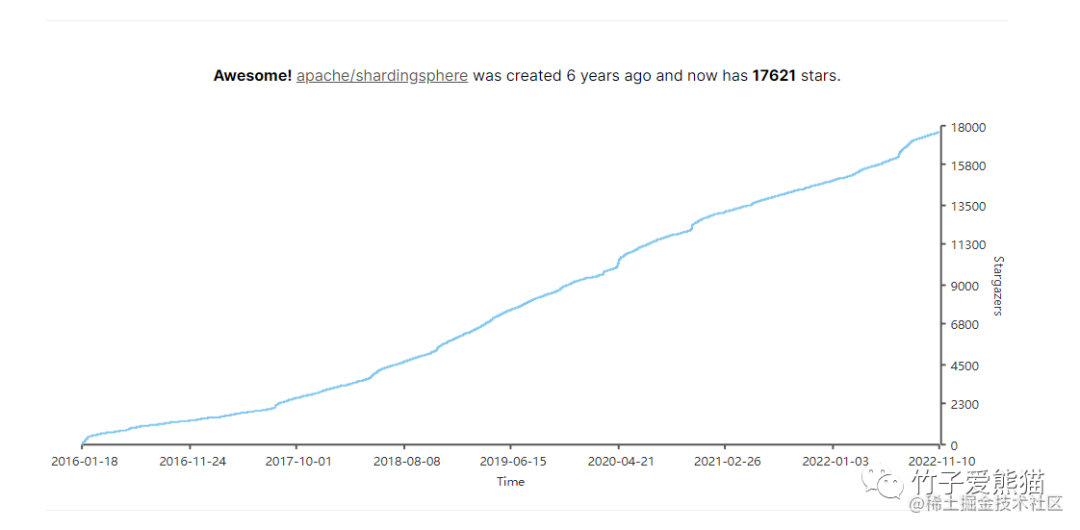
欢迎度
从社区生态和GitHub的趋势来看,基本上近些年的增长也十分迅猛,并且Sharding-Sphere中对分库分表后产生的一系列问题,也提供了一站式解决方案。
六、分库分表后患问题总结
所谓的架构师并不是指能做架构选型即可,比如决定缓存用
Redis、消息中间件用RocketMQ、ORM框架用MyBatis-Plus、微服务框架用SpringCloud Alibaba.......,真正的架构是要能够清楚各层面中主流的技术方案,毕竟能够充分结合业务去做选型,最关键的是自身也得清楚选用某个技术栈后能够带来的性能收益,以及引入某项技术后会带来的风险问题及解决方案。
比如当你考虑对存储层做分库分表时,就得先考虑清楚本章中提到的所有问题,以及具体该如何解决,只考虑追求技术风潮,不考虑技术风险的做法,显然无法被称作一位合格的架构师。一名合格的架构除开能全面考虑到技术风险且给出解决方案外,应当还得将项目架构设计的更为合理才行,比如设计的技术架构具备很强的弹性伸缩能力,可根据业务的增长/萎靡进行动态的伸缩调整。
月增上亿条数据的单表处理方案
一、源自于软硬结合的特殊业务
先来聊聊之前碰到的这个业务,这个业务比较特殊,相信很多小伙伴从未碰到过,这种业务本身用户量不大,甚至可以说用户量非常非常少,因为业务的起源来自于一款硬件设备,但具体的设备类型由于某些缘故就不透露了,可以理解成是下面这个东东:

超市收银机
虽然当时的硬件设备并不是这个,但也和它很类似,相信大家但凡在超市购过物都认识它,也就是超市收银台的收银机,当时我们是对外提供了一千台设备,这种设备通常一台只有一个用户,所以当时整个系统上线后所有的用户加起来,涵盖后台管理员、超级管理员账号在内,也不过1200个用户,这个用户规模相较于常见业务而言属实不多。
而当时我们需要负责的就是:为这些设备开发一个操作系统,这里不是指
Windows、Linux、Mac这类嵌入式的底层系统,而是给机器的操作员开发一个操作界面,就类似于诸位在超市购物时,超市收银员用手操作的那个界面。
因为这些机器本身会安装一个带UI的系统,里面也支持安装一些软件,我们的软件会以GUI的形式嵌入这些设备,当时我要干的就是直接开发API接口,然后提供给GUI界面界面调用。本质上就属一个前后端分离的项目,只不过前端从原本的Web界面变成了GUI界面。
大家听起来这个项目是不是特别容易完成,用户量又少代表不需要考虑并发,也不会存在太大的流量冲击,性能要求也不会太高,似乎就是一个简简单单的单体增删改查项目呀?但事情远没有表面这么简单。
1.1、项目的难点
起初当我收到通知要负责这个需求时,从表面浅显的想了一下,似乎发现也不是太难,就是一个单体项目的CRUD工作,以我这手出神入化的CV大法,Hlod住它简直轻轻松松,因此当时也没想太多就直接接手了,项目初期由于团队每位成员经验都很丰富,各自凭借着个人的Copy神功,项目的开发进度可谓是一骑千里,但慢慢的问题来了,而且这个问题还不小!
当时大概对外预计分发
1000台机器,每台机器正式投入运营后,预估单日会产生500~600条数据的产出,套到前面的举例中,也就是大概会向几百个超市投放共计1000台收银机,每个收银台平均下来之后,大概单日内会有500~600个顾客结账!
这里咱们做个数学题:现在有1000台机器,每台机器单日就算产生500条数据:1000 * 500 = 500000,这也就意味着单日的账单表中会新增50W条流水数据,单月整个账单表的数据增长量为:50W * 30 = 1500W!
单月数据增长
1500W的概念不言而喻,这也就代表着一年的数据增长量为1500W * 12 = 1.8E,这批机器投入后预估最少会运行三年起步,甚至十年乃至更久,同时第一批次就要投入1000台,后面可能还会有第二批次、第三批次.....的投入。
50W只是最低的账单流水数据量,后续正式运营后可能数据量更大,此时架构的设计就成了难题!
1.2、方案的探讨
基本上当时团队的成员中,没人在此之前碰过这类需求,因此开了一个研讨会,去决定该如何将具体的方案落地,这里有人也许会说,数据量这么大,快上分布式/微服务啊!但实则解决不了这个问题,Why?因为项目整体的用户量并不大,最多同一时刻也才1000并发请求,就算这个并发量再增大几个级别,这里用单体架构优化好了也能够抗住,所以问题并不在业务系统的架构上面,而是在数据落库这方面。
这里直接用分库可以吗?答案是也不行,
Why?因为整个项目中只有账单表才有这么大的数据量,其他的用户表、系统表、功能菜单表、后台表......,基本上不会有太大的数据量,所以直接做分库也没必要,属实有些浪费资源。
这里可以按月份对流水表做分区,但依旧不行,因为第一批机器投入后,单月预计就会产生1500W条数据,后续可能会增加机器数量,因此单月的数据量达到2000W、3000W.....都有可能,如果按月做表分区,每个分区里面都有几千万条数据,一张账单表的流水随着时间推移,数据量甚至会达到几十亿!
一张表中存储几十亿条数据,这基本上不现实,虽然
InnoDB在数据页为16KB尺寸下,单表最多能存储64TB数据,有可能这几十亿条数据真的能存下去,但查询时的性能简直令人头大,并且最关键的是不方便后续对数据做维护、管理、备份和迁移工作。
因此经过一番探讨后,最后决定选择了表分区技术的进阶版实现,即单库内做水平分表,按月份对数据做分表,也就是将账单表分为month_bills_202210、month_bills_202211、month_bills_202212.......以月份结尾的多张表,每个月的账单流水数据最终都会插入到各自的月份表中。
最终架构定型为:业务系统使用单体架构 + 数据库使用单库 + 流水表按月份做水平分表。
二、按月分表方案的落地实践
在上一阶段中已经决定好了具体的方案,但又该如何将方案落地呢?首先咱们先把方案落地的思路捋清楚:
-
• ①能够自动按月创建一张月份账单表,从而将每月的流水数据写入进去。
-
• ②写入数据时,能够根据当前的日期,选择对应的月份账单表并插入数据。
实现了上面两个需求后,整个方案近乎落地了一半,但接下来该如何去实现相应功能呢?咱们一点点来动手实现。
2.1、利用存储过程实现按月动态创建表
创建表的SQL语句大家都不陌生,按月份创建表之前,自然也需要一份原生创建表的DDL语句,如下:
CREATE TABLE `month_bills_202211`(
`month_bills_id`int(8) NOT NULL AUTO_INCREMENT COMMENT '账单ID',
`serial_number`varchar(50) NOT NULL COMMENT '流水号',
`bills_info` text NOT NULL COMMENT '账单详情',
`pay_money`decimal(10,3) NOT NULL COMMENT '支付金额',
`machine_serial_no`varchar(20) NOT NULL COMMENT '收银机器',
`bill_date`timestamp NOT NULL COMMENT '账单日期',
`bill_comment`varchar(100) NULL DEFAULT '无' COMMENT '账单备注',
PRIMARY KEY (`month_bills_id`) USING BTREE,
UNIQUE`serial_number`(`serial_number`),
KEY `bill_date`(`bill_date`)
)
ENGINE =InnoDB
CHARACTER SET= utf8
COLLATE= utf8_general_ci
ROW_FORMAT =Compact;上述的语句会创建一张月份账单表,这张表主要包含七个字段,如下:
| 字段 | 简介 | 描述 |
month_bills_id | 月份账单ID | 主要作为月份账单表的主键字段 |
serial_number | 流水号 | 所有账单流水数据的唯一流水号 |
bills_info | 账单详情 | 顾客本次订单中,购买的所有商品详情数据 |
pay_money | 支付金额 | 本次顾客共计消费的总金额 |
machine_serial_no | 收银机器 | 负责结算顾客订单的收银机器 |
bill_date | 账单日期 | 本次账单的结算日期 |
bill_comment | 账单备注 | 账单的额外备注 |
其中注意的几个小细节:
-
• ①日期字段使用的是
timestamp类型,而并非datetime,因为前者更省空间。 -
• ②账单详情字段用的是
text类型,因为这个字段可能会出现很多的信息。 -
• ③定义了一个和表没有关系的自增字段作为主键,用于维护聚簇索引树的结构。
除开有上述七个字段外,还有三个索引:
| 索引字段 | 索引类型 | 索引作用 |
month_bills_id | 主键索引 | 主要作用就是用来维护聚簇索引树 |
serial_number | 唯一索引 | 当需要根据流水号查询数据时使用 |
bill_date | 唯一联合索引 | 当需要根据日期查询数据时使用 |
到这里就有了最基本的建表语句,主要是用来创建第一张月份账单表,如果想要实现动态按照每月建表的话,还需要用到存储过程来实现。
最终撰写出的存储过程如下:
DELIMITER //
DROPPROCEDURE IF EXISTS create_table_by_month //
CREATEPROCEDURE`create_table_by_month`()
BEGIN
-- 用于记录下一个月份是多久
DECLARE nextMonth varchar(20);
-- 用于记录创建表的SQL语句
DECLARE createTableSQL varchar(5210);
-- 执行创建表的SQL语句后,获取表的数量
DECLARE tableCount int;
-- 用于记录要生成的表名
DECLARE tableName varchar(20);
-- 用于记录表的前缀
DECLARE table_prefix varchar(20);
-- 获取下个月的日期并赋值给nextMonth变量
SELECT SUBSTR(
