一、MySQL索引
1、何为索引?
MySQL中的索引是一种数据结构,用于加快对数据库表中数据的查询速度【查询速度提升】。它类似于书本目录,使得用户可以根据特定字段快速定位到所需的数据行,而无需扫描整个表。
2、索引分类
Hash索引
Hash索引的数据结构为Hash表。
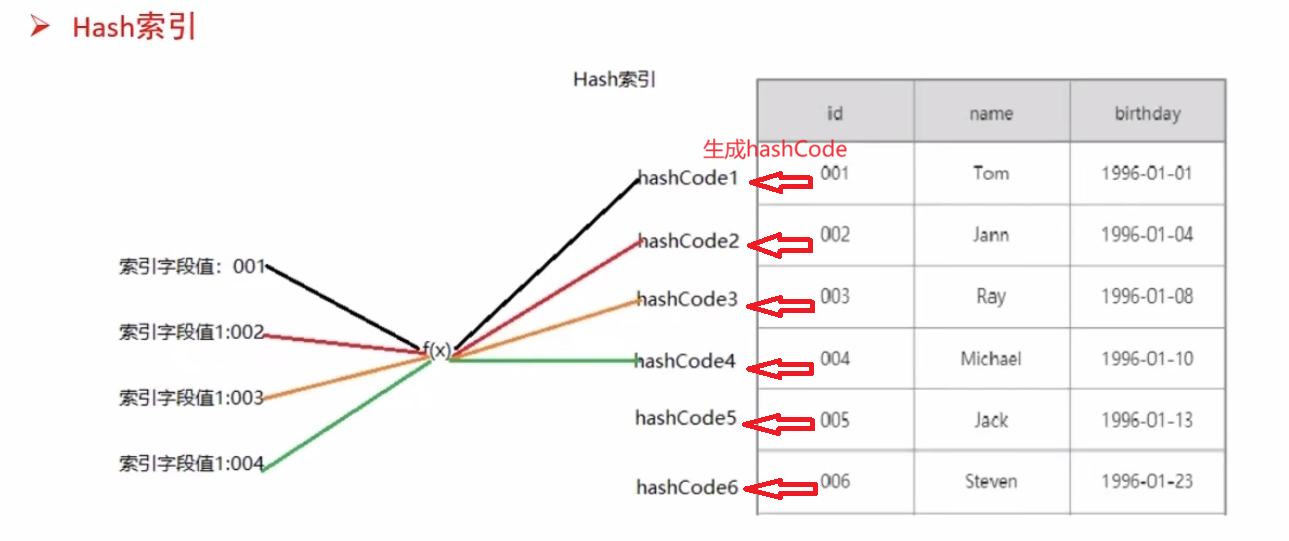
Hash索引讲解:
1、将所要查找的索引字段值放入公式f(x)中,从而会生成对应的HashCode值,所算出来的HashCode值会快速定位对应相应表中的行数据,从而达到快速查找。
2、若出现几个行数据所对应的hashCode相同【hash碰撞】,则会在这些对应相同的hashCode的行数据中进行顺序查找操作,直到找到为止。
B+Tree索引
B+Tree索引的数据结构为B+树【多叉树结构】,MySQL索引的本质就是B+Tree的数据结构。
节点存储的是【区间】,叶子节点存储的是【数据记录的地址】;叶子节点处形成链表,便于锁定区间【头,尾】,易获取值。
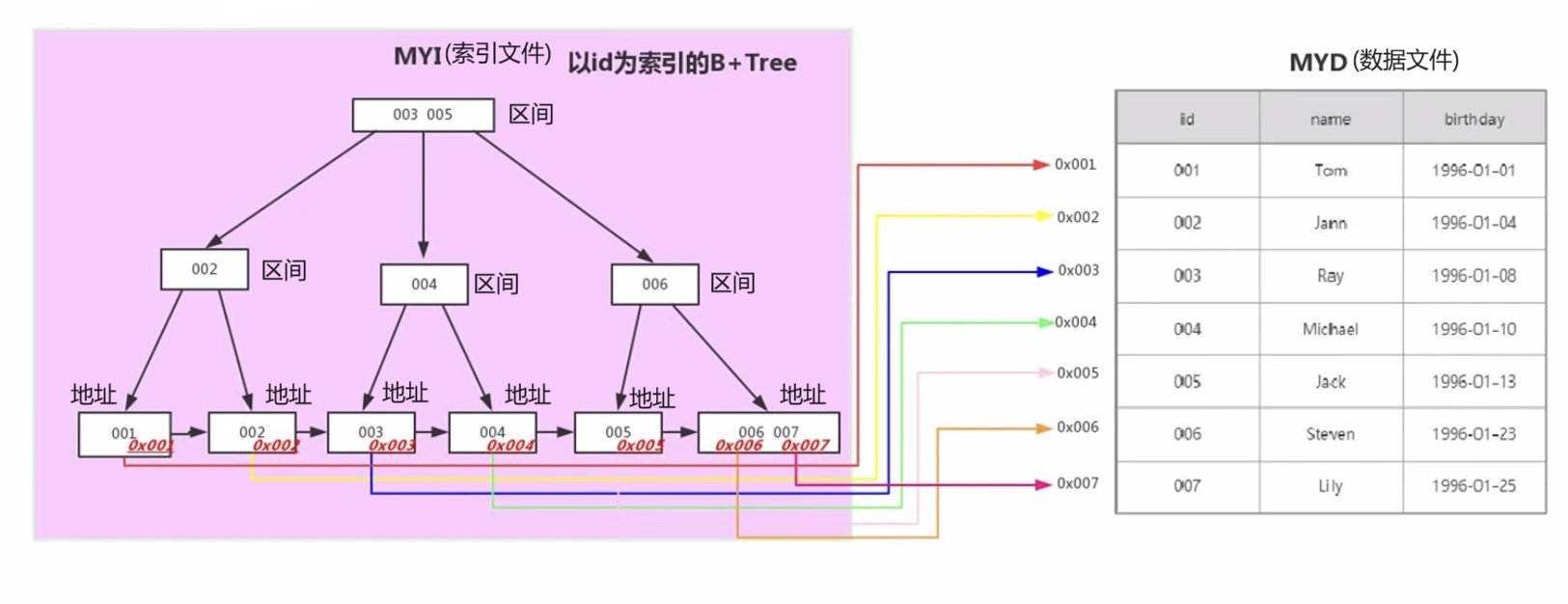
详细分析:
Mysql查询语句:
select * from tableTest where id = 2;
底层原理分析:
由于是根据id来建索引的,因此会根据id来进行查找。
其中内部节点会根据节点存储的键值来决定进入哪个子节点,一直进行查找,
最终找到所在id的叶子节点。
叶子节点处所存储的是数据记录的地址,通过地址来找到与之相对应的行数据。
3、索引的优点
- 借助数据结构,实现快速检索
4、索引的缺点
- 占用表空间,挤压数据的存储。
- 维持平衡的开销大
5、索引失效的场景
-
数据量少的表不要使用索引
-
where之后未加索引字段【注意:许多查询语句都需要用这字段【where后面出现的频次高】,适合建立索引】
-
重复数据多且更新频繁的字段不建议设置索引。
-
where name like ‘%男’【左边有%,就无法建立,右边有无无影响】
6、常用索引实际应用
索引在功能上可分类为单列索引【普通索引,唯一索引,主键索引】,组合索引,全文索引,空间索引。
查看索引
-- show index from 表名
