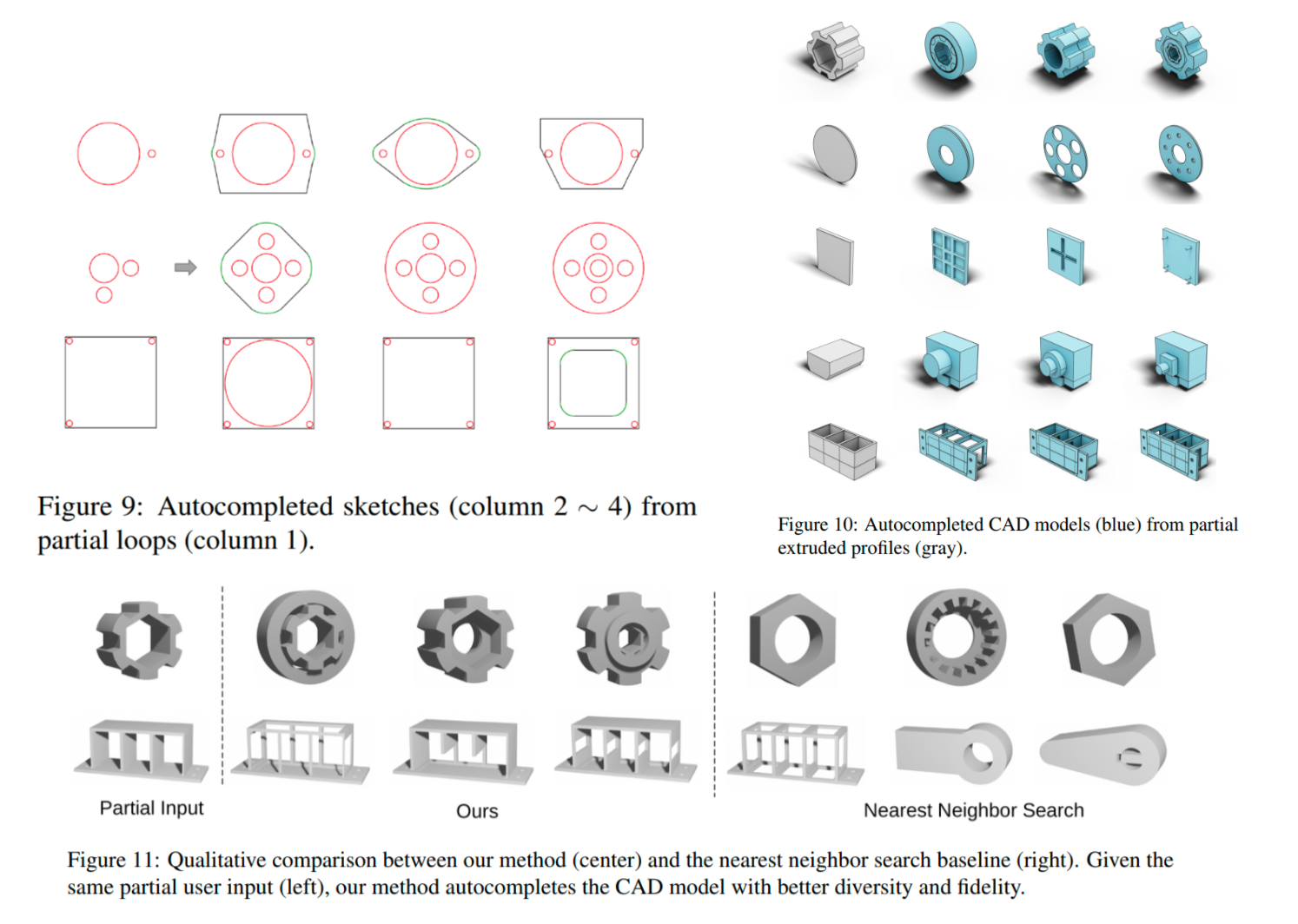
概述
SGI-STL与C++标准库提供的STL一样,都通过空间配置器allocator来申请或释放容器的空间。空间配置器的作用可以参考:浅谈C++空间配置器allocator及其重要性
// C++标准库的vector
template < class T, class Alloc = allocator<T> >
class vector;
// SGI-STL中的vector
template <class _Tp, class _Alloc = __STL_DEFAULT_ALLOCATOR(_Tp) >
class vector : protected _Vector_base<_Tp, _Alloc> ;C++标准库中只有一种空间配置器实现


