注: 原文发布于 2017 年,两篇合二为一。未与作者沟通,侵权,立删。
导语: Intel 对 X86 的授权有着极为严格的限制,那么上海兆芯的 X86 芯片技术到底从何而来?ZX-C 目前的短板在哪里?在性能上和 Intel 相差多远呢?

雷锋网按:本文作者铁流,雷锋网首发文章。
在第 18 届中国国际工业博览会上,上海兆芯公司的 ZX-C 处理器获得了金奖。在 2017 年 3 月,更是接连荣获 “2017 年度大中华 IC 设计成就奖”(见图 22)、“第十一届(2016 年度)中国半导体创新产品和技术奖”。在国家十二五科技创新成就展中兆芯的宣传材料显示,“兆芯国产 X86 通用处理器的成功自主研发和量产,令国产处理器在性能方面完成了一次跨越式的提升,从十二五初期的不足国际整体水准的 10% 提升到了目前的 80%”。
众所周知,Intel 对 X86 的授权有着极为严格的限制,那么上海兆芯的 X86 芯片技术到底从何而来?ZX-C 目前的短板在哪里?在性能上和 Intel 相差多远呢?
兆芯 C4600 cpuinfo 的信息显示:设计厂商为美国 Centaur,微结构是 VIA 的以赛亚
在 Linux 系统中命令 cat /proc/cpuinfo 可以读出芯片的一些信息和特性。其命令和 Windows 系统中 cpu-z 软件获得的信息类似。芯片 cpuinfo 的信息是通过 CPUID 指令读出来的。例如 eax=1 时,读出的是处理器的信息以及特征位 (CPUID 指令的使用,见 en.wikipedia.org/wiki/CPUID)。
从图 1 兆芯 C4600 芯片 cpuinfo 的信息可以看出,这个芯片的厂商(vendor_id)为 CentaurHauls,即 Centaur 公司。其中 cpu family 表示那一代芯片,其中的 family 6 表示 VIA 的 Nano 系列。其中的 model 表示型号,也就是采用哪种微结构,15 表示以赛亚。model name 为处理器的型号,图中为 C-QuadCore C4600@2.0GHz。表示 4 核芯片 C4600,主频为 2GHz。
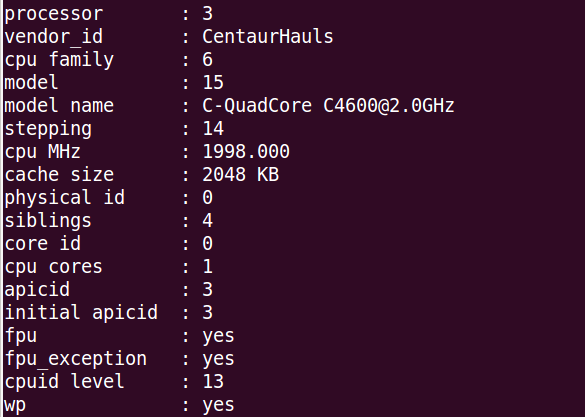
- 图 1 兆芯 C4600 芯片 cpuinfo 的信息 *
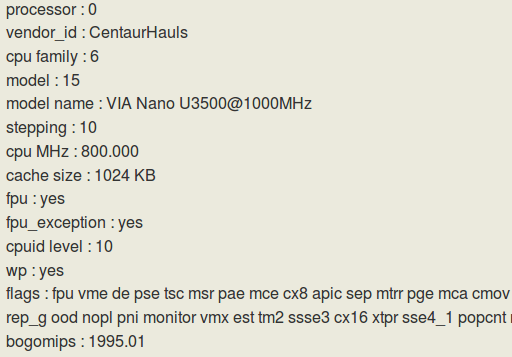
- 图 2 威盛 Nano U3500 芯片 cpuinfo 的信息 *
图 2 给出了威盛公司的 Nano U3500 芯片 cpuinfo 的信息,其 model name 为 VIA Nano U3500@1000MHz。对比 vendor_id 的信息可以看出都是 VIA 的 Centaur 公司,对比 cpu family 和 model 的信息,也可以看出都是 family 6 和 model 15,即都是 “以赛亚” 架构。
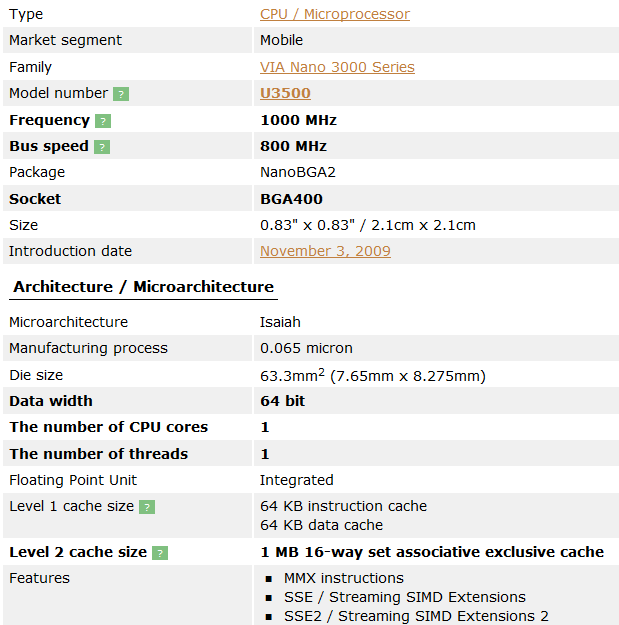
- 图 3 威盛 Nano U3500 芯片的信息 *
从图 3 可以看出 U3500 芯片属于 VIA Nano 系列。其中的微架构为 Isaiah(以赛亚)。支持的指令集到 SSE4.1 为止,并且支持 x86-64 指令集。
从 C4600 芯片 cpuinfo 的信息可以看出,C4600 的设计厂商(vendor_id)还是 VIA 的 Centaur 公司,而没有改为 ZX 的标志。
美国 Centaur 公司和 Glenn Henry
根据维基的资料显示:Centaur(半马人)科技公司,创立于 1995 年,创建者为 Glenn Henry, Terry Parks, Darius Gaskins 和 Al Sato,其获得的投资来自于 IDT 公司。其公司的目标是开发兼容的 x86 处理器,目标定位为开发比 Intel 公司的 x86 芯片价格更低,功耗更小的芯片。早期的产品称为 WinChip,1999 年 9 月,Centaur 被 IDT 公司出售给 VIA 公司,其后续的产品为 VIA C3 和 VIA C7,以及 VIA Nano。Centaur 公司的芯片主要面向嵌入式市场,包括移动市场,也就是面积更小、价格更便宜,功耗更低的 x86 芯片市场。Centaur 的设计理念是对于面向特定市场需求 “够用就好”。VIA Nano Isaiah(以赛亚),是 Centaur 第一款超标量、乱序执行的 CPU,第一款 64 位的 CPU,Nano 芯片这时更为强调性能,而不再是追随性能功耗比的等式,但是其维持和 C7 相同的功耗(TDP)。