replace(
DATE_ADD(CURDATE(),INTERVAL1MONTH),
'-',''),
1,6)INTO@nextMonth;
-- 设置表前缀变量值为td_user_banks_log_
set@table_prefix='month_bills_';
-- 定义表的名称=表前缀+月份,即 month_bills_2022112 这个格式
SET@tableName= CONCAT(@table_prefix,@nextMonth);
-- 定义创建表的SQL语句
set@createTableSQL=concat("create table if not exists ",@tableName,"(
`month_bills_id` int(8) NOT NULL AUTO_INCREMENT COMMENT '账单ID',
`serial_number` varchar(50) NOT NULL COMMENT '流水号',
`bills_info` text NOT NULL COMMENT '账单详情',
`pay_money` decimal(10,3) NOT NULL COMMENT '支付金额',
`machine_serial_no` varchar(20) NOT NULL COMMENT '收银机器',
`bill_date` timestamp NOT NULL DEFAULT now() COMMENT '账单日期',
`bill_comment` varchar(100) NULL DEFAULT '无' COMMENT '账单备注',
PRIMARY KEY (`month_bills_id`) USING BTREE,
UNIQUE `serial_number` (`serial_number`),
KEY `bill_date` (`bill_date`)
) ENGINE = InnoDB
CHARACTER SET = utf8
COLLATE = utf8_general_ci
ROW_FORMAT = Compact;");
-- 使用 PREPARE 关键字来创建一个预备执行的SQL体
PREPARE create_stmt from@createTableSQL;
-- 使用 EXECUTE 关键字来执行上面的预备SQL体:create_stmt
EXECUTE create_stmt;
-- 释放掉前面创建的SQL体(减少内存占用)
DEALLOCATEPREPARE create_stmt;
-- 执行完建表语句后,查询表数量并保存再 tableCount 变量中
SELECT
COUNT(1)INTO@tableCount
FROM
information_schema.`TABLES`
WHERE TABLE_NAME =@tableName;
-- 查询一下对应的表是否已存在
SELECT@tableCount'tableCount';
END//
delimiter ;上述这个存储过程比较长,但基本上都写好了注释,所以阅读起来应该还是比较轻松的,也包括该存储过程在MySQL5.1、8.0版本中都测试过,所以大家也可以直接用,主要拆解一下里面较为难理解的一句SQL,如下:
SELECT SUBSTR(
replace(
DATE_ADD(CURDATE(), INTERVAL 1 MONTH),
'-', ''),
1, 6) INTO @nextMonth;这条语句执行之后会生成一个202212这样的月份数字,主要用来作为表名的后缀,以此来区分不同的表,但里面用了几个函数组合出了该效果,下面做一下拆解,如下:
-- 在当前日期的基础上增加一个月,如2022-11-12 23:46:11,会得到2022-12-12 23:46:11
select DATE_ADD(CURDATE(), INTERVAL 1 MONTH);
-- 使用空字符代替日期中的 - 符号,得到 20221212 23:46:11 这样的效果
select replace('2022-12-12 23:46:11', '-', '');
-- 对字符串做截取,获取第一位到第六位,得到 202212 这样的效果
select SUBSTR("20221212 23:46:11",1,6);经过上述拆解之后大家应该能看的很清楚,最终每次调用该存储过程时,都会基于当前数据库的时间,然后向后增加一个月,同时将格式转化为YYYYMM格式,接下来调用该存储过程,如下:
call create_table_by_month();
+------------+
| tableCount |
+------------+
| 1 |
+------------+当返回的值为1而并非0时,就表示已经在数据库中查到了前面通过存储过程创建的表,即表示动态创建表的存储过程可以生效!接着为了能够每月定时触发,可以在MySQL中注册一个每月执行一次的定时事件,如下:
create EVENT
`create_table_by_month_event`-- 创建一个定时器
ON SCHEDULE EVERY
1 MONTH-- 每间隔一个月执行一次
STARTS
'2022-11-28 00:00:00'-- 从2022-11-28 00:00:00后开始
ON COMPLETION
PRESERVE ENABLE -- 执行完成之后不删除定时器
DO
call create_table_by_month(); -- 每次触发定时器时执行的语句MySQL5.1版本中除开引入了存储过程/函数、触发器的支持外,还引入了定时器的技术,也就是支持定时执行一条SQL,此时咱们可借助MySQL自带的定时器来定时调用之前的存储过程,最终实现按月定时创建表的需求!
但定时器在使用之前,需要先查看定时器是否开启,如下:
show variables like 'event_scheduler';
如果是OFF关闭状态,需要通过set global event_scheduler = 1 | on;命令开启。
如果想要永久生效,MySQL8.0以下的版本可找到my.ini/my.conf文件,然后找到[mysqld]的区域,再里面多加入一行event_scheduler = ON的配置即可。
这里再附上一些管理定时器的命令:
-- 查看创建的定时器
show events;
select * from mysql.event;
select * from information_schema.EVENTS;
-- 删除一个定时器
drop event 定时器名称;
-- 关闭一个定时器任务
alter event 定时器名称 on COMPLETION PRESERVE DISABLE;
-- 开启一个定时器任务
alter event 定时器名称 on COMPLETION PRESERVE ENABLE; 经过上述几步后,就能够让MySQL自己按月创建表了,但为啥我会将定时器的时间设置为2022-11-28 00:00:00这个时间后开始呢?因为202211这张表我已经手动建立了,不将建立表的工作放在月初一号执行,这是因为前面的存储过程是创建下月表,而不是创建当月表,同时月底提前创建下月表,还能提高容错率,在MySQL定时器故障的情况下,能预留人工介入的时间。
2.2、写入数据时能够根据月份插入对应表
还需要搭建客户端,这里用SpringBoot+MyBatis来快速构建一个单体项目,这里需要注意,月份账单表对应的实体类中要多出一个targetTable字段,如下:
public class MonthBills{
// 月份账单表ID
private Integer monthBillsId;
// 账单流水号
private String serialNumber;
// 支付金额
private BigDecimal payMoney;
// 收银机器
private String machineSerialNo;
// 账单日期
private Date billDate;
// 账单详情
private String billsInfo;
// 账单备注
private String billComment;
// 要操作的目标表
private String targetTable;
// 省略构造方法和Get/Set方法.....
}上述的实体类与之前的表字段结构几乎完全相同,但会多出一个targetTable属性,后续会用来记录要操作的目标表,接着再撰写一个工具类,如下:
public class TableTimeUtils{
/*
* 使用ThreadLocal来确保线程安全,或者可以使用Java8新引入的DateTimeFormatter类:
* monthTL:负责将一个日期处理成 YYYYMM 格式
*/
privatestatic ThreadLocal<SimpleDateFormat> monthTL =
ThreadLocal.withInitial(()->
new SimpleDateFormat("YYYYMM"));
// 表的前缀
private static String tablePrefix="month_bills_";
// 将一个日期格式化为YYYYMM格式
public static String getYearMonth(Date date){
return monthTL.get().format(date);
}
// 获取目标数据的表名(操作单条数据公用的方法:增删改查)
public static void getDataByTable(MonthBills monthBills){
// 获取传入对象的时间
Date billDate= monthBills.getBillDate();
// 根据该对象中的时间,计算出要操作的表名后缀
String yearMonth= getYearMonth(billDate);
// 将表前缀和后缀拼接,得到完整的表名,如:month_bills_202211
monthBills.setTargetTable(tablePrefix + yearMonth);
}