而SGI-STL中有两种空间配置器实现,它们分别被叫做一级空间配置器和二级空间配置器。一级空间配置器用来处理大小大于128字节的大内存,二级空间配置器用来管理大小小于等于128字节的小内存。SGI-STL是使用一级空间配置器还是二级空间配置器是由__USE_MALLOC宏来控制的,默认是使用二级空间配置器。
# ifdef __USE_MALLOC
typedef malloc_alloc alloc;
typedef malloc_alloc single_client_alloc;
# else
... // 二级空间配置器的定义与实现
# endif从SGI-STL中vector的定义可以看到,SGI-STL容器的默认空间配置器是__STL_DEFAULT_ALLOCATOR( _Tp),它是一个宏定义
# ifndef __STL_DEFAULT_ALLOCATOR
# ifdef __STL_USE_STD_ALLOCATORS
# define __STL_DEFAULT_ALLOCATOR(T) allocator< T >
# else
# define __STL_DEFAULT_ALLOCATOR(T) alloc
# endif
# endif从上面可以看出来__STL_DEFAULT_ALLOCATOR通过宏来控制两种实现,一种是allocator< T >,另一种是alloc,这两种分别就是SGI STL的一级空间配置器和二级空间配置器的实现。
// 一级空间配置器
template <int __inst>
class __malloc_alloc_template;
// 二级空间配置器
template <bool threads, int inst>
class __default_alloc_template;一级空间配置器与C++标准中一样,通过malloc和free来管理空间。
// 一级空间配置器
template <int __inst>
class __malloc_alloc_template {
private:
static void* _S_oom_malloc(size_t); // malloc申请空间失败时的应急处理函数
static void* _S_oom_realloc(void*, size_t); // realloc的应急处理函数
#ifndef __STL_STATIC_TEMPLATE_MEMBER_BUG
// 定义名叫__malloc_alloc_oom_handler的函数指针,类型为void(*)()
static void (* __malloc_alloc_oom_handler)();
#endif
public:
// 封装malloc来申请空间
static void* allocate(size_t __n)
{
void* __result = malloc(__n);
if (0 == __result) __result = _S_oom_malloc(__n); // 如果申请失败则调用_S_oom_malloc来进行处理
return __result;
}
// 封装free来释放空间
static void deallocate(void* __p, size_t /* __n */)
{
free(__p);
}
static void* reallocate(void* __p, size_t /* old_sz */, size_t __new_sz)
{
void* __result = realloc(__p, __new_sz);
if (0 == __result) __result = _S_oom_realloc(__p, __new_sz);
return __result;
}
// 设定malloc的应急处理函数
// 这个函数叫做__set_malloc_handler,参数为函数指针,返回值也为函数指针
// 参数为__f,其类型为void(*)()
// 返回值类型为void(*)()
static void (* __set_malloc_handler(void (*__f)()))()
{
void (* __old)() = __malloc_alloc_oom_handler;
__malloc_alloc_oom_handler = __f;
return(__old);
}
};
而二级空间配置器是通过基于freelist自由链表的内存池的方式来管理内存,同时二级空间配置器在分配空间有困难时也会借助一级空间配置器来完成分配任务或处理事件,本文之后会有更详细的分析。
剖析SGI-STL二级空间配置器
内存池
内存池是池化技术的一种典型应用,内存池在真正使用内存之前,会预先申请分配一定数量的、大小相等(或相近)的内存块留作备用。当有新的内存需求时,就从内存池中分出一部分内存块给申请者使用。如果内存池中的内存块不够,则再继续申请新的内存块。这种方式避免了频繁地向系统申请和释放内存,从而减少了内存分配和释放的开销,提高了程序的执行效率。
内存池可以防止小块内存频繁的分配、释放,从而导致内存中存在很多碎片,没有很多连续的大内存块。所以对于小块内存的操作,一般都会使用内存池来管理。
内存池中的重要类型与变量定义
// 描述内存池的粒度信息
enum {_ALIGN = 8}; // 以8字节内存对齐
enum {_MAX_BYTES = 128}; // 内存池中管理内存的最大大小
enum {_NFREELISTS = 16}; // _MAX_BYTES/_ALIGN,内存池中自由链表的数量
// 每一个内存chunk块的头信息
union _Obj {
union _Obj* _M_free_list_link; // 类似于链表的next指针,指向下一个空闲chunk块
char _M_client_data[1]; // client see this,这里的1只是一个占位符
};
// 组织所有自由链表的数组,数组的每一个元素的类型是_Obj*,全部初始化为0(NULL)
static _Obj* __STL_VOLATILE _S_free_list[_NFREELISTS]; 自由链表通常由一系列的内存块组成,这些内存块被组织成一个或多个链表。每个内存块都有一个头部(header)区域,用于存储管理信息,如内存块的大小、是否空闲、以及指向下一个空闲内存块的指针(如果有的话)。当内存块被分配时,它的头部信息会被更新以反映其状态(不再空闲),并且它会被从链表中移除。当内存块被释放时,它的头部信息会被更新以表明它是空闲的,并且它会被重新添加到适当的链表中,以便后续分配。
因为自由链表是由一系列的内存块组成,所有它在空间上往往是连续的。

二级空间配置器中自由链表节点的头就为联合体_Obj。这个联合体有两个成员:
1、union _Obj* _M_free_list_link:这是一个指向下一个union _Obj的指针,用于在自由链表中维护未分配的内存块。当内存块未被使用时,这个指针用于将内存块连接成一个链表,方便管理。
2、char _M_client_data[1]:这是一个长度为1的字符数组。虽然它本身只占用1个字节的空间,但其主要作用是作为内存块的首地址的占位符。由于union的特性,client_data和free_list_link共享同一块内存空间。当内存块被分配给客户端使用时,client_data[0](即整个union _Obj的地址)作为内存块的起始地址返回给客户端,客户端可以通过这个地址访问整个内存块。
union _Obj是一个设计精巧的结构体,它通过联合体的特性实现了小块内存的高效管理和灵活使用。 由于union的特性,union _Obj在作为链表节点时不需要额外的空间来存储链表指针,从而节省了空间;当内存块被分配给客户端时,客户端可以通过client_data直接访问整个内存块,而不需要进行额外的类型转换或计算。
管理这些自由链表的是一个数组static _Obj* __STL_VOLATILE _S_free_list[_NFREELISTS]。由于该数组用static修饰所以在数据段上,所以用__STL_VOLATILE(其实就是对C++中的volatile进行了封装)修饰,防止在多线程环境中线程对该数据进行缓存(放到寄存器中)导致多个线程看到的数据版本不一致,以便及时看到其他线程对该资源的修改。在多线程中程序中,堆内存资源往往会用volatile修饰。
数组的成员是_Obj*类型的指针,它们指向不同大小的chunk块。chunk块的大小是8的倍数,以8字节为起点,一直到128字节为止。