show index from student;
删除索引
-- drop index 索引名 on 表名
drop index index_name on student;
创建索引
一:单列索引操作
单列索引介绍:一个索引只包含单个列,而一个表中可含有多个单列索引。
普通索引
要求:无任何限制,任意的列都能作为普通索引。
-- 创建索引
-- create index 索引名称 on 表(字段名)
create index name_index on student(name);
-- 修改表结构(添加索引)
-- alter table 表 add index 索引名(字段名)
alter table student add index index_age(age);
唯一索引
要求:列中的值必须是唯一的,不可重复,但允许为空
-- 创建索引
-- create unique index 索引名 on 表(字段名)
create unique index index_card_id on student(card_id);
-- 修改表结构(添加索引)
-- alter table 表 add unique 索引名(字段名)
alter table student add unique index_phone_num(phone_num);
主键索引
说明:mysql会自动在主键列上建立一个索引【唯一且非null】
二:组合索引操作
要求:多个字段进行组合,列值组合必须唯一【查询时,遵循最左原则,即:查询条件中包含(phone_num字段)或(phone_num字段和name字段),索引才会生效】
-- 组合索引(普通索引组合)
-- create index index 索引名 on 表(列1,列2,..)
create index index_phone_name on student(phone_num,name);
-- 组合索引(唯一索引组合)
-- create unique index 索引名 on 表(列1,列2,..)
create unique index index_phone_name on student(phone_num,name);
二、MySQL事务
1、何为事务?