}这个工具类主要负责处理日期的时间格式,以及用来定位要操作的目标表名,对于日期格式化类:SimpleDateFormat由于是线程不安全的,所以使用ThreadLocal来确保线程安全!上述工具类中主要提供了两个基础方法:
-
•
getYearMonth():将一个日期格式化成YYYYMM格式。 -
•
getDataByTable():获取单条数据操作时的表名。
有了工具类后,接着来撰写Dao、Mapper层的代码,如下:
@Mapper
@Repository
public interface MonthBillsMapper{
int deleteByPrimaryKey(Integer monthBillsId);
int insertSelective(MonthBills record);
MonthBills selectByPrimaryKey(Integer monthBillsId);
int updateByPrimaryKeySelective(MonthBills record);
}上述是月份账单表对应的Dao/Mapper接口,因为我这里是通过MyBatis的逆向工程文件自动生成的,所以名字就是上面那样,我这边未成更改,接着来看看对应的xml文件,如下:
<insert id="insertSelective" parameterType="com.zhuzi.dbMachineSubmeter.entity.MonthBills">
insert into ${targetTable}
<trim prefix="(" suffix=")" suffixOverrides="," >
<if test="monthBillsId != null" >
month_bills_id,
</if>
<if test="serialNumber != null" >
serial_number,
</if>
<if test="payMoney != null" >
pay_money,
</if>
<if test="machineSerialNo != null" >
machine_serial_no,
</if>
<if test="billDate != null" >
bill_date,
</if>
<if test="billComment != null" >
bill_comment,
</if>
<if test="billsInfo != null" >
bills_info,
</if>
</trim>
<trim prefix="values (" suffix=")" suffixOverrides="," >
<if test="monthBillsId != null" >
#{monthBillsId,jdbcType=INTEGER},
</if>
<if test="serialNumber != null" >
#{serialNumber,jdbcType=VARCHAR},
</if>
<if test="payMoney != null" >
#{payMoney,jdbcType=DECIMAL},
</if>
<if test="machineSerialNo != null" >
#{machineSerialNo,jdbcType=VARCHAR},
</if>
<if test="billDate != null" >
#{billDate,jdbcType=TIMESTAMP},
</if>
<if test="billComment != null" >
#{billComment,jdbcType=VARCHAR},
</if>
<if test="billsInfo != null" >
#{billsInfo,jdbcType=LONGVARCHAR},
</if>
</trim>
</insert>是MyBatis逆向工程生成的代码,但我对其中的一处稍微做了改动,如下:
-- 原本生成的代码是:
insert into month_bills_202211
-- 然后被我改成了:
insert into ${targetTable}还记得最开始的实体类中,咱们多添加的那个targetTable属性嘛?在这里会根据该字段的值动态的去操作不同月份的表,接着来写一下Service层的接口和实现类,如下:
// Service接口(目前里面只有一个方法)
public interface IMonthBillsService{
int insert(MonthBills monthBills);
}
// Service实现类
@Service
public class MonthBillsServiceImpl implements IMonthBillsService{
@Autowired
private MonthBillsMapper billsMapper;
@Override
public int insert(MonthBills monthBills){
// 获取要插入数据的表名
TableTimeUtils.getDataByTable(monthBills);
// 返回插入数据的状态
return billsMapper.insertSelective(monthBills);
}
}在service层目前仅实现了一个插入数据的方法,其中的逻辑也非常简单,仅仅在调用Dao层的插入方法之前,获取了一下当前这条数据要插入的表名,最后来看看Controller/API层,如下:
@RestController
@RequestMapping("/bills")
publicclass MonthBillsAPI{
@Autowired
private IMonthBillsService billsService;
// 账单结算的API
@RequestMapping("/settleUp")
public String settleUp(MonthBills monthBills){
// 设置账单交易时间为当前时间
monthBills.setBillDate(newDate(System.currentTimeMillis()));
// 使用UUID随机生成一个流水号
monthBills.setSerialNumber(monthBills.getMachineSerialNo()
+System.currentTimeMillis());
// 调用新增账单数据的service方法
if(billsService.insert(monthBills)>0){
return">>>>账单结算成功<<<<";
}
return">>>>账单结算失败<<<<";
}
}在API层主要对外提供了一个账单结算的接口,这里为了方便测试,所以对于请求方式的处理就没那么严谨了,在调用该接口后,会先获取一下当前系统时间作为账单时间,接着会随机生成一个UUID作为流水号,最后就会调用service层的insert()方法。
到这里为止就搭建出了一个最简单的
WEB接口,接着来做一个小小的测试,这里为了方便就不用专门的PostMan工具了,就通过浏览器简单的调试一下,接口如下:http://localhost:8080/bills/settleUp?billsInfo=白玉竹子*3:9999.999&payMoney=9999.999&machineSerialNo=NF-002-X
最终测试效果图如下:
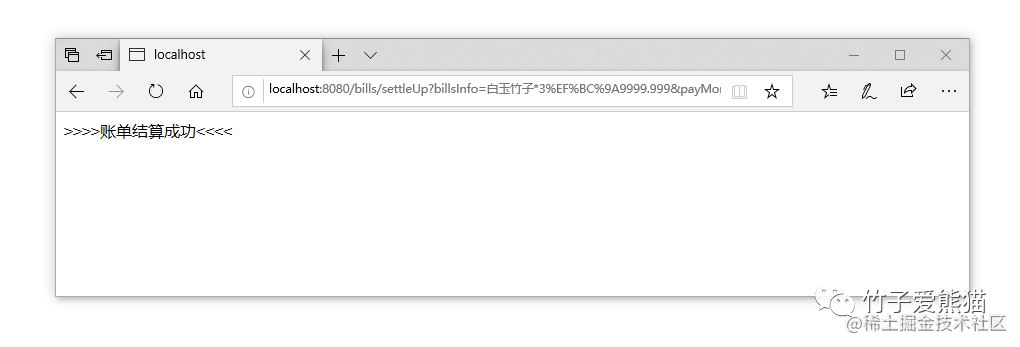
动态插入
效果很明显,确实做到了咱们需要的效果,接着来看看控制台输出的SQL日志,如下:

控制台insert日志
主要可以观察到,原本xml中的动态表名,最终会根据月份被替换为具体的表名,最后再来看看数据库中的表是否真正插入了数据,如下:
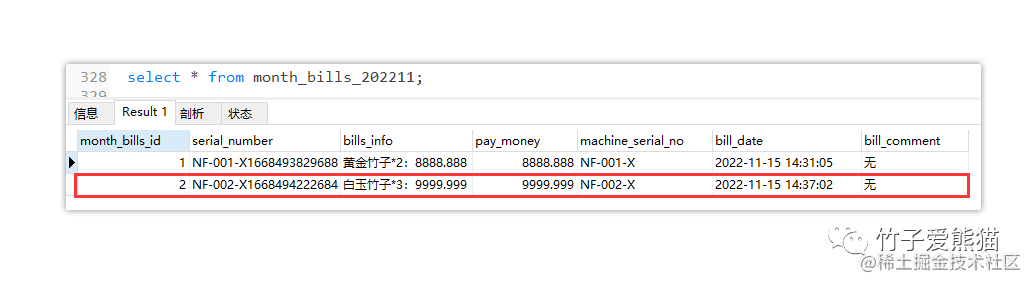
数据库的表数据
因为之前测试过一次,因此表中早有了一条数据,主要观察第二条,的确是咱们刚刚测试时插入的数据,这也就意味着咱们按月动态插入的需求已经实现。
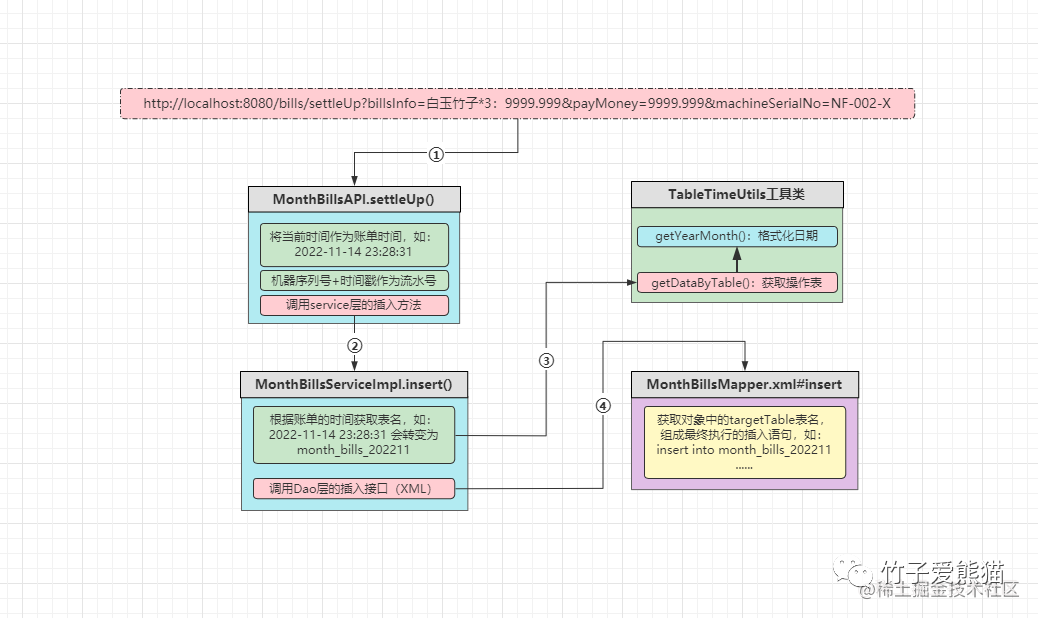
执行流程
-
• ①客户端调用结算接口,传入相关的账单数据,即账单详情、账单金额、收银机器。
-
• ②
API层会先获取当前系统时间作为账单交易的时间,然后调用Service层的插入方法。 -
• ③
Service层会先根据账单交易时间,获取到数据具体要插入的表名,接着调用Dao层接口。 -
• ④
Dao层会根据上层传递过来的表名,生成具体的SQL语句,然后执行插入数据的操作。
三、按月分表后要解决的问题
上述已经将最基础的需求做了简单实现,那么接着再分析一下这些月份账单表还会有哪些需求呢?
-
• ①除去最基本的新增操作外,还会有删除、修改、查询账单的需求。
-
• ②一般账单表中的流水数据,都会支持按时间进行范围查询操作。
上述这两个需求会是账单表中还会存在的操作,对于第一点也比较容易实现,就是要求客户端在修改、删除、查询数据时,都必须携带上对应的时间,一般客户端的修改、删除操作都是基于先查询出数据的基础之上的,而一般查询数据都会按照月份进行查询,或者根据流水号进行查询。
3.1、根据流水号查询数据
还记得前面对于流水号的设计嘛?前面没有太过说明,这里咱们单独拧出来聊一聊:
setSerialNumber(monthBills.getMachineSerialNo()+System.currentTimeMillis());这里使用了收银机器序列号+时间戳作为账单流水号,因为同一台机器在同一时间内,绝对只能对一个账单进行结算,所以再结合递增的时间戳,就能够得到一个全局唯一的流水号。System.currentTimeMillis()获取到的时间戳是13位数字,会放在机器序列号的后面,那接下来如果客户端要根据流水号查询账单数据,又该如何定位具体的表呢?首先需要在工具类中撰写一个新的方法:
// 根据流水号得到表名
public static void getTableBySerialNumber(MonthBills monthBills){
// 获取流水号的后13位(时间戳)
String timeMillis= monthBills.getSerialNumber().