二级空间配置器在分配内存时还需要三个变量来记录内存分配的情况,这三个变量在后续讲到分配内存的流程时会涉及到。
// Chunk allocation state. 记录内存chunk块的分配情况
// 用来标记内存池中还未使用的大块内存的起始与末尾位置
static char* _S_start_free;
static char* _S_end_free;
// 用来记录该空间配置器已经想系统申请了多少字节的内存
static size_t _S_heap_size;
// 将这三个变量初始化
template <bool __threads, int __inst>
char* __default_alloc_template<__threads, __inst>::_S_start_free = 0;
template <bool __threads, int __inst>
char* __default_alloc_template<__threads, __inst>::_S_end_free = 0;
template <bool __threads, int __inst>
size_t __default_alloc_template<__threads, __inst>::_S_heap_size = 0;重要的辅助接口函数
/* 将 __bytes 上调至最邻近的 8 的倍数 */
static size_t _S_round_up(size_t __bytes)
{ return (((__bytes) + (size_t)_ALIGN - 1) & ~((size_t)_ALIGN - 1)); }
/* 返回 __bytes 大小的chunk块位于 free-list 中的编号 */
static size_t _S_freelist_index(size_t __bytes) {
return (((__bytes) + (size_t)_ALIGN - 1) / (size_t)_ALIGN - 1); }在内存池的实现中,会频繁的用到这两个函数,我们来看看它们是如何达到它们想要的效果的。
_S_round_up
容器在申请小块空间时,会通过该函数将用户想要申请的空间大小上调至最邻近的 8 的倍数。如果用户想申请15字节的空间,_S_round_up会将其上升至16字节;如果用户想申请57个字节,会将其上升至64字节。
1、2、3、...... -> 8
9、10、11、...... -> 16
...我们首先来看按位与后面的部分
~((size_t)_ALIGN - 1)首先将_ALIGN强转为无符号4字节(看环境,x86为4字节,x64为8字节)大小整形,然后减去1,最后再按位取反,这里以x86为例
00000000 00000000 00000000 00001000 -》 (size_t)_ALIGN
00000000 00000000 00000000 00000111 -》 (size_t)_ALIGN - 1
11111111 11111111 11111111 11111000 -》~((size_t)_ALIGN - 1)所以该部分总体上起到了将1000前面的0全部取反但自身保持不变的效果。因为之后会进行按位与,所以其目的是在进行按位与操作时,将对方高位上的1全部留下来。
如果我们将后半部分进行输出,可以看到这样的结果
~((size_t)_ALIGN - 1) = 18446744073709551608 //x64
~((size_t)_ALIGN - 1) = 4294967288 // x86
~(_ALIGN - 1) = -8会出现这种差异主要是_ALIGN原本是有符号的,操作完后会把最高位的1看作符号位,即负数,高位的1全部被当作负数的补码;而强转后为无符号数,最后的结果一定会是正数,所以高位的1全部作为数据位,正数的补码和原码是相同的,最后就是一个非常大的正数。
然后我们来整体来看一下
((__bytes) + (size_t) _ALIGN-1) & ~((size_t) _ALIGN - 1)
当__byte等于0时:
(size_t) _ALIGN-1 & ~((size_t) _ALIGN - 1 = 0
虽然一般也不会出现申请0字节的情况,但最后处理的结果没有任何问题
当__byte等于1时,后四位为1000;当__byte等于8时,后四位为1111
与 11111111 11111111 11111111 11111000 按位与后,后三位全部舍弃
只保留下第四位的1,即0B1000 = 8
当__byte等于9时,后五位为10000;当__byte等于16时,后五位为10111
与 11111111 11111111 11111111 11111000 按位与后,后三位全部舍弃
只保留下第五位的1,即0B10000 = 16
......
以此类推,该表达式的处理结果一直都是把后三位给舍弃掉,然后让高位上的1组合
如: 0001 000、0010 000、0011 000、0100 000、
0101 000、0110 000、0111 000、1000 000、
......
即8、16、24、32、40、......
最后得到的结果一直会是__bytes最邻近的 8 的倍数_S_freelist_index
_S_freelist_index的作用是计算__bytes大小的chunk块位于 free-list 中的编号。通俗易懂的来说,你可以把它理解为一个通过__bytes来计算数组下标的工具函数,事实上也确实如此。
((__bytes) + (size_t)_ALIGN - 1) / (size_t)_ALIGN - 1)
这个函数的计算过程为:
先计算 (__bytes) + (size_t)_ALIGN
再计算 (__bytes) + (size_t)_ALIGN - 1
然后计算 ((__bytes) + (size_t)_ALIGN - 1) / (size_t)_ALIGN
最后计算 ((__bytes) + (size_t)_ALIGN - 1) / (size_t)_ALIGN - 1
记住是算完了除法再减1而不是分母先减了1再相除
代入数值计算,最后会发现
数值 下标
0 -> 0
1、2、......、8 -> 0
9、10、......、16-> 1
17、18、......、24-> 2
......
符合我们之前画的图allocate
// 分配内存的入口函数
// 参数__n: 用户所需空间字节数
// 返回值:返回空间的首地址
static void* allocate(size_t __n) // __n 必须要 > 0
{
void* __ret = 0; // 返回值
if (__n > (size_t)_MAX_BYTES) { // 如果用户申请的空间大于128字节,就交付给一级空间配置器来申请空间
__ret = malloc_alloc::allocate(__n);
}
else {
_Obj* __STL_VOLATILE* __my_free_list // 定义一个二级指针指向数组中管理__n对应大小chunk块的位置
= _S_free_list + _S_freelist_index(__n);
// 通过构造函数来获取锁
// 这个确保当程序退出或离开作用域的时候会释放锁
# ifndef _NOTHREADS
/*REFERENCED*/
_Lock __lock_instance; // 利用RAII的锁,保护线程安全
# endif
_Obj* __RESTRICT __result = *__my_free_list; // 拿到__n对应位置的自由链表
if (__result == 0) // 如果对应位置没有chunk块则通过_S_refill申请chunk块
__ret = _S_refill(_S_round_up(__n)); // 会将用户申请的__n字节提升到最邻近的8的整数倍,再拿去申请空间
else { // 如果有的话就将第一个chunk块返回给用户,并将数组中指针指向原先的第二个chunk块
*__my_free_list = __result->_M_free_list_link;
__ret = __result;
}
}
return __ret;
};
//_Lock的实现类似C++标准库中的lock_guard
class _Lock {
public:
_Lock() { __NODE_ALLOCATOR_LOCK; }
~_Lock() { __NODE_ALLOCATOR_UNLOCK; }
};__my_free_list是一个二级指针,它指向的元素的数据类型为_Obj*,它指向_S_free_list(二级空间配置器中管理自由链表的数组) 的第 _S_freelist_index(__n)位置,如果你理解不了,可以这样想
_Obj* __STL_VOLATILE* __my_free_list = _S_free_list + _S_freelist_index(__n)
_Obj* volatile *__my_free_list = &_S_free_list[_S_freelist_index(__n)] ->
_Obj* volatile *__my_free_list = &(*(_S_free_list + _S_freelist_index(__n))) ->
_Obj* volatile *__my_free_list = = _S_free_list + _S_freelist_index(__n)
第一步到第二步是因为
array[n] = *(array + n)
第二步到第三步是因为
& 和 * 抵消掉了同理拿到__n对应位置的自由链表可以理解为
// 拿到__n对应位置的自由链表
_Obj* __RESTRICT __result = *__my_free_list
_Obj* __STL_VOLATILE* __my_free_list = _S_free_list + _S_freelist_index(__n)
和
_Obj* __RESTRICT __result = *__my_free_list
结合起来就是
_Obj* __RESTRICT __result = *(_S_free_list + _S_freelist_index(__n))
即
_Obj* __RESTRICT __result = _S_free_list[_S_freelist_index(__n)]
其实__result就是_S_free_list数组_S_freelist_index(__n)下标位置的内容,就是一个指向自由链表(chunk块)的指针现在,我们假设内存池中有足够的chunk块来大致了解一下allocate的执行流程