根据 Centaur(半马人)公司的网站的介绍,Centaur(半马人)科技公司,位于德克萨斯 - 奥斯丁。主要设计高性能、低功耗的 x86 兼容的微处理器,号称具有最快的设计流程,设计周期是竞争对手厂商的三分之一。该公司没有管理者,所有的工程师直接向 Centaur 公司的创建者和总裁 Glenn Henry 汇报,Glenn Henry 是前 DELL 公司的 CTO 和 IBM 的工程系列的 Fellow(20 年的 Fellow)。1999 年 8 月,Centaur 公司被 VIA 公司收购。但是这次收购没有改变 Centaur 的文化,也就是 Centaur 作为 VIA 公司的子公司独立地运营,而不会受到 VIA 的影响。在 Cyrix 解散后,VIA 公司的 x86 芯片的设计都是来自于 Centaur 公司,而 VIA QuadCore C4650 芯片也是出自 Centaur 公司的 Glenn Henry 之手。

- 图 4 Glenn Henry*
这里介绍以下 Glenn Henry。Glenn Henry 于 1967 年加入 IBM,在 IBM 干了 21 年,担任首席架构师,是 RISC 工作站、AIX 操作系统和 AS/400 等创新产品的主要研发管理者,于 1985 年获得 IBM fellow 的称号,1988 年离开 IBM 加入 DELL 公司,为 DELL 公司负责研发的副总和 CTO,1994 年离开 DELL 公司,担任 MIPS 公司的咨询顾问,试图把 x86 和 MIPS 架构结合在一起,1995 年 Henry 获得了来自 IDT 公司的投资,创建了 Centaur 公司,设计低功耗、低成本的 x86 处理器。
揭开以赛亚神秘的面纱
正如 Intel 在研发出酷睿 2 后一举翻身,AMD 在开发出 Zen 之后终于做出能与 Intel 相比较的产品,一款 CPU 最关键的就在于其微结构,那么 QuadCore C4650 芯片的微结构究竟怎么样呢?

图 5 The VIA Isaiah Architecture
Centaur 公司的灵魂人物和总裁和 Glenn Henry 撰写的一篇文章 “The VIA Isaiah Architecture”(图 5),文章中分析了为什么采用 3 发射、乱序执行结构,和 Intel 的 Core 比较起来有什么优势,为了降低功耗,采用了什么样的权衡。文章介绍的非常详细,有兴趣的网友可以找原文品读。
从图 6 中可以看出,以赛亚采用类似于 Core 架构的设计,7 个部件,2 个定点 I1 和 I2,2 个浮点 MA 和 MB,1 个取数 LD,1 个存数 ST 和 1 个 SA 地址计算。也就是 2 个定点、2 个浮点、2 个访存。属于中规中矩的设计。
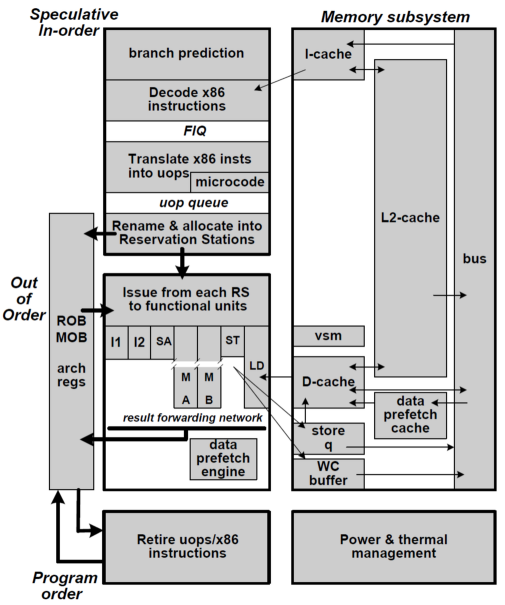
- 图 6 以赛亚微结构框图 *
Cache 的设计为 64KB+64KB L1 cache,16 路组相联,2MB 的 uninclusive 的 L2 cache。保留站的项数为 76 项(micro-ops,其 micro-ops 类似 Intel 处理器的 uops,每条 X86 指令对应 1-3 条 uops),规模和 Intel 的 Core 以及 AMD 的 K10 基本相当。其也采用了大量的低功耗技术,例如为了降低功耗,分支预测器的表项只有 4K 项,取指令时只取 16 字节大小等。
从文章中介绍和测试数据来看,该处理器结构在 2008 年而言是非常棒的微架构,兼顾了低功耗和适度性能。从性能上可以打赢当时的按序发射的 Intel Atom,但是由于技术团队人数有限,在功耗控制实现上不是那么完美,所以导致其市场定位高不成低不就。在高性能上没法和 Intel 的 Core 和 AMD 的 K10 抗衡,在低功耗上又不能做到无风扇设计,没法和 Atom 以及近年来崛起的 ARM 相比。导致 Nano 的芯片主要用于上网本等市场,但是由于出货量较少,每片的成本相对较高,随着上网本市场的消亡,Nano 芯片基本也退出了主流市场。
Glenn Henry 曾在 2008 年接受记者 Dave Altavilla 的采访,在采访中 Glenn Henry 对低功耗的以赛亚架构处理器的一些解释(“VIA’s Glenn Henry Speaks On New Low Power Isaiah Processor,by Dave Altavilla, January, 2008”)。

图 7 Glenn Henry 介绍 “以赛亚” 架构
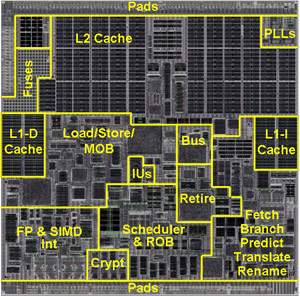