substring(monthBills.getSerialNumber().length()-13);
// 将字符串类型的时间戳转换为long类型
long millis=Long.parseLong(timeMillis);
// 调用getYearMonth()方法获取时间戳中的年月
String yearMonth= getYearMonth(newDate(millis));
// 用表的前缀名拼接年月,得到最终要操作的表名
monthBills.setTargetTable(tablePrefix + yearMonth);
}上面这个方法实际上很简单,就是先解析流水号中的时间戳,然后根据时间戳得到具体的年月,最后拼接表的前缀名,得到最终需要操作的表名,接着来写一下Dao层代码,如下:
<!-- 在MonthBillsMapper中多定义一个接口: -->
<!-- MonthBills selectBySerialNumber(MonthBills record); -->
<!-- 定义返回的结果集 -->
<resultMap id="ResultMapMonthBills" type="com.zhuzi.dbMachineSubmeter.entity.MonthBills" >
<constructor >
<idArg column="month_bills_id" jdbcType="INTEGER" javaType="java.lang.Integer" />
<arg column="serial_number" jdbcType="VARCHAR" javaType="java.lang.String" />
<arg column="pay_money" jdbcType="DECIMAL" javaType="java.math.BigDecimal" />
<arg column="machine_serial_no" jdbcType="VARCHAR" javaType="java.lang.String" />
<arg column="bill_date" jdbcType="TIMESTAMP" javaType="java.util.Date" />
<arg column="bill_comment" jdbcType="VARCHAR" javaType="java.lang.String" />
<arg column="bills_info" jdbcType="LONGVARCHAR" javaType="java.lang.String" />
</constructor>
</resultMap>
<!-- 定义字段列表 -->
<sql id="Base_Column_List" >
month_bills_id, serial_number, bills_info, pay_money, machine_serial_no,
bill_date, bill_comment
</sql>
<!-- 编写对应的查询语句,这里依旧是通过 ${targetTable} 动态表名做查询 -->
<select id="selectBySerialNumber" resultMap="ResultMapMonthBills"
parameterType="com.zhuzi.dbMachineSubmeter.entity.MonthBills" >
select
<include refid="Base_Column_List" />
from ${targetTable}
where serial_number = #{serial_number,jdbcType=VARCHAR}
</select>接着来写一下Service层的代码,如下:
// 在IMonthBillsService接口中多定义一个方法
MonthBills selectBySerialNumber(MonthBills monthBills);
// 在MonthBillsServiceImpl实现类中撰写具体的实现
@Override
public MonthBills selectBySerialNumber(MonthBills monthBills){
// 根据流水号获取要查询数据的具体表名
TableTimeUtils.getTableBySerialNumber(monthBills);
// 调用Dao层根据流水号查询数据的方法
return billsMapper.selectBySerialNumber(monthBills);
}这里的实现尤为简单,仅调用了一下前面写的工具类方法,获取了一下要查询数据的动态表名,接着再来写一下API层的接口,如下:
// 根据流水号查询数据的API
@RequestMapping("/selectBySerialNumber")
public String selectBySerialNumber(MonthBills monthBills){
// 调用Service层根据流水号查询数据的方法
MonthBills result= billsService.selectBySerialNumber(monthBills);
if(result !=null){
return result.toString();
}
return">>>>未查询到流水号对应的数据<<<<";
}接着来做一下测试,调用地址如下:
-
•
http://localhost:8080/bills/selectBySerialNumber?serialNumber=NF-002-X1668494222684
测试效果图如下:
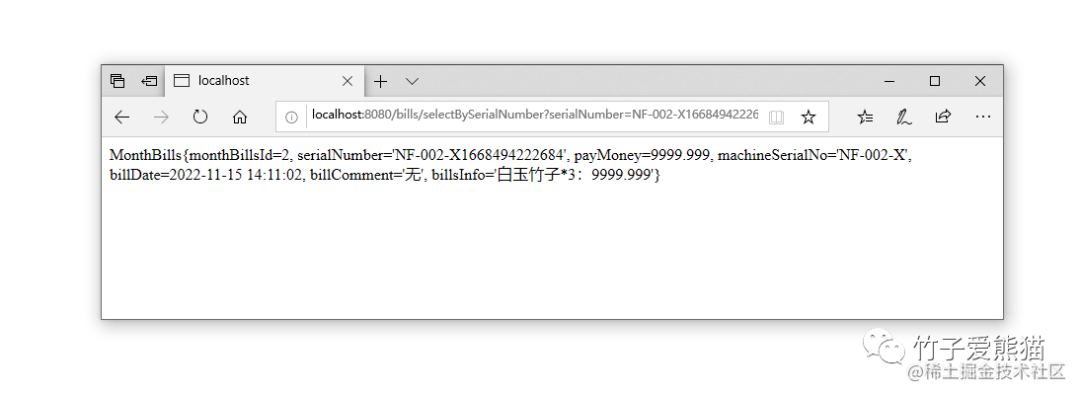
流水号查询
此时会发现,根据流水号查询数据的效果就实现啦,这里主要是得设计好流水号的组成,其中一定要包含一个时间戳在内,这样就能够通过解析流水号的方式,得到具体要查询数据的表名,否则根据流水号查询数据的动作将异乎寻常的困难,因为需要把全部表扫描一次才能得到数据。
设计好根据流水号查询数据后,对于修改和删除的操作则不再重复撰写啦!因为过程也大致相同,就是在修改、删除时,同样先根据流水号定位到具体要操作的表,接着再去对应表中做相应操作即可。
3.2、按时间范围查询数据
按时间范围查询账单的流水数据,这是所有后台管理系统中都支持的功能,在这个项目中也不例外,但想要实现这个功能,则必须要有先实现两个功能:
-
• ①能够根据用户输入的两个时间范围,得到两个日期之间的所有表名。
-
• ②能够根据第①步中得到的表名,生成对应的查询语句,能够在单张表、多张表中通用。
上述这两个需求实际上实现起来也并不难,接着来一起做一下!
3.2.1、得到两个日期之间的所有表名
想要实现这个功能,那必然需要再在工具类中撰写一个方法,如下:
// 获取按时间范围查询时,两个日期之间,所有月份账单表的表名
public static List<String> getRangeQueryByTables(String startTime, String endTime){
// 声明一个日期格式化类
SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM");
// 声明保存表名的集合
List<String> tables =new ArrayList<>();
try{
// 将两个传入的字符日期转换成日期类型
Date startDate= sdf.parse(startTime);
Date endDate= sdf.parse(endTime);
//用 Calendar 进行日期比较判断
Calendarcalendar=Calendar.getInstance();
while(startDate.getTime()<= endDate.getTime()){
// 把生成的月份拼接表前缀名,加入到集合中
tables.add(tablePrefix + monthTL.get().format(startDate));
// 设置日期,并把比对器的日期增加一月
calendar.setTime(startDate);
calendar.add(Calendar.MONTH,1);
// 获取增加后的日期
startDate = calendar.getTime();
}
}catch(ParseException e){
e.printStackTrace();
}
// 返回两个日期之间的所有表名
return tables;
}该方法需要传入两个参数,即两个字符串类型的时间,接着会通过Calendar工具类,对两个日期的大小做判断,当开始日期小于结束日期时,则会直接将表前缀名与年月拼接,得到一张月份账单表的表名,接着会对开始日期加一个月,然后继续重复上一步......,直至得到两日期之间的所有表名。
3.2.2、根据表名集合生成对应的SQL语句
想要实现这个功能其实也非常简单,只需要做一堆判断即可,再在工具类中写一个方法:
// 根据日期生成SQL语句的方法
public static String getRangeQuerySQL(String startTime, String endTime){
// 先获取两个日期之间的所有表名
List<String> tables = getRangeQueryByTables(startTime, endTime);
// 提前创建一个字符串对象保存SQL语句
StringBuffer sql=new StringBuffer();
// 如果查询的两个日期是同一张表,则直接生成 BETWEEN AND 的SQL语句
if(tables.size()==1){
sql.append("select * from ")
.append(tables.get(0))
.append(" where bill_date BETWEEN '")
.append(startTime)
.append("' AND '")
.append(endTime)
.append("';");
// 如果本次范围查询的两个日期之间有多张表
}else{
// 则用for循环遍历所有表名
for(String table : tables){
// 对于第一张表则只需要查询开始日期之后的数据
if(table.equals(tables.get(0))){
sql.append("select * from ")
.append(table)
.append(" where bill_date > '")
.append(startTime)
.append("' union all ");
}
// 对于最后一张表只需要查询结束日期之前的数据
elseif(table.equals(tables.get(tables.size()-1))){
sql.append("select * from ")
.append(table)
.append(" where bill_date < '")
.append(endTime)
.append("';");
// 对于其他表则获取所有数据
}else{
sql.append("select * from ")
.append(table)
.append("' union all ");
}
}
}
// 返回最终生成的SQL语句
return sql.toString();
}这个方法看起来似乎有些长,但其实功能也非常简单,如下:
-
• ①如果两个日期在一个月内,则生成
BETWEEN AND的查询语句。 -
• 如果两个日期间隔了多月,则用
for循环遍历前面得到的表名:-
• 如果是第一张表,则只需要查询开始日期之后的数据,再用
union all拼接后面的语句。 -
• 如果是最后一张表,则只需要查询结束日期之前的数据,以
;分号结尾即可。 -
• 如果是中间的表,则查询对应的所有数据,接着继续用
union all拼接其他语句。
-
接着做个简单的小测试,效果如下:
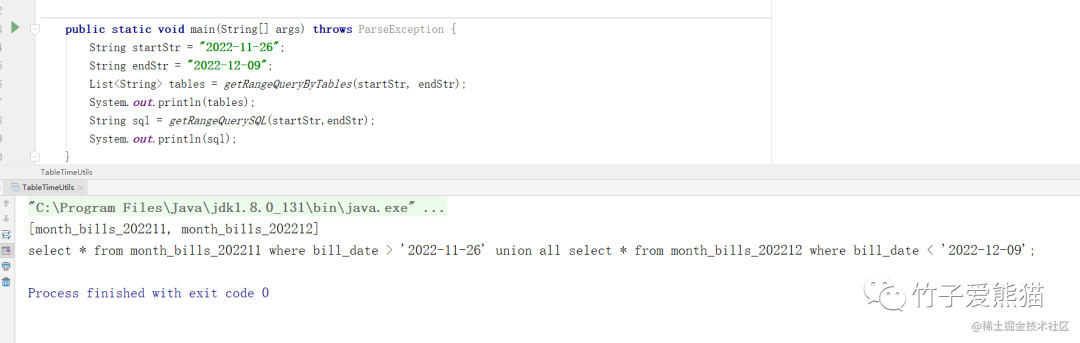
SQL生成
很明显,通过这两个方法,可以实现最初咱们提出的两个需求,实现这两个基础功能后,接着套入到前面的项目中~
3.2.3、实现按时间做范围查询的API接口
依旧按照之前的步骤,先定义Dao层的接口和.xml文件,如下:
// 定义一个返回多条数据的接口
List<MonthBills> rangeQueryByDate(@Param("sql") String sql);<select id="rangeQueryByDate" resultMap="ResultMapMonthBills"
parameterType="java.lang.String" >
${sql}
</select>主要观察xml文件中的代码,因为这里需要实现自定义SQL的执行,所以将SQL语句的生成工作放在了外部完成,在xml中仅需将对应的SQL语句发给MySQL执行,并接收返回结果即可,接着来写一下Service层的接口和实现:
// 在IMonthBillsService接口中多定义一个方法
List<MonthBills> rangeQueryByDate(String startTime, String endTime);
// 在MonthBillsServiceImpl实现类中撰写具体的实现
@Override
public List<MonthBills> rangeQueryByDate(String startTime, String endTime){
// 获取范围查询时的SQL语句
String sql=TableTimeUtils.getRangeQuerySQL(startTime,endTime);
return billsMapper.rangeQueryByDate(sql);
}其实核心工作已经在之前的工具类中完成了,这里仅需调用工具类中,生成两个日期之间的查询语句即可,接着再写一下API层的对外接口,就大功告成啦!如下:
// 按照范围查询两个日期之间的所有账单数据
@RequestMapping("/rangeQueryByTime")
public String rangeQueryByTime(@RequestParam("start") String start,
@RequestParam("end")String end){
// 调用Service层根据流水号查询数据的方法
List<MonthBills> bills = billsService.rangeQueryByDate(start, end);
if(bills !=null){
return bills.toString();
}
return">>>>指定的日期中没有账单数据<<<<";
}在这里面仅仅只是调用了Service层的方法而已,接下来测试一下,测试地址为:
-
•
localhost:8080/bills/rangeQueryByTime?start=2022-11-01&end=2022-11-30
最终效果如下:
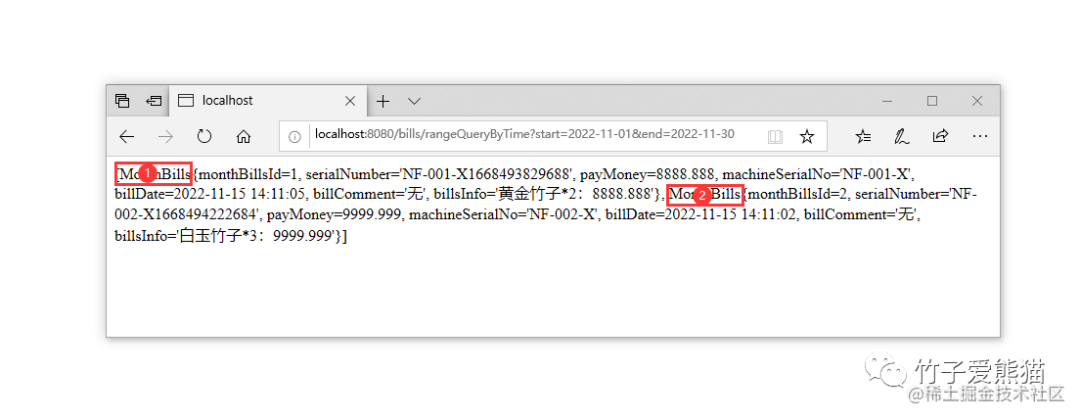
范围查询
因为我表中就两条数据,所以就做了一个单月表的测试,这里单月账单表的数据查询无误,大家也可以再建立一张其他月份的账单表,效果也是照样没有问题的~
3.2.4、按时间范围查询数据小结
其实这里的做法仅仅只是为了给大家演示效果,之前的实际业务中远比这更加复杂,因为每张月份账单表会有上千万条数据,不可能一次性查询几张、几十张的月份账单表,这样对于网络、资源的开销太大。
实际业务中,一方面会限制查询的日期范围,最多只允许客户查询近六月的账单流水。另一方面还会结合数据分页,也就是每页仅显示
20条数据,随着用户的翻页动作触发后,才会对每张不同的月份账单表做查询。
对于这种会批量查询所有账单表的业务,基本上是查询一些流水交易金额的统计数据,而且也仅是提供给后台系统操作,用于定时跑批去生成统计数据,如近一周、一月、一季、半年、一年的交易金额、账单总量.....等这类需求。
这里给大家实现这个需求的目的在于:让大家理解按月做了水平分表后,该如何查询多张表的数据。
四、库内分表篇总结
不过一般对于库内分表的场景会很少用到,毕竟库中只有某些表的数据量较大时,才会选用这种方案,如果整库的数据量较大、访问压力较高,则会直接采用分库方案。
其实库内分表除开本文讲解的方式外,大家通过整合Sharding-JDBC框架来实现会更加轻松,但那样会导致依赖变多,所以如果你项目中不需要用到太多的分表,则可采用本文这种方式实现。
主从复制中数据同步原理与优化
一、主从复制架构概述
但凡提高可用、高性能、高稳定这些词汇,必然会牵扯到集群、主从架构的概念,如MQ、Redis、ES、MongoDB、Zookeeper.....任何技术栈中都会有,而MySQL中同样不例外,官方也提供了主从架构的支持,通过调整多个MySQL节点的配置信息,即可将一个节点的数据同步给另一个或多个节点,但这种方式同步的是所有数据!