_S_refill
我们通过allocate发现,如果用户申请的内存大小对应的自由链表中没有chunk块,就会调用_S_refill,我们可以猜出来它肯定有申请空间和分配chunk的功能。
// 负责把分配好的chunk块进行连接,添加到自由链表当中
// 参数__n:想要申请的单个chunk块的字节数
// 返回值:首个chunk块的首地址
/* 返回大小为 __n 的对象,并可选择添加到大小为 __n 的空闲列表中。*/
/* 我们假设 __n 是正确对齐的。 */
/* 我们持有分配锁。 */
template <bool __threads, int __inst>
void*
__default_alloc_template<__threads, __inst>::_S_refill(size_t __n)
{
int __nobjs = 20; // 默认申请20个chunk块
char* __chunk = _S_chunk_alloc(__n, __nobjs); // 调用_S_chunk_alloc来申请内存,自己负责对申请出来的chunk的后续处理
_Obj* __STL_VOLATILE* __my_free_list; // 二级指针
_Obj* __result; // 返回值
_Obj* __current_obj; // 当前chunk块
_Obj* __next_obj; // 下一个chunk块
int __i; // 用于for循环的迭代变量
if (1 == __nobjs) return(__chunk); // 这里为什么会判断1 == __nobjs呢?因为_S_chunk_alloc中会改变它。如果只申请到了一个chunk块就直接返回给用户,因为不需要后续将chunk连接成自由链表的处理
__my_free_list = _S_free_list + _S_freelist_index(__n); // 找到新申请出的chunk块应该挂在数组的哪个位置
/* 在chunk块中构建自由链表 */
__result = (_Obj*)__chunk; // 返回第一个chunk块
*__my_free_list = __next_obj = (_Obj*)(__chunk + __n); // 将*__my_free_list = __next_obj都指向第二个chunk块
for (__i = 1; ; __i++) { // 死循环
// 更新__current_obj和__next_obj
__current_obj = __next_obj;
__next_obj = (_Obj*)((char*)__next_obj + __n);
if (__nobjs - 1 == __i) { // 处理最后一个chunk块
__current_obj -> _M_free_list_link = 0;
break;
} else {
// 与普通链表一样,连接节点
__current_obj -> _M_free_list_link = __next_obj;
}
}
return(__result);
}__nobjs会作为输入输出型参数传入函数_S_chunk_alloc中,传入时的含义是默认开辟chunk块的数量,传出时的含义是真正开辟出的chunk块的数量,这可以用于确定后面连接chunk时需要的循环次数。
template <bool __threads, int __inst>
char*
__default_alloc_template<__threads, __inst>::_S_chunk_alloc(size_t __size,
int& __nobjs)
// __nobjs是通过引用传入的用来将chunk块连接成自由链表的for循环,表面上是死循环,其实是通过临界条件在for循环体内来结束for循环,可以写成
for (__i = 1; __i <= __nobjs - 1; __i++)
{ ... }这么写可能是因为,for循环体内一定要对最后一个节点做特殊处理,一定会判断临界条件,为了避免一个for循环内出现两次相同的临界条件判断,所以删除了for循环本身的判断。
因为第一个chunk块是需要分配给用户的,所以不需要把它连接到自由链表中,所以最后的循环次数是__nobjs - 1次,恰好可以把除了头chunk块的所有chunk块连接起来。
// allocate中调用_S_refill
__ret = _S_refill(_S_round_up(__n));
// _S_refill的一些片段
template <bool __threads, int __inst>
void*
__default_alloc_template<__threads, __inst>::_S_refill(size_t __n)
char* __chunk = _S_chunk_alloc(__n, __nobjs);allocate中调用_S_refill函数时,是把经过_S_round_up处理过参数传入的。所以_S_refill中的参数__n一定是8的整数倍,根据该大小开辟出的chunk块一定可以归属于某个自由链表。我们接下来看如何将chunk块连接起来。
char* __chunk = _S_chunk_alloc(__n, __nobjs);
// 将*__my_free_list = __next_obj都指向第二个chunk块
*__my_free_list = __next_obj = (_Obj*)(__chunk + __n); 首先这是一个连续赋值语句, *__my_free_list 和 __next_obj 最后都会等于(_Obj*)(__chunk + __n)。那么(_Obj*)(__chunk + __n)是什么呢?
因为__chunk是char*类型,所以每次++(+ 1)都会向后走一个字节的大小。这里__chunk是开辟出内存的首地址,也是第一个chunk块的地址,我们之前说过,每次一起开辟出来的chunk块的内存都是连续的,或者说是把开辟出来的一大块空间在逻辑上划分成多个chunk块。所以第一个chunk块的首地址在向后走__n个字节(chunk块自身的大小)就是第二个chunk块的首地址,以此类推就能够找到任意一个chunk块的首地址。
在找到第二个chunk块后,就把它的地址强转成_Obj*类型,然后赋值给自由链表数组中的对应位置,之后我们想再次申请对应大小的chunk块的时候就能直接找到了。
_Obj* __current_obj; // 当前chunk块
*__my_free_list = __next_obj = (_Obj*)(__chunk + __n);
for (__i = 1; __i <= __nobjs - 1; __i++) {
// 更新__current_obj和__next_obj
__current_obj = __next_obj;
__next_obj = (_Obj*)((char*)__next_obj + __n);
if (__nobjs - 1 == __i) { // 处理最后一个chunk块
__current_obj->_M_free_list_link = 0;
break;
}
else {
// 与普通链表一样,连接节点
__current_obj->_M_free_list_link = __next_obj;
}
}for循环内也是这样确定每个内存块的地址的,先将__next_obj强转成char*类型,这样+1就只会向后走一个字节。确定了每个chunk块的地址后,就把它赋值给上一个chunk块的__next_obj指针,这样就能把chunk块连接成自由链表了。
_S_chunk_alloc
_S_chunk_alloc是用来开辟被划分成chunk的内存空间的。
/* 为了避免过分碎片化malloc堆,我们通过大的chunk块来分配内存 */
/* 我们假设__size已正确对齐。 */
/* 我们持有分配锁。 */
template <bool __threads, int __inst>
char*
__default_alloc_template<__threads, __inst>::_S_chunk_alloc(size_t __size,
int& __nobjs)
{
char* __result; // 返回值
size_t __total_bytes = __size * __nobjs; // 开辟__nobjs个大小为__size的chunk块需要多少字节的内存
size_t __bytes_left = _S_end_free - _S_start_free; // 之前开辟剩下的备用内存块有多少字节
if (__bytes_left >= __total_bytes) { // 之前剩下的内存块的大小大于本次总共需要申请的内存大小
__result = _S_start_free;
_S_start_free += __total_bytes;
return(__result);
} else if (__bytes_left >= __size) { // 之前剩下的内存块不满足上述情况,但是至少能分配一个__size大小的chunk块
__nobjs = (int)(__bytes_left/__size);
__total_bytes = __size * __nobjs;
__result = _S_start_free;
_S_start_free += __total_bytes;
return(__result);
} else { // 之前剩下的内存块一个__size大小的chunk块都分配不出来
size_t __bytes_to_get =
2 * __total_bytes + _S_round_up(_S_heap_size >> 4);
// 尽量利用剩下的残羹剩饭内存
if (__bytes_left > 0) {
_Obj* __STL_VOLATILE* __my_free_list =
_S_free_list + _S_freelist_index(__bytes_left);
((_Obj*)_S_start_free) -> _M_free_list_link = *__my_free_list;
*__my_free_list = (_Obj*)_S_start_free;
}
_S_start_free = (char*)malloc(__bytes_to_get);
if (0 == _S_start_free) {
size_t __i;
_Obj* __STL_VOLATILE* __my_free_list;
_Obj* __p;
// 尽量利用我们现有的资源。这不会有什么坏处。
// 我们不会尝试更小的请求,因为这往往会在多进程机器上造成灾难.
for (__i = __size;
__i <= (size_t) _MAX_BYTES;
__i += (size_t) _ALIGN) {
__my_free_list = _S_free_list + _S_freelist_index(__i);
__p = *__my_free_list;
if (0 != __p) {
*__my_free_list = __p -> _M_free_list_link;
_S_start_free = (char*)__p;
_S_end_free = _S_start_free + __i;
return(_S_chunk_alloc(__size, __nobjs));
// Any leftover piece will eventually make it to the
// right free list.
}
}
_S_end_free = 0; // 异常情况
_S_start_free = (char*)malloc_alloc::allocate(__bytes_to_get);
// 这样做要么会出现异常,要么会纠正这种情况。因此,我们假设它成功了。
}
_S_heap_size += __bytes_to_get;
_S_end_free = _S_start_free + __bytes_to_get;
return(_S_chunk_alloc(__size, __nobjs));
}
}可以看出来,这个函数非常的大,并且处理了很多的情况,为了分析方便,我们把它拆分出来分析。
情况1、第一次调用该函数申请chunk块内存(无剩余内存块)
// 有关的静态成员变量
template <bool __threads, int __inst>
char* __default_alloc_template<__threads, __inst>::_S_start_free = 0; // 剩余内存块的起始位置
template <bool __threads, int __inst>
char* __default_alloc_template<__threads, __inst>::_S_end_free = 0; // 剩余内存块的结束位置
template <bool __threads, int __inst>
size_t __default_alloc_template<__threads, __inst>::_S_heap_size = 0; // 所有的二级空间配置器一共申请过多少堆内存
// 部分片段
template <bool __threads, int __inst>
char*
__default_alloc_template<__threads, __inst>::_S_chunk_alloc(size_t __size,
int& __nobjs)
{
char* __result; // 返回值
size_t __total_bytes = __size * __nobjs; // 开辟__nobjs个大小为__size的chunk块需要多少字节的内存
size_t __bytes_left = _S_end_free - _S_start_free; // 之前开辟剩下的备用内存块有多少字节
if (__bytes_left >= __total_bytes) { // 之前剩下的内存块的大小大于本次总共需要申请的内存大小
......
} else if (__bytes_left >= __size) { // 之前剩下的内存块不满足上述情况,但是至少能分配一个__size大小的chunk块
......
} else { // 之前剩下的内存块一个__size大小的chunk块都分配不出来
size_t __bytes_to_get =
2 * __total_bytes + _S_round_up(_S_heap_size >> 4); // _S_heap_size >> 4 == _S_heap_size / 2^4
// 尽量利用剩下的残羹剩饭内存
if (__bytes_left > 0) {
......
}
_S_start_free = (char*)malloc(__bytes_to_get);
if (0 == _S_start_free) {
......
}
_S_heap_size += __bytes_to_get;
_S_end_free = _S_start_free + __bytes_to_get;
return(_S_chunk_alloc(__size, __nobjs));
}
}我们假设__size为8,所以我们开辟20个chunk块所需要的字节数为 8 * 20 = 160字节。又因为我们是第一次申请内存,所以_S_end_free 和 _S_start_free都为0,即之前剩余的内存块大小为0字节。在后续的判断中,我们毫无疑问的会进入eles语句。
进入else语句之后,我们会计算得到实际上真正申请的字节数为2倍的20个chunk块需要的字节数(即40个__size大小的chunk块)再加上之前一共开辟过的内存大小除以16后向上取8的倍数。这里我们算的结果为320字节(40 * 8),因为我们之前没有剩余内存,所以我们会直接通过malloc申请内存,我们假设申请成功,_S_start_free就会指向申请出来的空间。将_S_heap_size加上我们本次申请的字节大小,再让_S_end_free指向申请出来的空间末尾,最后递归调用本身来再次分配块。
if (__bytes_left >= __total_bytes) {
__result = _S_start_free;
_S_start_free += __total_bytes;
return(__result);
}递归之后,我们就会进入if语句。让返回值指针指向剩余内存块的头,然后让_S_start_free指针向后走20个__size内存块的大小(即我们还会剩下20个内存块的大小,如果不是第一次开辟chunk块内存,在系统空间足够的情况下还会有更多剩余内存),最后将20个chunk块的内存首地址返回回去,交由_S_refill处理。