图 8 “以赛亚” 架构 Nano 处理器版图
ZX-C QuadCore C4600 和 VIA QuadCore C4650 关系密切
根据媒体报道:
《真正走向市场化,揭秘中国兆芯 X86 处理器》
《国货新贵 兆芯 X86 处理器来了!-- 开先 ZX-C C4600 处理器体验》
《兆芯傅城:国产 X86 通用处理器已接近国际水平》
这三篇报道算是比较全面的介绍兆芯的 X86 处理器。文章中介绍了是兆芯公司打造了中国 X86 CPU,也介绍了兆芯 ZX-C 四核心处理器,ZX-C 处理器是国家 “十二五” 核高基重大科技专项创新成果,采用 28nm 工艺等内容。
不过,这些报道中的一些内容经不起对敲,比如文章中称:兆芯 ZX-C 四核处理器的推出,让国产处理器的性能完成了从 “十二五” 初期不足国际主流水准 10% 到目前 80% 的跨越性提升。
其实,这段话并非媒体妄言,而是出自兆芯(VIA Alliance Semiconductor)在 “十二五” 科技成果展上的宣传资料。不过,兆芯官方宣传资料中达到国际主流水准的 80% 是不客观的。
但经过实际测试,即便是兆芯 ZX-C 四核处理器中主频达到 2.0G 的 C4600,与 Intel G1840 和 I5 4460 相比较。从图 10 可以看出,就定点而言,I5 4460 是 ZX-C 的 3.3 倍,G1840 是 ZX-C 的 2.4 倍。就浮点而言,I5 4460 是 ZX-C 的 4.4 倍,G1840 是 ZX-C 的 2.8 倍。在这种情况下,宣称 ZX-C 达到国际主流 80%,存在虚假宣传行为。
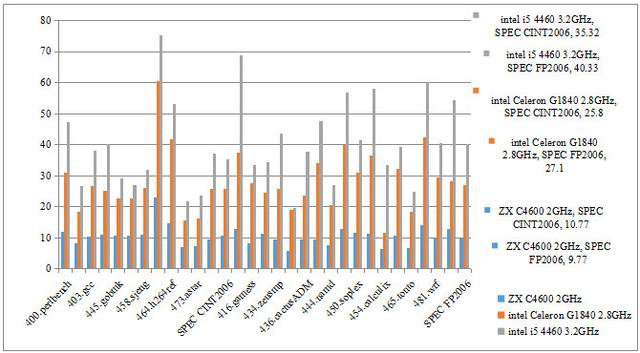
(图 10)
言归正传,一起先来探究以下 ZX-C 处理器和 VIA QuadCore C4650 的关系。
根据 2014 年的报道 “Report: VIA’s quad-core, 64-bit Isaiah II chip coming this summer – 07/07/2014 by Brad Linder”。2014 年的 VIA 的 2GHz 的 Isaiah II QuadCore 处理器的性能基本和 AMD Kabini 的 Athlon 5350 和 Intel Atom 的 Z3770 相当,详细参数见图 11。
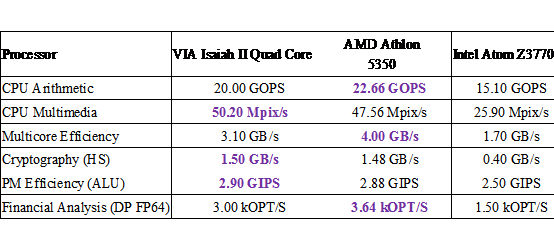
(图 11)
根据 2015 年的一篇文章,“VIA’s New 28nm C4650 QuadCore x86 Processor Spotted – Gaming and General Purpose Benchmarks Surface, Impressive Low-End Performance”。从中可以推测在至少在 2015 年,VIA 已经有了 VIA QuadCore C4650。
在 2016 年,兆芯宣布开始将量产 100 万套 ZX-C 四核 X86 处理器。这里先介绍下 C4600 和 ZX-C 的关系。根据兆芯官网资料,ZX-C 可分为 C4200/4210、C4400/4410、C4600/C4610 三个类别,之间的差别在于主频,C4600 是 ZX-C 系列处理器的 2.0G 主频版本,兆芯官方截图见图 12 和图 13。 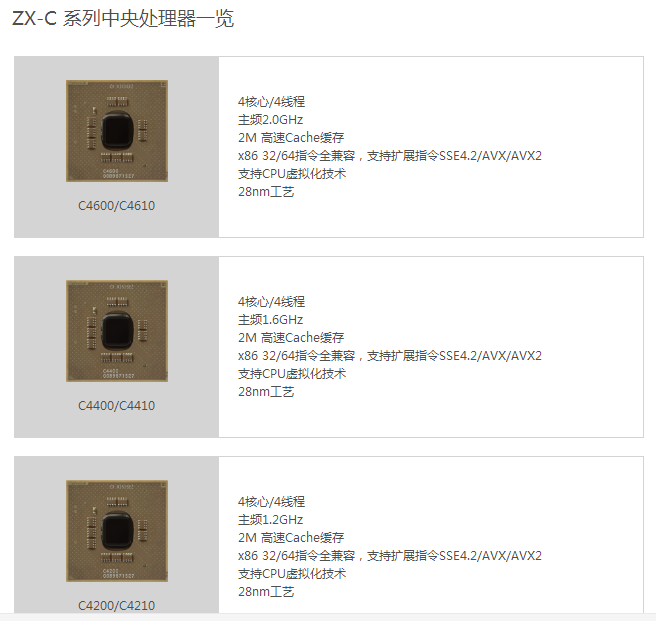
(图 12)
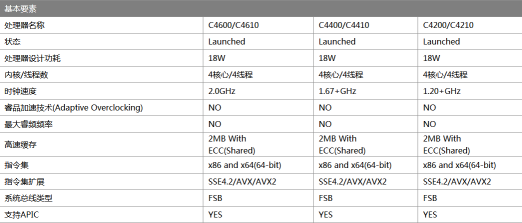
(图 13)
而且之前已经介绍了,从 C4600 芯片 cpuinfo 的信息可以看出,C4600 的设计厂商(vendor_id)还是 VIA 的 Centaur 公司,而没有改为 ZX 的标志。
兆芯的 C4600 与 VIA 公司的 QuadCore C4650 有非常紧密的联系。这种联系存在两种可能:
第一种可能是,Centaur 公司已经由威盛公司完全出售给了兆芯公司了,所以直接使用 Centaur 公司的标志,Centaur 公司的技术成果也就顺理成章的成为国家 “十二五” 核高基重大科技专项创新成果。
第二种可能是,通过 VIA 的关系,兆芯直接把 QuadCore C4650 的设计或版图买过来,或者直接拿过来,重新在台积电流片,然后改头换面变成了国家 “十二五” 核高基重大科技专项创新成果。
以赛亚和以赛亚 2 到底有多少差异
根据资料显示:兆芯 ZX-A 处理器,如 C4350AL 的微结构是 “以赛亚”,而 ZX-C 系列处理器,比如 C4600 的微结构是 “以赛亚 2”。那么,以赛亚和以赛亚 2 到底有多少差异呢?