有人也许会疑惑:为什么要同步所有数据呀?难道不能对数据作分片,不同的节点同步不同的数据嘛?这实际上属于历史遗留性的问题,在早些年由于分布式技术还未完善,所以大多技术栈在设计高可用方案时,基本上都选用主从架构,也就是各节点之间都同步所有数据,从而对外提供高可用的保障。
主从架构中必须有一个主节点,以及一个或多个从节点,所有的数据都会先写入到主,接着其他从节点会复制主节点上的增量数据,从而保证数据的最终一致性,使用主从复制方案,可以进一步提升数据库的可用性和性能:
-
• ①在主节点宕机或故障的情况下,从节点能自动切换成主节点的身份,从而继续对外提供服务。
-
• ②提供数据备份的功能,当主节点的数据发生损坏时,从节点中依旧保存着完整数据。
-
• ③可以基于主从实现读写分离,主节点负责处理写请求,从节点处理读请求,进一步提升性能。
但无论任何技术栈的主从架构,都会存在致命硬伤,同时也会存在些许问题需要解决:
-
• ①硬伤:木桶效应,一个主从集群中所有节点的容量,受限于存储容量最低的哪台服务器。
-
• ②数据一致性问题:由于同步复制数据的过程是基于网络传输完成的,所以存储延迟性。
-
• ③脑裂问题:从节点会通过心跳机制,发送网络包来判断主机是否存活,网络故障情况下会产生多主。
上述提到的三个问题中,第一个问题只能靠加大服务器的硬件配置解决,第二个问题相对来说已经有了很好的解决方案(后续讲解),第三个问题则是部署方式决定的,如果将所有节点都部署在同一网段,基本上不会出现集群脑裂问题。
上面简单了解了主从复制架构的一些基本概念后,接着来聊一聊MySQL中的主从复制。
二、MySQL中的主从复制技术
MySQL本身提供了主从复制的技术支持,所以无需通过第三方技术来协助实现,MySQL数据复制的过程就是基于该binlog日志完成的,但MySQL复制数据的过程并非同步,而是异步的方式,啥是同步、异步方式呢?如下:
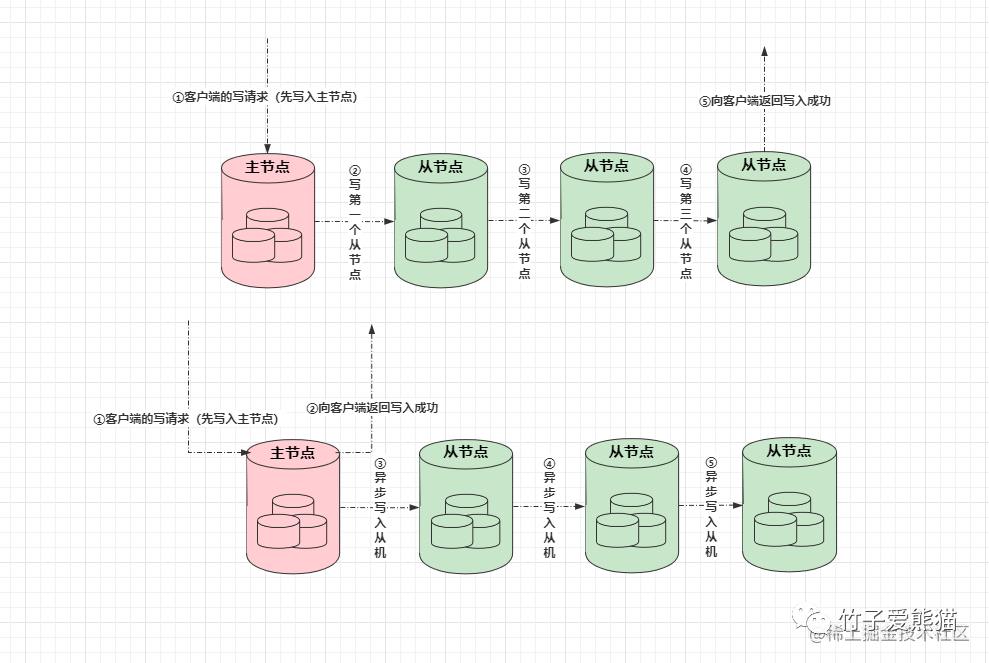
同步复制和异步复制
上图中,上面是同步复制的过程,也就是当主节点接收到一个客户端的写请求后,先会往自身写入数据,接着会去要求其他从节点也写入数据,当从节点的数据写入完成后,最终才会向客户端返回写入成功。
而异步复制的过程恰恰相反,当主节点接收到一个客户端的写请求后,先会往自身写入数据,自身数据写入成功后,就会立马向客户端返回写入成功的信息,对于从节点的数据,会在其他的时间内再异步复制过去。
对比同步复制和异步复制的过程,显然同步复制的过程极其影响效率,因为需要等到所有从节点写完之后才返回数据。而异步复制的过程则快很多了,基本和MySQL单机版的写入效率差距不大,只要主节点自身写入成功,则立马返回写入成功,性能自然会快很多,而MySQL主从的数据复制,就是基于这种异步方案实现。
有人也许会好奇:同步复制方案效率那么低,一般没有谁用吧?实则不然,比如大名鼎鼎的
Zookeeper中,就采用的是同步复制方案,这是为什么呢?因为同步复制方案能够确保数据100%不丢失,和数据的强一致性。如果采用异步复制方案,那么当一个数据写入后,主节点立马宕机或故障了,从机顶替上线,这时的从机是不一定有最新数据的,而同步方案则不需要担心这个问题(Zookeeper采用的是半同步模式)。
2.1、MySQL数据同步的原理
前面搞清楚了MySQL同步数据的方式,接着聊一聊它的同步原理,前面简单提到过一句:MySQL是基于它自身的Bin-log日志来完成数据的异步复制,因为Bin-log日志中会记录所有对数据库产生变更的语句,包括DML数据变更和DDL结构变更语句,数据的同步过程如下:
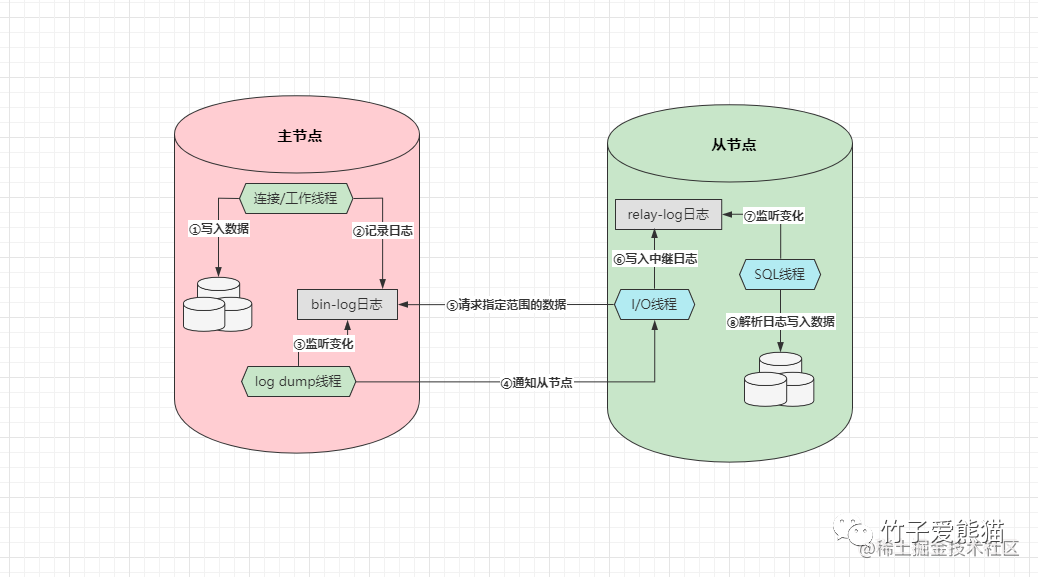
主从复制原理
上述即是主从同步数据的原理图,但在讲解之前先来了解一下两种数据同步的方式:
-
• 主节点推送:当主节点出现数据变更时,主动向自身注册的所有从节点推送新数据写入。
-
• 从节点拉取:从节点定期去询问一次主节点是否有数据更新,有则拉取新数据写入。
那MySQL究竟采用的是什么方式呢?其实是「从拉」的方案,但对其稍微做了一些优化,传统的「从拉」方案是需要从节点一直与主节点保持长连接,从节点定时或持续性的对主节点做轮询,查看主机的数据是否发生了变更,而MySQL的数据同步原理如下:
-
• ①客户端将写入数据的需求交给主节点,主节点先向自身写入数据。
-
• ②数据写入完成后,紧接着会再去记录一份
Bin-log二进制日志。 -
• ③配置主从架构后,主节点上会创建一条专门监听
Bin-log日志的log dump线程。 -
• ④当
log dump线程监听到日志发生变更时,会通知从节点来拉取数据。 -
• ⑤从节点会有专门的
I/O线程用于等待主节点的通知,当收到通知时会去请求一定范围的数据。 -
• ⑥当从节点在主节点上请求到一定数据后,接着会将得到的数据写入到
relay-log中继日志。 -
• ⑦从节点上也会有专门负责监听
relay-log变更的SQL线程,当日志出现变更时会开始工作。 -
• ⑧中继日志出现变更后,接着会从中读取日志记录,然后解析日志并将数据写入到自身磁盘中。
阅读上述流程后,相信大家能感受出MySQL主从复制时做的优化,在主从数据同步的过程中,从节点并不会无限制的询问主机,这样实在太影响效率了,在MySQL中引入了惰性的思想,只有当主节点真正出现数据变更时,才会通知从节点拉取数据!