事务是数据库管理系统执行过程中的一个逻辑单位,它由一个或多个SQL语句组成,这些语句作为一个整体一起向系统提交,要么全部执行,要么全部不执行。
2、事务的特性
-
原子性:事务是一个不可再分的整体,要么全部执行,要么全部不执行。
-
一致性:事务必须使数据库从一个一致性状态变换到另一个一致性状态。例如:对于转账而言,两者转账前钱的总和与转账后钱的总和要一样,否则会出错。
-
隔离性:保证在数据库系统中并发执行的事务不会相互干扰,每个事务看起来就像在独立运行,避免了数据错乱和不一致的问题。
事务的隔离级别:

-
持久性:事务一旦提交(commit),就会进行落盘操作,无法再改变。
3、事务的实际操作
事务有三大操作:开启事务(begin),回滚事务(rollback),提交事务(commit)。
此处,以账户转账的案例来讲解事务的运用。
-- 创建account账户信息表
create table if not exists account(
id int primary key auto_increment,
name varchar(255),
money double
);
-- 插入数据
insert into account values
(1,'猪猪侠',1000),
(2,'小菲菲',1000);
# 事务案例:账户转账
-- 设置 MySQL 的事务为手动提交(关闭自动提交)
-- 查看状态
select @@autocommit; // 1为自动提交,0为手动提交
-- 关闭自动提交
set autocommit = 0;
-- 模拟账户转账
-- 【开启事务】
begin;
-- 开始转账操作
update account set money = money - 520 where `name` = '猪猪侠';
update account set money = money + 520 where `name` = '小菲菲';
-- 查看转账结果
select * from account;
-- 若易过程中遇到错误,则【回滚事务】至原来状态,此时数据存储在【内存】,还未落盘(二选一)
rollback;
-- 若没有问题,则【提交事务】,【落盘】,不可再进行回滚操作(二选一)
commit;
-- 开启自动提交
set autocommit = 1;
三、MySQL锁机制
1、何为锁?
锁是协调多个事务同时并发访问相同资源的机制(避免争抢),确保数据的完整性和一致性,避免多个事务同时对同一数据造成冲突和错误。当多客户端来访问共享资源时,可通过锁机制来保证共享资源可以得到合理访问。
2、锁的分类
从数据操作的粒度来划分:表锁,行锁。
表锁解释:操作是会锁定整个表
行锁解释:操作时会锁定当前操作行
从数据操作的角度来划分:读锁(共享锁),写锁(排他锁)。
读锁(共享锁):简称S,对于同一份数据,读操作可以同时进行且互不干扰。
写锁(排他锁):简称X,当前操作还未完成前,他会阻断其他写锁和读锁操作。
表锁操作:
一:读锁(共享锁)
对【表R】添加读锁时,**只能操作被上读锁的那张【表R】**进行select查找操作,无法对其他表进行select查找操作。
-- 添加读锁
-- 语法:lock table 表名 read;
lock table tb_lock read;
-- 释放锁
unlock tables;
二:写锁(排他锁)
当【用户A】对【表R】添加写锁时,【用户A】可以对表R进行查找或修改操作,其他用户无法对【表R】进行读取或修改等操作,以及对【表R】添加任意锁操作,直到【用户A】释放锁。
-- 添加写锁
-- 语法:lock table 表名 write;
lock table tb_lock write;
-- 释放锁
unlock tables;
行锁操作:
注意:增删改时会自动添加
一:读锁(共享锁)
select * from 表名 where 条件 lock in share mode
二:写锁(排他锁)
select * from 表名 where 条件 for update
-- 添加写锁
-- 语法:lock table 表名 write;
lock table tb_lock write;
-- 释放锁
unlock tables;
行锁操作:
注意:增删改时会自动添加
一:读锁(共享锁)
select * from 表名 where 条件 lock in share mode
二:写锁(排他锁)
select * from 表名 where 条件 for update



![[紧急!!!]20240719全球Windows10/11蓝屏问题,CrowdStrike导致的错误解决方案](https://i-blog.csdnimg.cn/direct/4e02b7cfbfa340748d1ce43f3d7f51b4.png)