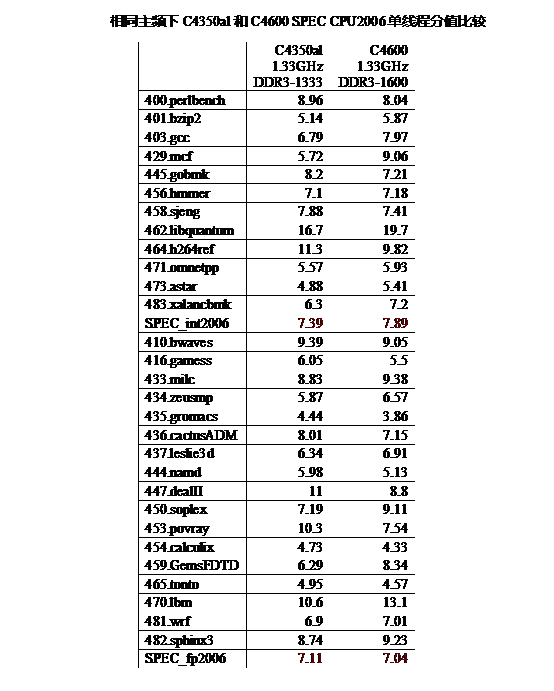
下面对 VIA Nano X2 C4350AL 和兆芯 C4600 在进行测试。实验中为了尽可能较少不同的因素,将 C4600 和 C4350al 的频率都降到 1.33GHz。不过,受条件有限的原因,还是有一些区别的 ——C4600 使用内存为 DDR3-1600,C4350al 使用的内存为 DDR3-1333,C4600 编译选项最高采用 SSE4.2,而 C4350al 编译选项最高支持到 SSE4.1,另外,两个平台的前端总线(FSB)频率也不同,C4600 为 1333MHz,C4350al 为 1066MHz。
(图 14)
从图 14 的对比可以看出,在相同主频下,C4600 和 C4350al 的 SEPC2006 的分值基本相当,也就是两者在相同频率下的性能基本相同。抛开主频的影响和编译器的影响,处理器性能的差别在于微结构的差别。
由于即便是同一款处理器跑两次 SEPC2006 的分值也有有少许上下浮动。因而可以推断出兆芯的 C 款处理器 C4600 和兆芯的 A 款处理器 VIA Nano C4350AL 采用了相同的微架构,或者说以赛亚和以赛亚 2 的差异微乎其微,以至于在性能上处于原地踏步状态。
除了前端总线的频率和工艺的差别,各种微结构的参数都没有任何变化,也就是说 “以赛亚 2” 和 “以赛亚” 其实是同一个东西,或者说修改的地方微乎其微,以至于在性能上处于原地踏步状态,修改可以忽略不计。
必须说明是是实验中,C4600 的定点性能比 C4350al 略高一些,主要原因是 C4600 的前端总线的频率提高了,C4600 浮点性能反而略有下降,主要原因是由于其采用的 SSE4.2 指令集没有硬件的逻辑实现,并且 DDR3-1600 带宽的提升反而弥补不了延迟的略微增加,以至于浮点性能下降。
兆芯 C4600 和 VIA 以赛亚的短板
Centaur 公司设计的以赛亚在当时是立足差异化竞争的产物,以赛亚也是一个轻量级的架子,虽然在 2009 年的时候这个设计还是挺不错的。但随着技术的进步,以赛亚在今天就有点不够看了,面对 ARM Cortex A57/A72/A73 就难以招架了。下面简单介绍一下兆芯 C4600 和 VIA 以赛亚的短板:
** 短板一:没有对最新的指令系统在微结构和硬件上进行改动 **
根据 VIA 官方资料,VIA Nano 只支持到 SSE4.1 指令集系统,至于原因只要回溯 Intel 指令集系统的发展历史就明了了:MMX(1996), SSE(1999), SSE2(2001), SSE3(2004),SSSE3(2006), SSE4.1(2006)SSE4.2(2007), AES, AVX(2011), F16C(2009), ACE, PCLMUL(2010), VMX, BMI1, BMI2, AVX2(2013)。
正是因为历史原因以及 Intel 对外的 X86 授权因素,当时的 VIA 公司没有拿到 Intel 最新指令集系统的授权,所以 2009 年的 Nano 处理器最高支持到 SSE4.1。
相比之下,VIA QuadCore C4650 和兆芯 C4600 处理器支持后续的 SSE4.2 和最新的 AVX 和 AVX2 等指令集系统。
对于 VIA QuadCore C4650 和兆芯 C4600 支持最新的 AVX 和 AVX2 等指令集系统,可能的原因是 VIA 已经买到了 Intel 公司最新指令集系统的授权。不过 VIA 如何将指令集授权转让给兆芯,这个问题无论是 Intel,还是 VIA、兆芯都没有任何公开声明。
诚然,这个不是本文关注的重点。本文关注的是缘何增加了 AVX 和 AVX2 等指令集系统 C4600 的性能反而下降了。
Intel 和 AMD 的 CPU 在使用了最新的 256 位的 AVX/AVX2 向量指令集后,性能有所提高 ——Intel 和 AMD 处理器采用向量指令(128 位和 256 位),INT2006 的性能平均可以提高 5%,FP2006 的性能平均可以提高 16-18%。而从 128 位的 SSE,增加到 256 位的 AVX/AVX2 指令,INT2006 的性能可以提高 2-3%,FP2006 的性能可以提高 6-8%。
必须说明的是,采用向量指令提高性能的前提是处理器的访存通路能供应上足够宽的数据,如 Haswell 为了支持 256 位的 AVX/AVX,采用了 3 个访存的端口,同时支持 2 个 256 位的 load 操作和 1 个 256 位的 store 操作。