2.2、从节点拉取的数据到底是什么格式?
前面从整体角度出发,简单讲述了主从同步数据的过程,但从节点复制的数据到底是什么格式的呢?这里要根据主节点的Bin-log日志格式来决定,它会有三种格式,如下:
-
•
Statment:记录每一条会对数据库产生变更操作的SQL语句(默认格式)。 -
•
Row:记录具体出现变更的数据(也会包含数据所在的分区以及所位于的数据页)。 -
•
Mixed:Statment、Row的结合版,可复制的记录SQL语句,不可复制的记录具体数据。
一般在搭建主从架构时,最好将Bin-log日志调整为Mixed格式,因为这种方式绝对不会出现数据不一致性,毕竟默认的Statment格式会导致主从节点间的数据出现不一致,例如:
insert into `zz_users` values(11,"棕熊","男","3333",now());当主节点插入数据时,使用了sysdate()、now()....这类函数时,主节点会取自身的系统时间插入数据,而当从节点拉取SQL执行时,则会获取从节点的系统时间插入数据,因为主/从节点执行SQL语句绝对不可能发生在同一时间,因此就会导致主/从节点中,同一条数据的时间不一致。
而将
Bin-log日志调整为Mixed格式后,就不会再出现这样的问题,因为对于这种不可复制的记录,会直接选择记录具体变更过的数据到日志中,当从节点读取数据写入时,则可以直接将数据放到磁盘对应的位置中即可。
那为什么不选择Row格式来作为数据同步时的格式呢?这种方式同步数据不需要经过SQL解析过程,只需直接将数据放到磁盘的具体位置即可,但这种方式会让主节点的I/O负载直线拉高,在传输时也会大量占用网络带宽,因此一般都不会选择Row作为同步复制时的格式。
2.3、基于主从模型的不同架构
前面将最基本的主从复制原理和细节讲清楚了,虽然MySQL官方只提供了最基本的主从复制技术的支持,但这并不妨碍咱们将其玩出花来,目前业内可以基于主从机制实现:一主一从/多从、双主/多主、多主一从、级联复制四种架构,下面详细聊一聊每种架构。
2.3.1、一主一从/多从架构
一主一从或一主多从,这是传统的主从复制模型,也就是多个主从节点组成的集群中,只有一个主节点,剩余的所有节点都为其附属关系,大致如下:
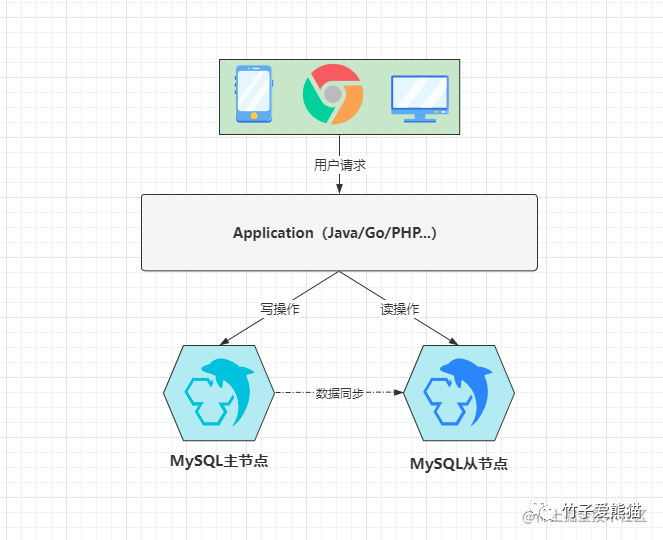
主从读写分离
这种架构中,从节点的所有数据都源自于主节点,如上图所示,为了充分的利用好这种架构,一般都会基于它实现读写分离,也就是将客户端的写请求发给主节点处理,将客户端的读请求发给从节点处理。这种模式下,相较于单机节点而言,能够在性能上进一步提升,因为读写请求都被分发到了不同的节点处理,所以吞吐量至少会提升50%以上。
2.3.2、双主/多主架构
上述的一主一从/多从架构,更加适用于一些读大于写的场景,因为这类项目中,读请求的数量远超出写请求,因此将读操作分发到从库上,能够大大降低主库的访问压力,但如若你的项目中读写请求的比例对半开,同时整体的并发量也不算低,至少超出了单库的承载阈值,这时就可以选用双主/多主架构,如下:
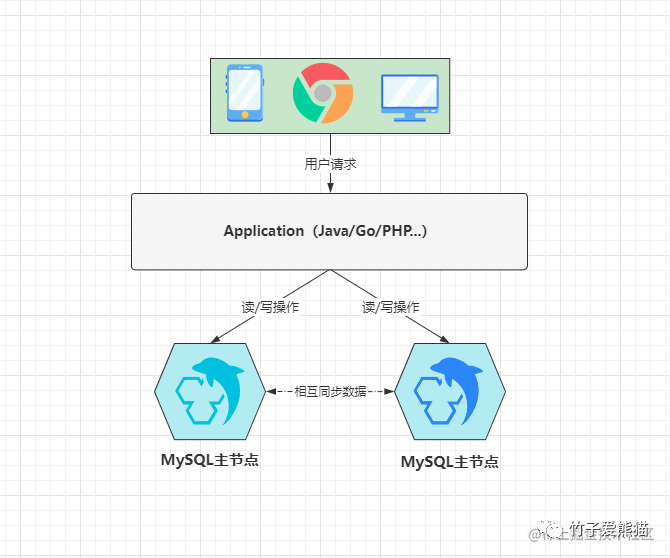
双主双写架构
上图是一个典型的双主架构,这里有两个MySQL节点,它们都是主库,也都属于对方的从库,也就是两者之间会相互同步数据,这时为了防止主键出现冲突,一般都会通过设置数据库自增步长的方式来防重,通常会将两个节点的自增步长设为2,然后为两个节点分配自增初始值1、2,最终会出现如下效果:
-
•
DB1:1、3、5、7、9、11、13、15、17....... -
•
DB2:2、4、6、8、10、12、14、16、18......
在两个库上插入数据时,各自会以上述序列进行主键的递增,接着两个节点会各自同步对方的数据,这也就意味着双方都具备完整的数据,因此无论是:简单读、简单写、批量写、多表查......等任何类型的操作,都可以随便分发到任意节点上处理。
2.3.3、多主一从架构
除开上述两种主从架构的基本玩法外,面对于不同场景时也会有一些新奇玩法,比如面对于一些写大于读的场景,不管是一主多从、还是多主的方式,似乎都无法很好的解决这个问题,因此要处理这类问题时,可以选用多主一从架构,啥意思呢?如下图:
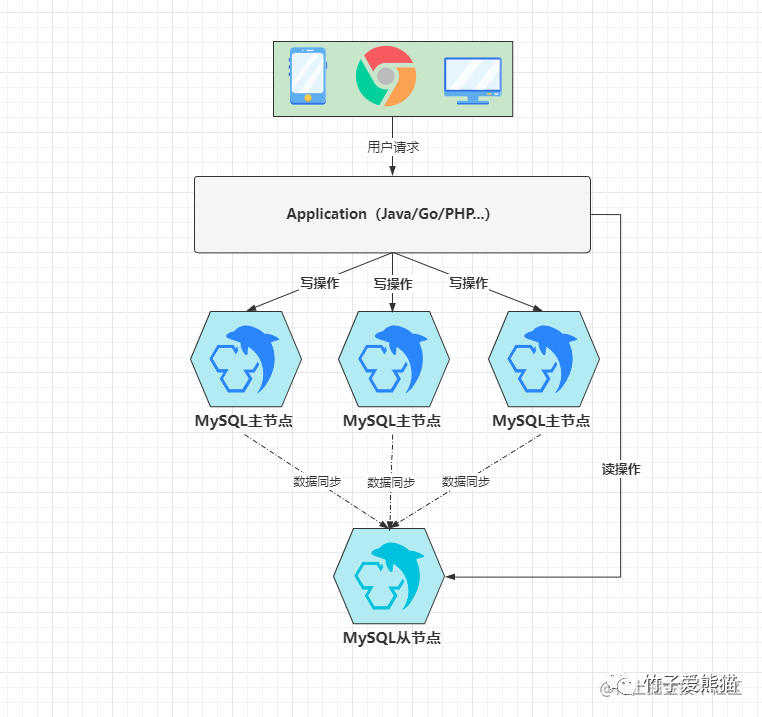
多主一从架构
因为这种架构要解决写大于读造成的性能瓶颈,所以这里会采用多主来承载客户端的写请求,同时为了做好主键防重,也需要设置数据库自增步长和初始值,这里有三个主节点,因此自增步长为三,初始值分别为1、2、3,最终三个主节点中的数据如下:
-
•
DB1:1、4、7、10、13、16..... -
•
DB2:2、5、8、11、14、17..... -
•
DB3:3、6、9、12、15、18.....
