YOLO检测蒸馏
和分类和分割蒸馏的差异:
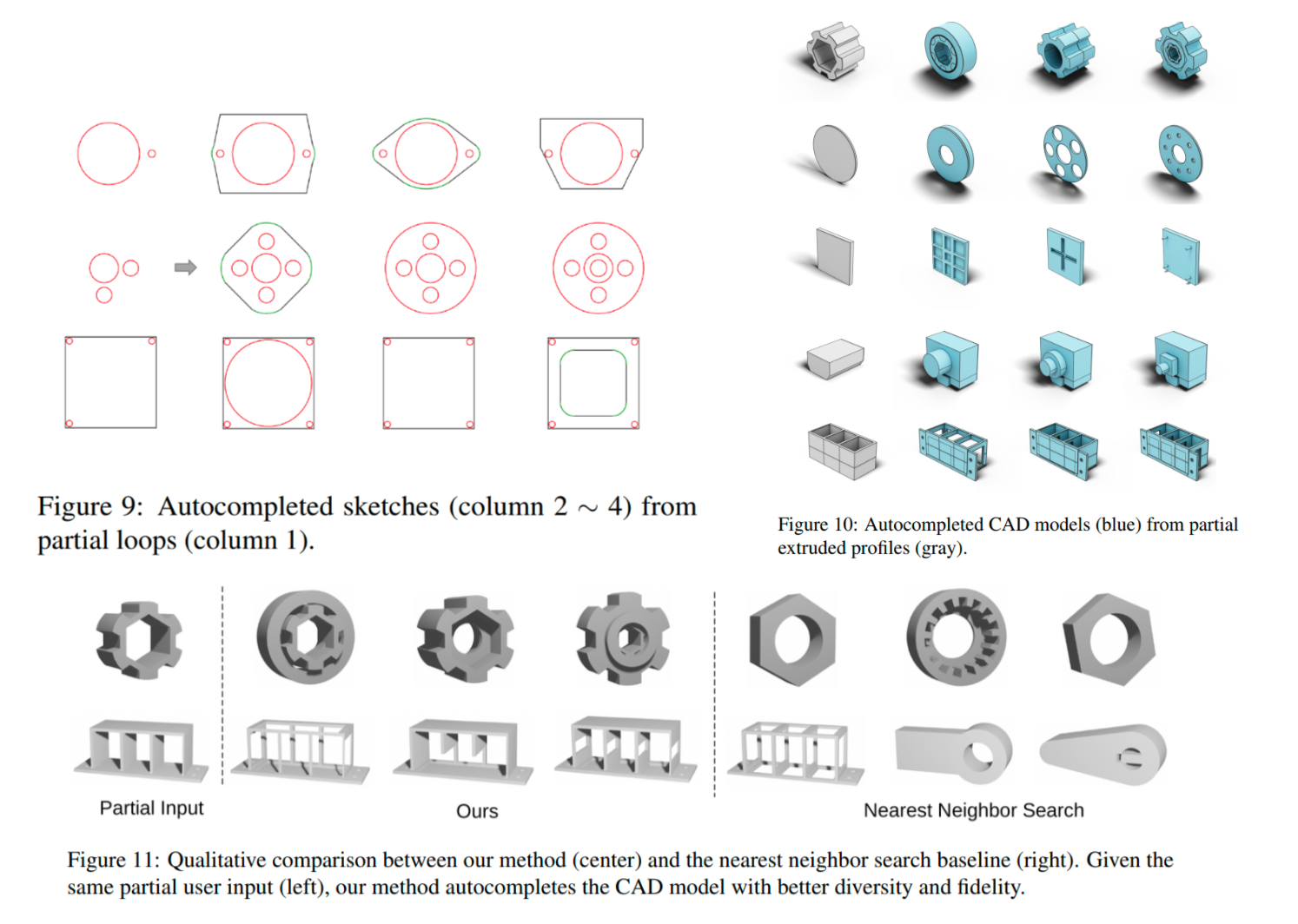
由于YOLOv3检测框的位置输出为正无穷到负无穷的连续值,和上面将的分类离散kdloss不同,而且由于yolo是基于anchor的one stage模型,head out中99%都是背景预测。
Object detection at 200 Frames Per Second论文中指出,
直接在Yolo算法中引入distillation loss会有一些问题,因为目前的network distillation算法主要是针对RCNN系列的object detection算法(或者叫two stage系列)。对于two stage的object detection算法而言,其最后送给检测网络的ROI数量是很少的(默认是128个),而且大部分都是包含object的bbox,因此针对这些bbox引入distillation loss不会有太大问题。但是对于Yolo这类one stage算法而言,假设feature map大小是1313,每个grid cell预测5个bbox,那么一共就会生成1313*5=845个bbox,而且大部分都是背景(background)。如果将大量的背景区域传递给student network,就会导致网络不断去回归这些背景区域的坐标以及对这些背景区域做分类,这样训练起来模型很难收敛。因此,作者利用Yolo网络输出的objectness对distillation loss做一定限定,换句话说,只有teacher network的输出objectness较高的bbox才会对student network的最终损失函数产生贡献,这就是objectness scaled distillation。
原来Yolo算法的损失函数,包含3个部分(公式1):1、objectness loss,表示一个bbox是否包含object的损失;2、classification loss,表示一个bbox的分类损失;3、regression loss,表示一个bbox的坐标回归损失。
Yolo损失:回归损失+目标损失+分类损失,核心的算法如下图:

code
def distillation_output_MSEloss(outs, soft_outs):
lambda_pi = 10
loss_distillation = 0
# pi = []
# t_pi = []
t_lcls , t_lbox, t_lobj = 0, 0, 0
DboxLoss = nn.MSELoss(reduction="none")
DclsLoss = nn.MSELoss(reduction="none")
DobjLoss = nn.MSELoss(reduction="none")
for index in range(len(outs[0])):
num_grid_h = outs[0][index].size(2)
num_grid_w = outs[0][index].size(3)
pi = outs[0][index].view(-1,3,13,num_grid_h,num_grid_w).permute(0, 1, 3, 4, 2).contiguous()
t_pi = soft_outs[0][index].view(-1,3,13,num_grid_h,num_grid_w).permute(0, 1, 3, 4, 2).contiguous()
t_obj_scale = t_pi[..., 4].sigmoid()
# BBox
b_obj_scale = t_obj_scale.unsqueeze(-1).repeat(1, 1, 1, 1, 4)
t_lbox += torch.mean(DboxLoss(pi[..., :4], t_pi[..., :4]) * b_obj_scale)
# Class
c_obj_scale = t_obj_scale.unsqueeze(-1).repeat(1, 1, 1, 1, 8)
t_lcls += torch.mean(DclsLoss(pi[..., 5:], t_pi[..., 5:]) * c_obj_scale)
#objectness
t_lobj += torch.mean(DobjLoss(pi[..., 4], t_pi[..., 4]) * t_obj_scale)
loss_distillation = t_lbox + t_lcls + t_lobj
loss_distillation = lambda_pi * loss_distillation
return loss_distillation