与 Intel 和 AMD 的 CPU 相反,C4600 处理器兼容了 Intel 最新的 256 位向量指令 AVX/AVX2 等(不支持乘加 FMA 指令)。在编译时打开了 AVX2, AVX, bmi 等最新指令集编译选项,但编译出来的程序实测性能反而下降。具体成绩为图 15。
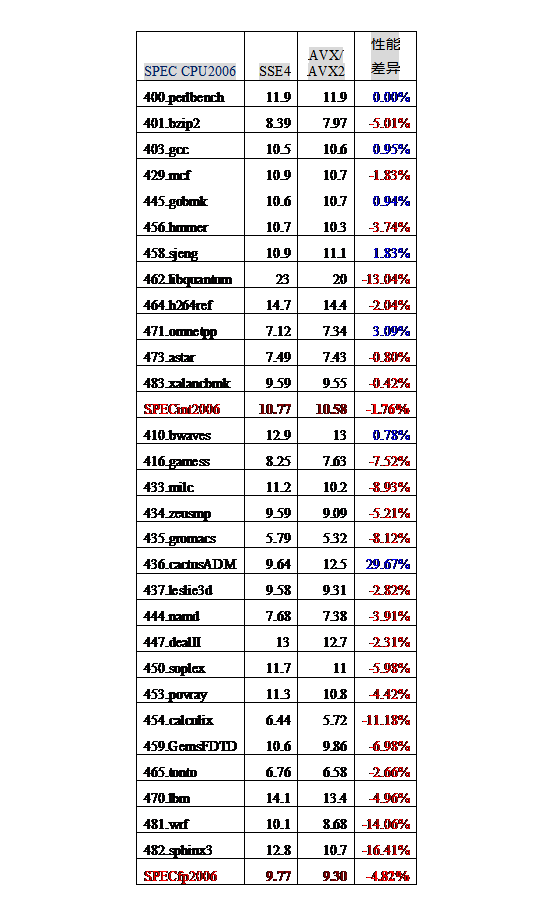
(图 15)
从图 15 中可以看出,采用最新的指令集系统,对于大部分 CPU2006 的程序,其性能反而下降了。对于 INT2006,几何平均的性能下降了 1.76%,如 401.bzip2 下降了 5.01%,456.hmmer 下降了 3.74%,462.libquantum 下降了 13.04%;对于 FP2006,几何平均的性能下降了 4.82%。416.games 下降了 7.52%,433.milc 下降了 8.93%,435.gromacs 下降了 8.12%,454.calculix 下降了 11.18%,454.calculix 下降了 14.06%,459.GemsFDTD 下降了 6.98%,482.sphinx3 下降了 16.41%。而这些程序正好是易于被向量化的程序,其采用了 256 位的 AVX 指令。例如 459.GemsFDTD 中 256 位的 Packed Double 动态指令数占到 16.53%。
为什么采用新型的指令集系统,SPEC CPU2006 程序性能反而有所下降呢?很可能是兆芯 C4600 处理器保留了 Centaur 公司的原始设计,没有对最新的指令系统在微结构和硬件上进行改动,也就是在微结构上除了指令译码部分,在数据通路和访存通路上没有变化。而这也作证了之前提到的:以赛亚 2 和以赛亚其实是同一个东西,或者说修改的地方微乎其微。
首先来看处理器在指令译码部分怎么支持最新的指令集系统,在当前的 CISC 指令集系统的实现都是将外部 CISC 指令翻译为内部的类 RISC,即 uops,通常一条 CISC 指令可以在内部被翻译为 1-3 条内部的 uops 指令。uops 指令在 “以赛亚” 被称为 micro-ops,见 VIA Isaiah Architectural 文章中 “microcode subsystem”,“以赛亚” 架构中的微码子系统(microcode subsystem)包括 24K 微指令加上一个强大的打补丁(patch)的功能,使得微码能被更新,每个 ROM 中的微码指令被翻译为最多 3 条融合的微操作(fused micro-ops)。可以看出 “以赛亚” 架构仍然在沿用 X86 处理器早期的部分复杂 X86 指令微码实现的方式,如果要支持新的如 AVX 的指令,就可以通过更新微码的方式来实现,再通过微码指令转换为内部的微操作指令实现。
第二,256 位寄存器的实现,既然要支持 AVX 指令,需要实现 256 位的体系结构可见的寄存器和 256 位的重命名物理寄存器,我们猜测其内部实现为仅实现了体系结构可见的寄存器,而没有实现 256 位的重命名物理寄存器,这不会增加太多的开销。在数据通路和访存通路的实现上,在内部很可能是将 256 位的向量指令拆分为多条 128 位的类 SSE 指令实现的,这种方法在第一代 AMD 的推土机实现 256 位的 AVX 指令和第一代的 K8 实现 128 位的 SSE 指令也是这么做的,通过内部拆分在数据通路上支持新的指令集系统,但是这样做的结果是,新的指令系统对性能不但没有好处,反而会有性能的下降,因为数据通路和访存通路根本就没有实现更宽的设计,就好比本身很窄的马路,可以通过 2 个车道,这时候同时来 4 辆车,这 4 辆车就得排成两排,顺序通过。另外,更宽的向量操作导致其架构的访存和供数能力跟不上,这也造成了新指令集有时性能下降的原因。
短板二:前端总线设计和带宽
限制兆芯 C4600 芯片的一大瓶颈是 Centaur 公司延续了其前端总线(VIA V4 bus)的设计,而且没有将内存控制器集成到处理器上。
前端总线(front-side bus,FSB)是早期 Intel 芯片的计算机通信的接口,和 AMD 公司的 EV6 类似,其连接 CPU 和北桥芯片,内存控制器通常集成在北桥中。PCI,AGP 等各种设备以及内存都是通过北桥和 CPU 进行通讯。
前端总线出现在 1995-2006,用于 Intel 的 Atom,Celeron,Pentium,Core2 芯片以及早期的 Xeon 芯片,其很快被现代处理器中 AMD 的 HT(HyperTransport)和 Intel 的 QPI(QuickPath Interconnect)以及 DMI(Direct Media Interface)所取代。