而这三个主节点都会具备一个相同的从节点,也就是只有一个从库,它会负责同步所有主库的数据,这也就意味着从库中会具备三个主库的完整数据,这样做有什么好处呢?通过多个主节点解决了写请求导致压力过大的问题,同时从库中还有完整数据,因此也不会由于拆分了主库而影响读操作。
2.3.4、级联复制架构
级联复制架构是一种特殊的主从结构,之前聊到的几种主从结构都只有两层,但级联复制架构中会有三层,关系如下:
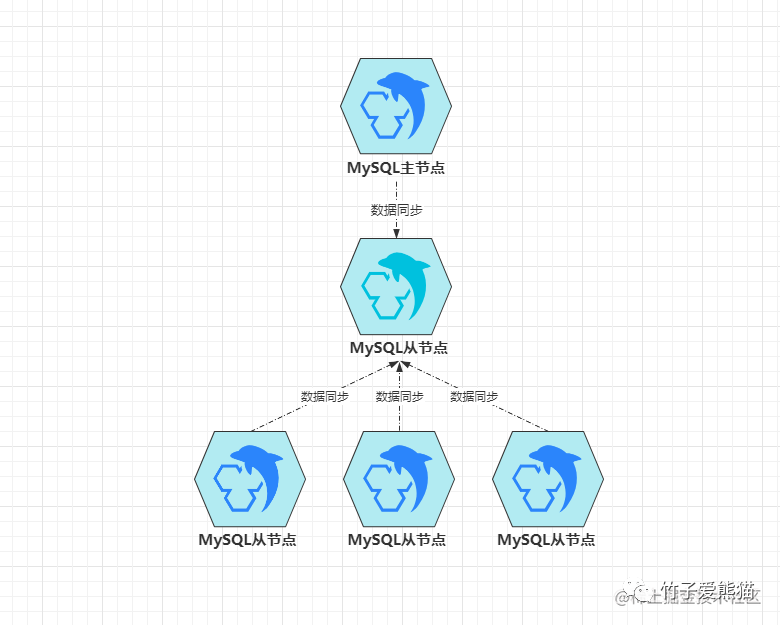
级联复制架构
也就是在级联复制架构中,存在两层从库,这实际上属于一主多从架构的升级版,毕竟如果一个主节点存在多个从节点时,多个从节点都会同时去主节点拉取新数据,如果数据量较大,就会导致主节点的I/O负载过高,因此这种级联复制架构要解决的问题,也就是多个从库会对主库造成太大压力的问题。
这个过程中,第一层从库只有一个节点,它会负责从主库上拉取最新的数据,接着第二层的多个从库会从上一层的从库中拉取数据,这样能够这在从库较多的情况下,尽量降低数据同步对主节点的性能影响。
2.3.5、主从架构小结
前面聊完了四种主从架构的模式,下面做个简单的小总结:
-
• 一主多从架构:适用于读大于写的场景,采用多个从库来分担数据库系统的读压力。
-
• 多主架构:适用于读写参半的场景,采用多个主库来承载数据库系统整体的读写压力。
-
• 多主一从架构:适用于写大于读的场景,采用多个主库分担写压力,单个从库承载读压力。
-
• 级联复制架构:适用于读大于写的场景,采用单个从节点来分担从库对主库造成的
I/O压力。
三、主从复制数据的方式
在第二阶段时,曾简单的聊过两种主从复制数据的方式,即同步与异步方式,但MySQL中一共支持四种数据同步方式,即:异步复制、同步复制、半同步复制、增强式半同步复制/无损复制,其中对于同步、异步复制已经在前面聊了,接着再聊一聊后面两者。
3.1、半同步式复制
虽然同步复制的模式能够确保数据的强一致性,但由于其太影响写入效率,因此很少有主从机制会采用这种模式同步数据,包括MySQL默认也是采用异步复制方案,不过异步模式虽然性能不错,但特殊情况下会导致数据出现丢失,因此也会存在风险,这时半同步模式就出现了!
半同步模式:当客户端的数据到来时,会先写入到主节点中,接着主节点会向所有从节点发送一个写入数据的请求,但半同步模式中无需等待所有从节点全部写入完成后再返回,而是只要有一个从节点写入成功并返回了
ACK,则会直接向客户端返回写入成功,这样既能够保证性能,又能够确保数据不丢失。
同时为了避免网络延迟造成主库长时间收不到从库的ACK,因此在配置半同步式复制时,会有一个rpl_semi_sync_master_timeout参数来控制超时时间,其默认值是10000ms/10s,如若主库在10s内依旧未收到从库的ACK,则会将复制模式切换成异步模式,切成异步模式后,会在后续网络正常后再次切回半同步模式。
但实际上这种只要求一个节点返回
ACK的半同步模式,依旧存在数据丢失风险,所以Zookeeper中,是要求收到一半从节点以上的ACK时,也就是一半从节点以上写入数据成功后,才会向客户端返回写入成功,至于为什么是一半写入成功后就返回,具体原因跟其内部的ZAB一致性协议有关。
3.2、增强式半同步复制/无损复制
增强式半同步复制也被称为无损复制,这是MySQL5.7版本中引入的一种新技术,在MySQL5.7版本中就不存在普通的半同步模式了,当将复制模式配置成半同步时,默认就会选用无损复制模式,和之前传统的半同步复制区别在于:从after-commit变成了after-sync,啥意思呢?
after-commit:主库在未收到从库的ACK之前,虽然不会给客户端返回写入成功,但本质上在MySQL中会提交事务,也就是主库中的其他事务是可以看见对应数据的,当此时出现宕机时,就会导致旧主上能查询出的数据,在新主(原本的从库)上无法查询出来了。after-sync:当主库未收到从库的ACK之前,也不会在主库上提交事务,也就是保证了主从节点的数据强一致性,解决了after-commit中存在的问题。
其实简单来说,无损复制中等待ACK的动作会放到事务提交前进行,而传统半同步复制中,等待ACK的动作会放到事务提交后进行。两者之间的区别就在于:对主从节点的数据严格性不同,一般情况下,无损复制会比传统半同步复制开销更大一些,因为事务迟迟不提交,会导致对应的锁资源不会主动释放,其他需要获取对应锁资源的事务只能阻塞等待,这会造成主库的整体性能出现一定影响。
上面聊完了主从复制的四种数据同步方式,接着来聊一聊MySQL5.6中,两种新的复制特性,即从库数据的延迟复制,和从库数据的并行复制。
3.3、延迟复制
延迟复制通常用于一些特殊场景,它可以支持从库数据的延迟同步,也就是当从库上的I/O线程,将主库的Bin-log日志请求回来后,从节点的SQL线程并不会立刻解析日志执行,而是等待一段时间后再解析日志执行,这个等待的时间可以由开发者来配置,一般建议设为3~6小时之间。
那延迟复制的好处在于什么呢?可以防止误删操作,如若在主库上不小心误删了大量数据、表、库或其他数据库对象,因为从库并不是立即执行同步过去的记录,因此可以及时通过从节点上的数据回滚数据。除此之外,也能对一些线上
Bug进行实时观测,比如一个无法复现的故障问题发生时,如果发现时还在配置的延迟复制时间内,则可以去到从库上观察。
但开启延迟复制,基本上就无法再对主从架构做读写分离,毕竟很少有业务能够接受3~6小时的数据延迟,因此延迟复制的技术,通常都仅适用于一些作为备库的节点使用。
3.4、并行复制
并行复制是在MySQL5.6加入的新技术,但实际上5.6版本中的支持并不完善,直到5.7版本中才真正实现了并行复制技术,但想要说清楚并行复制,则得先弄懂组复制的概念,想要弄明白组复制,在此之前还得理解GTID复制的概念,所以并行复制技术会比前面几个概念难啃一些。
3.4.1、GTID复制
GTID复制依旧是5.6版本中的新功能,在传统的主从架构中,当需要发生主从切换时,需要开发/运维人员手动找到Bin-log的POS同步点,然后执行change master to [new-master-pos]命令,将其他从节点指向新主库,但每个从节点可能同步数据的进度都不一致,因此每个从节点都需要去找到它上次的POS点,然后指向新主库,这个工作是不是听起来就比较繁杂?答案是Yes,不过到了MySQL5.6版本后,开启了GTID复制后,则无需手动寻找POS点!
GTID(Global Transaction ID)也就是全局事务标识符的意思,它由节点UUID+事务ID两部分组成,MySQL在第一次启动时都会利用UUID随机生成一个server_id,MySQL会对每一个写事务都分配一个顺序递增的值作为事务ID,而GTID则是由这两玩意儿组成的,格式为server_uuid:trx_id。
当主库的事务有了这个全局事务标识后,再发生主从切换时就无需手动寻点了,仅需要执行change master to master_auto_position = 1这条命令即可,它会自动去新主库上寻找数据的同步点,也就是MySQL自身就具备断点复制的功能。
为什么需要用GTID代替POS同步点呢?
因为同一个主从集群中,所有节点加入集群的时间可能会不同,比如下面的这个主从集群:
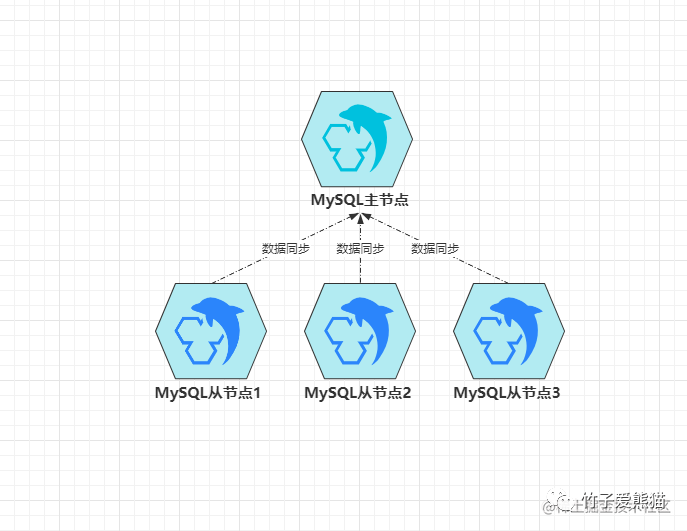
主从集群
假设这个集群中每个节点加入的时间都不一致,如:
-
•
master:日志文件中的同步点POS=1200。 -
•
slave1:日志文件中的同步点POS=1100。 -
•
slave2:日志文件中的同步点POS=800。 -
•
slave3:日志文件中的同步点POS=200。
此时假设master节点宕机或故障了,slave1成为了新主,那么slave2、slave3也应该成为新主slave1的从节点,但此刻问题就来了:原本slave2、slave3的POS同步点是基于master中的日志而言的,但现在主节点变成了slave1,这时slave2、slave3如何去寻找自己在slave1中的POS点呢?显然MySQL无法自己完成该工作,因此需要人工指定同步点才行。
而
GTID出现的原因,就是为了解决上述这个问题,但具体怎么解决的呢?接下来重点聊一聊这个。
GTID的工作过程
-
•
master在更新数据时,会为每一个写事务分配一个全局的GTID,并记录到Bin-log中。 -
•
slave节点的I/O线程拉取数据时,会将读到的记录写到relay-log中,并设置gtid_next值。 -
•
slave节点的SQL线程执行前,会读取gtid_next值得知接下来该解析哪条日志并执行。 -
•
slave节点的SQL线程在执行时,会先比对自身的Bin-log日志中是否有对应的GTID:-
• 有:意味着该
GTID对应的事务已经执行过了,slave会自动忽略掉这条记录。 -
• 没有:
SQL解析该GTID对应的relay-log记录并执行,再将GTID记录到Bin-log。
-
GTID自动寻找同步点的原理
前面得知了GTID的大致工作过程,开启GTID后,从库会基于它来复制主库的数据,此时发生了主从切换,假设这时主从集群中有多个从节点,MySQL首先会选择距离master的GTID最近的从节点作为新主,然后将其他从节点转变为新主的从库,其他从库会根据自身gtid_next值,去新主的日志文件中做对比,然后找到各自的同步点,继续从新主中复制数据。
因为
MySQL挑选的是和旧主GTID值,最接近的从节点作为新主,也就意味着作为新主的从节点,绝对会比其他从节点的数据要完善,因此新主中的GTID值也是最大的!同时,每个从节点中都存在一个gtid_next值,记录着自身下一次要同步数据的GTID值,此时剩下的从节点就可以根据该值,直接去新主中寻找到自己的同步点位置,从而避免了之前那种手动介入的尴尬场景出现。
不过由于GTID复制是基于事务来实现的,这也就代表不支持事务的存储引擎无法使用这种机制,在之前的章节中也聊过,MySQL众多存储引擎中,基本上只有InnoDB支持事务,所以GTID机制基本上只对InnoDB引擎生效。
3.4.2、组复制
前面阐述的GTID复制则是组复制的实现基础,而组复制则是并行复制的基础,那么什么叫做组复制呢?组复制是指将一组并行执行的事务,全部放入到一个GTID中记录,后续从节点同步数据时,会一次性读取这一组事务解析并执行,与传统的GTID区别如下:
-
• 传统的
GTID值由节点ID+事务ID组成:12EEA4RD6-45AC-667B-33DD-CCC55EF718D:88。 -
• 组复制的
GTID通过逗号分隔:12EEA4RD6-45AC-667B-33DD-CCC55EF718D:89, 12EEA4RD6-45AC-667B-33DD-CCC55EF718D:89-94, ......。
MySQL如何实现事务分组的呢?