情况2、有剩余内存块且该内存块至少能构造出一个目标大小的chunk块
if (__bytes_left >= __total_bytes) { // 之前剩下的内存块的大小大于本次总共需要申请的内存大小
__result = _S_start_free;
_S_start_free += __total_bytes;
return(__result);
}
else if (__bytes_left >= __size) { // 之前剩下的内存块不满足上述情况,但是至少能分配一个__size大小的chunk块
__nobjs = (int)(__bytes_left / __size);
__total_bytes = __size * __nobjs;
__result = _S_start_free;
_S_start_free += __total_bytes;
return(__result);
}
else{
......
}其实本情况中也有3种情况,但由于差别不是特别大就放在一起来讲述。
我们再上述情况1的基础上,再假设__size分别等于8、16和128。
当__size等于8时,函数会进入if语句,因为上次的剩余内存块为160字节,而当__size等于8时__total_bytes也为160字节,剩下的操作就和情况1递归后进入if语句一样,只不过这次把剩余内存块消耗完了,所以下一次再申请chunk块时,就会进入情况1。
当__size等于16时,函数会进入else if语句。else if中会把__nobjs更改为剩余空间最多能划分成__size大小chunk块的数量,然后计算这些chunk消耗了多少字节的剩余空间,将_S_start_free向后移动这些字节大小的距离,最后将那些被分配出去的内存块首地址返回回去。因为160刚好为16的倍数,所以最后剩余内存块大小为0字节,下一次申请chunk块内存又会回到情况1.
当__size等于128时,函数会进入else if语句,执行流程大体上与__size等于16时相同,只有一个不一样的地方就是,160不能被128整除,所以这次在分配出去1个128字节大小的chunk块后会有剩余空间,就是这点差别可能会导致情况3。