前端总线为 64 位,8 个字节,每拍能传输 4 次。前端总线的速度是当时计算机系统一个重要的衡量指标,当前,前端总线最高的频率为 333~400MHz,每个周期能进行 4 次传输。由于设计的缺陷,前端总线的频率没法得到进一步提升。假设前端总线的实际频率为 333MHz,也就是通常厂家说的 1333MHz,其峰值理论带宽为 10.65GB/s,即 8 bytes/transfer × 333 MHz × 4 transfers/cycle = 10656MB/s。
前端总线的设计,使得 CPU 需要等待来自内存中的数据,对于每个元素需要的大量复杂计算的应用,这样的应用访存不是那么的密集,前端总线能跟上 CPU 的速度。而对于图像、音频、视频、游戏、FPGA 综合以及科学应用等应用,通常是对于大工作集的少部分数据进行操作,这样前端总线就成为一个主要的性能瓶颈。
图 16 比较了 2.0GHz 的兆芯 C4600、1.5GHz 的龙芯 3A3000、1.5GHz 的 AMD K10 三款处理器访存带宽测试程序 STREAM 的带宽分值,从中可以看出,单线程 STREAM 的测试,C4600 的 STREAM 带宽基本为 4-5GB/s,而 3A3000 为 8+GB/s,K10 为 6-7GB/s。多线程 STREAM 的测试,C4600 的 STREAM 带宽基本为 3+GB/s,而 3A3000 为 12-13GB/s,K10 位 6+GB/s。
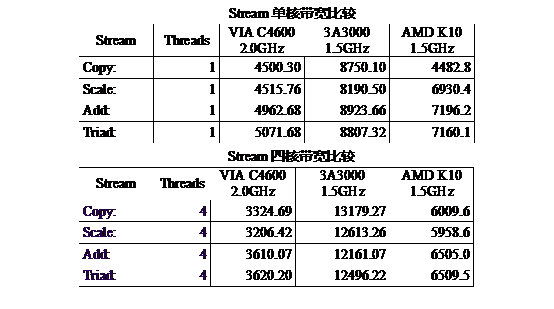
(图 16)
国际主流 CPU 都在十年前把内存控制器集成在 CPU 芯片中,而兆芯 C4600 继续把内存控制器集成在桥片上,访存带宽受限于前端总线。VIA 以赛亚系列处理器从 2009 年开始一直采用 VIA V4 BUS 的前端总线设计,而没有将内存控制器集成到芯片上,即使是 2014 年对 Nano X2 的改版也不愿意去动其结构和设计。只是从 40nm 工艺提高到 28nm TSMC 的工艺,同时把 V4 总线的频率从 800MHZ 提高到 1333MHz,也就是其前端总线的理论带宽为 10.6GB/s。所以其内存带宽不高原因也就可以解释。
另外,多线程的情况下,多个 CPU 核以及 I/O 等会竞争前端总线,前端总线和内存控制器的预期机制截然不同,造成访存序的紊乱。所以在多个线程尤其是访存压力很大的情况下,其性能会急剧下降。这也是 C4600 多线程带宽反而不如单线程带宽的原因。
对于 C4600,1-2 个核基本上就吃满了访存带宽,对于龙芯 3A3000 而言,访存带宽具备显著的优势,其能满足 4-8 个处理器核的需求。所以,在单线程性能差距不大的情形下,龙芯 3A3000 的 SPEC CPU2006 多线程 rate 的性能,明显超过了 C4600 的 rate 性能。具体参数见图 17
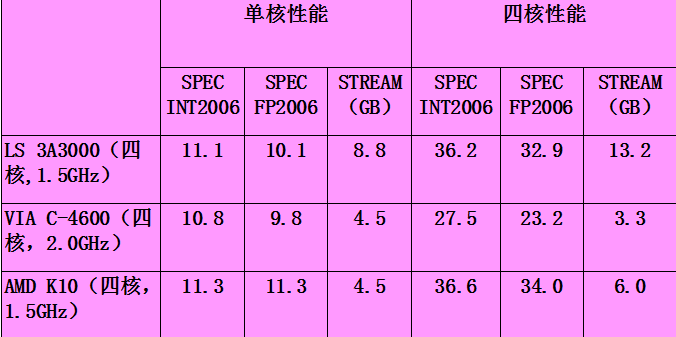
(图 17)
结语
虽然在一系列兆芯官方宣传和中文宣传资料上,兆芯一直宣传自主安全可控(见图 18),在其官方网站上也标明自主可控(见图 19)。但与兆芯相关的英文材料却标明:Based on Centaur Technologie’s microarchitecture designs (见图 20)。

(图 18)

(图 19)
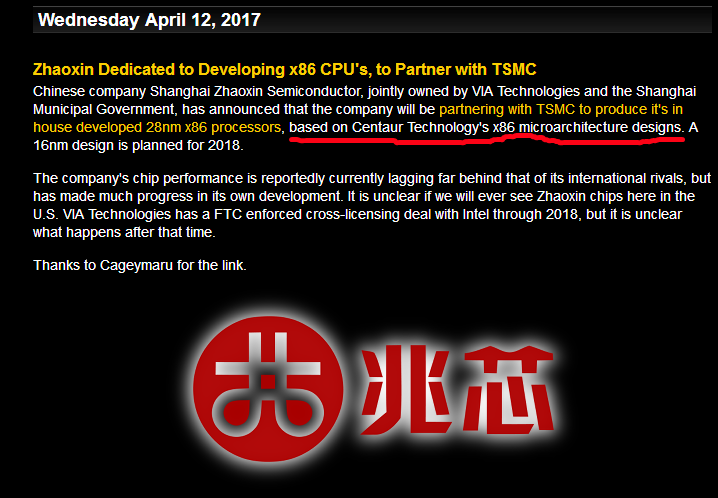
(图 20)
在微结构源自 Centaur 公司,指令集授权也模糊不清的情况下,就宣布兆芯自主安全可控,未免有点超之过急 —— 即便是走技术引进道路,也要在凭借自己的能力完成消化吸收再创新之后,才能称得上自主可控安全。比如在充分消化 Centaur 公司设计的以赛亚之后,凭借境内设计团队设计出可以匹敌 Intel SNB 或者 AMD Zen 的产品,这才真的称得上再创新。拿 Centaur 公司设计的以赛亚,改制程堆核心数提升总线频率做出一款 CPU 就宣传自主可控,无非是自欺欺人而已。
至于拿 Centaur 公司早年的设计,改头换面就成为国家 “十二五” 核高基重大科技专项创新成果,并能够荣获 “第 18 届中国国际工业博览会金奖”(见图 21)、“2017 年度大中华 IC 设计成就奖”(见图 22)、“第十一届(2016 年度)中国半导体创新产品和技术奖”(见图 23),也难怪国外资深 IC 设计工程师会对中国的 IC 设计水平嗤之以鼻了。 
(图 21)

(图 22)

(图 23)
技术引进再创新,国产 X86 CPU 和 Intel 还有多少差距?
导语:就裸 CPU 性能而言,ZXD 大约是 Intel 主流四核 CPU 的 30%—40%。