看过MySQL源码的小伙伴应该清楚,MySQL提交事务时内部会调用ordered_commit函数来处理相关工作,其函数执行的逻辑流程图如下:
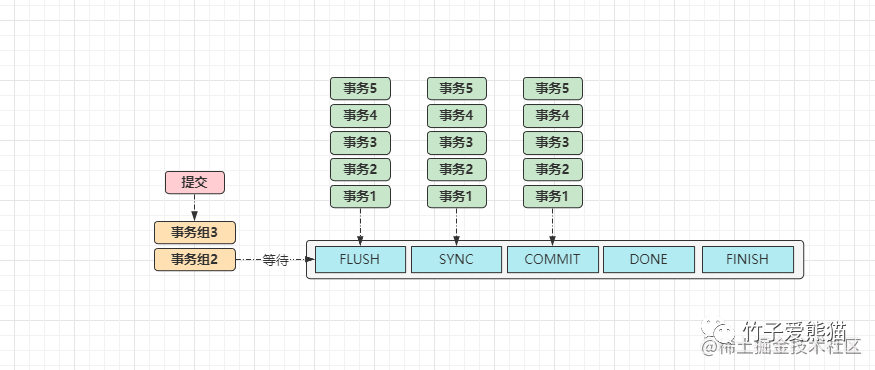
事务组提交原理
当一个事务提交时都会调用ordered_commit函数,首先会将事务加入等待事务组,接着会经过三个核心步骤:FLUSH、SYNC、COMMIT,对应的也会有三个队列,它们三者的工作原理都大致相同:
-
• ①如果某个事务进入
FLUSH队列时,该队列还是空的,则这个事务会担任“队长”的角色。 -
• ②当后续其他事务进入队列时,发现队列不为空,则会将提交工作委托给队长来完成。
-
• ③如上图中的「事务1」则是队长,后续的都是队员,但队长不会无限制等待队员到来:
-
• 从队长加入的时间点开始,当超出
binlog_group_commit_sync_delay规定的时间后,就会进行一次组提交。
-
同一时刻只允许一组事务做这些工作,也就是当有另外一组事务提交时,需要等待上一组事务提交完成。
在做组提交工作时,会将当前事务组的内容记录到Bin-log日志中,同时会将这组事务记录成一个GTID,不同事务之间通过,逗号分隔(实际过程更为复杂,这里只做简单讲解)。
经过上述步骤后,就实现了按事务组去生成
GTID值,这也是后续并行复制的基础。
3.4.3、并行复制
在MySQL5.6之前的版本中,从库同步数据时,所有数据同步工作都是基于单线程完成的,也就是不管主库上的数据是不是多线程并发写入的,从库上只会有一条SQL线程来执行解析执行工作。
到了
MySQL5.6之后,引入了并行复制的思想,但5.6中的并行复制极其鸡肋,基本无人问津,因为是基于库级别的并行复制,也就是一个从节点对应多个主节点时,有几个主节点就开几条SQL线程去解析并写入数据,即多主一从架构中才会用到。
因为官方最初在实现并行复制时,一直纠结锁冲突的问题,所以为了防止并行执行时出现数据冲突,就造出了上面那种库级别的并行复制,为啥要纠结锁/数据冲突呢?比如从库I/O线程在主库中请求了100条记录回去,从库中开100条SQL线程解析并执行这些记录,如果其中有两条记录操作的是同一条数据,就会出现锁冲突问题。
但上述原因不是最主要的,最主要的是并发执行的顺序问题,如果主库上对于一条数据是先改后删,从库在并发执行时,因为多线程执行的无序性,把执行顺序改为了先删后改,这显然就会导致数据冲突,因此变更操作很难实现并行复制。
到了MySQL5.7中,才基于组复制技术实现了真正意义上的并行复制,因为能够在同一时间内提交的事务,绝对是不存在锁冲突的,所以可以开启多条线程同时执行一个组中不同的事务,但这个思想是从MariaDB中照抄过来的~
主库上是咋样并发写入数据的,从库也会开启对应的线程数去并发写入。
在5.7中官方为这种机制命名为enhanced multi-threaded slave,简称MTS机制,同时为了兼容5.6版本中的并行复制,又多加入了一个slave-parallel-type参数:
-
•
DATABASE:默认的并行复制模式,表示基于库级别的来完成并行复制。 -
•
LOGICAL_CLOCK:表示基于组提交的方式来完成并行复制。
但当你想要使用这种并行复制的技术,必须要将版本升级到MySQL 5.7.19才行,因为在此之前的版本中,MTS技术依旧存在不小瑕疵。
并行复制出现的意义是什么?
对于这个问题相信大家都能直接想出来答案,能够在很大程度上提升从库复制数据的速度,也就是能够让从库的数据实时性提升,尤其是无损复制模式中,主节点需要等待从节点的ACK才会真正提交事务,从库使用并行复制后,能够在一定程度上解决从库的复制延迟问题。
不过虽然
5.7中的并行复制,在一定程度上解决了原有的从库延迟问题,但如果一个新的从节点加入集群时,因为要从头开始同步数据,这种并行复制的模式依旧存在效率问题,而到了MySQL8.0中,对于并行复制技术提出了真正的解决之道,也就是基于writeset的MTS技术。
啥叫基于writeset的MTS技术呢?即多个事务之间,只要变更的数据记录没有重叠,也就是操作的数据没有冲突,无需在一个事务组内,也可以支持并发执行,这也是MySQL-MTS技术的最终的完美形态。
四、主从数据一致性的解决方案
主从节点之间的数据一致性问题。通常情况下,对MySQL搭建了主从集群,往往从节点不会只充当备库的角色,为了充分利用已有的资源,都会在主从热备的基础上,采用读写分离方案,将写请求分发给主库、读请求分发给从库处理。
这样的确能够充分发挥从库所在机器的性能,但随之而来的还有一些问题,由于从库需要处理读取数据的请求,但主从节点之间的数据绝对会有一定延时,那对于一些关键性的数据,在主库上修改之后,再去从库上读取,这时就很有可能读取到的是旧数据,即修改前的原数据。
但这种情况对于用户而言显然是无法接受的,比如一个用户将个人信息修改后,然后再次查看时,发现个人信息依旧是修改之前的原数据,这时用户就有可能再次修改,经过反反复复多次修改后,用户发现依旧未生效,大多数情况下都会心里骂一句:“去你*的,乐色系统”!
想要解决上述这种读写分离导致的数据不一致性,主要有四种解决方案:
-
• 业务逻辑做改变、复制方式做更改、数据库架构做调整、引入第三方中间件。
4.1、改变业务逻辑
改变业务逻辑的潜在含义是:对业务做一定更改,比如当用户立即修改数据后,因为在从库读不到数据,所以先显示一个审核状态,这样能够给出用户的反馈,从而避免用户再次重复操作,如:
审核状态
上述是掘金的个人资料,当用户手动更改后,会先显示一个「审核中」的状态,这种方式属于和数据不一致妥协的方案,接受一定的数据延迟,不过这种方式并不适用于一些对数据实时性要求较高的场景。
4.2、更改复制方式
在之前曾聊过MySQL四种数据同步复制的方式,即全同步、异步、半同步与无损复制,MySQL默认会是异步复制模式,即主节点写入数据后会立即返回成功的状态给客户端,这样能够确保性能达到最佳,但如果对实时性要求较高,可以将其改为全同步或半同步模式。
改成全同步的模式能够确保数据
100%不会存在延迟,但性能会因此严重下降,因此半同步是个不错的选择,但如果数据库仅仅是一主一从的架构,那么半同步模式和全同步模式没有任何区别,因为半同步是至少要求一个从库返回ACK,才向客户端返回写入成功,而一主一从架构中只有一个从节点~
不过就算是半同步(无损)复制模式,对比异步复制而言,依旧会导致性能下降较为严重。
4.3、调整数据库架构
如果无法接受主从架构带来的短期数据不一致,那可以升级服务器硬件,并将架构恢复成单库架构,所有读写操作都走单库完成,这就自然不会出现数据不一致问题。但如果升级硬件配置后,无法承载客户端的访问压力时,可将整体架构升级到分库分表架构,制定好合适的分片策略和路由键,每次读写数据都根据业务不同,操作不同的库。
但如果项目的业务规模目前或未来两三年内达不到分库分表的规模,这会导致性能过剩的问题出现,也就是浪费机器性能。
4.4、引入第三方中间件
前面聊到的三种方案,多多少少都存在一些局限性,因为要么接受数据不一致、要么损失性能、要么使用更高规模的架构处理,但这些方案似乎都存在令人不能接受的后患,那有没有一种万全之策来解决这个问题呢?答案是有的,就是引入Canal中间件来监控主节点的Bin-log日志。
在之前讲主从同步数据原理时,曾讲到过,主节点上存在一个
log dump线程会监听Bin-log日志,当日志出现变更时会通知从节点来拉取数据,而Canal的思想也是一样的,会监控主节点的Bin-log日志,当发生变更时,就直接去拉取数据,然后直接推送给从节点写入。
Canal在主从集群的身份就类似于一个中间商,对于主节点而言,它是一个从库,因为Canal会去主库上拉取新增数据。而对于集群中真正的从节点而言,它是一个主库,因为Canal会给其他真正的从节点推送数据。但这种方式也无法做到真正的数据实时性,毕竟Canal监听变更、拉取数据、推送数据都需要时间,这部分的时间开销必然存在,只是它会比从库去主库上拉取,速度会更快一些罢了。
一般企业内部都会引入
Canal来解决数据不一致问题,因为它不仅仅只能解决主从延迟问题,还能解决MySQL-ES、MySQL-Redis.....等多种数据不一致的场景,Canal是由阿里巴巴开源的一项技术,也包括在阿里内部应用也较为广泛。
当然,也可以制定某些敏感数据走主库查询,这样能够确保数据的实时性,但容易模糊读写分离的界限,不过因为不需要引入额外的技术,所以在某些情况下也是个不错的方案。