情况3、有剩余内存块,但是一个目标大小的chunk块也构造不出来。
if (__bytes_left >= __total_bytes) { // 之前剩下的内存块的大小大于本次总共需要申请的内存大小
...
}
else if (__bytes_left >= __size) { // 之前剩下的内存块不满足上述情况,但是至少能分配一个
...
}
else { // 之前剩下的内存块一个__size大小的chunk块都分配不出来
size_t __bytes_to_get =
2 * __total_bytes + _S_round_up(_S_heap_size >> 4);
// 尽量利用剩下的残羹剩饭内存
if (__bytes_left > 0) {
_Obj* __STL_VOLATILE* __my_free_list =
_S_free_list + _S_freelist_index(__bytes_left);
((_Obj*)_S_start_free)->_M_free_list_link = *__my_free_list;
*__my_free_list = (_Obj*)_S_start_free;
}
_S_start_free = (char*)malloc(__bytes_to_get);
if (0 == _S_start_free) {
...
}
_S_heap_size += __bytes_to_get;
_S_end_free = _S_start_free + __bytes_to_get;
return(_S_chunk_alloc(__size, __nobjs));
}在经历过情况2的__size等于128后,我们再令__size等于40来申请空间。
这次我们会进入else语句中,我们再计算完__bytes_to_get(本次为 2 * 800 + _S_round_up(320 / 16) 即 1600 + 24 = 1624)后会因为__bytes_left(本次为32) > 0而进入if语句中。该if语句的主要功能为将剩余的内存块大小划分到单个chunk块大小与其一致的自由链表中,充分利用了剩余空间。且因为之后_S_start_free和_S_end_free会指向新申请的内存块,新申请的内存块与旧内存块可能并不是连续的,所以这也是为了避免内存泄漏。之后的流程就与情况1一样了。