雷锋网按: 2017年 6 月,核高基总师魏少军接受科技日报采访时表示,“国产兆芯 x86 通用处理器的成功自主研发和量产,令国产桌面处理器在性能方面完成了一次跨越式的提升,从 “十二五” 初期的不足国际整体水准的 7%提升到了目前的 50%,综合性能体验达到 80%。”
实际上,国产 X86 芯片的性能和英特尔对比究竟怎么样?在技术引进吸收创新的过程中又取得了怎样的进步呢?
几个月前,上海兆芯最新的产品 ZXD 在 2017 年北京国际互联网科技博览会暨世界网络安全大会上亮相。ZXD 虽然相对于 Intel 和 AMD 的 CPU 还有不小差距,但相对应兆芯第一款 CPU ZXA 而言,确实有着很大的进步 —— 自上海兆芯自 2013 年成立以来,从第一款产品 ZXA,到如今最新的产品 ZXD,上海兆芯用了数年时间实现以 VIA 的技术为基础,将产品的裸 CPU 性能提升了 80% 以上。
ZXC 相当于 ZXA 性能有多少提升?
ZX-A 是兆芯的第一款 CPU,技术源自 VIA,拥有 2 个核心,主频 1.6G,采用台积电 40nm 制造工艺。就其性能来说,根据相关单位的 SPEC2006 测试,主频 1.6G 的 ZXC 在采用 Ubuntu 14.04 操作系统,ICC 编译器的情况下,成绩为:
SPECint2006 : 11.3
SPECint_rate2006: 20.5
SPECfp2006 : 12.4
SPECfp_rate2006: 18.7
STREAM 测试的单线程成绩为:
Copy 5502.8MB/s;
Scale 5042.9MB/s;
Add 5321.6MB/s
Triad 5252.7MB/s
STREAM 测试的多线程成绩为:
Copy 5191.1MB/s;
Scale 5104MB/s;
Add 5383.8MB/s
Triad 5461.9MB/s
这里介绍下,SPEC2006 是在行业内相对比较权威的测试软件,通过 26 个程序对 CPU 进行测试,然后计算结果,分数越高性能越好。不过 SPEC2006 测试也并非无懈可击 —— 可以通过不说明编译器等条件作弊,是否打开 auto parallelization 也有有成绩差异,还有 base 分值和 peak 分值会有一定的差别等等。
即便如此,相当于一些黑箱测试而言,SPEC 依旧是相对比较公正的测试,能够比较客观的反映 CPU 的实际性能,毕竟绝对客观的测试是不存在的,就如同高考,即便存在这样或那样的问题,但目前来看,依旧是最具可操作性,相对公平合理的考评方式(北京、上海除外)。
ZX-C 是对 VIA 技术的引进消化吸收,相对于 ZXA 的 2 个 CPU 核,ZXC 改为 4 个 CPU 核,而且 CPU 核之间核心通过 L2 Cache 交互,相比较 ZXA 而言,ZXC 的多核性能有所提升。针对从 VIA 引进的内核存在资源冗余和不均衡的问题做了重新设计,并采用了台积电 28nm 制造工艺,降低了功耗,提高了稳定性,减少了量产成本,将 CPU 的主频从 ZXA 的 1.6G,提升到 ZXC 的 2G。
另外,兆芯还重新设计 FSB 接口,FSB 频率从 1066MHz 提高到 1333MHz。对访存单元进行了重新设计,设计了全新的 L1/L2 访存控制单元,优化访存性能等工作。
而这些修改最直接的体体现就是在性能上,根据相关单位的 SPEC2006 测试,主频 2.16G(睿频)的 ZXC 在采用 Ubuntu 14.04 操作系统,ICC 编译器的情况下,成绩为:
Specint 2006: 17
Specint rate2006: 50
Specfp 2006: 18.2
Specfp rate2006: 36.3
ZXC 相对于 ZXA,在单线程定点成绩上提升了约 54%,多线程提升了约 147%;就浮点性能而言,ZXC 相对于 ZXA 单线程性能提升了约 50%,多线程性能提升了约 50%。
虽然在 Ubuntu 14.04 操作系统,ICC 编译器的情况下,Specint 2006:17;Specfp 2006:18.2 的成绩相对应 Intel 有较大的差距,但相对于 ZXA 而言,ZXC 的进步着实不小。

ZXD 性能再提升且弥补了 ZXC 的最大短板
之前介绍了,ZXC 相对于 ZXA,在单线程定点成绩上提升了约 54%,多线程提升了约 147%;就浮点性能而言,ZXC 相对于 ZXA 单线程性能提升了约 50%,多线程性能提升了约 50%。
但 ZXC 也有自己的短板,那就是前端总线 —— 对于图像、音频、视频、游戏、FPGA 综合以及科学应用等应用,通常是对于大工作集的少部分数据进行操作,前端总线就成为一个主要的性能瓶颈。
