1. 单机服务器的瓶颈:
单机服务器:一台服务器独立运行一个工程所需的全部的业务模块

- 受限于服务器硬件资源,所承受用户并发量受限,32位linux操作系统最大并发量为两万
- 任一模块的变动和修改,都会导致整个项目代码重新编译、部署,浪费大量时间成本
- 系统模块对硬件资源的需求不一样,CPU密集型(3D展示,大量计算)、I/O密集型(服务器信息收发),部署在一台服务器则对服务器的整体硬件资源提出更高的要求,增加了成本
2. 集群服务器:
分布式集群服务器:每一个服务器都运行一个工程的所有模块。

优点:
- 解决了单机服务器的并发量限制,但是服务器机数和并发量并不成正比关系
- 配置简单,只需要在服务器部署所有模块并增加Nginx反向代理的服务器配置即可
缺点:
- 项目代码的修改需要所有服务器重新编译,单机只进行一次部署而现在要进行多次部署!
- 部分使用量少,不需要大量并发的模块仍然部署在所有服务器一定程度上浪费了资源
- 并未解决功能模块对服务器的多硬件资源需求问题(CPU密集型、I/O密集型)
3. 分布式服务器:
分布式服务器:一个工程拆分了很多模块,每一个模块独立部署运行在一个服务器主机上,所有服务器协同工作共同提供服务,每一台服务器称作分布式的一个节点,根据节点的并发要求,对一个节点可以再做节点模块集群部署

优点:
- 可以将工程模块分别部署在不同的服务器,根据模块对硬件资源的需求:
-
- 分别将CPU密集型的模块部署在CPU资源较好的服务器;
- 将I/O密集型的模块部署在CPU资源较差的服务器,解决了单机、集群均无法解决的问题;
- 将并发要求高的模块结点进行集群部署,扩充并发。
- 当单独模块的代码需要修改时,仅编译当前的模块代码并在当前服务器编译部署,并不影响其他的模块正常运行
- 可以根据服务器的资源条件,进行最匹配的功能模块,最大化的利用资源,避免资源浪费,并部署高可用,容灾的主备服务器功能保障服务器可靠性
引发的问题:
1.大系统的软件模块该怎么划分?
- 模块和模块之间的界线不清晰(有的模块里面的函数调动另一个模块的函数代码)
- 各模块可能实现大量重复的代码!如果在不同模块重复的公共代码修改成过程中逐渐分离,变成不可控制了。
2、各模块之间该怎么访问?
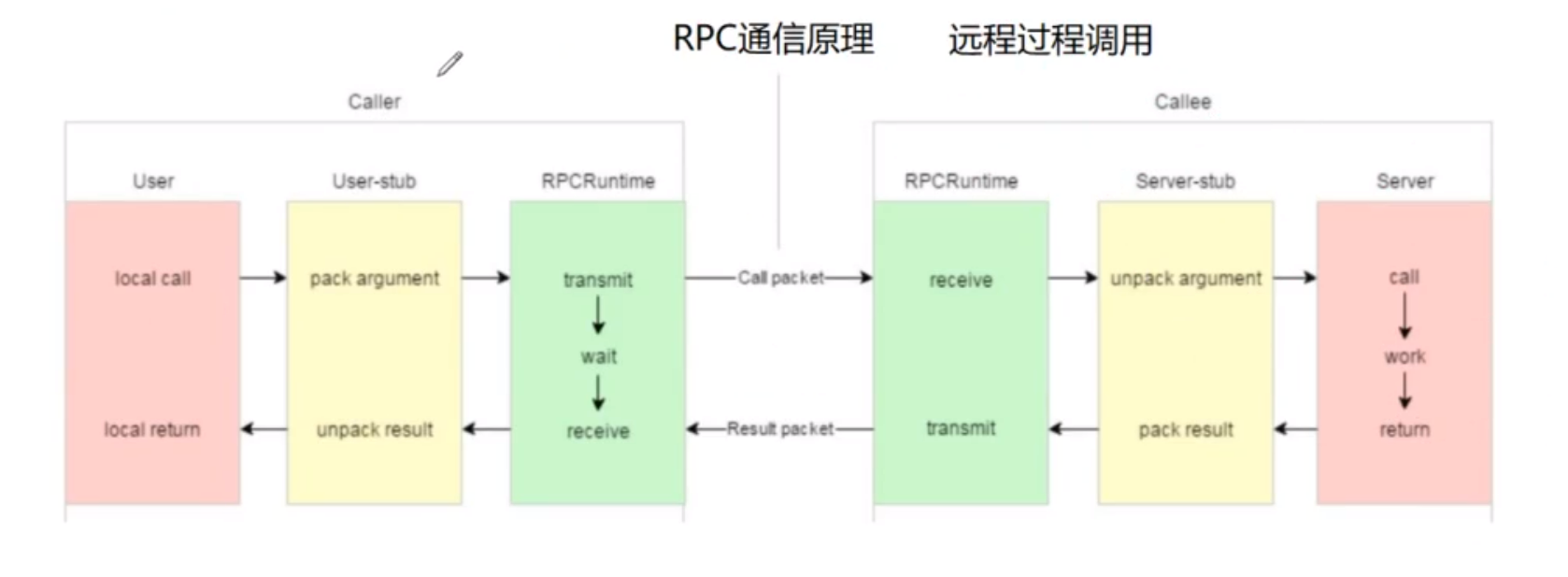
因为现在各模块可能运行不在一个机器上,或者不在一个进程上。
在单机或者集群中,这些模块是运行在一个服务器进程当中,相当于自己调用自己。但是在分布式中,用户管理和好友管理部署在不同的进程中,用户管理进程如何调用另一个模块上的业务呢?
机器1上的模块怎么调用机器2上的模块的一个业务方法呢?(软件设计师通过经验来解决)
机器1上的一个模块进程1怎么调用机器1上的模块进程2里面的一个业务方法呢?

调用过程涉及网络传输,携带区分函数的标识(函数的参数,函数命名等)发送给另一台机器调用方法,将传递过来的参数代入执行,执行之后将返回值通过网络返回。