异常情况、系统内存资源不足
当内存池中没有剩余内存块时(即情况1),我们想要直接借助malloc来申请内存块,但是非常可惜,系统中的内存也不够了就会导致_S_start_free == 0,为了处理这种情况。设计者设计了两种处理方法。
向别人借一点
if (__bytes_left >= __total_bytes) { // 之前剩下的内存块的大小大于本次总共需要申请的内存大小
...
}
else if (__bytes_left >= __size) { // 之前剩下的内存块不满足上述情况,但是至少能分配一个__size大小的chunk块
...
}
else { // 之前剩下的内存块一个__size大小的chunk块都分配不出来
size_t __bytes_to_get =
2 * __total_bytes + _S_round_up(_S_heap_size >> 4);
// 尽量利用剩下的残羹剩饭内存
if (__bytes_left > 0) {
...
}
_S_start_free = (char*)malloc(__bytes_to_get);
if (0 == _S_start_free) {
size_t __i; // for循环迭代变量
_Obj* __STL_VOLATILE* __my_free_list; // 二级指针
_Obj* __p; // 目标自由链表
// 尽量利用我们现有的资源。这不会有什么坏处。
// 我们不会尝试更小的请求,因为这往往会在多进程机器上造成灾难.
for (__i = __size;
__i <= (size_t)_MAX_BYTES;
__i += (size_t)_ALIGN) {
__my_free_list = _S_free_list + _S_freelist_index(__i);
__p = *__my_free_list;
if (0 != __p) {
*__my_free_list = __p->_M_free_list_link;
_S_start_free = (char*)__p;
_S_end_free = _S_start_free + __i;
return(_S_chunk_alloc(__size, __nobjs));
// 任何剩下的部分最终都会进入正确的自由链表。
}
}
_S_end_free = 0; // 异常情况
_S_start_free = (char*)malloc_alloc::allocate(__bytes_to_get);
// 这样做要么会出现异常,要么会纠正这种情况。因此,我们假设它成功了。
}
_S_heap_size += __bytes_to_get;
_S_end_free = _S_start_free + __bytes_to_get;
return(_S_chunk_alloc(__size, __nobjs));
}在申请空间失败后,会进入for循环。该for循环的功能为,从当前目标大小chunk对应的自由链表开始,一个一个的向后搜索更大的chunk块对应的自由链表有没有空闲的chunk块,如果没有(即 __p == 0)就继续搜索下一个自由链表,直到搜索完128字节chunk块对应的自由链表。如果搜索到了就向它借一个chunk块。__S_start_free会指向借到的chunk块的起始地址,_S_end_free会指向借到的chunk块的末尾地址,然后再递归调用自己,进入情况2。
我们假设__size等于40,向chunk块为48字节的自由链表借一个chunk块。