ZXC 延续了 VIA 原本的前端总线(VIA V4 bus)的设计 —— 前端总线(front-side bus,FSB)是早期 Intel 芯片的计算机通信的接口,和 AMD 公司的 EV6 类似,其连接 CPU 和北桥芯片,内存控制器通常集成在北桥中 ——ZXC 没有将内存控制器集成到处理器上,而是在桥片里。这样一来,导致 STREAM 测试的成绩就不太好看了。
根据 STREAM 5.10 测试的成绩,单线程的成绩为:
Copy: 7685.0 MB/s
Scale: 7446.4 MB/s
Add: 8129.5 MB/s
Triad: 7981.7 MB/s
4 线程测试成绩为:
Copy: 7426.3 MB/s
Scale: 7504.0 MB/s
Add: 7656.8MB/s
Triad: 7787.7 MB/s
从中可以看出,ZXC 的 STREAM 测试成绩是比较一般的,而且相对于 ZXA 而言提升也比较有限。
ZXD 的最明显改进之处就在于更换了更好的 DDR4 内存控制器,是国内首款集成了 DDR4 内存控制器的国产桌面 CPU,而且 ZXD 还把内存控制器集成到芯片里 —— 相对于 ZXC 的 DDR3 内存控制器,ZXD 采用了 DDR4 内存控制器,并把内存控制器集成到芯片里,而非像 ZXC 那样把内存控制器集成在桥片里,而这个改变一定程度上提升了 CPU 的综合性能。
此外,ZXD 很有可能将 FSB 总线换了类似于 Intel 的 dmi 这样的接口。两者因素相加,使 ZXC 存在的短板不复存在。最典型的证明就是 STREAM 测试成绩大幅提升。根据相关单位的测试,STREAM 5.10 测试单线程成绩为:
Copy: 10942.4 MB/s
Scale: 10371.4 MB/s
Add: 10603.1 MB/s
Triad: 9850.1MB/s
多线程成绩为:
Copy: 12666.1 MB/s
Scale: 13060.3 MB/s
Add: 11270.2MB/s
Triad: 11302.6MB/s
从测试成绩可以看出,ZXD 的 SRTEAM 测试成绩相对于 ZXC 有了显著提升,弥补了过去的短板。并且通过更新了 ddr4 内存控制器,在商业上还能有效应对各家内存大厂的 DDR3 内存条停产的问题。
除了内存控制器上的改进之外,ZXD 增加 X86 指令缓冲器,提供了更精确的循环缓冲功能,并通过整体流水线前后端各级优化,大幅减少流水线级数,有效降低了分支预测失败的性能损失… 经过一系列的改进,直接体现在 ZXD 相对于 ZXC 的性能提升,根据相关单位的数据,在采用 Ubuntu 14.04 操作系统,内存为 32GB DDR4 内存,硬盘为 Intel 530 系列 120GB 的 SSD 硬盘,编译器为 ICC,ZXD 睿频到 2.2G 的情况下,SPEC2006 测试成绩为:
Specint 2006: 20.4
Specint rate2006: 63.3
Specfp 2006: 23
Specfp rate2006: 47.6
**ZXD 这个成绩虽然相对于 Intel 和 AMD 依旧有不小的差距,就裸 CPU 性能而言,ZXD 大约是 Intel 主流四核 CPU 的 30%—40%。**而且必须说明的是,兆芯对 CPU 架构的修改还是相对有限的,目前所做的修改并非脱胎换骨的大换血,比如没有实现类似于 AMD 从 “打桩机” 到 Zen 的提升和飞跃。

配图来自 兆芯官网
via:
-
原标题:中国 X86 CPU 技术源自何方 | 雷峰网 本文作者:铁流 编辑:[程弢] 2017-05-12 14:4
https://www.leiphone.com/category/industrynews/6zCdjUToIhWSIILD.html
-
原标题:技术引进再创新,国产 X86 CPU 和 Intel 还有多少差距? | 雷峰网 本文作者:铁流 2017-09-22 15:21
https://www.leiphone.com/category/industrynews/lr9j2UsLCbnsNbsL.html







![[Redis]典型应用——缓存](https://i-blog.csdnimg.cn/direct/198a0b16789a493d811d97445bfdca6f.png)
![[CSS] 浮动布局的深入理解与应用](https://img-blog.csdnimg.cn/img_convert/c809c2b3fd092a6f38d90182d3a63b91.png)