注:当借用的40字节chunk使用完后,会直接归还到40字节chunk块对应的自由链表。
通过一级空间配置器来进行紧急处理
当内存池中连一个可以借的chunk块都没有的时候,就只能借助其他方式了。
_S_end_free = 0; // 异常情况
_S_start_free = (char*)malloc_alloc::allocate(__bytes_to_get);首先会将_S_end_free重新设置成0,然后就会借助一级空间配置器来做紧急处理。
// 封装malloc来申请空间
static void* allocate(size_t __n)
{
void* __result = malloc(__n);
if (0 == __result) __result = _S_oom_malloc(__n); // 如果申请失败则调用_S_oom_malloc来进行处理
return __result;
}如果一级空间配置器申请到了空间,就会直接返回。如果没有,就要调用_S_oom_malloc做最后的挣扎。
// 设定malloc的应急处理函数
// 这个函数叫做__set_malloc_handler,参数为函数指针,返回值也为函数指针
// 参数为__f,其类型为void(*)()
// 返回值类型为void(*)()
static void (* __set_malloc_handler(void (*__f)()))() // 该函数在一级空间配置器中
{
void (* __old)() = __malloc_alloc_oom_handler;
__malloc_alloc_oom_handler = __f;
return(__old);
}
template <int __inst>
void*
__malloc_alloc_template<__inst>::_S_oom_malloc(size_t __n)
{
void (* __my_malloc_handler)();
void* __result;
for (;;) {
__my_malloc_handler = __malloc_alloc_oom_handler;
if (0 == __my_malloc_handler) { __THROW_BAD_ALLOC; }
(*__my_malloc_handler)();
__result = malloc(__n);
if (__result) return(__result);
}
}__my_malloc_handler是可以让用户借助一级空间配置器中的__set_malloc_handler自行设置的应急处理函数,用来处理系统内存不足的情况。如果用户没有设置回调函数的话,就会抛出异常或打印错误信息。
#ifndef __THROW_BAD_ALLOC
# if defined(__STL_NO_BAD_ALLOC) || !defined(__STL_USE_EXCEPTIONS)
# include <stdio.h>
# include <stdlib.h>
# define __THROW_BAD_ALLOC fprintf(stderr, "out of memory\n"); exit(1)
# else /* Standard conforming out-of-memory handling */
# include <new>
# define __THROW_BAD_ALLOC throw std::bad_alloc()
# endif
#endif如果设置了回调函数,就会死循环调用该回调函数来尝试处理内存不足的情况。该回调函数的逻辑可以是清理系统中已经不需要或者不重要的资源等等,如果应急成功了就会返回申请到的资源,如果没有就会一直死循环。所以设置回调函数时,一定要保证能够释放出空间,否则的话就默认抛出异常更好。
deallocate
将使用完的chunk块归还给自由链表就需要使用该函数。
/* __p 不能为0 */
static void deallocate(void* __p, size_t __n)
{
if (__n > (size_t)_MAX_BYTES) // 如果归还的内存大小大于二级空间配置器最大chunk块的大小就会使用一级空间配置器来归还空间
malloc_alloc::deallocate(__p, __n);
else {
_Obj* __STL_VOLATILE* __my_free_listchunk
= _S_free_list + _S_freelist_index(__n); // 找到__n大小chunk块对应的自由链表
_Obj* __q = (_Obj*)__p;
// 获取锁
# ifndef _NOTHREADS
/*REFERENCED*/
_Lock __lock_instance;
# endif /* _NOTHREADS */
__q->_M_free_list_link = *__my_free_list; // 将归还的chunk块连接到自由链表的头部
*__my_free_list = __q; // 更新数组中指向自由链表头部的指针
// 锁在这里释放
}
}reallocate
// 参数__p为需要重新分配内存的地址
// 参数__old_sz为旧空间的大小
// 参数__new_sz为想要申请的新空间的大小
// __olod_sz与__new_sz的大小关系不确定
template <bool threads, int inst>
void*
__default_alloc_template<threads, inst>::reallocate(void* __p,
size_t __old_sz,
size_t __new_sz)
{
void* __result;
size_t __copy_sz; // 需要拷贝的字节数
// 如果新空间和旧空间都大于二级空间配置器的管辖范围,就直接使用标准库的realloc
if (__old_sz > (size_t) _MAX_BYTES && __new_sz > (size_t) _MAX_BYTES) {
return(realloc(__p, __new_sz));
}
if (_S_round_up(__old_sz) == _S_round_up(__new_sz)) return(__p); // 如果新空间对应的chunk大小等于旧空间对应的chunk块大小,就不做任何处理
__result = allocate(__new_sz); // 申请新空间
__copy_sz = __new_sz > __old_sz? __old_sz : __new_sz; // 确定需要拷贝的字节数,因为有可能时扩容,有可能是缩容。这里取最小的容量
memcpy(__result, __p, __copy_sz); // 拷贝
deallocate(__p, __old_sz); // 释放旧空间
return(__result);
}总结
SGI-STL二级空间配置器内存池的优点:
1、对于每一种字节数的chunk块分配,都是给出一部分进行使用,另一部分作为备用,这个备用可以给当前字节数chunk块自由链表使用,也可以给其他字节数chunk块自由链表使用。
2、备用内存块划分完chunk块后,如果还有剩余的很小的内存块,在再次分配chunk的时候,会把这些小的内存块再次分配出去,没有内存浪费。
3、当指定字节数内存分配失败之后,有一个异常处理的过程,bytes - 128字节所有的chunk对应的自由链表都会被检查,如果哪一个自由链表有空闲的chunk块,就会直接借过来。如果借不到,还会调用oom_malloc这么一个预先设置好的malloc内存分配失败之后的回调函数,如果没设置该回调函数就会进行相应的异常处理。
一级空间配置器allocate

二级空间配置器allocate

_S_refill

_S_chunk_alloc

二级空间配置器deallocate

二级空间配置器reallocate

_S_oom_malloc

各函数流程图和SGI-STL源码可从此处下载:SGI-STL相关资料 密码:kotori
感谢你的阅读,如有错误还请指正!